利用结合视频描述的分层自注意力网络总结视频的方法与流程
本发明涉及视频总结任务,尤其涉及一种利用结合视频描述的分层自注意力网络总结视频的方法。
背景技术:
视频总结任务是一项十分有挑战性的任务,目前吸引了很多人的关注。在该任务中需要系统针对于某个特定视频,给出该视频中的关键帧,完成对于该视频的总结任务。目前视频总结任务的研究仍处于探索阶段。对于视频总结任务的研究可以应用于众多领域之中。
目前已有的视频总结任务解决方法一般是关注解决视频总结任务的多样性与代表性问题,对于视频中含有的语义信息关注较少。传统的视频总结任务解决方法,主要是利用手工调节的启发式方法来选取视频中的重要帧或视频的重要片段。这种方法挑出的视频总结片段不能与视频的主题紧密帖合。
为了解决上述问题,本发明利用结合视频描述的分层自注意力网络来解决视频总结任务,提高视频总结任务形成视频摘要总结片段的准确性。
技术实现要素:
本发明的目的在于解决现有技术中的问题,为了克服现有技术对于视频总结任务无法提供较为准确的视频摘要总结片段的问题,本发明提供一种利用结合视频描述的分层自注意力网络总结视频的方法。本发明所采用的具体技术方案是:
利用结合视频描述的分层自注意力网络总结视频的方法,包含如下步骤:
1.设计一种分层自注意力网络模型,利用该分层自注意力网络模型获得视频中所有视频分段的重要程度分数与视频中所有帧的综合重要程度分数。
2.设计一种增强标题生成器模型,利用该增强标题生成器模型结合步骤1中获取的视频中所有视频分段的重要程度分数,获取对于视频的自然语言描述。
3.设计相应梯度函数对步骤2设计的增强标题生成器模型进行训练,将训练后得到的步骤2对应的视频中所有视频帧的综合重要程度分数返回给步骤1设计的分层自注意力网络模型,设计损失函数对步骤1设计的分层自注意力网络模型进行训练,利用训练出的分层自注意力网络模型获取视频中的重要帧作为视频总结任务的结果。
上述步骤可具体采用如下实现方式:
对于视频总结任务的视频帧,利用训练好的resnet网络获取视频中的帧表达特征
将视频分段sk中含有的视频帧表达
f(oi,oj)=p(f)tanh([w1oi+w2oj+b])
其中,p(f)、w1、w2为可训练的参数矩阵,b为可训练的偏置向量。利用如上公式,对视频分段sk所有视频帧的卷积输出表达两两计算获得相关度向量,得到相关度矩阵
对视频分段sk中的第i帧与第j帧,按照如下公式计算得到视频分段sk中的第i帧针对于第j帧的注意力分数向量γij,
其中,exp()代表以自然底数e为底数的指数运算。利用得到的视频分段sk中的第i帧针对于第j帧的注意力分数向量γij,按照如下公式计算得到视频分段sk中的第j帧的注意力分数sj,
其中,dc代表视频分段sk中的第i帧针对于第j帧的注意力分数向量γij的维度。
利用如上方法计算获得视频分段sk中所有帧的注意力分数
按照如上方法计算得到视频中所有分段的分段级别表达
其中,p(s)、w1(s)、w2(s)代表可训练的参数矩阵,b(s)代表可训练的偏置向量。利用如上公式,对所有视频分段的卷积输出表达两两计算获得相关度向量,得到视频分段相关度矩阵m(s)。利用得到的视频分段相关度矩阵m(s),分别加上正向位置矩阵mfw与负向位置矩阵mbw,得到正向视频分段相关度矩阵m(s)fw与负向视频分段相关度矩阵m(s)bw,正向位置矩阵mfw与负向位置矩阵mbw的元素
利用得到的正向视频分段相关度矩阵m(s)fw与负向视频分段相关度矩阵m(s)bw,按照如下公式计算得到视频分段sk的视频分段级别正向综合特征
其中,
将得到的视频分段sk的视频分段级别正向综合特征
其中
利用得到的视频中所有视频分段的重要程度分数
其中,wg与wh为可训练的权重矩阵,b(w)为可训练的偏置向量、p(w)为提前设置好的参数向量。利用如上方法计算得到针对于第t次循环所有视频分段的注意力分数
利用得到的针对于第t次循环的上下文向量ct,结合lstm网络第t次循环的状态输出
其中,w1:t-1代表前t-1次循环增强标题生成器模型的输出单词,θ代表增强标题生成器模型的所有参数集合。
利用如下公式作为增强标题生成器模型的梯度函数,
其中qt为第t次循环对应的预测回报函数,按照如下公式计算,
其中n代表视频中含有的视频帧个数,函数r()代表按照bleu函数计算增强标题生成器模型生成的输出单词与视频对应的描述文本单词之间的差别大小。
按照如上计算公式作为增强标题生成器模型的梯度函数,对于增强标题生成器模型进行训练,将训练后的增强标题生成器模型对应的视频中所有视频帧的综合重要程度分数返回给分层自注意力网络模型,利用返回的视频中所有视频帧的综合重要程度分数
利用如上公式对于分层自注意力网络模型进行梯度下降训练,利用训练好的分层自注意力网络模型输出视频中所有视频帧的综合重要程度分数,将综合重要程度分数高的视频帧取出作为视频总结任务的结果。
附图说明
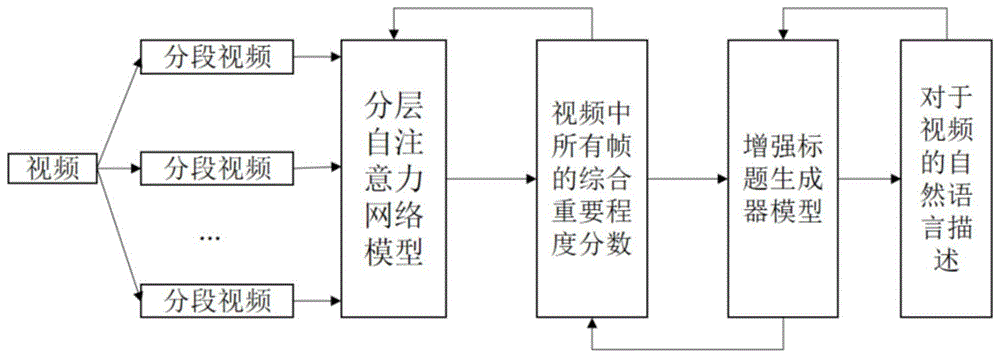
图1是根据本发明的一实施例的用于解决视频总结任务的结合视频描述的分层自注意力网络的整体示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
如图1所示,本发明利用结合视频描述的分层自注意力网络总结视频的方法包括如下步骤:
1)设计一种分层自注意力网络模型,利用该分层自注意力网络模型获得视频中所有视频分段的重要程度分数与视频中所有帧的综合重要程度分数;
2)设计一种增强标题生成器模型,利用该增强标题生成器模型结合步骤1)中获取的视频中所有视频分段的重要程度分数,获取对于视频的自然语言描述;
3)设计相应梯度函数对步骤2)设计的增强标题生成器模型进行训练,将训练后得到的步骤2)对应的视频中所有视频帧的综合重要程度分数返回给步骤1)设计的分层自注意力网络模型,设计损失函数对步骤1)设计的分层自注意力网络模型进行训练,利用训练出的分层自注意力网络模型获取视频中的重要帧作为视频总结任务的结果。
所述步骤1),其具体步骤为:
对于视频总结任务的视频帧,利用训练好的resnet网络获取视频中的帧表达特征
将视频分段sk中含有的视频帧表达
f(oi,oj)=p(f)tanh([w1oi+w2oj+b])
其中,p(f)、w1、w2为可训练的参数矩阵,b为可训练的偏置向量。利用如上公式,对视频分段sk所有视频帧的卷积输出表达两两计算获得相关度向量,得到相关度矩阵
对视频分段sk中的第i帧与第j帧,按照如下公式计算得到视频分段sk中的第i帧针对于第j帧的注意力分数向量γij,
其中,exp()代表以自然底数e为底数的指数运算。利用得到的视频分段sk中的第i帧针对于第j帧的注意力分数向量γij,按照如下公式计算得到视频分段sk中的第j帧的注意力分数sj,
其中,dc代表视频分段sk中的第i帧针对于第j帧的注意力分数向量γij的维度。
利用如上方法计算获得视频分段sk中所有帧的注意力分数
按照如上方法计算得到视频中所有分段的分段级别表达
其中,p(s)、w1(s)、w2(s)代表可训练的参数矩阵,b(s)代表可训练的偏置向量。利用如上公式,对所有视频分段的卷积输出表达两两计算获得相关度向量,得到视频分段相关度矩阵m(s)。利用得到的视频分段相关度矩阵m(s),分别加上正向位置矩阵mfw与负向位置矩阵mbw,得到正向视频分段相关度矩阵m(s)fw与负向视频分段相关度矩阵m(s)bw,正向位置矩阵mfw与负向位置矩阵mbw的元素
利用得到的正向视频分段相关度矩阵m(s)fw与负向视频分段相关度矩阵m(s)bw,按照如下公式计算得到视频分段sk的视频分段级别正向综合特征
其中,
将得到的视频分段sk的视频分段级别正向综合特征
其中
所述步骤2),其具体步骤为:
利用得到的视频中所有视频分段的重要程度分数
其中,wg与wh为可训练的权重矩阵,b(w)为可训练的偏置向量、p(w)为提前设置好的参数向量。利用如上方法计算得到针对于第t次循环所有视频分段的注意力分数
利用得到的针对于第t次循环的上下文向量ct,结合lstm网络第t次循环的状态输出
其中,w1:t-1代表前t-1次循环增强标题生成器模型的输出单词,θ代表增强标题生成器模型的所有参数集合。
所述步骤3),其具体步骤为:
利用如下公式作为增强标题生成器模型的梯度函数,
其中qt为第t次循环对应的预测回报函数,按照如下公式计算,
其中n代表视频中含有的视频帧个数,函数r()代表按照bleu函数计算增强标题生成器模型生成的输出单词与视频对应的描述文本单词之间的差别大小。
按照如上计算公式作为增强标题生成器模型的梯度函数,对于增强标题生成器模型进行训练,将训练后的增强标题生成器模型对应的视频中所有视频帧的综合重要程度分数返回给分层自注意力网络模型,利用返回的视频中所有视频帧的综合重要程度分数
利用如上公式对于分层自注意力网络模型进行梯度下降训练,利用训练好的分层自注意力网络模型输出视频中所有视频帧的综合重要程度分数,将综合重要程度分数高的视频帧取出作为视频总结任务的结果。
下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。
实施例
本发明在activitynet实验数据集上进行训练,在summe实验数据集与tvsum实验数据集上进行测试实验。为了客观地评价本发明的算法的性能,本发明在所选出的测试集中,分别采用了无监督的方法与有监督的方法来对于本发明的效果进行评价,并且针对于无监督的方法与有监督的方法均采用f分数的评价标准来对于本发明的效果进行评价。按照具体实施方式中描述的步骤,所得的实验结果如表1-2所示,本方法表示为hsan:
表1本发明针对于无监督方法的测试结果
表2本发明针对于有监督方法的测试结果。
- 还没有人留言评论。精彩留言会获得点赞!