一种基于并行解码的反向散射上行数据收集方法与流程
本发明涉及反向散射上行数据收集方法,具体为一种基于并行解码的反向散射上行数据收集方法。
背景技术:
在现有的反向散射通信系统中,无源节点本身不携带供电设备,能量主要来源于依靠接收器对节点发出的载波供能,接收器利用反向散射原理与节点通信。为了避免节点通信冲突,现有的数据收集协议遵循epcc1g2协议,单个节点只能在单一时隙与接收器通信,这很大程度限制了节点的传输速率。单个节点单时隙传输信息效率低下,一个潜在方法就是允许多个节点在单一时隙内并行传输数据至接收器,接收器并行解码,分离多个节点信息。
技术实现要素:
本发明为了解决现有反向散射系统中上行数据收集效率低下的问题,提出了一种基于并行解码的反向散射上行数据收集方法。
本发明是采用如下的技术方案实现的:一种基于并行解码的反向散射上行数据收集方法,包括以下步骤:
(1)在反向散射通信中,接收器发送载波信号为无源节点提供能量供给,节点通过吸收或反射载波信号进行信号发送,接收器在同一时隙接收到多个节点的信号后,多个节点的信号叠加;
(2)叠加后的信号在iq域能够被表示为iq平面上的复数信号,采用基于密度的dbscan聚类算法对节点状态结合簇分簇;
(3)在分簇之后,寻找节点状态结合簇与节点发送信号状态对应关系,根据已知的为全低电平状态结合簇,距离全低电平状态结合簇最远的为全高电平状态结合簇,根据状态结合簇结构化规律,即可求得剩余代表节点发送信号状态的状态结合簇;
(4)依据节点状态结合簇的形成次序,将每个节点状态结合簇数据串的第一位数字按形成次序结合形成一个序列,将每个节点状态结合簇数据串的第二位数字按形成次序结合形成一个序列,依次类推将每个节点状态结合簇数据串的最后一位数字按形成次序结合形成一个序列,形成的若干序列即为节点发出的序列;
(5)对于不同节点信号序列,其前导码规律是已知,根据节点前导码规律区分上述形成的若干序列,完成了冲突序列的并行解码。
上述的一种基于并行解码的反向散射上行数据收集方法,利用fm0编码特性,对节点状态结合簇进行纠错操作。
上述的一种基于并行解码的反向散射上行数据收集方法,该方法只需解决四个和四个节点以下的通信冲突问题就能够实现接收器对节点信号的高效收集。
相比接收器在单时隙与单节点通信,多个节点在同一时隙内并发传输信号,势必会在接收器处发生通信冲突。接收器对m个节点信息收集,在这其中,有n个节点发生通信冲突,j个节点处于同一个时隙的概率为1/j,这m个节点在接收器处发生通信冲突的概率pc表达式如下:
对上述公式进行理论分析得出,当接收器与节点通信时,有36.77%的时隙为空时隙,即没有节点与接收器传输信息;有36.81%的时隙为单一时隙,即只有一个节点与接收器传输信息,不发生通信冲突;有18.40%的时隙是两个节点同时与接收器传输信息,发生通信冲突;有6.13%的时隙是三个节点同时与接收器传输信息,发生通信冲突;有1.53%的时隙是四个节点同时与接收器传输信息,发生通信冲突;只有0.36%的时隙是五个节点和五个节点以上同时与接收器传输信息的情况,此时节点之间通信冲突激烈。因此,只要解决了四个和四个节点以下的通信冲突问题就能够实现接收器对节点信息的高效收集。
相比传统的节点在单时隙内单一通信,多个节点并行传输信息,接收器并行解码极大地提高了反向散射上行数据收集效率。
附图说明
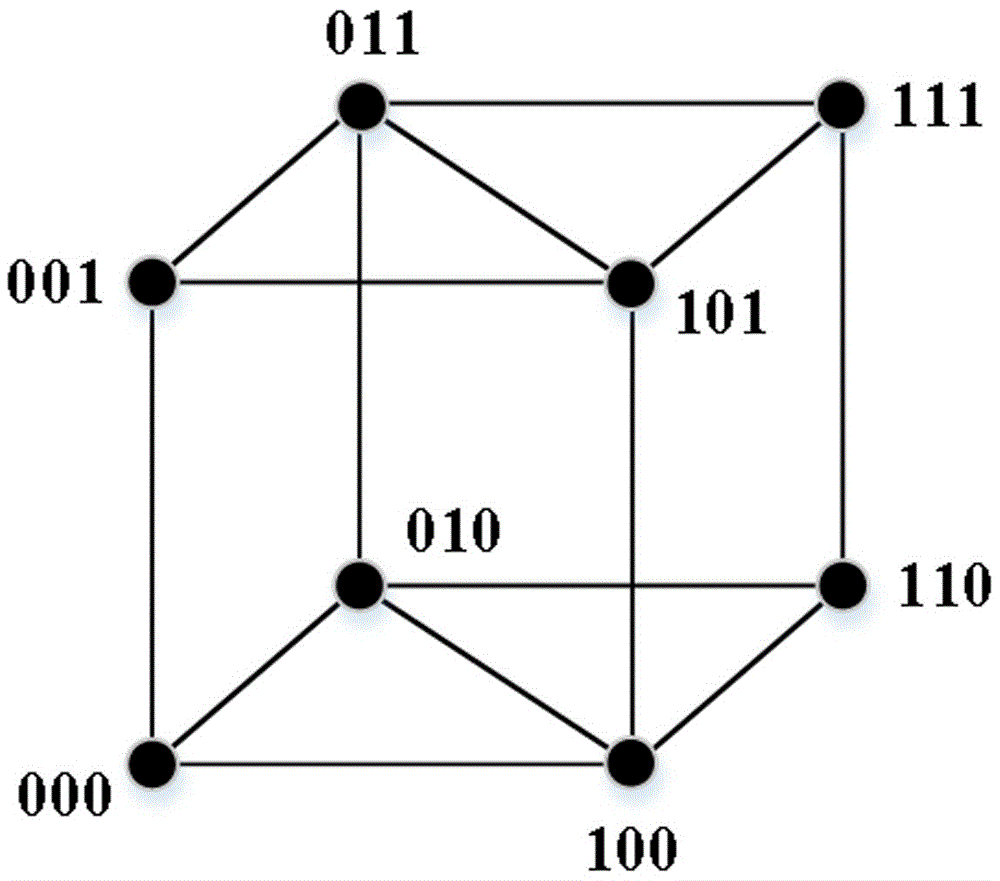
图1是8个状态结合簇的示意图。
图2是fm0符号序列图。
图3是fm0编码(前导码)图。
具体实施方式
下面结合实例和附图对本发明方法作进一步详细的描述:
一种基于并行解码的反向散射上行数据收集方法包括以下步骤:
(1)在反向散射通信中,接收器为无源节点提供了能量供给,当接收器发送载波与节点通信的过程中,载波中包含同向分量i分量和正交分量q分量。节点通过吸收或反射载波信号进行信号发送,反向散射至接收器的信号中依然包含同向i分量和正交q分量,对于单个节点k来说,接收器收到的信号表示为:
其中
多个节点在位边界处发生翻转,对应于时域信息中发生了幅度的变化,在星座域中发生了多个状态结合簇之间的转换。
(2)在没有噪声干扰的理想状态下,节点反向散射的信号会在星座域中叠加到一个点上。但是,在实际情况中由于噪声干扰且遵循高斯分布,噪声信号在星座域中叠加到一个中心点周围分布。接收器接收到反向散射的信号在星座域中表示为多个散落的点,接收器把具有相似特征的信号归为一类。节点的星座域中的信号分散于低密度区域,且具有稠密特性,采用基于密度的dbscan聚类算法对符号点进行分簇,原因如下:dbscan聚类算法基于密度计算聚类,会剔除异常点,对节点抗噪有一定的帮助;接收器无法提前预知节点的数量,一般聚类算法对划分簇的个数尤为敏感,dbscan聚类算法能够在不提前判断分簇个数的情况下,对节点聚类进行划分。
(3)在对节点状态簇进行划分之后需要对状态簇与节点状态相结合。对于全是低电平的状态簇,由于所有节点对于接收器发出的载波信号进行了吸收,不存在节点发送信号彼此之间产生冲突,所以这个全为低电平的状态簇接收器是已知的。通过节点状态簇的数量,接收器可以反推断出并发节点的数量。例如,对于8个状态结合簇,如图1所示,则为3个节点并发数据,即状态簇的个数为2n,并发节点的数量为n。结合状态簇分布规律可得知,与000状态簇距离最远的状态即为111状态簇,结合节点状态簇结构化特点,即可分别求得剩余状态簇所代表的节点状态。
(4)节点状态结合簇在恢复之前,需要对节点状态结合簇进行纠错,复杂算法不适用于节点这种能量受限型设备,同时也会增加接收器解码时间。对节点编码的本身特性进行分析,fm0编码在每一位数据开始前会发生一次跳变,如果码元中心处发生跳变,该数据信息表示为0;如果码元的中心处没有发生跳变,该数据表示为1。如图2所示,正常的fm0编码会在码元变化处发生翻转。如果有的码元没有发生相应的翻转,则对该状态结合簇进行编码纠正。
(5)对于不同的节点能够分别得到各自节点的信息序列,例如,节点a的序列为xx’xx00x’x’,节点b的序列为y0yy’y’yy’y,节点的前导码规律是已知的(如图3所示),根据节点的前导码规律能够解码节点信息,进而确定x和y具体表示的值为“1”还是“0”,从而对应于节点信息。
- 还没有人留言评论。精彩留言会获得点赞!