一种基于历史信息的失联车辆位置预测方法和系统与流程
本发明涉及信息处理技术领域,具体涉及一种基于历史信息的失联车辆位置预测方法和系统。
背景技术:
汽车作为一种便利的交通工具,已经成为人们日常生活中不可或缺的出行方式。现实生活中,无论是开私家车出行,还是租车或是打车,都已变得很普遍。目前,大多数汽车都装有定位装置,通过该定位装置能够实现用户对该车辆所在位置的实时跟踪。私家车车主和汽车租赁商家,能够通过车辆内的定位装置知晓车辆所在位置,及时找到丢失车辆;对于打车用户,能够通过车辆内的定位装置知晓自身所在位置,并将该位置分享给家人和朋友,以更好的保证打车用户人身安全。、
汽车内的定位装置大多是采用gps定位系统或北斗定位系统,该系统的正常运行需要有良好的卫星通讯网络做保障。当车辆行驶入通讯网络信号差的位置,或是车辆内的定位装置被不法分子破坏后,远程端则不能知晓车辆所在位置,这就为失联车辆的找回造成困难,也严重影响着打车用户的人身安全。
当车辆失联后,需要对失联车辆所在位置进行预测。现有的位置预测方法,有如下几个局限性:
1)gps记录的轨迹信息过于粗糙,往往丢失了大量可能的预测结果;
2)对位置预测相关的概率模型统计和真实情况误差较大;
3)预测方法仅仅依赖于车辆历史轨迹,缺乏对其它因素的分析,导致定位精度较低;
可见,现有的对于失联车辆的位置预测方法不能充分的满足用户的精准定位需求。
技术实现要素:
有鉴于此,本发明的目的在于克服现有技术的不足,提供一种基于历史信息的失联车辆位置预测方法和系统。
为实现以上目的,本发明采用如下技术方案:一种基于历史信息的失联车辆位置预测方法,包括:
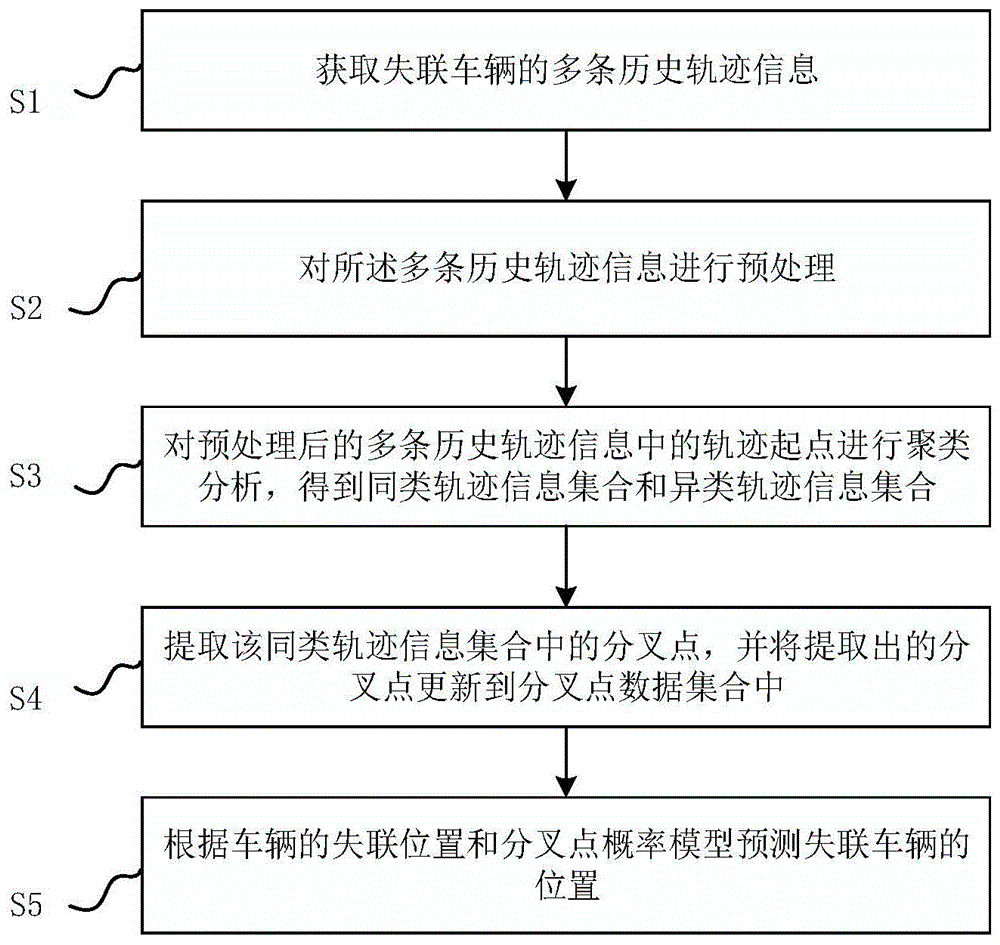
s1:获取失联车辆的多条历史轨迹信息;
s2:对所述多条历史轨迹信息进行预处理;
s3:对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,得到同类轨迹信息集合和异类轨迹信息集合;
s4:提取该同类轨迹信息集合中的分叉点,并将提取出的分叉点更新到分叉点数据集合中;
s5:根据车辆的失联位置和分叉点概率模型预测失联车辆的位置。
可选的,所述车辆的历史轨迹是由按时间先后顺序排列的多个轨迹点组成的;
所述车辆的历史轨迹信息包括多个轨迹点的基本信息,每个轨迹点的基本信息均包括:该轨迹点所对应的经度、纬度、时间点和车辆行驶速度。
可选的,所述对所述多条历史轨迹信息进行预处理,包括:
查找轨迹信息中的异常点,并对所述异常点进行修正。
可选的,所述查找轨迹信息中的异常点,并对所述异常点进行修正,包括:
查找轨迹信息中的异常点,移除该异常点,并通过插值算法,插入合理的轨迹点;
具体的,在一条行驶轨迹s上依次取出两个点pi=(xi,yi,vi,ti)和pi+1=(xi+1,yi+1,vi+1,ti+1),其中i=1,2,3……n,n表示这条轨迹上总的轨迹点数量;
根据式(1)计算两点之间的距离δdi,i+1,并通过式(2)计算从pi点出发经过时间δt=ti+1-ti,可能行驶的一个路程区间δri;
δri=[min(vi,vi+1)×δt,max(vi,vi+1)×δt]式(2)
如果δdi,i+1不在δri的范围内,则判断pi+1是异常点,剔除pi+1并选其后面pi+2作为pi的下一节点,再重复上面的计算,此时
如果δdi,i+2在δri区间内,则认为pi+2点位置正常,再根据式(3),修正pi+1点的位置;
其中j表示点pi后第j个点,当前j=2;
更新pi+1点位置信息,并继续向后依次计算<pi+2,pi+3>、<pi+3,pi+4>、<pi+4,pi+5>……,最后将处理后的数据,保存为历史轨迹s信息。
可选的,所述对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,包括:
对多个历史轨迹起点进行相似度分析,将起点位置信息相似的归为一类;
具体的,多条历史轨迹数据集合记为s={s1,s2,s3,......,sn},其中sn表示第n条轨迹,取出各个轨迹的起点位置信息作为一个新的集合记做
先任取p中两点,并根据式(4),计算
设置相似阈值threshold;
若
同时根据式(5)计算同类起点轨迹的平均点,遍历整个历史轨迹信息,和同类轨迹的起点平均值做相似度分析,每次有新的起点加入,更新其平均值;
最后得到若干个起点相似的轨迹点集合,
pm类的起始点位置为
最后将同类的轨迹信息存入同类轨迹信息集合,将非同类的轨迹信息存入异类轨迹信息集合。
可选的,所述提取该同类轨迹信息集合中的分叉点,包括:
当s={s1,s3,s6,......,sn}是同类轨迹时,任意选出其中两条轨迹si和sj,si={(xi,1,yi,1),(xi,2,yi,2),(xi,3,yi,3),…,(xi,n,yi,n)},和sj={(xj,1,yj,1),(xj,2,yj,2),(xj,3,yj,3)......(xj,n,yj,n)};
分别从si和sj中按时间顺序取出一个点,假设从轨迹si中取第m个轨迹点si,m=(xi,m,yi,m),从轨迹sj中取第n个轨迹点sj,n=(xj,n,yj,n),按式(6)计算两个点之间的距离,按式(7)计算从起始点到m或n点行驶的路程差,按式(8.1)和式(8.1)计算同一条轨迹中相邻两点间的轨迹方程;
将式(8)简化为ax+by+c=0,并根据式(9)计算点sj,n到另外一条轨迹方程的最短路径,
分叉点的选取条件为:
(a)δdim,jn>δd';
(b)δs>δs';
(c)δdmin>δd';
其中δd'为两点是近似点的最大值,δs'为行驶里程差值,δdmin表示一条轨迹上的轨迹点到另外一条轨迹上两点之间轨迹方程的最短路径;
对两条历史行车轨迹si和sj交叉点的选取过程如下:依次取出si中第m个点和sj中的第n个点,其中m,n=1,2,3,4……m≠n,做上面计算;
如果不满足选取条件(a),则m和n依次向后移动一位;若满足选取条件(a),但不满足选取条件(b),且δs>=10,则将si的第m个点和sj的第n+1个点重复上面比较;若也满足条件(b),此时m和n点可能是轨迹si和sj的交叉点;再进行第三步判断,判断sj第n个点位置到si第m点所在轨迹方程的最小距离是否大于δd',若满足,将第m点标记为si轨迹分叉点,将n点标记为sj轨迹分叉点;且m和n点位置在以后的计算分叉点中,每当有轨迹经过该分叉点,都记录一次数据;
再在同类轨迹信息集合中,每两条轨迹进行如上操作,最后更新出同类轨迹的分叉点数据集合。
可选的,所述根据车辆的失联位置和分叉点概率模型预测失联车辆的位置,包括:
当车辆在位置p点失联,以车辆最后被记录的行驶速度v来进行位置预测:
经过一段时间t,如果车辆经过一个交叉点为a点,假如a点有n个分叉点,根据历史轨迹的统计计算,车辆从第i个分叉点经过的概率是ti/t,其中t表示以往经过当前n个分叉点的总次数,ti表示经过第i个分叉点的次数;则根据该分叉点概率模型预测失联车辆距p点的位置;
行车结束后,更新分叉点概率模型。
可选的,在执行完步骤s5后,还包括:
结合失联车辆的热点数据库对步骤s5预测出的失联车辆的位置进行进一步预测,以得到失联车辆更精确的位置。
可选的,该预测方法还包括:
在失联车辆所在的位置预测结束后,记录该位置信息,并同步更新到失联车辆的热点数据库中。
本发明还提供了一种基于历史信息的失联车辆位置预测系统,包括:
历史轨迹信息获取模块,用于获取失联车辆的多条历史轨迹信息;
预处理模块,用于对所述多条历史轨迹信息进行预处理;
聚类分析模块,用于对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,得到同类轨迹信息集合和异类轨迹信息集合;
分叉点提取模块,用于提取该同类轨迹信息集合中的分叉点,并将提取出的分叉点更新到分叉点数据集合中;
预测模块,用于根据车辆的失联位置和分叉点概率模型预测失联车辆的位置。
本发明采用以上技术方案,所述基于历史信息的失联车辆位置预测方法,包括:s1:获取失联车辆的多条历史轨迹信息;s2:对所述多条历史轨迹信息进行预处理;s3:对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,得到同类轨迹信息集合和异类轨迹信息集合;s4:提取该同类轨迹信息集合中的分叉点,并将提取出的分叉点更新到分叉点数据集合中;s5:根据车辆的失联位置和分叉点概率模型预测失联车辆的位置;本发明所述的预测方法增加了异常轨迹点的剔除和插入算法的预处理操作,通过修正历史轨迹中的异常轨迹点,来提高分叉点统计的准确性;同时对分叉点的提取,新增最小距离算法进行判断,能够提高定位的精确度,从而有利于更加充分的满足用户的精准定位需求。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明失联车辆位置预测方法实施例一提供的流程示意图;
图2是本发明车辆历史轨迹的示意图;
图3是本发明失联车辆位置预测方法中步骤s5所涉及的预测失联车辆的位置的示意图;
图4是本发明失联车辆位置预测方法实施例二提供的流程示意图;
图5是本发明失联车辆位置预测系统的结构示意图。
图中:1、历史轨迹信息获取模块;2、预处理模块;3、聚类分析模块;4、分叉点提取模块;5、预测模块。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
图1是本发明失联车辆位置预测方法实施例一提供的流程示意图。
如图1所示,本实施例所述的位置预测方法包括:
s1:获取失联车辆的多条历史轨迹信息;
进一步的,所述车辆的历史轨迹是由按时间先后顺序排列的多个轨迹点组成的;
所述车辆的历史轨迹信息包括多个轨迹点的基本信息,每个轨迹点的基本信息均包括:该轨迹点所对应的经度、纬度、时间点和车辆行驶速度。
具体的,在一段时间内,车辆的历史轨迹,是由一系列的轨迹点构成的一个集合。每个轨迹点可以简化为pi=(xi,yi,ti,vi);其中xi表示ti时刻汽车的经度,yi表示纬度,vi表示ti时刻的速度。因此一条行车轨迹可以看作是轨迹点按照时间的先后顺序排列的一组有限集合,可以用集合s表示,其中s={(long1,lat1,v1,t1),(long2,lat2,v2,t2),(long3,lat3,v3,t3),......,(longn,latn,vn,tn)}。
s2:对所述多条历史轨迹信息进行预处理;
由于gps定位会受到天气、地形、电磁场等环境干扰,导致定位不准,产生一些异常的位置信息。
进一步的,所述对所述多条历史轨迹信息进行预处理,包括:
查找轨迹信息中的异常点,并对所述异常点进行修正。
进一步的,所述查找轨迹信息中的异常点,并对所述异常点进行修正,包括:
查找轨迹信息中的异常点,移除该异常点,并通过插值算法,插入合理的轨迹点;
具体的,在一条行驶轨迹s上依次取出两个点pi=(xi,yi,vi,ti)和pi+1=(xi+1,yi+1,vi+1,ti+1),其中i=1,2,3……n,n表示这条轨迹上总的轨迹点数量;
根据式(1)计算两点之间的距离δdi,i+1,并通过式(2)计算从pi点出发经过时间δt=ti+1-ti,可能行驶的一个路程区间δri;
δri=[min(vi,vi+1)×δt,max(vi,vi+1)×δt]式(2)
如果δdi,i+1不在δri的范围内,则判断pi+1是异常点,剔除pi+1并选其后面pi+2作为pi的下一节点,再重复上面的计算,此时
如果δdi,i+2在δri区间内,则认为pi+2点位置正常,再根据式(3),修正pi+1点的位置;
其中j表示点pi后第j个点,当前j=2;
更新pi+1点位置信息,并继续向后依次计算<pi+2,pi+3>、<pi+3,pi+4>、<pi+4,pi+5>……,最后将处理后的数据,保存为历史轨迹s信息。
本实施例通过查找轨迹信息中的异常点,并对所述异常点进行修正的预处理操作,能够移除异常的轨迹点,并通过插值算法,插入合理的轨迹点,该处理过程能够提高后续提取分叉点的准确性,从而提高对失联车辆位置预测的准确性。
s3:对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,得到同类轨迹信息集合和异类轨迹信息集合;
进一步的,所述对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,包括:
对多个历史轨迹起点进行相似度分析,将起点位置信息相似的归为一类;
具体的,多条历史轨迹数据集合记为s={s1,s2,s3,......,sn},其中sn表示第n条轨迹,取出各个轨迹的起点位置信息作为一个新的集合记做
先任取p中两点,并根据式(4),计算
设置相似阈值threshold;相似阈值的取值范围为1米-10米。
若
同时根据式(5)计算同类起点轨迹的平均点,遍历整个历史轨迹信息,和同类轨迹的起点平均值做相似度分析,每次有新的起点加入,更新其平均值;
最后得到若干个起点相似的轨迹点集合,
pm类的起始点位置为
最后将同类的轨迹信息存入同类轨迹信息集合,将非同类的轨迹信息存入异类轨迹信息集合。
s4:提取该同类轨迹信息集合中的分叉点,并将提取出的分叉点更新到分叉点数据集合中;
对同类历史轨迹信息进行分叉点提取,分叉点就是一条道路中的分叉路或者是可能会导致目的地不一致的轨迹点。
进一步的,所述提取该同类轨迹信息集合中的分叉点,包括:
当s={s1,s3,s6,......,sn}是同类轨迹时,任意选出其中两条轨迹si和sj,si={(xi,1,yi,1),(xi,2,yi,2),(xi,3,yi,3),…,(xi,n,yi,n)},和sj={(xj,1,yj,1),(xj,2,yj,2),(xj,3,yj,3)......(xj,n,yj,n)};
分别从si和sj中按时间顺序取出一个点,假设从轨迹si中取第m个轨迹点si,m=(xi,m,yi,m),从轨迹sj中取第n个轨迹点sj,n=(xj,n,yj,n),按式(6)计算两个点之间的距离,按式(7)计算从起始点到m或n点行驶的路程差,如图2所示,按式(8.1)和式(8.1)计算同一条轨迹中相邻两点间的轨迹方程;
将式(8)简化为ax+by+c=0,并根据式(9)计算点sj,n到另外一条轨迹方程的最短路径,
分叉点的选取条件为:
(a)δdim,jn>δd';
(b)δs>δs';
(c)δdmin>δd';
其中δd'为两点是近似点的最大值,δs'为行驶里程差值,δdmin表示一条轨迹上的轨迹点到另外一条轨迹上两点之间轨迹方程的最短路径;在实际应用中,δd'一般设置为车道的宽度,取平均值1米-3米;δs'取3米-5米;δdmin的有效范围不超过车道宽度。
对两条历史行车轨迹si和sj交叉点的选取过程如下:依次取出si中第m个点和sj中的第n个点,其中m,n=1,2,3,4……m≠n,做上面计算;
如果不满足选取条件(a),则m和n依次向后移动一位;若满足选取条件(a),但不满足选取条件(b),且δs>=10,则将si的第m个点和sj的第n+1个点重复上面比较;若也满足条件(b),此时m和n点可能是轨迹si和sj的交叉点;再进行第三步判断,判断sj第n个点位置到si第m点所在轨迹方程的最小距离是否大于δd',若满足,将第m点标记为si轨迹分叉点,将n点标记为sj轨迹分叉点;且m和n点位置在以后的计算分叉点中,每当有轨迹经过该分叉点,都记录一次数据;
再在同类轨迹信息集合中,每两条轨迹进行如上操作,最后更新出同类轨迹的分叉点数据集合。
s5:根据车辆的失联位置和分叉点概率模型预测失联车辆的位置。
需要说明的是,对当前行驶车辆进行分析,如果行车起点没有匹配到历史同类轨迹位置起点,那么这次行驶过程不做预测;如果行车起点匹配到历史同类轨迹,那么在车辆行驶的过程中,每经过一次分叉点,按照分叉点统计的分叉点概率模型,来计算每个分叉点的行驶概率,估算车辆可能的行驶路线。
进一步的,所述根据车辆的失联位置和分叉点概率模型预测失联车辆的位置,包括:
当车辆在位置p点失联,以车辆最后被记录的行驶速度v来进行位置预测:
经过一段时间t,如果车辆经过一个交叉点为a点,假如a点有n个分叉点,根据历史轨迹的统计计算,车辆从第i个分叉点经过的概率是ti/t,其中t表示以往经过当前n个分叉点的总次数,ti表示经过第i个分叉点的次数;则根据该分叉点概率模型预测失联车辆距p点的位置;
行车结束后,更新分叉点概率模型。
如图3所示,假如车辆在位置p点失联,以车辆最后被记录的行驶速度v来进行位置预测。当经过时间t,车辆没有到达分叉点a,那么车辆的位置,在p-a段内,预测位置距p点s(其中s=vt)。当车辆经过分叉点a,根据分叉点概率模型,在一定时间内的预测位置距p点s(其中s=vt),车辆走a1的概率是2/17,车辆走a2的概率是12/17,车辆走a3的概率是3/17。
行车结束后,更新数据库中的分叉点概率模型。
若此次行车没有匹配到同类轨迹信息集合中的同类轨迹点,则此次行车轨迹不做判断。
本实施例所述的失联车辆位置预测方法主要应用于车辆的定位系统,该方法能够根据车辆历史轨迹数据,计算出失联车辆最后可能落在的范围,综合评估出失联车辆可能的位置。
本实施例所述的失联车辆位置预测方法增加了异常轨迹点的剔除和插入算法,通过修正历史轨迹中的异常轨迹点,来提高分叉点统计的准确性;同时对分叉点的提取,新增最小距离算法进行判断,能够提高定位的精确度,从而有利于更加充分的满足用户的精准定位需求。
图4是本发明失联车辆位置预测方法实施例二提供的流程示意图。
如图4所示,本实施例所述的位置预测方法包括:
s1:获取失联车辆的多条历史轨迹信息;
s2:对所述多条历史轨迹信息进行预处理;
s3:对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,得到同类轨迹信息集合和异类轨迹信息集合;
s4:提取该同类轨迹信息集合中的分叉点,并将提取出的分叉点更新到分叉点数据集合中;
s5:根据车辆的失联位置和分叉点概率模型预测失联车辆的位置;
s6:结合失联车辆的热点数据库对步骤s5预测出的失联车辆的位置进行进一步预测,以得到失联车辆更精确的位置。
进一步的,该预测方法还包括:
在失联车辆所在的位置预测结束后,记录该位置信息,并同步更新到失联车辆的热点数据库中,以便进行下一次失联车辆位置预测时,使用更新后的热点数据库分析。
本实施例所述的预测方法与实施例一所述的预测方法区别仅在于:本实施在执行完步骤s5后,还能够结合失联车辆的热点数据库对失联车辆的位置进行进一步预测,能够缩小预测范围,提高预测位置的精确度。
具体的,所述失联车辆的热点数据库包括:由于天气、地形、电磁场等环境强烈干扰导致的易发生失联现象的区域,或者是,不法分子进行人为破坏的车辆处理点。
本实施例所述的失联车辆位置预测方法增加了异常轨迹点的剔除和插入算法,通过修正历史轨迹中的异常轨迹点,来提高分叉点统计的准确性;同时对分叉点的提取,新增最小距离算法进行判断,以及将历史轨迹和失联车辆的热点数据相结合,进一步提高了对失联车辆的定位精确度。
图5是本发明失联车辆位置预测系统提供的结构示意图。
如图5所示,本实施例所述的位置预测系统包括:
历史轨迹信息获取模块1,用于获取失联车辆的多条历史轨迹信息;
预处理模块2,用于对所述多条历史轨迹信息进行预处理;
聚类分析模块3,用于对预处理后的多条历史轨迹信息中的轨迹起点进行聚类分析,得到同类轨迹信息集合和异类轨迹信息集合;
分叉点提取模块4,用于提取该同类轨迹信息集合中的分叉点,并将提取出的分叉点更新到分叉点数据集合中;
预测模块5,用于根据车辆的失联位置和分叉点概率模型预测失联车辆的位置。
本实施例所述的失联车辆位置预测系统的工作原理与上文所述的失联车辆位置预测方法的工作原理相同,在此不再赘述。
本实施例所述的失联车辆位置预测系统通过所述预处理模块2对历史轨迹中的异常轨迹点进行修正,提高了分叉点统计的准确性;同时对分叉点的提取,新增最小距离算法进行判断,能够提高定位的精确度,从而有利于更加充分的满足用户的精准定位需求,提高用户体验。
可以理解的是,上述各实施例中相同或相似部分可以相互参考,在一些实施例中未详细说明的内容可以参见其他实施例中相同或相似的内容。
需要说明的是,在本发明的描述中,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是指至少两个。
流程图中或在此以其他方式描述的任何过程或方法描述可以被理解为,表示包括一个或更多个用于实现特定逻辑功能或过程的步骤的可执行指令的代码的模块、片段或部分,并且本发明的优选实施方式的范围包括另外的实现,其中可以不按所示出或讨论的顺序,包括根据所涉及的功能按基本同时的方式或按相反的顺序,来执行功能,这应被本发明的实施例所属技术领域的技术人员所理解。
应当理解,本发明的各部分可以用硬件、软件、固件或它们的组合来实现。在上述实施方式中,多个步骤或方法可以用存储在存储器中且由合适的指令执行系统执行的软件或固件来实现。例如,如果用硬件来实现,和在另一实施方式中一样,可用本领域公知的下列技术中的任一项或他们的组合来实现:具有用于对数据信号实现逻辑功能的逻辑门电路的离散逻辑电路,具有合适的组合逻辑门电路的专用集成电路,可编程门阵列(pga),现场可编程门阵列(fpga)等。
本技术领域的普通技术人员可以理解实现上述实施例方法携带的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,该程序在执行时,包括方法实施例的步骤之一或其组合。
此外,在本发明各个实施例中的各功能单元可以集成在一个处理模块中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,也可以存储在一个计算机可读取存储介质中。
上述提到的存储介质可以是只读存储器,磁盘或光盘等。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!