基于运动信息的尺寸限制的制作方法
相关申请的交叉引用根据适用的专利法和/或依据巴黎公约的规则,本申请是为了及时要求于2018年10月6日提交的国际专利申请no.pct/cn2018/109255的优先权和利益。出于根据相关法律的所有目的,前述专利申请的全部内容通过引用而并入作为本专利文档的公开的一部分。本专利文档涉及视频编码技术、设备和系统。
背景技术:
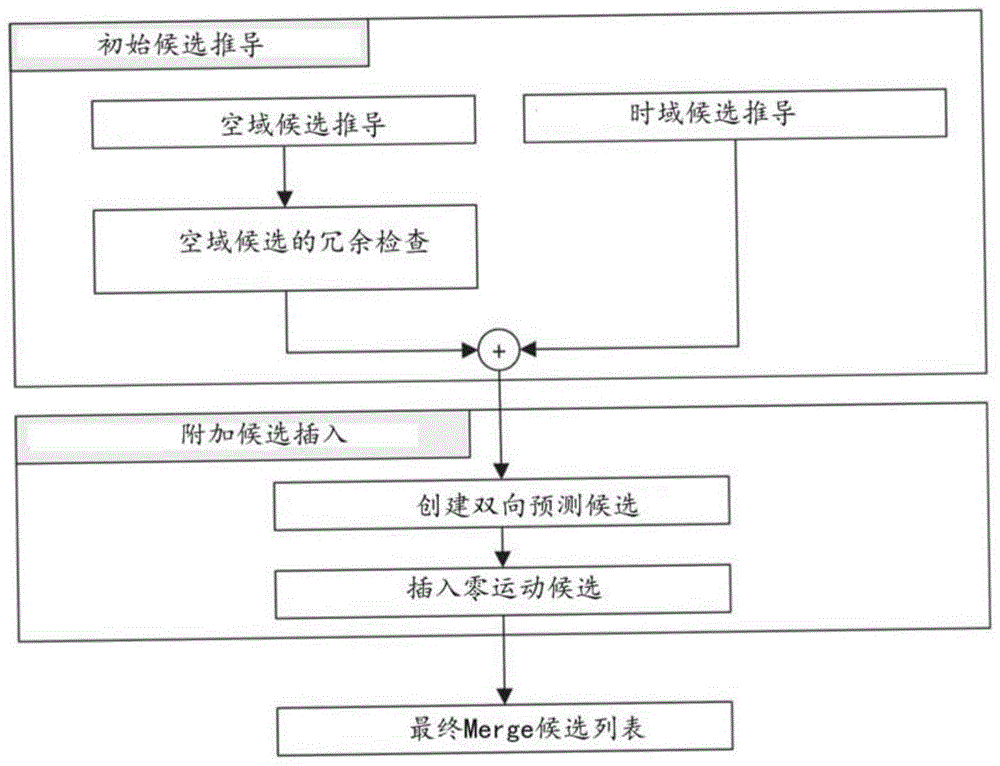
:尽管视频压缩技术有所进步,但数字视频仍然占互联网和其他数字通信网络上的最大带宽使用。随着能够接收和显示视频的连接用户设备的数量增加,预计对数字视频使用的带宽需求将继续增长。技术实现要素:描述了与数字视频编码,特别是与视频编码中子块编码工具的存储带宽减小有关的设备、系统和方法。所描述的方法可以应用于现有视频编码标准(例如,高效视频编码(highefficiencyvideocoding,hevc))和未来视频编码标准或视频编解码器。在一个代表性方面,所公开的技术可以用来提供用于视频处理的方法。该方法包括:对于视频的编码单元和视频的比特流表示之间的转换,基于与编码单元相关联的运动信息来确定编码单元的子块的子块尺寸;以及基于确定的子块尺寸来执行该转换。在另一代表性方面,所公开的技术可以用来提供用于视频处理的方法。该方法包括:对于包括子块的视频的编码单元和视频的比特流表示之间的转换,基于编码单元的尺寸来确定是否针对该转换使用存储带宽减小工具;以及基于该确定来执行该转换。在另一代表性方面,所公开的技术可以用来提供用于视频处理的方法。该方法包括:对于仿射模式中视频的编码单元和视频的比特流表示之间的转换,基于与编码单元相关联的信息来确定子块尺寸。该方法还包括基于子块尺寸来执行仿射模式中的转换。在另一代表性方面,所公开的技术可以用来提供用于视频编码的方法。该方法包括:对于当前块的比特流表示,基于与当前块相关联的运动信息来选择子块尺寸;以及基于子块尺寸来执行比特流表示和当前块之间的转换。在另一代表性方面,上述方法以处理器可运行代码的形式而体现,并且被存储在计算机可读程序介质中。在又一代表性方面,公开了一种被配置为或可操作来执行上述方法的设备。该设备可以包括被编程为实施该方法的处理器。在又一代表性方面,视频解码器装置可以实施如本文所描述的方法。在附图、说明书和权利要求中更详细地描述了所公开的技术的上述以及其他方面和特征。附图说明图1示出了构建merge候选列表的示例。图2示出了空域候选的位置的示例。图3示出了进行空域merge候选的冗余检查的候选对的示例。图4a和图4b示出了基于当前块的尺寸和形状的第二预测单元(predictionunit,pu)的位置的示例。图5示出了用于时域merge候选的运动矢量缩放的示例。图6示出了时域merge候选的候选位置的示例。图7示出了生成组合的双向预测merge候选的示例。图8示出了构建运动矢量预测候选的示例。图9示出了用于空域运动矢量候选的运动矢量缩放的示例。图10示出了使用用于编码单元(codingunit,cu)的可选时域运动矢量预测(alternativetemporalmotionvectorprediction,atmvp)算法的运动预测的示例。图11示出了具有由空时运动矢量预测(spatial-temporalmotionvectorprediction,stmvp)算法使用的子块和相邻块的编码单元(cu)的示例。图12示出了以不同的mv精度进行编码的示例流程图。图13a和图13b示出了当使用重叠块运动补偿(overlappedblockmotioncompensation,obmc)算法时的子块的示例快照。图14示出了用来推导局部光照补偿(localilluminationcompensation,lic)算法的参数的相邻样点的示例。图15示出了简化的仿射运动模型的示例。图16示出了每个子块的仿射运动矢量场(affinemotionvectorfield,mvf)的示例。图17示出了af_inter仿射运动模式的运动矢量预测(motionvectorprediction,mvp)的示例。图18a和图18b分别示出了4-参数仿射模型和6-参数仿射模型的示例。图19a和图19b示出了af_merge仿射运动模式的示例候选。图20示出了模式匹配的运动矢量推导(patternmatchedmotionvectorderivation,pmmvd)模式中的双边匹配的示例,其是基于帧速率上转换(frame-rateupconversion,fruc)算法的特殊merge模式。图21示出了fruc算法中的模板匹配的示例。图22示出了fruc算法中的单边运动估计的示例。图23示出了由双向光流(bi-directionalopticalflow,bio)算法使用的光流轨迹的示例。图24a和图24b示出了在没有块扩展的情况下使用双向光流(bio)算法的示例快照。图25示出了基于双边模板匹配的解码器侧运动矢量细化(decoder-sidemotionvectorrefinement,dmvr)算法的示例。图26示出了编码单元的参考矩形区域的示例。图27示出了仿射模式中的运动矢量约束的示例。图28示出了用于视频编码的示例方法的流程图。图29是用于实施本文档中描述的可视媒体解码或可视媒体编码技术的硬件平台的示例的框图。图30是其中可以实施所公开的技术的示例视频处理系统的框图。图31是根据本技术的用于视频处理的方法的流程图表示。图32是根据本技术的用于视频处理的另一方法的流程图表示。图33是根据本技术的用于视频处理的又一方法的流程图表示。具体实施方式由于对更高分辨率视频的日益增长的需求,视频编码方法和技术在现代技术中无处不在。视频编解码器通常包括压缩或解压缩数字视频的电子电路或软件,并且正在不断被改进以提供更高的编码效率。视频编解码器将未压缩的视频转换为压缩格式,反之亦然。视频质量、用来表示视频的数据量(由比特率确定)、编码和解码算法的复杂性、对数据丢失和错误的敏感性、编辑的简易性、随机访问和端到端延迟(时延)之间存在复杂的关系。压缩格式通常符合标准视频压缩规范,例如,高效视频编码(hevc)标准(也已知为h.265或mpeg-h第2部分)、要完成的通用视频编码标准、或其他当前和/或未来视频编码标准。所公开的技术的实施例可以应用于现有视频编码标准(例如,hevc、h.265)和未来标准以改进压缩性能。在本文档中使用章节标题以提高描述的可读性,并且不以任何方式将讨论或实施例(和/或实施方式)仅限制于各个章节。1.hevc/h.265中的帧间预测的示例多年来,视频编码标准已经得到显着改进,并且现在部分地提供高编码效率并且支持更高的分辨率。诸如hevc和h.265的最新标准基于其中利用时域预测加变换编码的混合视频编码结构。1.1预测模式的示例每个帧间预测的pu(预测单元)具有一个或两个参考图片列表的运动参数。在一些实施例中,运动参数包括运动矢量和参考图片索引。在其他实施例中,也可以使用inter_pred_idc来信令通知对两个参考图片列表中的一个的使用。在又一些实施例中,可以将运动矢量显式地编码为相对于预测值的增量(delta)。当用跳过模式对cu进行编码时,一个pu与cu相关联,并且不存在显著的残差系数、不存在编码的运动矢量增量或参考图片索引。指定merge模式,从而从相邻pu获得当前pu的运动参数,包括空域和时域候选。merge模式可以应用于任何帧间预测的pu,而不仅应用于跳过模式。merge模式的替代是运动参数的显式传输,其中,对于每个pu,显式地信令通知运动矢量、每个参考图片列表的对应参考图片索引、以及参考图片列表使用。当信令指示将使用两个参考图片列表中的一个时,从一个样点块产生pu。这被称为“单向预测(uni-prediction)”。单向预测可用于p条带和b条带两者。当信令指示将使用两个参考图片列表时,从两个样点块产生pu。这被称为“双向预测(bi-prediction)”。双向预测仅可用于b条带。1.1.1构建merge模式的候选的实施例当使用merge模式预测pu时,从比特流解析指向merge候选列表中的条目的索引并将其用于检索运动信息。该列表的构建可以根据以下步骤序列总结:步骤1:初始候选推导步骤1.1:空域候选推导步骤1.2:空域候选的冗余检查步骤1.3:时域候选推导步骤2:附加候选插入步骤2.1:创建双向预测候选步骤2.2:插入零运动候选图1示出了基于上面总结的步骤序列构建merge候选列表的示例。对于空域merge候选推导,在位于五个不同位置的候选当中选择最多四个merge候选。对于时域merge候选推导,在两个候选当中选择最多一个merge候选。由于在解码器处假设每个pu的恒定数量的候选,因此当候选的数量未达到在条带报头中信令通知的最大merge候选数量(maxnummergecand)时,生成附加候选。由于候选的数量是恒定的,因此使用截断的一元二值化(truncatedunarybinarization,tu)来编码最佳merge候选的索引。如果cu的尺寸等于8,则当前cu的所有pu共享单个merge候选列表,其与2n×2n预测单元的merge候选列表相同。1.1.2构建空域merge候选在空域merge候选的推导中,在位于图2描绘的位置的候选当中选择最多四个merge候选。推导的顺序是a1、b1、b0、a0和b2。仅当位置a1、b1、b0、a0的任何pu不可用(例如,因为它属于另一条带或片)或者是帧内编码时,才考虑位置b2。在添加位置a1处的候选之后,对剩余候选的添加进行冗余检查,其确保具有相同运动信息的候选被排除在列表之外,使得编码效率提高。为了降低计算复杂度,在所提到的冗余检查中并未考虑所有可能的候选对。相反,仅考虑图3中用箭头连结的对,并且仅在用于冗余检查的对应候选具有不一样的运动信息时,才将候选添加到列表。重复运动信息的另一来源是与不同于2n×2n的分割相关联的“第二pu”。作为示例,图4a和图4b分别描绘了针对情况n×2n和2n×n的第二pu。当当前pu被分割为n×2n时,位置a1处的候选不被考虑用于列表构建。在一些实施例中,添加该候选可能导致具有相同运动信息的两个预测单元,这对于在编码单元中仅具有一个pu是冗余的。类似地,当当前pu被分割为2n×n时,不考虑位置b1。1.1.3构建时域merge候选在该步骤中,只有一个候选被添加到列表。具体地,在该时域merge候选的推导中,基于并置pu来推导缩放的运动矢量,该并置pu属于给定参考图片列表内与当前图片具有最小poc差的图片。在条带报头中显式地信令通知要用于并置pu的推导的参考图片列表。图5示出了时域merge候选的缩放的运动矢量的推导的示例(如虚线),其是使用poc距离tb和td从并置pu的运动矢量缩放的,其中tb被定义为当前图片的参考图片与当前图片之间的poc差,并且td被定义为并置图片的参考图片与并置图片之间的poc差。时域merge候选的参考图片索引被设置为等于零。对于b条带,获得两个运动矢量,一个用于参考图片列表0,另一个用于参考图片列表1,并且组合该两个运动矢量以得到双向预测merge候选。在属于参考帧的并置pu(y)中,在候选c0和c1之间选择时域候选的位置,如图6所描绘的。如果位置c0处的pu不可用、是帧内编码的、或者在当前ctu之外,则使用位置c1。否则,位置c0用于时域merge候选的推导。1.1.4构建附加类型的merge候选除了空时merge候选之外,还存在两种附加类型的merge候选:组合的双向预测merge候选和零merge候选。通过利用空时merge候选来生成组合的双向预测merge候选。组合的双向预测merge候选仅用于b条带。通过将初始候选的第一参考图片列表运动参数与另一候选的第二参考图片列表运动参数组合来生成组合的双向预测候选。如果这两个元组提供不同的运动假设,它们将形成新的双向预测候选。图7示出了该过程的示例,其中,原始列表(左侧的710)中的具有mvl0和refidxl0或mvl1和refidxl1的两个候选用来创建添加到最终列表(右侧的720)的组合的双向预测merge候选。插入零运动候选以填充merge候选列表中的剩余条目,从而达到maxnummergecand容量。这些候选具有零空域位移和从零开始并且每当新的零运动候选被添加到列表时增加的参考图片索引。对于单向和双向预测,由这些候选使用的参考帧的数量分别是一和二。在一些实施例中,不对这些候选执行冗余检查。1.1.5用于并行处理的运动估计区域的示例为了加速编码处理,可以并行执行运动估计,从而同时推导给定区域内部的所有预测单元的运动矢量。从空域邻域推导merge候选可能干扰并行处理,因为一个预测单元直到其相关联的运动估计完成时才能从邻近pu推导运动参数。为了减轻编码效率和处理等待时间之间的折衷,可以定义运动估计区域(motionestimationregion,mer)。mer的尺寸可以在图片参数集(pictureparameterset,pps)中使用“log2_parallel_merge_level_minus2”语法元素而信令通知。当定义mer时,落入相同区域的merge候选被标记为不可用,并且因此在列表构建中不予考虑。1.2高级运动矢量预测(advancedmotionvectorprediction,amvp)的示例amvp利用运动矢量与相邻pu的空时相关性,其用于运动参数的显式传输。它通过首先检查时域上相邻的pu位置的左侧、上侧的可用性,移除冗余候选并添加零矢量以使候选列表为恒定长度来构建运动矢量候选列表。然后,编码器可以从候选列表选择最佳预测值,并且发送指示所选候选的对应索引。与merge索引信令类似,使用截断的一元来编码最佳运动矢量候选的索引。在这种情况下要编码的最大值是2(参见图8)。在以下章节中,提供了关于运动矢量预测候选的推导过程的细节。1.2.1构建运动矢量预测候选的示例图8总结了运动矢量预测候选的推导过程,并且可以针对具有作为输入的refidx的每个参考图片列表而实施。在运动矢量预测中,考虑两种类型的运动矢量候选:空域运动矢量候选和时域运动矢量候选。对于空域运动矢量候选推导,最终基于位于如先前在图2中示出的五个不同位置的每个pu的运动矢量推导两个运动矢量候选。对于时域运动矢量候选推导,从两个候选选择一个运动矢量候选,其是基于两个不同的并置位置推导的。在产生空时候选的第一列表之后,移除列表中的重复的运动矢量候选。如果潜在候选的数量大于二,则从列表移除相关联的参考图片列表内的其参考图片索引大于1的运动矢量候选。如果空时运动矢量候选的数量小于二,则将附加零运动矢量候选添加到列表中。1.2.2构建空域运动矢量候选在空域运动矢量候选的推导中,在五个潜在候选当中考虑最多两个候选,其从位于如先前在图2中示出的位置的pu推导,那些位置与运动merge的位置相同。将当前pu的左侧的推导顺序定义为a0、a1,以及缩放的a0、缩放的a1。将当前pu的上侧的推导顺序定义为b0、b1、b2,缩放的b0、缩放的b1、缩放的b2。因此,对于每一侧,存在可以用作运动矢量候选的四种情况,其中两种情况不需要使用空域缩放,并且两种情况使用空域缩放。四种不同的情况总结如下:--无空域缩放(1)相同的参考图片列表,以及相同的参考图片索引(相同的poc)(2)不同的参考图片列表,但相同的参考图片(相同的poc)--空域缩放(3)相同的参考图片列表,但不同的参考图片(不同的poc)(4)不同的参考图片列表,以及不同的参考图片(不同的poc)首先检查无空域缩放的情况,然后检查允许空域缩放的情况。当poc在相邻pu的参考图片和当前pu的参考图片之间不同时,考虑空域缩放,而不管参考图片列表。如果左侧候选的所有pu都不可用或者是帧内编码的,则允许对上侧运动矢量进行缩放以帮助左侧和上侧mv候选的并行推导。否则,不允许对上侧运动矢量进行空域缩放。如图9中的示例所示,对于空域缩放情况,以与时域缩放类似的方式缩放相邻pu的运动矢量。一个差异是给出参考图片列表和当前pu的索引作为输入;实际缩放过程与时域缩放过程相同。1.2.3构建时域运动矢量候选除了参考图片索引推导之外,用于推导时域merge候选的所有过程与用于推导空域运动矢量候选的过程相同(如图6中的示例所示)。在一些实施例中,参考图片索引被信令通知到解码器。2.联合探索模型(jointexplorationmodel,jem)中的帧间预测方法的示例在一些实施例中,使用已知为联合探索模型(jem)的参考软件来探索未来视频编码技术。在jem中,在几个编码工具中采用基于子块的预测,诸如仿射预测、可选时域运动矢量预测(atmvp)、空时运动矢量预测(stmvp)、双向光流(bio),帧速率上转换(fruc)、局部自适应运动矢量分辨率(locallyadaptivemotionvectorresolution,lamvr)、重叠块运动补偿(obmc)、局部光照补偿(lic)和解码器侧运动矢量细化(decoder-sidemotionvectorrefinement,dmvr)。2.1基于子cu的运动矢量预测的示例在具有四叉树加二叉树(quadtreesplusbinarytrees,qtbt)的jem中,每个cu可以具有用于每个预测方向的至多一个运动参数集。在一些实施例中,通过将大cu划分为子cu并且推导大cu的所有子cu的运动信息,在编码器中考虑两个子cu级别运动矢量预测方法。可选时域运动矢量预测(atmvp)方法允许每个cu从小于并置参考图片中的当前cu的多个块提取运动信息的多个集合。在空时运动矢量预测(stmvp)方法中,通过使用时域运动矢量预测值和空域相邻运动矢量来递归地推导子cu的运动矢量。在一些实施例中并且为了保留子cu运动预测的更准确的运动场,可以禁用参考帧的运动压缩。2.1.1可选时域运动矢量预测(atmvp)的示例在atmvp方法中,通过从小于当前cu的块提取运动信息(包括运动矢量和参考索引)的多个集合来修改时域运动矢量预测(temporalmotionvectorprediction,tmvp)方法。图10示出了cu1000的atmvp运动预测过程的示例。atmvp方法以两个步骤预测cu1000内的子cu1001的运动矢量。第一步骤是利用时域矢量识别参考图片1050中的对应块1051。参考图片1050也被称为运动源图片。第二步骤是将当前cu1000划分为子cu1001,并且从对应于每个子cu的块获得运动矢量以及每个子cu的参考索引。在第一步骤中,通过当前cu1000的空域相邻块的运动信息确定参考图片1050和对应块。为了避免相邻块的重复扫描过程,使用当前cu1000的merge候选列表中的第一merge候选。第一可用运动矢量及其相关联的参考索引被设置为时域矢量和运动源图片的索引。这样,与tmvp相比,可以更准确地识别对应块,其中对应块(有时称为并置块)总是在相对于当前cu的右下方或中心位置。在第二步骤中,通过向当前cu的坐标添加时域矢量,通过运动源图片1050中的时域矢量来识别子cu1051的对应块。对于每个子cu,其对应块(例如,覆盖中心样点的最小运动网格)的运动信息用于推导子cu的运动信息。在识别了对应n×n块的运动信息之后,以与hevc的tmvp相同的方式将其转换为当前子cu的运动矢量和参考索引,其中运动缩放和其他过程适用。例如,解码器检查是否满足低延迟条件(例如,当前图片的所有参考图片的poc小于当前图片的poc)并且可能使用运动矢量mvx(例如,对应于参考图片列表x的运动矢量)来预测每个子cu的运动矢量mvy(例如,x等于0或1,y等于1-x)。2.1.2空时运动矢量预测(stmvp)的示例在stmvp方法中,按照光栅扫描顺序递归地推导子cu的运动矢量。图11示出了具有四个子块的一个cu和相邻块的示例。考虑包括四个4×4子cua(1101)、b(1102)、c(1103)和d(1104)的8×8cu1100。当前帧中的相邻4×4块被标记为a(1111)、b(1112)、c(1113)和d(1114)。子cua的运动推导通过识别其两个空域邻居开始。第一邻居是子cua(1101)的上侧的n×n块(块c1113)。如果该块c(1113)不可用或者是帧内编码的,则检查子cua(1101)的上侧的其他n×n块(从块c1113开始,从左到右)。第二邻居是子cua1101的左侧的块(块b1112)。如果块b(1112)不可用或者是帧内编码的,则检查子cua1101的左侧的其他块(从块b1112开始,从上到下)。从每个列表的相邻块获得的运动信息被缩放到给定列表的第一参考帧。接下来,通过遵循与hevc中指定的tmvp推导的过程相同的过程来推导子块a1101的时域运动矢量预测值(temporalmotionvectorpredictor,tmvp)。提取块d1114处的并置块的运动信息并对应地缩放。最后,在检索和缩放运动信息之后,分别针对每个参考列表平均所有可用的运动矢量。指派平均的运动矢量为当前子cu的运动矢量。2.1.3子cu运动预测模式信令通知的示例在一些实施例中,启用子cu模式作为附加merge候选,并且不需要附加语法元素来信令通知该模式。将两个附加merge候选添加到每个cu的merge候选列表以表示atmvp模式和stmvp模式。在另一些实施例中,如果序列参数集指示启用了atmvp和stmvp,则使用多达七个merge候选。附加merge候选的编码逻辑与hm中的merge候选相同,这意味着,对于p条带或b条带中的每个cu,对于两个附加merge候选可能需要另外两个rd检查。在一些实施例中,例如jem,merge索引的所有二进制位通过cabac(基于上下文的自适应二进制算术编码)进行上下文编码。在另一些实施例中,例如,hevc,仅对第一个二进制位进行上下文编码,并且对剩余的二进制位进行上下文旁路编码。2.2自适应运动矢量差分辨率的示例在一些实施例中,当条带报头中的use_integer_mv_flag等于0时,以四分之一亮度样点为单位信令通知(pu的运动矢量和预测的运动矢量之间的)运动矢量差(motionvectordifference,mvd)。在jem中,引入了局部自适应运动矢量分辨率(lamvr)。在jem中,mvd可以以四分之一亮度样点、整数亮度样点或四亮度样点为单位而编码。在编码单元(cu)级别控制mvd分辨率,并且对于具有至少一个非零mvd分量的每个cu有条件地信令通知mvd分辨率标志。对于具有至少一个非零mvd分量的cu,信令通知第一标志以指示在cu中是否使用四分之一亮度样点mv精度。当第一标志(等于1)指示不使用四分之一亮度样点mv精度时,信令通知另一标志以指示是使用整数亮度样点mv精度还是使用四亮度样点mv精度。当cu的第一mvd分辨率标志为零或不针对cu而编码(意味着cu中的所有mvd是零)时,四分之一亮度样点mv分辨率用于cu。当cu使用整数亮度样点mv精度或四亮度样点mv精度时,cu的amvp候选列表中的mvp被取整到对应精度。在编码器中,cu级别rd检查用于确定哪个mvd分辨率要用于cu。即,对于每个mvd分辨率执行三次cu级别rd检查。为了加快编码器速度,在jem中应用以下编码方案:--在具有常规四分之一亮度样点mvd分辨率的cu的rd检查期间,存储当前cu的运动信息(整数亮度样点精度)。存储的(在取整之后的)运动信息在具有整数亮度样点和4亮度样点mvd分辨率的相同cu的rd检查期间用作进一步小范围运动矢量细化的开始点,使得耗时的运动估计过程不重复三次。--有条件地调用具有4亮度样点mvd分辨率的cu的rd检查。对于cu,当整数亮度样点mvd分辨率的rd成本比四分之一亮度样点mvd分辨率的rd成本大得多时,跳过cu的4亮度样点mvd分辨率的rd检查。编码过程在图12中示出。首先,测试1/4像素mv,并且计算rd成本并将其表示为rdcost0,然后测试整数mv并将rd成本表示为rdcost1。如果rdcost1<th*rdcost0(其中th为正值阈值),则测试4像素mv;否则跳过4像素mv。基本上,在检查整数或4像素mv时,对于1/4像素mv已经知道运动信息和rd成本等,其可以被重新使用以加快整数或4像素mv的编码过程。2.3更高的运动矢量存储精度的示例在hevc中,运动矢量精度为四分之一像素(对于4:2:0视频,四分之一亮度样点和八分之一色度样点)。在jem中,内部运动矢量存储和merge候选的精度增加到1/16像素。更高的运动矢量精度(1/16像素)用于以跳过/merge模式编码的cu的运动补偿帧间预测。对于以常规amvp模式而编码的cu,使用整数像素或四分之一像素运动。具有与hevc运动补偿插值滤波器相同的滤波器长度和归一化因子的shvc上采样插值滤波器被用作附加分数像素位置的运动补偿插值滤波器。在jem中色度分量运动矢量精度为1/32样点,通过使用两个相邻的1/16像素分数位置的滤波器的平均来推导1/32像素分数位置的附加插值滤波器。2.4重叠块运动补偿(obmc)的示例在jem中,可以使用cu级别的语法来打开和关闭obmc。当在jem中使用obmc时,除了cu的右侧边界和底部边界之外,对所有运动补偿(motioncompensation,mc)块边界执行obmc。此外,它还应用于亮度和色度分量两者。在jem中,mc块对应于编码块。当用子cu模式(包括子cumerge、仿射和fruc模式)编码cu时,cu的每个子块是mc块。为了以统一的方式处理cu边界,对于所有mc块边界以子块级别执行obmc,其中子块尺寸被设置为等于4×4,如图13a和图13b所示。图13a示出了cu/pu边界处的子块,并且阴影子块是obmc应用的位置。类似地,图13b示出了atmvp模式中的子pus。当obmc应用于当前子块时,除了当前运动矢量之外,四个连接的相邻子块的运动矢量(如果可用且与当前运动矢量不同)也用于推导当前子块的预测块。组合基于多个运动矢量的这些多个预测块以生成当前子块的最终预测信号。将基于相邻子块的运动矢量的预测块表示为pn,其中n指示相邻的上侧、下侧、左侧和右侧子块的索引,并且将基于当前子块的运动矢量的预测块表示为pc。当pn是基于包含与当前子块相同的运动信息的相邻子块的运动信息时,不从pn执行obmc。否则,将pn的每个样点添加到pc中的相同样点,即将pn的四行/列添加到pc。加权因子{1/4,1/8,1/16,1/32}用于pn,并且加权因子{3/4,7/8,15/16,31/32}用于pc。例外是小mc块(即,当编码块的高度或宽度等于4或cu是用子cu模式编码的时),对其仅将pn的两行/列添加到pc。在这种情况下,加权因子{1/4,1/8}用于pn,并且加权因子{3/4,7/8}用于pc。对于基于垂直(水平)相邻子块的运动矢量生成的pn,将pn的相同行(列)中的样点添加到具有相同加权因子的pc。在jem中,对于尺寸小于或等于256个亮度样点的cu,信令通知cu级别标志以指示是否对当前cu应用obmc。对于尺寸超过256个亮度样点或未使用amvp模式进行编码的cu,默认应用obmc。在编码器处,当将obmc应用于cu时,在运动估计阶段期间考虑其影响。由obmc使用顶部相邻块和左侧相邻块的运动信息形成的预测信号用于补偿当前cu的原始信号的顶部边界和左侧边界,然后应用常规运动估计处理。2.5局部光照补偿(lic)的示例lic是基于使用缩放因子a和偏移b的、用于光照变化的线性模型。并且针对每个帧间模式编码的编码单元(cu)自适应地启用或禁用它。当lic应用于cu时,采用最小平方误差方法来通过使用当前cu的相邻样点及其对应参考样点来推导参数a和b。图14示出了用来推导ic算法的参数的相邻样点的示例。更具体地并且如图14所示,使用cu的子采样(2:1子采样)相邻样点和参考图片中的(由当前cu或子cu的运动信息识别的)对应样点。推导ic参数并将其分别应用于每个预测方向。当用merge模式编码cu时,以类似于merge模式中的运动信息复制的方式从相邻块复制lic标志;否则,向cu信令通知lic标志以指示是否应用lic。当针对图片启用lic时,需要附加cu级别rd检查以确定是否将lic应用于cu。当针对cu启用lic时,分别针对整数像素运动搜索和分数像素运动搜索,使用去均值绝对差之和(mean-removedsumofabsolutedifference,mr-sad)和去均值绝对哈达玛变换差之和(mean-removedsumofabsolutehadamard-transformeddifference,mr-satd),而不是sad和satd。为了降低编码复杂度,在jem中应用以下编码方案:--当当前图片与其参考图片之间没有明显的光照变化时,对于整个图片禁用lic。为了识别这种情形,在编码器处计算当前图片和当前图片的每个参考图片的直方图。如果当前图片与当前图片的每个参考图片之间的直方图差小于给定阈值,则针对当前图片禁用lic;否则,针对当前图片启用lic。2.6仿射运动补偿预测的示例在hevc中,仅将平移运动模型应用于运动补偿预测(motioncompensationprediction,mcp)。然而,相机和物体可以具有多种运动,例如放大/缩小、旋转、透视运动和/或其他不规则运动。另一方面,jem应用简化的仿射变换运动补偿预测。图15示出了块1500的由两个控制点运动矢量v0和v1描述的仿射运动场的示例。块1500的运动矢量场(mvf)可以通过以下等式描述:如图15所示,(v0x,v0y)是左上角控制点的运动矢量,并且(v1x,v1y)是右上角控制点的运动矢量。为了简化运动补偿预测,可以应用基于子块的仿射变换预测。子块尺寸m×n如下推导:这里,mvpre是运动矢量分数精度(例如,jem中的1/16)。(v2x,v2y)是左下角控制点的运动矢量,根据等式(1)而计算。如果需要,可以向下调整m和n,使其分别为w和h的除数。图16示出了块1600的每个子块的仿射mvf的示例。为了推导每个m×n子块的运动矢量,可以根据等式(1)计算每个子块的中心样点的运动矢量,并且将其取整到运动矢量分数精度(例如,jem中的1/16)。然后,可以应用运动补偿插值滤波器以用推导的运动矢量生成每个子块的预测。在mcp之后,对每个子块的高精度运动矢量进行取整,并且将其以与常规运动矢量相同的精度保存。2.6.1af_inter模式的示例在jem中,存在两种仿射运动模式:af_inter模式和af_merge模式。对于宽度和高度都大于8的cu,可以应用af_inter模式。在比特流中信令通知cu级别中的仿射标志以指示是否使用af_inter模式。在af_inter模式中,使用相邻块来构建具有运动矢量对{(v0,v1)|v0={va,vb,vc},v1={vd,ve}}的候选列表。图17示出了af_inter模式中的块1700的运动矢量预测(mvp)的示例。如图17所示,从子块a、b或c的运动矢量选择v0。可以根据参考列表缩放来自相邻块的运动矢量。还可以根据相邻块的参考的图片顺序计数(poc)、当前cu的参考的poc和当前cu的poc之间的关系来缩放运动矢量。从相邻子块d和e选择v1的方法是类似的。如果候选列表的数量小于2,则由通过复制每个amvp候选而组成的运动矢量对填充列表。当候选列表大于2时,可以首先根据相邻运动矢量(例如,基于对候选(paircandidate)中的两个运动矢量的相似性)对候选进行排序。在一些实施方式中,保留前两个候选。在一些实施例中,速率失真(ratedistortion,rd)成本检查用来确定选择哪个运动矢量对候选作为当前cu的控制点运动矢量预测(controlpointmotionvectorprediction,cpmvp)。可以在比特流中信令通知指示cpmvp在候选列表中的位置的索引。在确定当前仿射cu的cpmvp之后,应用仿射运动估计并找到控制点运动矢量(controlpointmotionvector,cpmv)。然后在比特流中信令通知cpmv和cpmvp的差。在af_inter模式中,当使用4/6参数仿射模式时,需要2/3个控制点,因此需要针对这些控制点编码2/3个mvd,如图18a和图18b所示。在现有实施方式中,mv可以如下推导,例如,它从mvd0预测mvd1和mvd2。本文中,mvdi和mv1是预测的运动矢量,左上方像素(i=0)、右上方像素(i=1)或左下方像素(i=2)的运动矢量差和运动矢量分别如图18b所示。在一些实施例,添加两个运动矢量(例如,mva(xa,ya)和mvb(xb,yb))等于两个分量各自地的和。例如,newmv=mva+mvb暗示newmv的两个分量被分别设置为(xa+xb)和(ya+yb)。2.6.2af_inter模式中的快速仿射me算法的示例在仿射模式的一些实施例中,需要联合确定2个或3个控制点的mv。直接联合搜索多个mv是计算复杂的。在示例中,提出一种快速仿射me算法,并且将其纳入vtm/bms。例如,针对4-参数仿射模型描述了快速仿射me算法,并且该思想可以扩展到6-参数仿射模型。用a’替换(a-1)使得运动矢量能够被重写为:如果假设两个控制点(0,0)和(0,w)的运动矢量是已知的,则根据等式(5),仿射参数可以被推导为:可以以矢量形式将运动矢量重写为:本文中,p=(x,y)是像素位置。在一些实施例中,并且在编码器处,可以迭代地推导af_inter的mvd。将mvi(p)表示为在位置p的第i次迭代中推导的mv,并且将dmvci表示为在第i次迭代中mvc的更新的增量。然后在第(i+1)次迭代中,将picref表示为参考图片,并将piccur表示为当前图片,并且表示q=p+mvi(p)。如果mse用作匹配准则,则需要最小化的函数可以写为:如果假设足够小,则可以被重写为基于1阶泰勒展开的近似值,如下:本文中,如果采用符号ei+1(p)=piccur(p)-picref(q),则:项可以通过将误差函数的导数设置为零,然后根据计算控制点(0,0)和(0,w)的增量mv而推导,如下:在一些实施例中,该mvd推导过程可以迭代n次,并且最终mvd可以如下计算:在前述实施方式中,从由mvd0表示的控制点(0,0)的增量mv预测由mvd1表示的控制点(0,w)的增量mv,引起对于mvd1,仅被编码。2.6.3af_merge模式的示例当在af_merge模式中应用cu时,其从有效的相邻重构块得到以仿射模式编码的第一块。图19a示出了当前cu1900的候选块的选择顺序的示例。如图19a所示,选择顺序可以是从当前cu1900的左侧(1901)、上侧(1902)、右上侧(1903)、左下角(1904)到左上侧(1905)。图19b示出了af_merge模式中的当前cu1900的候选块的另一示例。如果相邻的左下角块1901以仿射模式而编码,如图19b所示,则推导包含子块1901的cu的左上角、右上角和左下角的运动矢量v2、v3和v4。基于v2、v3和v4计算当前cu1900的左上角的运动矢量v0。可以相应地计算当前cu的右上侧的运动矢量v1。在根据等式(1)中的仿射运动模型计算当前cuv0和v1的cpmv之后,可以生成当前cu的mvf。为了识别当前cu是否以af_merge模式而编码,当存在至少一个相邻块以仿射模式而编码时,可以在比特流中信令通知仿射标志。2.7模式匹配的运动矢量推导(pmmvd)的示例pmmvd模式是基于帧速率上转换(fruc)方法的特殊merge模式。利用该模式,在解码器侧推导块的运动信息,而不是信令通知块的运动信息。当cu的merge标志为真时,可以向cu信令通知fruc标志。当fruc标志为假时,可以信令通知merge索引并使用常规merge模式。当fruc标志为真时,可以信令通知附加fruc模式标志以指示将使用哪种方法(例如,双边匹配或模板匹配)来推导该块的运动信息。在编码器侧,关于是否对cu使用frucmerge模式的决定是基于对常规merge候选所做的rd成本选择。例如,通过使用rd成本选择来针对cu检查多个匹配模式(例如,双边匹配和模板匹配)。引起最小成本的匹配模式与其他cu模式进一步比较。如果fruc匹配模式是最有效的模式,则对于cu将fruc标志设置为真,并且使用相关的匹配模式。通常,frucmerge模式中的运动推导过程具有两个步骤:首先执行cu级别运动搜索,然后进行子cu级别运动细化。在cu级别处,基于双边匹配或模板匹配,为整个cu推导初始运动矢量。首先,生成mv候选的列表,并且选择引起最小匹配成本的候选作为进一步cu级别细化的起点。然后,在起点附近执行基于的双边匹配或模板匹配的局部搜索。将引起最小匹配成本的mv结果作为整个cu的mv。随后,以推导的cu运动矢量作为起点,在子cu级别处进一步细化运动信息。例如,对于w×hcu运动信息推导执行以下推导过程。在第一阶段,推导整个w×hcu的mv。在第二阶段,该cu进一步被划分为m×m子cu。m的值如等式(3)而计算,d是预定义的划分深度,在jem中默认设置为3。然后推导每个子cu的mv。图20示出了在帧速率上转换(fruc)方法中使用的双边匹配的示例。通过在两个不同参考图片(2010、2011)中沿当前cu(2000)的运动轨迹找到两个块之间的最接近匹配,使用双边匹配来推导当前cu的运动信息。在连续运动轨迹的假设下,指向两个参考块的运动矢量mv0(2001)和mv1(2002)与当前图片和两个参考图片之间的时域距离(例如,td0(2003)和td1(2004))成比例。在一些实施例中,当当前图片2000在时域上在两个参考图片(2010、2011)之间并且从当前图片到两个参考图片的时域距离相同时,双边匹配成为基于镜像的双向mv。图21示出了在帧速率上转换(fruc)方法中使用的模板匹配的示例。模板匹配可以用来通过找到当前图片中的模板(例如,当前cu的顶部和/或左侧相邻块)与参考图片2110中的块(例如,与模板的尺寸相同)之间的最接近匹配来推导当前cu2100的运动信息。除了前述frucmerge模式之外,模板匹配也可以应用于amvp模式。在jem和hevc两者中,amvp具有两个候选。利用模板匹配方法,新的候选可以被推导。如果模板匹配新推导的候选与第一现有amvp候选不同,则将其插入amvp候选列表的最开始处,然后将列表尺寸设置为二(例如,通过移除第二现有amvp候选)。当应用于amvp模式时,仅应用cu级别搜索。cu级别处的mv候选集可以包括以下:(1)如果当前cu处于amvp模式,则原始amvp候选,(2)所有merge候选,(3)插值mv场中的几个mv(稍后描述),以及(4)顶部和左侧相邻运动矢量。当使用双边匹配时,可以将merge候选的每个有效mv用作输入,以生成假设双边匹配的情况下的mv对。例如,在参考列表a处,merge候选的一个有效mv是(mva,refa)。然后,在另一参考列表b中找到其配对的双边mv的参考图片refb,使得refa和refb在时域上位于当前图片的不同侧。如果这样的refb在参考列表b中不可用,则refb被确定为与refa不同的参考,并且其到当前图片的时域距离是列表b中的最小值。在确定refb之后,通过基于当前图片与refa、refb之间的时域距离来缩放mva来推导mvb。在一些实施例中,来自插值mv场的四个mv也可以被添加到cu级别候选列表。更具体地,添加当前cu的位置(0,0)、(w/2,0)、(0,h/2)和(w/2,h/2)处的插值mv。当fruc应用于amvp模式中时,原始amvp候选也被添加到cu级别mv候选集。在一些实施例中,在cu级别处,amvpcu的15个mv和mergecu的13个mv可以被添加到候选列表。子cu级别处的mv候选集包括:(1)从cu级别搜索确定的mv,(2)顶部、左侧、左上角和右上角相邻mv,(3)来自参考图片的并置mv的缩放版本,(4)一个或多个atmvp候选(例如,多达四个),和(5)一个或多个stmvp候选(例如,多达四个)。来自参考图片的缩放mv如下推导。遍历两个列表中的参考图片。参考图片中的子cu的并置位置处的mv被缩放到起始cu级别mv的参考。atmvp和stmvp候选可以是前四个。在子cu级别处,一个或多个mv(例如,多达17个)被添加到候选列表。插值mv场的生成。在对帧进行编码之前,基于单边me为整个图片生成插值运动场。然后,运动场可以稍后用作cu级别或子cu级别mv候选。在一些实施例中,两个参考列表中的每个参考图片的运动场以4×4块级别遍历。图22示出了fruc方法中的单边运动估计(motionestimation,me)2200的示例。对于每个4×4块,如果与块相关联的运动通过当前图片中的4×4块并且块未被分配任何插值运动,则参考块的运动根据时域距离td0和td1(以与hevc中的tmvp的mv缩放的方式相同的方式)被缩放到当前图片,并且缩放的运动被分配给当前帧中的块。如果没有缩放的mv被分配给4×4块,则在插值运动场中将块的运动标记为不可用。插值和匹配成本。当运动矢量指向分数样点位置时,需要运动补偿插值。为了降低复杂度,可以将双线性插值而不是常规8抽头hevc插值用于双边匹配和模板匹配。匹配成本的计算在不同步骤处有点不同。当从cu级别处的候选集中选择候选时,匹配成本可以是双边匹配或模板匹配的绝对和差(absolutesumdifference,sad)。在确定起始mv之后,子cu级别搜索处的双边匹配的匹配成本c如下计算:这里,w是加权因子。在一些实施例中,w可以被经验主义地设置为4。mv和mvs分别指示当前mv和起始mv。sad仍可以用作子cu级别搜索处的模板匹配的匹配成本。在fruc模式中,仅通过使用亮度样点来推导mv。推导的运动将用于mc帧间预测的亮度和色度两者。在决定mv之后,对于亮度使用8抽头插值滤波器并且对于色度使用4抽头插值滤波器来执行最终mc。mv细化是基于模式的mv搜索,具有双边匹配成本或模板匹配成本的准则。在jem中,对于cu级别处和子cu级别处的mv细化,分别支持两种搜索模式—无限制中心偏置菱形搜索(unrestrictedcenter-biaseddiamondsearch,ucbds)和自适应交叉搜索。对于cu和子cu级别mv细化两者,以四分之一亮度样点mv精度直接搜索mv,并且接着是八分之一亮度样点mv细化。将用于cu和子cu步骤的mv细化的搜索范围设置为等于8亮度样点。在双边匹配merge模式中,应用双向预测,因为cu的运动信息是基于两个不同的参考图片中沿当前cu的运动轨迹的两个块之间的最接近匹配推导的。在模板匹配merge模式中,编码器可以从来自列表0的单向预测、来自列表1的单向预测、或双向预测当中为cu选择。选择可以如下基于模板匹配成本:如果costbi<=factor*min(cost0,cost1)则使用双向预测;否则,如果cost0<=cost1则使用来自列表0的单向预测;否则,使用来自列表1的单向预测;这里,cost0是列表0模板匹配的sad,cost1是列表1模板匹配的sad,并且costbi是双向预测模板匹配的sad。例如,当factor的值等于1.25时,这意味着选择过程偏向于双向预测。帧间预测方向选择可以应用于cu级别模板匹配过程。2.8双向光流(bio)的示例双向光流(bio)方法是在用于双向预测的块方式运动补偿的顶部执行的样点方式的运动细化。在一些实施例中,样点级别运动细化不使用信令。假定i(k)是来自块运动补偿之后的参考k(k=0,1)的亮度值,并且和分别表示i(k)梯度的水平分量和垂直分量。假设光流是有效的,则运动矢量场(vx,vy)由以下等式给出:将此光流等式与每个样点运动轨迹的埃尔米特插值相结合,得到唯一的三阶多项式,该三阶多项式最后匹配函数值i(k)和其导数和该三阶多项式在t=0处的值是bio预测:图23示出了双向光流(bio)方法中的光流轨迹的示例。这里,τ0和τ1表示到参考帧的距离。基于ref0和ref1的poc计算距离τ0和τ1:τ0=poc(当前)-poc(ref0),τ1=poc(ref1)-poc(当前)。如果两个预测都来自相同的时域方向(两者都来自过去或都来自未来),则sign是不同的(例如,τ0·τ1<0)。在这种情况下,如果预测不是来自相同的时刻(例如,τ0≠τ1),则应用bio。两个参考区域都具有非零运动(例如,mvx0,mvy0,mvx1,mvy1≠0)并且块运动矢量与时域距离成比例(例如,mvx0/mvx1=mvy0/mvy1=-τ0/τ1)。通过最小化点a和b中的值之间的差δ来确定运动矢量场(vx,vy)。图9示出了运动轨迹和参考帧平面的交叉的示例。模型仅使用δ的局部泰勒展开的第一线性项:上述等式中的所有值都取决于表示为(i′,j′)的样点位置。假设运动在局部周围区域是一致的,可以在以当前预测点(i,j)为中心的(2m+1)×(2m+1)的方形窗口ω内部最小化δ,其中m等于2:对于该优化问题,jem使用简化的方法,首先在垂直方向上进行最小化,然后在水平方向上进行最小化。结果如下所示:其中,为了避免除以零或非常小的值,可以在等式(28)和等式(29)中引入正则化参数r和m,其中r=500·4d-8等式(31)m=700·4d-8等式(32)这里d是视频样点的比特深度。为了使bio的存储访问与常规双向预测运动补偿保持相同,针对当前块内部的位置计算所有预测和梯度值i(k)、图24a示出了块2400的外部的访问位置的示例。如图24a所示,在等式(30)中,以在预测块的边界上的当前预测点为中心的(2m+1)×(2m+1)方形窗口ω需要访问块的外部的位置。在jem中,将块的外部的i(k)、的值设置为等于块内部最近的可用值。例如,这可以实施为填充区域2401,如图24b所示。利用bio,可以针对每个样点细化运动场。为了降低计算复杂度,在jem中使用基于块的bio设计。可以基于4×4块计算运动细化。在基于块的bio中,可以聚合4×4块中的所有样点的等式(30)中的sn的值,然后将sn的聚合值用于推导4×4块的bio运动矢量偏移。更具体地,以下公式可以用于基于块的bio推导:这里,bk表示属于预测块的第k个4×4块的样点集。将等式(28)和等式(29)中的sn替换为((sn,bk)>>4),以推导相关联的运动矢量偏移。在一些场景中,由于噪音或不规则运动,bio的mv群(mvregiment)可能不可靠。因此,在bio中,mv群的幅度被限幅到阈值。阈值是基于当前图片的参考图片是否都来自一个方向而确定的。例如,如果当前图片的所有参考图片都来自一个方向,则将阈值的值设置为12×214-d;否则,将其设置为12×213-d。可以利用使用与hevc运动补偿过程(例如,2d可分离有限脉冲响应(finiteimpulseresponse,fir))一致的操作的运动补偿插值来同时计算bio的梯度。在一些实施例中,该2d可分离fir的输入是与运动补偿过程和根据块运动矢量的分数部分的分数位置(fracx,fracy)相同的参考帧样点。对于水平梯度首先使用与具有去缩放偏移d-8的分数位置fracy相对应的biofilters垂直插值信号。然后在水平方向上应用梯度滤波器biofilterg,该biofilterg与具有去缩放偏移18-d的分数位置fracx相对应。对于垂直梯度使用与具有去缩放偏移d-8的分数位置fracy相对应的biofilterg垂直应用梯度滤波器。然后在水平方向上使用biofilters执行信号位移,该biofilters与具有去缩放偏移18-d的分数位置fracx相对应。为了保持合理的复杂度,用于梯度计算的插值滤波器biofilterg和用于信号位移的插值滤波器biofilterf的长度可以更短(例如,6抽头)。表1示出了可以用于bio中块运动矢量的不同分数位置的梯度计算的示例滤波器。表2示出了可以用于bio中预测信号生成的示例插值滤波器。表1:用于bio中的梯度计算的示例性滤波器分数像素位置梯度的插值滤波器(biofilterg)0{8,-39,-3,46,-17,5}1/16{8,-32,-13,50,-18,5}1/8{7,-27,-20,54,-19,5}3/16{6,-21,-29,57,-18,5}1/4{4,-17,-36,60,-15,4}5/16{3,-9,-44,61,-15,4}3/8{1,-4,-48,61,-13,3}7/16{0,1,-54,60,-9,2}1/2{-1,4,-57,57,-4,1}表2:用于bio中的预测信号生成的示例性插值滤波器分数像素位置预测信号的插值滤波器(biofilters)0{0,0,64,0,0,0}1/16{1,-3,64,4,-2,0}1/8{1,-6,62,9,-3,1}3/16{2,-8,60,14,-5,1}1/4{2,-9,57,19,-7,2}5/16{3,-10,53,24,-8,2}3/8{3,-11,50,29,-9,2}7/16{3,-11,44,35,-10,3}1/2{3,-10,35,44,-11,3}在jem中,当两个预测来自不同的参考图片时,bio可以应用于所有双向预测块。当针对cu启用了局部光照补偿(lic)时,可以禁用bio。在一些实施例中,obmc在常规mc过程之后应用于块。为了降低计算复杂性,在obmc过程期间可以不应用bio。这意味着bio在使用其自身的mv时才应用于块的mc过程,并且当在obmc过程期间使用相邻块的mv时不应用于mc过程。2.9解码器侧运动矢量细化(dmvr)的示例在双向预测操作中,对于一个块区域的预测,将分别使用列表0的运动矢量(mv)和列表1的mv形成的两个预测块进行组合以形成单个预测信号。在解码器侧运动矢量细化(decoder-sidemotionvectorrefinement,dmvr)方法中,通过双边模板匹配过程进一步细化双向预测的两个运动矢量。双边模板匹配应用在解码器中,以在双边模板和参考图片中的重构样点之间执行基于失真的搜索,以便获得细化的mv而无需发送附加运动信息。在dmvr中,双边模板被生成为两个预测块的加权组合(即,平均),该两个预测块分别来自列表0的初始mv0和列表1的mv1,如图25所示。模板匹配操作包括计算生成的模板与参考图片中的(在初始预测块周围的)样点区域之间的成本计量(costmeasure)。对于两个参考图片中的每一个,将产生最小模板成本的mv考虑为该列表的更新mv以替换原始mv。在jem中,针对每个列表搜索九个mv候选。该九个mv候选包括原始mv和8个与原始mv在水平或垂直方向上或两个方向上具有一个亮度样点偏移的环绕的mv。最后,将两个新的mv,即如图25中所示的mv0'和mv1',用于生成最终的双向预测结果。将绝对差之和(sad)用作成本计量。将dmvr应用于双向预测的merge模式,其中一个mv来自过去的参考图片,另一mv来自未来的参考图片,而无需发送附加语法元素。在jem中,当针对cu启用lic、仿射运动、fruc或子cumerge候选时,不应用dmvr。3.现有实施方式的缺点在如atmvp、stmvp和仿射模式的基于子块的编码工具中,更小的子块通常带来更高的编码增益,尽管是以更高的存储带宽为代价的。另一方面,如果直接使用更大的子块以减小存储带宽,则可能导致不小的编码性能损失。在仿射模式的一些实施方式中,为每个4×4块推导运动矢量,并且还以4×4块级别执行运动补偿,与4×8、8×4或8×8块相比,这可能会增加存储带宽。在现有实施方式中,针对最坏情况的带宽减小,提出了对仿射模式的限制。为了确保仿射块的最坏情况的带宽不比4×8或8×4块差,仿射控制点之间的运动矢量差用来决定仿射块的子块尺寸是4×4还是8×8。通过限制仿射控制点之间的运动矢量差(也称为控制点差)来控制仿射模式的存储带宽减小。通常,如果控制点差满足如(34)中的以下限制,则仿射运动使用4×4子块(即4×4仿射模式)。否则,它使用8×8子块(8×8仿射模式)。6-参数模型和4-参数模型的限制如下。6-参数仿射模型的限制:在上述等式中,左侧表示子仿射块的跨度(span)级别的缩小,(7/2)因子指示3.5像素偏移,并且norm(.)函数是运动矢量差基于(w×h)的归一化。在一些实施例中,norm(.)被定义为:4-参数仿射模型的限制:在4-参数仿射模型中,(v2x-v0x)和(v2y-v0y)被设置如下:在这种情况下,(v2x-v0x)和(v2y-v0y)的norm为:通过将(36)应用于(34),建立了4-参数仿射模型的限制。在另一现有实施方式中,块内的每个8×8块被视为基本单元。约束8×8块内部的所有四个4×4子块的mv,使得四个4×4子块mv的整数部分之间的最大差不超过1个像素。使得带宽为(8+7+1)*(8+7+1)/(8*8)=4样点/像素。两种实施方式都能够将最坏情况的带宽减小到小于4×8或8×4,但是会导致不小的编码性能损失。4.仿射帧间模式的示例性实施例在一些实施例中,可以通过分析仿射模型的参考图片中的涉及区域来解决仿射模式中的存储带宽问题。如图26所示,cu的四个角的参考像素定义了可以覆盖cu的所有参考像素的最小矩形区域。假设cu及其矩形参考区域的尺寸分别为w×h和m×n,如果(m+7)*(n+7)/(w*h),例如,平均存储带宽,小于给定值,则可以加载图26中示出的外部矩形2603中一次插值参考区域所需的像素,但是可以用不同的mv插值cu的不同子块。在仿射模式中,实际上为包括角点像素(cornerpixel)的子块推导了角点像素的运动矢量,详细描述如下。对于如等式(38)中所示的6-参数模型,通过用(sw/2,sh/2)、(w–sw/2,sh/2)、(sw/2,h–sh/2)、(w–sw/2,h–sh/2)替换(x,y)到公式(38)中来推导四个角点像素的运动矢量,其中w×h和sw×sh分别是cu尺寸和子块尺寸。等式(39)至(42)中示出了四个角点像素的运动矢量,并且0、1、2和3分别是指左上角、右上角、左下角和右下角。利用运动矢量,参考像素(相对于当前cu的左上角)的位置可以计算如下:表3中列出了四个角点像素中的任何两个参考像素之间的水平和垂直距离。从中可以看出,p0和p1之间的水平/垂直距离与p2和p3之间的水平/垂直距离相同,并且p0和p2之间的水平/垂直距离与p1和p3之间的水平/垂直距离相同。以hormax和vermax表示最大水平和垂直距离,则矩形参考区域为hormax*vermax。对于任何给定的仿射模型参数,都可以计算出cu的矩形参考区域,并且确定所需的存储带宽。表3:不同参考像素之间的示例性距离水平距离垂直距离(p0,p1)|a*(w-sw)+w-1||e*(w-sw)|(p0,p2)|b*(h-sh)||d*(h-sh)+h-1|(p0,p3)|a*(w-sw)+b*(h-sh)+w-1||e*(w-sw)+d*(h-sh)+h-1|(p1,p2)|a*(w-sw)-b*(h-sh)+w-1||-e*(w-sw)+d*(h-sh)+h-1|(p1,p3)|b*(h-sh)||d*(h-sh)+h-1|(p2,p3)|a*(w-sw)+w-1||e*(w-sw)|类似地,对于等式(47)中的4-参数仿射模型,用-b和a代替等式(39)至(46)和表3中的e和f。5.用于子块编码工具中的存储带宽减小的示例方法本公开技术的实施例克服了现有实施方式的缺点,从而为视频编码提供了更高的编码效率。在针对各种实施方式描述的以下示例中阐明了基于所公开的技术的子块编码工具中的存储带宽减小可以增强现有和未来视频编码标准。下面提供的所公开技术的示例解释了一般概念,并且不意味着被解释为限制性的。在示例中,除非明确地相反指示,否则可以组合这些示例中描述的各种特征。尽管在编码单元(cu)的上下文中描述了示例,但是它们也可以应用于块、预测单元(pdu)等。此外,对于预测方向0和1,分别将cu的参考矩形区域的尺寸表示为m0×n0和m1×n1,并且将cu的尺寸表示为w×h。示例1.提出在atmvp/stmvp中使用的子块尺寸可以取决于cu(或当前块)的运动信息(如预测方向、运动矢量、参考图片等)。(a)在一个示例中,具有更小尺寸的子块可以用于单向预测,并且具有更大尺寸的子块可以用于双向预测。例如,如果当前cu是单向预测的,则使用4×4、4×8或8×4子块。可替代地,如果当前cu是双向预测的,则使用8×8子块。(b)在一个示例中,如果当前cu是单向预测的,则当cu高度大于cu宽度时使用m×n子块,以及在其他情况下使用n×m子块。n大于或等于m,诸如m=4且n=8。(i)可替代地,如果当前cu是单向预测的,则当cu高度大于cu宽度时使用m×n子块,以及在其他情况下使用n×m子块。m大于或等于n,诸如m=8且n=4。(c)在一个示例中,如果w<=n且h<=m,例如,n=m=8,则针对尺寸为w×h的cu禁用atmvp/stmvp。(i)可替代地,如果w<=n或h<=m,例如,n=m=8,则针对尺寸为w×h的cu禁用atmvp/stmvp。(ii)可替代地,如果w>=n且h>=m,例如,n=m=64,则针对尺寸为w×h的cu禁用atmvp/stmvp。(iii)可替代地,如果w>=n或h>=m,例如n=m=64,则针对尺寸为w×h的cu禁用atmvp/stmvp。(d)在一个示例中,不同子块的mv被约束在一个或多个所选择的mv周围的给定范围内。(i)在一个示例中,所选择的mv是中心子块的mv。(ii)在一个示例中,所选择的mv是左上角子块的mv。示例2.提出仿射模式中使用的子块尺寸可以取决于仿射模式参数、预测方向、参考图片和cu的形状。(a)在一个示例中,cu的参考矩形区域的每个维度的填充像素的数量是flen1和flen2。对于双向预测的cu,如果(m0+flen1)*(n0+flen2)+(m1+flen1)*(n1+flen2)小于或等于th1*w*h,则使用子块sw1×sh1;否则,使用子块sw2×sh2。(i)在一些实施例中,对于单向预测的cu,如果(m0+flen1)*(n0+flen2)小于或等于th2*w*h,则使用子块sw1×sh1;否则,使用子块sw2×sh2。(ii)在一些实施例中,对于双向预测的cu,如果(m0+flen1)*(n0+flen2)大于th3*w*h,或者如果(m1+flen1)*(n1+flen2)大于th3*w*h,则使用子块sw2×sh2;否则,使用子块sw1×sh1。(iii)在一些实施例中,对于双向预测的cu,可以将不同的子块尺寸用于不同的预测方向。如果(m0+flen1)*(n0+flen2)大于th4*w*h,则对于预测方向0,使用子块sw2×sh2,否则使用子块sw1×sh1。如果(m1+flen1)*(n1+flen2)大于th4*w*h,则对于预测方向1,使用子块sw2×sh2,否则使用子块sw1×sh1。(iv)在一个示例中,子块的尺寸可以取决于当前块的位置。例如,当当前块在或不在编码树单元(codingtreeunit,ctu)边界处时,子块的尺寸可以不同。(v)在一个示例中,sw1和sh1等于4,并且sw2和sh2等于8。可替代地,sw1×sh1等于4×8或8×4。可替代地,sw1和sh1可以取决于cu的形状。例如,对于宽度大于或等于高度的cu,将sw1×sh1设置为等于8×4,以及对于其他cu,将sw1×sh1设置为等于4×8。(vi)可以将flen1和flen2设置为等于插值滤波器的长度,或可替代地,可以将其设置为等于插值滤波器的长度加上/减去n,例如,n等于1。可替代地,如果水平mv分量具有整数mv精度,则将flen1设置为零,以及如果垂直mv分量具有整数mv精度,则将flen2设置为零。(vii)th1、th2和th3为正浮点数。(1)在一个示例中,将th2设置为等于10.3125(165/16),并且将th1、th3和th4设置为等于5.15625(165/32)。(2)在一个示例中,将th2设置为等于7.03125(225/32),并且将th1,th3和th4设置为等于3.515625(225/64)。(b)在一个示例中,始终使用子块sw1×sh1,但是,可以约束每个子块的mv。如图27所示,首先将cu划分为sw2×sh2(大于sw1×sh1)子块,然后使用中心位置来推导sw2×sh2子块的运动矢量(表示为mvc),最终推导sw2×sh2块内的每个sw1×sh1子块的mv,并且将mv限制在mvc周围的给定范围内。对于双向预测的cu,在每个预测方向上执行这样的处理。(i)在一个示例中,sw1×sh1等于4×4,并且sw2×sh2等于8×8。左上角、右上角、左下角和右下角4×4子块的运动矢量分别被表示为mv0、mv1、mv2、mv3。对于每个预测方向x(x=0或1),将abs(mvilx[0]-mvclx[0])限制为小于rhori,并且将abs(mvilx[1]-mvclx[1])限制为小于rveri,其中rhori和rveri是正浮点数,并且对于不同的i(i=0、1、2或3),它们可以不同,并且mvilx[0]和mvilx[1]分别是mvilx的水平和垂直分量。(ii)在一个示例中,sw1×sh1等于4×4,并且sw2×sh2等于4×8。顶部和底部4×4子块的运动矢量分别被表示为mv0和mv1。对于每个预测方向x(x=0或1),将abs(mvilx[0]-mvclx[0])限制为小于rhori,并且将abs(mvilx[1]-mvclx[1])限制为小于rveri,其中rhori和rveri是正浮点数,并且对于不同的i(i=0或1),它们可以不同,并且mvilx[0]和mvilx[1]分别是mvilx的水平和垂直分量。(iii)在一个示例中,sw1×sh1等于4×4,并且sw2×sh2等于8×4。左侧和右侧4×4子块的运动矢量分别被表示为mv0和mv1。对于每个预测方向x(x=0或1),将abs(mvilx[0]-mvclx[0])限制为小于rhori,并且将abs(mvilx[1]-mvclx[1])限制为小于rveri,其中rhori和rveri是正浮点数,并且对于不同的i(i=0或1),它们可以不同,并且mvilx[0]和mvilx[1]分别是mvilx的水平和垂直分量。(iv)在一个示例中,mvc被设置为等于sw1×sh1子块中的一个的mv,例如,mvc被设置为等于左上角sw1×sh1子块的mv。(v)rhori和rveri可以取决于cu的预测方向和sw2×sh2的尺寸,例如,对于单向预测的cu,它们可以更大,以及对于双向预测的cu,它们可以更小;并且对于更大的sw2×sh2,它们可以更大,反之亦然。(vi)在一个示例中,当sw2×sh2等于8×8/8×4/4×8并且sw1×sh1等于4×4时,rhori和rveri都被设置为等于1/2像素。(vii)在一个示例中,当sw2×sh2等于8×8/8×4/4×8并且sw1×sh1等于4×4时,rhori和rveri都被设置为等于1/4像素。(viii)在一个示例中,当sw2×sh2等于8×8/8×4/4×8并且sw1×sh1等于4×4时,rhori被设置为等于1/2像素并且rveri被设置为等于1像素。(ix)在一个示例中,当sw2×sh2等于8×8/8×4/4×8并且sw1×sh1等于4×4时,rhori被设置为等于1/2像素并且rveri被设置为等于1/4像素。示例3.当cu尺寸大于wmax×hmax时,可以将其划分为几个更小的区域,并且基于示例2中描述的技术来处理每个区域。(a)在一个示例中,当cu尺寸为128×128时,其被划分为4个64×64区域。(b)在一个示例中,当cu尺寸为128×64或64×128时,其被划分为2个64×64区域。示例4.是否在子块编码的cu上应用或如何在子块编码的cu上应用存储带宽减小可以取决于cu的尺寸。(a)在一个示例中,如果cu尺寸大于w×h,则不执行存储带宽减小方法。(b)在一个示例中,如果cu尺寸小于w×h,则不执行存储带宽减小方法。上面描述的示例可以并入下面描述的例如方法2800的方法的上下文中,该方法可以在视频解码器或视频编码器处实施。图28示出了用于视频编码的示例性方法的流程图。方法2800包括,在步骤2810处,对于当前块的比特流表示,基于与当前块相关联的运动信息来选择子块尺寸。在一些实施例中,并且在示例1的上下文中,选择子块尺寸包括:如果执行转换包括单向预测,则选择第一尺寸;以及如果执行转换包括双向预测,则选择第二尺寸,并且其中第一尺寸小于第二尺寸。在一个示例中,当前块的高度大于当前块的宽度,并且子块尺寸为4×8。在另一示例中,当前块的宽度大于当前块的高度,并且子块尺寸为8×4。在一些实施例中,其中子块尺寸为m×n,其中当前块的尺寸为w×h,并且其中执行转换不包括可选时域运动矢量预测(atmvp)和空时运动矢量预测(stmvp)。在一个示例中,w≤n且h≤m,并且n=m=8。在另一示例中,w≤n或h≤m,并且n=m=8。在又一示例中,w≥n且h≥m,并且n=m=64。在又一示例中,w≥n或h≥m,并且n=m=64。在一些实施例中,选择子块尺寸进一步基于当前块的一个或多个维度,并且运动信息包括预测方向、运动矢量或参考图片中的至少一个。在其他实施例中,执行转换基于当前块的中心子块的运动矢量。在又一些其他实施例中,执行转换基于当前块的左上角子块的运动矢量。方法2800包括,在步骤2820处,基于子块尺寸来执行比特流表示和当前块之间的转换。在一些实施例中,该转换从比特流表示生成当前块(例如,可以在视频解码器中实施)。在其他实施例中,该转换从当前块生成比特流表示(例如,可以在视频编码器中实施)。在一些实施例中,并且在示例2的上下文中,执行转换基于仿射模式,并且其中选择子块尺寸进一步基于一个或多个仿射模型参数。在一些实施例中,并且在示例2的上下文中,执行转换基于仿射模式,其中当前块的尺寸为w×h,其中对于第一预测方向,当前块的参考矩形区域的尺寸为m0×n0,其中对于第二预测方向,参考矩形区域的尺寸为m1×n1,并且其中参考矩形区域的每个维度的填充像素的数量分别为flen1和flen2。在一种场景中,执行转换包括双向预测,其中选择子块尺寸包括:如果(m0+flen1)×(n0+flen2)+(m1+flen1)×(n1+flen2)小于或等于th1×w×h,则选择第一尺寸;否则选择第二尺寸,并且其中th1为正分数。例如,th1为165/32或225/64。在另一种场景中,执行转换包括单向预测,其中选择子块尺寸包括:如果(m0+flen1)×(n0+flen2)小于或等于th2×w×h,则选择第一尺寸;否则选择第二尺寸,并且其中th2为正分数。例如,th2为165/16或225/32。在又一种场景中,执行转换包括双向预测,其中选择子块尺寸包括:如果(m0+flen1)×(n0+flen2)或(m1+flen1)×(n1+flen2)大于th3×w×h,则选择第一尺寸;否则选择第二尺寸,并且其中th3为正分数。例如,th3为165/32或225/64。在又一种场景中,执行转换包括双向预测,并且不同的子块尺寸用于不同的预测方向。例如,选择子块尺寸包括:如果(m0+flen1)×(n0+flen2)小于或等于th4×w×h,则对于第一预测方向,选择第一尺寸;否则选择第二尺寸,并且其中th4为正分数。此外,选择子块尺寸进一步包括:如果(m1+flen1)×(n1+flen2)小于或等于th4×w×h,则对于第二预测方向,选择第一尺寸;否则选择第二尺寸。在示例中,th4为165/32或225/64。在上述示例性场景中,第一尺寸可以是4×4或4×8或8×4,并且第二尺寸可以是8×8。在一些实施例中,执行转换基于尺寸为sw2×sh2的子块的中心位置并且包括双向预测,并且其中尺寸为sw2×sh2的子块包括尺寸为sw1×sh1的多个子块。在一些实施例中,尺寸为sw2×sh2的子块的第一运动矢量和尺寸为sw1×sh1的多个子块中的一个的第二运动矢量之间的绝对差小于预定阈值。在一个示例中,sw2×sh2是8×8或8×4或4×8,sw1×sh1是4×4,并且预定阈值是1/2像素。在另一示例中,sw2×sh2是8×8或8×4或4×8,sw1×sh1是4×4,并且预定阈值是1/4像素。在一些实施例中,并且在示例3的上下文中,当前块的尺寸为128×128,并且执行转换包括将当前块划分为四个64×64块并针对四个64×64块中的每一个执行转换。在一些实施例中,当前块的尺寸为128×64或64×128,并且执行转换包括将当前块划分为两个64×64块并针对两个64×64块中的每一个执行转换。在一些实施例中,并且对于上述实施例,当前块可以是编码单元或预测单元。6.所公开的技术的示例实施方式图29是视频处理装置2900的框图。装置2900可以用来实施本文描述的方法中的一种或多种。装置2900可以体现在智能电话、平板电脑、计算机、物联网(internetofthings,iot)接收器等中。装置2900可以包括一个或多个处理器2902、一个或多个存储器2904、以及视频处理硬件2906。(多个)处理器2902可以被配置为实施本文档中描述的一种或多种方法(包括但不限于方法2800)。存储器(多个存储器)2904可以用于存储用于实施本文描述的方法和技术的数据和代码。视频处理硬件2906可以用来在硬件电路中实施本文档中描述的一些技术。在一些实施例中,视频编码方法可以使用在如关于图29描述的硬件平台上实施的装置而实施。图30是示出可以在其中实施本文公开的各种技术的示例视频处理系统3000的框图。各种实施方式可以包括系统3000的一些或所有组件。系统3000可以包括用于接收视频内容的输入3002。视频内容可以以例如8或10比特多分量像素值的原始或未压缩格式而接收,或者可以是压缩或编码格式。输入3002可以表示网络接口、外围总线接口或存储接口。网络接口的示例包括诸如以太网、无源光网络(passiveopticalnetwork,pon)等的有线接口和诸如wi-fi或蜂窝接口的无线接口。系统3000可以包括可以实施本文档中描述的各种编码方法的编码组件3004。编码组件3004可以将来自输入3002的视频的平均比特率减小到编码组件3004的输出,以产生视频的编码表示。编码技术因此有时被称为视频压缩或视频转码技术。编码组件3004的输出可以被存储,或者经由如由组件3006表示的通信连接而发送。在输入3002处接收的视频的存储或通信传送的比特流(或编码)表示可以由组件3008用于生成像素值或传送到显示接口3010的可显示视频。从比特流表示生成用户可视视频的过程有时被称为视频解压缩。此外,虽然某些视频处理操作被称为“编码”操作或工具,但是将理解,编码工具或操作在编码器处被使用,并且反转编码结果的对应的解码工具或操作将由解码器执行。外围总线接口或显示接口的示例可以包括通用串行总线(universalserialbus,usb)、或高清晰度多媒体接口(highdefinitionmultimediainterface,hdmi)、或显示端口(displayport)等。存储接口的示例包括sata(serialadvancedtechnologyattachment,串行高级技术附件)、pci、ide接口等。本文档中描述的技术可以体现在各种电子设备中,诸如移动电话、膝上型电脑、智能电话、或能够执行数字数据处理和/或视频显示的其他设备。图31是根据本技术的用于视频处理的方法3100的流程图表示。方法3100包括,在操作3110处,对于视频的编码单元和视频的比特流表示之间的转换,基于与编码单元相关联的运动信息来确定编码单元的子块的子块尺寸。方法3100包括,在操作3120处,基于确定的子块尺寸来执行该转换。在一些实施例中,该转换从比特流表示生成编码单元。在一些实施例中,该转换从编码单元生成比特流表示。在一些实施例中,选择子块尺寸包括在转换包括单向预测的编码单元的情况下选择第一尺寸作为子块尺寸,以及在转换包括双向预测的编码单元的情况下选择第二尺寸。第一尺寸可以小于第二尺寸。在一些实施例中,在转换包括单向预测的编码单元的情况下,第一尺寸包括4×4、4×8或8×4作为子块尺寸。在一些实施例中,在转换包括双向预测的编码单元的情况下,第二尺寸包括8×8作为子块尺寸。在一些实施例中,在转换包括单向预测的编码单元的情况下,在确定编码单元的高度大于编码单元的宽度时,编码单元包括m×n子块。在一些实施例中,在转换包括单向预测的编码单元的情况下,在确定编码单元的高度小于或等于编码单元的宽度时,编码单元包括n×m子块。在一些实施例中,n大于或等于m。例如,m=4且n=8。在一些实施例中,m大于或等于n。例如,m=8且n=4。在一些实施例中,当前块的维度为w×h,w和h为正整数。转换不包括对编码单元执行可选时域运动矢量预测(atmvp)或空时运动矢量预测(stmvp)。在一些实施例中,在w≤n且h≤m的情况下,转换不包括对编码单元执行atmvp或stmvp,n和m为正整数。例如,n=m=8。在一些实施例中,在w≤n或h≤m的情况下,转换不包括对编码单元执行atmvp或stmvp。例如,n=m=8。在一些实施例中,在w≥n且h≥m的情况下,转换不包括对编码单元执行atmvp或stmvp。例如,n=m=64。在一些实施例中,在w≥n或h≥m的情况下,转换不包括对编码单元执行atmvp或stmvp。例如,n=m=64。在一些实施例中,运动信息包括编码单元的预测方向、运动矢量或参考图片中的至少一个。在一些实施例中,编码单元的子块的运动矢量被约束在所选择的运动矢量周围的范围内。在一些实施例中,所选择的运动矢量是编码单元的中心子块的运动矢量。在一些实施例中,所选择的运动矢量是编码单元的左上角子块的运动矢量。在一些实施例中,子块尺寸基于编码单元的尺寸而选择性地调整。在一些实施例中,在编码单元大于wmax×hmax的情况下,不调整子块尺寸,wmax和hmax为正整数。在一些实施例中,在编码单元小于wmin×hmin的情况下,不调整子块尺寸,wmin和hmin为正整数。图32是根据本技术的用于视频处理的方法3200的流程图表示。方法3200包括,在操作3210处,对于包括子块的视频的编码单元和视频的比特流表示之间的转换,基于编码单元的尺寸来确定是否针对该转换使用存储带宽减小工具。方法3200包括,在操作3220处,基于该确定来执行该转换。在一些实施例中,在编码单元大于wmax×hmax的情况下,不使用存储带宽减小工具,wmax和hmax为正整数。在一些实施例中,在编码单元小于wmin×hmin的情况下,不使用存储带宽减小工具,wmin和hmin为正整数。在一些实施例中,该转换从比特流表示生成编码单元。在一些实施例中,该转换从编码单元生成比特流表示。图33是根据本技术的用于视频处理的方法3300的流程图表示。方法3300包括,在操作3310处,对于仿射模式中视频的编码单元和视频的比特流表示之间的转换,基于与编码单元相关联的信息来确定子块尺寸。方法3300包括,在操作3320处,基于子块尺寸来执行仿射模式中的转换。该转换可以从比特流表示生成编码单元。该转换可以从编码单元生成比特流表示。在一些实施例中,该信息包括仿射模式的一个或多个参数、编码单元的预测方向、编码单元的一个或多个参考图片或编码单元的形状。在一些实施例中,编码单元的尺寸为w×h,其中对于第一预测方向,当前块的第一参考矩形区域的尺寸为m0×n0,其中对于第二预测方向,第二参考矩形区域的尺寸为m1×n1,并且其中第一参考矩形区域和第二参考矩形区域的每个维度分别包括用于运动补偿的flen1个和flen2个附加像素。在一些实施例中,转换包括双向预测,并且其中在(m0+flen1)×(n0+flen2)+(m1+flen1)×(n1+flen2)小于或等于th1×w×h的情况下,子块尺寸为第一尺寸,否则子块尺寸为第二尺寸,th1为正分数。th1可以是165/32或225/64。在一些实施例中,转换包括单向预测,并且其中在(m0+flen1)×(n0+flen2)小于或等于th2×w×h的情况下,子块尺寸为第一尺寸,否则子块尺寸为第二尺寸,th2为正分数。th2可以是165/16或225/32。在一些实施例中,转换包括双向预测,并且其中在(m0+flen1)×(n0+flen2)或(m1+flen1)×(n1+flen2)大于th3×w×h的情况下,子块尺寸为第一尺寸,否则子块尺寸为第二尺寸,th3为正分数。th3可以是165/32或225/64。在一些实施例中,转换包括双向预测,并且其中不同的子块尺寸用于不同的预测方向。在一些实施例中,在(m0+flen1)×(n0+flen2)小于或等于th4×w×h的情况下,对于第一预测方向,子块尺寸为第一尺寸,否则子块尺寸为第二尺寸,th4为正分数。在一些实施例中,在(m1+flen1)×(n1+flen2)小于或等于th4×w×h的情况下,对于第二预测方向,子块尺寸为第一尺寸,否则子块尺寸为第二尺寸。th可以是165/32或225/64。在一些实施例中,第一尺寸是4×4、4×8或8×4,并且其中第二尺寸是8×8。在一些实施例中,第一尺寸基于编码单元的形状而确定。在一些实施例中,flen1和flen2基于插值滤波器的长度而确定。在一些实施例中,插值滤波器的长度是l,并且其中flen1=l±n并且flen2=l±n,n为正整数。例如,n=1。在一些实施例中,flen1和flen2根据编码单元的运动矢量的精度而确定。在一些实施例中,在运动矢量的水平分量具有整数精度的情况下,flen1=0。在一些实施例中,在运动矢量的垂直分量具有整数精度的情况下,flen2=0。在一些实施例中,子块尺寸进一步基于编码单元的位置而确定。在一些实施例中,子块尺寸基于编码单元是否位于编码树单元的边界处而确定。在一些实施例中,转换包括双向预测,并且子块尺寸被固定为sw1×sh1。编码单元被分割为尺寸为sw2×sh2的至少一个区域,该至少一个区域包括每个的子块尺寸为sw1×sh1的多个子块,区域的运动矢量mvc根据区域的中心位置而推导,并且多个子块中的每一个的运动矢量被局限在区域的运动矢量mvc周围的范围内。在一些实施例中,对于多个子块中的每一个的一个或多个预测方向,多个子块中的每一个的运动矢量和区域的运动矢量mvc之间的绝对差小于与运动矢量的预测方向相关联的一个或多个阈值。在一些实施例中,对于多个子块中的每一个的不同预测方向,一个或多个阈值不同。在一些实施例中,一个或多个阈值基于编码单元的预测方向或区域的尺寸而确定。在一些实施例中,区域的运动矢量mvc与多个子块中的一个的第一运动矢量相同。在一些实施例中,第一运动矢量对应于多个子块中的左上角子块。在一些实施例中,sw2×sh2是8×8、8×4或4×8,sw1×sh1是4×4,并且一个或多个预定阈值都等于1/2像素。在一些实施例中,sw2×sh2是8×8、8×4或4×8,sw1×sh1是4×4,并且一个或多个预定阈值都等于1/4像素。在一些实施例中,sw2×sh2是8×8、8×4或4×8,sw1×sh1是4×4,一个或多个预定阈值的第一阈值等于1/2像素,并且一个或多个预定阈值中的第二阈值等于1像素。在一些实施例中,sw2×sh2是8×8、8×4或4×8,sw1×sh1是4×4,一个或多个预定阈值的第一阈值等于1/2像素,并且一个或多个预定阈值中的第二阈值等于1/4像素。在一些实施例中,在编码单元的尺寸大于wmax×hmax的情况下,编码单元被分割为至少一个区域。在一些实施例中,编码单元的尺寸为128×128,并且编码单元被分割为四个区域,每个区域的尺寸为sw2×sh2=64×64。在一些实施例中,编码单元的尺寸为128×64或64×128,并且编码单元被分割为两个区域,每个区域的尺寸为sw2×sh2=64×64。在一些实施例中,在编码单元大于wmax×hmax或小于wmin×hmin的情况下,子块尺寸是固定的,wmax、hmax、wmin和hmin为正整数。在一些实施例中,在编码单元大于wmax×hmax或小于wmin×hmin的情况下,多个子块中的每一个的运动矢量不被局限在区域的运动矢量mvc周围的范围内,wmax、hmax、wmin和hmin为正整数。根据前述内容,将理解,本文已经出于说明的目的描述了本公开技术的特定实施例,但是在不脱离本发明的范围的情况下可以进行各种修改。因此,本公开技术不受除了所附权利要求之外的限制。本专利文档中描述的主题和功能操作的实施方式可以在各种系统、数字电子电路中、或者在计算机软件、固件或硬件(包括本说明书中公开的结构及其结构等同物)中、或者在它们中的一个或多个的组合中实施。本说明书中描述的主题的实施方式可以实施为一个或多个计算机程序产品,即在有形且非暂时性计算机可读介质上编码的计算机程序指令的一个或多个模块,该计算机程序指令用于由数据处理装置运行或控制数据处理装置的操作。计算机可读介质可以是机器可读存储设备、机器可读存储基板、存储器设备、影响机器可读传播信号的物质的组合、或它们中的一个或多个的组合。术语“数据处理单元”或“数据处理装置”包含用于处理数据的所有装置、设备和机器,包括例如可编程处理器、计算机、或多个处理器或计算机。除了硬件之外,装置还可以包括为所讨论的计算机程序创建运行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统、或它们中的一个或多个的组合的代码。计算机程序(也已知为程序、软件、软件应用、脚本或代码)可以以任何形式的编程语言(包括编译或解释语言)编写,并且其可以以任何形式部署,包括作为独立程序或作为适合在计算环境中使用的模块、组件、子例程或其他单元。计算机程序不一定对应于文件系统中的文件。程序可以存储在保存其他程序或数据(例如,存储在标记语言文档中的一个或多个脚本)的文件的一部分中,存储在专用于所讨论的程序的单个文件中,或存储在多个协调文件中(例如,存储一个或多个模块、子程序或代码部分的文件)。计算机程序可以被部署以在一个计算机上或在位于一个站点上或跨多个站点分布并通过通信网络互连的多个计算机上运行。本说明书中描述的过程和逻辑流程可以由运行一个或多个计算机程序的一个或多个可编程处理器执行,以通过对输入数据进行操作并生成输出来执行功能。过程和逻辑流程也可以由专用逻辑电路执行,并且装置也可以实施为专用逻辑电路,例如,fpga(fieldprogrammablegatearray,现场可编程门阵列)或asic(applicationspecificintegratedcircuit,专用集成电路)。适合于运行计算机程序的处理器包括例如通用和专用微处理器、以及任何类型的数字计算机的任何一个或多个处理器。通常,处理器将从只读存储器或随机存取存储器或两者接收指令和数据。计算机的基本元件是用于执行指令的处理器和用于存储指令和数据的一个或多个存储器设备。通常,计算机还将包括用于存储数据的一个或多个大容量存储设备(例如,磁盘、磁光盘或光盘),或可操作地耦合以从该一个或多个大容量存储设备接收数据或向该一个或多个大容量存储设备传递数据、或者从其接收数据并向其传递数据。然而,计算机不需要这样的设备。适用于存储计算机程序指令和数据的计算机可读介质包括所有形式的非易失性存储器、介质和存储器设备,包括例如半导体存储器设备,例如eprom、eeprom和闪存设备。处理器和存储器可以由专用逻辑电路补充或并入专用逻辑电路中。旨在将说明书与附图一起视为仅示例性的,其中示例性意味着示例。如本文所使用的,“或”的使用旨在包括“和/或”,除非上下文另外明确地指示。虽然本专利文档包含许多细节,但这些细节不应被解释为对任何发明或可能要求保护的范围的限制,而是作为特定于特定发明的特定实施例的特征的描述。在本专利文档中在单独的实施例的上下文中描述的某些特征也可以在单个实施例中组合实施。相反,在单个实施例的上下文中描述的各种特征也可以分别在多个实施例中或以任何合适的子组合实施。此外,尽管特征可以在上面描述为以某些组合起作用并且甚至最初如此要求保护,但是在一些情况下可以从组合排除来自所要求保护的组合的一个或多个特征,并且所要求保护的组合可以针对子组合或子组合的变化。类似地,虽然在附图中以特定顺序描绘了操作,但是这不应该被理解为需要以所示的特定顺序或以先后顺序执行这样的操作或者执行所有示出的操作以实现期望的结果。此外,在本专利文档中描述的实施例中的各种系统组件的分离不应被理解为在所有实施例中都需要这样的分离。仅描述了一些实施方式和示例,并且可以基于本专利文档中描述和示出的内容来进行其他实施方式、增强和变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1