一种能实现篡改帧定位的视频加密方法与流程
本发明涉及视频加密技术领域,特别是涉及一种能实现篡改帧定位的视频加密方法。
背景技术:
随着传媒产业的迅速发展,视频在传输过程中的真实性与安全性尤为重要,视频加密与防篡改技术被广泛地应用到视频传输过程中。传统方法在视频图像中嵌入数字水印,再对视频进行加密传输,接收者通过视频解密,提取数字水印进行视频内容完整性认证。这类方法中,加密与防篡改功能往往分开进行;此外,对于帧删除与帧交换攻击,基于数字水印的完整性认证会导致篡改信息无法被察觉,存在一定的安全隐患。
技术实现要素:
本发明的目的是针对现有技术中存在的技术缺陷,而提供一种能实现篡改帧定位的视频加密方法,能同时完成视频保密传输与完整性认证。
为实现本发明的目的所采用的技术方案是:
一种能实现篡改帧定位的视频加密方法,包括以下步骤:
利用logistics混沌映射产生一组密钥流,作为视频中每一帧图像加密的第一密钥;
对每一帧图像边缘特征进行提取,并进行特征阵列求和运算,作为每一帧图像加密的第二密钥;
基于超混沌系统得到需要的行置乱向量与列置乱向量,选择预定的行置乱向量与列置乱向量对视频中每一帧图像阵列进行行列坐标置乱,从而完成加密。
所述的对每一帧图像边缘特征进行提取,并进行特征阵列求和运算的步骤具体为:
用相对变分法rtv对图像进行平滑处理,滤除图像中的噪声和图像中复杂的纹理信息之后,对平滑处理后的图像进行canny边缘检测,获取每帧图像的边缘轮廓特征阵列egi,计算sumegi,即为第二密钥。
所述的选择预定的行置乱向量与列置乱向量对视频中每一帧图像阵列进行行列坐标置乱,从而完成加密的步骤为:
将第k帧图像对应的第一密钥与第k-1帧视频对应的第二密钥,分别对4取余,利用计算结果对超混沌系统生成的行置乱向量与列置乱向量进行选择,得到该第k帧图像的行列置乱向量,用该行列置乱向量对第k帧图像行列坐标进行置乱,从而完成对第k帧图像的加密,以此类推,直至完成对视频中所有帧的加密。
与现有技术相比,本发明的有益效果是:
本发明能实现篡改帧定位的视频加密方法,能够同时实现视频信息在传输过程中的加密与防篡改功能,并能够抵御帧删除与帧交换攻击这些数字水印无法察觉的篡改手段。
附图说明
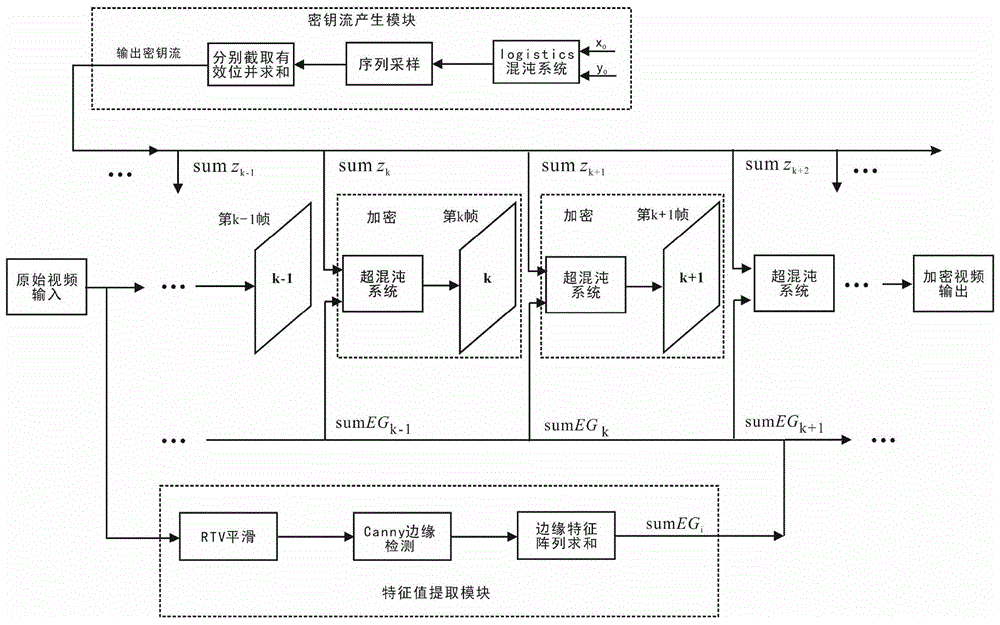
图1为能实现篡改帧定位的视频加密方法示意图;
图2为对应的能实现篡改帧定位的视频加密的解密示意图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明的一种能实现篡改帧定位的视频加密方法,包括以下的步骤:
s1,利用logistics混沌映射产生一组密钥流,作为视频中每一帧加密的部分密钥;
所述的logistics映射是密码体系中常用的混沌系统,其差分表达式如下:
xk+1=μxk(1-xk)
其密钥流产生步骤如下:
步骤1:输入初始参数x0,y0(即logistics混沌序列的初始密钥),生成两个混沌序列,并对两个混沌序列分别进行间隔为l1和12的采样,得到混沌序列{xi},{yi},i=1,2,…,l,其中l为视频总帧数;
步骤2:分别将{xi},{yi},i=1,2,…,l整数位置零,并将其转换为二进制,取小数点后前16位得到序列{x'i},{y'i},i=1,2,…,l;
步骤3:令
s2,对每一帧图像边缘特征进行提取,并进行特征阵列求和运算,作为每一帧加密的另一部分密钥;
首先,利用相对变分法(rtv)对图像进行平滑处理,滤除图像中的噪声和图像中复杂的纹理信息,之后,对平滑处理后的图像进行canny边缘检测,获取每帧图像的边缘轮廓特征阵列egi计算sumegi,
s3,基于超混沌系统,结合前面两步生成的密钥对视频中每一帧图像进行加密。
其中,一种超混沌系统的动力学方程式为:
合理设置a,b,c,d,e,使系统处于超混沌状态,对于每一帧视频的加密步骤如下:
步骤1:设置初始参数{x10,x20,x30,x40}和{y10,y20,y30,y40},对于m×n图像,将{x10,x20,x30,x40}与{y10,y20,y30,y40}利用超混沌系统分别迭代m次和n次,从而得到8组混沌序列{xam,a=1,2,3,4,m=1,2,…,m},{ybn,b=1,2,3,4,n=1,2,…,n};
步骤2:将{xam},{ybn}中的元素从大到小进行排列,得到的重排后的8组混沌序列{xam},{ybn};计算{xam},{ybn}中的元素在{xam},{ybn}中的位置,分别得到4组行置乱向量
步骤3:令s1=sumzimod4,mod是取余运算,即sumzi的值对4取余,若s1=0,则选用
步骤4:利用选择的置乱向量对该帧图像进行行列置乱,完成加密。设原始第i帧图像行、列坐标序列分别为prow={pr1,pr2,…,prn},pcol={pc1,pc2,…,pcm},置乱加密后的行、列坐标序列为p’row={p'r1,p'r2,…,p'rn},p’col={p'c1,p'c2,…,p'cm},其中,
下面结合图1-2进行说明,图1中,x0,y0为生成logistics混沌序列的初始密钥;sumzk-1,sumzk,sumzk+1分别为第k-1帧,第k帧和第k+1帧所对应的采样混沌序列经过截取、求和的结果;sumegk-1,sumegk,sumegk+1分别为第k-1帧,第k帧和第k+1帧所对应边缘特征阵列求和结果。
加密具体流程如图1所示:首先,基于logistics混沌映射产生密钥流sumzi,将密钥流中的密钥分配给视频的每一帧;特征提取模块对输入视频中的每一帧图像进行rtv平滑、canny边缘检测和边缘特征阵列求和提取每帧视频的边缘特征值sumegi;之后,sumzi与sumegi-1基于超混沌系统共同完成对第i帧图像的加密。例如对于图1中第k帧视频来说,将本帧视频对应的sumzk与从第k-1帧视频提取的边缘特征值sumegk-1分别对4取余,利用计算结果对超混沌系统生成的置乱向量进行选择,得到该帧图像的行列置乱向量,用该置乱向量对图像行列坐标进行置乱,从而完成对第k帧视频的加密,以此类推,直至完成对视频中所有帧的加密。
视频解密的具体流程如图2所示。解密过程与加密过程类似,利用视频发送方发送的密钥x0,y0通过密钥流产生算法计算每一帧视频对应sumzi,首先通过sumz1与初始密钥对第1帧视频进行解密;之后,将提取的sumeg1与第2帧图像对应的sumz2分别对4取余,利用计算结果对超混沌系统生成的置乱向量进行选择,得到该帧图像的行列置乱向量,通过对行列置乱向量与加密图像行列坐标进行逆变换,实现对第2帧视频的解密,以此类推,逐帧完成对视频的解密。
关于篡改帧定位:
对于视频当前帧来说,加密过程中所运用的密钥有两个方面决定,一是logistics产生的密钥流sumzi,二是前一帧图像的边缘轮廓特征sumegi-1,故在解密过程中,如果发生帧内容篡改、帧交换和帧删除,则解密过程无法顺利进行,通过视频逐帧解密的结果判断篡改发生的位置。下面参照图2,对篡改位置的识别进行详细阐述:
①对于帧内容篡改:
在视频传输过程中,若视频中第k帧图像被攻击者暴力破解并进行篡改,则收方接收该视频后对视频进行解密过程中,提取的第k帧的边缘轮廓特征sumegk发生变化,计算得到的解密向量不正确,导致第k+1帧无法被解密,从而发现视频篡改帧的位置。
②对于帧交换:
若视频中第k-1帧图像与第k+1帧图像进行交换,则在解密过程中对于第k帧视频来说,前一帧的边缘轮廓特征由sumegk-1变为sumegk+1,计算得到的解密向量不正确,导致第k帧无法被解密,从而发现视频篡改帧的位置。
③对于帧删除:
若视频中第k帧图像被删除,则在解密过程中对于第k+1帧视频来说,前一帧的边缘轮廓特征由sumegk变为sumegk-1,计算得到的解密向量不正确,导致第k+1帧无法被解密,从而发现视频篡改帧的位置。
本发明相对于传统方法在视频图像中嵌入数字水印,再对视频进行加密传输的方式,本方法只需要对视频进行一次加密,过程更为简洁;另外,本发明能够对帧删除与帧交换攻击等基于数字水印无法察觉的攻击进行检测。
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!