基于AI语音的智能交互处理方法、系统及存储介质与流程
本发明涉及智能家居技术领域,具体涉及一种基于ai语音的智能交互处理方法、系统及存储介质。
背景技术:
随着科学技术的进步,智能化的消费电子也逐渐普及,ai语音的技术之一声纹识别是一种当前较为前沿的技术,能够识别出说话人的声音属性(性别、年龄,能够区分不同的说话人的声音归属(通过声纹能够区分出那一句话是哪一个用户说的))。
当前的声纹识别应用还停留在初级阶段,基本上还处于能够识别出一些基础的声纹属性(如:男、女、老、幼、声纹归属(是谁的声纹)),缺乏基于声纹识别技术的ai家居场景应用级开发。
现有技术的智能电视也不具有更好的智能交互功能,有时不方便用户使用
因此,现有技术还有待于改进和发展。
技术实现要素:
鉴于上述现有技术的不足之处,本发明的目的在于提供一种基于ai语音的智能交互处理方法、系统及存储介质,提供了一种方便智能识别和交互推荐的基于ai语音的智能交互处理方法、系统,使智能电视增加了更好的智能交互功能,方便用户使用。
为了达到上述目的,本发明采取了以下技术方案:
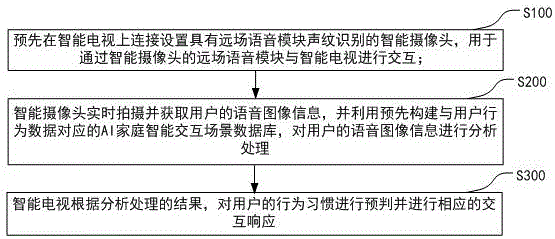
一种基于ai语音的智能交互处理方法,其中,包括如下步骤:
a、预先在智能电视上连接设置具有远场语音模块声纹识别的智能摄像头,用于通过智能摄像头的远场语音模块与智能电视进行交互;
b、智能摄像头实时拍摄并获取用户的语音图像信息,并利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
c、智能电视根据分析处理的结果,对用户的行为习惯进行预判并进行相应的交互响应。
所述的基于ai语音的智能交互处理方法,其中,所述步骤a还包括:a1、预先构建与用户行为数据对应的ai家庭智能交互场景数据库。
所述的基于ai语音的智能交互处理方法,其中,所述步骤b包括:
智能电视开机时智能摄像头处于工作状态;
智能摄像头实时拍摄并获取用户的语音图像信息,侦听用户的说话语音,并将用户说话语音记录进行ai家庭智能交互处理;
ai家庭智能交互处理利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正。
所述的基于ai语音的智能交互处理方法,其中,所述步骤b中的利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理的步骤包括:
进行语音指令的语义识别和场景构建类;
进行当前用户的声纹属性分析、声纹情绪特征分析、人脸识别分析、用户家庭场景分析、用户的情绪分析、场景历史记录分析;
智能创建用户系统大数据,通过构建ai家庭智能交互场景对用户的语音指令进行分析处理。
所述的基于ai语音的智能交互处理方法,其中,所述进行语音指令的语义识别和场景构建类的步骤包括:
进行语音指令分解的语义识别:分析用户的说话是属于指令类还是场景构建类;
所述进行当前用户的声纹属性分析的步骤包括:
进行当前用户的声纹属性识别:哪些声纹用户同时出现过;
所述声纹情绪特征分析包括:声纹出现的场景是什么样,每个人的声纹场景是什么,综合场景是什么;
所述人脸识别分析包括:谁跟谁在同一时间出现过,表情是什么,时间是什么;
所述用户家庭场景分析通过智能摄像头取景按照预定模板分析;
所述用户的情绪分析通过声纹、声纹情绪特征、人脸表情和场景进行分析;
所述场景历史记录分析包括:哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,用于通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出。
所述的基于ai语音的智能交互处理方法,其中,所述步骤c包括:
智能电视根据分析处理的结果创建一个用户的属性记录,并将用户的id、声纹属性、人脸属性作为用户的辨识值,通过上述三个任何一个属性定位到用户;
当检测到一个陌生的声纹或者人脸时,默认创建用户的属性记录,并通过后续的互动智能增加声纹对应用户的声纹属性;而如果用户首先记录的是声纹属性增加的用户id,过后续的互动智能增加用户的人脸属性;
创建成功用户之后,自动创建基于用户id的大数据数据表,数据表记录用户的各种行为记录、互动记录、交互记录;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正;
对用户的语音图像信息进行ai家庭智能交互分解后,得出用户的预执行操作,或者推荐用户最好的互动场景并进行相应的提示。
一种基于ai语音的智能交互处理系统,其中,包括:处理器、存储器和通信总线;
所述存储器上存储有可被所述处理器执行的基于ai语音的智能交互处理程序;
所述通信总线实现处理器和存储器之间的连接通信;
所述处理器执行所述基于ai语音的智能交互处理程序时实现如下步骤:
a、预先在智能电视上连接设置具有远场语音模块声纹识别的智能摄像头,用于通过智能摄像头的远场语音模块与智能电视进行交互;
b、智能摄像头实时拍摄并获取用户的语音图像信息,并利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
c、智能电视根据分析处理的结果,对用户的行为习惯进行预判并进行相应的交互响应。
所述的基于ai语音的智能交互处理系统,其中,所述处理器执行所述基于ai语音的智能交互处理程序时还实现如下步骤:
a1、预先构建与用户行为数据对应的ai家庭智能交互场景数据库;
智能电视开机时智能摄像头处于工作状态;
智能摄像头实时拍摄并获取用户的语音图像信息,侦听用户的说话语音,并将用户说话语音记录进行ai家庭智能交互处理;
ai家庭智能交互处理利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正。
所述的基于ai语音的智能交互处理系统,其中,所述处理器执行所述基于ai语音的智能交互处理程序时还实现如下步骤:
进行语音指令的语义识别和场景构建类;
进行当前用户的声纹属性分析、声纹情绪特征分析、人脸识别分析、用户家庭场景分析、用户的情绪分析、场景历史记录分析;
智能创建用户系统大数据,通过构建ai家庭智能交互场景对用户的语音指令进行分析处理;
进行语音指令分解的语义识别:分析用户的说话是属于指令类还是场景构建类;
所述进行当前用户的声纹属性分析的步骤包括:
进行当前用户的声纹属性识别:哪些声纹用户同时出现过;
所述声纹情绪特征分析包括:声纹出现的场景是什么样,每个人的声纹场景是什么,综合场景是什么;
所述人脸识别分析包括:谁跟谁在同一时间出现过,表情是什么,时间是什么;
所述用户家庭场景分析通过智能摄像头取景按照预定模板分析;
所述用户的情绪分析通过声纹、声纹情绪特征、人脸表情和场景进行分析;
所述场景历史记录分析包括:哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,用于通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出;
智能电视根据分析处理的结果创建一个用户的属性记录,并将用户的id、声纹属性、人脸属性作为用户的辨识值,通过上述三个任何一个属性定位到用户;
当检测到一个陌生的声纹或者人脸时,默认创建用户的属性记录,并通过后续的互动智能增加声纹对应用户的声纹属性;而如果用户首先记录的是声纹属性增加的用户id,过后续的互动智能增加用户的人脸属性;
创建成功用户之后,自动创建基于用户id的大数据数据表,数据表记录用户的各种行为记录、互动记录、交互记录;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正;
对用户的语音图像信息进行ai家庭智能交互分解后,得出用户的预执行操作,或者推荐用户最好的互动场景并进行相应的提示。
一种存储介质,其中,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现任意一项所述的基于ai语音的智能交互处理方法中的步骤。
相较于现有技术,本发明提供的基于ai语音的智能交互处理方法、系统及存储介质,本发明通过在智能电视搭载具有远场语音模块声纹识别的智能摄像头,用户通过智能摄像头的远场语音与电视进行交互,用户的每一句语音交互都通过ai家庭智能交互系统块进行分析处理,分析处理的内容包括:语音指令的语义识别(语音指令分解,将指令分解为明确指令类和场景构建类(根据分析系统的完善可以增加新的细分领域的分类))、当前用户的声纹属性(声纹识别(性别、年龄)、声纹情绪特征(兴奋、忧愁、平淡等)、人脸识别(用户属性、表情属性)、用户系统关联)、用户家庭场景分析(一个人、多个人、人员组合、家庭场景(聚会、聚餐、休闲等,通过智能摄像头取景按照预定模板分析)、用户的情绪分析(通过声纹+声纹情绪特征+人脸表情+场景)、场景历史记录分析(哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出)),智能创建用户系统大数据(用户id、用户属性、用户交互记录、用户关联(用户跟用户的互动)记录),通过构建ai家庭智能交互场景对用户的语音指令进行进一步的分析处理,提升ai语音的场景构建能力和情感交互能力;上述所有数据存在云上。
本发明为智能家居及ai语音智能交互提供了一种深层次的情感交互体验,提升了产品的体验性和趣味性,提升了以电视为中心的家庭智能家居智能化体验,提供了一种陪伴式的家居体验。本发明使智能电视增加了更好的智能交互功能,方便用户使用。
附图说明
图1为本发明提供的基于ai语音的智能交互处理方法的流程图。
图2为本发明移动终端较佳实施例的功能模块图。
具体实施方式
为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
请参阅图1,本发明提供的基于ai语音的智能交互处理方法包括以下步骤:
s100、预先在智能电视上连接设置具有远场语音模块声纹识别的智能摄像头,用于通过智能摄像头的远场语音模块与智能电视进行交互;
本发明实施例中需要预先在智能电视上连接设置具有远场语音模块声纹识别的智能摄像头,用于通过智能摄像头的远场语音模块与智能电视进行交互。智能电视搭载具有远场语音模块声纹识别的智能摄像头,用户通过智能摄像头的远场语音与电视进行交互,用户的每一句语音交互都通过ai家庭智能交互系统块进行分析处理。
所述步骤s100还包括:a1、预先构建与用户行为数据对应的ai家庭智能交互场景数据库。例如构建当用户语音讲“有什么好玩的”行为数据,则对应推荐“用户经常需要玩的游戏或旅游项目”给用户。
s200、智能摄像头实时拍摄并获取用户的语音图像信息,并利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理。
所述步骤s200具体包括:
智能电视开机时智能摄像头处于工作状态;
智能摄像头实时拍摄并获取用户的语音图像信息,侦听用户的说话语音,并将用户说话语音记录进行ai家庭智能交互处理;
ai家庭智能交互处理利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正。
其中,所述步骤b中的利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理的步骤包括:
进行语音指令的语义识别和场景构建类;
进行当前用户的声纹属性分析、声纹情绪特征分析、人脸识别分析、用户家庭场景分析、用户的情绪分析、场景历史记录分析;
智能创建用户系统大数据,通过构建ai家庭智能交互场景对用户的语音指令进行分析处理。
其中,所述进行语音指令的语义识别和场景构建类的步骤包括:
进行语音指令分解的语义识别:分析用户的说话是属于指令类还是场景构建类;
所述进行当前用户的声纹属性分析的步骤包括:
进行当前用户的声纹属性识别:哪些声纹用户同时出现过;
所述声纹情绪特征分析包括:声纹出现的场景是什么样,每个人的声纹场景是什么,综合场景是什么;
所述人脸识别分析包括:谁跟谁在同一时间出现过,表情是什么,时间是什么;
所述用户家庭场景分析通过智能摄像头取景按照预定模板分析;
所述用户的情绪分析通过声纹、声纹情绪特征、人脸表情和场景进行分析;
所述场景历史记录分析包括:哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,用于通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出。
本步骤s200中实现,用户通过智能摄像头的远场语音与电视进行交互,用户的每一句语音交互都通过ai家庭智能交互系统块进行分析处理,分析处理的内容包括:语音指令的语义识别(语音指令分解,将指令分解为明确指令类和场景构建类(根据分析系统的完善可以增加新的细分领域的分类))、当前用户的声纹属性(声纹识别(性别、年龄)、声纹情绪特征(兴奋、忧愁、平淡等)、人脸识别(用户属性、表情属性)、用户系统关联)、用户家庭场景分析(一个人、多个人、人员组合、家庭场景(聚会、聚餐、休闲等,通过智能摄像头取景按照预定模板分析)、用户的情绪分析(通过声纹+声纹情绪特征+人脸表情+场景)、场景历史记录分析(哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出)),智能创建用户系统大数据(用户id、用户属性、用户交互记录、用户关联(用户跟用户的互动)记录),通过构建ai家庭智能交互场景对用户的语音指令进行进一步的分析处理,提升ai语音的场景构建能力和情感交互能力。上述所有数据存在云上。
s300、智能电视根据分析处理的结果,对用户的行为习惯进行预判并进行相应的交互响应。
所述步骤s300具体包括:
智能电视根据分析处理的结果创建一个用户的属性记录,并将用户的id、声纹属性、人脸属性作为用户的辨识值,通过上述三个任何一个属性定位到用户;
当检测到一个陌生的声纹或者人脸时,默认创建用户的属性记录,并通过后续的互动智能增加声纹对应用户的声纹属性;而如果用户首先记录的是声纹属性增加的用户id,过后续的互动智能增加用户的人脸属性;
创建成功用户之后,自动创建基于用户id的大数据数据表,数据表记录用户的各种行为记录、互动记录、交互记录;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正;
对用户的语音图像信息进行ai家庭智能交互分解后,得出用户的预执行操作,或者推荐用户最好的互动场景并进行相应的提示。
例如:用户a+用户b在对着摄像头发出了一个指令【我们今天干吗呢】,ai家庭智能交互系统分析a\b用户之前有没有同时出现过电视前,如果出现过则给出他们之前做过的事情的互动回忆,并根据今天的家庭场景给出今天的意见和推荐,意见和推荐是多元的,可以是电视里面的应用数据(如看电视、玩游戏、学烹饪)也可以是购物(新款推荐、购物打折)、旅游(旅行推荐)等运营数据,这些数据都是根据用户的行为习惯进行预判的,并根据用户的互动行为不断的学习纠正,使ai家庭智能交互系统智能贴近用户所想及所得。
以下通过一具体应用实施例本发明做进一步详细描述:
s11、智能电视搭载具有远场语音模块声纹识别的智能摄像头。
s12、智能电视开机时智能摄像头处于工作状态。
s13、智能摄像头侦听用户的说话,并将用户说话记录传递给ai家庭智能交互系统。
s14、ai家庭智能交互系统对用户的说话进行分析处理;分析处理的内容包括:语音指令的语义识别(语音指令分解):分析用户的说话是属于指令类(指令类属于用户的说话意向性非常明确,且不需要通过场景分析就能进行指令执行的,如:我要看刘德华的电影、我要听张靓颖的歌、我要吃红烧肉等)还是场景构建类(如:天气太热怎么办、现在做什么好呢、好无聊啊、中午吃什么呢等)。
当前用户的声纹属性(声纹识别(性别、年龄段等):哪些声纹用户同时出现过
声纹情绪特征(兴奋、忧愁、平淡等):声纹出现的场景是什么样,每个人的声纹场景是什么,综合场景是什么(通过声纹分析出场景(默认定义:兴奋、温馨、高兴、热闹等))
人脸识别(用户属性、表情属性)、用户系统关联):谁跟谁在同一时间出现过,表情是什么,时间是什么。
用户家庭场景分析(一个人、多个人、人员组合、家庭场景(聚会、聚餐、休闲等,通过智能摄像头取景按照预定模板分析)
用户的情绪分析(通过声纹+声纹情绪特征+人脸表情+场景)
场景历史记录分析(哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出))
通过构建ai家庭智能交互场景对用户的语音指令进行进一步的分析处理,提升ai语音的场景构建能力和情感交互能力。
s15、当智能摄像头检测到用户语音数据并传输给ai家庭智能交互系统时,ai家庭智能交互系统会创建一个用户的属性记录,并将用户的id、声纹属性、人脸属性作为用户的辨识值,通过上述三个任何一个属性可以定位到用户。
s16、当ai家庭智能交互系统检测到一个陌生的声纹或者人脸的时候,就会默认创建用户的属性记录,并通过后续的互动智能增加声纹对应用户的声纹属性。反过来如果用户首先记录的是声纹属性增加的用户id,过后续的互动智能增加用户的人脸属性。
s17、创建成功用户之后,自动创建基于用户id的大数据数据表,数据表记录用户的各种行为记录、互动记录、交互记录等(包括用户发送的指令历史及指令执行的记录、用户对指令执行的后续互动等,用户的基础数据见6、7、8、9、10、11列出但不局限于已经列举的数据记录)。
s18、用户发送的语音通过ai家庭智能交互系统分解后,得出用户的预执行操作,或者推荐用户最好的互动场景。
如:用户a+用户b在对着摄像头发出了一个指令【我们今天干吗呢】,ai家庭智能交互系统分析a\b用户之前有没有同时出现过电视前,如果出现过则给出他们之前做过的事情的互动回忆,并根据今天的家庭场景给出今天的意见和推荐,意见和推荐是多元的,可以是电视里面的应用数据(如看电视、玩游戏、学烹饪)也可以是购物(新款推荐、购物打折)、旅游(旅行推荐)等运营数据,这些数据都是根据用户的行为习惯进行预判的,并根据用户的互动行为不断的学习纠正,使ai家庭智能交互系统智能贴近用户所想及所得。
由上可见,本发明提供了一种基于ai语音的智能交互处理方法,提供了一种方便智能识别和交互推荐的基于ai语音的智能交互处理方法、系统,使智能电视增加了更好的智能交互功能,方便用户使用。
如图2所示,基于上述基于ai语音的智能交互处理方法,本发明还相应提供了一种基于ai语音的智能交互处理系统,所述基于ai语音的智能交互处理系统可以是智能电视、桌上型计算机、笔记本、掌上电脑及智能音响智能设备。该基于ai语音的智能交互处理系统包括处理器10、存储器20及显示屏30,处理器10通过通信总线50与存储器20连接,所述显示屏30通过通信总线50与处理器10连接。图2仅示出了基于ai语音的智能交互处理系统的部分组件,但是应理解的是,并不要求实施所有示出的组件,可以替代的实施更多或者更少的组件。
所述存储器20在一些实施例中可以是所述基于ai语音的智能交互处理系统的内部存储单元,例如基于ai语音的智能交互处理系统的内存。所述存储器20在另一些实施例中也可以是所述基于ai语音的智能交互处理系统的外部存储设备,例如所述基于ai语音的智能交互处理系统上配备的插接式u盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)等。进一步地,所述存储器20还可以既包括所基于ai语音的智能交互处理系统的内部存储单元也包括外部存储设备。所述存储器20用于存储安装于所述基于ai语音的智能交互处理系统的应用软件及各类数据,例如所述安装基于ai语音的智能交互处理系统的程序代码等。所述存储器20还可以用于暂时地存储已经输出或者将要输出的数据。在一实施例中,存储器20上存储有基于ai语音的智能交互处理方法程序40,该基于ai语音的智能交互处理方法程序40可被处理器10所执行,从而实现本申请中基于ai语音的智能交互处理方法。
所述处理器10在一些实施例中可以是一中央处理器(centralprocessingunit,cpu),微处理器,手机基带处理器或其他数据处理芯片,用于运行所述存储器20中存储的程序代码或处理数据,例如执行所述基于ai语音的智能交互处理方法等。
所述显示屏30在一些实施例中可以是led显示屏、液晶显示屏、触控式液晶显示屏以及oled(organiclight-emittingdiode,有机发光二极管)触摸器等。所述显示屏30用于显示在所述基于ai语音的智能交互处理系统的信息以及用于显示可视化的用户界面。
在一实施例中,当处理器10执行所述存储器20中基于ai语音的智能交互处理方法程序40时实现以下步骤:
a、预先在智能电视上连接设置具有远场语音模块声纹识别的智能摄像头,用于通过智能摄像头的远场语音模块与智能电视进行交互;
b、智能摄像头实时拍摄并获取用户的语音图像信息,并利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
c、智能电视根据分析处理的结果,对用户的行为习惯进行预判并进行相应的交互响应,具体如上所述。
其中,所述处理器执行所述基于ai语音的智能交互处理程序时还实现如下步骤:
a1、预先构建与用户行为数据对应的ai家庭智能交互场景数据库;
智能电视开机时智能摄像头处于工作状态;
智能摄像头实时拍摄并获取用户的语音图像信息,侦听用户的说话语音,并将用户说话语音记录进行ai家庭智能交互处理;
ai家庭智能交互处理利用预先构建与用户行为数据对应的ai家庭智能交互场景数据库,对用户的语音图像信息进行分析处理;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正。
其中,所述处理器执行所述基于ai语音的智能交互处理程序时还实现如下步骤:
进行语音指令的语义识别和场景构建类;
进行当前用户的声纹属性分析、声纹情绪特征分析、人脸识别分析、用户家庭场景分析、用户的情绪分析、场景历史记录分析;
智能创建用户系统大数据,通过构建ai家庭智能交互场景对用户的语音指令进行分析处理;
进行语音指令分解的语义识别:分析用户的说话是属于指令类还是场景构建类;
所述进行当前用户的声纹属性分析的步骤包括:
进行当前用户的声纹属性识别:哪些声纹用户同时出现过;
所述声纹情绪特征分析包括:声纹出现的场景是什么样,每个人的声纹场景是什么,综合场景是什么;
所述人脸识别分析包括:谁跟谁在同一时间出现过,表情是什么,时间是什么;
所述用户家庭场景分析通过智能摄像头取景按照预定模板分析;
所述用户的情绪分析通过声纹、声纹情绪特征、人脸表情和场景进行分析;
所述场景历史记录分析包括:哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,用于通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出;
智能电视根据分析处理的结果创建一个用户的属性记录,并将用户的id、声纹属性、人脸属性作为用户的辨识值,通过上述三个任何一个属性定位到用户;
当检测到一个陌生的声纹或者人脸时,默认创建用户的属性记录,并通过后续的互动智能增加声纹对应用户的声纹属性;而如果用户首先记录的是声纹属性增加的用户id,过后续的互动智能增加用户的人脸属性;
创建成功用户之后,自动创建基于用户id的大数据数据表,数据表记录用户的各种行为记录、互动记录、交互记录;
根据用户的行为习惯进行预判,并根据用户的互动行为不断的学习纠正;
对用户的语音图像信息进行ai家庭智能交互分解后,得出用户的预执行操作,或者推荐用户最好的互动场景并进行相应的提示,具体如上所述。
基于上述实施例,本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现如上述任意一项所述的基于ai语音的智能交互处理方法中的步骤,具体如上所述。
综上所述,本发明提供的基于ai语音的智能交互处理方法、系统及存储介质,本发明通过在智能电视搭载具有远场语音模块声纹识别的智能摄像头,用户通过智能摄像头的远场语音与电视进行交互,用户的每一句语音交互都通过ai家庭智能交互系统块进行分析处理,分析处理的内容包括:语音指令的语义识别(语音指令分解,将指令分解为明确指令类和场景构建类(根据分析系统的完善可以增加新的细分领域的分类))、当前用户的声纹属性(声纹识别(性别、年龄)、声纹情绪特征(兴奋、忧愁、平淡等)、人脸识别(用户属性、表情属性)、用户系统关联)、用户家庭场景分析(一个人、多个人、人员组合、家庭场景(聚会、聚餐、休闲等,通过智能摄像头取景按照预定模板分析)、用户的情绪分析(通过声纹+声纹情绪特征+人脸表情+场景)、场景历史记录分析(哪些声纹场景组合发生过什么处理事件,什么时候发生的,发生之后用户进行过什么交互,通过历史数据分析,预判用户的下一步行为,进行一些预处理的输出)),智能创建用户系统大数据(用户id、用户属性、用户交互记录、用户关联(用户跟用户的互动)记录),通过构建ai家庭智能交互场景对用户的语音指令进行进一步的分析处理,提升ai语音的场景构建能力和情感交互能力;上述所有数据存在云上。
本发明为智能家居及ai语音智能交互提供了一种深层次的情感交互体验,提升了产品的体验性和趣味性,提升了以电视为中心的家庭智能家居智能化体验,提供了一种陪伴式的家居体验。本发明使智能电视增加了更好的智能交互功能,方便用户使用。
当然,本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关硬件(如处理器,控制器等)来完成,所述的程序可存储于一计算机可读取的存储介质中,该程序在执行时可包括如上述各方法实施例的流程。其中所述的存储介质可为存储器、磁碟、光盘等。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!