软件定义移动社交网络中的路由机制的制作方法
本发明属于网络通信技术领域,涉及软件定义网络与移动社交网络的结合,稀疏模式路由机制与密集模式路由机制及判别机制。
背景技术:
移动社交网络(mobilesocialnetwork,msn)作为一种延迟容忍网络,不提供可靠的端到端网络连接,且节点资源受限,在网络中自由移动会造成msn网络拓扑不稳定、延迟高、投递率低、数据传输率低等种种问题。现msn采用存储-转发的传输模式,节点携带消息,当遇到合适的节点才转发消息。
关于软件定义网络(softwaredefinednetwork,sdn),onf(opennetworkingfoundation)给出的定义如下:“在sdn的体系结构中,数据平面和控制平面相分离,网络的智能和状态是逻辑集中式的,底层网络设备被抽象出来为上层提供服务。”这个定义反应了sdn的四大特点:(1)数据平面和控制平面相解耦。(2)转发决策是基于流而不是目的。(3)逻辑集中式的控制。(4)控制平面通过对底层网络设备的抽象赋予网络可编程的能力。
技术实现要素:
为了解决msn中节点资源有限,延迟高,投递率低等问题,本发明设计了一种软件定义移动社交网络中的路由机制。
本发明采用的技术方案是:
一种软件定义移动社交网络中的路由机制,网络模型是基于sdn的msn体系结构,在此体系结构中,有一个连接到internet的远程sdn控制器;节点可以同时进行端到端通信和访问sdn控制器;节点传输数据时,如果无法确定下一跳,节点将访问sdn控制器。
sdn控制器在稀疏模式路由机制中采用基于聚类的社区发现算法;
假定节点运动过程中经常到达某一ap覆盖区,该ap为节点的常用ap;在本算法中,首先确定节点常用ap的集合;然后采用基于距离的聚类算法对常用ap的集合进行聚类,从而确定节点的常驻区;最后根据两个节点常驻区的重叠度判断它们是否处于同一社区;稀疏模式路由机制的社交度量;
稀疏模式路由机制中的社交度量包括3个:圈子相似度cs,全局流行度gp和区内流行度ip;
圈子相似度:首先定义稳定连接,进而定义朋友圈,最后令节点u和节点v的朋友圈中相同节点的个数与节点u、节点v的朋友圈中节点个数最大值的比值为圈子相似度;
全局流行度:首先定义全局相遇频繁度和相遇稳定性,然后定义全局关系密切度,最后定义节点u的全局流行度为节点u与网络中其它节点全局关系密切度的平均值;
区内流行度:首先定义区内相遇频繁度和相遇稳定性,然后定义区内关系密切度,最后定义节点u的区内流行度为节点u与社区内其它节点区内关系密切度的平均值。
稀疏模式路由机制的路由流程;
对bubblerap算法进行改进,增加了“圈子相似度”这一社交度量,从中心度相对较低的节点中,选择与目的节点具有更高圈子相似度的节点也作为中继节点,从而提高传递速率;另外,对bubblerap算法中的全局中心度和局部中心度重新进行了定义,命名为全局流行度和区内流行度,用以提升算法的性能。
sdn控制器在密集模式路由机制中采用基于羊群算法so的社区发现算法;
基于羊群算法so的社区发现算法把社区发现问题看成一个优化问题,使用羊群算法对拓展的模块度eq进行优化,直至达到迭代阈值;
密集模式路由机制的社交度量;
密集模式路由机制中的社交度量包括3个:社区密切度cc,区外流行度op,区内流行度ip;
社区密切度:首先定义区间相遇频繁度和相遇稳定性,然后定义区间关系密切度(rcb),最后定义社区1co1和社区
其中,n(co1)和n(co2)分别为社区1和社区2的节点个数;特殊的,定义同一社区间的社区密切度为1;
区外流行度:首先定义区外相遇频繁度和相遇稳定性,然后定义区外关系密切度,最后定义节点u的区外流行度为节点u与社区外其它节点区外关系密切度的平均值;
区内流行度:定义与稀疏模式路由机制中的区内流行度相同;
密集模式路由机制的路由流程;
在bubblerap算法中,消息是通过高中心度的节点进行传递的,但节点的电量和存储空间是有限的,尤其是在密集网络中,消息传输量大,通过高中心度的的节点进行路由的特点无疑成为了一个瓶颈,极大地影响了路由性能;这里再次对bubblerap进行改进,使社区作为一个整体参与路由,引入“社区密切度”的概念,从而解决了上述问题。
sdn控制器判别机制;
设网络中ap数为n(ap),节点数为n(node);当n(node)=o(n(ap))时,sdn控制器判定此时的网络为稀疏网络,需要采用稀疏模式路由机制;当n(node)=θ(n(ap)*n(ap))时,sdn控制器判定此时的网络为密集网络,需要采用密集模式路由机制。
本发明的优点如下:
1、首先,不同于以往的改进角度,我们选择网络疏密程度这一角度对bubblerap算法进行改进,设计了更适合于稀疏网络的稀疏模式路由机制和更适合于密集网络的密集模式路由机制。
2、其次,本设计将sdn控制器引入移动社交网络,sdn控制器可以根据判别机制判断网络总体的疏密程度,从而灵活地采取稀疏模式路由机制或密集模式路由机制。
3、基于以上两点,从理论上来说,本发明将在投递率、平均时延、网络开销等性能指标上有明显提升,从而实现高效的路由。
附图说明
图1为软件定义移动社交网络的网络模型。
图2(a)为稀疏模式社区发现算法的常驻区关系之一。
图2(b)为稀疏模式社区发现算法的常驻区关系之二。
图2(c)为稀疏模式社区发现算法的常驻区关系之三。
图3为稀疏模式路由机制的路由流程。
图4为密集模式路由机制的路由流程。
具体实施方式
下面结合说明书附图1、图2(a)、图2(b)、图2(c)图3、图4对本发明进一步详细说明。
1、网络模型,为了提高路由效率,我们将sdn部署到msn中。此时,节点必须能够连接到sdn控制器。这是能够做到的,一方面,移动设备是可以同时实现端到端通信和到ap通信的,如wifi直连;另一方面,wifi在园区内实现全面的覆盖是很容易做到的。
基于sdn的msn体系结构如图1所示。在此体系结构中,有一个连接到internet的远程sdn控制器。节点可以同时进行端到端通信和访问sdn控制器。节点传输数据时,如果无法确定下一跳,它将访问sdn控制器。
2、稀疏模式路由机制;
(1)基于聚类的社区发现算法
假定节点运动过程中经常到达某一ap覆盖区,即节点会通过该ap访问sdn控制器,我们称该ap为节点的常用ap,那么在不久的将来,该节点在此ap覆盖区出现的概率也非常高.很多现实环境都表现出这样的特征,例如,研究动物习性的网络中,动物经常在同一片区域觅食饮水;校园里学生经常出现在宿舍、教室等地.利用节点历史运动信息确定其常用ap,有利于准确预测该节点将来出现的位置,有目的地指导路由。
建立节点的常驻区
在时间段t内,sdn控制器负责统计节点竟连接了哪些ap及连接时长。我们设定阈值δ1,若连接时长超过δ1,则该ap为节点的常用ap。设bi={b1,b2,…bn}为节点i常用ap的集合,采用基于距离的聚类算法对bi中的点进行聚类,生成节点i的常驻区ri,节点的常驻区为圆形区域,记为r=(cx,y,r),其中cx,y表示圆心,r为半径。过程如下:
步骤1:遍历bi,找出bm和bl,两者是集合bi中距离最近的两个元素,即:
步骤2:如果bm和bl均为点,则二者合并形成类bm=<cx,y,k>,其中类中心
步骤3:若集合bi中所包含的元素个数多于1,则转步骤1,继续聚类。
步骤4:根据聚类所得b=<cx,y,n>计算常驻区的半径r。定义
社区发现
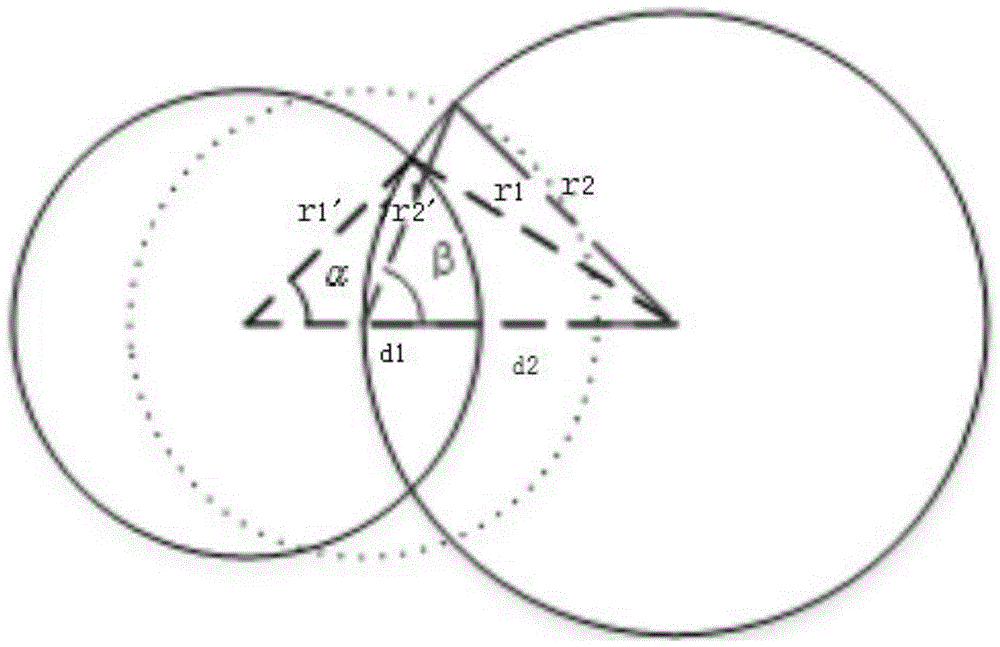
如果2个节点的常驻区重叠度比较大,则认为它们处于同一社区。2个节点常驻区的关系主要有不相交、包含、相交3种,如下图所示,图(a)不相交的两个节点不存在社区关系;图(b)包含关系的节点间关系密切,相遇概率很高,可以认为处于同一社区;常驻区相交的两个节点根据区域重叠程度确定是否为同一社区,具体方法为根据交点和2个圆心确定的角度大小近似衡量重叠的程度,如图(c)中的角度α,β,角度越大表示重叠的范围越大,我们设定阈值δ2,若角度大于δ2,则认为两个节点位于同一社区。
基于聚类的社区发现算法实质上是把经常出现在相同区域的节点划分为同一社区,不像在密集网络,在稀疏网络中采用该种社区划分方法得到的社区所包含的节点不会太多,所以基于聚类的社区划分方法适合于稀疏网络。
(2)社交度量
圈子相似度(cs):
newman曾对科学家之间的合作关系进行了长期的观察和分析,结果发现,一对有5个共同合作者的科学家,他们再次合作的可能性是只有2个共同合作者的科学家的2倍,是没有共同合作者的科学家的200倍。由此启发,我们向msn的路由机制中引入“圈子相似度”这一社交度量。
稳定连接:每个节点记录和其它节点的相遇情况,若节点a与节点b的一次连接时间t大于等于阈值δ3,我们则认为节点a与节点b的本次连接是稳定的。
朋友圈:和节点u具有稳定连接的节点的集合称为节点u的朋友圈。
我们称节点u和节点v的朋友圈中相同节点的个数与节点u、节点v的朋友圈中节点个数最大值的比值为圈子相似度,可表示为:
其中,c(u)和c(v)分别表示节点u和v的朋友圈。我们认为它们的圈子相似度越大,表示将来彼此相遇的机会越大,因而在路由选择时,我们会更倾向于选择与目的节点圈子相似度较高的节点作为中继节点。
全局流行度(gp)与区内流行度(ip):
相遇频繁度(fre):相遇频繁度分为全局相遇频繁度freg和区内相遇频繁度frei。若节点u与节点v不属于同一社区,设freg(u,v)为节点u对节点v的全局相遇频繁度,则可表示为:
若节点u'与节点v'属于同一社区,设frei(u',v')为节点u'对节点v'的区内相遇频繁度,则可表示为:
其中,函数f表示两个节点在一个时间片内的相遇次数;nsg(u)为在整个网络范围内与节点u相遇的节点集合;nsi(u')为与u'相遇的社区内节点的集合。
相遇稳定性(sta):节点间的相遇稳定性包括相遇持续时间稳定性sta1和相遇间隔时间稳定性sta2。假设在某一时间片内,节点u与节点v总共相遇ω次(ω≥2),并设第i次相遇的时间长度为tli,第i次与第i+1次相遇的时间间隔为tgi。
计算出节点u与节点v的相遇持续时间的均值为
计算出节点u与节点v的相遇间隔时间的均值为
则我们定义节点u与节点v的相遇持续时间稳定性
定义节点u与节点v的相遇间隔时间稳定性
其中,相遇持续时间次数为0时,规定节点u与节点v的相遇持续时间稳定性sta1(u,v)=1;相遇间隔时间次数为0时,规定节点u与节点v的相遇间隔时间稳定性sta2(u,v)=1。
从而得出节点u与节点v的相遇稳定性
sta(u,v)=α1*sta1(u,v)+α2*sta2(u,v)
其中,α1,α2为满足0<α1,α2<1且α1+α2=1的常数
综合考虑相遇频繁度和相遇稳定性,我们定义节点u与节点v的全局关系密切度
rcg(u,v)=β1*freg(u,v)+β2*sta(u,v)
继而,我们定义节点u的全局流行度为节点u与网络中其它节点全局关系密切度的平均值,可表示为
其中,β1,β2为满足0<β1,β2<1且β1+β2=1的常数,n1为整个网络的节点数。
我们定义节点u'与节点v'的区内关系密切度
rci(u',v')=γ1*frel(u',v')+γ2*sta(u',v')
继而,我们定义节点u'的区内流行度为节点u'与社区内其它节点区内关系密切度的平均值,可表示为
其中,γ1,γ2为满足0<γ1,γ2<1且γ1+γ2=1的常数,n2为社区内的节点数。
(3)稀疏模式路由机制
稀疏网络中,节点相对较少,节点间的通信链路很难建立,若采用经典的bubblerap算法进行路由,则投递率相对较低。我们对经典的bubblerap算法进行改进,增加了“圈子相似度”这一社交度量,从中心度相对较低的节点中,选择与目的节点具有更高圈子相似度的节点也作为中继节点,从而提高传递速率。另外,我们对bubblerap算法中的全局中心度和局部中心度重新进行了设计,并改名为全局流行度和区内流行度,用以提升算法的性能。虽然引入“圈子相似度”这一社交度量增加了网络开销,但因为稀疏网络中路由开销原本就相对较小,所以增加的开销并不影响路由性能。
当一个节点要给另一个节点发送消息时(假设发送节点与目标节点不位于同一个社区),若相遇节点是目标节点或与目标节点位于同一社区,则把消息发送给相遇节点。否则,它首先把消息发送给任意一个相遇的且全局流行度大于自身的节点,或与目标节点圈子相似度更大的节点,其它节点也做相同操作,直到消息被传输到目标节点或与目标节点同一社区的节点中。当消息被传输到目标节点所在的社区后,具有消息的节点把消息发送给任意一个相遇的且区内流行度大于自身的节点,或与目标节点圈子相似度更大的节点,直到消息最终到达目标节点。在路由过程中,节点可能无法通过本地信息确定下一跳,此时节点需要询问sdn控制器。
3、密集模式路由机制;
(1)基于so的社区发现算法
不同于稀疏网络中基于聚类的社区发现算法,基于so的社区发现算法把社区发现问题看成一个优化问题,从而可以获得更好的社区划分效果,更适用于密集网络。
优化目标
模块度q也称为模块化度量值,是目前常用的一种衡量社区划分好坏的评价指标,最早由marknewman提出,但模块度只能评价非重叠社区的划分结果,对于重叠社区的评价,本文选择了拓展的模块度eq,公式如下:
其中,δ(i,j)是克罗内克函数,当δ(i,j)=1时表示节点i和j在同一个社区内,否则δ(i,j)=0表示节点i和j不在同一社区内。aij表示邻接矩阵的值,aij=1表示节点i和节点j之间存在连边,aij=0表示节点i和节点j之间不存在连边,αi为节点i所属的社区个数,ki是节点i的度数,2m是所有节点的度数之和。eq取值越大说明社区划分越好。
编码方法,假设每个节点最多可以属于m个社区,则为每个节点划分m个编码位置,所以每头“羊”一共需要节点数乘以m个编码位置空间。这种编码方案的缺点是在编码之前需要指定社区数和节点可同时属于的最大社区数,而且所需空间与节点可同时属于的最大社区数相关,但是由于可直接得到社区划分结果,在计算扩展的模块度时十分方便,所以本文采取这种编码方法来实现基于so的社区发现算法。
“羊”中的每个编码位置是可以在一定的连续范围内取值的,但社区号是离散的,这就需要对连续数据到离散数据进行映射,本文将区间[u-0.5,u+0.5)映射到社区u,假设要把网络划分为n个社区,则编码的取值范围为[0.5,n+0.5)。下表是一个编码示例,其中,节点1属于1号社区和2号社区,节点2属于2号社区和3号社区。
算法描述,初始时刻,由于缺乏历史信息,我们没有任何依据对节点划分社区,所以我们采取随机划分的策略,即“羊”中的每个编码位置都在编码范围内随机取一个值。基于so的社区发现算法包括头羊引领、羊群互动、牧羊犬监督三个阶段,下面分别给出这三个阶段的算法描述。
头羊引领,每只羊向头羊移动的行为对应全局探索机制,为保证搜索性能,只有在移动后的性能变好才更新,否则放弃本次更新。
算法1.头羊引领算法.
算法1中的xold和xnew分别表示执行头羊引领前与后的羊群,xbellwether表示头羊,
羊群互动
羊群互动行为对应局部开发机制,每只羊xi会与随机选定的另外一只羊xj进行互动策略,如果xi优于xj,则xj靠近xi,xi远离xj;否则,执行相反操作。同样为保证搜索性能,在两只羊互动后,比较执行前后的值,如果变好则更新,否则放弃本次更新。
算法2.羊群互动算法.
算法2中的xold和xnew分别表示执行羊群互动前与后的羊群,line3-9表示两只羊之间性能较差的一只羊向性能较好的一只羊移动,line10-15表示如果移动后性能没有变好,则不更新。
牧羊犬监督
当羊群陷入某个局部优化解,即本代头羊与上一代头羊的差值小于一个阈值时,牧羊犬监督机制被引入以引导部分羊随机重置来跳出局部优化。
算法3.牧羊犬监督算法.
算法3中的xold和xnew分别表示执行牧羊犬监督前与后的羊群,;line1-9表示如果头羊差小于阈值,除领头羊外的每只羊都按重置概率被牧羊犬放牧,即重新被初始化;line10-17表示对于没有被放牧即没有被重新初始化的每只羊,随机选择一只被放牧后的羊
基于so的社区发现算法流程
step1.初始化划分的社区;
step2.while算法终止条件不满足/*未满足阈值或未达到最大迭代次数*/
根据算法1执行头羊引领过程;
根据算法2执行羊群互动过程;
根据算法3执行牧羊犬监督过程;
endwhile
step3.输出社区划分结果。
(2)社交度量;
密集模式路由机制涉及3个社交度量,分别为社区密切度、区外流行度及区内流行度,其中,区内流行度和稀疏模式路由机制的区内流行度是相同的。下面将对社区密切度和区外流行度这两个社交度量进行介绍。
在密集网络中,我们对相遇频繁度进行扩展,定义了区外相遇频繁度freo,节点u对节点v的区外相遇频繁度如下:
其中,nso(u)为与u相遇的社区外节点的集合。
继而,我们定义节点u与节点v的区外关系密切度为相遇稳定性(即稀疏模式路由机制中的相遇稳定性)与区外相遇频繁度的加权和
rco(u,v)=α1*freo(u,v)+α2*sta(u,v)
定义节点u的区外流行度为节点u与社区外其它节点区外关系密切度的平均值。
其中,n为网络中节点的总数,n(cou)为节点u所在社区中节点的个数。
我们对相遇频繁度进行扩展,定义区间相遇频繁度freb,节点u对节点v的区间相遇频繁度如下:
其中,nsi(v’)为与u’相遇的v’所在社区中节点的集合,nsi(u’)为与v’相遇的u’所在社区中节点的集合。
继而,我们定义节点u’与节点v’的区间关系密切度为相遇稳定性(即稀疏模式路由机制中的相遇稳定性)与区间相遇频繁度的加权和
rcb(u',v')=α1*freb(u',v')+α2*sta(u',v')
所以,我们定义社区co1和社区co2社区密切度cc如下:
其中,n(co1)和n(co2)分别为社区1和社区2的节点个数。特殊的,我们定义同一社区间的社区密切度为1。
(3)密集模式路由机制;
在bubblerap算法中,消息都是通过高中心度的节点进行传递的,但节点的电量和存储空间是有限的,尤其是在密集网络中,消息传输量大,通过高中心度的的节点进行路由的特点无疑成为了一个瓶颈,极大地影响了路由性能。这里我们再次对bubblerap进行改进,使社区作为一个整体参与路由,引入“社区密切度”的概念,从而在一定程度上解决了上述问题。
假定发送节点与目标节点不在同一社区,若相遇节点为目标节点,则把消息传递给目标节点。否则,若发送节点与相遇节点位于同一社区且相遇节点的区外流行度更大,则把消息传递给相遇节点;若发送节点与相遇节点不位于同一社区且相遇节点所在社区与目标社区的社区密切度更大,则也把消息传递给相遇节点。其中,社区密切度的优先级要高于区外流行度。当消息到达目标社区,消息将沿着区内流行度更大的方向进行传递,直到消息被传递至目标节点。在路由过程中,节点可能无法通过本地信息确定下一跳,此时节点需要询问sdn控制器。
4、判别机制;
网络中节点的个数是随时间变化的,如白天节点数较多,晚间节点数较少。所以需要在sdn控制器上运行一个判别机制,当网络中节点数较少时,采用稀疏模式路由机制;当网络中节点数较多时,采用密集模式路由机制。
本文借鉴图论中稀疏图和密集图的概念,设计出了判别机制。下面先介绍图论中的一些相关概念。
大o表示法:设对一切非负的整数n有一个非负函数f(n),如果存在一个整数n0和一个正常数c,且对任意的n>=n0有f(n)<=cg(n),那么就说“f(n)是g(n)的大o表示”,记为f(n)=o(g(n))。如f(n)=7*n+98,存在c=1,n0=14,对于任意的n>=n0,f(n)<=cn*n,故f(n)=o(n*n)。
ω表示法:设对一切非负的整数n有一个非负函数f(n),如果存在一个整数n0和一个正常数c,且对任意的n>=n0有f(n)>=cg(n),那么就说“f(n)是g(n)的ω表示”,记为f(n)=ω(g(n))。如f(n)=2n*n-16n+64,存在c=1,n0=0,对于任意的n>=n0,f(n)>=cn*n,故f(n)=ω(n*n)。
θ表示法:设对一切非负的整数n有一个非负函数f(n),当且仅当f(n)既是o(g(n))又是ω(g(n))时,才说“f(n)是g(n)的θ表示”,记为f(n)=θ(g(n))。如f(n)=3n*n+4*n+3为o(n*n),也为ω(n*n),所以f(n)=θ(n*n)
设网络中ap数为n(ap),节点数为n(node)。当n(node)=o(n(ap))时,sdn控制器判定此时的网络为稀疏网络,需要采用稀疏模式路由机制;当n(node)=θ(n(ap)*n(ap))时,sdn控制器判定此时的网络为密集网络,需要采用密集模式路由机制。
- 还没有人留言评论。精彩留言会获得点赞!