本发明涉及一种图像信号的处理方法,尤其是涉及一种立体视频重定位方法。
背景技术:
随着立体显示技术的快速发展,各种具有不同立体显示功能的立体显示终端也广泛出现了,但是,由于立体显示终端的种类繁多,宽/高比规格不一,因此若将宽/高比一定的立体视频放在不同的立体显示终端上显示,则必须先对立体视频的尺寸进行调整,以达到立体显示的效果。传统的视频缩放方法是通过裁剪或者是按固定比例进行缩放,然而这样做可能会出现视频中的内容减少或者导致显著物体形变。
对于立体视频,如果直接对左视点视频和右视点视频分别采用相同的视频重定位方法,即单独处理立体视频中的左视点视频和右视点视频,则会造成错误的深度信息;同时,当立体视频有较快的深度运动时,传统的深度保持会使得重定位后的立体视频仍然有不舒适的深度运动,进而会造成视觉不舒适,影响观看体验。因此,如何对立体视频进行缩放以优化深度运动、减少图像形变、避免时域抖动、突出显著内容,从而降低视觉不舒适,都是在对立体视频进行重定位过程中需要研究解决的问题。
技术实现要素:
本发明所要解决的技术问题是提供一种立体视频重定位方法,其符合显著语义特征,且能够有效地调整立体视频的尺寸大小。
本发明解决上述技术问题所采用的技术方案为:一种立体视频重定位方法,其特征在于包括以下步骤:
步骤一:将待处理的原始立体视频序列中当前待处理的第t帧左视点视频图像和第t帧右视点视频图像对应定义为当前左视点视频图像和当前右视点视频图像;其中,t为正整数,t的初始值为1,1≤t≤t-1,t表示待处理的原始立体视频序列中包含的宽度为w且高度为h的左视点视频图像的总帧数和包含的宽度为w且高度为h的右视点视频图像的总帧数,t为正整数,t>1,w和h均能被8整除;
步骤二:将当前左视点视频图像和当前右视点视频图像对应记为和然后采用基于光流的视差估计方法,计算与的左视差图像,记为其中,1≤x≤w,1≤y≤h,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值;
步骤三:将分割成个互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为然后根据中的所有四边形网格和获取中的所有互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为其中,k为正整数,k的初始值为1,1≤k≤m,m表示中包含的四边形网格的总个数和中包含的四边形网格的总个数,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,以的水平坐标位置和垂直坐标位置来描述,以的水平坐标位置和垂直坐标位置来描述,以的水平坐标位置和垂直坐标位置来描述,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值;
步骤四:采用基于图论的视觉显著模型提取出的显著图,记为然后根据和获取的三维显著图,记为再根据和获取的三维显著图,记为其中,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值;
步骤五:采用基于光流的估计方法,计算与的运动矢量,记为将中坐标位置为(x,y)的像素点的运动矢量记为同样,采用基于光流的估计方法,计算与的运动矢量,记为将中坐标位置为(x,y)的像素点的运动矢量记为其中,用于表示水平方向,用于表示垂直方向,表示的水平偏移量,表示的垂直偏移量,表示的水平偏移量,表示的垂直偏移量,表示待处理的原始立体视频序列中的第t+1帧左视点视频图像,表示中坐标位置为(x,y)的像素点的像素值,表示待处理的原始立体视频序列中的第t+1帧右视点视频图像,表示中坐标位置为(x,y)的像素点的像素值;
步骤六:根据中的所有四边形网格和获取中的所有互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为同样,根据中的所有四边形网格和获取中的所有互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为其中,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量;通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量;
步骤七:计算和中的所有四边形网格对应的目标四边形网格的深度运动能量,记为计算和中的所有四边形网格对应的目标四边形网格的形状保持能量,记为计算和中的所有四边形网格对应的目标四边形网格的时域一致能量,记为计算和中的所有四边形网格对应的目标四边形网格的空间一致能量,记为计算和中的所有四边形网格对应的目标四边形网格的视差保持能量,记为
步骤八:根据和计算和中的所有四边形网格对应的目标四边形网格的总能量,记为etotal,然后通过最小二乘优化求解得到中的所有四边形网格对应的最佳目标四边形网格构成的集合及中的所有四边形网格对应的最佳目标四边形网格构成的集合,对应记为接着根据计算中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,将对应的最佳目标四边形网格的最佳相似变换矩阵记为并根据计算中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,将对应的最佳目标四边形网格的最佳相似变换矩阵记为其中,为的加权参数,为的加权参数,为的加权参数,为的加权参数,min()为取最小值函数,表示中的所有四边形网格对应的目标四边形网格构成的集合,表示中的所有四边形网格对应的目标四边形网格构成的集合,表示对应的最佳目标四边形网格,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,表示对应的最佳目标四边形网格,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,为的转置,为的逆,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,为的转置,为的逆,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置;
步骤九:根据中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,计算中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,将中水平坐标位置为和垂直坐标位置的像素点经最佳相似变换矩阵变换后的水平坐标位置和垂直坐标位置对应记为和然后根据中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,获取经重定位后的重定位左视点视频图像,记为其中,重定位左视点视频图像的宽度为w',重定位左视点视频图像的高度为h,1≤x'≤w',1≤y'≤h,表示中坐标位置为(x',y')的像素点的像素值;
同样,根据中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,计算中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,将中水平坐标位置为和垂直坐标位置的像素点经最佳相似变换矩阵变换后的水平坐标位置和垂直坐标位置对应记为和然后根据中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,获取经重定位后的重定位右视点视频图像,记为其中,重定位右视点视频图像的宽度为w',重定位右视点视频图像的高度为h,1≤x'≤w',1≤y'≤h,表示中坐标位置为(x',y')的像素点的像素值;
步骤十:令t=t+1;然后将待处理的原始立体视频序列中当前待处理的第t帧左视点视频图像和第t帧右视点视频图像对应作为当前左视点视频图像和当前右视点视频图像;再返回步骤二继续执行,直至获得待处理的原始立体视频序列中的前t-1帧左视点视频图像对应的重定位左视点视频图像和前t-1帧右视点视频图像对应的重定位右视点视频图像,进而得到包含t-1帧重定位左视点视频图像和t-1帧重定位右视点视频图像的重定位立体视频序列;其中,t=t+1中的“=”为赋值符号。
所述的步骤四中,其中,λ1表示的权重,λ2表示的权重,λ1+λ2=1,表示中坐标位置为的像素点的像素值。
所述的步骤七中,的获取过程为:
a1、计算的直方图分布,记为然后将以向量形式表示为同样,计算的直方图分布,记为然后将以向量形式表示为其中,b为正整数,b的初始值为1,b为正整数,和中所包含的视差等级的总数目均为b,表示中视差等级为b的像素点在中出现的概率,表示与的左视差图像,表示中坐标位置为(x,y)的像素点的像素值,表示中视差等级为b的像素点在中出现的概率;
a2、计算其中,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,符号“||||”为求欧氏距离符号,t0为阈值,
所述的步骤七中,的获取过程为:
其中,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,表示的高度,表示的目标四边形网格的高度,表示的高度,表示的目标四边形网格的高度,表示中的所有像素点的三维显著值的均值,表示中的所有像素点的三维显著值的均值。
所述的步骤七中,的获取过程为:
其中,表示的目标四边形网格的宽度,表示的目标四边形网格的宽度,表示的目标四边形网格的高度,表示的目标四边形网格的高度,表示的目标四边形网格的宽度,表示的目标四边形网格的宽度,表示的目标四边形网格的高度,表示的目标四边形网格的高度。
所述的步骤七中,的获取过程为:
b1、采用尺度不变特征转换提取出中的所有特征点,将中的第q个特征点记为接着根据中的每个特征点和获取中与中的每个特征点匹配的特征点,将中与匹配的特征点记为其中,q为正整数,q的初始值为1,1≤q≤q,和各自中的特征点的总个数均为q,表示的横坐标位置,表示的纵坐标位置,表示的横坐标位置,表示中坐标位置为的像素点的像素值,表示的纵坐标位置,
b2、计算其中,表示中的所有特征点包含的四边形网格构成的集合,表示中的第k'个四边形网格,为中的第q个特征点包含的四边形网格,k'为正整数,k'的初始值为1,1≤k'≤q,表示中所有特征点包含的四边形网格构成的集合,表示中的第k'个四边形网格,为中的第q个特征点包含的四边形网格,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度。
所述的步骤七中,的获取过程为:其中,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度。
与现有技术相比,本发明的优点在于:
本发明方法通过提取立体视频每个时刻的左视点视频图像和右视点视频图像中的所有四边形网格对应的目标四边形网格的深度运动能量、形状保持能量、时域一致能量、空间一致能量、视差保持能量,并通过优化获取最佳相似变换矩阵,这样使得获得的重定位立体视频能够较好地保留重要的显著语义信息、较好地保持时域一致性、有效地调整立体视频尺寸大小且保持视觉舒适性。
附图说明
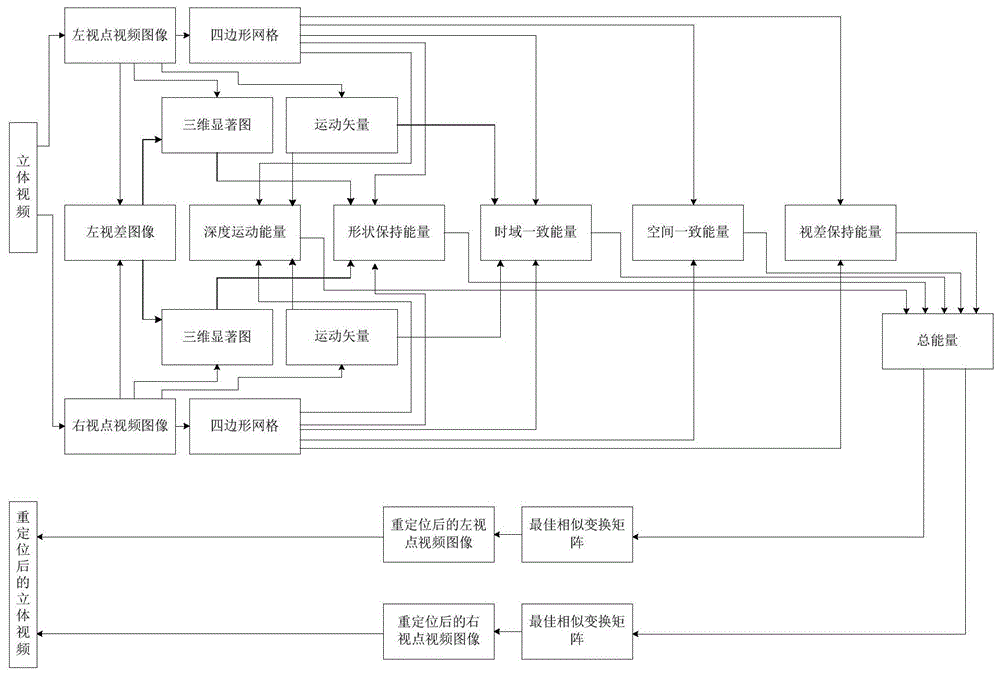
图1为本发明方法的总体实现框图;
图2a为“videol”立体视频序列的第1时刻的原始立体图像的“红/绿”图;
图2b为“videol”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图2c为“videol”立体视频序列的第2时刻的原始立体图像的“红/绿”图;
图2d为“videol”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图2e为“videol”立体视频序列的第3时刻的原始立体图像的“红/绿”图;
图2f为“videol”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图2g为“videol”立体视频序列的第4时刻的原始立体图像的“红/绿”图;
图2h为“videol”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图3a为“video2”立体视频序列的第1时刻的原始立体图像的“红/绿”图;
图3b为“video2”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图3c为“video2”立体视频序列的第2时刻的原始立体图像的“红/绿”图;
图3d为“video2”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图3e为“video2”立体视频序列的第3时刻的原始立体图像的“红/绿”图;
图3f为“video2”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图3g为“video2”立体视频序列的第4时刻的原始立体图像的“红/绿”图;
图3h为“video2”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图4a为“video3”立体视频序列的第1时刻的原始立体图像的“红/绿”图;
图4b为“video3”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图4c为“video3”立体视频序列的第2时刻的原始立体图像的“红/绿”图;
图4d为“video3”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图4e为“video3”立体视频序列的第3时刻的原始立体图像的“红/绿”图;
图4f为“video3”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图4g为“video3”立体视频序列的第4时刻的原始立体图像的“红/绿”图;
图4h为“video3”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图5a为“video4”立体视频序列的第1时刻的原始立体图像的“红/绿”图;
图5b为“video4”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图5c为“video4”立体视频序列的第2时刻的原始立体图像的“红/绿”图;
图5d为“video4”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图5e为“video4”立体视频序列的第3时刻的原始立体图像的“红/绿”图;
图5f为“video4”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;
图5g为“video4”立体视频序列的第4时刻的原始立体图像的“红/绿”图;
图5h为“video4”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
本发明提出的一种立体视频重定位方法,其总体实现框图如图1所示,其包括以下步骤:
步骤一:将待处理的原始立体视频序列中当前待处理的第t帧左视点视频图像和第t帧右视点视频图像对应定义为当前左视点视频图像和当前右视点视频图像;其中,t为正整数,t的初始值为1,1≤t≤t-1,t表示待处理的原始立体视频序列中包含的宽度为w且高度为h的左视点视频图像的总帧数和包含的宽度为w且高度为h的右视点视频图像的总帧数,t为正整数,t>1,t的值根据实际视频而定,w和h均能被8整除。
步骤二:将当前左视点视频图像和当前右视点视频图像对应记为和然后采用现有的基于光流的视差估计方法,计算与的左视差图像,记为其中,1≤x≤w,1≤y≤h,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值。
步骤三:将分割成个互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为然后根据中的所有四边形网格和获取中的所有互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为其中,k为正整数,k的初始值为1,1≤k≤m,m表示中包含的四边形网格的总个数和中包含的四边形网格的总个数,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,以的水平坐标位置和垂直坐标位置来描述,以的水平坐标位置和垂直坐标位置来描述,以的水平坐标位置和垂直坐标位置来描述,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的像素值。
步骤四:采用现有的基于图论的视觉显著(graph-basedvisualsaliency,gbvs)模型提取出的显著图,记为然后根据和获取的三维显著图,记为再根据和获取的三维显著图,记为其中,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值,表示中坐标位置为(x,y)的像素点的像素值。
在此具体实施例中,步骤四中,其中,λ1表示的权重,λ2表示的权重,λ1+λ2=1,在本实施例中取λ1=λ2=0.5,表示中坐标位置为的像素点的像素值。
步骤五:采用现有的基于光流的估计方法,计算与的运动矢量,记为将中坐标位置为(x,y)的像素点的运动矢量记为同样,采用现有的基于光流的估计方法,计算与的运动矢量,记为将中坐标位置为(x,y)的像素点的运动矢量记为其中,用于表示水平方向,用于表示垂直方向,表示的水平偏移量,表示的垂直偏移量,表示的水平偏移量,表示的垂直偏移量,表示待处理的原始立体视频序列中的第t+1帧左视点视频图像,表示中坐标位置为(x,y)的像素点的像素值,表示待处理的原始立体视频序列中的第t+1帧右视点视频图像,表示中坐标位置为(x,y)的像素点的像素值。
步骤六:根据中的所有四边形网格和获取中的所有互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为同样,根据中的所有四边形网格和获取中的所有互不重叠的尺寸大小为8×8的四边形网格,将中的第k个四边形网格记为并将中的所有四边形网格构成的集合记为其中,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量;通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量,以的水平坐标位置和垂直坐标位置来描述,表示中坐标位置为的像素点的运动矢量的水平偏移量,表示中坐标位置为的像素点的运动矢量的垂直偏移量。
步骤七:为了通过重定位降低由于较快的深度运动导致的视觉不舒适现象,本发明获取以下几个能量,计算和中的所有四边形网格对应的目标四边形网格的深度运动能量,记为计算和中的所有四边形网格对应的目标四边形网格的形状保持能量,记为计算和中的所有四边形网格对应的目标四边形网格的时域一致能量,记为计算和中的所有四边形网格对应的目标四边形网格的空间一致能量,记为计算和中的所有四边形网格对应的目标四边形网格的视差保持能量,记为
在此具体实施例中,步骤七中,的获取过程为:
a1、计算的直方图分布,记为然后将以向量形式表示为同样,计算的直方图分布,记为然后将以向量形式表示为其中,b为正整数,b的初始值为1,b为正整数,和中所包含的视差等级的总数目均为b,表示中视差等级为b的像素点在中出现的概率,表示与的左视差图像,表示中坐标位置为(x,y)的像素点的像素值,表示中视差等级为b的像素点在中出现的概率。
a2、计算其中,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,符号“||||”为求欧氏距离符号,t0为阈值,
在此具体实施例中,步骤七中,的获取过程为:
其中,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度,表示的高度,表示的目标四边形网格的高度,表示的高度,表示的目标四边形网格的高度,表示中的所有像素点的三维显著值的均值,表示中的所有像素点的三维显著值的均值。
在此具体实施例中,步骤七中,的获取过程为:
其中,表示的目标四边形网格的宽度,表示的目标四边形网格的宽度,表示的目标四边形网格的高度,表示的目标四边形网格的高度,表示的目标四边形网格的宽度,表示的目标四边形网格的宽度,表示的目标四边形网格的高度,表示的目标四边形网格的高度。
在此具体实施例中,步骤七中,的获取过程为:
b1、采用现有的尺度不变特征转换(scaleinvariantfeaturetransform,sift)提取出中的所有特征点,将中的第q个特征点记为接着根据中的每个特征点和获取中与中的每个特征点匹配的特征点,将中与匹配的特征点记为其中,q为正整数,q的初始值为1,1≤q≤q,和各自中的特征点的总个数均为q,表示的横坐标位置,表示的纵坐标位置,表示的横坐标位置,表示中坐标位置为的像素点的像素值,表示的纵坐标位置,
b2、计算其中,表示中的所有特征点包含的四边形网格构成的集合,表示中的第k'个四边形网格,为中的第q个特征点包含的四边形网格,k'为正整数,k'的初始值为1,1≤k'≤q,表示中所有特征点包含的四边形网格构成的集合,表示中的第k'个四边形网格,为中的第q个特征点包含的四边形网格,表示的宽度,即中的第q个特征点的坐标位置落在内部,表示的目标四边形网格的宽度,表示的宽度,即中的第q个特征点的坐标位置落在内部,表示的目标四边形网格的宽度。
在此具体实施例中,步骤七中,的获取过程为:其中,表示的宽度,表示的目标四边形网格的宽度,表示的宽度,表示的目标四边形网格的宽度。
步骤八:根据和计算和中的所有四边形网格对应的目标四边形网格的总能量,记为etotal,然后通过最小二乘优化求解得到中的所有四边形网格对应的最佳目标四边形网格构成的集合及中的所有四边形网格对应的最佳目标四边形网格构成的集合,对应记为及接着根据计算中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,将对应的最佳目标四边形网格的最佳相似变换矩阵记为并根据计算中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,将对应的最佳目标四边形网格的最佳相似变换矩阵记为其中,为的加权参数,为的加权参数,为的加权参数,为的加权参数,在本实施例中取min()为取最小值函数,表示中的所有四边形网格对应的目标四边形网格构成的集合,表示中的所有四边形网格对应的目标四边形网格构成的集合,表示对应的最佳目标四边形网格,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,表示对应的最佳目标四边形网格,通过其左上、左下、右上和右下4个网格顶点的集合来描述,对应表示的作为第1个网格顶点的左上网格顶点、作为第2个网格顶点的左下网格顶点、作为第3个网格顶点的右上网格顶点、作为第4个网格顶点的右下网格顶点,为的转置,为的逆,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,为的转置,为的逆,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置,和对应表示的水平坐标位置和垂直坐标位置。
步骤九:根据中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,计算中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,将中水平坐标位置为和垂直坐标位置的像素点经最佳相似变换矩阵变换后的水平坐标位置和垂直坐标位置对应记为和然后根据中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,获取经重定位后的重定位左视点视频图像,记为其中,重定位左视点视频图像的宽度为w',重定位左视点视频图像的高度为h,1≤x'≤w',1≤y'≤h,表示中坐标位置为(x',y')的像素点的像素值。
同样,根据中的每个四边形网格对应的最佳目标四边形网格的最佳相似变换矩阵,计算中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,将中水平坐标位置为和垂直坐标位置的像素点经最佳相似变换矩阵变换后的水平坐标位置和垂直坐标位置对应记为和然后根据中的每个四边形网格中的每个像素点经最佳相似变换矩形变换后的水平坐标位置和垂直坐标位置,获取经重定位后的重定位右视点视频图像,记为其中,重定位右视点视频图像的宽度为w',重定位右视点视频图像的高度为h,1≤x'≤w',1≤y'≤h,表示中坐标位置为(x',y')的像素点的像素值。
步骤十:令t=t+1;然后将待处理的原始立体视频序列中当前待处理的第t帧左视点视频图像和第t帧右视点视频图像对应作为当前左视点视频图像和当前右视点视频图像;再返回步骤二继续执行,直至获得待处理的原始立体视频序列中的前t-1帧左视点视频图像对应的重定位左视点视频图像和前t-1帧右视点视频图像对应的重定位右视点视频图像,进而得到包含t-1帧重定位左视点视频图像和t-1帧重定位右视点视频图像的重定位立体视频序列;其中,t=t+1中的“=”为赋值符号。
以下就利用本发明方法对韩国科学技术院ivylab提供的数据库中的video1、video2、video3和video4四组立体视频序列进行重定位实验。图2a给出了“videol”立体视频序列的第1时刻的原始立体图像的“红/绿”图,图2b给出了“videol”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图2c给出了“videol”立体视频序列的第2时刻的原始立体图像的“红/绿”图,图2d给出了“videol”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图2e给出了“videol”立体视频序列的第3时刻的原始立体图像的“红/绿”图,图2f给出了“videol”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图2g给出了“videol”立体视频序列的第4时刻的原始立体图像的“红/绿”图,图2h给出了“videol”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;图3a给出了“video2”立体视频序列的第1时刻的原始立体图像的“红/绿”图,图3b给出了“video2”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图3c给出了“video2”立体视频序列的第2时刻的原始立体图像的“红/绿”图,图3d给出了“video2”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图3e给出了“video2”立体视频序列的第3时刻的原始立体图像的“红/绿”图,图3f给出了“video2”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图3g给出了“video2”立体视频序列的第4时刻的原始立体图像的“红/绿”图,图3h给出了“video2”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;图4a给出了“video3”立体视频序列的第1时刻的原始立体图像的“红/绿”图,图4b给出了“video3”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图4c给出了“video3”立体视频序列的第2时刻的原始立体图像的“红/绿”图,图4d给出了“video3”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图4e给出了“video3”立体视频序列的第3时刻的原始立体图像的“红/绿”图,图4f给出了“video3”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图4g给出了“video3”立体视频序列的第4时刻的原始立体图像的“红/绿”图,图4h给出了“video3”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图;图5a给出了“video4”立体视频序列的第1时刻的原始立体图像的“红/绿”图,图5b给出了“video4”立体视频序列的第1时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图5c给出了“video4”立体视频序列的第2时刻的原始立体图像的“红/绿”图,图5d给出了“video4”立体视频序列的第2时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图5e给出了“video4”立体视频序列的第3时刻的原始立体图像的“红/绿”图,图5f给出了“video4”立体视频序列的第3时刻的重定位到原始立体图像的宽度60%后的“红/绿”图,图5g给出了“video4”立体视频序列的第4时刻的原始立体图像的“红/绿”图,图5h给出了“video4”立体视频序列的第4时刻的重定位到原始立体图像的宽度60%后的“红/绿”图。从图2a至图5h中可以看出,采用本发明方法得到的重定位立体视频图像能够较好地保留重要的显著语义信息,同时又能保证时域一致性。