MIMO通信方法、发送装置和接收装置与流程
相关申请的交叉引用
本申请与于2013年3月1日递交的临时申请no.61/771,470有关,并且根据35u.s.c.§119(e)要求该临时申请的优先权,其内容通过引用的方式并入本文。
背景技术:
本公开涉及使用mimo(多输入和多输出通信)的mimo(多用户mimo:在下文中称为:“mu-mimo”)通信方法,并且涉及发送装置和接收装置。
背景技术
移动通信终端和许多其它类型的装置经由无线电网络来进行通信的情况的数量与日俱增。在作为已经开始被投入实际使用的通信标准的lte(长期演进)及其扩展版本或者lte-advance和lte-evoluation被投入实际使用的情形中,预期这一点会更加显著。这种情形是全球趋势,并且,由3gpp(第三代合作伙伴计划)进行的分析预测了一种情况,其中,例如,智能电话的数量将大幅地增加,从而导致无线电通信的拥堵。特别地,对于诸如智能电话的通信终端,预测许多装置之间的通信将不受人类控制并且会发生无线电通信拥堵。
作为对抗上述情形的对策之一,lte当前采用了基于ofdm(正交频分复用)的调制方案,以实现通信容量的增加。也就是说,在lte中,当前,多载波技术被用来提高频率利用效率。另外,在将来发布lte标准时,将提出具有最大带宽为100mhz的系统。
但是,即使在使用这样的方法的情况下,在不远的将来,预计还会发生通信的严重拥堵。也就是说,由3gpp进行的分析预测出,通过其中提高通信速度并且提高使用的频带数量来提高通信信道容量的常规方法,可能不足以缓和这样的拥堵。
作为对抗此的对策之一,已经提出了mu-mimo(多用户mimo)。mu-mimo是在第8版的3gpp标准中的发送模式5中定义的通信方案。例如,为了通过将mu-mimo应用于lte而从单个单元中的多个(n个)终端到基站进行上行链路通信,基站准备n个接收天线。各个终端在相同的时间段期间以相同的频率执行完全不同的内容的通信,并且基站使用n个接收天线来接收内容。基站利用信道之间的正交性(相关性)来识别已经从其接收到信号的终端。
还对扩展版本进行了研究,其中,多个终端以及总地管理多个单元的基站控制器(bsc)的mimo以bsc为单位进行构建。
通过应用mu-mimo,存在潜在地提高频率资源的利用效率并且提高通信信道容量的有益效果,并且mu-mimo正在作为在一定程度上解决通信流量的未来增长的技术被研究。
在mimo中,基于在发送器侧的天线和在接收器侧的天线的组合,以矩阵的形式来表示信道。例如,在3gpp中,提出多达16个发送天线和16个接收天线的配置。在这种情况中,获得16×16矩阵(在下文中称为“h矩阵”)。也就是说,基站需要使用h-矩阵的逆矩阵来分离并接收来自多达16个终端的通信。实际上,由于使用这样的16×16h-矩阵的逆矩阵来准确地分离16个信道的信号的技术的难度,导致不大于4×4或8×8的mimo将有可能被投入到实际使用中。通信供应商正通过其研究机构的实验来准备这样的mu-mimo用于实际使用。
mu-mimo要求在接收器侧(基站侧)确定h矩阵的逆矩阵。通常,在终端侧使用从基站发送的参考信号或导频信号(rs)来确定h矩阵的元素(即,关于信道的瞬时传递函数),并且终端将结果反馈给基站。基站通过使用所有结果来构建h矩阵,并且确定其逆矩阵。在通信开始后,在接收时,来自所有终端的信号被接收,然后使用该逆矩阵将来自各个终端的接收信号分离。对于逆矩阵的利用,使用迫零、mmse方法等。
同时,某些终端高速地移动。另外,当在诸如都市区域的不利环境中使用终端的情况中,主要由于大量的衰减和遮挡而导致关于信道的瞬时传递函数会不断地改变。因此,需要以某些较短的时间间隔来更新h矩阵。也就是说,基站需要继续频繁地计算和更新逆矩阵。随着矩阵阶数的增加,逆矩阵的计算要求更大数量的计算处理。
在n阶方阵的情况中,需要执行(n3×n!)次计算以确定逆矩阵,并且,对于四阶或更高阶,通常使用lu分解等,然而,高速计算需要时间和大量的功率消耗。另外,逆矩阵并不总是存在。也就是说,在h矩阵不是正则矩阵的情况中,逆矩阵不存在。阶数越高,逆矩阵不被确定的可能性越高。如果不能确定逆矩阵,则信道的正交性崩溃,从而导致mimo不能被建立。
因此,确定逆矩阵对mu-mimo基站施加相当大的负荷,从而导致处理时间的延迟和功率消耗的增加。此外,由于mimo未被建立,因此存在通信拥堵的问题未被实质解决的问题。
此外,为了在基站处通过分集提高接收质量,所需的接收天线或接收单元的数量翻倍,并且随着mu-mimo的阶数的增加,mu-mimo变得更难实现。
本发明者已经认识到了实现mu-mimo中的困难。
技术实现要素:
根据本公开的mimo通信方法被配置为通过使用mu-mimo方案在n(n是大于或等于2的整数)个发送装置与具有n个接收天线的至少一个接收装置之间进行通信,每个发送装置都具有发送天线。
n个发送装置被分成多个组。将正交码作为要由每个发送装置发送的数字信号序列分配给每一组的发送装置。沿频率轴方向布置将要由发送装置发送的数字信号序列并且执行编码,在该频率轴方向上执行逆快速傅里叶变换。
根据本公开的发送装置被用于mu-mimo方案,在该mu-mimo方案中,被分成多个组的n(n是大于或等于2的整数)个发送装置被使用并与具有n个接收天线的至少一个接收装置进行无线通信。
发送装置包括:数据产生单元、逆快速傅里叶变换单元、射频单元和发送天线。
数据产生单元使用分配给每个组的正交码来产生要被发送的数字信号序列。
逆快速傅里叶变换单元将由数据产生单元获得的正交码分配给频率轴上的每个频率,执行逆快速傅里叶变换并产生ofdm信号。
射频单元,从发送天线发送由逆快速傅里叶变换单元通过变换获得的ofdm信号作为射频信号。
根据本公开的接收装置被用于mu-mimo方案,在该mu-mimo方案中,具有n个接收天线的至少一个接收装置接收从被分成多个组的n个(n是大于或等于2的整数)发送装置发送的信号。
由接收天线接收的信号包括通过使用分配给n个发送装置被分成的多个组中的每个组中的发送装置的正交码对数字信号序列执行逆快速傅里叶变换而获得的信号。
根据本公开,通过使用正交码,发送装置被分成若干个组。信道矩阵的代码复用和正交化使接收装置能够使用较少数量的天线执行接收。这样可以简化信道矩阵,因此防止产生非正则矩阵,以实现计算负荷的减少。由于可以减少天线的数量,因此可以促进分集的应用。
附图说明
图1是示出根据本公开的实施例的例子的通信系统的示例配置的示图。
图2是示出根据本公开的实施例的例子的信道矩阵的示图。
图3是示出根据本公开的实施例的例子的发送装置的框图。
图4是示出根据本公开的实施例的例子的发送装置中的数据排列的示图。
图5是示出ovsf代码的例子的示图。
图6是示出根据本公开的实施例的例子的接收装置的框图。
图7a、图7b和图7c包括示出根据本公开的实施例的例子的h矩阵的示图。
图8是示出接收装置中的数据分离单元的例子的示图。
图9a和图9b包括示出根据本公开的另一个实施例的例子的mu-mimo中的分组的例子的示图。
图10是根据本公开的另一实施例的例子的使用分集的例子的示图。
具体实施方式
在下文中,将按照下面的顺序参照附图描述本公开的实施例的例子。
1.根据实施例的整个通信系统的例子(图1、图2)
2.根据实施例的发送装置的配置的例子(图3)
3.数据排列的例子(图4、图5)
4.根据实施例的接收装置的配置的例子(图6)
5.接收操作的例子
6.h矩阵的例子(图7a、图7b和图7c)
7.数据分离处理的例子(图8)
8.其它实施例的例子(mu-mimo中的分组的其它例子:图9a和图9b)
9.其它实施例的例子(实现分集的例子:图10)
10.其它变型例
[1.根据实施例的整个通信系统的例子]
图1是示出根据本公开的实施例的整个通信系统的示例配置的示图。
本实施例的例子提供包括基站和终端的无线通信系统,该无线通信系统使用被称为lte的通信标准。根据终端的位置,每个终端与能够进行无线通信的相邻基站进行无线通信。在图1中示出的通信系统中,从终端到基站的上行链路的配置被示出,而从基站到终端的下行链路的配置的图示被省略。
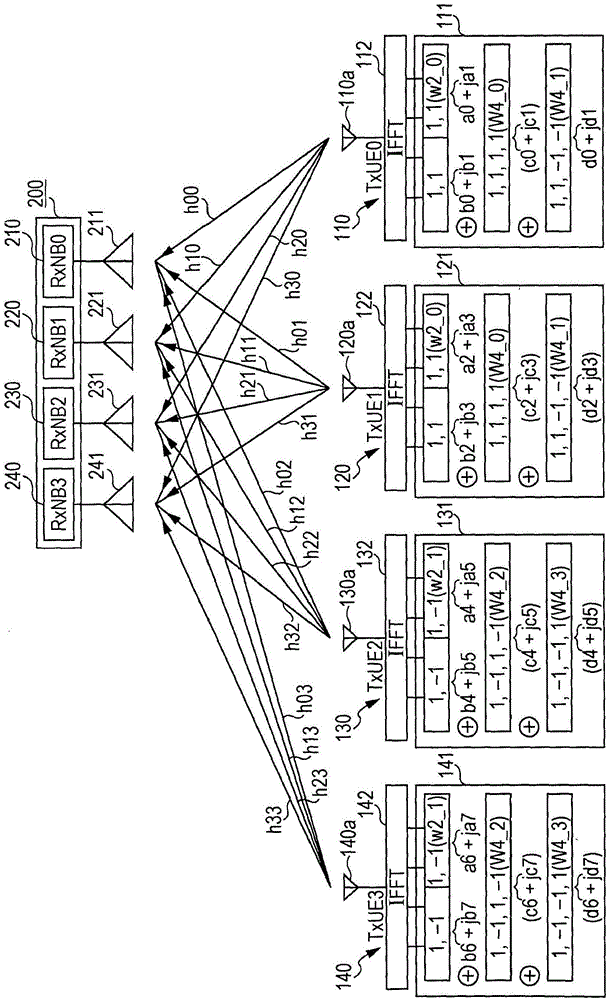
在图1中的例子中,示出包括在各个终端中的发送装置110、120、130和140以及包括在基站200中的接收装置210、220、230和240。在图1中的例子中,四个发送装置110到140分别包括发送天线110a、120a、130a和140a,并且接收装置210到240分别包括接收天线211、221、231和241。四个发送天线110a到140a和四个接收天线211到241被用来进行使用mimo方案的无线通信。这里,发送天线110a到140a是被包括在各个终端中的天线,并且基于mu-mimo方案,通过mu-mimo方案,基站200与多个用户(多用户)同时通信。在本文中公开的例子中,发送装置110到140使用相同的频带进行无线通信。
四个发送装置110到140形成成对的两个装置(发送装置110和120的对以及发送装置130和140的对)。每一对都被分配扩展的正交码,从而使得这些正交码具有成对的正交关系。例如,这里使用的正交码是ovsf(正交可变扩频因子)码,其是在utra(通用移动通信系统)标准中使用的代码。此外,每个数据复用单元111、121、131和141将二阶ovsf码和四阶ovsf码相加,以产生发送数据序列。下面将描述使用作为数据产生单元的数据复用单元111到141来将信号相加的具体例子。
在发送装置110到140中,如图1所示,由逆快速傅里叶变换单元112、122、132和142对由数据复用单元111、121、131和141获得的发送数据序列进行逆快速傅里叶变换。使用ofdm方案调制的多载波信号是通过逆快速傅里叶变换产生的,并且发送天线110a到140a无线地发送多载波信号。下面将描述图1中示出的发送装置110到140的具体的详细配置。
由四个发送装置110到140的发送天线110a到140a发送的信号由基站200中的连接到四个接收装置210到240的接收天线211到241来接收。
这里,四个发送装置110到140由txue0、txue1、txue2和txue3表示,四个接收装置210到240由rxnb0、rxnb1、rxnb2和rxnb3表示。在这种情况中,在四个发送装置110到140与四个接收装置210到240之间发送和接收的信号由图2中示出的矩阵来表示。在图2中的矩阵中,h00到h33是图1中示出的天线之间的传递函数。也就是说,如图1所示,在四个发送天线110a到140a与四个接收天线211到241之间存在4×4(或16个)发送路径,并且针对各个发送路径存在传递函数h00到h33。
通常,每个传递函数在接收器侧被估计,并被反馈给发送器侧。也就是说,例如,预定参考信号(例如,在lte中,zadoff-chu码)被放置在由ofdm调制的在时间域和频率域中无重叠的位置处并被发送。在接收器侧,得知时间域和频率域,使用参考信号估计信道,并且估计结果被发送到发送器侧。在发送器侧,从所有接收装置发送的传递函数被收集,以获得在图2中示出的矩阵。
[2.根据实施例的发送装置的配置的例子]
图3是示出发送装置110的配置的示图。其它的发送装置120、130和140也具有相同的配置。
在发送装置110中,通信控制单元110y控制在发送单元110x中执行的发送处理。
在发送单元110x中,从通信控制单元110y发送来的数据流被供应到映射单元113。映射单元113执行数据流的映射。从映射单元113输出的数据被供应到交织单元114。交织单元114执行交织处理以根据某一规则来分发数据。
由交织单元114进行过处理的数据被供应到数据复用单元111,并且执行复用处理。复用处理的细节将在稍后被描述。由数据复用单元111复用的数据在ifft帧构建单元115中形成,以产生要被进行逆快速傅里叶变换(ifft)的具有帧配置的数据。
由ifft帧构建单元115获得的具有帧配置的数据被供应到逆快速傅里叶变换单元112。逆快速傅里叶变换单元112执行ofdm调制以从频率轴转换到时间轴,并且获得i分量(实部分量)和q分量(虚部分量)的发送数据。i分量的发送数据和q分量的发送数据被分别供应到保护间隔插入单元116i和116q,以插入保护间隔。从保护间隔插入单元116i和116q输出的发送数据被供应到并行/串行转换单元117i和117q,并被转换为串行数据。由并行/串行转换单元117i和117q通过转换获得的i分量和q分量的串行数据被供应到数字/模拟转换器118i和118q,并被转换为模拟信号。由数字/模拟转换器118i和118q通过转换获得的i分量和q分量的信号被供应到正交调制单元和射频单元119,并且使用i分量和q分量进行正交调制并被频率转换到一定发送频率。从正交调制单元和射频单元119输出的发送信号被供应到发送天线110a,并且被从发送天线110a无线地发送。
请注意,用于从发送装置110到140的发送天线110a到140a无线地发送的发送频率都是相同的。
[3.数据排列的例子]
图4示出由发送装置110的数据复用单元111执行的处理。如上文中已经描述的,发送装置使用正交信号来扩展发送信号的数据。这里,例如,如图1所示,当使用四个发送装置110到140时,发送装置110到140被分成两对,每对两个装置。例如,获得发送装置110和120的对以及发送装置130和140的对。
然后,每一对都被分配扩展的正交码,从而使得这些正交码具有成对的正交关系。例如,在本文中使用的正交码为ovsf码。此外,每个数据复用单元111、121、131和141将二阶ovsf码和四阶ovsf码相加,以产生发送数据序列。
对于二阶码和四阶码的复用应当注意的是,由于所有信号都在接收器侧被相加,因此相互不正交的代码也可以被加在一起。在这种情况中,当通过解扩对数据解调时,根据要被复用的数据模式可以产生内积0,并且分离是不可能的。为了避免此种情况,在发送器侧执行用于提高数据幅值的预处理。请注意,发送装置不必一定以最大速度进行通信。如果需要的话,可以改变用于代码复用的层。在小于或等于最大速度的一半的情况中,只使用sf2码。相反地,为了提高通信速度,更高阶(诸如八阶)的ovsf码被复用。
图5是示出ovsf码的配置的示图。
例如,在4×4mimo的情况中,使用二阶和四阶ovsf码来复用sf2码和sf4码,即,在图5中示出的所有的sf2码和sf4码。为了补偿通信速度的降低而执行复用,其中通过扩展有效地降低了通信速度。在图5中,示出二阶(sf2)、四阶(sf4)和八阶(sf8)ovsf码。
例如,在图1中示出的一对发送装置110和120中的数据复用单元111和121使用在图5中示出的sf2码之中的一个代码w2_0(1,1)作为二阶(sf2)ovsf码。数据复用单元111和121还使用在图5中示出的四个sf4码之中的两个代码w4_0(1,1,1,1)和w4_1(1,1,-1,-1)作为四阶(sf4)ovsf码。请注意,为了避免冗余,在图1中示出的发送装置110到140的逆快速傅里叶变换单元112到142中的数据未被示出。
此外,在图1中示出的另一对的发送装置130和140中的数据复用单元131和141使用在图5中示出的sf2码之中的另一个代码w2_1(1,-1)作为二阶(sf2)ovsf码。数据复用单元131和141还使用在图5中示出的四个sf4码之中的两个代码w4_2(1,-1,1,-1)和w4_3(1,-1,-1,1)作为四阶(sf4)ovsf码。
现在将描述由二阶ovsf码(sf2)进行的分割。这里,使用qpsk(正交相移键控)对子载波进行调制。
两个正交码sf2由下面的表达式(1)和表达式(2)来给出。
表达式(1)w2_0=(1,1)
表达式(2)w2_1=(1,-1)
这里,如图1所示,作为同一对发送装置的ue0的发送装置110和ue1的发送装置120具有相同的数据结构。此外,ue3的发送装置130和ue4的发送装置140具有相同的数据结构。
首先,将描述ue0的发送装置110和ue1的发送装置120这一对的数据配置。
在发送装置110的逆快速傅里叶变换单元112的输入单元处获得的发送数据流被交替地分发到实部(i部)和虚部(q部)中。在逆快速傅里叶变换单元112的输入单元处获得的数据是设置到用于逆快速傅里叶变换的频率轴的数据。
然后,将i部侧和q部侧中的每一个乘以上述表达式(1)给出的正交码w2_0。
各个流可以由下面的表达式(3)和(4)来表示:
表达式(3)i=(a0,a2,a4,,,)
表达式(4)q=(a1,a3,a5,,,),
其中,a0、a1等表示1,-1等。
作为表达式(3)和(4)中的数据流被表达式(1)给出的正交码所扩展的结果,获得由下面的表达式(5)给出的数据。
表达式(5)(a0+j·a1,a0+j·a1,a2+j·a3,a2+j·a3,,,)
由表达式(5)给出的数据被设置到逆快速傅里叶变换单元112在其上执行变换的频率轴。这里,j是虚单位。
对于ue1的发送装置120,由表达式(3)和(4)给出的数据流变成由下面的表达式(6)和(7)给出的数据流。
表达式(6)i=(b0,b2,b4,,,)
表达式(7)q=(b1,b3,b5,,,)
设置到发送装置120的逆快速傅里叶变换单元122的频率轴的数据流由下面的表达式(8)来给出:
表达式(8)(b0+j·b1,b0+j·b1,b2+j·b3,b2+j·b3,,,)。
这同样适用于作为另一对发送装置的ue2的发送装置130和ue3的发送装置140。也就是说,作为已经由表达式(2)给出的正交码所扩展的结果,要被设置到逆快速傅里叶变换单元132和142的频率轴的数据由表达式(9)和(10)给出。
表达式(9)(c0+j·c1,-c0-j·c1,c2+j·c3,-c2-j·c3,,,)
表达式(10)(d0+j·d1,-d0-j·d1,d2+j·d3,-d2-j·d3,,,)
在表达式(9)和(10)中,由c*和d*(*表示表达式中的值)表示的信号是设置在ue2的发送装置130和ue3的发送装置140中的数据流。
在本文中公开的例子中,四阶(sf4)ovsf码被进一步复用。其原因在于,使得通信速度与没有使用扩展时的通信速度匹配。也就是说,作为使用二阶(sf2)ovsf码扩展的结果,要在逆快速傅里叶变换期间被排列的数据的数量是没有使用扩展时的数量的一半。因此,通信速度减半。为了补偿减半的通信速度,执行对代码的进一步的复用,以恢复通信速度。
在该复用的情况中,由于长度为2的二阶ovsf码被全部使用,因此,如图1所示,使用长度为4的四阶(sf4)编码。这允许4比特ovsf码被分配给每个数据比特,导致通信速度被降低到四分之一。因此,使用两个sf4码来将通信速度恢复到一半。如前所述,复用sf4码和sf2码可以将通信速度恢复到1,从而防止由于扩展而导致速度降低。
使用具有不同长度的代码的正交性(这是一种特征)来分配ovsf码。因此,如图1所示,代码w4_0和w4_1被分配给使用代码w2_0的一对发送装置110和120,代码w4_2和w4_3被分配给使用代码w2_1的一对发送装置130和140。代码w4_0、w4_1、w4_2和w4_3的细节在下面给出。下面的代码与图5中示出的代码相同。
w4_0(1,1,1,1)
w4_1(1,1,-1,-1)
w4_2(1,-1,1,-1)
w4_3(1,-1,-1,1)
如上所述,所有的sf2和sf4码被使用,并且在接收器侧被相加。因此,存在其中在正常解调处理中甚至通过(内积)解扩也不能对数据进行成功解调的模式。为了避免此种情况,当使用四阶(sf4)代码w4_*的扩展被执行时,在发送期间,乘以其幅值在扩展之后被提高的系数cg0(w4_*是w4_0、w4_1、w4_2和w4_3的其中之一)。系数cg0被设置为大于或等于1.0的值。例如,系数cg0被设置为1.3。在发送器侧乘以该系数使得能够在接收器侧完成解调。
图4示出将代码w4_*乘以系数cg0的状态。也就是说,sf4代码w4_0、w4_1、w4_2和w4_3(全部由数据复用单元111乘以系数cg0)被复用。乘以系数cg0后的数据被供应到逆快速傅里叶变换单元112。
[4.根据实施例的接收装置的配置的例子]
图6是示出根据实施例的被包括在基站200中的四个接收装置210、220、230和240的示例配置的框图。尽管图6示出接收装置210的配置,但是其它接收装置220到240也具有相同的配置。
由接收天线211接收的信号被供应到射频单元和正交调制单元219,其中,以一定频率无线发送的信号被解调并且获得i分量和q分量的接收数据。i分量的接收数据和q分量的接收数据被分别供应到串行/并行转换单元212i和212q,并且被转换为并行数据。由串行/并行转换单元212i和212q通过转换获得的i分量和q分量的接收数据被供应到模拟/数字转换器213i和213q,并被转换为数字数据。
由模拟/数字转换器213i和213q通过转换获得的接收数据被供应到保护间隔去除单元214i和214q,并且保护间隔(gi)被去除。已经从其中去除了保护间隔的i分量和q分量的接收数据被供应到快速傅里叶变换单元(fft单元)215,并且执行用于转换时间轴和频率轴的转换处理,以便从ofdm调制进行解调。
由快速傅里叶变换单元215通过变换获得的数据被供应到数据分离单元216,并且对接收数据执行分离处理。被分离的接收数据被供应到解交织单元217。解交织单元217恢复由交织单元在发送处理中分发的数据。由解交织单元217恢复的接收数据被供应到去映射单元218,并被去映射。由去映射单元218去映射的接收数据被供应到通信控制单元290。
[5.接收操作的例子]
接下来将描述接收装置的接收操作。
接收装置210获得图2中示出的矩阵的形式的接收信号。
图2中示出的矩阵表示由接收装置210的快速傅里叶变换单元215执行的变换后获得的矩阵。也就是说,该矩阵被表示为进行了快速傅里叶变换的频率范围。这里,h矩阵的元素取决于频率完全不同。对于在图2中示出的各个传递函数,取决于频率而不同的元素被表示为h00(f)等,并且数据由a、b、c和d表示。
在这种情况中,要从连接到图1中示出的接收装置210的接收天线211的接收装置210中所包括的快速傅里叶变换单元215输出的信号的频率f0和f1的分量由下面的表达式(11)和(12)给出:
表达式(11)rx(f0)=h00(f0)*a*(1)+h10(f0)*b*(1)+h20(f0)*c*(1)+h40(f0)*d*(-1)
表达式(12)rx(f1)=h00(f1)*a*(1)+h10(f1)*b*(1)+h20(f1)*c*(1)+h40(f1)*d*(-1)
在表达式(11)和(12)中,(1)和(-1)表示由表达式(1)和(2)给出的代码w2_0和w2_1的元素。数据a从发送天线110a发送,数据b从发送天线120a发送,其中,f0和f1分量已经分别乘以了代码w2_0的第一元素(1)和代码w2_1的第二元素(1)。类似地,数据c从发送天线130a发送,数据d从发送天线140a发送,其中,f0和f1分量已经分别乘以了代码w2_1的第一元素(1)和代码w2_1的第二元素(-1)。
接收装置210通过代码w2_0和w2_1对接收信号进行解扩。解扩基于下面的表达式。
表达式(13)rx0(f0)+rx0(f1)=[rx(f0),rx(f1)]*(1,1)t
=[h00(f0)+h00(f1)]*a+[h10(f0)+h10(f1)]*b
+[h20(f0)-h20(f1)]*c+[h30(f0)-h30(f1)]*d
表达式(14)rx0(f0)-rx0(f1)=[rx(f0),rx(f1)]*(1,-1)t
=[h00(f0)-h00(f1)]*a+[h10(f0)-h10(f1)]*b
+[h20(f0)+h20(f1)]*c+[h30(f0)+h30(f1)]*d
在表达式(13)和(14)中,“t”表示转置。此外,由表达式(5)、(8)、(9)和(10)表示的复数数据由“a”、“b”、“c”和“d”表示。rx0、rx1、rx2和rx3分别表示接收装置210、220、230和240的接收信号。
表达式(13)的第三项和第四项以及表达式(14)的第一项和第二项基本上等于零。这基于信道的相邻频率之间的差。例如,lte标准通常采用15khz间隔,并且每个信道具有最小为1.5mhz的带宽。因此,该差通常小到可以忽略不计。因此,只有来自发送装置110的信号和来自发送装置120的信号仍然留在表达式(13)中。此外,只有来自发送装置130的信号和来自发送装置140的信号仍然留在表达式(14)中。
通过使用对应信道的信号h**(f)并将数据乘以对应信号1/h**(f),使得能够进行在频率上对信道的差的正确消除(这里,h**是图1和图2中示出的传递函数h00到h33的其中之一)。
该消除处理可以是在发送装置执行发送时所执行的处理,或者可以是对接收装置接收到的信号所执行的处理。由于h00(f)通常表示远小于1的值,因此发送期间的相乘可以提高发送功率。因此,优选地,在接收器侧执行该处理。
在实际中,由于噪声被相加,因此在频率上的差被埋没在噪声中,并且可能不必一定执行对该差的校正。
对于代码sf4,由于代码w2_0与代码w4_2和w4_3正交,因此来自发送装置130和发送装置140的四阶(sf4)代码在与表达式(13)中的代码w2_0的内积中产生零。类似地,由于代码w2_1与代码w4_0和w4_1正交,因此来自发送装置110和发送装置120的四阶(sf4)代码在与表达式(14)中的代码w2_1的内积中产生零。
因此,只需要使用代码w2_0和代码w2_1来计算内积,以分离用于一对发送装置110和120的信号和用于一对发送装置130和140的信号。
对于在与四阶代码sf4的内积中产生零,如同在二阶代码sf2的情况中,发生基于不同频率的信道的差。但是,这样的差也是可以忽略的,这是由于,例如,lte标准提供高达60khz的频宽。如果需要的话,在频率上信道的差可以使用类似于用于二阶代码sf2的方法的方法来校正。
[6.h矩阵的例子]
将参照图7a、图7b和图7c来描述通过上述处理的图2中示出的h矩阵的简化。
在图7a中示出的h矩阵是在该实施例的处理未被执行时获得的,并且该h矩阵是4×4矩阵。对于应用逆快速傅里叶变换与快速傅里叶变换的频率中的每个频率,存在该矩阵。在实际中,如果在频率上信道的差很小,则相同的矩阵被重复地使用。图7a、图7b和图7c中,这被表示为函数“f”。作为来自发送装置的发送数据,来自四个发送装置110、120、130和140的发送数据分别由a、b、c和d表示。这也被设置到用于逆快速傅里叶变换的频率轴,并且是频率的函数。
在根据本实施例的处理被执行的情况中,数据排列不同于在图7中示出的例子中给出的数据排列,并且相同的数据被排列在诸如频率轴f0和f1以及频率轴f2和f3的相邻频率轴上。因此,a(f0)=a(f1)等等。在图7a、图7b和图7c中,这种状态被表示为a(f0)。
接收装置执行上述的内积,从而使得在图7a中示出的矩阵被表示为如图7b所示。图7b中的矩阵的上半部分表示与代码w2_0的内积,图7b中的矩阵的下半部分表示与代码w2_1的内积。
就接收天线201、202、203和204来说重新排列图7b中示出的矩阵产生图7c中示出的矩阵。在图7c中示出的矩阵中,不存在图7b中示出的矩阵中的rx2和rx3的项。这意味着只有rx0和rx1被用于接收。结果,4×4的h矩阵的计算为块对角化4×4矩阵的计算,使得明显简单的逆矩阵计算变得可行。
也就是说,图7c中的矩阵的对角块的逆矩阵被确定,并且与由代码w2_0和w2_1解扩而获得的结果相乘(图7c中的左侧)。因此,可以确定发送信号a、b、c和d。
[7.数据分离处理的例子]
通过上述处理提取的数据a、b、c和d,在其上叠加有代码sf4。
图8是示出用于从由快速傅里叶变换单元215变换和输出的信号中将代码sf2的数据和代码sf4的数据分离的处理的示图。
为了分离相加的信号,首先,在第一步骤中,通过乘以更高阶的代码sf4来计算内积。也就是说,乘法器216b将接收数据串216a乘以作为四阶代码的代码w4_0。此外,乘法器216c将接收数据串216a乘以代码w4_1。此外,乘法器216d将接收数据串216a乘以代码w4_2。此外,乘法器216e将接收数据串216a乘以代码w4_3。在每个相乘期间,都乘以系数cg0。
通过上述处理,相互正交的四个代码4_0、4_1、4_2和4_3相互之间的内积为零,因此可以获得发送信号(c0、c1、c2、c3、d0、d1、d2、d3)。由于二阶代码的干扰,其中的一些可能未被解码。通过将四阶代码乘以系数cg0可以避免此种情况。
在第二步骤中,以类似于发送的方式,乘法器216f、216g、216h和216i进一步再次使用获得的与四阶代码有关的数据来乘以代码w4_0、w4_1、w4_2和w4_3。这些结果由加法器216j相加,并且由减法器216k将相加的信号从接收信号中减去。正如可以从表达式(9)看出的,该操作对应于将与四阶代码有关的项从接收信号中减去的操作,结果,只有与二阶代码有关的项保留下来。
在第三步骤中,以上述方式获得的结果与代码w2_0和w2_1的内积由乘法器216m和216n来计算。因此,所有的接收流(a0、a1、a2、a3、b0、b1、b2、b3)可以被分离并解码。
在诸如16qam的多级调制被用作调制方案的情况中,由于已经通过乘以参数cg0使得信息被携带在幅值上,因此不容易进行解码。因此,为了提高发送效率,具有不同长度的代码被进一步复用。当具有不同长度的正交码要被复用时,乘以用于提高幅值的系数。
[8.其它实施例(mu-mimo中的分组的其它例子)的例子]
在上述描述中,已经描述了如图1所示的4×4mu-mimo通信的应用的例子。作为发送装置或接收装置的数量的n可以被扩展到一般的整数。例如,在当前正在被研究的16×16mu-mimo通信中,可以进行任意分组,诸如,八个装置和八个装置、四个组四个装置、以及六个装置和十个装置。这样可以降低信道矩阵的阶,从而促进逆矩阵的求得以及促进避免变成非正则。
图9a示出这样的例子,其中,布置有作为分离的终端的六个发送装置110到160并且基站200包括六个接收装置210到260。由于设置有六个发送装置和六个接收装置,因此6×6mu-mimo通信被实现。图9a示出在6×6mu-mimo通信被执行的情况中的分组的例子。
发送装置110到160分别包括发送天线110a到160a。此外,接收装置210到260分别包括接收天线211到261。
在图9a中的系统配置中,六个发送装置110到160被分成下列四个组:
第一组:发送装置110和120
第二组:发送装置130和140
第三组:发送装置150
第四组:发送装置160
图9b示出以图示的方式来应用分组时为各个组分配ovsf码的例子。在图9b中,ue0、ue1、ue2、ue3、ue4和ue5分别表示发送装置110、120、130、140、150和160,rx0、rx1、rx2、rx3、rx4和rx5分别表示接收装置210、220、230、240、250和260。
正如图9b中的矩阵所给出的,ovsf码被分配给各个组。
例如,如果第一组中的发送装置110和120是执行高速通信的终端,则作为二阶代码sf2的代码w2_0和四阶代码w4_0和w4_1被分配给发送装置110和120,从而使得可以执行高速通信。
此外,如果第二组中的发送装置130和140是执行中速通信的终端,那么四阶代码w4_2和w4_3被分配给发送装置130和140。
此外,如果第三组和第四组中的发送装置150和160是执行低速通信的终端,则分配代码w8_4、w8_5和w8_6作为小于或等于八阶代码sf8并且相互正交的代码。
通过上述分配,信道矩阵可以图9b中示出的方式被块对角化。
在图9a和图9b中示出的例子中,在发送天线和接收天线的数量相同的情况下,执行块对角化。相反地,接收天线的组合可以被改变。在这种情况中,在图9b中的块对角化矩阵中除了零以外的组的位置被改变。在任意一种情况中,应用根据上述本实施例的处理促进了接收信号的分离。
还可以确定在接收装置侧或者在基站200侧上的ovsf码的分配。基站200基于来自终端或发送装置的呼叫设置请求中包括的通信质量信息来确定每个终端所需的通信速度,确定要被复用的代码的阶,并且将其告知每个发送装置。用于在基站侧执行代码分配的处理并不限于如图9a和图9b所示的分组的情况。
[9.其它实施例的例子(实现分集的例子)]
接下来,作为本实施例的变型例的分集接收的例子在图10中示出。
图10示出在发送器侧具有四个天线并且在接收器侧具有四个天线的4×4mu-mimo通信的例子。
在这种情况中,应用根据上文中描述的本实施例的处理允许基站200仅使用两个接收装置#0210和#1220接收来自四个发送装置110的信号。
因此,两个接收装置#2230和#3240被用于执行与两个接收装置#0210和#1220执行的接收处理相同的接收处理,从而允许具有两种系统的分集接收,即,接收装置210和220的系统以及接收装置230和240的系统。
例如,使用在本领域中已知作为用于分集接收的处理的技术的rake组合,在两个系统上的接收信号被组合。因此,接收s/n可以被改进。可替换地,通过在由快速傅里叶变换解调之前使用最大比例组合,接收信号可以被组合。
如上所述,根据本公开实施例的例子,作为分离的终端的发送装置使用正交码被分组到多个组中,并且利用信道矩阵的正交化和代码复用,使得能够在基站侧使用较小数量的天线进行接收。这样可以简化信道矩阵,从而防止h矩阵成为非正则的。另外,可以实现计算负荷的减少。此外,由于天线的数量和接收装置的数量可以被减少,因此可以预期到使用数量减少的天线和接收装置来促进分集接收的压倒性的有利效果。
[10.其它变型例]
请注意,在本公开的权利要求中阐述的配置和处理并不限于上述实施例的例子中的配置和处理。应该理解,对于本领域的技术人员来说清楚的是,根据设计或其它要素,可以在权利要求或其等同物的范围内对示出的示例性实施例进行各种修改、合并和改变。
例如,实施例的示出的例子提供对终端与基站之间的上行链路的无线通信的应用,其应用被称为lte的通信标准。根据本公开的配置或处理还可以被应用于其它类似的上行链路的无线通信。
[附图标记列表]
110、120、130和140、150、160:发送装置(终端),
101:通信控制单元,
110a、120a、130a、140a、150a、160a:发送天线,
110x:发送单元,
101y:通信控制单元,
111、121、131和141:数据复用单元,
112、122、132、142:逆快速傅里叶变换单元(ifft单元),
113:映射单元,
114:交织单元,
115:ifft帧构建单元,
116i、116q:保护间隔插入单元,
117i、117q:并行/串行转换单元,
118i、118q:数字/模拟转换器,
119:正交调制单元和射频单元,
200:基站,
201:接收天线,
210、220、230和240、250、260:接收装置,
211:射频单元和正交调制单元,
212i、212q:串行/并行转换单元,
213i、213q:模拟/数字转换器,
214i、214q:保护间隔去除单元,
215:快速傅里叶变换单元(fft单元),
216:数据分离单元,
217:解交织单元,
218:去映射单元,
290:通信控制单元
- 还没有人留言评论。精彩留言会获得点赞!