用于自定义音频体验的系统和处理方法与流程
本公开总体涉及一种用于自定义音频体验的系统和处理方法。
背景技术:
通常,期望提供适合于个人的音频体验。然而,承认的是在实现这一点时可能存在困难。
在根本上,人的头部是独特的。因此,个人可以感知音频信号的方式会有所不同。在消声条件下,这可以基于头部相关脉冲响应(headrelatedimpulseresponse,hrir)/头部相关传递函数(headrelatedtransferfunction,hrtf)来共同地表征。
此外,需要考虑音频信号如何在给定环境(例如,房间)中行进并且到达人可能使得事情进一步复杂化。可以基于双耳房间脉冲响应(binauralroomimpulseresponse,brir)/双耳房间传递函数(binauralroomtransferfunction,brtf)来共同地表征房间中的音频信号的行进。
在一个示例中,为个人自定义音频体验的当前解决方案涉及将对象个体的图像(例如,个体的照片)与brir/brtf数据库或hrir/hrtf数据库进行匹配,以获得最佳地匹配主体个体的brir/brtf/hrir/hrtf(即通常基于主体个体的图像和与brir/brtf/hrir/hrtf相关联的相应图像之间的相似性)。
本公开预期上述方法不是理想的。
因此,本公开预期因此需要至少部分地改进用于自定义音频体验的当前解决方案的解决方案/提供用于自定义音频体验的不同/改进的方法的解决方案。
技术实现要素:
根据本公开的一方面,提供了一种处理方法。
该处理方法可以包括处理对象的至少一个捕获图像以生成至少一个输入信号。可以在处理装置处处理捕获图像以生成(一个或多个)输入信号。
该处理方法还可以包括基于至少一个数据库信号处理所生成的(一个或多个)输入信号以生成多个中间处理器数据集。该(一个或多个)数据库信号可以从至少一个数据库传送到处理装置。
该处理方法还可以包括组合多个中间处理器数据集以产生至少一个输出信号。
该(一个或多个)输出信号可以对应于对象特有的音频响应特性。优选地,该(一个或多个)输出信号可以应用于输入音频信号以生成对象可以听觉感知的输出音频信号,从而为对象提供自定义音频体验。
根据本公开的另一方面,提供了一种处理装置。
该处理装置可以被配置为与至少一个数据库进行通信,该至少一个数据库包含与基于来自至少一个人的生物识别数据的音频响应特性相对应的至少一个数据集。来自数据库的至少一个数据集可以作为相应的至少一个数据库信号被传送到处理装置。
此外,处理装置可以以多种处理模式的至少一种处理模式来操作。每种处理模式可以对应于识别器类型。
此外,处理装置可以被配置为接收对象的图像并基于所接收的图像生成至少一个输入信号。处理装置还可以被配置为基于数据库信号处理输入信号以生成至少一个输出信号。处理装置还可以进一步被配置为基于数据库信号处理输入信号以生成多个中间处理器数据集。可以组合中间处理器数据集以生成(一个或多个)输出信号。
该(一个或多个)输出信号可以对应于对象特有的音频响应特性,并且可以应用于输入音频信号以生成对象可以听觉感知的输出音频信号,从而为对象提供自定义音频体验。
附图说明
在下文中参考以下附图描述本公开的实施例,其中:
图1示出了根据本公开的实施例的可操作用于自定义音频体验并包括处理装置的系统;
图2根据本公开的实施例更详细地示出了图1的处理装置;
图3示出了根据本公开的实施例的与被配置为生成至少一个输出信号的图2的处理装置相关的示例性上下文;以及
图4示出了根据本公开的实施例的与图1的系统相关联的处理方法。
具体实施方式
本公开涉及用于自定义音频体验的系统(以及与系统相关联的处理方法)。音频体验的自定义可以基于导出至少一个自定义音频响应特性,其可以应用于由人使用的音频设备。在音频设备处,可以基于自定义音频响应特性来处理输入音频信号,以产生人以听觉感知的输出音频信号。在这方面,可以操作系统和与其相关联的处理方法以通过导出/生成对于人来说可以是独特的至少一个自定义音频响应特性来自定义人的音频体验。
音频响应特性可以与音频相关传递函数相关联。音频相关传递函数可以涉及例如头部相关脉冲响应(hrir)和/或双耳房间脉冲响应(brir)。在具体示例中,音频相关传递函数可以基于头部相关传递函数(hrtf)和/或双耳房间传递函数(brtf),其可以基于相应的hrir和/或brir的适当变换(例如,傅立叶变换)来导出。
这些将在下文中参考图1至图4进一步详细讨论。
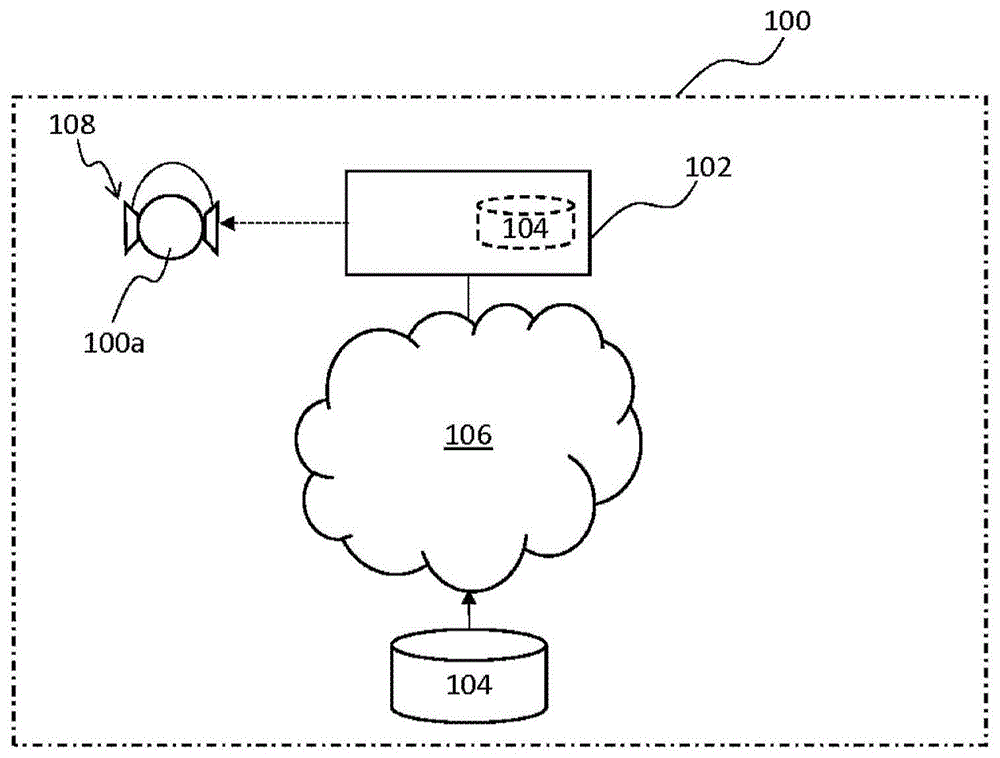
参考图1,示出了根据本公开的实施例的系统100。具体地,系统100可操作来自定义音频体验。更具体地,系统100可操作来自定义人100a的音频体验。
系统100可以包括处理装置102、一个或多个数据库104和通信网络106。系统100还可以包括音频设备108。人100a可以使用音频设备108来体验音频信号。
处理装置102可以例如对应于计算机(例如,台式计算机、智能电话、电子平板计算机、膝上型计算机、媒体播放器、或上述示例中的两个或更多个的组合)。
例如,一个或多个数据库104可以对应于一个或多个基于hrir的数据库和/或一个或多个基于brir的数据库(或者替代地,相应的一个或多个基于hrtf和/或brtf的数据库)。在一个示例中,(一个或多个)数据库104可以对应于(一个或多个)hrir/hrtf数据库,其包含关于个体对象和/或不同的人工头躯干模拟器测量、提取和/或参数化的hrir/hrtf。在另一示例中,(一个或多个)数据库104可以对应于(一个或多个)brir/brtf数据库,其包含在具有各种参数(例如,所考虑的源/接收器距离和/或方位角)的不同类型的房间中测量、提取和/或参数化的brir/brtf。在又一示例中,对象个体的图像可以与数据库相匹配,该数据库可以存储brir/brtf/hrir/hrtf的特征或参数(即而不是实际的brir/brtf/hrir/hrtf)。
通信网络106可以例如对应于互联网网络或内联网网络。
音频设备108可以例如对应于耳机,其可以由人100a佩戴以用于音频信号的音频体验。在一个实施例中,音频设备108可以包括音频源(未示出)、音频处理器(未示出)和一对扬声器驱动器(未示出)。音频源可以耦合到音频处理器。音频处理器可以耦合到该对扬声器驱动器。
处理装置102可以耦合到(一个或多个)数据库104。此外,处理装置102可以耦合到音频设备108。处理装置102可以通过有线耦合和无线耦合中的一种或两种的方式耦合到(一个或多个)数据库104和音频设备108。在这方面,处理装置102和(一个或多个)数据库104可以被配置为彼此发信号通信。此外,处理装置102和音频设备108可以被配置为彼此通信。
此外,处理装置102可以是直接耦合和间接耦合到(一个或多个)数据库104中的一个或两个。
在一个实施例中,一个或多个数据库104可以例如由一个或多个主机设备(例如,一个或多个服务器)承载。一个或多个数据库104(即由一个或多个主机设备承载)可以耦合到通信网络106。此外,处理装置102可以耦合到通信网络106。在这方面,处理装置102和(一个或多个)数据库104可以被认为是间接耦合的,因为处理装置102经由通信网络106耦合到(一个或多个)数据库104。
在另一实施例中,一个或多个数据库104可以由处理装置102承载。在这方面,处理装置102和(一个或多个)数据库104可以被认为是直接耦合的。
在又一实施例中,一个或多个数据库104可以由一个或多个主机设备(例如,一个或多个服务器)承载,并且一个或多个数据库104可以由处理装置102承载。一个或多个数据库104(由一个或多个主机设备和/或处理装置102承载)可以耦合到通信网络106。在这方面,一个或多个数据库104可以直接耦合到处理装置102,而一个或多个其他数据库104可以间接耦合(即经由通信网络106)到处理装置102。
通常,处理装置102可以被配置为捕获人100a的一个或多个图像和/或接收人100a的一个或多个捕获图像,并处理(一个或多个)捕获图像以生成至少一个输入信号。处理装置102还可以被配置为处理(一个或多个)输入信号以生成至少一个输出信号。
(一个或多个)数据库104可以与至少一个数据库信号相关联。数据库信号可以对应于(一个或多个)数据库104中包含的数据集。在一个示例中,数据集可以对应于上述hrir/hrtf。在另一示例中,数据集可以对应于上述brir/brtf。
在一个实施例中,处理装置102可以被配置为基于可以从(一个或多个)数据库104传送的(一个或多个)数据库信号来处理(一个或多个)输入信号,以生成/产生(一个或多个)输出信号。
可以从处理装置102传送生成的(一个或多个)输出信号以进行进一步处理。具体地,(一个或多个)输出信号可以从处理装置102传送到音频装置108以进行进一步处理。更具体地,可以基于所接收的(一个或多个)输出信号来处理音频设备108处的一个或多个输入音频信号,以产生/生成一个或多个输出音频信号。
更具体地,在音频设备108处,可以生成输入音频信号并将其从音频源传送到音频处理器。可以基于从处理装置102传送的(一个或多个)输出信号来配置音频处理器。具体地,音频处理器可以被配置为基于(一个或多个)输出信号来处理输入音频信号以生成/产生输出音频信号。所生成的输出音频信号可以从音频处理器传送到扬声器驱动器。
(一个或多个)输出音频信号可以经由扬声器驱动器从音频设备108输出,并且可以由穿戴音频设备108的人100a听觉地感知。
在一个实施例中,可以处理人100a的捕获图像以提取/确定与人100a相关联的输入数据。与人100a相关联的输入数据可以例如对应于与人100a相关联的生物识别数据(一个或多个耳廓特征、与眼睛分离相关的距离等)。在这方面,(一个或多个)输入信号可以对应于与人100a相关联的生物识别数据,并且(一个或多个)输出信号可以对应于与(一个或多个)音频响应特性(例如,音频相关传递函数)相对应的输出数据,该音频响应特性对于人100a来说可以是独特的。因此,可以认为生成(一个或多个)输出信号以便于促进自定义人100a的音频感知体验(即音频体验)。
通常,本公开预期可以通过导出/生成人100a的至少一个自定义音频响应特性(即输出信号)的方式来针对人100a自定义音频体验。通过基于(一个或多个)自定义音频响应特性处理输入音频信号以生成用于人100a可听觉感知的输出音频信号,可以针对人100a自定义音频体验。
人100a的图像捕获、处理(一个或多个)捕获图像以生成(一个或多个)输入信号、以及处理(一个或多个)输入信号以产生/生成(一个或多个)输出信号将在下文参考图2进一步详细讨论。
图2更详细地示出了根据本公开的实施例的处理装置102。
如图所示,处理装置102可以包括输入部分202、处理部分204和输出部分206。处理装置102还可以包括收发器部分208。输入部分202可以耦合到处理部分204。处理部分204可以耦合到输出部分206。此外,处理部分204可以耦合到收发器部分208。
在一个实施例中,输入部分202可以对应于图像捕获设备,该图像捕获设备被配置为可以以捕获人100a的一个或多个图像的方式操作。在另一实施例中,输入部分202可以对应于收发器,该收发器被配置为从输入源(未示出)接收人100a的一个或多个捕获图像。输入源例如可以是远程图像捕获设备,其可以通过有线耦合和无线耦合中的一个或两者连接到输入部分202。
在一个实施例中,处理部分204可以对应于微处理器,并且可以包括图像处理部分204a和自定义处理部分204b。图像处理部分204a可以耦合到输入部分202。此外,图像处理部分204a可以耦合到自定义处理部分204b。自定义处理部分204b可以耦合到输出部分206和收发器部分208中的一者或两者。
图像处理部分204a可以被配置为接收人100a的一个或多个捕获图像以进行进一步处理以产生/生成一个或多个输入信号。如前所述,(一个或多个)输入信号可以对应于与人100a相关联的生物识别数据。在一个实施例中,图像处理部分204a可以被配置为接收捕获图像并通过图像处理技术处理捕获图像,以自动提取与人100a相关联的生物识别数据。在一个示例中,所提取的生物识别数据可以与人100a的耳朵的耳廓/外耳相关。在另一示例中,所提取的生物识别数据可以与人100a的头部/肩部相关。对应于所提取的生物识别数据的输入信号可以从图像处理部分204a传送到自定义处理部分204b。
自定义处理部分204b可以被配置为接收一个或多个输入信号以进一步处理以产生/生成一个或多个输出信号。可以基于一个或多个处理策略来处理(一个或多个)输入信号。例如,可以基于第一处理策略、第二处理策略和第三处理策略中的一个或多个或其任何组合来处理(一个或多个)输入信号。
在一个实施例中,可以基于第一处理策略、第二处理策略和第三处理策略中的任何一个来处理(一个或多个)输入信号。在另一实施例中,可以基于第一处理策略、第二处理策略和第三处理策略的任何组合来处理(一个或多个)输入信号。
例如,第一处理策略可以对应于基于多匹配处理的策略。
关于基于多匹配处理的策略,本公开预期在一个实施例中,从捕获图像提取的生物识别数据可以(例如,经由收发器部分208)从处理装置102传送到(一个或多个)数据库104,以标识和获取与生物识别数据相匹配的一个或多个数据集(例如,hrir/htrf或brir/brtf)。具体地,处理装置102可以被配置为标识和获取与生物识别数据相匹配的一个或多个数据集
此外,关于基于多匹配处理的策略,本公开预期在另一实施例中,可以训练处理装置102。如稍后将进一步详细讨论的,处理装置102的训练可以例如基于第二处理策略和第三处理策略中的一者或二者。具体地,处理装置102可以例如被训练(例如,基于第二和/或第三处理策略),并且可以由经训练的处理装置102基于生物识别数据来标识和获取一个或多个数据集(例如,hrir/htrf或brir/brtf)。
本公开进一步预期所获取的(一个或多个)数据集可以不被认为是与生物识别数据相关的完美匹配。
具体地,本公开预期所获取的每个数据集可以与关于生物识别数据的一定程度的不匹配相关联。在这方面,处理装置102可以被配置(例如,通过编程的方式)为确定关于生物识别数据的与每个获取的数据集相关联的置信水平。置信水平可以是对参考生物识别数据的所获取的数据集的匹配或不匹配程度的度量。因此,置信水平可以被认为是形式接近度度量(即匹配程度或不匹配程度),其量化所获取的数据集与生物识别数据之间的匹配程度/不匹配程度。
例如,基于生物识别数据,可以获取第一数据集(即第一brir)、第二数据集(即第二brir)和第三数据集(即第三brir)。与第二和第三brir相比,第一brir可以被认为是与生物识别数据最接近的匹配。第二brir可以被认为是与生物识别数据下一最接近的匹配,然后是第三brir。如果完全匹配可以用置信水平“1”量化并且完全不匹配可以用置信水平“0”量化,则第一至第三brir可以例如分别用置信水平“0.8”、“0.6”和“0.4”量化。
基于基于多匹配处理的策略所获取的每个数据集(例如,第一brir、第二brir和第三brir)可以被认为是中间处理器数据集。例如,第一brir、第二brir和第三brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集和第三中间处理器数据集。
在这方面,可以基于第一处理策略生成/导出一个或多个中间处理器数据集。如稍后将进一步详细讨论的,处理装置102可以被配置为进一步处理(一个或多个)中间处理器数据集以生成/产生输出信号。
例如,第二处理策略可以对应于基于多识别器的处理策略。
关于基于多识别器的处理策略,本公开预期处理装置102可以被配置为多识别器。具体地,处理装置102可以通过训练的方式被配置为多识别器。更具体地,处理装置102可以被训练为基于多个训练参数来获取一个或多个数据集(例如,一个或多个brir)。
例如,多个训练参数可以基于与生物识别数据相关联的特征类型(即生物识别数据特征类型)。具体地,多个训练参数可以基于与生物识别数据相关联的多个特征类型。可以针对与生物识别数据相关联的每个特征类型捕获一个或多个人的图像。
如上所述,生物识别数据的示例可以包括(一个或多个)耳廓特征和与眼睛分离相关的距离(即眼睛分离)。生物识别数据的另一示例可以包括人100a头部的大小(即头部半径)。此外,耳廓特征可以例如与耳廓的尺寸(即耳廓半径)相关。
在这方面,头部半径可以被认为是第一生物识别数据特征类型的示例,并且耳廓半径可以被认为是第二生物识别数据特征类型的示例。此外,眼睛分离可以被认为是第三生物识别数据特征类型的示例。
此外,在示例中,五个人(即第一对象“a”、第二对象“b”、第三对象“c”、第四对象“d”和第五对象“e”)的图像可以关于每个生物识别数据特征类型来捕获。
在一个示例中,训练参数可以包括第一和第二生物识别数据特征类型。在另一示例中,训练参数还可以包括第三生物识别数据特征类型。在这方面,在一个示例中,训练参数可以包括五组(即对象“a”至“e”)第一和第二生物识别数据特征类型中的每一个。在另一示例中,训练参数还可以包括五组(即对象“a”至“e”)第三生物识别数据特征类型。
作为示例,处理装置102可以基于三种生物识别数据特征类型被训练为三类型识别器(即多识别器)。具体地,处理装置102可以被训练为第一类型识别器(例如,基于对象“a”到“e”中的每一个的头部半径)、第二类型识别器(例如,基于对象“a”到“e”中的每一个的耳廓半径)和第三类型识别器(例如,基于对象“a”到“e”中的每一个的眼睛分离)。此外,以与前面参考基于多匹配处理的策略所讨论的类似的方式,给定新的第一生物识别数据特征类型、新的第二生物识别数据特征类型和新的第三生物识别数据特征类型中的相应的一个或多个,第一至第三类型识别器中的一个或多个可以被配置为从(一个或多个)数据库104标识和获取一个或多个数据集(例如,hrir/htrf或brir/brtf)。(一个或多个)新的生物识别数据特征类型可以基于新对象(即第六对象“f”)。
本公开预期训练参数可以基于其他特征,例如,与数据集相关联的特征。例如,brir的频谱幅度、频谱陷波和brir的峰值可以用作训练参数。
在一个示例中,处理装置102可以基于brir频谱峰值和陷波被训练为第一类型识别器。处理装置102还可以基于brir频谱幅度被训练为第二类型识别器。第一类型识别器(即基于brir频谱峰值和陷波)可以强调某些空间特性,例如,对音频源的高度的敏感度。第二类型识别器(即基于brir频谱幅度)可以涉及人的头部的形状。
本公开进一步预期,除了上述(一个或多个)特征类型之外,处理装置102的训练(即被配置为多识别器)可以通过一种或多种机器学习方法(例如,神经网络和统计混合模型)的方式。
基于基于多识别器的处理策略所获取的每个数据集可以被认为是中间处理器数据集。在一个示例中,第一至第三类型识别器各自可以被配置为标识和获取一个或多个数据集(即一个或多个中间处理器数据集)。
在一个具体示例中,第一类型识别器可以被配置为标识和获取第一brir和第二brir,第二类型识别器可以被配置为标识和获取第三brir,并且第三类型识别器可以被配置为标识和获取第四brir和第五brir。第一至第五brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集、第三中间处理器数据集、第四中间处理器数据集和第五中间处理器数据集。
在另一具体示例中,第一类型识别器可以被配置为标识和获取第一brir和第二brir,并且第三类型识别器可以被配置为标识和获取第三brir。第一至第三brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集和第三中间处理器数据集。
在又一具体示例中,第一类型识别器可以被配置为标识和获取第一brir,第二类型识别器可以被配置为标识和获取第二brir,并且第三类型识别器可以被配置为标识和获取第三brir。第一至第三brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集和第三中间处理器数据集。
在这方面,可以基于第二处理策略生成/导出一个或多个中间处理器数据集。如稍后将进一步详细讨论的,处理装置102可以被配置为进一步处理(一个或多个)中间处理器数据集以生成/产生输出信号。
例如,第三处理策略可以对应于基于集群(cluster)的处理策略。
关于基于集群的处理策略,本公开预期可以使用诸如基于k均值的集群、基于层级分布的集群、基于密度的集群和基于机器学习(ai)的集群(例如,支持向量机集群和深度卷积神经网络)之类的方法来对一个或多个)数据库104的/来自(一个或多个)数据库104的数据集(例如,brir)进行集群(即分组)。具体地,在示例中,可以从(一个或多个)数据库104获取一个或多个数据集,并且可以通过集群所获取的数据集来导出一个或多个集群组。
在一个实施例中,处理装置102可以进行基于集群的训练。具体地,处理装置102可以由所导出的一个或多个集群组进行训练。优选地,可以将被认为相似的数据集(例如,相似的brir)进行分组以形成集群。
例如,基于关于每种生物识别特征类型所捕获的五个人(即第一对象“a”、第二对象“b”、第三对象“c”、第四对象“d”和第五对象“e”)的图像的先前示例,可以获得第一数据集(即第一brir)、第二数据集(即第二brir)、第三数据集(即第三brir)、第四数据集(即第四brir)和第五数据集(即第五brir)。例如,第一和第二brir可以被分组为第一集群,而第三、第四和第五brir可以例如被分组为第二集群。此外,可以理解,上述五个人的示例的图像可以对应于第一图像(即与第一数据集相关联)、第二图像(即与第二数据集相关联)、第三图像(即与第三数据集相关联)、第四图像(即与第四数据集相关联)和第五图像(即与第五数据集相关联)。
处理装置102可以通过关联的方式来训练。例如,可以通过将第一图像与第一集群相关联、将第二图像与第一集群相关联、将第三图像与第二集群相关联并将第四图像与第二集群相关联的方式来训练处理装置102。
可以理解,由一个集群(即一组数据集)训练的处理装置102可以对应于模型。因此,当由多个集群(例如,第一集群、第二集群和第三集群)训练时,处理装置102可以对应于多个模型(即基于第一集群的第一模型、基于第二集群的第二模型和基于第三集群的第三模型)。可以理解,可以促进更精确的插值,因为与数据库104中所包含的数据集的整个集合相比,模型的域空间通常更小。例如,插值可以在频域或时域中。
在一个实施例中,处理装置102可以被配置为基于上述多个模型中的一个或多个模型从(一个或多个)数据库104导出一个或多个数据集(例如,brir/brtf或hrir/hrtf)。在另一实施例中,处理装置102可以被配置为表征每个模型(即来自上述多个模型)以导出/生成响应特性。
根据本公开的实施例,基于基于集群的处理策略所获取的每个数据集可以被认为是中间处理器数据集。在一个示例中,基于上述多个模型(例如,第一至第三模型)中的一个或多个模型,处理装置102可以被配置为标识和获取一个或多个对应的数据集(例如,一个或多个brir)。
在一个具体示例中,基于第一模型,处理装置102可以被配置为标识和获取第一brir和第二brir。基于第二模型,处理装置102可以被配置为标识和获取第三brir。基于第三模型,处理装置102可以被配置为标识和获取第四brir和第五brir。第一至第五brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集、第三中间处理器数据集、第四中间处理器数据集和第五中间处理器数据集。
在另一具体示例中,基于第一模型,处理装置102可以被配置为标识和获取第一brir和第二brir。基于第二模型,处理装置102可以被配置为标识和获取第三brir。第一至第三brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集和第三中间处理器数据集。
在又一具体示例中,基于第一模型,处理装置102可以被配置为标识和获取第一brir。基于第二模型,处理装置102可以被配置为标识和获取第二brir。基于第三模型,处理装置102可以被配置为标识和获取第三brir。第一至第三brir可以被认为分别对应于第一中间处理器数据集、第二中间处理器数据集和第三中间处理器数据集。
前面提到,在另一实施例中,处理装置102可以被配置为表征每个模型(即来自上述多个模型)以导出/生成响应特性。在一个示例中,基于上述多个模型(例如,第一至第三模型)中的一个或多个模型,处理装置102可以被配置为导出/生成一个或多个相应的响应特性。
根据本公开的另一实施例,基于基于集群的处理策略所导出/生成的每个响应特性可以被认为是中间处理器数据集。在一个示例中,基于上述多个模型(例如,第一至第三模型)中的一个或多个模型,处理装置102可以被配置为导出/生成一个或多个相应的响应特性(例如,第一响应特性、第二响应特性和第三响应特性)。所导出/生成的(一个或多个)响应特性可以对应于所导出/生成的(一个或多个)中间处理器数据集(例如,第一中间处理器数据集、第二中间处理器数据集和第三中间处理器数据集)。例如,第一至第三响应特性可以分别对应于第一至第三中间处理器数据集。
本公开预期处理装置102可以被配置为通过静态集群表征和动态集群表征中的一者或二者的方式来表征(一个或多个)模型。此外,每个集群可以与质心(centroid)和多个数据集(例如,brir/brtf或hrir/hrtf)相关联。
关于静态集群表征,可以考虑数据集(例如,brir)和/或集群的质心。在一个示例中,可以获得集群中的brir的平均值以导出/生成响应特性。在另一示例中,可以标识被认为是最接近质心的brir以导出/生成响应特性。在又一示例中,可以获得所有brir的加权和(其中更接近质心的brir比距质心更远的brir被加权更高)以导出/生成响应特性。在又一示例中,可以基于一般统计方法(例如,基于中值的统计方法)来考虑数据集。
可以理解,在这方面,基于静态集群表征,每个模型可以与响应特性(例如,以brir的形式)相关联。例如,第一模型可以与第一响应特性(例如,以第一brir的形式)相关联,第二模型可以与第二响应特性(例如,以第二brir的形式)相关联并且第三模型可以与第三响应特性(例如,以第三brir的形式)相关联。
关于动态集群表征,可以结合捕获的新图像(例如,在关于第一对象“a”、第二对象“b”、第三对象“c”、第四对象“d”和第五对象“e”的五个图像的先前示例的上下文中,关于新的第六对象“f”的第六图像)来考虑数据集和/或集群的质心。
可以从(一个或多个)数据库104标识和获取(例如,以与前面讨论的类似的方式)与新捕获的图像(例如,新的第六对象“f”的图像)相关联的数据集(例如,brir)。此外,可以将新捕获的图像(即第六图像)与例如第一至第五图像进行比较。例如,可以将与第六图像相关联的生物识别数据与和(与第一图像至第五图像相关联的)相应的生物识别数据相关联的生物识别数据进行比较。通过确定第六图像与第一至第五图像中的任何一个或任何组合之间的相似性/接近度的方式,可以确定与和第六图像相关联的数据集相关联的权重/贡献。
基于与第六图像相关联的数据集的权重/贡献,可以以与先前关于静态集群表征所讨论的类似的方式来确定响应特性。
例如,先前在静态集群表征的上下文中提到,质心可以用作确定所有brir的加权和(其中更接近质心的brir比距质心更远的brir被加权更高)的参考,以便导出/生成响应特征。在动态集群表征的情况下,代替质心,与新捕获的图像(例如,第六图像)相关联的数据集的权重/贡献可以用作参考。
在这方面,可以基于第三处理策略生成/导出一个或多个中间处理器数据集。如稍后将进一步详细讨论的,处理装置102可以被配置为进一步处理(一个或多个)中间处理器数据集以生成/产生输出信号。
基于关于处理策略的上述内容,可以理解,可以基于处理策略中的任何一个或处理策略的任何组合来导出/产生多个中间处理器数据集,以产生至少一个输出信号。前面提到,(一个或多个)输出信号可以对应于例如自定义音频响应特性(例如,音频相关传输函数)形式的输出数据。这些将在下文中参考图3基于示例性上下文300进一步详细讨论。
参考图3,示出了根据本公开的实施例的与被配置为生成至少一个输出信号的处理装置102相关的示例性上下文300。
具体地,在示例性上下文300中,数据库104可以是基于brir的数据库,其包含多个brir(即如图3所示的brira至brirl)。
此外,可以基于先前讨论的处理策略的组合来配置处理装置102。例如,处理装置102可以通过基于先前讨论的第二和第三处理策略的组合的训练的方式来配置以导出/产生多个中间处理器数据集,并且基于第一处理策略组合中间处理器数据集。
此外,可以考虑多个对象302用于训练处理装置102。例如,可以考虑至少五个对象(即对象“a”至对象“e”)用于训练处理装置102。此外,生物识别数据可以涉及第一生物识别数据特征类型(例如,五个对象中的每一个的耳廓半径)和第二生物识别数据特征类型(例如,五个对象中的每一个的头部半径)中的一者或二者。
更具体地,如箭头302a所示,处理装置102可以被配置为捕获数据(即捕获五个对象中的每一个的图像)和接收捕获数据(即五个对象中的每一个的捕获图像)中的一者或二者,该数据对应于第一图像(即对象“a”)、第二图像(即对象“b”)、第三图像(即对象“c”)、第四图像(即对象“d”)和第五图像(即对象“e”)。
第一至五图像可以各自与来自brir数据库104的brir相关联。具体地,第一图像可以与第一brir(即brir“a”)相关联。第二图像可以与第二brir(即brir“b”)相关联。第三图像可以与第三brir(即brir“c”)相关联。第四图像可以与第四brir(即brir“d”)相关联。第五图像可以与第五brir(即brir“e”)相关联。
此外,处理装置102可以被配置为从第一至第五图像中的每一个提取生物识别数据。如上所述,所提取的生物识别数据可以包括耳廓半径和头部半径中的一者或二者。在这方面,处理装置102可以被配置为确定每个对象(即对象“a”到“e”)的耳廓半径和/或头部半径。
在一个实施例中,处理装置102可以通过集群的方式进一步处理第一至第五brir。集群可以基于所提取的生物识别数据,例如,头部半径。例如,第一至第五brir可以基于每个对象(即对象“a”至对象“e”)的头部半径进行基于k均值的集群以导出第一集群和第二集群。具体地,第一集群可以例如包括第一brir(即brir“a”)、第二brir(即brir“b”)和第五brir(即brir“e”)。第二集群可以例如包括第三brir(即brir“c”)和第四brir(即brir“d”)。
此外,可以通过多个训练选项来训练处理装置102。该多个训练选项可以包括例如第一训练选项和第二训练选项。
例如,第一训练选项可以涉及基于第一生物识别数据特征类型(例如,耳廓半径)将处理装置102训练为第一类型识别器。具体地,基于第一图像(即对象“a”)提取的耳廓半径可以与第一brir(即brir“a”)相关联,基于第二图像(即对象“b”)提取的耳廓半径可以与第二brir(即brir“b”)相关联,基于第三图像(即对象“c”)提取的耳廓半径可以与第三brir(即brir“c”)相关联,基于第四图像(即对象“d”)提取的耳廓半径可以与第四brir(即brir“d”)相关联,并且基于第五图像(即对象“e”)提取的耳廓半径可以与第五brir(即brir“e”)相关联。
处理装置102可以被配置为以参考表304(即基于生物识别数据特征类型和数据集之间的关联的参考数据的表)的形式存储耳廓半径和brir之间的上述关联中的每一个。参考表304可以被存储在例如处理装置102的存储器部分(未示出)中。参考表304可以是用于生成一个或多个中间处理器数据集的基础,如将在后面进一步详细讨论的。
第二训练选项可以例如涉及基于第二生物识别数据特征类型(例如,头部半径)将处理装置102训练为第二类型识别器。此外,第二训练选项可以通过基于第二生物识别数据特征类型的集群的方式来导出一个或多个集群306(例如,第一集群和/或第二集群)。
在较早的示例中,可以对每个对象(即对象“a”至对象“e”)的头部半径进行集群以导出第一集群和第二集群。第一集群可以例如包括第一brir(即brir“a”)、第二brir(即brir“b”)和第五brir(即brir“e”)。第二集群可以例如包括第三brir(即brir“c”)和第四brir(即brir“d”)。
此外,可以对第一和第二集群中的每一个集群的brir进行平均(即处理装置102可以被配置为通过平均的方式来进一步处理集群)以导出/产生中间处理器数据集(例如,brir)。具体地,可以进一步处理第一集群以导出/生成中间处理器数据集(例如,brir),并且可以进一步处理第二集群以导出/生成另一个中间处理器数据集(例如,另一brir)。
在一个实施例中,(一个或多个)集群306可以用于训练处理装置102。例如,第一和第二集群可以用于训练处理装置102。
具体地,处理装置102例如可以通过头部半径(即对象)和集群(即第一集群/第二集群)之间的关联的方式基于第一和第二集群进行训练。
例如,基于第一图像(即对象“a”)提取的头部半径可以与第一集群相关联,基于第二图像(即对象“b”)提取的头部半径可以与第一集群相关联,基于第三图像(即对象“c”)提取的头部半径可以与第二集群相关联,基于第四图像(即对象“d”)提取的头部半径可以与第二集群相关联,并且基于第五图像(即对象“e”)提取的头部半径可以与第一集群相关联。
(一个或多个)集群306和第二生物识别数据特征类型(例如,头部半径)之间的关联可以以类似于上述参考表304的参考查找的形式被存储在处理装置102的存储器部分(未示出)中。
基于第二训练选项训练的处理装置102可以被配置为生成一个或多个中间处理器数据集,如稍后将进一步详细讨论的。
前面提到,处理装置102可以通过基于前面讨论的第二和第三处理策略的组合的训练的方式来配置,以导出/产生多个中间处理器数据集。
可以理解,可以基于第一和第二训练选项的组合来配置处理装置102。还可以理解,第一训练选项可以被认为是基于第二处理策略,而第二训练选项可以被认为是基于第二处理策略和第三处理策略的组合。以这种方式,根据本公开的实施例,处理装置102可以通过基于第二和第三处理策略的组合的训练的方式来配置。
此外,前面提到,参考表304(即关于第一训练选项)可以是用于生成一个或多个中间处理器数据集的基础,并且基于第二训练选项训练的处理装置102可以被配置为生成一个或多个中间处理器数据集。
处理装置102(根据本公开的实施例,其已经基于第一和第二训练选项的组合进行训练)可以被配置为基于第一处理策略组合中间处理器数据集以生成/产生至少一个输出信号。这将在关于与图1中提到的上述人100a相对应的新对象“f”生成的输出信号的上下文中进行讨论。
可以获得与新对象“f”(即人100a)相关联的捕获数据(如虚线箭头308所示)。具体地,可以获得新对象“f”的生物识别数据,并且所获得的生物识别数据可以包括第一生物识别特征类型(例如,耳廓半径)和第二生物识别特征类型(例如,头部半径)。
处理装置102可以被配置为基于第一处理模式生成/产生第一组中间处理器数据集。此外,处理装置102可以被配置为基于第二处理模式生成/产生第二组中间处理器数据集。
第一组和第二组中间处理器数据集中的每一个可以包括一个或多个中间处理器数据集(例如,一个或多个brir)。此外,第一处理模式可以基于处理装置102用作上述第一类型识别器,并且第二处理模式可以基于处理装置102用作上述第二类型识别器。
在第一处理模式中,新对象“f”的生物识别数据可以由处理装置102通过数据比较的方式进一步处理。更具体地,可以获得与新对象“f”相关联的第一生物识别特征类型(例如,耳廓半径)并且与参考表304进行比较以确定/获取可以被认为最接近匹配例如新主题“f”的耳廓半径的一个或多个brir。
在一个示例中,数据比较可以基于与预定容差的基于最接近匹配的比较。具体地,预定容差可以基于1cm的差异。更具体地,可以获取与参考表304中与新对象“f”的耳廓半径的差异小于1cm的耳廓半径相关联的brir。
在更具体的示例中,基于新对象“f”的耳廓半径与记录/存储在参考表304中的主题(即主题“a”至“e”)之间的比较。可以获取多个brir(例如,与对象“a”的耳廓半径相关联的brir、与对象“c”的耳廓半径相关联的brir和与对象“e”的耳廓半径相关联的brir)。最接近的匹配(例如,与对象“e”的耳廓半径相关联的brir)可以具有0.9的置信水平(1.0的置信水平被认为是完全匹配),下一最接近的匹配(例如,与对象“a”的耳廓半径相关联的brir)可以具有0.8的置信水平,并且随后的最接近的匹配(例如,与对象“c”的耳廓半径相关联的brir)可以具有0.6的置信水平等。
在这方面,第一组中间处理器数据集可以例如包括与置信水平0.9相关联的第一brir(例如,briri)、与置信水平0.8相关联的第二brir(例如,bririi)以及与置信水平0.6相关联的第三brir(bririii)。
在第二处理模式中,处理装置102可以通过数据比较的方式进一步处理新对象“f”的生物识别数据。更具体地,可以获得与新对象“f”相关联的第二生物识别特征类型(例如,头部半径),并与上述查找参考进行比较以获取一个或多个集群306。所获取的每个集群306可以与置信水平相关联。
例如,可以基于新对象“f”的头部半径来获取上述第一集群和上述第二集群。第一集群可以被认为是最接近的匹配,并且第二集群可以被认为是更小的程度。在这方面,第一集群可以与接近1.0(例如,0.9)的置信水平相关联,而第二集群可以与远离1.0(例如,0.5)的置信水平相关联。
此外,如前所述,可以对第一和第二集群中的每一个的brir进行平均以导出/产生中间处理器数据集(例如,brir)。具体地,可以进一步处理第一集群以导出/生成中间处理器数据集(例如,brir),并且可以进一步处理第二集群以导出/生成另一中间处理器数据集(例如,另一brir)。基于第一集群导出的brir可以对应于例如第一集群brir。基于第二集群导出的brir可以对应于例如第二集群brir。
在这方面,第二组中间处理器数据集可以例如包括与置信水平0.9相关联的第一集群brir和与置信水平0.5相关联的第二集群brir。
前面提到,处理装置102可以被配置为基于第一处理策略组合中间处理器数据集。
具体地,可以基于第一处理策略来组合第一和第二组中间处理器数据集。
在一个实施例中,可以基于加权和来组合第一和第二组中间处理器数据集以获得输出信号。
更具体地,基于加权和,输出信号可以例如是:
输出信号=0.9*briri+0.8*bririi+0.6*bririii+0.9*第一集群brir+0.5*第二集群brir
在另一实施例中,可以基于加权和来组合第一和第二组中间处理器数据集,并且该加权和还经受比例因子(即“n”)以获得输出信号。例如,输出信号=(0.9*briri+0.8*bririi+0.6*bririii+0.9*第一集群brir+0.5*第二集群brir)*n(例如,假设在该加权和中存在5个brir,n=1/5)。
图4示出了根据本公开的实施例的与图1的系统100相关联的处理方法400。
处理方法400可以包括提取步骤402、生成步骤404和输出步骤406。
在提取步骤402处,可以捕获对象(例如,上述人100a/对象“f”)的至少一个图像(例如,照片)。捕获图像可以例如对应于对象的头部的图像、对象的上躯干的图像或对象的耳朵的图像。可以在处理装置102处接收和处理(一个或多个)捕获图像以生成至少一个输入信号。
(一个或多个)输入信号可以对应于与对象相关联的生物识别数据。可以从(一个或多个)捕获图像中提取(例如,通过处理装置102)生物识别数据。在一个实施例中,生物识别数据可包括第一生物识别特征类型(例如,耳廓半径)和第二生物识别特征类型(例如,头部半径)。
在生成步骤404处,处理装置102可以基于至少一个数据库信号来进一步处理(一个或多个)所生成的输入信号。(一个或多个)数据库信号可以从至少一个数据库104传送到处理装置102。具体地,可以基于(一个或多个)数据库信号进一步处理(一个或多个)所生成的输入信号以生成多个中间处理器数据集。
在一个实施例中,处理装置102可以被训练为用作多个识别器中的至少一种类型的识别器(例如,第一类型识别器或第二类型识别器)。在另一实施例中,处理装置能够被训练为用作与至少第一类型识别器和第二类型识别器相对应的多识别器(即多个识别器)。
前面提到,处理装置102可以以某种方式用作第一类型识别器以便基于第一生物识别特征类型(例如,耳廓半径)生成第一组中间处理器数据集。此外,处理装置102可以用作第二类型识别器以基于第二生物识别特征类型(例如,头部半径)生成第二组中间处理器数据集。
在输出步骤406处,可以组合中间处理器数据集。具体地,处理装置102可以被配置为以某种方式组合中间处理器数据集以便产生至少一个输出信号。
在一个实施例中,中间处理器数据集可以包括上述第一组中间处理器数据集和上述第二组中间处理器数据集。第一和第二组中间处理器数据集中的每一个可以包括一个或多个中间处理器数据集。第一和第二组中间处理器数据集可以由处理装置102通过加权和的方式进行组合。
在另一实施例中,(一个或多个)数据库104可以包括多个数据集。该多个数据集可以以相应的多个数据库信号的形式从(一个或多个)数据库104传送到处理装置102。前面提到,(一个或多个)数据库104的多个数据集可以被分组为多个集群组(即对应于上述集群306)。每个集群组可以对应于可以包括至少一个数据集的集群(例如,上述第一集群或上述第二集群)。
此外,处理装置102可以通过关联的方式进行训练,其中,从一个或多个捕获图像(例如,从对象“a”至“e”)获取的生物识别特征类型(例如,头部半径)可以与集群(例如,上述第一集群或上述第二集群)相关联。
在这方面,在一个实施例中,处理装置102可以被训练为用作多识别器(例如,第一类型识别器和第二类型识别器),其中,识别器之一(例如,第一类型识别器)可以基于第一生物识别特征类型(例如,耳廓半径)生成第一组中间处理器数据集,并且另一识别器(例如,第二类型识别器)可以基于与集群(例如,第一集群/第二集群)相关联的第二生物识别特征类型(例如,头部半径)生成第二组中间处理器数据集。
前面提到,第一和第二组中间处理器数据集可以由处理装置102通过加权和的方式进行组合。
可以理解,(一个或多个)输出信号可以对应于对象特有的至少一个音频响应特性。此外,(一个或多个)输出信号可以应用于输入音频信号(例如,在对象穿戴的音频设备108处)以生成对象可以听觉感知的输出音频信号,从而为对象提供自定义音频体验。
更具体地,如前所述,在一个实施例中,音频设备108可以包括音频源(未示出)、音频处理器(未示出)和一对扬声器驱动器(未示出)。音频源可以耦合到音频处理器。音频处理器可以耦合到该对扬声器驱动器。
在这方面,可以基于(一个或多个)输出信号来配置音频处理器。所生成并从音频源传送到音频处理器的输入音频信号可以由音频处理器基于(一个或多个)输出信号进行处理,以生成/产生输出音频信号。所生成的输出音频信号可以从音频处理器传送到该对扬声器驱动器。穿戴音频设备108的对象可以通过该对扬声器驱动器听觉地感知输出音频信号。
本领域技术人员应进一步理解,可以组合上述特征的变化和组合(而不是替代或替换)以形成其他实施例。
以上述方式,描述了本公开的各种实施例,以解决至少一个上述缺点。这些实施例旨在由以下权利要求所涵盖,并且不限于被如此描述的部件的特定形式或布置,并且鉴于本公开对本领域技术人员将明显的是,可以进行许多变化和/或修改,这些也意图由以下权利要求所涵盖。
在一个示例中,上述集群306可以由处理装置102进一步处理,以导出具有顶级和多个较低级的集群金字塔(例如,顶级之后的第一较低级,以及可选地,第一较低级之后的第二较低级)。
顶级可以与特征相关联,该特征可以是域空间的初步分区的形式。例如,频谱幅度可以是用于初步匹配的特征,以便从例如顶级处的四个集群中选择集群。
基于所选择的集群,不同的特征(例如,频谱峰值/陷波)可以用于第一较低级处的辅助匹配。例如,可以对所选择的集群进行进一步匹配(即基于频谱峰值/陷波在所选集群内)以产生/生成细化的集群。可以基于另一特征在第二较低级处对细化的集群进行进一步的匹配(以根据第一较低级的类似方式)以产生/生成进一步细化的集群。
- 还没有人留言评论。精彩留言会获得点赞!