一种基于遗传算法的存储型XSS漏洞检测系统的制作方法
本发明涉及一种基于遗传算法的存储型xss漏洞检测系统,属于计算机软件领域。
背景技术:
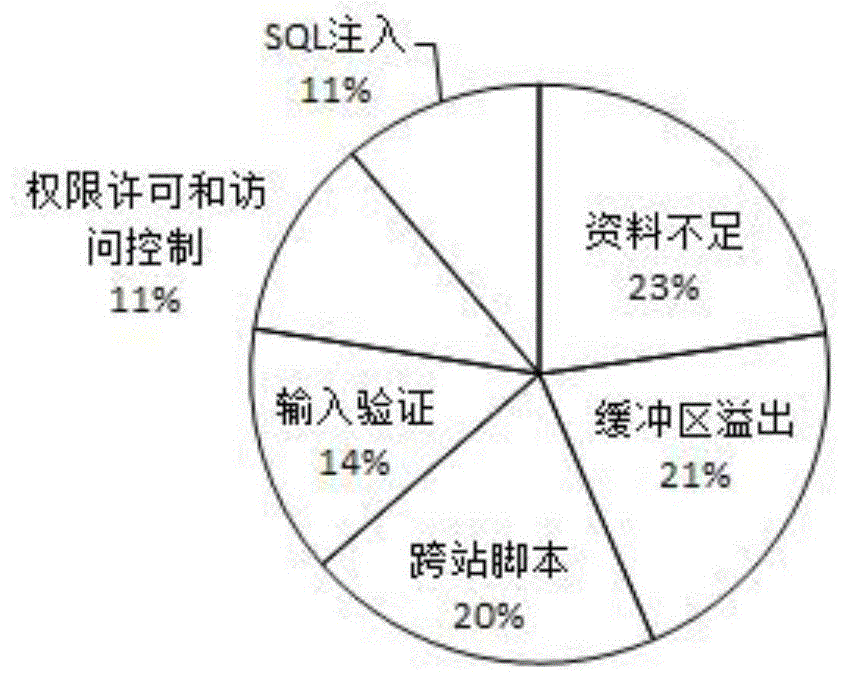
:随着互联网技术高速发展,各种web应用层出不穷,同时由于开发人员技术参差不齐,越来越多的web安全问题也陆续出现。据国家信息安全漏洞库统计,跨站脚本漏洞(crosssitescriptexecution,xss)位居第三,占20%,详情如图1所示。根据非盈利组织owasp(theopenwebapplicationsecurityproject)公布的十大应用安全风险中,xss漏洞也一直名列其中,这些都表明xss漏洞已经成为目前各类web应用需要面对的常见漏洞之一。xss漏洞产生的本质原因是各类web应用对用户输入的数据没有能够进行有效过滤,造成攻击者提交的恶意代码可以在web应用中恶意执行,给用户造成一系列的危害,例如盗取用户cookies、网络钓鱼、劫持会话等。而xss漏洞传统分为反射型、存储型以及基于dom型三种类型。在这三类xss漏洞中,存储型xss漏洞危害相对于其他两类较为严重,影响时间长,故在本发明中,只针对存储型xss漏洞检测进行研究。目前针对存储型xss漏洞检测的常用方法有白盒测试和黑盒测试两种。白盒测试对应用源码的依赖性很强,需要测试人员对源码全部了解,完成对代码的审计工作,检测方法的实现一般依赖于编程语言,可移植性差。对于黑盒测试来说,测试人员不需要了解应用源码,只需要站在用户的角度进行测试,一般依赖于爬虫算法获取网页信息,在众多的网页中查找可能的漏洞注入点。然而,在使用爬虫算法的时候,有些算法只关注提高爬虫的速度而忽略了某些网站的反爬虫规则产生的影响,从而造成爬虫的失败。同时,攻击向量设计的完备性与有效性也与漏洞检测的效率有关,常用的方法是模糊测试技术和设计变形规则。模糊测试技术通过向目标网站发送大量随机生成的无意义的数据,然后根据响应结果来判断是否存在漏洞。这些随机生成的数据由于缺少明确的意义和指向性,存在较大的盲目性。有些方法是通过一些编码、大小写混编、插入字符等方式对已有的攻击向量进行处理以保证最终注入的脚本能够得到有效执行。这种方法针对不同的被测网站的过滤机制的不同,检测结果的好坏也大不相同。综上所述,本发明从黑盒测试的角度对存储型xss漏洞检测进行了研究。提出了一种基于遗传算法的攻击向量生成方法,通过对已有的攻击向量变形,生成适应被测网站的攻击向量,具有较好的全局最优解求解能力。首先,扫描目标网站所有网页尽可能获取注入点,然后针对目标网站生成适合的攻击向量,最后对注入点进行模拟攻击,判断漏洞是否存在。技术实现要素:本发明的内容为:①提出了一种基于遗传算法的攻击向量生成与优化方法,该方法可以动态地生成适应待测网站的攻击向量。②提出了一种基于广度优先搜索算法的爬虫框架,该框架可以通过解析页面来获取网页中向数据库中存储数据的交互点,扩大了存储型xss漏洞注入点检测的覆盖率。③提出了一种高效判定存储型xss漏洞是否存在的方法。④对相关方法以及框架进行实现并测试,验证了其实用性及有效性。本发明从黑盒测试的角度出发,利用爬虫技术以及遗传算法对web应用进行漏洞检测,以达到提高注入点覆盖率和存储型xss漏洞的发现率。为达到以上发明目的,经过反复研究与讨论,本软件系统确定最终方案如下:1、系统总体设计本系统主要分为三个模块:网络爬虫与注入点分析模块、攻击向量生成模块、漏洞检测模块。(1)网络爬虫与注入点分析模块:该模块采用多线程技术提高爬虫速度,主要负责爬取网站链接并查找其中的注入点。本发明采用广度优先爬虫算法搜寻链接,递归地将获取到的链接经过去重处理后,将同域名下的所有url加入队列便于后期解析。对每一个html文档,定位form表单,获取注入点信息。为了便于后期漏洞的检测,提高检测速度,对于网页中的每一个注入点,首先提交“探子”确定注入点的输入点位置,避免漏洞检测时网页全篇扫描,提高了效率。(2)攻击向量生成模块:该模块采用遗传算法对收集到的基本攻击向量进行变形,得到适应目标网站的攻击向量,基本攻击向量库是指从owasp中xssfilterevasioncheatsheet收集的攻击向量。首先将攻击向量特征形式化,然后基于one-hot编码进行改进用于遗传算法的基因编码,完成遗传算法执行前的数据准备工作。(3)漏洞检测模块:该模块主要负责模拟攻击行为与并进行漏洞分析。主要思想是随机从遗传算法产生的攻击向量中选择攻击向量,再使用selenium测试框架对注入点自动填充攻击向量,通过提交这些攻击向量对相关页面检测是否存在漏洞。首先利用爬虫与注入点分析模块得到注入点信息,直接对相关页面进行分析,定位到注入点后判定攻击向量是否存在。若存在则需要接着利用selenium.webdriver来确定攻击向量是否执行,若攻击向量执行则可以确定存在存储型xss漏洞。2、运行环境本软件系统整体由python2.7编写,可以在windows64位系统上正常运行。3、软件系统可根据实际情况改变的内容由于本系统具有较强的通用型,在设计之初就考虑到了对其它操作系统的支持。本项目核心库包括selenium、beautifulsoup、re、threading、mysql-connector-python以及各种浏览器驱动库等,这些库都是独立.py文件,可以在所有主流的操作系统上运行,因此可以很好的实现跨平台移植。由于selenium框架与浏览器紧密相关,可能会有版本不兼容的情况,故实际情况中,可以根据selenium的版本来调整浏览器的版本。4、附图说明图1国家信息安全漏洞库漏洞分类图2系统架构图(按模块)图3应对网站反爬虫规则图4攻击向量生成图(遗传算法)表1基本攻击向量示例序号部分攻击向量示例1<script>alert(“xss”)</script>2<imgsrc=javascript:prompt(“xss”)/>3"><imgsrc=#onerror='alert(“xss”)'/><"4><script>alert(“xss”)</script><5><imgsrc=javascript:prompt(“xss”)/><6"><imgsrc=javascript:confirm(“xss”)/><"表1具体实施方式本系统的原理是基于遗传算法生成与优化攻击向量,利用爬虫技术快速获取源码,通过解析网页进行分析获取与后台交互的注入点,然后利用selenium实现表单提交,最后动态判断网页是否存在存储型xss漏洞。本系统主要分为网络爬虫与注入点分析模块、攻击向量生成模块、漏洞检测模块三个模块,具体的系统架构如图2所示。5.1网络爬虫与注入点分析模块该模块主要实现搜索网页链接和通过页面解析技术查找注入点功能。搜索网页链接使用了广度优先爬虫算法,仅搜索同域名下的网页,该算法描述如算法1所示,并采用设置用户代理头部的方式来应对网站的反爬虫规则,以此避免爬虫的失败,用户代理头部详细情况如图3所示。算法1:广度优先爬虫算法input:初始网页url,爬取深度depthoutput:与网址url同网站的所有页面url在爬取网页的过程中,涉及到网页解析。针对每一个待爬取网页,需要对其进行解析,分析网页的源码才能提取到网页链接和web表单。结合上述提到的广度优先爬虫算法,整个网页爬虫模块的具体流程如下:(1)根据给定的url初始化待爬取队列和待检测队列。(2)结合广度优先搜索算法,从待爬取队列首部取出一个网页url。(3)利用python语言提供的urllib2模块,提取网页中的链接和form表单信息。(4)将步骤(3)中提取到的链接url去重并添加到待爬取队列尾部。(5)若网页url中含有form表单,则将网页url加入待检测队列,并利用selenium提交探子,否则跳至步骤(7)(6)分析响应结果,找到注入点的展示页面,完善注入点信息。(7)结束。在对每一个页面解析之后,定位form标签在html文档中的位置,然后直接找到其子类标签,如<input>,<textarea>等这类向后台提供数据的标签,并以字典的形式存储下来,以便后期攻击注入。5.2攻击向量生成模块在本发明中,通过对遗传算法的基本流程进行改进,对已有的攻击向量进行变形,以产生适应能力高的攻击向量。基本攻击向量是从owasp中xssfilterevasioncheatsheet收集的攻击向量,部分示例如表1所示。首先将改进的one-hot编码方式作为遗传算法的编码方法,整个基因串为20位的“01”串,然后选择随机竞争选择算法作为选择算子,算法描述如算法2所示。在第8位以后随机选择交叉点,然后进行单点交叉。最后,为了提高攻击向量的多样性,对攻击向量进行变异。利用遗传算法生成攻击向量的详细流程如图4所示。算法2随机竞争选择算法5.3漏洞检测模块该模块是基于黑盒测试的思想,在前面两个模块的基础上来判定存储型xss漏洞的存在。主要分为模拟攻击以及漏洞检测阶段,从待检测队列中选择一个url,以及相关的注入点信息,对表单填充遗传算法生成的攻击向量并提交,在其相关页面判定攻击向量是否执行以达到判定漏洞是否存在的目的。具体操作如算法3所述。综上,在判定是否存在漏洞时,需要判定弹窗是否出现,本发明中通过借用selenium框架中的alert_is_present()方法来确定是否出现弹窗,并进一步确定弹窗内容是否为提交的攻击向量中的内容。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1