一种移动边缘计算网络中基于LT码的雾化缓存方法与流程
本发明属于无线通信领域,具体涉及一种移动边缘计算网络中基于lt码的雾化缓存方法。
背景技术:
通信设备数目剧增、移动数据流量激增等现状给移动通信网络带来了巨大的压力,使得网络负载增加,带宽资源紧张,网络延时增大,用户体验变差。移动边缘计算(mobileedgecomputing,mec)通过将存储、计算、服务等迁移到靠近用户端的网络边缘处来解决上述问题。移动边缘计算中的缓存技术通过将流行内容缓存到网络边缘处(如边缘服务器、用户设备等),有效缓解回程链路带宽压力,降低网络时延。相比于边缘服务器处的内容缓存,在用户终端缓存流行内容,用户不仅可以在其缓存中存储流行内容以满足自己的请求,还可以通过d2d通信直接从其他用户那里获取内容,使得系统总缓存能力随着网络中缓存设备的数量而增长。编码缓存作为一种利用缓存制造多播机会来减小通信负载的新技术,获得了广泛的关注。lt码作为一种无速率喷泉码,编码器可以生成的编码符号的个数是无限的,因此可以在边缘缓存中灵活应用。
尽管现有的基于lt码的编码缓存方案已经设计了缓存放置策略,但是没有针对编码缓存特定参数的描述,尤其是缓存冗余设计。
技术实现要素:
本发明的目的在于克服上述不足,提供一种移动边缘计算网络中基于lt码的雾化缓存方法,对于给定的mec网络以及文件大小,给出lt编码参数和缓存冗余,确保内容请求者可以通过d2d通信,从附近的少数缓存用户处获得编码包,以99.9%的概率恢复出原始文件。本发明不仅可以充分利用用户的存储空间,还可以减轻从远程服务器获取内容带来的带宽负担,具有重要的研究意义。
为了达到上述目的,本发明包括以下步骤:
步骤一,文件库根据内容流行度分布,随机决定待缓存的文件f;
步骤二,根据待缓存的文件f,确定lt编码参数,再根据lt编码参数,获得恢复原始待缓存的文件f所需要的编码包缓存冗余γf;
步骤三,根据编码包缓存冗余γf判断待缓存的文件f是否满足边缘缓存内存限制;
若满足,继续步骤四,若不满足,结束此轮内存放置,返回步骤一,等待用户释放缓存内存;
步骤四,根据编码包缓存冗余γf,通过lt编码器获得k(1+γf)个编码包,然后将这些编码包均匀分发给系统中的每个用户,其中k表示将文件f等分后的数据包数目;
步骤五,内容请求用户发送请求,通过d2d通信从周围的缓存用户处获取编码包,边接收边解码,直至恢复出请求文件。
步骤一中,假定文件的流行度服从zipf分布。
编码包缓存冗余γf为:
其中,γ'f为理论恢复文件冗余,u为缓存用户数目,λ为用户之间能够进行d2d通信的接触率。
步骤四中,每个用户缓存关于待缓存的文件f的
步骤五中,内容请求用户向周围的用户广播内容f的下载请求,收到请求的用户检查缓存中是否有文件f的编码包,若有,则通过d2d通信向内容请求者传输编码包,内容请求者边接收边解码,直至恢复出原始请求文件,不再接收编码包。
步骤五中,解码采用高斯消去法。
与现有技术相比,本发明通过lt码对待缓存的文件进行编码,文件被碎片化,由边缘用户设备缓存。由于编码包较小,每个用户缓存的编码包数目少,占用的内存小,充分利用了设备的空闲内存,提高了系统的内存利用率。内容请求者可以通过d2d通信获取其他用户缓存的内容,用户既是内容请求者也是内容提供者,充分体现了互联网中的共享思维,提高了内存利用率。本发明的内容在网络边缘以雾化状态存储,缓存内容靠近内容请求用户,提升了用户体验。本发明中内容请求用户能够以更高的概率获取请求文件,实现更好的缓存效果。
附图说明
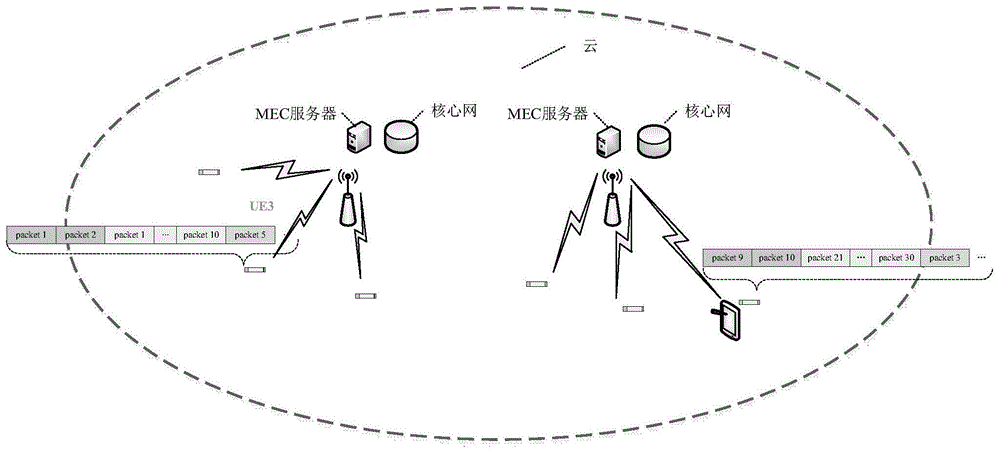
图1为本发明的系统框图;
图2为不同数据包数目k和理论恢复概率1-δ下,lt码编码参数c=0.04时,鲁棒孤子度分布中参数β的变化情况图;
图3为不同用户接触率下,恢复出原始文件所需的缓存冗余对比图。
具体实施方式
下面结合附图对本发明做进一步说明。
参见图1,本发明的具体方法如下:
步骤1、确定缓存文件;
由于假设了用户请求内容的概率服从zipf分布,那么排名在第i位的文件被用户缓存的概率为
步骤2、确定缓存冗余;
假设文件f大小为cf,将文件f等分为kf个数据包,每个数据包具有相同的长度lf,则cf=kf·lf。利用lt编码器对文件f的数据包进行编码。
本发明中,lt编码采用的度分布为鲁棒孤子分布:
其中,c为大于0的常数,解码成功的概率为1-δ。在本方法中,为保证恢复率,令δ=0.001。根据多次试验,对于不同的k值,c=0.04时,能在较小的恢复冗余下保证恢复率达到99.9%,平衡缓存内存限制和高概率内容恢复之间的矛盾。
根据上述lt编码理论可得,要以1-δ的概率恢复出原始文件,则内容请求用户需要收集到kf=kfβ个编码包,定义
假设用户用于存储缓存内容的空间为m,第j次选择文件时,用户剩余的缓存内存为mj,(m1=m)。则内存约束条件:
判断第j次(初始值为1)选定的文件f是否满足边缘缓存内存约束,若满足,令
步骤3、文件lt编码及内容放置;
首先根据步骤2中确定的数据包数目kf,及每个数据包的长度为lf,对文件f进行切分。根据步骤2中计算的缓存冗余可知,对kf个数据包进行编码,获得kf(1+γf)个编码包。
接下来的编码过程可简述为:根据鲁棒孤子度分布,随机产生kf(1+γf)个度,度分布μ(d)在步骤2中给出了详细表达式。对于任意一个度d,从kf个数据包中随机选择d个,逐一进行异或操作,形成一个编码包,这一过程重复kf(1+γf)次,最终得到所有个kf(1+γf)编码包,lt编码过程结束。除了异或原始数据包得到长度为l的包,编码包中还需加入文件信息以及长度为kf的编码包组成信息。
将处理好的编码包均匀放置在系统中的每个用户处,即每个用户缓存
此时,文件f放置结束,服务器继续步骤1,进行下一文件的放置。
步骤4、内容请求与分发;
内容请求用户通过d2d通信,向周围的用户广播内容f的下载请求。周围用户收到请求后,检索自身缓存中是否存储了文件f的编码包,若有,则通过d2d通信向内容请求者传输编码包,内容请求者边接收边解码,直至恢复出原始请求文件,就不再接收编码包。至此,文件f的请求与分发过程结束。图3表明,满足内存限制时,不同的接触率下,总能存在适当的缓存冗余,使得内容请求者以99.9%的概率恢复出所需文件,同时仿真结果表明,实际恢复率99.9%时所需的缓存冗余要小于步骤3中计算出的缓存冗余。用户端的lt解码器采用高斯消去的解码方式,需要利用编码包中的异或信息。恢复请求文件时,内容请求用户不必关心接收到的编码包的具体内容,只要保证收集到足量的编码包,就可以恢复出所需要的内容。用户作为内容请求者的同时,也是内容提供者,实现了缓存内容的共享。
- 还没有人留言评论。精彩留言会获得点赞!