一种基于hadoop的自动数据均衡方法及工具与流程
本发明公开一种基于hadoop的自动数据均衡方法及工具,涉及软件信息技术领域。
背景技术:
hadoop是一个由apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。hdfs有高容错性的特点,并且设计用来部署在低廉的硬件上。
在hadoop集群中,当有新节点增加或者删除原有节点时,如果不启用数据均衡服务(负载均衡),则会造成数据在集群中分布不均匀。由此导致无法有效的利用mr本地化计算的优势,通俗来说就是a节点上运行的map任务所需数据不在a节点上,而到了b节点上,从而需要跨节点进行数据读取,造成了网络带宽的不必要消耗。本发明提供一种基于hadoop的自动数据均衡方法及工具,引入数据均衡机制,数据平衡自动检测并执行,同时提高参数优化效率和执行效率,达到集群中数据的均匀分布的目的。
技术实现要素:
本发明针对现有技术的问题,提供一种基于hadoop的自动数据均衡方法及工具,本发明提出的具体方案是:
一种基于hadoop的自动数据均衡方法,通过java应用程序调取hadoopapi,获取各数据节点磁盘使用率,计算各数据节点磁盘使用率的标准差,实时与预先设置的启动数据均衡脚本的启动阈值比较,当前标准差大于启动阈值,通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数,再通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度。
所述的方法中具体步骤为:
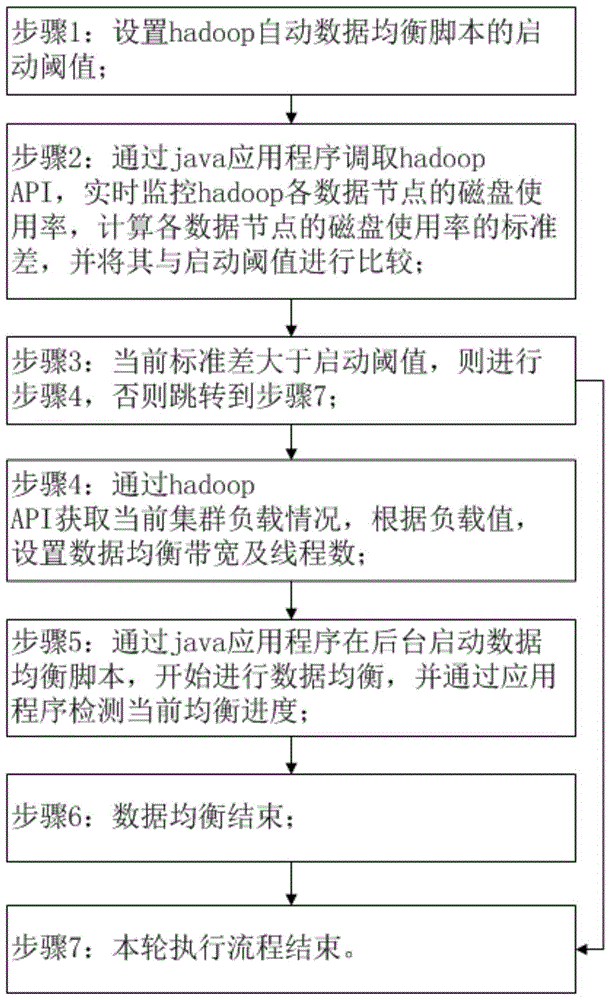
步骤1:设置hadoop自动数据均衡脚本的启动阈值;
步骤2:通过java应用程序调取hadoopapi,实时监控hadoop各数据节点的磁盘使用率,计算各数据节点的磁盘使用率的标准差,并将其与启动阈值进行比较;
步骤3:当前标准差大于启动阈值,则进行步骤4,否则跳转到步骤7;
步骤4:通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数;
步骤5:通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度;
步骤6:数据均衡结束;
步骤7:本轮执行流程结束。
所述的方法中步骤4中当负载值n大于等于1.5时,设置数据均衡带宽为机器最大带宽/10,设置线程数为1000/10。
所述的方法中步骤4中当负载值n大于等于1时,设置数据均衡带宽为机器最大带宽/2n、线程数为1000/2n。
所述的方法中步骤4中当负载值小于1时,设置数据均衡带宽为机器最大带宽、线程数为1000。
一种基于hadoop的自动数据均衡工具,包括调取单元、计算单元、分析单元、设置单元及启动单元,各个单元之间通信连接,
调取单元通过java应用程序调取hadoopapi,获取各数据节点磁盘使用率,
计算单元计算各数据节点磁盘使用率的标准差,
分析单元实时与预先设置的启动数据均衡脚本的启动阈值比较,若当前标准差大于启动阈值,设置单元通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数,
启动单元再通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度。
所述的工具中当负载值n大于等于1.5时,设置单元设置数据均衡带宽为机器最大带宽/10,设置线程数为1000/10。
所述的工具中当负载值n大于等于1时,设置单元设置数据均衡带宽为机器最大带宽/2n、线程数为1000/2n。
所述的工具中当负载值小于1时,设置单元设置数据均衡带宽为机器最大带宽、线程数为1000。
本发明的有益之处是:
本发明提供一种基于hadoop的自动数据均衡方法及工具,通过java应用程序调取hadoopapi,获取各数据节点磁盘使用率,计算各数据节点磁盘使用率的标准差,实时与预先设置的启动数据均衡脚本的启动阈值比较,当前标准差大于启动阈值,通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数,再通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度。相对于hadoop自带数据均衡工具,本发明自动化运行,设置好阈值并启动应用之后,无需干预,应用程序会自主检测并运行,从而减少了人工运维成本;并且数据均衡更合理,数据均衡前通过判断集群负载合理使用数据均衡参数,既保证了数据均衡的性能,有不对当前集群的其他应用产生影响。
附图说明
图1是本发明方法流程示意图。
具体实施方式
本发明提供一种基于hadoop的自动数据均衡方法,通过java应用程序调取hadoopapi,获取各数据节点磁盘使用率,计算各数据节点磁盘使用率的标准差,实时与预先设置的启动数据均衡脚本的启动阈值比较,当前标准差大于启动阈值,通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数,再通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度。
同时提供与上述方法相对应的一种基于hadoop的自动数据均衡工具,包括调取单元、计算单元、分析单元、设置单元及启动单元,各个单元之间通信连接,
调取单元通过java应用程序调取hadoopapi,获取各数据节点磁盘使用率,
计算单元计算各数据节点磁盘使用率的标准差,
分析单元实时与预先设置的启动数据均衡脚本的启动阈值比较,若当前标准差大于启动阈值,设置单元通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数,
启动单元再通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度。
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
利用本发明方法或工具,对hadoop的数据进行均衡,具体步骤为:
步骤1:设置hadoop自动数据均衡脚本的启动阈值,可根据使用情况进行设置,比如预先设置阈值为5%,表示集群各节点使用率超过该阈值时则触发自动均衡;
步骤2:通过java应用程序调取hadoopapi,实时监控hadoop各数据节点的磁盘使用率,实时监控周期可默认为1小时一次,或者根据使用情况进行设置,计算各数据节点的磁盘使用率的标准差,并将其与启动阈值进行比较;
步骤3:当前标准差大于启动阈值,则进行步骤4,否则跳转到步骤7;
步骤4:通过hadoopapi获取当前集群负载情况,根据负载值,设置数据均衡带宽及线程数,
当负载值n大于等于1.5时,设置数据均衡带宽为机器最大带宽/10,设置线程数为1000/10,
当负载值n大于等于1时,设置数据均衡带宽为机器最大带宽/2n、线程数为1000/2n,
当负载值小于1时,设置数据均衡带宽为机器最大带宽、线程数为1000;
步骤5:通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度;
步骤6:数据均衡结束;
步骤7:本轮执行流程结束。
当利用本发明工具进行数据均衡时,可按照本发明方法的步骤进行,如下:
步骤1:设置单元设置hadoop自动数据均衡脚本的启动阈值,可根据使用情况进行设置,比如预先设置阈值为5%,表示集群各节点使用率超过该阈值时则触发自动均衡;
步骤2:调取单元通过java应用程序调取hadoopapi,实时监控hadoop各数据节点的磁盘使用率,实时监控周期可默认为1小时一次,或者根据使用情况进行设置,计算单元计算各数据节点的磁盘使用率的标准差,分析单元将标准差与启动阈值进行比较;
步骤3:分析单元分析前标准差大于启动阈值,则进行步骤4,否则跳转到步骤7;
步骤4:调取单元通过hadoopapi获取当前集群负载情况,设置单元根据负载值,设置数据均衡带宽及线程数,
当负载值n大于等于1.5时,设置单元设置数据均衡带宽为机器最大带宽/10,设置线程数为1000/10,
当负载值n大于等于1时,设置单元设置数据均衡带宽为机器最大带宽/2n、线程数为1000/2n,
当负载值小于1时,设置单元设置数据均衡带宽为机器最大带宽、线程数为1000;
步骤5:启动单元通过java应用程序在后台启动数据均衡脚本,开始进行数据均衡,并通过应用程序检测当前均衡进度;
步骤6:数据均衡结束;
步骤7:本轮执行流程结束。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!