一种基于意图的云网资源服务链编排方法及系统与流程
本发明涉及通信技术领域,尤其涉及一种基于意图的云网资源服务链编排方法及系统。
背景技术:
具有不同qos要求的物联网服务的快速增长给网络运营商带来了快速交付和qos保证方面的巨大挑战。网络功能虚拟化(networkfunctionvirtualization,nfv)和软件定义网络(softwaredefinednetworking,sdn)已成为灵活资源分配和动态服务供应的关键技术。但是,这两种技术仍然需要应用手动操作来定义服务模型和配置网络细节,进而需要高技能的管理员和大量的时间。这些手动任务对提高可靠性和快速提供服务有不利作用。因此,提出了基于意图的网络(theintentbasednetworking,ibn)以简化低级配置并加快服务交付。
支持基于意图的服务供应的一个关键方面是与供应商无关且与技术无关的北向接口(northboundinterface,nbi),用于将客户语言转换为服务链(servicefunctionchain,sfc)的抽象定义。另一个关键步骤是基于sfc模型的抽象定义的在线编排,以实现需求驱动,自动调整的服务交付方式。
然而上述方法仍需要提前获得完整的网络细节以获得全局最优解,但这些准确的信息通常难以收集。因此现在亟需一种基于意图的云网资源服务链编排方法来解决上述问题。
技术实现要素:
为了解决上述问题,本发明实施例提供一种克服上述问题或者至少部分地解决上述问题的一种基于意图的云网资源服务链编排方法及系统。
第一方面本发明实施例提供一种基于意图的云网资源服务链编排方法,包括:
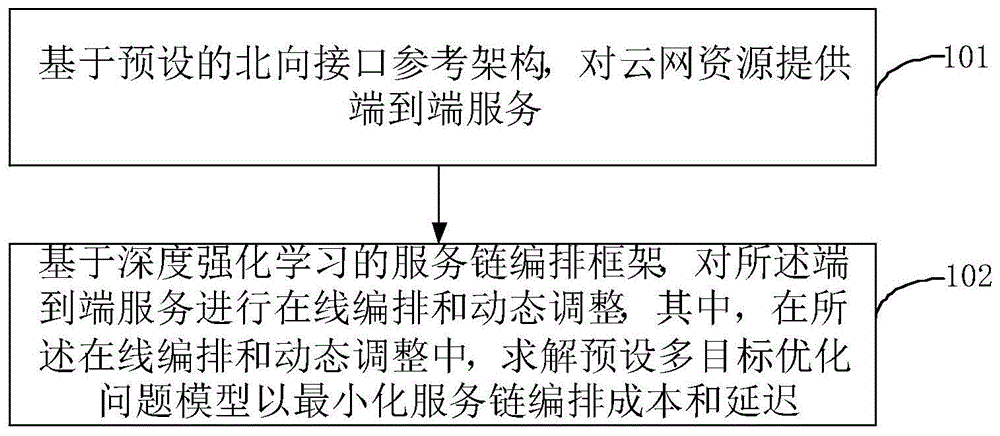
基于预设的北向接口参考架构,对云网资源提供端到端服务;
基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
其中,所述多目标优化问题模型表示为:
min{cost(server)+cost(link)}
其中,cost(server)为服务器资源的相关成本、cost(link)流量转发的成本,c1,c2,c3,c4,c5,c6,c7为资源约束条件。
其中,所述求解预设多目标优化问题模型以最小化服务链编排成本和延迟,包括:
基于预设的双层深度q网络算法获取所述多目标优化问题模型的最优解。
其中,所述基于预设的双层深度q网络算法获取所述多目标优化问题模型的最优解,包括:
对业务流程进行初始化;
基于预设的双层深度q网络,对初始化后的业务流程进行业务编排。
其中,所述对业务流程进行初始化,包括:
从云服务器集中随机选择满足要求的目标方案;
基于最短路径选择算法,确定vnf之间的目标路由方案;
计算所有服务链的编排费用。
其中,所述基于预设的双层深度q网络,对初始化后的业务流程进行业务编排,包括:
状态空间初始化后向双层深度q网络输入状态;
获取输入状态对应的动作并计算目标q值;
基于梯度下降法更新输入状态直至达到预设的终止条件。
第二方面本发明实施例还提供一种基于意图的云网资源服务链编排系统,包括:
服务模块,用于基于预设的北向接口参考架构,对云网资源提供端到端服务;
编排调整模块,用于基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
第三方面本发明实施例提供了一种电子设备,包括:
处理器、存储器、通信接口和总线;其中,所述处理器、存储器、通信接口通过所述总线完成相互间的通信;所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令能够执行上述基于意图的云网资源服务链编排方法。
第四方面本发明实施例提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述基于意图的云网资源服务链编排方法。
本发明实施例提供的一种基于意图的云网资源服务链编排方法及系统,通过提供预设的北向接口参考架构和基于drl的sfc编排框架,并构建了一个多目标优化问题模型,以最大限度地降低长期服务链编排成本。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种基于意图的云网资源服务链编排方法流程示意图;
图2是本发明实施例提供的不同学习速率下的训练步数示意图;
图3是本发明实施例提供的不同算法下的训练步数示意图;
图4是本发明实施例提供的不同算法的平均时延示意图;
图5是本发明实施例提供的不同算法的总成本示意图;
图6是本发明实施例提供的一种基于意图的云网资源服务链编排系统结构示意图;
图7是本发明实施例提供的电子设备的结构框图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1是本发明实施例提供的一种基于意图的云网资源服务链编排方法流程示意图,如图1所示,包括:
101、基于预设的北向接口参考架构,对云网资源提供端到端服务;
102、基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
需要说明的是,本发明实施例的应用场景是在于物联网中如何实现对云网资源的服务链编排,在此场景下,本发明实施例提出了一个ibn参考架构来管理物联网基础设施并跨多个域提供端到端服务。具体的,在步骤101中,本发明实施例提供的ibn参考架构包括:vnf管理器(vnfmanager,vnfm)和nfv编排器(nfvorchestrator,nfvo)、管理和控制平面以及数据平面。vnf管理器和nfv编排器用于允许客户使用人类可读语言声明ir,然后通过基于意图的nbi将声明性策略转换为高级服务抽象,例如vnf性质,qos功能和阈值。管理和控制平面包括虚拟化基础架构管理器(vim)和控制器,vim将高级抽象策略映射为低级服务链编排策略,协调sdn_c和云控制器(cloud_c)以自动化sfc编排。数据平面用于通过南向接口(southboundinterface,sbi)接收控制消息,并为云域中的vnf放置和流量路由提供物理资源,而物联网域的传感器和执行器负责数据收集。那么通过上述本发明实施例所提供的ibn参考架构能够实现管理物联网基础设施并跨多个域提供端到端服务。
进一步的,在步骤102中,本发明实施例提供了一种基于深度强化学习的服务链编排框架,即基于drl的sfc编排框架。该drl的sfc编排框架可以通过基于意图的nbi和网络学习模型获得sfc抽象模型和环境细节。然后基于drl的sfc编排框架能够协调控制器,通过技术特定的sbi实现当前网络的相应动作,同时,网络提供有关奖励或惩罚的反馈,以促使drl的sfc编排框架调整其行为,经过有效的训练使得drl的sfc编排框架实现最优策略,该最优策略即本发明实施例所需的云网资源服务链编排方案。其中,在获取最优策略的过程中,本发明实施例建立了一个多目标优化问题模型来最小化sfc编排成本和延迟,通过对该多目标优化问题模型的最优求解得到最终所需的云网资源服务链编排方案。
其中,在本发明实施例建立的多目标优化问题模型中,sfc由三元组s={(vso,vde)s,fs,rs}表示,其中(vso,vde)s表示s的源节点对和目标节点对。vso生成具有数据传输速率为rs的流量。fs表示特定的sfc信息,包括vnf的属性,顺序和连通性。云服务器中所需的cpu,内存资源和vnf的f∈fs的处理延迟由cpuf,memf和df表示。vnf的u和w之间的虚拟链接由
那么云域的物理网络由加权无向图g=(n,l)表示,其中n和l分别表示节点和有线链路。节点分为两类:第一类为用于转发流量的交换机,第二类为用于托管虚拟机v∈v的云服务器。服务器和链接的数量用m和h表示。云服务器v具有用于放置vnf实例的cpu计算和内存资源,这些实例分别由capcpu(v)和capmem(v)表示。节点i和j之间的物理链路lij具有最大数据传输速率bij和传输延迟dij。
vnf实例需要cpu计算资源和云服务器中的内存资源。需要考虑负载均衡,因为维护服务器和链路之间的负载均衡可以避免流量拥塞并进一步提高网络成本效率。因此,本发明实施例提出了两个负载均衡因子φv和θij,用于指示网络的负载状态,它们的值与资源使用率有正相关关系。φv计算如下:
其中α1,β1,χ1是正参数,用于调整成本计算过程中φv的值。φv是uv的线性函数还是指数函数是否取决于uv的范围。uv表示cpu和内存使用率的加权和,由下式计算:
其中,ep和em代表cpu和内存使用率的权重,ep+em=1。服务器资源的相关成本由下式计算:
cpu和内存资源的单价分别用c1和c2表示。接下来考虑流量路由中的转发成本,负载平衡因子θij计算如下:
其中α2,β2,χ2是正参数并用于调整θij的值。uij表示链路lij中传输速率的使用率,计算方式如下:
流量转发的成本计算方式如下:
其中,c3表示链路传输速率的单价。(el·θij+ed·dij/ds)代表θij的加权和延迟dij,el+ed=1。cost(link)由三部分组成:θij,固定延迟dij和单价。从上述计算式可以看出,具有较大剩余资源的节点或链路具有相对较低的成本。
sfc编排流程的总成本cost_total计算如下:
cost_total=cost(server)+cost(link);
资源约束由下式得到:
延迟约束由下式得到:
从而建立了旨在提高成本效率和保证qos的多目标优化问题模型:
min{cost(server)+cost(link)}
本发明实施例提供的一种基于意图的云网资源服务链编排方法及系统,通过提供预设的北向接口参考架构和基于drl的sfc编排框架,并构建了一个多目标优化问题模型,以最大限度地降低长期服务链编排成本。
在上述实施例的基础上,所述求解预设多目标优化问题模型以最小化服务链编排成本和延迟,包括:
基于预设的双层深度q网络(ddqn)算法获取所述多目标优化问题模型的最优解。
针对上述实施例中提出的多目标优化问题模型,本发明实施例设计了一个双层深度q网络算法来求出多目标优化问题模型的最优解。
具体的,本发明实施例将优化问题被表述为马尔可夫决策过程{st,a,rd,p},其中st表示状态空间,a表示动作空间,rd被定义为奖励函数,p是状态转移概率。定义如下:
状态空间为:每个代理在某个时刻都有相应的编排方案。该状态被定义为所有sfc的qos要求的满足程度,并由下式计算:
st={st1,sts,...,stk};
其中,sts={0,1},k是sfc的数量。sts=1表示在当前的编排方案下sfc的延迟要求能够得到满足。否则,sts=0。所有状态的数量是2k。
动作空间为:sfc的两个状态之间的转换表示通过采取动作来改变vnf的放置或路由。动作集a定义如下式所示:
其中,x被设计为sfc业务流程中vnf放置的可用动作集。另外,如果给出x,则可以通过最短路径算法获得vnf之间的路由。
y被设计为vnf之间的流量路由的可用动作集。因此,vnf放置和流量路由的操作空间表示为a={x,y}。s的动作数为2m+h。
奖励为:如果代理人采取某种行动,状态sts将转移到新的状态st's。代理s也可以获得立即奖励rds(as,st,st'),定义为sts转移到st's时的降低成本。
rds(as,st,st')=cost(sts)-cost(st's);
其中cost(sts)和cost(st's)代表状态sts和st's的编排费用和。通过积累长期奖励rds(as,st,st')可以实现最高的成本效率,根据当前状态,策略π可以获得sfc将采取的相应行动。最佳行动是
其中,γ是折扣因子,表示未来奖励在学习中的重要性。根据bellman方程,可以如下获得最优
ps(as,st,st')表示从状态st到状态st'的转换概率。因此,可以基于上式得到最优策略
在实践中,通常很难获得准确的转换概率。因此,q学习被设计为基于可用信息以迭代方式找到最优解,并且它使用以下等式来更新q值函数:
其中,δ为学习效率,影响到qs(st,a)的更新率。
可以理解的是,q学习基于q值表完成迭代,因此如果状态和动作空间非常大,则很难获得最优解。为了克服这个弱点,本发明实施例提供的深度q网络(dqn)通过深度神经网络(dnn)而不是q值表来近似q值函数。dnn可以被视为具有多个处理层的深度图。θ表示这些层的权重,并通过梯度下降更新。dqn使用的值函数的近似值由下式计算:
qs(st,a,θ)≈qs(st,a)。
除此之外,dqn利用经验重放和独立目标网络来消除数据依赖性。定义目标网络以基于权重θ-计算目标q值。θ和θ-之间的差异是θ在每次迭代中更新,但是θ-在固定次数的迭代中更新。目标q值函数由下式给出:
dqn的损失函数定义为均方误差,由下式计算:
l(θ)=e[(target_qs-qs(st,a,θ))2];
在每次迭代中,需要更新权重θ以根据梯度
值得强调的是,dqn和q学习都利用最大函数进行计算target_qs,这导致了高估问题。作为改进,ddqn首先在当前网络中找到具有最大q值的相应动作,而不是直接在目标网络中的所有动作的最大q值:
amax(st',θ)=argmaxa'∈aqs(st',a',θ);
然后使用所选动作amax(st',θ)重写target_qs。ddqn中的新target_qs由下式计算:
类似地,在ddqn中l(θ)和θ'也需要一起更新。
具体的,本发明实施例所提供的双层深度q网络算法可以包括两部分,第一部分为业务流程初始化,业务流程初始化可以包括以下步骤:
1、从σf,s随机选择f∈fs的可行的放置方案
2、通过最短路径算法获得vnf之间的路由方案。
3、计算所有sfc的编排费用。
第二部分为利用ddqn网络的业务编排,该部分可以包括以下步骤:
1、状态空间被初始化为st={st1,sts,...,stk}。
2、对于sfcs,它将sts作为输入添加进q值网络qs(sts,a,θ)。
3、通过ε-greedy策略获取动作。该策略分别以概率ε和1-ε选择随机动作和最佳动作。
4、所有sfc的转换存储在经验重放存储器中。
5、每个代理从er中取样(st,a,rd,st'),并根据是否为最终状态计算其目标q值。
6、它们相对于q值网络的θ执行梯度下降步骤(target_qs-qs(st,a,θ))2。在每ufθ步后,θ被替换为θ。
7、如果当前状态st={1,1,...,1},训练将被终止。
综合上述过程可以看出,本发明实施例设计的ddqn算法能够获取多目标优化问题模型的最优解,且该算法具有更好的成本效率和收敛性,并且可以保证qos要求,使流量均衡。
为了验证本发明实施例所提出方法的性能,本发明实施例进行了仿真实验。具体的,本发明实施例利用由30个节点(10个云服务器和20个交换机)和50个链路组成的云网络对所提算法进行仿真。链路的最大数据传输速率固定为1gbps。链路的传输延迟是1-3ms。服务器的cpu和内存资源分别设置为32和100-200gb。每个sfc需要2-4个vnf,其数据传输速率为20-50mbps。每个vnf需要2-4个cpu和5-10gb内存资源,其处理延迟为2-5ms。dnn的结构包括三个完全连接的神经网络的隐层,具有64、32、32个神经元。主要从算法的收敛性能、优化性能这两方面来进行仿真。
首先在在不同学习率下评估收敛性能:图2是本发明实施例提供的不同学习速率下的训练步数示意图,如图2所示,具有三种学习速率的ddqn算法在episode开始时具有巨大的训练步数。训练步数随着episode的增加而趋于下降,这反映了ddqn的良好收敛性能。另一方面,学习率是收敛性能的关键因素。以ep=90为例,δ=0.001的ddqn需要92个训练步骤。作为比较,δ=0.01和δ=0.1算法只需要40和26步就可以获得最优解。
然后再比较不同强化学习算法下的收敛性能,图3是本发明实施例提供的不同算法下的训练步数示意图,如图3所示。可以看出,q学习在不同episode下具有较低的收敛性能,因为它消除数据依赖性所需的措施较少。相反,dqn和ddqn建立了经验重放和独立目标网络来解决数据相关性,因此他们的训练步骤少于q学习。以q-learning,dqn,ddqn的训练步骤为例,分别为51、32、26。因此,与dqn相比,解决高估问题也是ddqn的优势。
进一步的,本发明实施例用以下两种算法作为对比来评估平均延迟,总奖励和负载平衡状态。qos驱动的布局算法(qpa):它首先获得sfc的端到端路径,然后扩展到路径之上,以最小化成本和延迟,同时满足资源需求。随机拟合放置算法(rpa):vnf的放置以随机拟合的形式执行,从而考虑满足所有约束的所有方案,并随机选择其中一个,然后也随机选择其中的路径。图4是本发明实施例提供的不同算法的平均时延示意图,如图4所示,由于sfc请求的数量很少,因此四种算法的平均延迟在开始时较低。随着sfc的增加,延迟随着不同的幅度而增加。当sfc数量为200时,ddqn,dqn,qpa和rpa的平均延迟分别为38ms,43ms,48ms,56ms。由于rpa的随机性,rpa的延迟性能较差。尽管dqn和qpa将延迟最小化考虑在内,但它们忽略了负载平衡的影响,这可能导致网络拥塞。相比之下,在不同的sfc请求数量下,ddqn具有更好的延迟性能。
图5是本发明实施例提供的不同算法的总成本示意图,如图5所示,在不同数量的sfc下,ddqn,dqn,qpa的总成本总是低于rpa,因为它们都考虑了目标函数的成本最小化。例如,当sfc数量为300时,rpa的成本比qpa,dqn,ddqn高16%,20%,27%。在这三种算法中,ddqn具有最佳的成本效率,因为它克服了高估问题且侧重于负载平衡,qpa和dqn忽略了这一点。因此,ddqn可以在sfc编排过程中获得最佳延迟和成本。
对于负载均衡状态而言,以sfcs=300为例,ddqn链路使用率的方差比rpa,spa和dqn低62%,55%,41%。同样,ddqn服务器使用率的变化也比81%,65%,48%低。在sfc编排优化模型中,φv和θij设计用于维护网络平衡,使得ddqn可以有效避免网络拥塞。
图6是本发明实施例提供的一种基于意图的云网资源服务链编排系统结构示意图,如图6所示,包括:服务模块601和编排调整模块602,其中:
服务模块601用于基于预设的北向接口参考架构,对云网资源提供端到端服务;
编排调整模块602用于基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
具体的如何通过服务模块601和编排调整模块602可用于执行图1所示的基于意图的云网资源服务链编排方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
本发明实施例提供的一种基于意图的云网资源服务链编排系统,通过提供预设的北向接口参考架构和基于drl的sfc编排框架,并构建了一个多目标优化问题模型,以最大限度地降低长期服务链编排成本。
在上述实施例的基础上,所述多目标优化问题模型表示为:
min{cost(server)+cost(link)}
其中,cost(server)为服务器资源的相关成本、cost(link)流量转发的成本,c1,c2,c3,c4,c5,c6,c7为资源约束条件。
在上述实施例的基础上,所述编排调整模块包括:
ddqn单元,用于基于预设的双层深度q网络算法获取所述多目标优化问题模型的最优解。
在上述实施例的基础上,所述ddqn单元包括:
初始化部分,用于对业务流程进行初始化;
业务编排部分,用于基于预设的双层深度q网络,对初始化后的业务流程进行业务编排。
在上述实施例的基础上,所述初始化部分具体用于:
从云服务器集中随机选择满足要求的目标方案;
基于最短路径选择算法,确定vnf之间的目标路由方案;
计算所有服务链的编排费用。
在上述实施例的基础上,所述业务编排部分具体用于:
状态空间初始化后向双层深度q网络输入状态;
获取输入状态对应的动作并计算目标q值;
基于梯度下降法更新输入状态直至达到预设的终止条件。
本发明实施例提供一种电子设备,包括:至少一个处理器;以及与所述处理器通信连接的至少一个存储器,其中:
图7是本发明实施例提供的电子设备的结构框图,参照图7,所述电子设备,包括:处理器(processor)701、通信接口(communicationsinterface)702、存储器(memory)703和总线704,其中,处理器701,通信接口702,存储器703通过总线704完成相互间的通信。处理器701可以调用存储器703中的逻辑指令,以执行如下方法:基于预设的北向接口参考架构,对云网资源提供端到端服务;基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
本发明实施例公开一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所提供的方法,例如包括:基于预设的北向接口参考架构,对云网资源提供端到端服务;基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
本发明实施例提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述各方法实施例所提供的方法,例如包括:基于预设的北向接口参考架构,对云网资源提供端到端服务;基于深度强化学习的服务链编排框架,对所述端到端服务进行在线编排和动态调整,其中,在所述在线编排和动态调整中,求解预设多目标优化问题模型以最小化服务链编排成本和延迟。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行每个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!