一种顺序感知的片上网络路由方法和网络路由器与流程
本发明涉及一种片上网络路由方法及装置,尤其涉及一种可以减轻多路径数据包重排序的顺序感知片上网络路由方法和网络路由器。
背景技术:
随着多核芯片核心数目的增加,高效的片上互连网络的设计变得越来越重要。给定一个网络的拓扑,它的性能很大程度上取决于路由算法。自适应路由算法能够将负载平衡到整个网络通道,从而改善网络性能并且提供容错。然而,多路径的并行传输会引起严重的乱序传输,其主要问题在于接收端的数据包只能被顺序接收。考虑到乱序数据包到达时间的不确定性,重排序缓冲通常需要设置得很大,这造成了严重的硬件开销。实际上,如果数据包顺序到达目的地,重排序缓冲就不需要了。因此,本发明致力于减轻自适应路由引起的乱序问题。
乱序主要由自适应路由中多路径传输引起的。路由算法可以分为确定性,无意识和自适应路由算法。确定性路由始终沿着同一条路径传输数据包,不管网络状态的变化。无意识路由算法路由数据包的时候不考虑网络状态。作为对比,自适应路由算法为数据包选择一条合适的路径基于网络状态。自适应路由算法促进负载均衡,因此在非均衡数据流中能够提高网络性能。此外,自适应路由算法的路径多样性增强网络的鲁棒性,并且允许网络容忍出错的通道和节点。路由算法也可以分为最短和非最短路由算法。最短路由算法总是选择从源到目的地之间最短的路径,而非最短路由算法从所有最短和非最短路径中选择。理论上,非最短路由算法能够在一定程度上改善负载均衡,但是很难在实际中应用,因为延迟极大增加而且易于遭受活锁和死锁。因此,在本发明中,本发明集中于设计最短自适应路由。
近年来,许多自适应路由方法已经被提出来改善网络性能。然而,由于多路径传输,自适应路由会造成严重的数据包乱序,尤其是对于非均衡流量模型。在非均衡的流量模型下,由于选择了一个较为拥挤的路径,一个流中前面的数据包可能比后面的数据包更晚到达目的地。不仅仅局限于乱序问题,顺序传输对于很多应用来说都是广泛假定的基础,例如多媒体,文件传输协议和缓存一致性协议。直接通信计算模型的实现,例如流计算,也需要数据包顺序传输,和显式消息传递应用程序一样。
自适应路由算法的自适应粒度是数据包,多路径传输导致数据包无法实现顺序传输。为了保证顺序传输,之前的工作选择确定性或无意识路由而不是自适应路由。为了使用自适应路由,必须抛弃顺序传输。如果数据包顺序是必须的,则只能在目的地上执行重排序,同时尽可能减轻数据包重排序来减少重排序的缓冲和延迟开销。
技术实现要素:
在本发明中,从路由器结构的角度来解决乱序问题,首先提出一个数据包重排序量化度量标准:乱序程度(ood)。它的定义是所有节点中最大的缓存占用率。为了最小化ood的目标,该发明提出了一种能够减轻多路径数据包重排序的顺序感知片上网络路由方法和网络路由器,该路由器从两个方面来对通过其的数据包进行重排序,首先,通过重排序逻辑来重排序输入缓存中的数据包,其次,本发明通过顺序感知开关分配器来对自不同输入端口的数据包重排序。通过两层重排序,从该发明的路由器排出的数据包能够保持顺序。该发明中的路由器能够感知数据包的顺序,并且对它们重排序,而不是限制数据包的传输,因此具有高效率并且不降低网络性能的优点。
本发明首先用乱序程度(odd)这一变量,作为对数据包重排序的度量标准,并给出了在接收端测量ood的方法。考虑一个数据包序列(0,1,2,...,n)从一个源节点向一个目的节点传输。期望的数据包(e)是未到达的数据包中最小序列号的数据包,所有序列号小于e的数据包都已经到达。一个序列号大于期望数据包的到达的数据包存储在一个假设的缓存中,这个缓存足够长,能够等到乱序恢复。在任何数据包到达的那个时刻,缓存占用(b)等于缓存中的乱序数据包数量,包括刚到达的数据包。缓存占用‘b’在每次数据包到达时都被记录。对一组数据包,本发明定义最大缓存占用量为数据包的ood。ood不仅适用于自然数序列,也适用于非连续的序列号。对于非连续的序列号,本发明需要先将不规则的序列号转化为自然数序列。
最大缓存占用决定在接收端需要的重排序缓冲的最低界限。相似地,一个流的ood是在接收过程中的最大缓存占用,整个网络的ood是所有流中最大的ood。
接收端的ood计算公式如下:
ood=max((pos(small)-pos(large))-num(less))
式中,pos(small)表示两个数据包中,pid(packetidentifier表示数据流中的数据包编号,缩写为pid)编号小的但是到达比较晚的数据包的位置坐标;pos(large)表示两个数据包中,pid编号大的但是到达早的那个数据包的位置坐标;num(less)表示到达序列中这两个数据包之间的pid比这两个数据包的pid都小的数据包个数。pos(small)和pos(large)是一个到达序列中的两个逆序数的位置。(pos(small)-pos(large))是这两个逆序数的间隔。由于序列号小于这两个逆序数的数据包已经从重排序缓存中恢复了,因此本发明减去num(less)。
ood测量的方法是,首先将到达序列转换为自然数序列;对于每个期望的数据包,本发明从第一个缓冲的数据包的位置,遍历到序列的末尾,序列中位于它之前的所有数据包都将按顺序排列并从重排序缓冲区中恢复;如果找到了期望数据包,则期望的数据包值(e)增加1,并且临时乱序度被更新;否则,程序被中断,由于预期的数据包丢失,因此序列中的后续数据包也无法处理。
有两种并行会导致数据包乱序。第一种是多虚拟通道(virtualchannel,vc)传输,这种情况下,即使数据包走相同的路径也会产生乱序。第二种是多路径传输,这会造成更严重的乱序。为了尽可能地减轻乱序程度而不限制路径多样性和并行传输,本发明从路由器结构着手进行设计。对于第一种情况,本发明对输入缓存中排队的数据包重排序;在第二种情况,本发明提出在路径交叉节点通过开关分配策略对数据包重排序。此外,所有路由器独立的执行数据包重排序,不会引入新的依赖环,因此本发明是无死锁的。
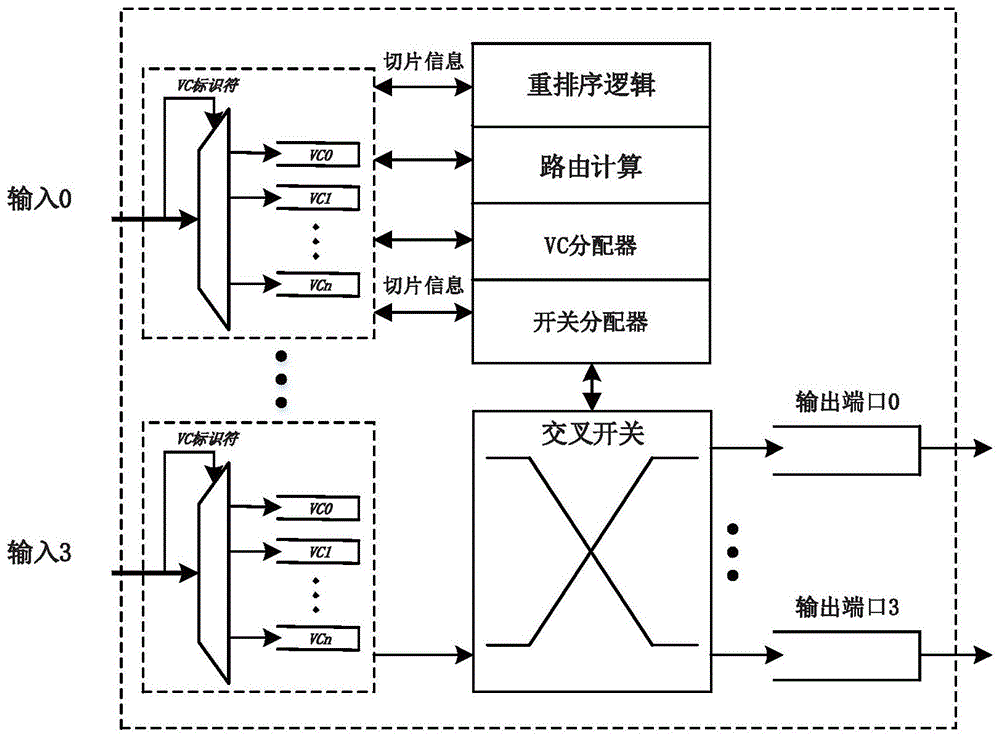
本发明是基于一个标准的虚通道路由器来实现。一个标准虚通道路由器的一个输入端口有多个虚通道,并且应用了虚通道流控。一个虚通道路由的组件可以被分成两类:数据路径和控制面板。路由器的数据路径处理数据包的存储和移动,包括输入缓存,一个开关,一组输出缓存。输入缓存又称为输入缓冲区,输出缓存又称为输出缓冲区。控制面板组件负责协调数据包在数据路径资源中的移动,对于虚通道路由器,控制面板执行路由计算、数据包重排序、多虚拟通道分配和开关分配。图1为本发明提出的路由器微体系结构示意图。
当数据包在等待vc、开关带宽和通道带宽的时候,输入缓冲区即输入缓存,保存数据切片。输出缓冲区即输出缓存,在各vc之间均匀划分,这可以在开关中实现输入加速,从而增加路由器的吞吐量。每个vc缓冲区采用链表数据结构,为缓冲区分配和管理提供了灵活性。开关是路由器的心脏。本发明在标准路由器中使用了通用交叉开关,有效地利用了内部带宽。由于不需要跨vc对输出缓冲区存储进行分区,因此每个输出缓存都使用单个先进先出(fifo)缓冲区。
本发明标准路由器的流水线由四个阶段组成:路由计算(rc),vc分配(va),开关分配(sa)和开关通过。本发明中每个流水线阶段需要一个时钟周期。先前关于提高路由器吞吐量的工作与提出的分组重新排序路由器设计是互不影响的,因此本发明的思想可以集成到大多数现代路由器体系结构中。
为了对输入缓冲区中的数据包进行重新排序,本发明将切片插入逻辑扩展为重新排序逻辑,使用重排序逻辑来对输入缓冲区中的数据包进行重新排序。如图2中所示,原始切片插入逻辑只是简单地将切片添加到链表的尾部,重排序逻辑将切片插入到适当的位置并保持数据包的顺序。这是通过利用切片信息感知数据包的顺序来实现的。切片包含fid和pid字段,fid是它所属的流的标识符,pid是流中的数据包的序列号。当片即将进入vc时,重排序逻辑将通过比较fid字段来找到该vc缓存中与其属于相同流的所有切片。然后,通过比较pid字段对它们在该切片内进行重新排序,其他切片不做改动。由于重新排序仅在尾片到达时触发,因此保证了数据包的完整性。
由于每次数据包进入vc的时候都执行重排序,因此vc中的数据包总是按顺序排列的。因此,本发明只需将到来的数据包和链表中的数据包比较一次。当一个链表中数据包切片的fid等于到来数据包的fid时,二者的pid进行比较,如果前者大于后者,则将到来数据包和链表中数据包交换位置,从而在链表的尾部创建一个新的数据节点。按照上述操作,依次遍历整个链表。上述重排序过程可以并行实现,即将到来的数据包的fid和pid与链表中的数据包对应项并行地比较,那些与到来数据包属于相同流,并且pid较大的数据包同时向后移动,到来的数据包同时插入到空位。重排序过程能够在两个周期内执行。由于只有vc中非头数据包被重排序,因此重排序多出的一个周期可以隐藏掉。
为了对来自不同输入端口的数据包进行重新排序,本发明还包含了一种顺序感知开关分配器,该分配器利用数据包信息来检测数据包的顺序,如图3所示。在展示顺序感知开关分配器的操作之前,首先简要介绍开关分配及其表示。在开关中,每个输入可以请求一个或多个输出,并且每个输出可以被一个或多个输入请求。分配器在输入端口和输出端口之间执行匹配。分配器根据三个规则考虑请求并执行分配:只有在声明相应的请求时才能声明授权;每个输入最多可以声明一个授权;每个输出最多可以声明一个授权。对于一组请求,可能存在许多有效的分配结果。包含最多可能分配数的解决方案称为maximum匹配。在不删除现有授权的情况下无法提供其他请求的解决方案称为maximal匹配。显然,maximum匹配肯定是maximal匹配,但反过来maximal匹配不一定是maximum匹配。请求可以由请求矩阵r表示,并且相应的授权可以由授权矩阵g表示。矩阵的每个单元表示输入-输出对。r是任意二进制值矩阵。g也是二进制值矩阵,其仅包含对应于r中的非零条目的条目。此外,g在每行中最多有一个“1”,并且每列中最多有一个“1”。
当来自不同输入端口的属于同一个流的数据包争用同一个输出端口时,本发明的顺序感知开关分配器优先选择较低pid的数据包。作为对比,传统的开关分配器在面对冲突时盲目地选择数据包。
综上所述,本发明公开了一种顺序感知的片上网络路由方法,基于一个标准的虚通道路由器来实现,一个标准虚通道路由器的一个输入端口有多个虚通道,并且应用了虚通道流控;一个虚通道路由的组件可以被分成两类:数据路径组件和控制面板组件,数据路径组件处理数据包的存储和移动,包括输入缓存,一个开关,一组输出缓存;控制面板组件负责协调数据包在数据路径资源中的移动;对于虚通道路由器,控制面板组件执行路由计算、多虚拟通道分配、数据包重排序和开关分配;当数据包在等待vc、开关带宽和通道带宽的时候,输入缓冲区保存数据切片;输入缓冲区在各vc之间均匀划分;每个vc缓冲区采用链表数据结构;在标准虚通道路由器中使用了通用交叉开关,每个输出缓存都使用单个先进先出缓冲区;控制面板组件对输入缓冲区中的数据包进行重新排序,重新排序仅在尾片到达时触发,利用切片信息感知数据包的顺序,将切片插入到适当的位置并保持数据包的顺序;每次数据包进入vc的时候都执行重排序,数据包切片包含fid和pid字段,fid是它所属的流的标识符,pid是流中的数据包的序列号,当一个链表中数据包切片的fid等于到来数据包的fid时,二者的pid进行比较,如果前者大于后者,则将到来数据包和链表中数据包交换位置,从而在链表的尾部创建一个新的数据节点,按照上述操作,依次遍历整个链表;通过顺序感知开关分配器在输入端口和输出端口之间执行匹配,该分配器通过利用数据包信息来检测数据包的顺序,分配器根据三个规则考虑请求并执行分配:只有在声明相应的请求时才能声明授权;每个输入最多可以声明一个授权;每个输出最多可以声明一个授权。
本发明公开了一种顺序感知的片上网络路由器,基于一个标准的虚通道路由器来实现,一个标准虚通道路由器的一个输入端口有多个虚通道,并且应用了虚通道流控;一个虚通道路由的组件可以被分成两类:数据路径组件和控制面板组件,数据路径组件处理数据包的存储和移动,包括输入缓存,一个开关,一组输出缓存;控制面板组件负责协调数据包在数据路径资源中的移动;对于虚通道路由器,控制面板组件包含分别用于执行路由计算、多虚拟通道分配、数据包重排序和开关分配的四类模块;当数据包在等待vc、开关带宽和通道带宽的时候,输入缓冲区保存数据切片;输入缓冲区在各vc之间均匀划分;每个vc缓冲区采用链表数据结构;在标准虚通道路由器中使用了通用交叉开关,每个输出缓存都使用单个先进先出缓冲区;控制面板组件使用重排序逻辑来对输入缓冲区中的数据包进行重新排序,重新排序仅在尾片到达时触发,利用切片信息感知数据包的顺序,将切片插入到适当的位置并保持数据包的顺序;每次数据包进入vc的时候都执行重排序,数据包切片包含fid和pid字段,fid是它所属的流的标识符,pid是流中的数据包的序列号,当一个链表中数据包切片的fid等于到来数据包的fid时,二者的pid进行比较,如果前者大于后者,则将到来数据包和链表中数据包交换位置,从而在链表的尾部创建一个新的数据节点,按照上述操作,依次遍历整个链表;还包括一种用于在输入端口和输出端口之间执行匹配的顺序感知开关分配器,该分配器利用数据包信息来检测数据包的顺序,分配器根据三个规则考虑请求并执行分配:只有在声明相应的请求时才能声明授权;每个输入最多可以声明一个授权;每个输出最多可以声明一个授权。
与现有技术相比,本发明具有如下有益效果:
①可有效减少网络中数据的乱序传输。根据与标准虚拟路由器(使用传统的切片插入逻辑和islip开关分配器)的实验比较结果,当使用footprint路由算法时,本发明相比基准路由器,在shuffle,位反转和均匀流量模式下显示出28.1%,14.6%和9.1%的ood减少,如图4所示;使用dyxy路由算法,相对于基准路由器,本发明改善饱和吞吐率下的ood,分别为23.7%,27.2%和8.3%。对于为1,2,4个切片的数据包,本发明分别比基准路由器减少了28.1%,18.8%和19.1%的ood。对于300数据包的流,500数据包的流和700数据包的流,本发明相对于基准路由器在饱和吞吐率下的ood减少分别为36.3%,14.8%和27.8%。对于2,4和8个vc,与基准路由器相比,本发明的ood减少分别为28.1%,17.2%和16.0%。对于4x4和16×16mesh,本发明相比基准路由器,ood分别减少了23.8%和26.7%。
②可扩展性强。本发明路由器与拓扑无关。它可以不经更改地应用于其他拓扑。此外,由网络中所有本发明路由器组成的重排序系统以完全局部的方式执行重排序,从而使其可以很好地扩展到大型网络。本发明路由器仅涉及路由器体系结构设计,不会更改路由策略。这使得本发明可应用于任何路由算法,包括自适应和确定性路由算法。除了片上网络外,本发明的思想也可以应用于片间网络,只要它需要对包进行重排序。
附图说明
图1为本发明提出的路由器微体系结构示意图;
图2是传统输入缓冲区与本发明顺序感知输入缓冲区的差异示意图;
图3是顺序感知开关分配器对来自不同输入端口的数据包进行重新排序的示意图;
图4是在shuffle数据流模式下,标准虚拟路由器和本发明的ood比较。
具体实施方式
为了更好的了解本发明,下面结合实施例对本发明方案的实施过程进行具体说明。
实施例一:ood计算。对于到达序列(4,3,2,0,1),相应的期待数据包是(0,0,0,0,1)。数据包4到达后,缓存占用值为1。因为数据包4提前到达,需要被缓存。相似地数据包3和2到达后,缓存占用变为3。然后,数据包0到达,然而缓存依然不能被释放,因为数据包1没有到达。最后,当数据包1到达,数据包4,3和2都从重排序缓冲中释放,缓冲占用变为0。因此,这些数据包的ood是3。
对于到达序列(4,3,2,0,1),逆序数4和3的缓存占用是1。相似地,逆序数4和0的缓存占用是3,根据公式ood=max((pos(small)-pos(large))-num(less)),特别地,对于逆序数4和1,中间的数据包0应该被排除,缓存占用是3。因此,这个到达序列的ood是3,与理论结果相符。
实施例二:重排序逻辑实现。图2显示了一个示例,阐述了传统输入缓冲区与本发明的顺序感知输入缓冲区之间的差异。假设一个输入端口有4个vc,黑色单元是来自相同流的数据包。白色单元是来自其他流的数据包。如图2所示,pid等于2的数据包即将进入vco。对于传统的输入缓冲区,此切片只是简单地添加到队列的尾部。输入缓冲区无法意识到这些数据包是乱序的。本发明采用重新排序逻辑,利用顺序感知输入缓冲区将切片插入到正确的位置并保持数据包顺序。
实施例三:顺序感知开关分配器对来自不同输入端口的数据包进行重新排序。如图3所示,假设有一个4端口的路由器,每个物理通道的vc数为2。在图3中,左边的矩阵是请求矩阵,右边的矩阵是由顺序感知开关分配器生成的相应授权矩阵。圆圈代表请求,黑色圆圈表示相应的请求包来自同一流,内部数字是pid。授权矩阵中的灰色单元是授权的请求。请求矩阵中有四个请求,即(0,0),(1,3),(2,1),(3,1),其中请求(2,1)与请求冲突(3,1)。对于顺序感知开关分配器,请求(2,1)被优先选择,因为相应的请求数据包具有较小的pid。相对来说,传统的开关分配器无法察觉数据包的顺序并盲目地选择请求。顺序感知开关分配器产生的授权矩阵如图片右侧的矩阵所示。同时,这里给出的开关分配器也实现了最高匹配。顺序感知开关分配器在输出冲突发生时可提供更好的选择,并且不影响匹配的数量。
- 还没有人留言评论。精彩留言会获得点赞!