基于TTS实现智能电视自定义播报音的系统及方法与流程
本发明涉及智能语音交互技术,特别涉及一种基于tts实现智能电视自定义播报音的系统及方法。
背景技术:
近年来,随着科技的快速发展,生活质量的不断提高,用户对智能电视设备的要求也愈加苛刻。为了极大的满足用户的个性化体验,产生了语音替代遥控器按键更加快捷的智能的电视操控方式。但仅仅这样的操作方式并不能完全满足所有用户对于电视娱乐性和趣味性的要求。
目前市场上智能电视、智能音箱、车载音响、智能手机等的语音播报音均是来自于系统的设置。在语音的使用过程中,难免会觉得语音的交互既陌生又机械,给人冷冰冰的机器回应。而如果把智能设备上的语音自定义成自己想听到的声音,如女儿儿子、正在追的爱豆的语音回应,就能够使用户使用语音的体验更好,更加具有趣味性,更加体现智能电视作为智能家居产品的属性。
目前市场上已有的语音播报音大多都是厂商提供的播报音,这种类型的播报音都是无差别统一定制化样式的,用户自身的个人风格并不能完整的体现,语音播报音也是单调乏味的。这种统一的播报音也不能满足大多数用户的偏好,比如一部分用户喜欢沙哑低沉的声音,一部分用户喜欢气质淑女的声音,也有部分用户喜欢玲珑的娃娃音等。在自定义语音播报音方面使用的较好的例子是地图导航类软件的语音,如微博热搜榜上的倪妮地图语音、被炒得火热的林志颖地图导航语音,这样的定制化的语音都受到了广大热心民众的支持及欢迎。但在智能电视方面很多场景下播报音的使用体验都是偏向于同冷冰冰的机器对话,同智能电视的语音交互变得很不日常,如果用户可以同自己喜欢的声音交流,智能电视语音方面的人机交互将变得很轻松愉快同时具有私人定制性。正如听音乐的喜好无法趋同于大众化一样,对于智能电视端的播报音而言,实现用户可定制专属于自己的播报音就显得优势突出了。
技术实现要素:
本发明的目的是提供一种基于tts实现智能电视自定义播报音的系统及方法,解决目前市场上已有的语音播报音大多都是厂商提供的播报音,单调且不能满足大多数用户的偏好的问题。
本发明解决其技术问题,采用的技术方案是:基于tts实现智能电视自定义播报音的系统,包括用户界面控制器、事件管理器、语音处理器、tts合成引擎和语音响应单元;
所述用户界面控制器,用于通过事件管理器协调用户控制器,用户在用户界面控制器的引导下进入开始自定义播报音,用户界面控制器引导用户输入自定义播报音的名称后开始录音,录音过程中通过指引用户阅读指定内容的文字来采集用户的声音特征,录音过程中事件管理器调起语音处理器;
所述语音处理器,用于在事件管理器调起语音处理器,协调用户界面控制器,一边录入一边暂存当前用户的录音,知道用户录音完成时,语音处理器将整段录音传输到tts合成引擎;
所述tts合成引擎,用于当语音处理器将整段录音传输到tts合成引擎时,开始工作,并在规定时间内根据采集的用户的声音特征合成用户自定义播报音,所述用户自定义播报音合成完毕时,语音处理器通知事件管理器;
所述事件管理器,用于当接收到语音处理器的通知时,将事件传输到用户界面控制器,在用户界面控制器提示用户当前自定义播报音录制完成,并生成播报音页面;
用户在播报音页面选择需要的自定义播报音,用户界面控制器协调语音处理器工作,将用户选择的自定义播报音通知给语音处理器,语音处理器将智能电视全局的语音播报音更新成用户选择的自定义播报音;
所述语音响应单元,用于当用户发出唤醒语音的指令时,事件管理器将指令下达到语音响应单元作对应的指令处理。
作为优选,在录音过程中,将用户阅读的制定内容的文字分成几个小段,每个小段录音完成时,语音处理器进行一次保存操作。
作为优选,所述规定时间为30分钟。
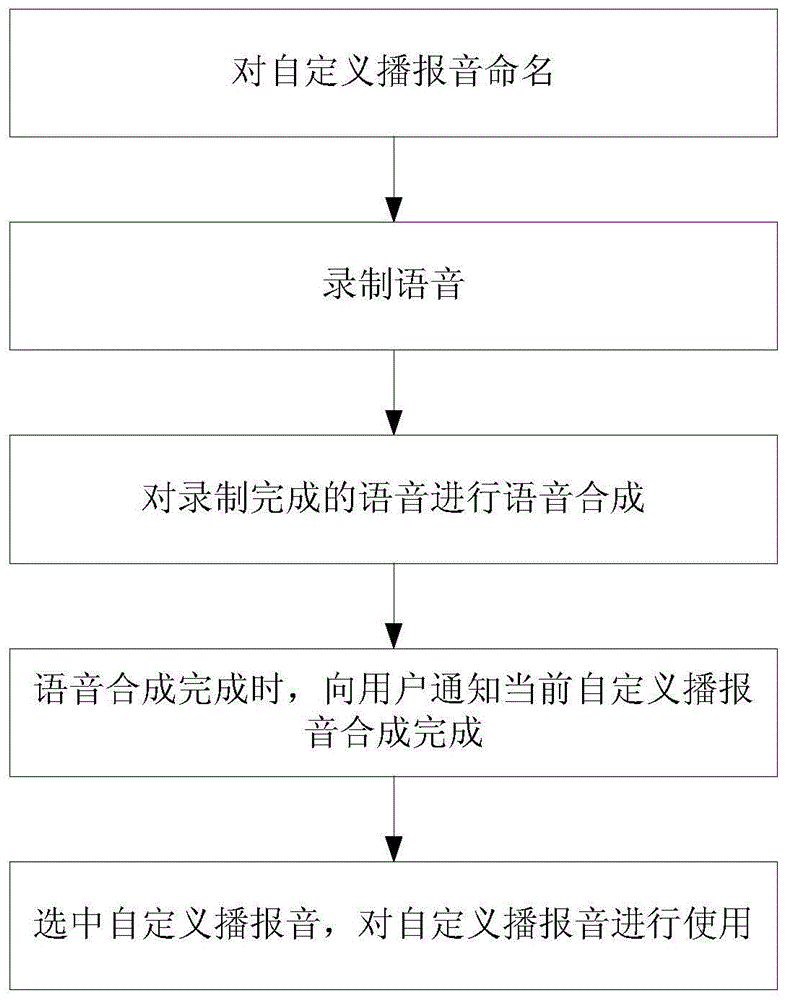
基于tts实现智能电视自定义播报音的方法,包括如下步骤:
步骤1、对自定义播报音命名;
步骤2、录制语音;
步骤3、对录制完成的语音进行语音合成;
步骤4、语音合成完成时,向用户通知当前自定义播报音合成完成;
步骤5、选中自定义播报音,对自定义播报音进行使用。
作为优选,步骤1中,用户能够选择任意需要的名称作为将要录制的自定义播报音的名称。
作为优选,步骤2中,录制语音时,用户按住遥控器的语音键朗读界面引导页面给出的文字内容直到朗读完成,松开语音键,录制的过程中用户若中途放弃录制,语音处理器会保存已经录制的部分内容,当用户再次进入录制时从上次录制的位置继续开始录制。
作为优选,步骤3中,点击界面端的保存按钮,开始对录制完成的语音进行语音合成,若合成失败,表示出现故障,语音处理器依然会保存当前已录制的内容,故障消除后,用户能够机选对已录制的内容进行保存,并通过tts合成引擎进行语音合成。
作为优选,步骤4中,语音合成完成时,用户界面控制器会适时向用户通知当前自定义播报音合成完成。
本发明的有益效果是,通过上述基于tts实现智能电视自定义播报音的系统及方法,用户只需要简短的输入录音,经过语音处理器和tts合成引擎的处理后就能够在智能电视端使用自定义的语音播报音同电视进行智能交互。不仅能够在唤醒电视的时候听到自定义的语音播报音回应,而且在与智能电视对话或者向智能电视提出需求的时候听到自定义的语音播报音回应。用户可在与智能电视的整体语音交互中使用自定义播报音,增强了用户在智能电视端的体验,同时也提供了一种语音的新的使用方式,用户可在电视端听到任意自己喜欢的语音播报音。摆脱了原本电视端语音播报音机械单调的桎梏,实现了个性化语音播报音定制。
附图说明
图1为本发明基于tts实现智能电视自定义播报音的方法的流程图。
具体实施方式
下面结合附图,详细描述本发明的技术方案。
本发明所述基于tts实现智能电视自定义播报音的系统,包括用户界面控制器、事件管理器、语音处理器、tts合成引擎和语音响应单元;用户界面控制器,用于通过事件管理器协调用户控制器,用户在用户界面控制器的引导下进入开始自定义播报音,用户界面控制器引导用户输入自定义播报音的名称后开始录音,录音过程中通过指引用户阅读指定内容的文字来采集用户的声音特征,录音过程中事件管理器调起语音处理器;语音处理器,用于在事件管理器调起语音处理器,协调用户界面控制器,一边录入一边暂存当前用户的录音,知道用户录音完成时,语音处理器将整段录音传输到tts合成引擎;tts合成引擎,用于当语音处理器将整段录音传输到tts合成引擎时,开始工作,并在规定时间内根据采集的用户的声音特征合成用户自定义播报音,用户自定义播报音合成完毕时,语音处理器通知事件管理器;事件管理器,用于当接收到语音处理器的通知时,将事件传输到用户界面控制器,在用户界面控制器提示用户当前自定义播报音录制完成,并生成播报音页面;用户在播报音页面选择需要的自定义播报音,用户界面控制器协调语音处理器工作,将用户选择的自定义播报音通知给语音处理器,语音处理器将智能电视全局的语音播报音更新成用户选择的自定义播报音;语音响应单元,用于当用户发出唤醒语音的指令时,事件管理器将指令下达到语音响应单元作对应的指令处理。
上述系统中,在录音过程中,可以将用户阅读的制定内容的文字分成几个小段,每个小段录音完成时,语音处理器进行一次保存操作。根据实际应用场景,规定时间优选为30分钟。
另外,本发明还提出一种基于tts实现智能电视自定义播报音的方法,其流程图参见图1,其中,该方法包括如下步骤:
步骤1、对自定义播报音命名;
步骤2、录制语音;
步骤3、对录制完成的语音进行语音合成;
步骤4、语音合成完成时,向用户通知当前自定义播报音合成完成;
步骤5、选中自定义播报音,对自定义播报音进行使用。
上述方法中,步骤1中,用户能够选择任意需要的名称作为将要录制的自定义播报音的名称。
步骤2中,录制语音时,用户可以按住遥控器的语音键朗读界面引导页面给出的文字内容直到朗读完成,松开语音键,录制的过程中用户若中途放弃录制,语音处理器会保存已经录制的部分内容,当用户再次进入录制时从上次录制的位置继续开始录制。
步骤3中,点击界面端的保存按钮,开始对录制完成的语音进行语音合成,若合成失败,表示出现故障,语音处理器依然会保存当前已录制的内容,故障消除后,用户能够机选对已录制的内容进行保存,并通过tts合成引擎进行语音合成。
步骤4中,语音合成完成时,用户界面控制器会适时向用户通知当前自定义播报音合成完成。
具体应用时,界面控制器是整个用户使用的入口,统一处理了用户的操作指引、操作结果返回等。用户在智能电视端的界面入口选择自定义播报音进入开始录制,录制完成后指引用户保存录音并向用户反馈当前合成进度和合成的结果,如果用户中途退出同样将结果转达事件管理器,再由事件管理器通知语音处理器保存当前的录制内容;事件管理器连接界面控制器、语音相应单元、语音处理器协调工作,把来自界面控制器的录音结果向语音处理器传送,也将语音处理器录音合成的结果回传给界面控制器,同时也将用户使用语音的情况转换为语音指令分发给各个语音响应单元;tts合成引擎则独立的工作,对来自语音处理器的录音进行合成操作,并将结果反馈给语音处理器;语音响应单元也是独立的处理用户每一次的语音指令。整个系统明确分工、互相协调,实现了完整的自定义播报音产生到使用的流程。
并且,该播报音的使用场景包括但不限于语音唤醒智能电视,语音下达操作智能电视指令时智能电视端的语音回馈,闲聊模式下与智能电视进行多轮对话时智能电视端的语音回馈等。
- 还没有人留言评论。精彩留言会获得点赞!