一种雾计算环境下数据安全去重系统及方法、云存储平台与流程
本发明属于云存储技术领域,尤其涉及一种雾计算环境下数据安全去重系统及方法、云存储平台。
背景技术:
目前,业内常用的现有技术是这样的:随着云计算的发展,越来越多的用户更青睐于将数据存放在云服务器上而不是在本地端,国际数据中心(internationaldatacenter,idc)的一份报告指出,2013年,全球一年新产生的数据量为4.4zb,而2017年,全球一年新产生的数据量激增至15.2zb,预计至2020年,全球每年新产生的数据量将达到40zb,这无疑给云服务器带来了极大的负担。而idc的另一份报告指出,全球每年产生的数据量中,有75%的数据是重复的,这严重损害了云服务器的存储效率以及通信开销,删除这些冗余数据可以为极大地优化云计算的存储效率。除此之外,每年因数据泄露而引发的安全问题也层出不穷。根据云安全联盟(cloudsecurityalliance,csa)最新的研究成果表明,在云计算遭受的所有安全威胁中,数据泄露排名首位。2011年,谷歌邮箱遭到泄露,15万用户受损,许多用户的数据永久被删除,部分用户账户被重置。2013年,雅虎用户数据持续遭到泄露,直到2016年,该问题才被解决,据雅虎统计,大约有10亿用户遭到不同程度的影响。2018年,facebook陷入数据泄露丑门事件,剑桥分析公司(cambridgeanalytica)通过一款应用程序获取了facebook五千万用户的个人数据,而facebook宣称,实际受损的用户远不止五千万。据不完全统计显示,一些大型企业平均每年因数据泄露的损失高达380万美元。因此,数据安全问题需要我们给予高度的重视。云计算的发展虽然极大的缓解了本地设备的存储开销与计算压力。然而,随着云服务器上用户数量的急剧增多,云服务器中心化服务的一些缺点也逐渐显露出来。首先,由于云服务器远离用户,因此延迟较高;其次,在云服务器使用的高峰期,容易发生网络拥塞事件,这使得用户体验极为不佳;最后,由于云计算集中处理数据,云服务器的故障很有可能导致整个网络的瘫痪。这些问题成为了云计算发展的瓶颈。2011年,思科针对云计算目前存在的一些问题,在微云(cloudlets)以及边缘计算(edgecomputing)的基础上,提出了一种新型的网络计算范式——雾计算(fogcomputing)。雾计算主要采用了分布式系统、虚拟化、web2.0等技术,融合了网络、计算、存储、应用等能力。通过将物理上离散的节点连接起来,将数据以及应用程序分散在位于网络边缘的设备中,就近为用户提供相应的服务。与云计算相比,雾计算分布在网络边缘,因此,延迟较低,而且各个雾节点之间相互独立,某一个节点的损坏并不影响其他节点的使用。雾计算的应运而生极大的缓解了云计算所出现的一些问题。
为了解决数据安全的问题,绝大多数云服务提供商采用让用户在客户端先将数据加密,再上传至云服务器的方式解决数据安全问题,但是,由于每个用户所选取的密钥不同,即使相同的数据也会被加密成不同的密文,因此,在密文数据下重复数据无法被删除。消息锁加密(message-lockedencryption,mle),该加密方式保证了相同的明文可以被加密为相同的密文。然而,mle并不具有动态性,如果一个用户的权限被撤销,但是他的mle密钥仍保留在本地端,如果该用户与一些黑客勾结,窃取到密文之后则可以通过采用之前保留的mle密钥解密即获明文数据,这对于云服务器而言是极不安全的。
综上所述,现有技术存在的问题是:加密数据去重与数据更新并不兼容,而且现有的加密数据均只适用于云服务器,因此,现有的方式并没有缓解数据增长带给云服务器的压力,也没有有效的保护用户的数据隐私。
解决上述技术问题的难度:
由于用户密钥选择的随机性,导致相同的明文文件可能被加密为不同的密文文件,除此之外,当某些用户权限被撤销后,为了防止这些用户依旧可以解密数据,需要将密文数据进行更新,传统的更新方式采用重加密技术,然而,对完整的数据进行重加密开销较大。
解决上述技术问题的意义:
既可以保证加密数据安全的存储在云服务器中,又能够实现高效的数据重加密,同时还可以保证被撤销权限的用户不能够正确的解密数据。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种雾计算环境下数据安全去重系统及方法、云存储平台。
本发明是这样实现的,一种雾计算环境下数据安全去重方法,所述雾计算环境下数据安全去重方法包括以下步骤:
第一步,用户在客户端对数据采用mle加密,并采用merkle树生成文件的标签t,并将加密后的文件与文件标签t上传至雾节点;
第二步,雾节点接收数据标签,并检测其是否在数据索引表中;如果是,雾节点将用户的所有权加入数据索引表,否则,进入下一步;
第三步,雾节点从mle密文中任意选取256比特进行重加密,并将256比特选取的位置与重加密的密钥分发给其他雾节点,雾节点将数据标签与用户所有权添加至数据索引表,并将重加密后的数据以及数据标签发送给云服务器;
第四步,云服务器接收到不同雾节点发送的数据,根据雾节点上传的数据标签,判断是否有重复的数据;如果是,只保留其中一份备份,删除其余冗余数据。
进一步,用户在客户端对数据采用mle加密包括:
(1)密钥的产生:输入明文m,采用sha256计算明文的哈希值,得到mle密钥,即hash(m)→k;
(2)采用(1)中所产生的mle密钥对明文m进行aes加密,得到密文c,即enc(m)k→c;
(3)用户对密文c采用merkletree生成哈希值,记为标签t;
(4)用户保留mle密钥k,并将密文c与标签t上传至雾节点。
进一步,用户数据所有权检测:
雾节点将用户上传的标签t与自己所建立的数据索引表中的数据比较,如果t在数据索引表中,雾节点无需接收用户上传的密文c,直接将用户的权限添加至数据索引表中;如果t不在索引表中,雾节点需要对数据执行重加密操作;
密文数据的重加密:
(1)密钥生成:输入安全参数,得到一个随机的加密密钥,称为filekey:gen(1λ)→fk;
(2)重加密:从mle密文c中选取256比特,记为c1,剩余部分记为c2,并采用aes对c1加密,得到stub,即:encfk(c1)→stub;
(3)数据索引表的更新:雾节点将用户数据标签t以及t的所有权用户添加至数据索引表;
(4)数据上传:雾节点将c2封装成trimmedpackage,并将trimmedpackage,stub,以及用户标签t上传至云服务器。雾节点保留随机加密密钥fk;
密文数据的更新:
(1)stub解密:雾节点接收到服务器的更新请求,采用之前保留的fk对stub解密得到c1,即decfk(stub)→c1;
(2)mle密文恢复:将密文c1与trimmedpackage(即c2)拼接,得到mle密文c;
(3)新filekey的生成:输入安全参数,得到一个随机的加密密钥:gen(1λ)→fk′;
(4)密文重加密:从密文c中重新选取256比特,记为c′1,其余的部分记为c′2,将c′1采用fk′加密,得到新的stub,即encfk′(c′1)→stub;
(5)数据上传:将c′2封装成新的trimmedpackage,并将新的stub和trimmedpackage上传至云服务器;
重加密密钥分发:
雾节点对密文进行重加密之后,将重加密的密钥以及c′1选取的位置分享给其他雾节点;雾节点采用属性加密abe的方式将密钥分发给其他节点,具体步骤如下:
(1)密钥生成:输入安全参数1λ,得到公钥pk,以及主密钥mk;即,setup(1λ)→pk,mk;
(2)私钥生成:输入公钥pk,主密钥mk,以及雾节点的属性集,输出雾节点的私钥;即,kengen(pk,mk,s)→sk;
(3)加密:雾节点将c′1的选取的位置,以及加密密钥作为消息m,输入其他雾节点的公钥pk,消息m以及访问策略t,输出密文ct,发送至云服务器,再由云服务器将ct分发至其他雾节点;即,enc(pk,m,t)→ct;
(4)解密:其余雾节点从云服务器接收到密文ct,采用公钥以及自己的私钥sk解密,每一条密文均对应一个访问策略t,如果该雾节点的属性集s符合访问策略t,则可以正确解密,否则解密失败;即,dec(pk,sk,ct)→miffs∈t。
进一步,服务器端的数据去重与数据存储,并删除冗余的数据,在服务器端保留一份数据具体方法包括:
(1)云服务器接收到雾节点发送的数据和数据标签t后,通过检测t判断这些数据是否有相同的;
(2)如果否,则将文件标签存储在数据索引表中,并将数据存放在云服务器中,与雾节点的数据索引表不同,云服务器的数据索引只保存数据标签,而并不存储该数据的拥有者;
(3)如果是,云服务删除相同的数据,只保留其中一份备份,删除其余冗余数据,并将数据标签添加至数据索引表中。
进一步,用户发送数据的哈希值,即可判断云服务器是否存储了该数据,某些恶意的用户可能会采取此方法,判断云服务器上存放了哪些数据,证明用户的文件所有权pow具体操作包括:
(1)将密文数据分块,记为b1,b2,...,bn;
(2)求b1,b2,...,bn依次求哈希值得到h1,h2,...,hn;
(3)将h1与h2级联,h3与h4级联,依次类推,将hn-1与hn级联;
(4)将级联之后的分别求哈希,得到hs1...hsn/2;
(5)再将hs1与hs2级联,hs3与hs4级联,依次类推;
(6)将级联之后继续求哈希值,不断循环,得到最终结果,即为数据标签t。
本发明的另一目的在于提供一种实现所述雾计算环境下数据安全去重方法的雾计算环境下数据安全去重系统,所述雾计算环境下数据安全去重系统包括:
客户端,用户在客户端对数据采用mle加密;
雾节点,雾节点主要执行四个操作:用户数据所有权的检测,密文数据的重加密,密文数据的更新以及重加密密钥的分发;
云服务器,云服务器负责服务器端的数据去重与数据存储,并删除冗余的数据,只在服务器端保留一份数据。
本发明的另一目的在于提供一种应用所述雾计算环境下数据安全去重方法的云存储平台。
综上所述,本发明的优点及积极效果为:在雾计算环境下数据安全去重的存储方法,安全加密方案主要分为两方面,一方面在用户的客户端,另一方面在雾节点,而去重操作则主要在雾节点与云服务器上。数据的密文的重加密更新由雾节点来完成。并结合merkletree与数据所有权证明技术,防止恶意用户对服务器进行侧信道攻击。
本发明在雾计算环境下实现了一个数据安全去重系统。将存储系统部署在雾节点上,缓解了云服务器的压力,同时也克服了云服务器上的如延迟高、网络拥塞等缺点。同时,本发明采用将数据先加密后上传的方式保存数据,有效的抵抗了因服务器数据泄露而导致的用户隐私数据丢失的问题。除此之外,本发明在雾节点上采用支持更新的重加密方案,可以防止已撤销权限的用户再次获得明文数据。本发明在雾节点上采用客户端去重的方案,即,用户先发送文件标签,如果查询到服务器有该数据,则用户无需上传,采用此种方式极大的节省了通信开销。本发明还采用了merkletree生成数据标签的方式,防止一些恶意用户对服务器进行侧信道攻击。
表1本发明和之前方案的对比
附图说明
图1是本发明实施例提供的雾计算环境下数据安全去重方法流程图。
图2是本发明实施例提供的雾计算环境下数据安全去重系统结构示意图;
图3是本发明实施例提供的对数据加解密的结构示意图。
图4是本发明实施例提供的消息锁加密(mle)的原理示意图。
图5是本发明实施例提供的对数据所有权标签生成的结构示意图。
图6是本发明实施例提供的在雾节点上对密文数据进行更新的结构示意图。
图7是本发明实施例提供的分发重加密密钥的结构示意图。
图8是本发明实施例提供的雾节点上数据索引表的结构示意图。
图9是本发明实施例提供的云服务器上数据索引表的结构示意图。
图10是本发明实施例提供的云服务器删除重复数据的操作示意图。
图11是trimmedpackage部分加密时所需的时间。
图12是stub部分加密时所需的时间。
图13是密文数据更新时所需的时间。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明的数据去重就是针对服务器中存储的大量数据,一些数据是完全相同的,而数据去重就是将这些相同的数据删除,只保留一份数据备份。从去重执行的细粒度区分,数据安全去重可以分为两种:文件级(filelevel)去重和块级(blocklevel)去重:文件级去重是指文件是去重的最小的单元,即服务器根据文件标签进行去重检测,并且只保留唯一的文件副本。块级去重则是指数据块是去重的最小单元,即服务器根据块标签进行去重检测,并且只保留唯一的数据块副本。根据分块方式不同,块级去重可分为基于定长分块的数据去重与基于变长分块的数据去重。从去重框架区分,数据安全去重可分为:服务器端(server-side)去重,客户端(client-side)去重:
服务器端去重是指用户将数据全部上传至服务器,服务器检测上传后的数据是否有重复,删除冗余的数据后只保留其中一份备份,在此过程中,用户不知道所上传的数据是否被去重。客户端去重是指用户将文件的标签发送给服务器,服务器通过标签检测该数据是否已经存在,如果服务器上存在该数据,用户无需再次上传,服务器为用户添加数据权限,整个过程中,用户知道自己的数据是否已经被去重。
在本发明在雾节点上采用客户端去重的方式,在云服务器上采用服务器端去重的方式。
消息锁加密,传统的加密方式在数据去重中并不适用,因为相同的明文文件将会被加密成不同的密文文件,这是由于用户不同用户选取的加密密钥不同。2002年,douceur提出了收敛加密(convergentencryption,ce)的概念,保证了相同的明文可以生成相同的密钥;2013年bellare在收敛加密的基础上提出了消息锁加密(messagelockedencryption,mle),mle的加密密钥由明文文件的哈希值生成,保证了相同的明文可以生成相同的密文,因此,采用消息锁加密可以保证数据在密文条件下能够进行去重操作。
属性加密(attributebasedencryption,abe)的概念最早由sahai和waters提出。属性加密是一种公钥加密方案,公钥即为用户的属性集,极大的简化了公钥的管理。它主要分为两种:密文策略基于属性加密(ciphertextpolicyattributebasedencryption,cp-abe),以及密钥策略基于属性加密(keypolicyattributebasedencryption,kp-abe)。两种方式恰好相反,其中,cp-abe中,密文为访问策略,密钥为用户的属性集。kp-abe中,密钥为访问策略,密文为用户的属性集。两种方案相比,cp-abe更为灵活。本发明主要采用的是cp-abe加密。
merkletree是一种哈希二叉树,由一个根节点,多个中间节点以及多个叶子节点构成,用户数据的完整性验证和用户的所有权证明。merkletree的叶子节点由数据信息构成,其余非叶子节点由其孩子节点值级联之后求哈希值获得,从下至上逐层计算,最终得到唯一的根节点。
下面结合附图对本发明的应用原理作详细的描述。
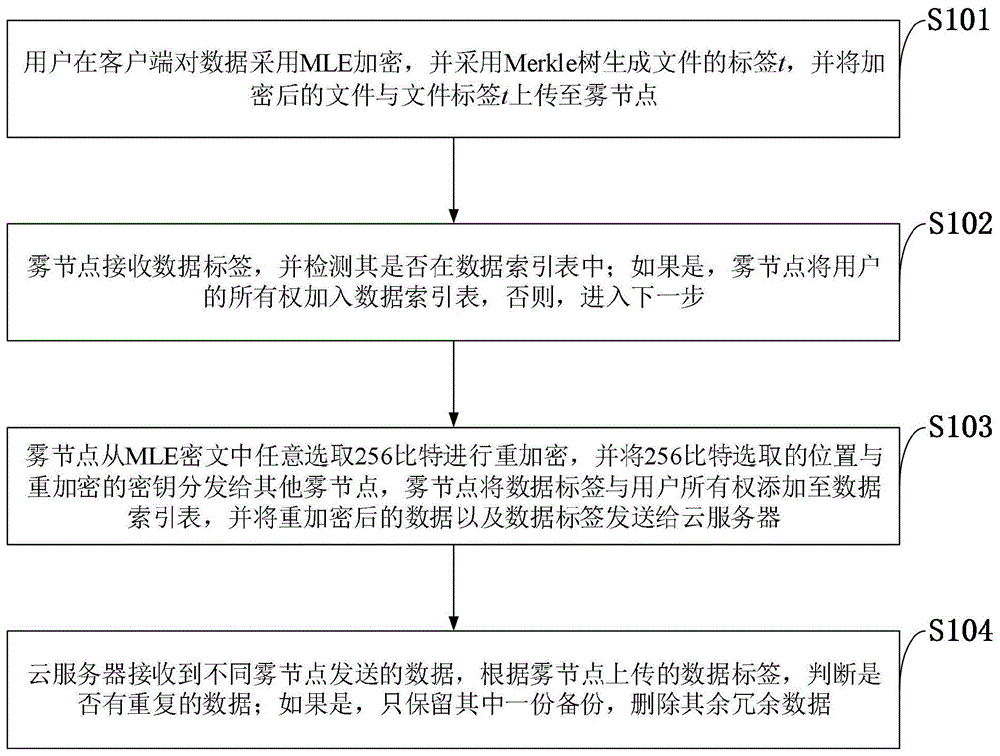
如图1所示,本发明实施例提供的雾计算环境下数据安全去重方法包括以下步骤:
s101:用户在客户端对数据采用mle加密,并采用merkle树生成文件的标签t,并将加密后的文件与文件标签t上传至雾节点;
s102:雾节点接收数据标签,并检测其是否在数据索引表中;如果是,雾节点将用户的所有权加入数据索引表,否则,进入下一步;
s103:雾节点从mle密文中任意选取256比特进行重加密,并将256比特选取的位置与重加密的密钥分发给其他雾节点,雾节点将数据标签与用户所有权添加至数据索引表,并将重加密后的数据以及数据标签发送给云服务器;
s104:云服务器接收到不同雾节点发送的数据,根据雾节点上传的数据标签,判断是否有重复的数据;如果是,只保留其中一份备份,删除其余冗余数据。
本发明实施例提供的雾计算环境下数据安全去重方法的用户在客户端执行,负责对文件进行第一步加密,并生成相应的文件标签。加密采用mle加密,保证相同的明文文件可以生成相同的密文文件。s102在雾节点执行,用于判断当前用户上传的文件是否已经被上传至云服务器,如果雾节点查询发现已经上传过该文件,则用户无需上传,只需将用户的数据所有权添加至如图7所示的数据索引表中,如果雾节点为查询到此文件则跳转至s103。s103也是在雾节点上执行,雾节点需要对用户上传的mle密文数据进行一次重加密,并添加用户的数据所有权至图7所示的数据索引表中,之后将重加密的文件上传至云服务器。并跳转至s104。s104在云服务器上执行,云服务检测不同雾节点上传的数据是否有重复的,如果有,云服务器删除冗余的数据,只保留其中一份,并将数据添加至图8所示的数据索引表中;如果不存在重复的数据,云服务器保存该数据,并将数据添加至图8所示的数据索引表中。
如图2所示,本发明实施例提供的雾计算环境下数据安全去重系统包括:
客户端,用户在客户端对数据采用mle加密;主要分为以下几个步骤:
(1)密钥的产生:输入明文m,采用sha256计算明文的哈希值,得到mle密钥,即hash(m)→k;
(2)采用mle密钥对明文m进行aes加密,得到密文c,即enc(m)k→c;
(3)用户对密文c采用merkletree生成哈希值,记为标签t;
(4)用户保留mle密钥k,并将密文c与标签t上传至雾节点。雾节点,雾节点主要执行四个操作:用户数据所有权的检测,密文数据的重加密,密文数据的更新以及重加密密钥的分发;具体步骤如下:
用户数据所有权检测:
雾节点将用户上传的标签t与自己所建立的数据索引表中的数据比较,如果t在数据索引表中,雾节点无需接收用户上传的密文c,直接将用户的权限添加至数据索引表中;如果t不在索引表中,雾节点需要对数据执行重加密操作。
密文数据的重加密:
(1)密钥生成:输入安全参数,得到一个随机的加密密钥,称为filekey:gen(1λ)→fk;
(2)重加密:从mle密文c中选取256比特,记为c1,剩余部分记为c2,并采用aes对c1加密,得到stub,即:encfk(c1)→stub;
(3)数据索引表的更新:雾节点将用户数据标签t以及t的所有权用户添加至数据索引表;
(4)数据上传:雾节点将c2封装成trimmedpackage,并将trimmedpackage,stub,以及用户标签t上传至云服务器。雾节点保留随机加密密钥fk;
密文数据的更新:
(1)stub解密:雾节点接收到服务器的更新请求,采用之前保留的fk对stub解密得到c1,即decfk(stub)→c1;
(2)mle密文恢复:将密文c1与trimmedpackage(即c2)拼接,得到mle密文c;
(3)新filekey的生成:输入安全参数,得到一个随机的加密密钥:gen(1λ)→fk′;
(4)密文重加密:从密文c中重新选取256比特,记为c′1,其余的部分记为c′2,将c′1采用fk′加密,得到新的stub,即encfk′(c′1)→stub;
(5)数据上传:将c′2封装成新的trimmedpackage,并将新的stub和trimmedpackage上传至云服务器。
重加密密钥分发:
雾节点对密文进行重加密之后,需要将重加密的密钥以及c′1选取的位置分享给其他雾节点,方便其他雾节点解密。在本发明中,雾节点采用属性加密(abe)的方式将密钥分发给其他节点,具体步骤如下:
(1)密钥生成:输入安全参数1λ,得到公钥pk,以及主密钥mk。即,setup(1λ)→pk,mk;
(2)私钥生成:输入公钥pk,主密钥mk,以及雾节点的属性集,输出雾节点的私钥。即,kengen(pk,mk,s)→sk;
(3)加密:雾节点将c′1的选取的位置,以及加密密钥作为消息m,输入其他雾节点的公钥pk,消息m以及访问策略t,输出密文ct,发送给云服务器,再由云服务器将ct分发至其他雾节点。即,enc(pk,m,t)→ct;
(4)解密:其余雾节点从云服务器接收到密文ct,采用公钥以及自己的私钥sk解密,每一条密文均对应一个访问策略t,如果该雾节点的属性集s符合访问策略t,则可以正确解密,否则解密失败。即,dec(pk,sk,ct)→miffs∈t。
云服务器,云服务器负责服务器端的数据去重与数据存储,并删除冗余的数据,只在服务器端保留一份数据;具体过程如下:
(1)云服务器接收到雾节点发送的数据和数据标签t后,通过检测t判断这些数据是否有相同的;
(2)如果否,则将文件标签存储在数据索引表中,并将数据存放在云服务器中,与雾节点的数据索引表不同,云服务器的数据索引只保存数据标签,而并不存储该数据的拥有者。
(3)如果是,云服务删除相同的数据,只保留其中一份备份,删除其余冗余数据,并将数据标签添加至数据索引表中。
本发明实施例提供的雾计算环境下数据安全去重系统主要分为三层结构,客户端,雾节点与云服务器。用户对数据的分块加密等操作均在客户端执行,而雾节点则管理某一区域的多个客户端,由于同一个雾节点下管理的客户端位置相近,因此,这些用户上传的数据有很大的相似度,因此采用此种方式去重效率较高。而且,雾节点将用户与服务器相隔离,因此,一些恶意用户很难直接在服务器上部署自己的应用程序。对每一个用户而言,雾节点就是一个小型的云服务器。服务器的功能与传统的云服务器相似,负责检测重复的数据并只保存唯一备份。在本发明中,云服务器不直接与用户相通信,而是与雾节点相连,因此,服务器不需要管理用户的数据所有权,而是只保存数据,这极大的降低了服务器的存储开销,简化了服务器的存储模式。
下面结合附图对本发明的应用原理作进一步的描述。
如图3所示,是本发明的加解密示意图,其中,mle加密这一步骤在客户端进行,用户需要执行上传操作时,需先对数据采用mle加密,保证明文数据不被泄露,之后,再将数据上传给雾节点。雾节点需要先将数据分割成两部分,其中一部分只有256比特,再对这256比特进行重加密,保证了密文数据的动态性。之所以并不是对整个的密文加密,是因为每次在更新时,都需要对所有的内容进行一次加解密操作,开销较大。当用户需要下载文件时,用户先向雾节点发送请求,雾节点检测用户数据所有权是否在数据索引表中,如果是,雾节点先从服务器上下载数据,对数据进行第一次解密,并将解密后的数据拼接,得到mle密文,将mle密文发送给用户,用户在本地端解密mle密文得到原始明文数据。
如图4所示,是消息锁加密,即mle的加密原理示意图。其中加密密钥k由明文m的哈希值产生,同时用明文文件生成数据标签t,数据标签的生成过程如图5所示。采用加密密钥k对明文m进行aes加密,得到密文c,采用此种方式加密,保证了相同的明文可以加密成相同的密文,在保证数据安全的同时节省了存储开销。
如图5所示,是数据标签t生成的示意图,主要包含以下几步:
(1)首先用户将加密后的数据分块,记为b1,b2,b3,b4;
(2)求b1,b2,b3,b4依次求哈希值得到h1,h2,h3,h4;
(3)将h1与h2级联,h3与h4级联;
(4)将级联之后的分别求哈希,得到s1和s2;
(5)最后将s1与s2级联并求哈希值,得到最终的结果,即为数据标签t。
如果一个恶意的用户,想要采用向服务器发送数据标签的方法来判断服务器中存有哪些数据,则该用户必须是这些数据的拥有者。即使数据的拥有者想要检测云服务器中是否存有这些数据,但是只能检测到该区域的雾节点是否上传过此数据,并不能检测其他雾节点是否存有这些数据,采用此种方式有效的抵抗了侧信道攻击。
如图6所示,是密文数据更新的示意图。当一些用户撤销权限时,必须对密文数据进行更新,否则,这些用户如果与一些恶意敌手共谋,这些敌手可以通过已撤销权限用户的密钥对服务器中的数据进行解密,这对于服务器而言是十分危险的,因此,需要对密文数据定期进行更新。更新主要分为以下几步:
(1)stub解密:雾节点接收到服务器的更新请求,对stub解密得到c1,即decfk(stub)→c1;
(2)mle密文恢复:将密文c2与trimmedpackage(即c1)拼接,得到mle密文c;
(3)新filekey的生成:输入安全参数,得到一个随机的加密密钥:gen(1λ)→fk′;
(4)密文重加密:从密文c中重新选取256比特,记为c′2,其余的部分记为c′11与c′12,将c′2采用fk′加密,得到新的stub,即encfk′(c′2)→stub;
(5)数据上传:将c′11和c′12封装成新的trimmedpackage,并将新的stub和trimmedpackage上传至云服务器。
如图7所示,是更新后密钥重新分发的示意图,雾节点将数据进行更新后,将新的stub选取的位置以及加密密钥通过abe加密的方式发送给服务器,而服务器则将abe密文,发送给其他雾节点。如果数据需要再次更新,则选取其中一个雾节点需要继续执行上述操作。
如图8所示,是雾节点上数据索引表的结构示意图。该索引表分为两栏,右栏记录的是数据标签,表示该雾节点已经上传了哪些数据至云服务器上,而左栏是这些数据的合法拥有者,当用户发出下载请求时,雾节点需要先检测该用户是否是数据的合法拥有者,如果是,雾节点采用将数据从云服务器上下载,并发送给该用户,否则,雾节点,直接拒绝该用户的请求。如图8所示,数据a68a791667344340的拥有者是用户a和用户b,如果用户a或b申请下载该数据,雾节点则将数据发送给用户,如果用户c申请下载该数据,雾节点则直接拒绝用户c的请求。
如图9所示,是云服务器上数据索引表的结构示意图。该索引表也是分成两栏,但与雾节点上的索引表有所不同,该索引表并不需要记录数据的拥有者,左栏记录的是数据标签,右栏记录的是该数据标签对应的数据,数据内容分为两个部分trimmedpackage和stub。当雾节点接收到用户的下载请求时,需要在云服务器上查找该数据标签对应的数据,并将数据先进行解密、拼接得到mle密文,并将mle密文发送给用户。例如,用户a想要下载数据a68a791667344340,雾节点检测到用户a为该数据的合法拥有者,雾节点将数据标签发送给云服务器,云服务检测到数据标签a68a791667344340对应的数据是trimmedpackage05与stub05,并将这两个数据发送给雾节点,雾节点对stub05解密并与trimmedpackage拼接,并将拼接后的mle密文发送给用户。
如图10所示,是在服务器端检测并删除重复数据的示意图。如图所示,云服务器接收到来自不同雾节点上传的数据,数据a,数据b,数据c,其中:
ta=bcdf0a4058a8943d;
tb=bcdf0a4058a8943d;
tc=bcdf0a4058a8943d;
经服务器检测,ta,tb,tc完全相同,证明数据a,数据b,数据c完全相同,此时,服务器删除数据b与c,只保存数据a,并将数据a与对应的数据标签ta添加至图9所示的数据索引表中。
图11为trimmedpackage加密所需的时间,图12为stub加密数据所需的时间,横坐标为分割之后每个数据块的大小,纵坐标为加密整个文件所需的时间,整个文件的大小为10mb。
图13为数据重加密更新时所需的时间,横坐标为每个数据块的大小,纵坐标为更新整个文件所需的时间,整个文件的大小为10mb。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!