一种基于流量可视化与机器学习算法的入侵检测方法与流程
本发明属于互联网技术领域,具体涉及一种基于流量可视化与机器学习算法的入侵检测方法。
背景技术:
近年来,随着互联网技术的不断发展,人们对互联网的应用越来越广泛,网络中攻击的频度与强度随之不断增强,网络环境也随之恶化。网络攻击即利用网络漏洞和安全缺陷对网络系统的硬件、软件及数据进行的攻击。从对信息的破坏性上看,攻击类型可以分为被动攻击和主动攻击。主动攻击会导致某些数据流的篡改和虚假数据流的产生。这类攻击可分为篡改、伪造消息数据和终端(拒绝服务)。被动攻击中攻击者不对数据信息做任何修改,是指在未经用户同意和认可的情况下攻击者获得了信息或相关数据。通常包括窃听、流量分析、破解弱加密的数据流等攻击方式。为了抵御这些攻击,改善网络环境,入侵检测系统(ids)随之提出。
入侵检测系统是一种监视主机和网络是否存在可疑事件,并对可疑事件自动做出相应反应的安全防护技术。ids主要的监视目标是计算机系统中的网络流量,在对流量嗅探的同时收集网络日志数据。通过对收集的网络数据进行规则分析,或者进行模型检测,便能够判断出是否存在入侵问题。可以通过从先前已知的攻击中提取特定规则来训练基于规则分析的系统,也可以从没有入侵时收集的正常数据中学习。当检测到任何威胁时,ids将会向网络管理员发出警报进行提醒。ids分为基于网络的ids和基于主机的ids以及后来出现的分布式ids。
但是大量具有较高精度的算法只能区分出异常数据,无法准确检测出每种攻击,这不利于对攻击的针对性处理,而能够准确检测出每种攻击的算法又存在着精度较低的问题,最为关键的是,大部分特征需要对流量进行长时间、完整的监测方可提取,这导致了难以实时检测网络攻击,此外,还存在着建立入侵系统速度慢、特征提取复杂、资源占用率代价高等不足,同时,每天都会大量新的攻击,因此如何针对新的攻击进行检测又对如今的入侵检测系统提出了新的挑战。
技术实现要素:
针对现有技术中的上述不足,本发明提出一种基于流量可视化与机器学习算法的入侵检测方法,用于解决现有技术存在的无法准确检测出每种攻击、无法实时检测网络攻击、建立入侵系统速度慢、特征提取复杂以及资源占用率代价高的问题。
为了达到上述发明目的,本发明采用的技术方案为:
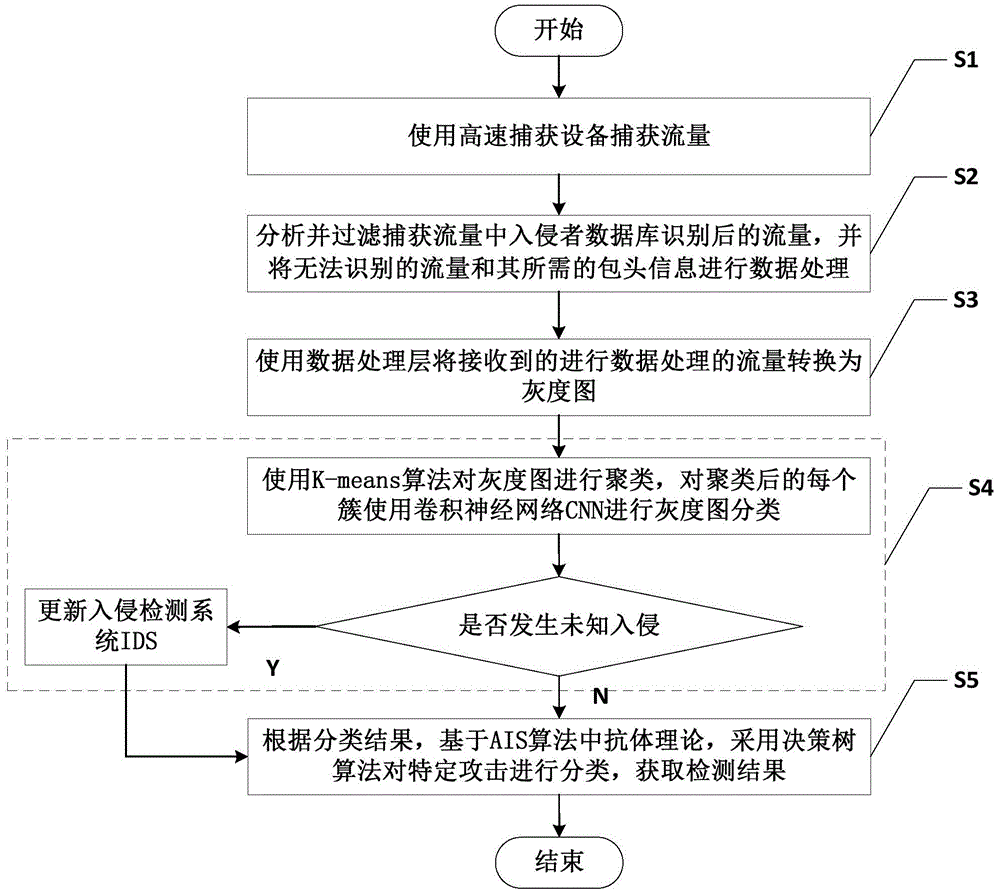
一种基于流量可视化与机器学习算法的入侵检测方法,包括如下步骤:
s1:使用高速捕获设备捕获流量;
s2:分析并过滤捕获流量中入侵者数据库识别后的流量,并将无法识别的流量和其所需的包头信息发送到数据处理层进行数据处理;
s3:使用数据处理层将接收到的进行数据处理的流量转换为灰度图;
s4:基于半监督学习对灰度图进行聚类,对聚类后的每个簇进行分类,并基于熵理论和分类结果判断是否发生未知入侵,若是则更新入侵检测系统ids,并进入步骤s5,否则直接进入步骤s5;
s5:根据分类结果,基于ais算法中抗体理论,采用决策树算法对特定攻击进行提纯,获取检测结果。
进一步地,步骤s2包括以下步骤:
s2-1:建立入侵者数据库,并使用其对当前捕获流量进行检测与分类;
分类类别包括识别后的流量和无法识别的流量;
s2-2:将识别后的流量信息存入入侵者数据库,并基于时间机制,接收其后续到达的数据包;
s2-3:提取该数据包的包头信息,并根据入侵者数据库中已有的流量信息进行搜索和对比,判断是否存在对应的流量信息,若是则输出该数据包为入侵流量,并进入步骤s2-4,否则输出该数据包为正常流量,并进入步骤s2-4;
s2-4:将无法识别的流量和其所需的包头信息发送到数据处理层进行数据处理。
进一步地,步骤s3包括如下步骤:
s3-1:判断接收到的进行数据处理的流量的大小是否大于10kb,若是则保留前10kb的流量,否则将其进行复制直到总体大小为10kb;
s3-2:将大小为10kb的流量二进制读取为8位无符号整数的向量,并将其进行组织获取2d数组;
s3-3:根据2d数组获取大小固定的灰度图。
进一步地,步骤s4中,采用k-means算法对灰度图进行聚类,包括如下步骤:
a-1:将灰度图中标记数据和未标记数据合并为数据集,使用k-means算法对数据集进行聚类;
a-2:将每个簇所关联的中心点移动到平均值的位置,更新中心;
a-3:重复步骤a-2,直至中心点不再变化,完成最终聚类。
进一步地,步骤a-1中,k-means算法通过随机初始化赋给每个簇不同的中心,将每一个数据点赋给距离类最近的中心,其公式为:
c(i)=argmink||x(i)-μk||2
式中,c(i)为与第i个输入数据的距离最近的聚类中心的索引;x(i)为第i个输入数据;μk为k个簇中的第k个聚类中心;k为簇总数;k为聚类中心指示量;i为输入数据指示量;
距离为欧氏距离,其公式为:
式中,d(x,y)为输入数据与聚类中心的欧氏距离;xn为当前样本的第n个特征值;yn为当前聚类中心的第n个特征值;n为特征值变量。
进一步地,步骤s4中,对聚类后的每个簇使用卷积神经网络cnn进行灰度图分类,包括如下步骤:
b-1:遍历检测聚类后的每个簇,将不含标记数据的簇中所有数据标记为未知数据;
b-2:根据簇中未知数据与标记数据对cnn进行训练;
b-3:使用训练后cnn对所有未标记数据进行分类,将分类结果为攻击的流量返回至数据处理层进行特征提取,并将其与对应的流量信息输入至ids,完成ids的更新;
所述分类类别包括已知攻击、未知攻击以及良性流量;
b-4:将分类为已知攻击或良性流量的数据合并到标记数据中,并重新标记未知数据,对cnn进行再次训练;
b-5:重复步骤b-1至b-4,直至完成对聚类后的簇中所有数据的分类,输出分类结果。
进一步地,步骤s4中,基于熵理论和分类结果判断是否发生未知入侵并更新入侵检测系统ids的具体方法为:
当簇分类结果的信息熵超过阈值时,从该簇中随机提取三条流量进行人工检测;
若这三条流量都属于同一种未知攻击,则发生未知入侵,对该簇中所有流量对应的未知攻击标记为新分类类别,重新对cnn进行训练,完成ids的更新,并创建与训练新分类类别的c4.5决策树;
若这三条流量都属于某一种已知攻击或良性流量,则将该簇中所有流量合并至对应已知攻击训练数据中,重新对cnn进行训练,完成ids的更新,并对对应的c4.5决策树进行训练;
若这三条流量都属于新的良性流量,则将该簇中所有流量合并至良性流量训练数据中,重新对cnn进行训练。
进一步地,步骤s4中,cnn包括输入层、卷积层、激励层、池化层以及全连接层;
输入层用于接收灰度图的二维形式输入数据,并对灰度图数据进行预处理;预处理包括依次进行的去均值处理、归一化处理以及pca/白化处理;
卷积层用于进行局部关联和窗口滑动,其公式为:
式中,
激励层用于将卷积层的输出结果进行非线性映射;
池化层的采样方法为最大值子采样方法,其公式为:
式中,
全连接层的最终输出结果的公式为:
y=f(ωkx+bk)
式中,y为全连接层的最终输出;ωk为连接权重;x为全连接层的输入;bk为偏差;f(·)为cnn的激活函数。
进一步地,步骤s5中,将数据处理层提取的分类结果为攻击的流量的特征输入对应类别的c4.5决策树,并采用决策树算法对特定攻击进行提纯,获取剔除良性流量后的攻击流量
进一步地,决策树算法,包括如下步骤:
s5-1:根据输入特征向量,获取训练集的信息熵,其公式为:
式中,info(d)为训练集d的信息熵,为各项自信息的累加值;d为训练集;pm为随机变量分别属于第m类的概率;m为输入特征向量指示量;m为输入特征向量总数;
s5-2:将训练集按照划分属性进行划分,并获取对应的划分属性的信息熵,其公式为:
式中,infoa(d)为属性a的信息熵;info(dv)为训练集中第v类样本的信息熵,且info(dv)∈info(d);|dv|为第v类样本的样本数量;|d|为训练集中样本数量;v为类别指示量;v为分类类别总数;a为选择的划分属性;
s5-3:根据训练集的信息熵和划分属性的信息熵,获取划分属性的信息增益,其公式为:
infogain(s,a)=info(d)-infoa(d)
式中,infogain(s,a)为属性a的信息增益;info(d)为训练集d的信息熵;infoa(d)为属性a的信息熵;
s5-4:获取划分属性的分裂信息,并根据其以及划分属性的信息增益,获取划分属性的信息增益率;
划分属性的分裂信息的公式为:
式中,splitlnfoa(d)为属性a的分裂信息;|dv|为第v类样本的样本数量;|d|为训练集中样本数量;v为类别指示量;v为分类类别总数;
划分属性的信息增益率的公式为:
式中,infogainration(s,a)为属性a的信息增益率;infogain(s,a)为属性a的信息增益;splitlnfoa(d)为属性a的分裂信息;
s5-5:遍历训练集中所有节点,选择信息增益率最大的划分属性作为当前节点的分裂属性进行分类。
本方案的有益效果:
(1)采用切实可行的过滤机制与灰度图转换机制将网络流量转化为灰度图,以新颖的方式来表征网络流量,在具备高精确性的基础上,同时保证了较好的实时性以及较低的资源占有率;
(2)本发明结合人工免疫系统思想,采用cnn+c4.5算法进行分类,采用多层体系,对流量分类,极大地提升了分类的精度;
(3)基于“熵”理论与半监督学习提出了样本拓展与ids进化机制,样本拓展机制减少了人工标记操作,在训练样本不足的情况下仍能够保证足够的精度,ids进化机制保证当发生未知攻击时,入侵检测系统可针对未知攻击完成更新进化。
附图说明
图1为基于流量可视化与机器学习算法的入侵检测方法流程图;
图2为本发明步骤s2方法流程图;
图3为本发明步骤s3方法流程图;
图4为采用k-means算法对灰度图进行聚类方法流程图;
图5为对聚类后的每个簇使用cnn进行灰度图分类方法流程图;
图6为决策树算法流程图;
图7为本发明cnn结构图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于流量可视化与机器学习算法的入侵检测方法,包括如下步骤:
s1:使用高速捕获设备rf_ring或tnapi捕获流量;
s2:分析并过滤捕获流量中入侵者数据库识别后的流量,并将无法识别的流量和其所需的包头信息发送到数据处理层进行数据处理,如图2所示,包括以下步骤:
s2-1:建立入侵者数据库,并使用其对当前捕获流量进行检测与分类;
分类类别包括识别后的流量和无法识别的流量;
s2-2:将识别后的流量信息存入入侵者数据库,并基于时间机制,接收其后续到达的数据包;
时间机制为:当某流量对应的最后到达时间已过去90s,仍无属于该流量的数据包到达,那么入侵者数据库中该流量的记录便会被删除;若仍然有属于该流量的数据包到达,便更新最后该流量对应的最后到达时间;
s2-3:提取该数据包的包头信息,并根据入侵者数据库中已有的流量信息进行搜索和对比,判断是否存在对应的流量信息,若是则输出该数据包为入侵流量,并进入步骤s2-4,否则输出该数据包为正常流量,并进入步骤s2-4;
s2-4:将无法识别的流量和其所需的包头信息发送到数据处理层进行数据处理;
s3:使用数据处理层将接收到的进行数据处理的流量转换为灰度图,如图3所示,包括如下步骤:
在现实网络中,流量的大小并不是固定的,有的流量持续时间长,数据量有几百kb甚至mb级单位,而有的流量持续时间短,仅有几百b;
s3-1:判断接收到的进行数据处理的流量的大小是否大于10kb,若是则保留前10kb的流量,否则将其进行复制直到总体大小为10kb;
s3-2:将大小为10kb的流量二进制读取为8位无符号整数的向量,并将其进行组织获取2d数组;
s3-3:根据2d数组获取大小固定的灰度图;灰度图属于[0,255]范围内,其大小设置为固定,避免图像大小的影响;
同时使用数据处理层提取部分特征,这些特征无需对流量进行长时间监控方能提取,简化了特征提取的过程;
s4:基于半监督学习,使用k-means算法对灰度图进行聚类,对聚类后的每个簇使用卷积神经网络cnn进行灰度图分类,并基于熵理论和分类结果判断是否发生未知入侵,若是则更新入侵检测系统ids,并进入步骤s5,否则直接进入步骤s5;
基于半监督学习,使用k-means算法对灰度图进行聚类,对聚类后的每个簇使用卷积神经网络cnn进行灰度图分类,对未标记数据进行迅速标记并将其纳入训练阶段来构建一个强大的分类器,在人体免疫系统中,由白细胞组成第一层防线,对所有入侵进行识别攻击;结合这个思想,我们采用基于cnn的图像分类模型,实现了对流量的初步分类;将k-means算法与熵理论结合,提出了ids更新模块,实现针对未知数据的细粒度分类,目标是在识别的未知数据中学习新的类别,并补充ids的知识,在未来该数据再次出现时能够对新的攻击或良性流量直接完成识别;
采用k-means算法对灰度图进行聚类,如图4所示,包括如下步骤:
a-1:将灰度图中标记数据t1={ψ1,ψ2,ψ3,...,ψn}和未标记数据t2={φ1,φ2,φ3,...,φm}合并为数据集t,使用k-means算法对数据集t进行聚类;
k-means算法接受未标记数据集,然后将数据聚类成不同的k个簇,通过随机初始化赋给每个簇不同的中心,将每一个数据点赋给距离类最近的中心,其公式为:
c(i)=argmink||x(i)-μk||2
式中,c(i)为与第i个输入数据的距离最近的聚类中心的索引;x(i)为第i个输入数据;μk为k个簇中的第k个聚类中心;k为簇总数;k为聚类中心指示量;i为输入数据指示量;
距离为欧氏距离,其公式为:
式中,d(x,y)为输入数据与聚类中心的欧氏距离;xn为当前样本的第n个特征值;yn为当前聚类中心的第n个特征值;n为特征值变量;
a-2:将每个簇所关联的中心点移动到平均值的位置,更新中心;
a-3:重复步骤a-2,直至中心点不再变化,完成最终聚类;
对聚类后的每个簇使用cnn进行灰度图分类,如图5所示,包括如下步骤:
b-1:遍历检测聚类后的每个簇,将不含标记数据的簇中所有数据标记为未知数据;
b-2:根据簇中未知数据与标记数据对cnn进行训练;
b-3:使用训练后cnn对所有未标记数据进行分类,将分类结果为攻击的流量返回至数据处理层进行特征提取,并将其与对应的流量信息输入至ids,完成ids的更新;
所述分类类别包括已知攻击、未知攻击以及良性流量;
b-4:将分类为已知攻击或良性流量的数据合并到标记数据中,并重新标记未知数据,对cnn进行再次训练;
b-5:重复步骤b-1至b-4,直至完成对聚类后的簇中所有数据的分类,输出分类结果;
信息熵是各项自信息的累加值,由于每一项都是整正数,故而随机变量取值个数越多,状态数也就越多,累加次数就越多,信息熵就越大,混乱程度就越大,因此,信息熵就会越大,簇的分类结果就越多,当信息熵超过某一阈值,就有理由相信分类结果不正确,出现了未知入侵或流量;基于熵理论和分类结果判断是否发生未知入侵并更新入侵检测系统ids的具体方法为:
当簇分类结果的信息熵超过阈值时,从该簇中随机提取三条流量进行人工检测;
若这三条流量都属于同一种未知攻击,则发生未知入侵,对该簇中所有流量对应的未知攻击标记为新分类类别,重新对cnn进行训练,完成ids的更新,并创建与训练新分类类别的c4.5决策树;
若这三条流量都属于某一种已知攻击或良性流量,则将该簇中所有流量合并至对应已知攻击训练数据中,重新对cnn进行训练,完成ids的更新,并对对应的c4.5决策树进行训练;
若这三条流量都属于新的良性流量,则将该簇中所有流量合并至良性流量训练数据中,重新对cnn进行训练;
cnn最显着的特征是通过训练过程自动提取图像特征,如图7所示,cnn包括输入层、卷积层、激励层、池化层以及全连接层,卷积层和池化层交替重复设置构成隐藏层,池化层位于连续的卷积层中间,激励层位于卷积层的输出端,全连接层设置于cnn的尾部;
输入层用于接收灰度图的二维形式输入数据,并对灰度图数据进行预处理;预处理包括依次进行的去均值处理、归一化处理以及pca/白化处理;白化即对数据各个特征轴上的幅度归一化然后通过卷积核(神经元的权重矩阵)映射到隐藏层,卷积核的作用是在降低了过拟合风险的同时又减少网络各层之间的连接以及神经网络的参数量;
卷积层用于进行局部关联和窗口滑动,其公式为:
式中,
激励层用于将卷积层的输出结果进行非线性映射,且其采用的激励函数为修正线性单元relu,其优点是收敛快以及求梯度简单;
池化层位于夹在连续的卷积层中间,用于压缩数据和参数的量,减小过拟合,其采样方法为最大值子采样方法,其公式为:
式中,
最后到达的是位于卷积神经网络尾部的全连接层,其两层之间所有神经元都有权重连接,与传统的神经网络神经元的连接方式是一样的,其输出被馈送到softmax函数,产生标签(该参数可自行设置)的概率分布,最终输出层将标签中概率最高的判断为最后的结果,完成最后的预测,cnn全连接层和输出层中的操作如下:首先,将前一层的输出特征图像逐一扩展为列向量,并堆叠以形成单列特征向量;全连接层的最终输出结果的公式为:
y=f(ωkx+bk)
式中,y为全连接层的最终输出;ωk为连接权重;x为全连接层的输入;bk为偏差;f(·)为cnn的激活函数;
cnn的配置参数对单相接地故障馈线检测的准确性有很大影响,应研究的cnn主要配置参数包括特征图像大小,归一化样本,激活函数,卷积核大小,合并层采样方法,迭代次数等;本发明对这些配置参数进行全面的分析,通过多次试验,发现特征图像大小在80*128的条件下,分类效果最为优良,并对网络参数进行优化与调整,以获得有利于所提出的故障检测方法性能的适当配置参数;
s5:根据分类结果,基于ais算法中抗体理论,采用决策树算法对特定攻击进行提纯,获取检测结果;结合人体免疫系统中t淋巴细胞识别特定抗原的思想,本发明在cnn分类的基础上,针对每一种攻击,设计了对应分类的决策树;
将数据处理层提取的分类结果为攻击的流量的特征输入对应类别的c4.5决策树,并采用决策树算法对特定攻击进行提纯,获取剔除良性流量后的攻击流量;
如图6所示,决策树算法,包括如下步骤:
s5-1:根据输入特征向量,获取训练集的信息熵,样本的信息熵表示的是所有样本中各种类别出现的不确定性之和,熵越大,不确定性就越大,把不同类别的数据划分开所需要的信息量就越多,其公式为:
式中,info(d)为训练集d的信息熵,为各项自信息的累加值;d为训练集;pm为随机变量分别属于第m类的概率;m为输入特征向量指示量;m为输入特征向量总数;
s5-2:每个输入特征向量都包含多种属性,将训练集按照划分属性进行划分,并获取对应的划分属性的信息熵,表示设置某种属性为划分条件后,划分后样本熵的大小,其公式为:
式中,infoa(d)为属性a的信息熵;info(dv)为训练集中第v类样本的信息熵,且info(dv)∈info(d);|dv|为第v类样本的样本数量;|d|为训练集中样本数量;v为类别指示量;v为分类类别总数;a为选择的划分属性将训练集d划分成v个不同的类;
s5-3:根据训练集的信息熵和划分属性的信息熵,获取划分属性的信息增益,其公式为:
infogain(s,a)=info(d)-infoa(d)
式中,infogain(s,a)为属性a的信息增益,即原始样本的信息熵减去属性a信息熵;info(d)为训练集d的信息熵;infoa(d)为属性a的信息熵;
s5-4:获取划分属性的分裂信息,并根据其以及划分属性的信息增益,获取划分属性的信息增益率;
“分裂信息”(splitinformation)是用来度量某种属性进行分裂时分支的数量信息和尺寸信息,这些信息被称为属性的内在信息(instrisicinformation);划分属性的分裂信息的公式为:
式中,splitlnfoa(d)为属性a的分裂信息;|dv|为第v类样本的样本数量;|d|为训练集中样本数量;v为类别指示量;v为分类类别总数;
划分属性的信息增益率的公式为:
式中,infogainration(s,a)为属性a的信息增益率;infogain(s,a)为属性a的信息增益;splitlnfoa(d)为属性a的分裂信息;
信息增益率用“信息增益/分裂信息”计算的优点是能够导致属性的重要性随着内在信息的增大而减小,即属性不确定性越大,就越不倾向于选取它,这可以看做对增益进行了归一化处理,避免了偏向选取分支多的属性,最终,c4.5算法构造决策树时,信息增益率最大的属性即为当前节点的分裂属性,随着递归计算,被计算的属性的信息增益率会变得越来越小,到后期则选择相对比较大的信息增益率的属性作为分裂属性;
由于决策树的建立完全是依赖于训练样本,因此对训练样本会产生完美的拟合效果,,但这样的决策树对于测试样本来说过于庞大而复杂,可能产生较高的分类错误率,这种现象称为过拟合,为了避免过拟合,需要将复杂的决策树去掉一些节点,即剪枝,剪枝方法分为预剪枝和后剪枝两大类,本发明采用的是后剪枝类的pep(pessimisticerrorpruning)剪枝法对c4.5决策树剪枝;
s5-5:遍历训练集中所有节点,选择信息增益率最大的划分属性作为当前节点的分裂属性进行分类。
本发明提出一种基于流量可视化与机器学习算法的入侵检测方法,解决了现有技术存在的无法准确检测出每种攻击、无法实时检测网络攻击、建立入侵系统速度慢、特征提取复杂以及资源占用率代价高的问题。
- 还没有人留言评论。精彩留言会获得点赞!