一种攻击组织发现方法及系统与流程
本发明涉及计算机网络安全和大数据领域,具体涉及一种基于web日志的攻击组织发现方法及系统。
背景技术:
随着互联网的发展,越来越多的应用开始架设于web平台之上,但web安全形势却不容乐观,目前web站点的安全问题愈发突出,在过去二十年中,互联网的发展导致了大量可供用户访问的数据。用户与web的交互被记录并存储在web访问日志中。web日志文件记录了各种信息,例如用户ip地址,请求响应时间,请求的资源url,请求方式,请求响应状态码,用户使用的浏览器信息等。攻击组织发现方法是通过从web日志提取所需信息后使用数据挖掘技术自动发现攻击组织的一种方法。由于web日志的上述特性,在入侵原因分析的过程中,对web日志的分析成为必不可少的一步,但是这些日志的数据量过于庞大冗余、分散独立、错漏混杂,命中率低、反应滞后,很难直接作为准确安全反应的触发性事件。
对于安全事件发生以后,找出入侵原因、网站存在漏洞,及时止损、预防下次攻击,以及对攻击组织进行定位是件非常重要的工作,由于攻击行为的个性化较强,日志数据量量大且杂,因此目前的攻击组织发现技术主要靠人工去进行分析验证,在这方面需要耗费大量的人力资源,自动化工具和机器学习的方法使用较少。对于实现日志自动化分析的产品,又没有办法将攻击组或攻击组织进行关联分析。
在攻击者进行网站攻击时,产生的web日志中包含了攻击者的ip,攻击时间,攻击目标,payload,useragent等信息,对于同一个攻击者或者攻击组织在进行网站攻击时,可能使用不同的ip地址或者浏览器等,但同一个攻击者的不同攻击中,总会存在一定的特性使之关联,攻击组织发现方法通过对海量数据进行综合分析和处理,揭示出其中隐藏的逻辑关联,从而定位到攻击者或攻击组织,以此对网络攻击进行预防和响应,实现对整个网络安全态势的有效监控。
技术实现要素:
针对上述问题,本发明提出了一种攻击组织的发现方法及系统,通过对web日志中的关键信息进行提取,进一步对攻击者/攻击组织进行关联。
为达到上述目的,本发明采取的具体技术方案是:
一种攻击组织发现方法,包括以下步骤:
1)获取待处理的web日志,对web日志中的关键特征进行提取,对所提取的特征进行预处理;
2)用affinitypropagation(ap)聚类方法对上述特征中的连续性特征,即无标签特征,进行单独聚类,将标签化处理后得到的结果与有标签特征合并;
3)根据每个特征在使用时的重要性,给标签特征赋予不同的权值,对比不同ip间特征值是否相同,对特征值相同的权值进行累加,得到最后的群体分值;
4)根据不同ip的群体分值得分情况,当分值高于预设阈值时,认定该群体内的ip为同一攻击者/攻击组织。
进一步地,步骤1)中所述预处理包括:检查数据的规范性与完整性,根据设定的数据格式,删除不符合该数据格式的冗余内容,将数据转换成计算机可读的形式。
进一步地,步骤2)中所述有标签特征包括攻击类型、总攻击日志条数/攻击类型数、域名领域、具体域名目标、时间段、post的tf-idf值、url的tf-idf值共七个;所述无标签特征包括ip-b段、ip-c段、post用词相似度、get用词相似度共四个。
进一步地,步骤2)中无标签的特征分别进行ap聚类后生成一个新的特征向量,向量中的内容为该ip的不同特征聚类结果编号;这里的聚类方法使用ap的原因是ap算法将全部恶意ip看作网络的节点,利用吸引度和归属度进行网络节点之间的信息传递,无需指定聚类个数,适合于大量簇,簇大小不均匀,簇边界不规则的情况,对初始值不敏感,不需要进行随机选取初值,算法误差平方和更小。
进一步地,步骤3)所述重要性是指特征对聚类结果准确性的影响程度,例如get用词模式,同一个攻击者在构造有效载荷(payload)时,经常会带有一些个人特性的标签,比如常用字符,那么通过常用字符来关联一个人具有很高的可信度,因此get用词模式就具有较高的重要性;权值的赋值范围一般为0-5,具体地,各个特征的权值设置规则如下:
攻击类型,为攻击者使用一个ip进行攻击的攻击方法数量,对于攻击能力强的攻击者,可以尝试多种攻击,而攻击能力弱的攻击者,可能只掌握少数攻击方法,因此攻击类型可以作为一个特征,但由于可能会出现攻击一次成功或有些网站并不存在多类型漏洞,所以该特征的重要性较低,建议该特征的权重值设置为0.8-1.5之间;
总攻击日志条数/攻击类型数,为攻击者使用一个ip进行攻击的总攻击日志条数除以攻击类型数,该特征可以在一定程度上反应攻击者的在攻击时的连续持久性,但该特征较弱,建议该特征的权重值设置为0.2-0.6之间;
域名领域,为攻击者使用一个ip进行攻击时,攻击目标的类型,如政府网,教育网等,可以反应出攻击者的攻击偏好,但该特征较弱,建议该特征的权重值设置为0.2-0.6之间;
具体域名目标,为攻击者使用一个ip进行攻击时的攻击具体目标,建议权重值设置为0.2-0.6之间;
时间段为攻击者使用一个ip进行攻击时所处时间段,建议权重值设置为0.2-0.6之间;
post的tf-idf值和url的tf-idf值为攻击者使用一个ip进行攻击时在post数据和get数据中用词的词频,可以反应出一个攻击的偏好特征,建议权重值设置为1.8-2.5之间;
ip-b段和ip-c段,为不同的ip根据b段和c段进行划分后的归类,同一个b段的ip有一定的可能为同一个攻击者,而同一个c段的ip为同一个攻击者的可能性更大,因此建议将ip-b段的权重值设置为2-2.5之间,而ip-c段的权重值设置为2.8-3.2之间;
post用词相似度和get用词相似度为攻击者使用一个ip在攻击构造有效载荷时,经常会带有一些个人特性的标签,比如常用字符,那么通过常用字符来关联一个人具有很高的可信度,因此get用词模式就具有较高的重要性,建议将权重值均设定为2.9-3.2之间。
进一步地,步骤3)具体为:
3-1)将ip和其对应的有标签的特征向量输入群体发现算法;
3-2)根据不同特征的重要性设置各个特征的权重,对于权值的设置要满足重要性最低的3-5个特征的权值之和大于剩余特征中至少一个的权值,这样低重要性权重才能在整个算法中发挥一定的作用,例如权重可以设置为[1,0.4,0.4,0.4,0.4,2.02,2.03,1.5,2.1,3.04,3.05],前五个弱特征的权重和为2.6大于第六到第九的特征权重值;
3-3)依次将两个或多个ip的同一个特征的特征值进行比较,如果特征值相同,将该特征的权重值加到群体分值上,如果特征值不同,群体分值保持不变。
进一步地,步骤4)中阈值的设定与每个特征设置的权重需要对应,阈值的取值要大于最高的一个权重值,同时要小于最高的三个权重值相加的和,这样可以降低重要特征的影响度,同时使低重要性特征发挥作用,例如权值设定为[1,0.4,0.4,0.4,0.4,2.02,2.03,1.5,2.1,3.04,3.05]时,阈值的范围则为[3.06,8.2],根据实验结果,取值为5时效果最佳。
一种攻击组织发现系统,包括:
web日志信息处理模块,获取待处理的web日志,对web日志中的关键特征进行提取,对所提取的特征进行预处理;
标签特征处理模块,将预处理后的特征分为有标签特征和无标签特征,使用ap聚类方法对无标签特征进行单独聚类,将标签化处理后得到的结果与有标签特征合并;
群体分值计算模块,根据每个特征在使用时的重要性,给标签特征赋予不同的权值,对比不同ip间特征值是否相同,对特征值相同的权值进行累加,得到最后的群体分值;
攻击组织判定模块,根据群体分值和预设阈值,对是否属于同一个攻击组织进行判定。
本发明的有益效果如下:
由于攻击者攻击特性的多样性,以及网站漏洞的不确定性,导致攻击产生的日志多且杂,导致自动化的发现攻击组织一直是一个难题,而本发明针对这一问题,提出了自动化的攻击组织发现方法,有效的节约了人力资源,并且大大的提高了工作效率,降低了企业入侵原因分析的人工成本和时间成本。
附图说明
图1是本发明方案的整体结构示意图。
图2是web日志信息处理流程图。
图3是无标签特征处理流程。
图4是群体分值计算以及攻击组织判定流程图。
图中100、200、300、400、500、210、220、310、320、330、340、410、420、430、440、510:步骤。
具体实施方式
为使本技术领域的人员更好地理解本发明实施例中的技术方案,并使本发明的目的、特征和优点能够更加明显易懂,下面结合附图和事例对本发明中技术核心作进一步的详细说明。
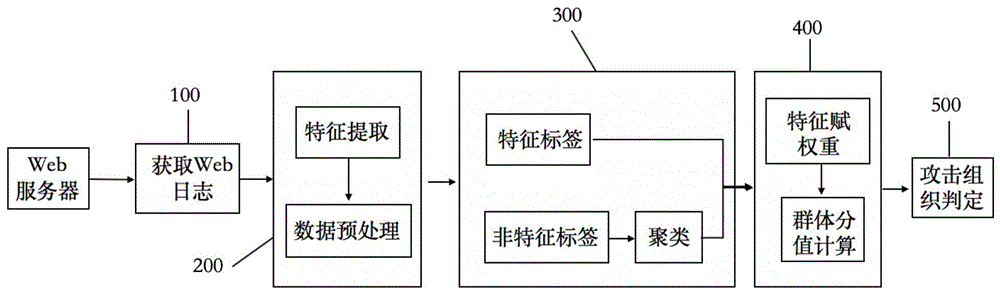
本实施例提供一种攻击组织的发现方法,如图1所示流程图,具体包括以下步骤:
步骤100:获取待分析的web日志。
步骤200:对web日志进行特征提取,包括攻击者的ip,攻击时间段,ip所属的b段、c段信息,攻击者的惯用字符串,攻击者攻击时所用的特殊字符,攻击者使用的payload模式,攻击者使用的ua信息,攻击类型,攻击的目标特征等,并对这些特征进行数据预处理,包括将数据规范化,填充空白数据,删除冗余数据,将数据转换为计算机能识别的格式。
步骤300:将提取到的特征分为有标签特征和无标签特征,使用affinitypropagation聚类的方法对无标签特征进行标签化处理,将无标签特征处理后得到的结果和有标签特征合并,输入到群体分值计算模块中。
步骤400:根据特征的重要性,对每一维特征进行赋值,检查不同ip间的标签值是否相等,并把标签值相等的标签所对应的权重进行累加,最后得到一个群体分值。
步骤500:依据群体的得分情况,设置一个阈值,当群体分值满足该阈值时,认定该群体内的ip,属于同一个攻击组织。
图2所示为web日志信息处理流程图,具体说明如下:
步骤210:此为特征提取,通过分析web日志数据,根据已有信息提取出可以进行关联,具有个人特性的特征,包括攻击者的攻击类型,总攻击日志条数/攻击类型数,域名领域,具体域名目标,攻击时间段,ip所属的b段、c段信息,攻击者的惯用字符串post内容用词相似度,get用词相似度,post的tf-idf值,url的tf-idf值。
步骤220,对提取出的特征进行数据预处理,以便在机器学习算法中使用,包括将数据规范化,填充空白数据,删除冗余数据,将数据转换为计算机能识别的格式。最后得到11维特征,包括7维无标签特征和4维有标签特征。
图3所示为将提取到无标签特征转化为有标签特征,具体如下:
步骤310:对每个无标签特征使用affinitypropagation算法进行聚类,将聚类得到的结果编号作为标签。
步骤320:在聚类的过程中,需要对聚类的效果进行调整优化,为了得到一个较好的聚类结果,此处需要对结果设置聚类的轮廓系数,大致规范每个类平均的ip个数。
步骤330:此处使用gridsearchcv来进行参数调优,该方法可以实现自动调参,只要把需要的参数输入,就能给出最优化的结果和参数。
步骤340:将无标签特征进行单独聚类后,可以得到一个有标签的新特征,将得到的新特征与原来的有标签特征进行合并,形成一个新的特征向量。
图4所示为攻击组织发现系统的核心示意图,具体流程如下:
步骤410:根据不同的特征在使用时的重要性不同,对各个特征进行权重的设置,设置权重时可以使用两位数的小数,如2.01,2.02。可以在避免相似的特征间权重差距大的情况,又可以保证任意两个或多个权重相加所得到的值不会出现相等的情况。
步骤420:对任意两个或多个ip的各个特征的特征值进行对比,如果ip1的特征1的特征值v11和ip2特征1的特征值v12相等,那么就将特征1所对应的权重w1加到群体分值中。
步骤430:依次对比每一个特征,对不同ip间同一个特征的特征值相等的情况,将该特征所对应的权重进行累加,最后结果赋值给群体分值。
步骤440:判断特征是否对比完毕,如果未将全部对比完毕,返回步骤420进行对比,待全部特征对比完毕,得到最终的群体分值。
步骤510:对最终得到的群体分值与预先设定的阈值进行对比,如果群体分值大于等于阈值,判定该群体内的ip属于同一个攻击组织,如果小于阈值则判定失败。
这里需要注意的是,会出现同一个ip和多个组织间所得分值均大于阈值的情况,此时将该ip归类为所得分值最大的组织。
还应该注意,阈值的设定与每个特征设置的权重需要对应,比如在本实验过程中,各个特征的权重被设置为[1,0.4,0.4,0.4,0.4,2.02,2.03,1.5,2.1,3.04,3.05],阈值被设定为5,该分值并不是固定唯一的,可以根据具体情况进行调整。
最后所应说明的是,以上实施案例仅用以说明本发明的技术方案而非限制,尽管使用事例对本发明进行了详细说明,本领域的普通技术人员应当理解,可对本发明的技术方案进行修改或者等价替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!