一种基于MacQueen聚类的MIMO预编码码本构造方法与流程
本发明涉及移动通信系统技术领域,具体为一种基于macqueen聚类的mimo预编码码本构造方法。
背景技术:
多输入多输出(multipleinputmultipleoutput,mimo)系统架构作为4g-lte中的关键技术得到了广泛的应用,最新出炉的5g标准,仍然继续采用mimo技术作为其物理层架构。在采用mimo技术时,因为基站端部署了多根天线,且小区内也存在着大量的用户,所以mimo系统存在着严重的流间干扰和用户间干扰,预编码作为解决这一问题的有效手段成为了mimo系统架构的核心功能模块并得到了广泛的应用,同时也受到了学术界和各大通信企业的深入研究。
预编码目前主要有线性预编码和非线性预编码两种,非线性预编码复杂度高实现困难,而线性预编码复杂度低、原理简单,普遍应用在实际的通信系统中。在已有线性预编码方案中又可以分为非码本的和基于码本的预编码,而实际通信系统中受反馈链路带宽的限制,往往无法实现理想的信道状态信息(csi)反馈,对于部分csi的反馈,3gpp规定采用基于码本的预编码方案。基于码本的预编码方案主要分为两个部分:码本的构造与码字选取,码本构造的方法有很多,例如dft码本、householder码本、层结构码本、lloyd矢量量化码本等。其中lloyd矢量量化码本是采用lloyd聚类算法来构造码本,但该方法生成的码本误码率性能好坏受限于初始码本的选取和误差门限的设置,因此导致了码本误码率性能的不稳定。
技术实现要素:
本发明的目的在于提供一种基于macqueen聚类的mimo预编码码本构造方法,本发明通过采用macqueen聚类算法来替代lloyd矢量量化码本中的lloyd聚类算法,使得在计算过程中并不涉及类似于lloyd迭代中的误差门限设置,避免了误差门限值的选取对码本误码率性能的影响,同时在每个信道矩阵h分类之后都更新了质心,为下一次信道矩阵的分类提供了更加准确的分类依据,因此本方法使mimo系统的误码率性能得到进一步的提高,提高通信系统的可靠性。
为实现上述目的,本发明提供如下技术方案:一种基于macqueen聚类的mimo预编码码本构造方法,包括如下步骤:
步骤1:随机选取q个信道样本h;
步骤2:对q个信道样本中的前n(q>>n)个信道矩阵h进行svd分解,得到相应的n个预编码矩阵f,并将这n个预编码矩阵作为初始码本f0={f1,f2,…,fn},每个码字fi(i=1,2,…,n)即是n个类的初始质心;
步骤3:选取下一个信道矩阵h,计算其与每个码字矩阵fi相乘的frobenius范数的平方,并将该信道矩阵h分配到使frobenius范数的平方最大的码字矩阵fi所对应的类中;
步骤4:重新计算步骤3中更新了的类的质心fi;
步骤5:重复步骤3和步骤4,直到q个信道样本全部分配完毕;
步骤6:将最终n个类所对应的质心作为预编码码本f。
优选的,对q个信道样本中的前n(q>>n)个信道矩阵h进行svd分解,得到相应的n个预编码矩阵f,其中预编码矩阵的获得按照以下公式进行:
h=u∑v
f=v(j)
其中u、∑、v矩阵分别为信道矩阵svd分解得到的左奇异矩阵,奇异值组成的对角矩阵,右奇异矩阵,v(j)为矩阵v的前j列组成的矩阵。
优选的,把信道矩阵按顺序逐个进行分类,且在每分配完一个信道矩阵h之后,都要重新计算增加了新信道矩阵的类的质心f,其中质心f的计算按照以下公式进行:
其中
优选的,所述步骤3中选取下一个信道矩阵h,是从第n+1个信道矩阵h开始,依次为第n+2,n+3,…,q个信道矩阵h。
优选的,所述步骤3中计算h与每个码字矩阵fi相乘的frobenius范数的平方的计算表达式为:
其中
本发明提供了一种基于macqueen聚类的mimo预编码码本构造方法,具备以下有益效果:
本发明通过采用macqueen聚类算法来替代lloyd矢量量化码本中的lloyd聚类算法,使得在计算过程中并不涉及类似于lloyd迭代中的误差门限设置,避免了误差门限值的选取对码本误码率性能的影响,同时在每个信道矩阵h分类之后都更新了质心,为下一次信道矩阵的分类提供了更加准确的分类依据,因此本方法使mimo系统的误码率性能得到进一步的提高,提高通信系统的可靠性。
附图说明
图1为mimo-ostbc系统框图;
图2为基于码本的预编码工作流程图;
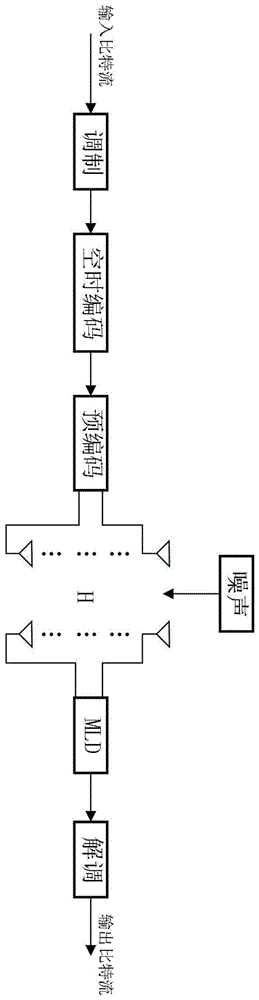
图3为本发明提供的基于macqueen聚类的mimo预编码码本构造方法流程图;
图4为预编码码本大小l=64时,本发明提供的基于macqueen聚类的mimo预编码码本构造方法与lloyd矢量量化码本,dft码本的误码率(ber)性能曲线对比示意图;
图5为预编码码本大小l=16时,本发明提供的基于macqueen聚类的mimo预编码码本构造方法与lloyd矢量量化码本的误码率(ber)性能曲线对比示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
在本实例中仿真采用的通信系统为mimo-ostbc系统,采用4-qam调制,alamouti空时编码,发射天线数tx为4,接收天线数rx为2,系统框图如图1所示,其中预编码部分采用的是基于码本的预编码方案,其具体工作流程如图2所示。
实施例1
一种基于macqueen聚类的mimo预编码码本构造方法,包括如下步骤:
步骤1:随机选取q=10000个信道矩阵h;
步骤2:将前n=64个信道矩阵进行svd分解h=uσv,并根据f=v(2),即选取右奇异矩阵v的前两列作为预编码矩阵,得到相应的64个预编码矩阵f,并将这64个预编码矩阵作为初始码本f0={f1,f2,…,f64},码本大小l=64,每个码字fi(i=1,2,…,64)即是64个
步骤3:选取第65个信道矩阵h65,计算该矩阵与每个码字矩阵fi相乘的frobenius范数的平方,即
然后将信道矩阵h65分配到使value值最大的码字矩阵f对应的类中,为了表述的更清楚,假设当i=m时,value值最大,则h65被分配到
步骤4:按照下述公式重新计算步骤3中更新了的
其中公式表示计算
步骤5:分别选取第66,67,…,10000个信道矩阵重复步骤3和步骤4;
步骤6:将最终分配完成后,每个
实施例2
一种基于macqueen聚类的mimo预编码码本构造方法,包括如下步骤:
步骤1:随机选取q=10000个信道矩阵h;
步骤2:将前n=16个信道矩阵进行svd分解h=uσv,并根据f=v(2),即选取右奇异矩阵v的前两列作为预编码矩阵,得到相应的64个预编码矩阵f,并将这64个预编码矩阵作为初始码本f0={f1,f2,…,f16},码本大小l=16,每个码字fi(i=1,2,…,16)即是16个
步骤3:选取第17个信道矩阵h17,计算该矩阵与每个码字矩阵fi相乘的frobenius范数的平方,即
然后将信道矩阵h17分配到使value值最大的码字矩阵f对应的类中,为了表述的更清楚,假设当i=m时,value值最大,则h17被分配到
步骤4:按照下述公式重新计算步骤3中更新了的
其中公式表示计算
步骤5:分别选取第18,19,…,10000个信道矩阵重复步骤3和步骤4;
步骤6:将最终分配完成后,每个
对本发明实施例1与已有预编码码本在上述通信系统中的误码率性能进行仿真对比,得到图4,对本发明实施例1与已有预编码码本在上述通信系统中的误码率性能进行仿真对比,得到图5。
结论:
(1)由从图4和图5可以看出,在相同条件下,与已有的预编码码本方案相比,本发明可以在不增加反馈开销,也就是相同码本大小的情况下,进一步降低系统的误码率,并且在信噪比较高的条件下,本发明展现出了更优异的误码率性能。
(2)从本文中所描述的具体实例可以看出,本发明方法在计算过程中并不涉及类似于lloyd迭代中的误差门限设置,避免了误差门限值的选取对码本误码率性能的影响,同时在每个信道矩阵h分类之后都更新了质心,使得分类更加准确,使mimo系统的误码率性能得到进一步的提高,从而增强通信系统的可靠性。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!