基于深度学习的3D-HEVC深度图编码单元快速决策方法与流程
本发明涉及视频编码领域,具体是一种基于深度学习的3d-hevc深度图编码单元尺寸快速决策方法。
背景技术:
在过去几年里,随着3d视频服务需求的增加,3d视频的展现、压缩和传输成为一个新的有挑战的研究课题。多视角加深度图(mvd)的视频格式是多种有发展前景的视频表现形式中的一种。由3d视频编码扩展开发联合协作组(jct-3v)提出的高质量视频编码的3d扩展(3d-hevc)是对于压缩mvd数据的一种新兴视频编码标准。
3d-hevc中深度图编码单元尺寸的选择过程,同hevc中纹理图编码树单元尺寸的选择过程是一样的。在hevc中,一帧图像被分割为多个互不重叠的最大编码单元(lcu),lcu大小一般设为64*64。每个lcu又可按照四叉树的方式递归划分为多个子cu。编码器编码时,需要判断当前cu是否已经进行划分。当前cu的划分情况由语法元素split_flag的值给出,其值为1表示cu已经划分,否则表示为进行子cu划分。
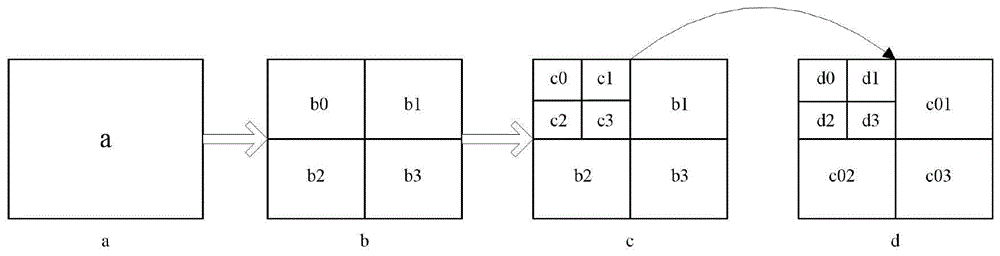
具体的划分如图1所示:1.如图1中的a,对大小为64×64深度为0的编码单元a遍历所有帧间和帧内预测模式,得到深度为0时的最优预测模式和率失真代价ra。2.如图1中的b,对a进行一次cu划分,得到四个子cu:b0,b1,b2,b3,此时编码深度为1,并对编码单元b0遍历所有帧间和帧内预测模式,得到b0的最优预测方式和率失真代价rb0。3.如图1中的c,对b0进行进一步的cu划分,得到四个子cu:c0,c1,c2和c3,此时编码深度为2,并对编码单元c0遍历所有可能的预测模式,得到c0的最优预测模式和率失真代价rc0。4.如图1中的d,对c0做进一步cu划分,得到四个子cu:d0,d1,d2和d3,此时编码深度为3,已达到最大编码深度,不能再进行cu划分。依次对d0、d1、d2和d3进行预测模式选择,得到各自对应的最优预测方式和率失真代价rd0、rd1、rd2以及rd3,计算四个cu的率失真代价之和,并与rc0进行比较,选择较小的值作为c0的最优率失真代价(记为min-rc0),其对应的预测方式以及分割方式即为c0的最优预测方式和分割方式。5.仿照第4步,依次对c1、c2和c3进行划分与预测模式选择,分别得到各自对应的最优预测方式和率失真代价min-rc1、min-rc2、min-rc3,并计算当前编码深度的四个cu的率失真代价之和,与rb0比较,得到较小的率失真代价(记为min-rb0),其所对应的预测模式以及分割方式即为b0的最优预测模式和分割方式。6.仿照第2步到第5步,依次对b1、b2和b3进行划分与预测模式选择,分别得到各自对应的最优预测方式和率失真代价min-rb1、min-rb2、min-rb3,计并计算当前编码深度的四个cu的率失真代价之和,并与ra比较,得到较小的率失真代价(记为min-ra),找出该lcu的最佳划分方式以及最优预测模式。
随着计算能力和数据量的提升,深度学习成为当前人工智能研究的热点之一。通过大批量数据训练,深度网络模型能够自动发现和提取图像特征,已普遍应用在人脸识别、图像分割、目标检测等任务上,并取得了优于传统手工特征方法的检测和识别性能。深度学习本质上是层次特征提取学习的过程,它通过构建多层隐含神经网络模型,利用海量数据训练出模型特征来提取最有利的参数,将简单的特征组合抽象成高层次的特征,以实现对数据或实际对象的抽象表达。
参考文献:
[1]techg,cheny,müllerk,etal.overviewofthemultiviewand3dextensionsofhighefficiencyvideocoding[j].ieeetransactionsoncircuits&systemsforvideotechnology,2016,26(1):35-49.
[2]xum,lit,wangz,etal.reducingcomplexityofhevc:adeeplearningapproach[j].ieeetransactionsonimageprocessing,2017,pp(99):1-1.
[3]wangt,chenm,chaoh.anoveldeeplearning-basedmethodofimprovingcodingefficiencyfromthedecoder-endforhevc[c]//datacompressionconference.ieeecomputersociety,2017:410-419.
技术实现要素:
本发明的目的是鉴于深度学习训练出的模型产生的参数对判断编码单元是否分割的重要性,提出了一种基于深度学习的3d-hevc深度图编码单元快速决策方法,该方法通过提取数据集、预处理数据集、构建深度卷积神经网络训练预处理的数据集得到64*64,32*32和16*16尺寸编码单元是否划分的参考标准。
该方法可以降低编码过程中的计算复杂度,缩短编码时间,在视频重建上也有良好的效果。
为了实现上述目的,本发明采用的技术方案如下:
步骤1:提取训练数据集
官方提供分辨率为1920*1088的gtfly、poznanhall2、undodancer、poznanstreet、shark与分辨率为1024*768的balloon、kendo、newspaper共8个测试序列。将gtfly、poznanhall2、undodancer、ballon、kendo作为训练集,poznanstreet、shark、newspaper作为测试集。具体的:提取分辨率为1920*1088的gtfly、poznanhall2、undodancer测试序列的前10帧图像组的64*64尺寸的深度图像素矩阵和分辨率为1024*768的balloon、kendo的测试序列的前26帧图像组的64*64尺寸的深度图像素矩阵作为训练集。训练集的深度图编码单元是否分割的标签通过逐级比较rd-cost的大小得到,即若分割后的rd-cost小于等于分割前的rd-cost,则设置标签为1,表示分割。若分割后的rd-cost大于分割前的rd-cost,则设置标签为0,表示不分割。
步骤2:训练集的预处理
将采集的64*64的深度图像素矩阵复制为3份,对这三个矩阵分别做不同的预处理。分别得到三个不同归一化处理的64*64的矩阵,作为卷积神经网络的输入;
步骤3:构建卷积神经网络,包括:
构建深度卷积神经网络,并设计损失函数,将得到的不同归一化处理后的64*64的矩阵输入到卷积神经网络中,调整参数,从而得到深度图编码单元是否分割的特征模型;
步骤4:卷积神经网络模型输出分类结果
通过卷积神经网络模型的训练,可以得到尺寸为64*64、32*32、16*16的深度图编码单元是否分割的判断依据。将得到的判断依据模型加载到htm13.0测试代码中,可作为判断深度图是否继续分割的标准。
步骤2所述的训练集的预处理,具体实现如下:
步骤2.1:当输入一个64*64的深度图像素矩阵时,先将此深度图像素矩阵复制为三份,对这三个矩阵分别做不同的归一化处理,分别是:
对第一个64*64的矩阵ⅰ,先对64*64个像素值求得其均值和方差,将其每个像素值减去求得的均值和方差,获得一个像素值分布均匀的矩阵i′;
对于第二个64*64矩阵ⅱ,先将其分为4个32*32矩阵,再分别求4个矩阵像素值的均值和方差,最后再将每个像素值减去求得的均值和方差,获得一个像素值分布均匀的矩阵ⅱ′
对于第三个64*64矩阵ⅲ,先将其分为16个16*16矩阵,再分别求16个矩阵像素值的均值和方差,最后再将每个像素值减去求得的均值和方差,获得一个像素值分布均匀的矩阵ⅲ′;
通过上面的不同归一化处理,可输出三个不同的64*64矩阵i′、ⅱ′、ⅲ′。
步骤2.2:将矩阵i′、ⅱ′、ⅲ′再通过下采样公式:
分别得到尺寸为16*16、32*32、64*64的像素矩阵,其中n为原始编码单元的宽度,p为添加宽度,f为卷积宽度,s为步长。
步骤3所述的构建卷积神经网络,具体实现如下:
所述的卷积神经网络包括3个卷积层和4个全连接层,最终得到3个模型m1、m2、m3,分别用于判断64*64、32*32、16*16是否分割的依据。在神经网络中,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着海量的参数,同时,会导致计算量的增大以及有可能会导致过拟合。解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这表明臃肿的稀疏网络可能被不失性能地简化。在该步骤的模块使用卷积inception结构,使得既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
在设计损失函数时,假设有r个训练样本集,总体的损失函数则定义为:
其中,lr是尺寸为64*64、32*32、16*16编码单元是否分割的有效标签的交叉熵之和,δ为调节参数,w2i为i2正则化。
步骤4所述的卷积神经网络模型输出分类结果,具体实现如下:
将步骤3得到三个预测模型m1、m2、m3分别用于判断,m1判断尺寸为64*64的深度图编码单元是否分割;m2判断4个32*32尺寸的深度图编码单元是否分割;m3判断16个16*16尺寸的深度图编码单元是否分割。
本发明的有益效果如下:
本发明将深度学习应用于三维视频编码上。由于深度学习产生的模型能够很好地区分深度图像的内容复杂度,不需要递归计算rd-cost的大小再决定是否需要向下分割。同时产生的模型也可以加载到深度图帧内预测模式的选择上,在需要划分的编码单元处,跳过原始的35种预测模式计算,只将针对深度图预测模式的dmm1和dmm2加入候选。利用以上两点,可以判断深度图编码单元是否要提前结束分割,以及深度图帧内模式的选择,并且在视频码率基本不变的情况下有效的减少了编码时间,避免了计算冗余模式,减少计算量。
附图说明
图1是hevc判断编码单元分割原始方法。
图2本发明流程图。
图3是设计的深度学习网络结构图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
如图2所示,基于深度学习的3d-hevc深度图编码单元快速决策方法,具体包括如下步骤:
步骤1.提取分辨率为1920*1088的gtfly、poznanhall2、undodancer测试序列的前10帧图像组的64*64深度图像素矩阵和分辨率为1024*768的balloon、kendo的测试序列的前26帧图像组的64*64深度图像素矩阵作为训练集。训练的样本的标签是通过逐级比较rd-cost的大小来得到的,即若分割后的rd-cost小于分割前的rd-cost,则设置标签为1,表示分割。若分割后的rd-cost大于分割前的rd-cost,则设置标签为0,表示不分割。poznanstreet、shark、newspaper3个序列作为测试集。再对每个测试集中的序列按照编码单元64*64、32*32、16*16大小以及25、30、35、40,4个量化参数,再分为12个子数据集,并采集所有测试数据;
步骤2.训练集的预处理
步骤2.1:当输入一个64*64的深度图像素矩阵时,先将此深度图像素矩阵复制为三份,对这三个矩阵分别做不同的归一化处理,分别是:
对第一个64*64的矩阵ⅰ,先对64*64个像素值求得其均值和方差,将其每个像素值减去求得的均值和方差,获得一个像素分布均匀的矩阵i′;
对于第二个64*64矩阵ⅱ,先将其分为4个32*32矩阵,再分别求4个矩阵像素值的均值和方差,最后再将每个像素值减去求得的均值和方差,获得一个像素分布均匀的矩阵ⅱ′
对于第三个64*64矩阵ⅲ,先将其分为16个16*16矩阵,再分别求16个矩阵像素值的均值和方差,最后再将每个像素值减去求得的均值和方差,获得一个像素分布均匀的矩阵ⅲ′;
通过上面的不同归一化处理,可输出三个不同的64*64矩阵i′、ⅱ′、ⅲ′。
步骤2.2:将矩阵i′、ⅱ′、ⅲ′再通过下采样公式:
其中n为原始编码单元的宽度64,p为添加宽度0,f为卷积宽度,s为步长分别设置为16、32、64,w为采样后的像素矩阵。先对每层矩阵进行不同的mean_pool操作,使得第一层64*64矩阵下采样成为16*16的矩阵,第二层64*64矩阵下采样成为32*32的矩阵,第三层64*64矩阵采样成为64*64的矩阵;
步骤3.构建卷积神经网络
3.1设定损失函数
假设有r个训练样本集,64*64、32*32、16*16尺寸大小的编码单元是否划分的标志分别为:
其中,
因为有r个训练样本集,总体的损失函数则定义为:
其中lr为尺寸为64*64、32*32、16*16编码单元是否分割的有效标签的交叉熵之和,δ为调节参数,w2i为i2正则化。
3.2深度卷积神经网络的卷积模块:
在3层卷积层模块中,本模块的inception结构如图:对于一个输入的矩阵,有四种操作,1*1,3*3,5*5的卷积操作以及max_pool操作,其padding都设置为smae模式,卷积的步长都为1,可知其padding分别为0,1,2,max_pool操作的宽度为1,步长为1,其中1*1卷积和1*1的max_pool保存了原始的数据,3*3,5*5卷积以不同的尺度来融合特征,我们将得到的数据以相同的维度拼接起来,以第一层矩阵16*16为例,假设1*1,3*3,5*5的卷积核分别有α,β,γ个,则得到的数据为16*16*α,16*16*β,16*16*γ,经过λ个max_pool后得到数据16*16*λ,将其拼接成16*16*(α+β+γ+λ)的立方体,即为inception处理16*16的输出
第二层的inception结构为2*2,4*4的卷积层和2*2的max_pool层,其padding都设置为valid模式,卷积的步长都为2,可知其padding分别为0,1,max_pool操作的宽度为2,步长为2,在这一次,把矩阵的长宽变为原来的一半,通道的数目维持不变,逐渐提取有区分度的数据。
第三层的inception结构为2*2,4*4的卷积层和2*2的max_pool层,其padding都设置为valid模式,卷积的步长都为2,可知其padding分别为0,1,max_pool操作的宽度为2,步长为2,在这一次,把矩阵的长宽变为原来的一半,通道的数目变为原通道个数的四分之一,以提取最有效的数据。
3.3深度卷积神经网络的全连接层:
将最后每层inception输出的数据reshape形成列向量,将列向量拼接在一起形成了全连接层的输入。
特征向量依次通过4个全连接层:包括三个隐含层,以及一个输出层。三个隐藏层的输出依次为{fl-1}其中l=1,3和最后一层的输出即为最终的模型m1、m2、m3。每个全连接层中的特征数量与其所在的支路有关,并能保证复制三个64*64分别输出1个,4个和16个特征,恰好对应三个m1、m2、m3预测值和。此外,需要考虑量化参数qp对cu分割的影响。一般,随着qp减小,更多的cu将被分割,反之当qp增大时,则倾向于不分割。因此,在设计的网络结构的第一、第二,第三全连接层中,将qp作为一个外部特征,添加到特征向量中,使网络能够对qp与cu分割的关系进行建模,在不同qp下准确预测分割结果,提高算法对不同编码质量和码率的适应性。另外,通过深度学习网络模型,可以跳过第二、三级全连接层,以节省计算时间。具体而言,如果第一级的64*64不分割时,则不需要计算所在的第二级;如果第二级的4个32*32都不分割,则不需要计算所在的第三级。
步骤4.将得到的m1、m2、m3加载到htm13.0测试代码中。
步骤4.1.在64*64尺寸的编码单元划分过程中,调用预测模型m1。若当前64*64的编码单元预测为不划分时,设划分标志
步骤4.2.进入预测模型m2,依次判断它4个32*32大小的编码单元是否需要划分,若当前的32*32大小的编码单元不需要划分,设划分标志
步骤4.3.进入预测模型m3,依次判断它16个16*16大小的编码单元是否需要划分,若不需要划分,设划分标志
步骤4.4.完成当前编码块完整的划分与预测模式选择步骤,再继续下一个64*64编码单元是否划分的判断。
- 还没有人留言评论。精彩留言会获得点赞!