基于智能终端的环境声抑制与增强可调节耳机系统与方法与流程
本发明属于电子电器技术领域,具体涉及一种基于智能终端的环境声过滤与增强可调节耳机系统与方法。
背景技术:
耳机是贴耳佩戴的声音播放设备。耳机接到收音机,cd机,电脑,手机等产生声音的终端(以下简称“音源终端”),广泛用于收听广播,欣赏音乐,学习外语等场合。相对于外放的音响设备,耳机对其他人的干扰很小,适合于单人使用的场合。
一般而言,耳机播放的声音来自于上述音源终端。对人耳而言,除了音源设备发出的声音(音源声)外,还会听到环境的声音。一般情况下,这些环境声被定义为噪声,他们可能会干扰人耳听到的音源声,特别是在一个嘈杂的环境中。
耳机的设计者通过适当的方法来降低噪声对音源声的干扰,包括被动降噪和主动降噪。
被动降噪主要是利用增强耳机和耳道之间的密封性来达到阻断外界噪声的效果。主动降噪通过在耳机外侧增加麦克风来侦听环境噪声,并通过信号处理芯片,产生该环境噪声振幅相同,相位相反的反相声波,达到抵消环境噪声的效果。
在实际生活中,我们发现,环境声也不一定是毫无用处的必须过滤的噪声。有些场合需要听到外接的声音,例如:
(1)城市中马路边戴着耳机跑步锻炼或者散步休闲时,如听不到汽车行驶的声音,喇叭声和刹车声等重要提示声音是很危险的。
(2)坐公交车或地铁的时候,如果戴着耳机,听不到报站声,容易坐过站。
(3)在办公场景(如写程序或文档)时,听音乐有助于提高效率。但如须与周围同事短暂沟通交流时,则需要先把耳机摘下来。如果要频繁戴上摘下,则会比较麻烦。
(4)在工厂场景,有些生产环境噪声较大,从劳动保护角度需要配备耳塞等,但是会导致听不到同事的声音,影响交流。
(5)在家里,戴着耳机听歌的时候,听不到妈妈叫我们吃饭的声音。
从以上的场景,我们可以看出环境声除了无用的噪声,还包括一些有用的声音,为我们提供警报、交流等方面的信息(信息声)。
因此,我们提出本发明,其基本思路是将环境声智能地区分为噪声和信息声,对噪声进行抑制,而对信息声进行增强。由于其智能性要求较强,并且允许用户定制,我们将智能处理的部分放在终端中进行处理,也就是说音源终端是一个智能终端,例如手机,电脑,平板电脑,智能音乐播放设备等。随着智能手机等智能终端的普及,我们利用智能终端的强大计算能力进行相关处理,耳机端仅需采集环境声的麦克风即可,无须现有主动降噪耳机所需的昂贵的且功能单一的专用处理器件,很大程度上降低了成本。利用智能终端的软件开发和数据管理,实现需求的定制化,很大程度上增加了系统的灵活性。
技术实现要素:
鉴于上述问题,本发明提出了一种基于智能终端的环境声抑制与增强可调节耳机系统,包括:声音采集装置,其用于采集环境声信号;智能终端,与所述声音采集装置连接,所述智能终端通过区分环境声信号中的噪声和信息声,根据噪声产生相应的同幅反向声波的抑制信号,根据信息声产生相应的同幅同向声波的增强信号;声音输出装置,其余所述智能终端连接,用于输出音源声信号,同时输出抑制信号和/或增强信号。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述智能终端包括:环境声信号分离模块,其与所述声音采集装置连接,用于接收所述环境声信号,并从中区分音源声信号中环境声的噪声和信息声;抑制模块,其与所述环境声信号分离模块连接,用于根据噪声产生相应的同幅反向声波的抑制信号;增强模块,其与所述环境声信号分离模块连接,用于根据信息声产生相应的同幅同向声波的增强信号;音频播放模块,其用于输出音源声信号;声音合成模块,其分别于所述抑制模块、增强模块、音频播放模块连接,并与所述声音输出装置连接,用于将音源声信号、抑制信号和/或增强信号进行合成输出至声音输出装置。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述智能终端还包括与所述环境声信号分离模块相连接的数据库,所述数据库内存储用于区分噪声和信息声的数据和训练好的用于分离的模型。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库进一步和自学习模块相连,所述自学习模块使用数据库中的声音数据,借用服务器端的算力,通过学习和训练相关的噪声信号和信息声信号并建立定制化模型。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库包括:通用数据库、个人数据库及模型;
所述通用数据库保存在服务器端,包括诸如汽车声敲门声等通用声音数据。个人数据库由用户定制,储存特定音源的声音信息。模型则是由服务器端训练完成后,传给智能终端的用于环境声分离及识别的模型。通用数据库及模型由服务器不定期更新,而个人数据库需要用户通过智能终端上配套的软件传入数据进行更新。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,智能终端可使用训练好的模型,来对环境声进行分离,并根据环境声的种类对分离后的音频分别进行抑制或将加强处理。
基于以上系统,本发明还提出了一种基于智能终端的环境声抑制与增强可调节方法,包括如下步骤:
步骤一:通过麦克风采集环境声信号;
步骤二:环境声分离模块检测环境声信号中的噪声和信息声;
步骤三:由抑制模块根据噪声产生相应的同幅反向声波的抑制信号,和/或由增强模块根据信息声产生相应的同幅同向声波的增强信号;
步骤四:输出音源声信号,同时输出抑制信号和/或增强信号。其特征在步骤二进一步包括:根据数据库区分环境声信号中的噪声和信息声。
本发明提出的基于智能终端的环境声抑制与增强可调节方法中,自学习在服务器完成,在服务器端获取到新的数据,或是模型参数得到改善后,会将新的模型参数输出至用户端。用户端只需定期获取最新的模型参数。模型训练共三部分,其细节如下:
步骤一:获取数据并进行预处理。所使用的数据集为互联网上公开可供使用的数据集,如timit,wsj0,thchs-30等等。数据集会不断扩充,将任意两音频混合即可形成新的混合音频,因此足以形成足够的训练音频。对每个训练音频做同样的预处理,其中包括:
1.预加重:对语音高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。
2.重采样:改变原始音频的采样率,方便数据的进一步处理。
3.分帧:根据波形的短时平稳性,将音频分割成一个个小段,减小计算量。
4.窗化:将频谱与窗函数相乘,使信号出现周期函数的部分特征。
5.端点检测:检测每帧是否有信号声存在。
6.短时傅里叶变换:将时域频谱转换为时频频谱。
步骤二:将上述预处理后的数据作为输入传入神经网络,计算原始数据频谱嵌入,作为原始音频的声音特征。
步骤三:将声音特征于特征空间进行聚类,每个聚类即是一个音源的音源特征。
与现有技术相比,本发明具有如下有益的技术效果:
1)将环境声分为噪声和信息声。对噪声进行降噪处理,对有用的信息声进行增强处理。
2)带着耳机时,仍然可以听到有用的警示音和提示音,避免发生危险或错过公交车站等。
3)不需要摘下耳机就可以和周围的人交流,操作方便,在达到降噪的同时,不会漏掉和自己有关或者自己关心的声音。
4)利用智能终端本身具有的计算性能,成本较低。
5)核心处理单元由软件实现,比较灵活,可以定制化。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
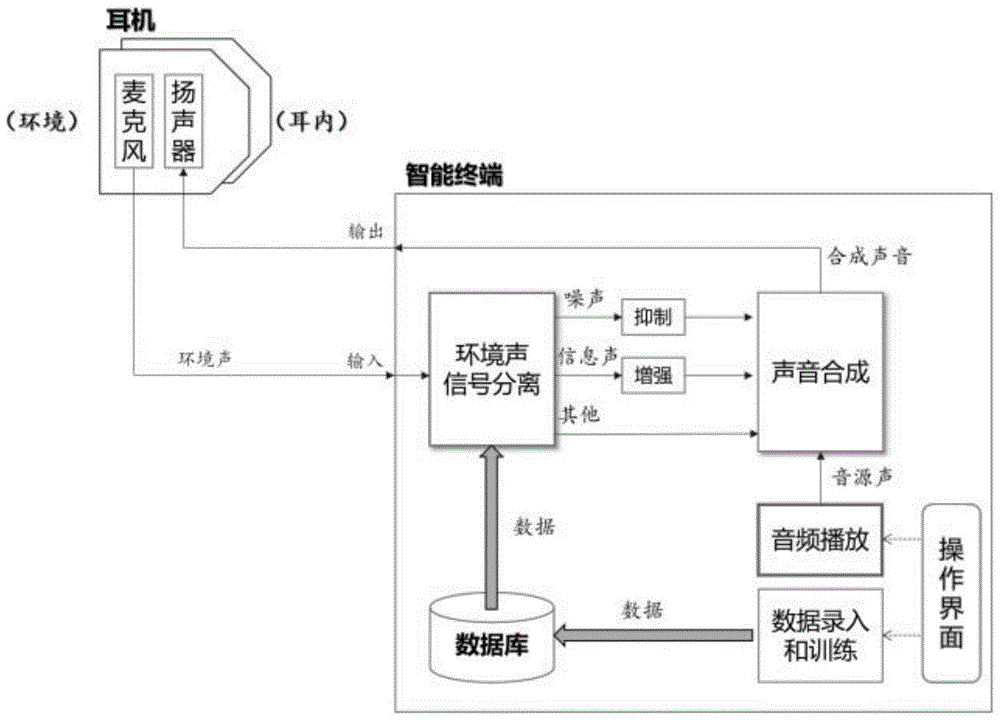
图1为实施例中基于智能终端的环境声抑制与增强可调节耳机系统的结构示意图。
图2为实施例中基于智能终端的环境声抑制与增强可调节方法的流程示意图。
具体实施方式
下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本申请实施例以及实施例中的具体特征是对本申请技术方案的详细的说明,而不是对本申请技术方案的限定,在不冲突的情况下,本申请实施例以及实施例中的技术特征可以相互组合。
本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
在本发明实施例的技术方案中,本发明基于智能终端的环境声抑制与增强可调节耳机系统包括:声音采集装置,其用于采集环境声信号;智能终端,与所述声音采集装置连接,所述智能终端通过区分环境声信号中的噪声和信息声,根据噪声产生相应的同幅反向声波的抑制信号,根据信息声产生相应的同幅同向声波的增强信号;声音输出装置,其余所述智能终端连接,用于输出音源声信号,同时输出抑制信号和/或增强信号。
具体而言,参见图1,所述智能终端包括:环境声信号分离模块,其与所述声音采集装置连接,用于接收所述环境声信号,并从中区分音源声信号中环境声的噪声和信息声;抑制模块,其与所述环境声信号分离模块连接,用于根据噪声产生相应的同幅反向声波的抑制信号;增强模块,其与所述环境声信号分离模块连接,用于根据信息声产生相应的同幅同向声波的增强信号;音频播放模块,其用于输出音源声信号;声音合成模块,其分别于所述抑制模块、增强模块、音频播放模块连接,并与所述声音输出装置连接,用于将音源声信号、抑制信号和/或增强信号进行合成输出至声音输出装置。优选的,声音采集装置和声音输出装置集成化一体设置。如图1所示,本实施例当中,声音采集装置和声音输出装置分别由麦克风和扬声器组成。麦克风处于耳机外侧,主要用于采集环境的声音,经过智能终端的处理,区分环境声中的噪声部分和信息声部分,对噪声产生相应的同幅反相声波,抵消该噪声;对信息声,不进行抑制,让其“穿透”耳机,或者进行适当的增强。耳机将播放音源声,噪声的反相声以及增强的信息声,使听者欣赏音源声、屏蔽噪声,同时又不影响信息声的输入。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述智能终端还包括与所述环境声信号分离模块相连接的数据库,所述数据库内存储用于区分噪声和信息声的数据。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库进一步和自学习模块相连,所述自学习模块通过手机环境声信号,通过学习和训练相关的噪声信号和信息声信号并建立定制化模型,用于将经训练的用于区分噪声和信息声的数据存入所述数据库中。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述自学习系统,使用一种听觉注意性选择模型。在事先训练模型时,需传入只包含特定说话人声音的音频,模型将自动提取该说话人声音中的声纹特征,并将其沉淀到数据库中的长时记忆单元中,以此完成对特定声音特征的学习记忆。每一次的模型训练都会加深对相应声音特征的记忆,并加强对该种声音的识别效果。凭借上述自学习功能,就可以在下一次接受到相应声音时,识别出数据库中储存的特定说话人的声纹特征,并将之放大处理。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库可事先通过上述自学习方法事先储存一些常见的、通用的、重要的声音特征(如汽车鸣笛声、刹车声、警报声等)作为需要被放大的音源,减少用户的作业量。并且在智能终端上,允许用户自行添加新的声源(如用户的亲人,朋友),只需要输入一定长度的音频,即可完成对新的生源的声纹特征的提取,之后由智能终端将声纹特征储存在数据库中在之后的使用中,系统若检测到与该声纹特征相同的音频,则自动将之放大或减小处理。并且该音频将反过来调整该声纹特征的具体参数,加强训练效果。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库由两部分组成。第一部分为该系统出厂时自带的通用数据库,该数据库储存各种常见音源的声音特征,如各种汽车的鸣笛声、敲门声、警报声、刹车声、汽车行驶声等等。该通用数据库在出厂后,仍可通过终端上的配套软件更新的形式进行统一更新,确保用户的通用数据库保持最新状态。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库的第二部分为可供用户自行定制的个人数据库,用户可通过终端软件中的数据录入功能,将特定音源(如家人的声音、同事的声音等等)的一定数量音频输入个人数据库。从而让自学习模块学习该特定音源的声音特征。之后当环境声分离模块检测到个人数据库中的音源时,会将其判断为信息声,并指挥增强模块对该声音进行增强处理。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库的第三部分储存环境声分离模块所使用的模型参数。初始为出厂前训练调整好的通用模型,在用户之后的使用中,可以通过自学习模块更新个人数据库及通用数据库中的数据,优化已有模型参数,以取得更好的效果。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述数据库和自学习模块相连,所述自学习模块通过学习数据库中的相关的噪声信号和信息声信号更新模型,以维持模型的长期有效。模型的学习和更新在服务器端来完成,服务器端将学习后的新模型参数返回智能终端,以避免智能终端算力不足的问题。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述服务器端学习模型,使用了近年来在机器学习诸多方向都展露头角的“深度聚类”技术,通过训练神经网络来让其产生对输入音频的分区标签有一定分辨能力的频谱嵌入,接下来对产生的频谱嵌入做传统聚类,聚类产生的波形掩膜可以直接作为滤波掩膜使用,用该滤波掩膜对原始音频进行滤波,滤波后的音频即是将含有多个音源的音频进行分离后的若干个子音频,之后对该子音频进行识别即可判断该子音频属于应被抑制的噪声还是应该被扩大的信号声。在分离的过程中会根据误差反向传播改良模型参数。训练完成后服务器将会在合适的时机向用户的智能终端发来更新模型的请求。
本发明提出的所述基于智能终端的环境声抑制与增强可调节耳机系统中,所述环境声信号分离模块仿照人类的注意力选择机制,在接受到一段音频信号后,先提取其声纹特征,之后遍历数据库,将之与数据库中的声纹特征加以匹配,如果能找到匹配程度较高的声源,便将该部分音频放大或缩小播放。则以此使用通过注意力选择机制将多个说话人的混合语音中筛选出受关注说话人的语音频率。
本发明还提出了一种基于智能终端的环境声抑制与增强可调节方法,包括如下步骤:
步骤一:通过麦克风采集环境声信号;
步骤二:环境声分离模块检测环境声信号中的噪声和信息声;
步骤三:由抑制模块根据噪声产生相应的同幅反向声波的抑制信号,和/或由增强模块根据信息声产生相应的同幅同向声波的增强信号;
步骤四:输出音源声信号,同时输出抑制信号和/或增强信号。
本发明提出的所述基于智能终端的环境声抑制与增强可调节方法中,步骤二进一步包括:根据数据库区分环境声信号中的噪声和信息声。
自学习在服务器完成,在服务器端获取到新的数据,或是模型参数得到改善后,会将新的模型参数输出至用户端。用户端只需定期获取最新的模型参数。模型训练共三部分,其细节如下:
步骤一:获取数据并进行预处理。所使用的数据集为互联网上公开可供使用的数据集,如timit,wsj0,thchs-30等等。数据集会不断扩充,将任意两音频混合即可形成新的混合音频,因此足以形成足够的训练音频。对每个训练音频做同样的预处理,其中包括:
1.预加重:对语音高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。
2.重采样:改变原始音频的采样率,方便数据的进一步处理。
3.分帧:根据波形的短时平稳性,将音频分割成一个个小段,减小计算量。
4.窗化:将频谱与窗函数相乘,使信号出现周期函数的部分特征。
5.端点检测:检测每帧是否有信号声存在。
6.短时傅里叶变换:将时域频谱转换为时频频谱。
步骤二:将上述预处理后的数据作为输入传入神经网络,计算原始数据频谱嵌入,作为原始音频的声音特征。
步骤三:将声音特征于特征空间进行聚类,每个聚类即是一个音源的音源特征。
上述仅为本发明的优选实施例而已,并不对本发明起到任何限制作用。任何所属技术领域的技术人员,在不脱离本发明的技术方案的范围内,对本发明揭露的技术方案和技术内容做任何形式的等同替换或修改等变动,均属未脱离本发明的技术方案的内容,仍属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!