基于边缘计算的流式大数据处理方法及系统与流程
本发明涉及数据处理技术领域,具体涉及一种基于边缘计算的流式大数据处理方法及系统。
背景技术:
流式数据是指由若干数据源持续生成的数据,这类数据具有海量、快速、时变的特点,广泛存在于金融服务、电信服务、气象预测等诸多领域。
常见的流式数据处理框架大多是针对云计算数据中心设计开发,数据通过网络传输到远端的云计算数据中心,经过处理后再将结果返回用户终端设备。
但对于无人驾驶车辆这类延迟敏感型应用来说,无人驾驶车辆每分钟可以产生gb级的数据,若将这些数据直接传送到云端,会受到网络瓶颈的限制,同时由于云计算数据中心距离通常较远,所产生的延迟对这类延迟敏感型应用来说是不可接受的。
技术实现要素:
本申请提供了一种基于边缘计算的流式大数据处理方法及系统,能够实现将计算能力从传统的云计算中心转移到网络边缘,方便边缘设备的使用,同时在满足吞吐量要求的前提下,有效降低了端到端延迟。
根据第一方面,一种实施例中提供了一种基于边缘计算的流式大数据处理方法,该方法包括:
数据接收步骤:接收特定区域无人驾驶车辆上搭载的传感器所产生的流式数据;
车流量预测步骤:获取当前时间段的车流数据和历史车流数据,基于所述车流数据和历史车流数据对车流量信息进行预测,以获取数据的到达速率;
处理步骤:基于所述数据的到达速率,发出控制指令,控制处理引擎对所述流式数据进行处理,并输出处理结果。
在一些实施例,所述车流量预测步骤包括:
获取当前时间段的车流数据和历史车流数据;
对所述历史车流数据进行汇总,得到车流量趋势,基于预测模型对所述车流量趋势进行拟合,以获得当前时间段内车流量的变化曲线;
基于动态时间规整算法,将当前时间段的车流数据和所述变化曲线进行时间对齐,基于对齐后的车流量变化曲线预测下一时间片的车流量信息,以获取下一批次数据的到达速率。
在一些实施例,所述处理步骤包括:
获取下一批次数据的到达速率和处理引擎处理上一批次的流式数据所消耗的时间;
根据所述数据的到达速率和处理引擎处理上一批次的流式数据所消耗的时间对处理引擎时间片的大小进行调节;
根据调节后的时间片大小对流式数据进行处理,并输出处理结果。
在一些实施例,处理引擎处理下一批次流式数据的时间小于或等于调节后的时间片大小。
在一些实施例,所述预测模型包括以下至少一种:灰色模型、整合移动平均自回归模型、递归神经网络或长短期记忆网络。
根据第二方面,一种实施例中提供了一种基于边缘计算的流式大数据处理
系统,该系统包括:
存储器,用于存储程序;
处理器,用于通过执行所述存储器存储的程序以实现如权利要求1-6中任一项所述的方法。
根据第三方面,一种实施例中提供了一种基于边缘计算的流式大数据理装置,该装置包括:
数据接收装置:接收特定区域无人驾驶车辆上搭载的传感器所产生的流式数据;
车流量预测装置:获取当前时间段的车流数据和历史车流数据,基于所述车流数据和历史车流数据对车流量信息进行预测,以获取数据的到达速率;
处理装置:基于所述数据的到达速率,发出控制指令,从而控制处理引擎对所述流式数据进行处理,并输出处理结果。
在一些实施例,所述车流量预测装置包括:
用于获取当前时间段的车流数据和历史车流数据的装置;
用于对所述历史车流数据进行汇总,得到车流量趋势,基于预测模型对所述车流量趋势进行拟合,以获得当前时间段内车流量的变化曲线的装置;
用于基于动态时间规整算法,将当前时间段的车流数据和所述变化曲线进行时间对齐,基于对齐后的车流量变化曲线预测下一时间片的车流量信息,以获取下一批次数据的到达速率的装置。
在一些实施例,所述处理装置包括:
用于获取下一批次数据的到达速率和处理引擎处理上一批次流式数据所消耗的时间的装置;
用于根据所述数据的到达速率和处理引擎处理上一批次流式数据所消耗的时间对处理引擎时间片的大小进行调节的装置;
处理引擎:用于根据调节后的时间片大小对流式数据进行处理,并输出处理结果。
在一些实施例,所述处理引擎包括以下至少一种:spark引擎、apacheflink引擎、storm引擎、kafkastreams引擎和samza引擎。
依据上述实施例的基于边缘计算的流式大数据处理方法及系统,将计算任务由云数据中心转移到网络边缘,满足延迟敏感型应用的需求,同时,通过对短时车流的准确预测,提高了处理数据的准确性,减少了处理时间,从而满足应用吞吐量和低延迟的要求。
附图说明
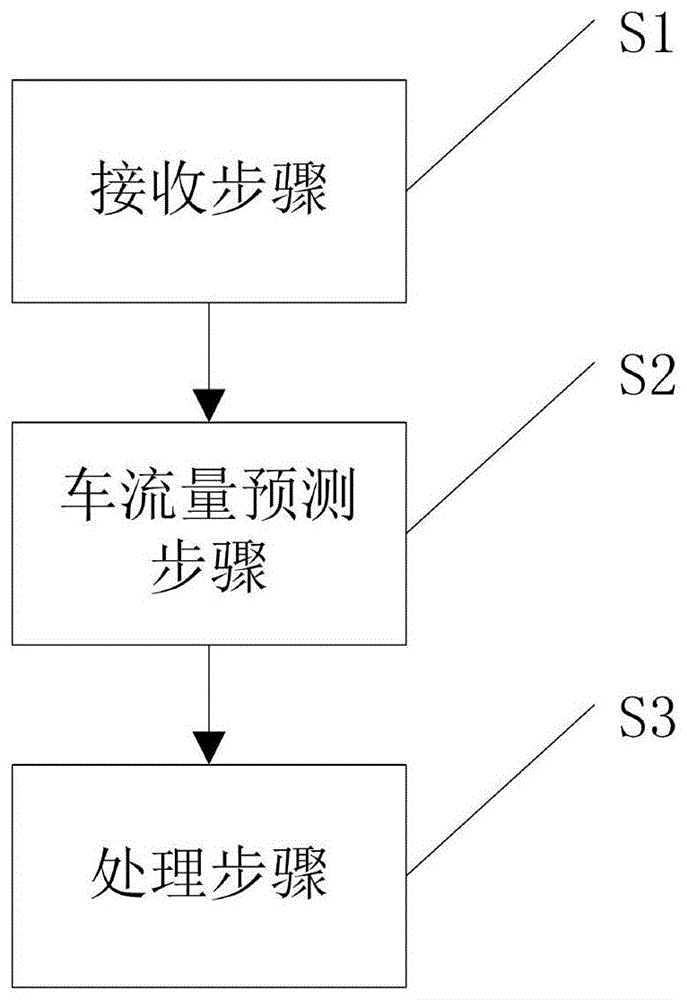
图1为根据本发明实施例的基于边缘计算的流式大数据处理方法的流程图;
图2为根据本发明一种实施例的基于边缘计算的流式大数据处理方法的车流量预测步骤的流程图;
图3为根据本发明一种实施例的基于边缘计算的流式大数据处理方法的处理步骤的流程图;
图4为根据本发明一种实施例的基于边缘计算的流式大数据处理装置的示例性框图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。其中不同实施方式中类似元件采用了相关联的类似的元件标号。在以下的实施方式中,很多细节描述是为了使得本申请能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他元件、材料、方法所替代。在某些情况下,本申请相关的一些操作并没有在说明书中显示或者描述,这是为了避免本申请的核心部分被过多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。
另外,说明书中所描述的特点、操作或者特征可以以任意适当的方式结合形成各种实施方式。同时,方法描述中的各步骤或者动作也可以按照本领域技术人员所能显而易见的方式进行顺序调换或调整。因此,说明书和附图中的各种顺序只是为了清楚描述某一个实施例,并不意味着是必须的顺序,除非另有说明其中某个顺序是必须遵循的。
边缘计算是指在靠近终端用户或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力的分布式开放平台,可就近提供边缘智能服务,满足行业数字化在敏捷联接、实时业务、数据优化、应用智能、安全与隐私保护等方面的关键需求。通过将资源(例如存储和计算处理能力)部署到接入网络的边缘,为终端用户提供了快速而强大的计算能力,较高的能源效率,存储容量移动性,以及位置和环境信息的支持。以无人驾驶场景为例,无人驾驶车辆使用5g通信技术将数据上传到边缘数据中心仅需毫秒级的传输延迟,即可获得边缘计算中心较为强大的计算能力。
本发明立足于资源有限的边缘数据中心,服务于特定地理区域内的若干无人驾驶车辆。对于无人驾驶车辆来说,处理时延至关重要,数据得到快速处理意味着无人驾驶车辆能够快速对周围环境变化做出响应,安全系数更高,若数据无法及时处理,则可能会危害车上乘客及周围车辆行人的安全。而对于边缘数据中心里的流式大数据处理系统来说,其具有的资源有限,架构各异,应充分利用已有资源,满足区域全体车辆产生数据的吞吐量要求,同时尽可能降低端到端延迟。
需要说明的是,在本申请中,假定每辆车搭载了相同的传感器并以固定频率发送数据,则车流量信息与车载传感器所产生的流式数据具有线性关系。
图1为根据本发明实施例的基于边缘计算的流式大数据处理方法的流程图。如图1所示,本发明实施例的基于缘计算的流式大数据处理方法包括以下步骤:
数据接收步骤s1:接收特定区域无人驾驶车辆上搭载的传感器所产生的流式数据。
车流量预测步骤s2:获取当前时间段的车流数据和历史车流数据,基于所述车流数据和历史车流数据对车流量信息进行预测,以获取数据的到达速率。
处理步骤s3:基于所述数据的到达速率,发出控制指令,控制处理引擎对所述流式数据进行处理,并输出处理结果。
图2为根据本发明一种实施例的基于边缘计算的流式大数据处理方法的车流量预测步骤的流程图。如图2所示,车流量预测步骤s2包括:
s21:获取当前时间段的车流数据和历史车流数据。
s22:对所述历史车流数据进行汇总,得到车流量趋势,基于预测模型对所述车流量趋势进行拟合,以获得当前时间段内车流量的变化曲线。
s23:基于动态时间规整算法,将当前时间段的车流数据和所述变化曲线进行时间对齐,基于对齐后的车流量变化曲线预测下一时间片的车流量信息,以获取下一批次数据的到达速率。
需要说明的是,本发明根据一天的早晚高峰情况,将一天划分为若干个时间段,每个时间段包含若干时间片,对某一时间片车流量信息的预测仅依赖于该时间段的历史车流数据以及当前时间段的车流数据。
举例来说,使用灰色模型对特定区域内的车流量进行预测。预测时首先获取该区域历史车流数据和当前时间段采集到的车流数据,使用灰色模型拟合出该时间段内车流量的变化曲线,考虑到每日的早晚高峰出现时间可能会存在一定程度的偏移,使用动态时间规整算法将当前时间段的车流数据和变化曲线进行时间对齐,从而得到下一批次数据的到达速率。
图3为根据本发明一种实施例的基于边缘计算的流式大数据处理方法的处理步骤的流程图。如图3所示,处理步骤s3包括:
s31:获取下一批次数据的到达速率和处理引擎处理上一批次的流式数据所消耗的时间。
s32:根据所述数据的到达速率和处理引擎处理上一批次的流式数据所消耗的时间对处理引擎时间片的大小进行调节。
应当理解的是,可通过模糊控制或具有类似输入输出的启发式控制算法对处理引擎的时间片进行实时调节,使得处理引擎处理下一批次流式数据的时间与调节后的时间片大小尽可能接近,且处理时间小于或等于调节后的时间片大小。
s33:根据调节后的时间片大小对下一批次的流式数据进行处理,并输出处理结果。
在一些实施例,预测模型包括以下至少一种:灰色模型、整合移动平均自回归模型、递归神经网络或长短期记忆网络。
图4为根据本发明一种实施例的基于边缘计算的流式大数据处理装置的示例性框图。如图4所示,流式大数据处理装置100包括:
数据接收装置10:接收特定区域无人驾驶车辆上搭载的传感器所产生的流式数据。
车流量预测装置20:获取当前时间段的车流数据和历史车流数据,基于所述车流数据和历史车流数据对车流量信息进行预测,以获取数据的到达速率。
处理装置30:基于所述数据的到达速率,发出控制指令,从而控制处理引擎对所述流式数据进行处理,并输出处理结果。
在一些实施例,车流量预测装置20包括:
用于获取当前时间段的车流数据和历史车流数据的装置。
用于对所述历史车流数据进行汇总,得到车流量趋势,基于预测模型对所述车流量趋势进行拟合,以获得当前时间段内车流量的变化曲线的装置。
用于基于动态时间规整算法,将当前时间段的车流数据和所述变化曲线进行时间对齐,基于对齐后的车流量变化曲线预测下一时间片的车流量信息,以获取下一批次数据的到达速率的装置。
在一些实施例,处理装置30包括:
用于获取下一批次数据的到达速率和处理引擎处理上一批次流式数据所消耗的时间的装置。
用于根据所述数据的到达速率和处理引擎处理上一批次流式数据所消耗的时间对处理引擎时间片的大小进行调节的装置。
举例来说,利用模糊控制模块对处理引擎时间片大小的实时调节。调节时,根据专家经验建立模糊系统控制规则库,模糊控制模块获取数据的到达速率和来自处理引擎的处理上一批次流式数据所消耗的时间,模糊控制模块基于规则库做出控制决策,实现对处理引擎时间片大小的实时调节。
处理引擎:用于根据调节后的时间片大小对流式数据进行处理,并输出处理结果。
在一些实施例,处理引擎包括以下至少一种:spark引擎、apacheflink引擎、storm引擎、kafkastreams引擎和samza引擎。
本领域技术人员可以理解,上述实施方式中各种方法的全部或部分功能可以通过硬件的方式实现,也可以通过计算机程序的方式实现。当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器、随机存储器、磁盘、光盘、硬盘等,通过计算机执行该程序以实现上述功能。例如,将程序存储在设备的存储器中,当通过处理器执行存储器中程序,即可实现上述全部或部分功能。另外,当上述实施方式中全部或部分功能通过计算机程序的方式实现时,该程序也可以存储在服务器、另一计算机、磁盘、光盘、闪存盘或移动硬盘等存储介质中,通过下载或复制保存到本地设备的存储器中,或对本地设备的系统进行版本更新,当通过处理器执行存储器中的程序时,即可实现上述实施方式中全部或部分功能。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
- 还没有人留言评论。精彩留言会获得点赞!