一种视频剪辑方法、系统及存储介质与流程
本发明涉及视频处理领域,尤其是一种视频剪辑方法、系统及存储介质。
背景技术:
视频剪辑技术是一种将待剪辑对象(例如静态图像、动态视频)通过剪辑的方式合成一段剪辑视频的视频处理方式,常应用于短视频制作、视频集锦等视频剪辑场景。
传统的视频剪辑技术需要剪辑人员看完整个视频的内容,然后使用手动剪辑的方式将所需的视频片段(如精彩片段、精彩集锦等)剪辑出来。这种视频剪辑的方式需要耗费视频剪辑人员大量的精力和时间,效率低下,尤其是当对无字幕而以语音、对话等为主的视频进行剪辑时,这种方式可能需要剪辑人员重复观看多次视频,熟悉视频内容后才能进行合理的剪辑。此外,若剪辑人员需要对视频中出现的某个对象(如某个文字等)进行定位以便于剪辑时,现有技术往往采用手动拖动视频播放时间轴的进度条(或进度指针等)的方式观看并寻找定位出该对象的出现位置,这种方式容易出现定位不精准的情况(如拖动过头等),需要剪辑人员反复拖动才能定位出该对象的出现位置,降低了视频剪辑的效率,且反复拖动操作也不够便捷,影响了剪辑人员的操作体验。
技术实现要素:
为解决上述技术问题,本发明实施例的目的在于:提供一种效率高和便捷的视频剪辑方法、系统及存储介质。
本发明实施例所采取的第一技术方案是:
一种视频剪辑方法,包括以下步骤:
获取待剪辑的视频数据;
根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑;所述视频播放时间轴的索引根据视频数据的语音识别结果、文字识别结果和图像识别结果中的至少一种生成,所述视频播放时间轴的索引包括文本索引和图像索引中的至少一种,且所述视频播放时间轴的索引还与视频数据的视频帧建立了一一对应关系。
进一步,所述文本索引包括语音识别得到的文字和/或文字识别得到的字幕,所述图像索引包括人物索引、场景索引和物体索引,所述人物索引包括对视频数据进行图像识别得到的人脸图像和/或人脸图像的文字描述,所述场景索引为对视频数据进行图像识别得到的场景,所述物体索引包括对视频数据进行图像识别得到的物体和/或物体的标识。
进一步,所述视频播放时间轴的索引还包括标签索引,所述标签索引包括根据视频数据的语音识别结果或文字识别结果进行出现次数统计及筛选得到的关键词和/或关键词的出现次数。
进一步,还包括以下步骤:
对待剪辑的视频数据进行语音识别、文字识别和图像识别;
根据语音识别的结果、文字识别的结果和图像识别的结果生成视频播放时间轴的索引。
进一步,所述根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑这一步骤,具体包括:
根据视频播放时间轴的索引确定视频剪辑的起始位置和结束位置;
根据视频剪辑的起始位置和结束位置完成待剪辑的视频数据的剪辑操作。
进一步,所述根据视频播放时间轴的索引确定视频剪辑的起始位置和结束位置这一步骤,具体为:
根据视频播放时间轴的索引确定视频剪辑的起始位置,进而结合预设的视频剪辑长度确定视频剪辑的结束位置;
或者,根据视频播放时间轴的索引确定视频剪辑的结束位置,进而结合预设的视频剪辑长度确定视频剪辑的起始位置;
或者,根据视频播放时间轴的索引分别确定视频剪辑的起始位置和结束位置。
本发明实施例所采取的第二技术方案是:
一种视频剪辑系统,包括:
获取模块,用于获取待剪辑的视频数据;
剪辑模块,用于根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑;所述视频播放时间轴的索引根据视频数据的语音识别结果、文字识别结果和图像识别结果中的至少一种生成,所述视频播放时间轴的索引包括文本索引和图像索引中的至少一种,且所述视频播放时间轴的索引还与视频数据的视频帧建立了一一对应关系。
进一步,所述剪辑模块具体包括:
剪辑位置确定单元,用于根据视频播放时间轴的索引确定视频剪辑的起始位置和结束位置;
剪辑单元,用于根据视频剪辑的起始位置和结束位置完成待剪辑的视频数据的剪辑操作。
本发明实施例所采取的第三技术方案是:
一种视频剪辑系统,包括:
至少一个处理器;
至少一个存储器,用于存储至少一个程序;
当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现本发明所述的一种视频剪辑方法。
本发明实施例所采取的第四技术方案是:
一种存储介质,其中存储有处理器可执行的指令,所述处理器可执行的指令在由处理器执行时用于实现本发明所述的一种视频剪辑方法。
上述本发明实施例中的一个或多个技术方案具有如下优点:本发明实施例根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑,通过语音识别结果、文字识别结果和图像识别结果生成的视频播放时间轴的索引来辅助视频剪辑,不再需要剪辑人员看完整个视频的内容或重复观看多次视频就能完成视频剪辑操作,提升了视频剪辑的效率;视频播放时间轴的索引还与视频数据的视频帧建立了一一对应关系,可通过与视频数据的视频帧一一对应的视频播放时间轴的索引直接定位出对应的视频帧以便于剪辑,省去了剪辑人员的反复拖动操作,不仅提升了视频剪辑的效率,而且提升了剪辑人员的操作体验,更加便捷。
附图说明
图1为本发明实施例提供的一种视频剪辑方法流程图;
图2为本发明实施例提供的视频剪辑系统的一种结构框图;
图3为本发明实施例提供的视频剪辑系统的另一种结构框图。
具体实施方式
下面结合说明书附图和具体实施例对本发明做进一步解释和说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
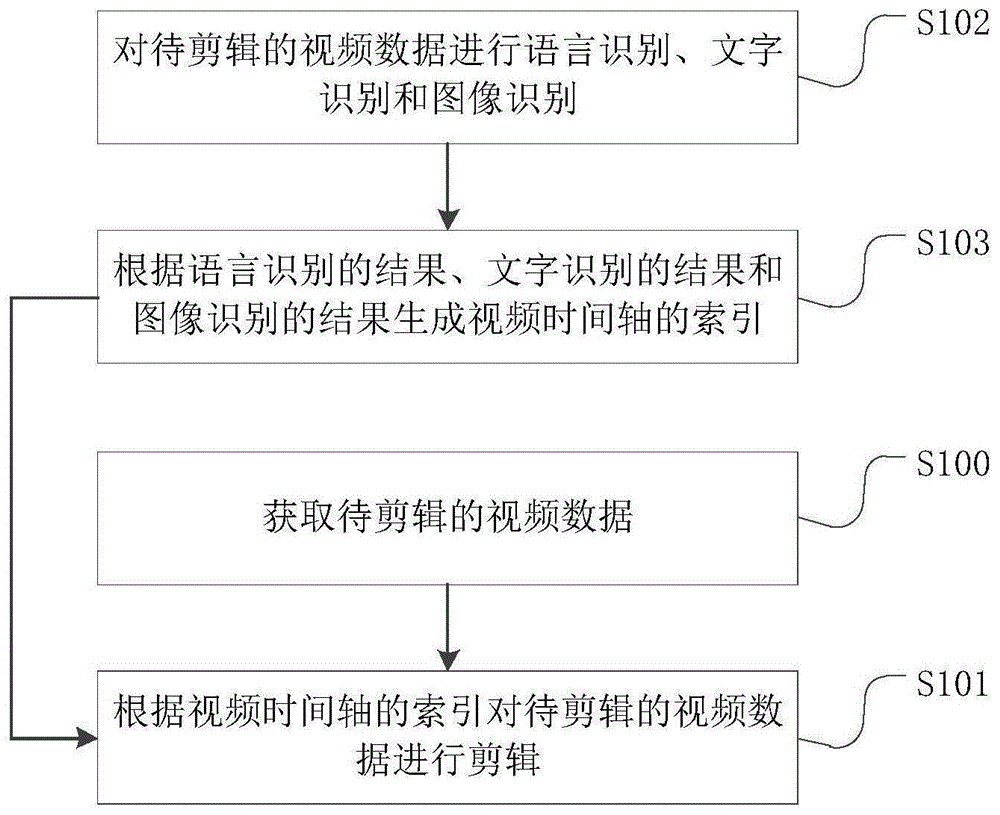
参照图1,本发明实施例提供了一种视频剪辑方法,包括以下步骤:
s100、获取待剪辑的视频数据;
s101、根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑;所述视频播放时间轴的索引根据视频数据的语音识别结果、文字识别结果和图像识别结果中的至少一种生成,所述视频播放时间轴的索引包括文本索引和图像索引中的至少一种,且所述视频播放时间轴的索引还与视频数据的视频帧建立了一一对应关系。
具体地,待剪辑的视频数据可来自电视直播节目、互联网等等。
视频播放时间轴与现有的视频播放时间轴一样,将视频的播放进度与视频数据对应的视频帧关联起来。视频时间轴一般可以设置在视频数据的下方或其他合理的位置。
与传统视频剪辑大多采用手动剪辑方式不同的是,本实施例通过视频剪辑平台(用于作为视频剪辑的工具或界面,主要提供视频的智能识别与索引生成、视频帧的预览、用户的数据输入、根据用户选择的索引确定视频的剪辑位置并生成剪辑后的视频等功能)先对每个视频进行智能识别(包括语音识别、文字识别和图像识别等),然后根据智能识别的结果生成视频播放时间轴的索引,这样用户在进行视频剪辑操作时即可通过鼠标、键盘、触摸输入等方式结合该索引选定所需剪辑的视频片段,从而完成视频剪辑操作。由于本实施例的视频播放时间轴的索引是根据语音识别、文字识别和图像识别的结果生成的并与视频数据的视频帧建立了一一对应关系,这样用户可通过该索引的辅助快速选定所需剪辑的视频片段,实现了视频剪辑的快速、高效和精准操作。
本实施例的视频剪辑平台主要包括智能识别模块、索引生成模块、输入模块、预览模块和剪辑视频生成模块。本实施例的视频剪辑平台可以移植于微信的小程序或网页浏览器,可供用户通过手机等移动终端访问。
其中,智能识别模块用于对各种视频数据进行智能识别,智能识别包括语音识别、文字识别和图像识别。
视频数据的语音识别,主要用于识别视频所包含的语音信息(如语音对话内容、语音介绍内容等等)并将语音识别的结果转换为相应的文字。语音识别的过程可采用现有的声文识别技术来实现。
视频数据的文字识别,主要用于识别视频所包含的文字信息(主要是字幕)。文字识别过程可采用现有的视频字幕识别技术来实现。
视频数据的图像识别,主要用于识别视频所包含的图像信息(如场景、人脸、物体等信息)。图像识别过程可采用现有的图像识别技术来实现。
索引生成模块,用于根据智能识别的结果生成视频播放时间轴的索引。视频播放时间轴的索引包括文本索引(对应语音识别的结果和文字识别的结果)、图像索引(对应图像识别的结果)等。文本索引、图像索引等索引可以采取分列排放的方式设置在待剪辑的视频的一侧,如待剪辑的视频右侧的第一列为文本索引,第二列为图像索引……。
视频播放时间轴的索引与视频数据的视频帧建立一一对应关系是指根据智能识别的结果将视频播放时间轴的索引的内容与视频的视频帧对应起来,即将索引的内容、视频帧和视频帧在视频播放时间轴的时间点(即位置)对应关联起来,这样视频剪辑用户在进行视频剪辑即可通过选择不同索引内容自动跳到视频播放时间轴(与视频内容相对应)的对应位置,省去了用户的手动拖动操作,避免了反复拖动带来的效率低、精度低和不便捷的问题。以视频播放时间轴的索引为文字识别得到的字幕索引为例,该字幕索引包含若干个字幕(如若干个词语),在视频剪辑人员通过鼠标点击等方式选择了该索引中的某个字幕后,视频会自动跳至该字幕对应的视频帧(即视频时间轴对应的时间点或位置)进行播放,同时视频时间轴上的光标(指示进度)也会自动指示对应的时间点,这样视频剪辑用户通过选取索引的不同字幕即可自动跳转至相应的位置,十分方便和快捷。
输入模块,用于提供用户的数据(包括用户的账号和密码、用户选择的视频时间轴的索引内容、剪辑参数等)输入。其中,剪辑参数包括视频剪辑长度(如剪辑时长)、视频的起始时间点和结束时间点等。输入模块可以采用现有的键盘、鼠标等来实现。
预览模块,用于提供视频帧的预览功能。预览模块可采用现有的视频预览技术来实现。预览模块可设置在视频时间轴的下方,便于视频剪辑用户直接预览视频帧,能更好地辅助视频剪辑。
剪辑视频生成模块,用于根据剪辑用户输入的剪辑参数生成剪辑后的视频。本实施例在用户通过输入模块选定剪辑参数后即可从视频中剪辑出用户所需的剪辑视频,十分方便和快捷。
进一步作为优选的实施方式,所述文本索引包括语音识别得到的文字和/或文字识别得到的字幕,所述图像索引包括人物索引、场景索引和物体索引,所述人物索引包括对视频数据进行图像识别得到的人脸图像和/或人脸图像的文字描述,所述场景索引为对视频数据进行图像识别得到的场景,所述物体索引包括对视频数据进行图像识别得到的物体和/或物体的标识。
具体地,文本索引既可以是通过对视频进行语音识别与转换后得到的文字(如新闻或电视节目的主持人与嘉宾的对话内容、主持人语音播报的广告等),也可以是文字识别得到的字幕(如带字幕的新闻或电视节目中主持人或嘉宾的名字、职业、荣誉等的文字介绍、主持人或嘉宾的说话内容等等)。人物索引主要是通过人脸图像识别得到的人脸图像(可以是带人脸的头像,如主持人头像、嘉宾头像等)或相应的文字描述(如主持人名字、嘉宾名字等),可供用户通过选取人脸图像和相应的文字描述中的至少一种来自动使得视频自动跳转至相应的视频帧。场景可以是高山流水、春夏秋冬等,也可以是办公、厨房、会议等场景。物体可以是杯子、笔、话筒等物体,相应地物体的标识可以是杯子、笔、话筒等物体的logo、品牌等。
本实施例通过文字、字幕、人物、场景、物体等不同的索引进一步丰富了索引的种类和内容,为用户提供了更灵活、更精细和更多样化的选择。
进一步作为优选的实施方式,所述视频播放时间轴的索引还包括标签索引,所述标签索引包括根据视频数据的语音识别结果或文字识别结果进行出现次数统计及筛选得到的关键词和/或关键词的出现次数。
具体地,本实施例还可以通过对文字或字幕进行统计和筛选等生成相应的标签,让视频剪辑人员通过该标签即可直观地了解视频所描述的内容,更加便捷。例如,对于带字幕的足球直播视频,可以先通过语音识别和字幕识别(这两种方式识别得到的内容一样)中任一种方式得到视频中出现的所有字幕,然后统计这些字幕出现的次数,最后把出现次数超过特定次数(如10次)的字幕作为标签索引并附加上对应的出现次数展示给剪辑人员。这样,视频剪辑用户通过观看标签索引的内容即可知道该视频属于足球类节目视频,十分直观和方便。
参照图1,进一步作为优选的实施方式,还包括以下步骤:
s102、对待剪辑的视频数据进行语音识别、文字识别和图像识别;
具体地,对待剪辑的视频数据进行语音识别、文字识别和图像识别可调用视频剪辑平台的智能识别模块来实现。
s103、根据语音识别的结果、文字识别的结果和图像识别的结果生成视频播放时间轴的索引。
具体地,视频播放时间轴的索引生成过程可调用视频剪辑平台的索引生成模块来实现。
进一步作为优选的实施方式,所述根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑这一步骤s101,具体包括:
s1011、根据视频播放时间轴的索引确定视频剪辑的起始位置和结束位置;
s1012、根据视频剪辑的起始位置和结束位置完成待剪辑的视频数据的剪辑操作。
具体地,本实施例通过确定视频剪辑的起始位置和结束位置的方式来从待剪辑的视频数据中剪辑出所需的视频数据,视频剪辑的起始位置和结束位置确定后,只要将这两个位置之间的视频数据剪切出来即可完成剪辑操作,十分方便和快捷。
进一步作为优选的实施方式,所述根据视频播放时间轴的索引确定视频剪辑的起始位置和结束位置这一步骤s1011,具体为:
根据视频播放时间轴的索引确定视频剪辑的起始位置,进而结合预设的视频剪辑长度确定视频剪辑的结束位置;
具体地,本实施例的视频编辑人员可以通过选取视频播放时间轴的索引(如文本索引)使得视频跳转至对应的视频帧,并可以以该视频帧在视频播放时间轴的时间点作为视频剪辑的起始位置。确定剪辑的起始位置后,即可根据特定的视频剪辑长度(如剪辑时长为180秒,该长度可通过键盘、触控等方式输入)计算出视频剪辑的结束位置。
或者,根据视频播放时间轴的索引确定视频剪辑的结束位置,进而结合预设的视频剪辑长度确定视频剪辑的起始位置;
具体地,本实施例的视频编辑人员可以通过选取视频播放时间轴的索引(如文本索引)使得视频跳转至对应的视频帧,并可以以该视频帧在视频播放时间轴的时间点作为视频剪辑的结束位置。确定剪辑的结束位置后,即可根据特定的视频剪辑长度(如剪辑时长为180秒,该长度可通过键盘、触控等方式输入)计算出视频剪辑的起始位置。
或者,根据视频播放时间轴的索引分别确定视频剪辑的起始位置和结束位置。
具体地,本实施例的视频编辑人员可以通过选取视频播放时间轴的第一索引(如文本索引)使得视频跳转至对应的第一视频帧,并可以以第一视频帧在视频播放时间轴的时间点作为视频剪辑的起始位置;可通过选取视频播放时间轴的第二索引(如文本索引)使得视频跳转至对应的第二视频帧,并可以以第二视频帧在视频播放时间轴的时间点作为视频剪辑的结束位置。
由上述内容可见,本实施例提供了3种不同的视频剪辑的起始位置和结束位置确定方式,可供剪辑人员根据实际的需要进行灵活的选择,更加方便和灵活。
以待剪辑的视频数据为新闻直播视频(如中央电视台的《新闻30分》)为例,应用本发明的方法进行视频剪辑,其具体实现过程如下:
s1、初始化:新闻直播视频的智能识别及索引生成。
该过程可具体分为以下几个步骤:
s11、将新闻直播视频输入视频剪辑平台;
s12、视频剪辑平台对新闻直播视频进行智能识别,智能识别包括语音识别、文字识别和图像识别;
s13、视频剪辑平台根据智能识别的结果生成视频播放时间轴的索引,所述视频播放时间轴的索引包括文本索引、人物索引和标签索引。
s2、视频剪辑参数的选取;
该过程可具体分为以下几个步骤:
s21、视频剪辑用户通过在输入模块输入账号和密码等方式登录视频剪辑平台;
s22、视频剪辑用户通过输入模块选取待剪辑的新闻直播视频,进入对应的视频剪辑界面;
s23、视频剪辑用户通过文本索引或人物索引选定剪辑的起始位置和结束位置,并在选取过程通过标签索引获取相应的视频信息以及通过预览模块对视频帧进行预览。
s3、根据剪辑的起始位置和结束位置得到剪辑后的新闻直播视频,并将剪辑后的新闻直播视频通过互联网或社交媒体进行分享或发布。
参照图2,本发明实施例提供了一种视频剪辑系统,包括:
获取模块101,用于获取待剪辑的视频数据;
剪辑模块102,用于根据视频播放时间轴的索引对待剪辑的视频数据进行剪辑;所述视频播放时间轴的索引根据视频数据的语音识别结果、文字识别结果和图像识别结果中的至少一种生成,所述视频播放时间轴的索引包括文本索引和图像索引中的至少一种,且所述视频播放时间轴的索引还与视频数据的视频帧建立了一一对应关系。
参照图2,进一步作为优选的实施方式,所述剪辑模块102具体包括:
剪辑位置确定单元1021,用于根据视频播放时间轴的索引确定视频剪辑的起始位置和结束位置;
剪辑单元1022,用于根据视频剪辑的起始位置和结束位置完成待剪辑的视频数据的剪辑操作。
上述方法实施例中的内容均适用于本系统实施例中,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
参照图3,本发明实施例提供了一种视频剪辑系统,包括:
至少一个处理器301;
至少一个存储器302,用于存储至少一个程序;
当所述至少一个程序被所述至少一个处理器301执行,使得所述至少一个处理器301实现本发明所述的一种视频剪辑方法。
上述方法实施例中的内容均适用于本系统实施例中,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法实施例所达到的有益效果也相同。
本发明实施例还提供了一种存储介质,其中存储有处理器可执行的指令,所述处理器可执行的指令在由处理器执行时用于实现本发明所述的一种视频剪辑方法。其中,所述存储介质可为软盘、光盘、dvd、硬盘、闪存、u盘、cf卡、sd卡、mmc卡、sm卡、记忆棒(memorystick)、xd卡等。
以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!