一种基于SLA的无状态云工作流负载均衡调度的方法与流程
本发明涉及工作流和云计算技术领域,更具体的,涉及一种基于sla的无状态云工作流负载均衡调度的方法。
背景技术:
随着分布式计算特别是网格技术的发展,云计算作为一种新型的服务计算模型而产生。云计算是一种资源交付和使用模式,指通过网络获得应用所需的资源,包括硬件、平台、软件等,提供资源的网络被称为“云”。在云计算中,任何事物都是服务,一般可分为三个层次:基础设施即服务(iaas)、平台即服务(paas)和软件即服务(saas)。
云工作流作为一种paas级服务,是指以平台即服务的云计算模式提供工作流服务的分布式系统。相比于传统工作流系统,云工作流的主要优势在于:云工作流提供了按需使用、按量付费的模式,这种模式能有效减少企业使用工作流管理软件的投入成本,减少起步难度;云工作流具有资源高利用率和服务高性能的优点,集中管理模式可以充分利用计算力,灵活的资源配置也可应对不同时段的请求负载。
传统工作流引擎往往是基于有状态方案实现的,而在云环境下,为了更好地发挥云资源的灵活性和提高云工作流系统的可靠性,基于无状态方案实现的工作流引擎会更加符合云工作流的需求;对于基于无状态工作流引擎实现的云工作流系统,一方面由于工作流服务本身的特性,解析流程模型和存储解析结果仍然必不可少,且需要占用一定的计算资源和存储资源;另一方面,在云环境下,云工作流需要支持多租户的业务流程执行,负载场景比传统工作流引擎复杂得多。基于无状态工作流引擎实现的云工作流系统,在面对多租户、多流程模型、多流程实例的请求负载时,如果只考虑服务的无状态性进行调度的话,会导致无法充分利用和发挥工作流服务本身的特性,从而无法实现更好的请求负载均衡效果和用户体验。
目前,工作流领域中已有的工作流集群系统的系统架构和管理结构通常只服务于同一个用户或是同一个组织。在云服务商业动作模式中,流程服务提供商希望在相同硬件资源情况下给更多的租户提供流程解析服务,不同的租户根据其业务场景,往往对引擎服务的请求吞吐量有不同的要求,同一租户对其不同流程定义的解析执行性能往往也有不同的要求,因此租户与流程服务提供商需要签订sla合约,系统按sla协议向租户提供相应的服务水平。
技术实现要素:
本发明为了解决基于对云工作流下不同租户对不同服务水平的需求以及流程服务提供商在相同硬件资源下对提高租户数量的需要的问题,提供了一种基于sla的无状态云工作流负载均衡调度的方法,其实现在保证云租户服务体验的同时,优化云工作流请求的负载均衡效果和执行性能,从而让云工作流系统在正常服务状态下为更多的租户提供流程解析服务。
为实现上述本发明目的,采用的技术方案如下:一种基于sla的无状态云工作流负载均衡调度的方法,当接收租户上传流程模型所对应的流程实例请求时,云工作流将流程实例请求调度到集群中的无状态工作流引擎中,执行包括以下步骤:
准入层负载波形平滑:
s101:准入层接收租户流程实例请求,准入层根据租户id或流程实例请求信息从租户sla仓库获取该租户的服务请求到达速率rar指标以及对于该流程实例请求的请求响应时间级别rtl;
s102:根据系统限流算法,判断租户服务请求速率是否满足rar指标,如果超过rar指标指定的服务请求速率,则直接过滤请求,并向租户反馈,提示购买更高的rar级别,否则执行下一步;
s103:判断rtl级别,根据不同的rtl级别执行调度层请求均衡分派,或获取当前立即执行队列和迟延队列的请求数,使用历史负载变量historysize,根据迟延队列的请求数,计算当前的流程实例请求针对每个延迟队列的评分,并将该请求放于评分最高的延迟队列中;
调度层请求均衡分派:
s201:调度层接收来自准入层立即执行队列的请求,调度层从共享内存获取流程服务层发送的每个流程引擎服务的负载信息集合e=[e1,…,em],ei=(cpui,rami),cpui表示流程引擎服务ei当前的cpu占用率,rami表示流程引擎服务ei当前的ram占用率;
s202:调度层从流程实例仓库中获取请求的流程模型对应的流程实例在流程引擎服务的分布状况集合d=[d1,d2,…,dm],di∈[0,1],当di=0时表示该流程模型没有运行过在ei引擎上,否则反之;
s203:根据分布状况集合d,将流程引擎服务分为两组e1和e2,e1中存放了所有流程模型执行过的引擎,也即di=1;e2存放了剩余的引擎;
s204:针对e1和e2的元素进行引擎繁忙度计算,分别得到e1、e2的繁忙度最小的引擎服务
其中,β是作为将流程实例请求分配到新引擎的代价参数,可根据具体硬件资源特性进行设置。
优选地,步骤s101,所述服务请求到达速率rar,用于衡量流程实例请求吞吐量,表示租户每秒最高可发送的流程实例请求数;
所述的rar指标分为三级,定义v0,v1,v2,其中,v0、v1、v2为整数,且有v0>v1>v2,则三个级别描述如下:
rar0:是指服务请求到达速率最高等于v0;
rar1:是指服务请求到达速率最高等于v1;
rar2:是指服务请求到达速率最高等于v2;
不同级别的rar对应着不同的计费。
优选地,步骤s101,所述的请求响应时间级别rtl,用于衡量不同流程请求处理性能,rtl的提出是基于工作流的执行时间范围的多样性;
所述的rtl级别分为三级,定义参数a,b,t,其中a,b,t为整数,且有a小于b,t表示引擎处理一个流程实例请求需求的时间,并表示一个时间片的长度,可通过对流程引擎服务测试得到,则该rtl各级别如下:
rtl0:流程实例请求在1个时间片内响应,即为t;
rtl1:请求最晚在(a+1)个时间片响应,即(a+1)t;
rlt2:请求最晚在(b+1)个时间片响应,即(b+1)t。
进一步地,所述系统限流算法采用滑动窗口算法来保证租户的rar指标;针对rtl级别使用请求缓存的方式进行实现,具体的方式如下:
准入层维护着b+1个用于存放流程实例请求的队列,每个队列都对应一个延迟时长变量,代表该队列中的流程实例请求的可延迟时长,其值分别为0t,1t,2t,…,bt,其中:t为rtl中定义的时间片,延迟时长变量为0t的队列为立即执行队列,延迟时长变量为1t,2t,…,bt的队列为延迟队列;准入层还需要在每过1个时间片的时间后更新延迟队列和历史负载变量,所述的历史负载变量用于衡量过去每个时间片的请求数情况;准入层需要根据租户对流程任务设置的rtl级别和当前各队列存放的流程实例请求数量情况,将新的流程实例请求放入相应的延迟队列中。
再进一步地,步骤s103,具体的,判断rtl级别;
若rtl级别为rtl0,则直接执行调度层请求均衡分派;
若rtl级别为rtl1,说明延迟时间小于或等于a个时间片,则获取当前立即执行队列和前两个迟延队列的请求数,集合为n=[n0,n1,…,na];
若rtl级别为rtl2,说明延迟时间小于或等于b个时间片,则获取当前立即执行队列和全部的迟延队列的请求数,集合为n=[n0,n1,…,nb]。
再进一步地,步骤s103,所述计算当前请求针对每个延迟队列的评分的计算方法如下:
式中:ni∈n,i表示当前延迟队列在集合n中的位置。
再进一步地,所述准入层需要在每过1个时间片的时间后更新延迟队列和历史负载变量,包括以下步骤:
h1:所有延迟队列的延迟时长变量都减1,并判断延迟时长变量是否等于0,若是,将队列中的请求全部添加到立即执行队列,并重新设置延迟时长为bt;
h2:立即执行队列需要一直运行一个线程来判断队列是否有请求,并根据引擎服务处理请求的速率,将请求依次提交给调度层进行请求分派,并记录每个时间片内提交给流程引擎的请求数;
h3:获取过去1个时间片时间内立即执行队列提交给调度层进行请求分派的请求数requestsize,依据以下公式更新历史负载变量historysize:
historysize=α*historysize+(1-α)*requestsize
其中:α表示权重因子,代表前一秒historysize值的衰减程度。
再进一步地,所述的引擎繁忙度计算公式如下:
busynessi=w1*cpui+w2*rami,w1+w2=1
其中:w1和w2两个参数分别表示cpu和ram这两种负载参数的重要程度,需要根据硬件资源特性进行配置。
本发明在所述调度层请求均衡分派中,调度层根据流程服务层的流程引擎服务的负载状况,并根据无状态工作流引擎的特性,实现同一个流程模型对应的请求分配到少数的引擎上,从而减少同一个流程模型的多次解析与结果存储带来的计算及内存消耗。
本发明的有益效果如下:本发明根据不同租户对其业务场景和流程模型的需要,选择不同的sla级别,通过不同的sla级别,云工作流系统对租户提供不同的请求吞吐量服务,并对不同的流程请求进行分级服务,结合共享内存实现的引擎负载实时监控和流程模型在引擎上分布状况,在消减了引擎服务的请求波峰的同时还减少了引擎集群的整体内存开销,从而提高云工作流在多租户架构下负载均衡的能力,使得流程服务提供商在满足不同租户对请求吞吐量和不同流程定义的解析执行性能需求的基础上,可以为更多的租户提供服务。
附图说明
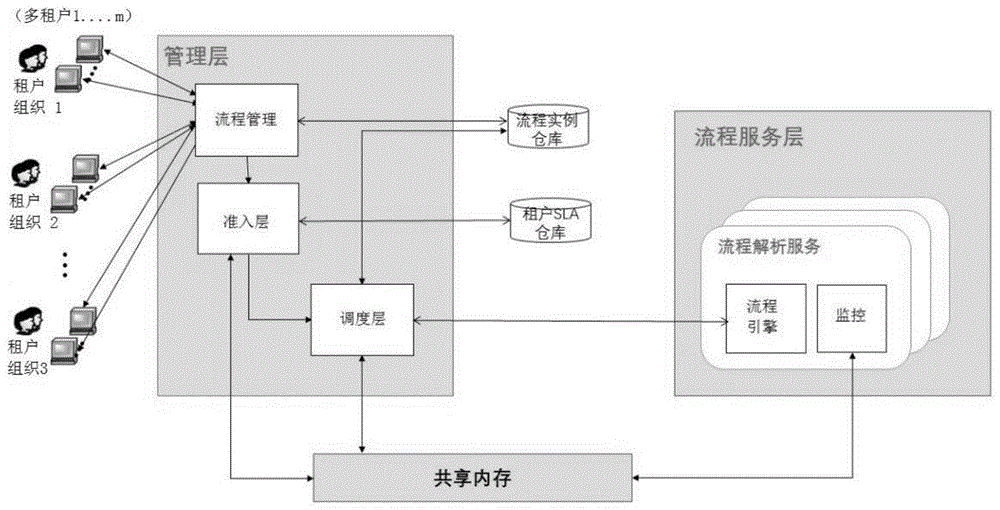
图1是云工作流核心部件图。
具体实施方式
下面结合附图和具体实施方式对本发明做详细描述。
实施例1
如图1所示,一种基于sla的无状态云工作流负载均衡调度的方法,该方法包括准入层负载波形平滑、调度层请求均衡分派处理步骤;在对这两步骤进行具体介绍之前,需要先定义云工作流服务sla中表征不同请求吞吐量以及对不同流程请求处理性能的量化指标,其中请求吞吐量使用服务请求到达速率rar来衡量,表示租户每秒最高可发送的流程实例请求数;不同流程请求处理性能使用请求响应时间级别rtl来衡量,请求响应时间级别rtl的提出是基于工作流的执行时间范围的多样性,时间范围从几微秒到几个月不等。
本实施例根据租户对其业务场景的需要,rar指标可分为三级,定义v0,v1,v2,其中,v0、v1、v2为整数,且有v0>v1>v2,则三个级别描述如下:
rar0:用于高并发业务场景,是指服务请求到达速率最高等于v0;
rar1:用于一般并发业务场景,是指服务请求到达速率最高等于v1;
rar2:用于低并发业务场景,是指服务请求到达速率最高等于v2;
不同级别的rar对应着不同的计费,有更高服务请求到达速率的级别相应也有更高的计费。
本实施例根据不同流程请求对处理实时性的不同需求,rtl级别可分为三级,在详细陈述前,定义参数a,b,t,其中,a、b、t为整数,且有a小于b,t表示引擎处理一个流程实例请求需求的时间,也表示一个时间片的长度,可通过对引擎服务测试得到,所述sla各级别陈述如下:
rtl0:对实时性要求较高的流程实例请求,流程实例请求在1个时间片内响应,即为t;多为自动化流程;
rtl1:对实时性要求一般的流程实例请求,请求最晚在(a+1)个时间片响应,即(a+1)t;
rlt2:对实时性要求较低的流程实例请求,请求最晚在(b+1)个时间片响应,即(b+1)t。
租户在上传流程模型时可以针对模型的实际使用情况,为流程模型中不同的任务选择不同的sla指标,从而得到不同的计费,处理性能越高的sla指标,计费相应就越高。
本实施例所述的基于sla的无状态云工作流负载均衡调度的方法,当接收租户上传流程模型所对应的流程实例请求时,云工作流将流程实例请求调度到集群中的无状态工作流引擎中,执行包括以下步骤:
准入层负载波形平滑:
s101:准入层接收租户流程实例请求,准入层根据租户id和流程请求信息从租户sla仓库获取该租户的rar指标以及对于该流程实例请求的rtl级别;
s102:依据时间窗口算法,判断租户服务请求速率是否满足rar指标,如果超过rar指标指定的服务请求速率,则直接过滤请求,并向租户反馈,提示购买更高的rar级别;否则执行下一步;
s103:判断rtl级别,如果rtl级别为rtl0,则直接执行调度层请求均衡分派进行调度;如果rtl级别为rtl1,说明最多只能延迟a个时间片,则获取当前立即执行队列和前两个迟延队列的请求数,集合为n=[n0,n1,…,na];如果rtl级别为rtl2,说明最多可延迟b个时间片,则获取当前立即执行队列和全部的迟延队列的请求数,集合为n=[n0,n1,…,nb];
s104:使用历史负载变量historysize,针对每个集合n的元素,使用如下计算当前请求针对每个延迟队列的评分:
式中,ni∈n,i表示当前延迟队列在集合n中的位置。
通过以上步骤计算出的各延迟队列的评分,将请求放于评分最高的延迟队列中。
所述调度层请求均衡分派包括以下步骤:
s201:调度层接收来自准入层立即执行队列的请求,调度层从共享内存获取流程服务层发送的每个流程引擎服务的负载信息集合e=[e1,…,em],ei=(cpui,rami),cpui表示流程引擎服务ei当前的cpu占用率,rami表示流程引擎服务ei当前的ram占用率;
s202:调度层从流程实例仓库中获取请求的流程模型对应的流程实例在流程引擎服务的分布状况集合d=[d1,d2,…,dm],di∈[0,1],当di=0时表示该流程模型没有运行过在ei引擎上,否则反之;
s203:根据分布状况集合d,将流程引擎服务分为两组e1和e2,e1中存放了所有流程模型执行过的引擎,也即di=1;e2存放了剩余的引擎;
s204:针对e1和e2的元素进行引擎繁忙度计算,公式如下:
busynessi=w1*cpui+w2*rami,w1+w2=1
其中:w1和w2两个参数分别表示cpu和ram这两种负载参数的重要程度,需要根据硬件资源特性进行配置;通过引擎繁忙度公式分别得到e1、e2的繁忙度最小的引擎服务
判断不等式
其中:β是作为将流程实例请求分配到新引擎的代价参数,可根据具体硬件资源特性进行设置;
s205:完成请求调度。
本实施例在所述调度层请求均衡分派中,调度层根据流程服务层的流程引擎服务的负载状况,并根据无状态工作流引擎的特性,实现同一个流程模型对应的请求分配到少数的引擎上,从而减少同一个流程模型的多次解析与结果存储带来的计算及内存消耗。
本实施例所述系统限流算法采用滑动窗口算法来保证租户的rar指标;针对rtl级别使用请求缓存的方式进行实现,具体的方式如下:
准入层维护着b+1个用于存放流程实例请求的队列,每个队列都对应一个延迟时长变量,代表该队列中的流程实例请求的可延迟时长,其值分别为0t,1t,2t,…,bt,其中:t为rtl中定义的时间片,延迟时长变量为0t的队列为立即执行队列,延迟时长变量为1t,2t,…,bt的队列为延迟队列;准入层还需要在每过1个时间片的时间后更新延迟队列和历史负载变量,所述的历史负载变量用于衡量过去每个时间片的请求数情况;准入层需要根据租户对流程任务设置的rtl级别和当前各队列存放的流程实例请求数量情况,将新的流程实例请求放入相应的延迟队列中。
所述准入层需要在每过1个时间片的时间后更新延迟队列和历史负载变量,包括以下步骤:
h1:所有延迟队列的延迟时长变量都减1,并判断延迟时长变量是否等于0,若是,将队列中的请求全部添加到立即执行队列,并重新设置延迟时长为bt;
h2:立即执行队列需要一直运行一个线程来判断队列是否有请求,并根据引擎服务处理请求的速率,将请求依次提交给调度层进行请求分派,并记录每个时间片内提交给流程引擎的请求数;
h3:获取过去1个时间片时间内立即执行队列提交给调度层进行请求分派的请求数requestsize,依据以下公式更新历史负载变量historysize:
historysize=α*historysize+(1-α)*requestsize
其中:α表示权重因子,代表前一秒historysize值的衰减速度。
本实施例的特点是基于不同租户的业务场景对请求吞吐量以及不同流程定义解析执行性能的不同需求,利用工作流中的执行时间范围的多样性,特别是部分任务并不需要实时响应的特性来进行请求的延迟,实现了对租户的限流和在限流约束下的请求负载均衡优化;结合无状态工作流引擎服务的特性,实现流程模型请求最少引擎数分配的负载均衡策略;利用共享内存实现引擎服务负载信息的存取;上述提出的方法,可以实现在保证云租户服务体验的同时,优化云工作流请求的负载均衡效果和执行性能,从而让云工作流系统在正常服务状态下为更多的租户提供流程解析服务。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!