基于语音识别技术接打电话的方法及车载电子装置与流程
本发明涉及车载电子设备技术领域,尤其涉及一种基于语音识别技术接打电话的方法及车载电子装置。
背景技术:
目前汽车保有量不断上升,其中私家车更是呈现几何数字增加,全球汽车数量的增加也导致交通安全事故呈指数上升,而发生交通事故90%是由司机注意力不集中导致的,比接打电话、查看手机信息等。
传统的车机蓝牙或其他带蓝牙接入车载电子设备仅仅与手机蓝牙bt连接,在蓝牙电话接入还需要在车机或者蓝牙设备上进行操作或者操作手机进行电话接听,该方法仅仅能将手机音频与设备进行连接通过a2dp协议进行传输,将手机声音接入到车机或车载蓝牙设备中进行播放。在进行电话接打过程中需要驾驶员收到操作车机或者电话进行来电接打,分散驾驶员的注意率影响驾驶安全。
因此,现有技术存在不足,需要改进。
技术实现要素:
本发明的目的是克服现有技术的不足,提供一种基于语音识别技术接打电话的方法及车载电子装置。
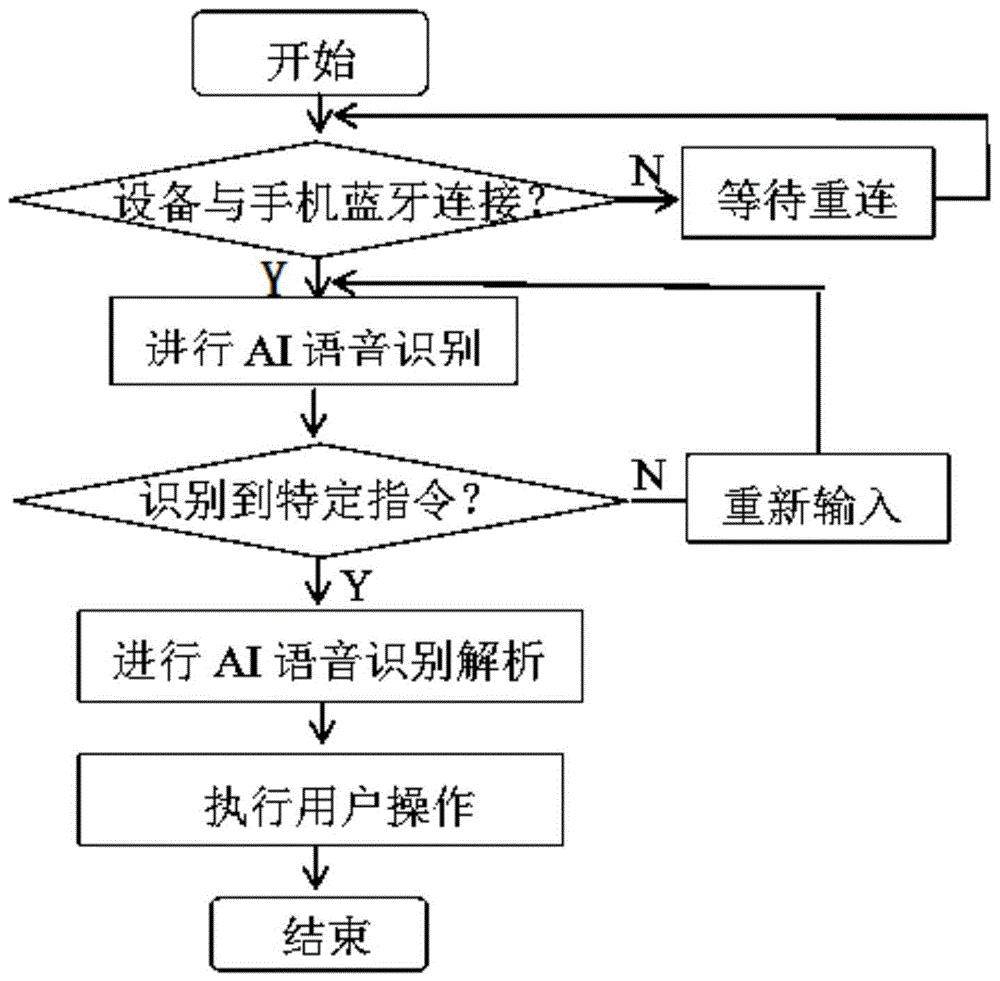
本发明的技术方案如下:提供一种基于语音识别技术接打电话的方法,包括以下步骤:
步骤s1,终端设备通过双模蓝牙与电子装置连接配对;
步骤s2,电子装置的ai系统进行语音识别、判断及解析;
步骤s3,电子装置的ai系统执行用户操作。
所述步骤s2包括以下步骤:
步骤s21,音频检测;
步骤s22,检测静音;
步骤s23,语音输入;
步骤s24,音频预处理;
步骤s25,特征提取;
步骤s26,声学模型匹配;
步骤s27,比较判断;
步骤s28,指令输出、动作响应。
进一步地,所述步骤s1中终端设备bt与电子装置bt连接配对,终端设备ble与电子装置ble连接绑定,电子装置bt打开后通过sdp搜索终端设备,连接绑定后,电子装置通过pbap、atcommand命令与终端设备进行蓝牙电话本、在线通话记录的同步,在同步完之后,电子装置通过hsp、hfp协议与终端设备连接,在连接配对后电子装置与终端设备蓝牙通过at指令进行用户操作,所述终端设备为手机、或pc、或车机。
进一步地,所述用户操作包括:接通或挂断电话、拉起拨打电话、播报或不播报信息。
进一步地,所述步骤s21中电子装置通过语音识别控制单元采集车内的音频数据,得到音频数据序列x(n)。
所述步骤s22具体包括:对所述步骤s21采集到的音频数据序列x(n)做傅里叶变换得到能量场分布图,其变换公式为:
所述步骤s23中对检测到的非静音状态下的音频数据作为语音进行输入。
所述步骤s24中的音频预处理是对音频数据进行数字滤波,去除背景噪声干扰,滤除方法采用lms自适应滤波方法,具体公式为:y(m)=v(m)-l(m),其中v(m)为语音输入信号,l(m)为对应的另一路mic采集的背景噪声,将噪声滤除后得到较为纯净的语音信号,再对语音信号进行加窗处理成帧数据,每帧的长度为t,帧移动的长度为t,则每帧之间存在着t-t的交替重叠,其中t>2t,所述背景噪声为音乐声、或发动机噪声、或胎噪、或风雨声。
所述步骤s25中提取的特征为识别语音信号中的口音特征,实现的方法是通过对语音信号进行傅里叶变换,利用梅尔倒频谱系数法后由深度神经网络来分析和综合运算来判断语音信号所属的口音类型,以便选择对应的语音识别模块。
所述步骤s26,所述声学模型中存储了若干种不同地区的模型数据,所述声学模型包括声学词典和解码器,根据特征提取结果进行所述声学模型的匹配,如匹配到所属的声学模型,则由所属的声学词典和解码器经过分析运算,匹配输出文本字符串;如反馈未匹配到所属的声学模型,则返回所述步骤s25重新特征提取,并继续进行声学模型匹配,如再次未匹配成功则提示重新再说一遍或放弃等待下一段语音。
所述步骤s27,根据特征提取和声学模型匹配的结果,选择最匹配的声学模型进行特征帧比对,根据概率比较器比较的结果输出识别结果。
所述步骤s28,在概率比较之后经解析识别到具体的指令。
本发明还提供一种车载电子装置,包括:核心处理模块、外接电源模块、通讯模块、音频采集模块、音频输出模块、双模蓝牙、及fm发射模块,所述核心处理模块与所述电源模块电连接,所述通讯模块、音频采集模块、音频输出模块、双模蓝牙、及fm发射模块均与所述核心处理模块通信连接,终端设备通过双模蓝牙与所述核心处理模块通信连接。
进一步地,所述双模蓝牙包括蓝牙bt模块和ble模块。
进一步地,所述蓝牙bt模块的芯片型号为rda5876,所述ble模块的型号为nrf51822。
进一步地,所述核心处理模块包括处理器、pmic模块、emmc模块、ddr模块,所述pmic模块、emmc模块、ddr模块均与所述处理器通信连接,所述外接电源模块与所述pmic模块电连接,所述通讯模块、音频采集模块及音频输出模块均与所述emmc模块通信连接,所述蓝牙bt模块及ble模块均与所述ddr模块通信连接,所述处理器的芯片型号为t7,所述pmic模块的芯片型号为axp858。
进一步地,所述音频采集模块为多路拾音器,所述多路拾音器包括两路,分别采集用户语音和背景噪音。
进一步地,所述通信模块包括usb模块和wifi模块,所述外接电源模块接入的是5v电压。
采用上述方案,本发明通过双模蓝牙与终端设备进行连接,能够同时进行音频传输和信息传输,ai的智能运用可以方便驾驶员能通过语音操作接打电话,并实时播报信息的内容。这样可以减少驾驶员在驾驶过程中减少操作手机,集中驾驶注意力,提高驾驶安全,减少驾驶事故,有效降低驾驶风险。
附图说明
图1为本发明基于语音识别技术接打电话的方法的流程图;
图2为本发明基于语音识别技术接打电话的方法中ai语音识别、判断及解析的流程图;
图3为本发明车载电子装置采集到的音频数据;
图4为本发明车载电子装置帧提取示意图;
图5为本发明车载电子装置的硬件框图;
图6为本发明车载电子装置中核心处理模块的电路原理图;
图7与图8为本发明车载电子装置中蓝牙bt模块的电路原理图;
图9为本发明车载电子装置中ble模块的电路原理图。
具体实施方式
以下结合附图和具体实施例,对本发明进行详细说明。
请参阅图1至图4,本发明提供一种基于语音识别技术接打电话的方法,包括以下步骤:
步骤s1,终端设备与电子装置连接配对;电子装置bt打开后通过sdp(sessiondescriptionprotocol)会话协议搜索终端设备(所述终端设备为手机、或pc、或车机);终端设备bt与电子装置bt连接配对,进行音频传输(接打电话、音乐播放等),终端设备低功耗蓝牙ble与电子装置低功耗蓝牙ble连接绑定,通过ancs协议传输信息提醒;连接绑定后,电子装置通过pbap(phonebookaccessprofil电话号码簿访问协议)、atcommand(attentioncommand)命令与终端设备进行蓝牙电话本、在线通话记录的同步;在同步完之后,电子装置通过hsp(headsetpro-file)、hfp(handprofile)协议与终端设备连接,在连接配对后电子装置与终端设备蓝牙通过at(attention)指令进行相关用户操作。
步骤s2,电子装置的ai系统进行语音识别、判断及解析,具体包括以下具体步骤:
步骤s21,音频检测,电子装置通过语音识别控制单元采集车内的音频数据,得到音频数据序列x(n)。
步骤s22,检测静音,对采集到的音频数据序列x(n)做傅里叶变换得到能量场分布图,其变换公式为:
步骤s23,语音输入,音频数据中
步骤s24,音频预处理,对音频数据进行数字滤波,去除背景噪声干扰,滤除方法采用lms自适应滤波方法,具体公式为:y(m)=v(m)-l(m),其中v(m)为语音输入信号,l(m)为对应的另一路mic采集的背景噪声,将噪声滤除后得到较为纯净的语音信号,再对语音信号进行加窗处理成帧数据,每帧的长度为t,帧移动的长度为t,则每帧之间存在着t-t的交替重叠,其中t>2t,所述背景噪声为音乐声、或发动机噪声、或胎噪、或风雨声或其他环境噪音。
步骤s25,特征提取,识别语音信号中的口音特征,实现的方法是通过对语音信号进行傅里叶变换,利用梅尔倒频谱系数法(mfcc)后由深度神经网络(dnn)来分析和综合运算语音信号所属的口音类型,以便选择对应的语音识别模块。
步骤s26,声学模型,所述声学模型中存储了若干种不同地区的模型数据,如福建、湖南、四川、广东、北方等地语音数据(包含普通话及地方方言)。所述声学模型包括声学词典和解码器,根据特征提取结果进行所述声学模型的匹配,如匹配到所属的声学模型,例如根据特征提取结果匹配所属为北京话,则对应找到所属的北京话的声学词典和解码器,则由所属的声学词典和解码器经过分析运算,匹配输出文本字符串;如反馈未匹配到所属的声学模型,则返回特征提取再根据最大概率重新匹配,如再次未匹配成功则提示重新再说一遍或放弃等待下一段语音。
步骤s27,比较判断;根据特征提取和声学模型匹配的结果,选择最匹配的声学模型进行特征帧比对,根据概率比较器比较的结果输出识别结果,比如用户回复“是/接/接通”或者“不/不接/挂断”接通或挂断电话。
步骤s28,指令输出、动作响应,在概率比较之后经解析识别到具体的指令,比如接听、拒接、拨打电话,播报/不播信息提醒的内容。
步骤s3,电子装置的ai系统执行用户操作。具体地用户操作包括接通或挂断电话、拉起拨打电话、播报或不播报信息。根据上述ai语音识别过程,用户实现接通或挂断电话的具体过程为:当电子装置进入配对模式时,开始连接hfp,当有第三方电话进来时会触发进行来电显示,ai会将来电的内容经组织后进行播报,如“主人,您的手机通讯录好友xxx来电,是否接通?”,ai进入语音识别交互模式,等待底层的mic(麦克风)采集的录音数据进行语音识别,当识别到“是/接/接通”,电子装置发送at指令“ig”通知终端设备bt运用层进行通话接听;当识别到“否/不/不接/挂断”时,电子装置发送at指令“if”给终端设备运用层进行蓝牙挂断。
根据上述ai语音识别过程,用户实现拉起拨打电话的具体过程为:当电子装置进入配对模式时,开始连接hfp,终端设备通讯录及通话记录经过终端设备运用层与设备蓝牙进行通讯,通过pbap、atcommand命令与终端设备进行蓝牙电话本、在线通话记录的同步,当终端设备接收到通讯录及通话记录同步成功at命令“pc”及“pe”后完成同步。此时可以唤醒ai进行语音电话拨打,如“我要打电话给xxx/帮我打电话给xxx”,电子装置识别到相应的拨打指令后会先到同步完成的终端设备通讯录中寻找xxx,系统对电话本进行搜索然后进行匹配,如通讯录中存在同名的多个联系人、备注的相似的联系人、多音字的联系人,则设备会对超过一个联系人的情况进行多轮交互,如“为您找多多个联系人,您是要拨打1、xxx江西;2、xxx经理...”,这时用户回复1则设备会将拨打指令通过at命令“cw[num]”将拨打指令及号码发送给终端设备蓝牙,终端设备蓝牙拉起并拨打电话。
根据上述ai语音识别过程,播报或不播报信息的具体过程为:终端设备ble与电子装置ble连接绑定,终端设备app模拟ancs协议,将信息通知(包括但不限于短信、qq、微信等)的内容推送到电子装置,电子装置接收到utf-8的信息提醒内容后缓存在设备内部的缓存中,ai播报“收到xxx/微信/qq联系人发来的消息,是否播报?”,然后ai进入等待识别状态,当ai识别到“要/播/播报”时播报信息的内容,当识别到“不/不播/不要”时忽略信息提醒播报并清空信息内容。
请参阅图5至图9,本发明还提供一种车载电子装置,包括:核心处理模块1、外接电源模块2、通讯模块3、音频采集模块4、音频输出模块5、双模蓝牙、及fm发射模块6。所述核心处理模块1与所述电源模块2电连接,所述通讯模块3、音频采集模块4、音频输出模块5、双模蓝牙、及fm发射模块6均与所述核心处理模块1通信连接,终端设备通过双模蓝牙与所述核心处理模块通信连接,具体地,本实施例中所述双模蓝牙包括蓝牙bt模块7和ble模块8,通过所述蓝牙bt模块7实现音频传输,所述蓝牙bt模块7的芯片型号为rda5876,通过所述ble模块8实现信息传输,所述ble模块的型号为nrf51822。所述音频采集模块4为多路拾音器,所述多路拾音器包括两路,分别采集用户语音和背景噪音。所述通信模块3包括usb模块和wifi模块。所述核心处理模块1包括处理器、pmic模块、emmc模块、ddr模块,所述pmic模块、emmc模块、ddr模块均与所述处理器通信连接,所述外接电源模块2与所述pmic模块电连接为整个电子设备供电,其中所述外接电源模块2接入的是5v的电压,所述pmic模块的芯片型号为axp858。所述通讯模块3、音频采集模块4及音频输出模块5均与所述emmc(embeddedmultimediacard,内嵌式存储器)模块通信连接,所述蓝牙bt模块及ble模块均与所述ddr(doubledatarate,双倍数据速率)模块通信连接,所述处理器的芯片型号为t7。
综上所述,本发明通过双模蓝牙与终端设备进行连接,能够同时进行音频传输和信息传输,ai的智能运用可以方便驾驶员能通过语音操作接打电话,并实时播报信息的内容。这样可以减少驾驶员在驾驶过程中减少操作手机,集中驾驶注意力,提高驾驶安全,减少驾驶事故,有效降低驾驶风险。
以上仅为本发明的较佳实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!