一种基于海量小文件高并发情况下动态负载均衡方法与流程
本发明涉及为网络负载均衡方法,特别是涉及一种处理分布式小文件存储系统在高并发访问情况下的负载均衡方法,属于一种分布式文件系统存储访问的资源调度技术。
背景技术:
随着移动互联网的高速发展和越来越普及,人们即将进入万物互联的时代。每天都会产生海量的移动数据信息,特别是近些年不断兴起的短视频社交app和电商app,这些app每天都会产生大量的短视频和图片,它们的数据占用空间相对较小,一般都在几十kb左右,最高也就几十m。
然而我们所熟知的例如hdfs、gfs等分布式文件存储系统都是针对大文件的,它们自身虽然带有负载均衡机制,主要是用来解决不同数据服务器节点的数据块的分配和调度问题,并非用来解决在高并发情况下的海量小文件访问问题。分布式文件系统fastdfs是针对海量小文件存储访问专门设计的分布式文件存储系统,但是其提供的负载均衡算法是基于轮询的负载均衡算法。轮询算法只是机械的将用户请求按顺序轮流地分配到后端存储服务器上,没有考虑后端服务器节点的本身的性能和实时负载,在实际应用中其可靠性往往很差。而当前的一些常见的负载均衡算法:
1)加权轮询:是轮询调度算法的升级版,这种负载均衡算法在开始时给每个服务器分配一个权重值,这个权重值是按照服务器自身性能来确定的,性能越高其权重值就越大。调度器按照服务器的权重值比例来分配请求,权重值高的被分配到更多的请求,权重值低的则相反。由于服务器权重值不能根据服务器的实时负载情况动态的改变,这种方法运行过程中会出现过载的服务器仍然被分配请求导致用户请求处理失败甚至服务器宕机。
2)最少连接数:调度器会记录后端服务器在某端口上的连接数即正在处理请求的数量,每次会把新请求分配给连接数最少的服务器。这种分配算法在分布式系统中后端服务器的处理能力相同的情况下一般工作较好。但是实际的分布式系统一般是异构网络,该分配方法在这种情况下没有考虑服务器的性能和负载情况,性能可能会急剧下降。
3)最快响应时间:调度器根据后端服务器的响应时间来智能的进行请求分配,响应时间短的服务器将优先分配请求。由于该响应时间一般是调度器对后端服务器节点发送一个探测请求来获得,因此该响应时间具有滞后性,不能反映真实的情况。
技术实现要素:
本发明根据现有的分布式文件存储系统自身在处理高并发访问情况下存在的不足,同时现有的负载均衡方法也同样不适用高并发小文件访问情况,提供针对分布式文件系统fastdfs的海量小文件高并发访问的动态自适应负载均衡调度方法。
本发明基于海量小文件高并发情况下动态负载均衡方法通过采集后端数据服务器节点的负载信息,并根据负载信息动态调整它们的权重值,从而充分合理利用后端服务器的资源。
本发明目的通过如下技术方案实现:
一种基于海量小文件高并发情况下动态负载均衡方法,包括于如下步骤:
1)数据服务器集群中每个节点都开启一个定时任务,定期收集其各个资源的利用情况,资源利用情况包括cpu利用率ucpu、内存利用率umem、磁盘io利用率uio和网络带宽利用率unet;以di表示数据服务器集群中的第i个节点,第i个节点di的cpu利用率ucpu(i)计算方法为:
第i个节点di的内存利用率umem(i)计算为:
第i个节点di的磁盘i/o利用率为uio(i);
第i个节点di的网络带宽利用率
2)数据服务器节点把自身的ucpu、umem、uio和unet发送给调度服务器;
3)调度服务器收到数据服务器节点的ucpu、umem、uio和unet之后使用如下公式来计算每一个数据服务器节点的负载值loadi:
loadi=r1×ucpu(i)+r2×umem(i)+r3×uio(i)+r4×unet(i);
其中r1,r2,r3,r4分别是cpu、内存、磁盘i/o和网络带宽影响因子,且满足i∈{1,2,3,4},
4)在后端数据服务器节点开始运行时,根据第i个节点的硬件配置信息给第i个节点初始的权重值wi,wi表示数据服务器集群中的第i个节点的权重值;
5)数据服务器节点的实时权重值wi用如下公式进行计算求得:
所述的
6)调度器节点根据计算出来各个数据服务器节点的实时权重值动态的改变请求任务的分配,权重值高的会收到较多的请求,权重低的收到较少的请求。
为进一步实现本发明目的,优选地,所述的
优选地,所述的muse和mtotal通过读取linux下的虚拟文件/proc/meminfo计算得到。
优选地,所述的uio(i)直接在linux中执行iostat-x-dsda命令获取;这个命令执行后会得到一个%util参数值,该值表示当前时间系统磁盘io的使用率;
优选地,所述的
优选地,所述的netmax利用ethtool工具获取。
优选地,所述的第i个节点初始的权重值wi的调整范围为[wmin,wmax],其中wmin=0,wmax=max(wi);max(wi)为理想负载值,理想负载值loadbest∈[0.7,0.8]。
优选地,所述的
为了更好的达到本发明的目的,在计算负载值时需要确定ucpu、umem、uio和unet的重要性系数r1,r2,r3和r4的值。这里采用apachebenchmark测试工具对数据服务器集群进行多组压力测试并收集每次的测试结果,这里包括平均请求响应时间和系统吞吐量;同时利用topsis综合评价法进行统计分析,得出最佳的各项指标比例系数值。优选地,所述的r1,r2,r3,r4通过如下步骤确定:
(1)给r1,r2,r3和r4一个初始值,然后用apachebenchmark进行压力测试;
(2)收集每次的测试结果;
(3)将多次的测试结果组成一个矩阵d;
(4)对矩阵中的数据进行归一化处理得到决策矩阵z;
(5)对矩阵进行加权处理,得到加权决策矩阵v;
(6)确定理想解和负理想解,即在每次的测试结果中选出最大值和最小值;
(7)计算每次的测试结果到理想点的距离d+和负理想点的距离d-,定义
优选地,所述的r1,r2,r3和r4的初始值设定分别为:r1=0.2,r2=0.25,r3=0.3,r4=0.25。
相对于现有技术,本发明优点在于:
1)相比于现有分布式文件系统本身的提供的负载均衡算法,本发明充分考虑了后端数据服务器节点的实时负载能力,并根据其来动态调整其权重值;
2)本发明采集了后端数据服务器节点的多项指标,各项指标的重要系数可以根据实际情况来进行调整,使得计算出的权重值更加贴合其实际情况。
附图说明
图1为本发明的获得数据服务器节点各项指标比例参数的理想值的过程图。
图2为本发明分布式文件存储系统下的负载均衡算法执行的总体流程图。
图3为本发明的海量小文件存储访问系统架构图。
图4为本发明的方法与加权轮询负载均衡算法的请求处理时间的对比图。
图5位本发明的方法与加权轮询负载均衡算法的系统吞吐率的对比图。
具体实施方式
为了更好的理解本发明,下面结合附图和实施例来对本发明做进一步的讲解说明,但本发明的实施方式不限于实施例表示的范围:
实施例
本实施例是使用分布式文件存储系统fastdfs来存储海量小文件,在访问过程中主要涉及到文件的读写,为i/o密集型任务。因此在高并发读取小文件的情况下系统性能主要由以下几个因素来决定:1)频繁读取文件会导致系统进行频繁的磁盘i/o操作,因此对磁盘i/o的性能要求很高;2)在文件读写过程中系统内存与磁盘会进行大量数据交互,会缓存大量文件内容到系统内存中,导致内存占用过高,因此内存也对系统性能起到重要作用;3)客户端请求的文件需要存储节点通过网络进行传输,高并发情况下需要传输大量文件数据,因此网络带宽是影响数据高效传输的重要因素;4)高并发访问文件会导致cpu频繁的进行上下文切换,cpu的利用率也会对系统性能产生一定影响。总的来说在高并发小文件读取情况下内存、磁盘i/o利用率和网络带宽对系统性能起到关键作用,因此这三个动态指标的系数r2,r3,r4较高,r1较低。r1,r2,r3和r4分别是ucpu、umem、uio和unet的重要性系数;ucpu、umem、uio和unet分别是cpu利用率、内存利用率、磁盘i/o利用率和网络带宽利用率。
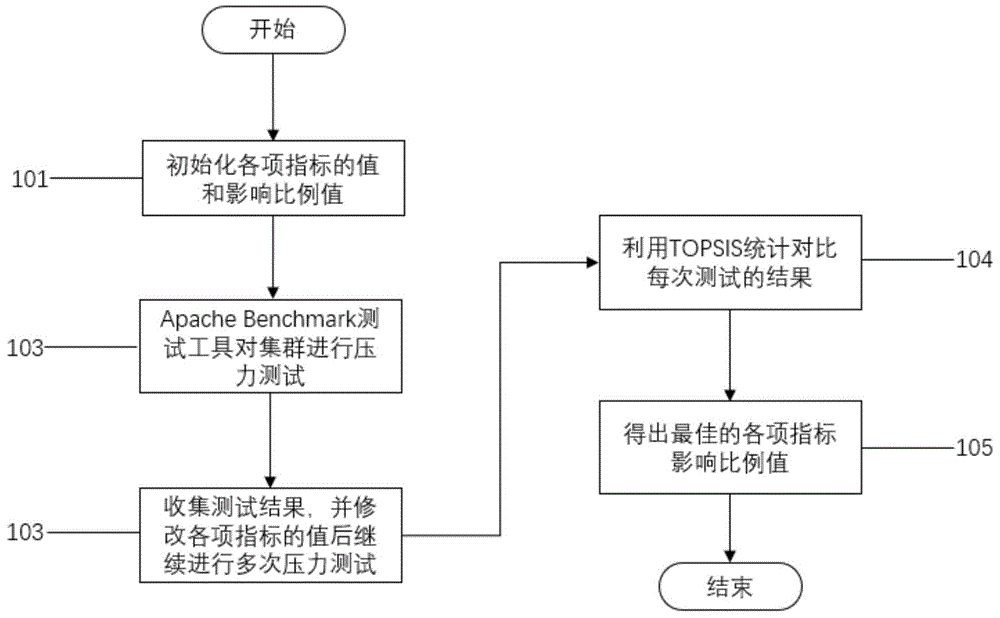
图1为计算数据服务器节点负载时各项指标的影响比例的理想值和调整权重时的两个用于收敛的系数值,具体来讲,可以分为以下几个步骤:
步骤101,首先根据数据服务器的配置,例如根据cpu个数,频率、内存大小等情况给ucpu、umem、uio和unet的重要性系数r1,r2,r3和r4一个初始权值,其中,r1=0.2,r2=0.25,r3=0.3,r4=0.25;
步骤102,利用apachebenchmark测试工具对分布式文件系统fastdfs进行压力测试,并收集测试结果;
步骤103,调整并修改服务器数据节点各项指标的系数值后继续用apachebenchmark测试工具多次压力测试;
步骤104,经过多次压力测试后,通过统计分析对比每次测试的结果;
这里假设进行了m次测试,每次有n个测试结果,将其组成矩阵d:
将矩阵中的数据进行归一化处理并得到决策矩阵z:
令wj为第j个指标的权值,表示第j和指标的重要性程度,则继续构造加权决策矩阵v:
vij=wj×rij,i=1,2,...,m,j=1,2,...,n
确定理想解v+和负理想解v-,即加权决策矩阵v中vij越大表示测试结果越好:
对测试结果进行评价:
ci越大表示第i次测试结果越好,则表示此时选定的各项指标参数越优;
步骤105,得出最佳的各项指标影响比例值,经过多次压测并把每次的测试结果收集起来用上述topsis流程进行确定最优解,得出各项指标的比例系数值分别为r1=0.15,r2=0.3,r3=0.35,r4=0.2。
如图2为分布式文件存储系统下的负载均衡算法执行的总体流程图,具体步骤包括:
步骤201,数据服务器集群中每个节点都开启一个定时任务,定期收集其各个资源的利用情况,资源利用情况包括cpu利用率ucpu、内存利用率umem、磁盘io利用率uio和网络带宽利用率unet;以di表示数据服务器集群中的第i个节点,第i个节点di的cpu利用率ucpu(i)计算方法为:
第i个节点di的内存利用率umem(i)计算为:
第i个节点di的磁盘i/o利用率为uio(i);
第i个节点di的网络带宽利用率
调度器节点利用linux操作系统中socket编程中的epoll多路复用技术,通过监听9999端口,后端数据服务器节点都会与其进行连接;
步骤202,后端服务器节点都会定期把自己的cpu利用率、内存利用率、磁盘io利用率和连接数等指标信息通过连接发给调度器;
步骤203,调度器收到各个数据服务器节点的指标信息后,先计算出其负载值,在计算出其权重值:
loadi=0.15×ucpu(i)+0.3×umem(i)+0.35×uio(i)+0.2×unet(i),=1,2,...,n
本发明
步骤204,调度器在计算出后端数据服务器节点的权重值后,就根据权值动态改变请求分发策略即权值大的会被分配更多的请求,权值小的会被分配到少量请求甚至不会进行分配请求:
假设后端有三台服务器s1、s2和s3,它们的权重值在运行过程中被调度器动态改变为4、2和1,那么在调度器收到7个请求时,调度器的具体分配过程如下表所示
从表中可以看出这7个请求的分配顺序是s1,s2,s1,s3,s1,s2,s1,不会出现连续的请求都分配到同一个节点的情况,而且这个7个请求中s1被分配4次,s2被分配2次,s3被分配1次,调度器分配比较合理而且很平滑;
步骤205,调度器判断是否继续采集数据服务器节点的指标信息,如果继续采集那么跳转到步骤203,否则将执行退出程序。
此外,考虑到数据服务器节点是定期即每隔一段时间t就把自身的各项指标信息发送给调度器,但是这个时间间隔t不宜过短,过短会导致数据服务器节点频繁的获取器各项指标信息,这样会对其处理读取文件请求造成性能影响,同时也会导致调度器频繁的计算权重和调整权重,这样也会对调度器增加大量负担。同理时间t也不宜过长,过长的会造成一定的延迟性以至于调度器采集到数据服务器各项指标信息不够准确,无法反映真实的数据服务器集群的负载情况。这个根据数据服务器节点具体情况设定时间t即可。
图3为实施例中的海量小文件存储访问系统的总体架构图,其包括用户访问层、数据访问层和数据存储层。数据访问层主要是对用户的访问进行代理,其既服务于上层的用户访问层,而且也衔接着下层的数据存储层,在应对高并发小文件访问请求时,可以根据数据存储层中存储节点的负载情况进行合理调度。
本发明方法是用以下指标来评价其性能:
1)请求处理时间:对于用户来讲,请求处理时间是指用户发送请求到请求完成所需的时间,该值反映了服务器对于用户的服务质量,该值越小对于用户的体验更好。
2)系统吞吐率:对于系统来讲,吞吐率是指单位时间内在网络上进行传输的数据总量,或者说是指在单位时间内系统处理用户的请求数,是衡量系统性能的重要指标,通常可以用请求数/s来进行衡量。
进一步的,为了更加直观的体现本发明算法在实际运行过程中对高并发海量小文件访问所带来的性能提升,本实施例还利用静态的加权轮询负载算法和本发明方法进行对比,如图4所示为不同并发量下请求处理时间的对比图,可以看出在并发访问量较小的时候本发明的算法和加权轮询负载均衡算法的平均响应时间差不多,甚至加权负载均衡算法的性能会稍高一点。这是因为此时的系统负载较低,还没达到性能瓶颈,反映到后端各个文件服务器节点资源利用率还不是很高。而本发明需要定期的收集各节点的资源利用信息并计算权值,这会给调度器带来一定的负担。但是随着并发访问量的增加,大量的文件访问请求导致系统负载增加,而此时加权轮询负载均衡算法并不关心后端各节点的实时负载,只是固定的按照开始设定的权值将任务分配给各节点。本发明充分考虑了影响后端节点性能的动态因素,并周期性的反馈给调度器,在负载值较低的时候,缓慢的提升其权值,调度器获取后端节点的负载情况更加准确,同时也不会频繁的更改其权值,可以更好的根据实际情况分配任务,在相同的高并发请求量情况下有更好的性能表现。
图5所示为不同并发访问量下的吞吐率的对比图,可以看出在并发访问量不高的时候两种方法的性能表现基本差不多,但是随着并发访问量增加,本发明的方法性能表现更好。这是因为加权轮询算法在分配任务时没有考虑分布式系统各节点的实时负载状态,不能根据各节点的负载程度均衡的分配任务,导致负载高的节点积累的任务过多而使大量请求长时间得不到处理甚至请求超时而降低系统吞吐量。而本发明充分考虑了影响后端节点性能的动态因素和集群的异构情况,并周期性的反馈给调度器,所以调度器获取系统各节点的负载情况更加准确,可以更好的根据实际情况合理的分配任务,在相同的高并发访问量情况下有更高的吞吐量,应用到小文件分布式存储系统中,能够带来更快的文件访问速度。
本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!