车载内容中心网络下基于一致性哈希的移动感知协作缓存方法与流程
本发明涉及一种车载内容中心网络下基于一致性哈希的移动感知协作缓存方法,属于车载内容中心网络技术领域。
背景技术:
车载自组网(vehicularad-hocnetwork,vanet)是一种特殊类型的移动自组网,它包含了若干固定的基础设施和车辆。在vanet中,每一辆车都可以与其他车辆或固定的路边基础单元进行通信。在过去的几十年里,vanet逐渐成为了一个无关来源的内容共享平台,即vanet更多的是关注内容本身,而不是内容的实际载体。面向内容的应用涵盖了诸如娱乐、体育、购物等不同领域。为满足vanet面向内容的特点,提出了一种新的网络结构——内容中心网络(content-centricnetworking,ccn)。与ip网络不同,内容名称是ccn中的基本元素,它的特征是内容请求包(称为“兴趣”)和内容响应包(称为“数据”)的基本交换。ccn的网络内缓存有助于在车辆的移动性和时断时续的连通性下有效地分发流行内容,从而产生了以内容为中心的车载网络(vehicularcontentcentricnetwork,vccn)。vccn可以在安全应用、流量应用和舒适应用(如文件共享和商业广告)下获得较好的网络性能。
然而,vccn中的机会路由和车辆的移动性导致数据分组可能不会沿着相应兴趣的反向路径返回,而且在动态的环境下很难确定可信的第三方来对内容的分发进行管理,因此ccn的协作缓存架构不能在vccn中直接部署或实现。现有的基于车载网络的协作缓存方案大致可以分为两类,集中式架构和分布式架构。集中式的架构中缓存监测和控制通常由计算和存储资源较多的rsu或更上层的控制服务器负责;分布式的缓存管理允许节点根据自身当前所处的环境和拥有的资源,独立地做出缓存决策。这些方案都根据自身的网络模型特点对基本的缓存策略进行了优化,但仍然存在一些普遍的问题。由于各个车辆根据自身的缓存策略进行缓存决策,这就导致请求次数较多、流行度高的内容会同时被大量车辆缓存,实质上造成了缓存冗余和缓存空间的浪费。同时,考虑到各个节点间的缓存能力不同,系统中缺乏统筹缓存资源的管理者或者相应的管理机制,可能导致缓存负载的不平衡。
技术实现要素:
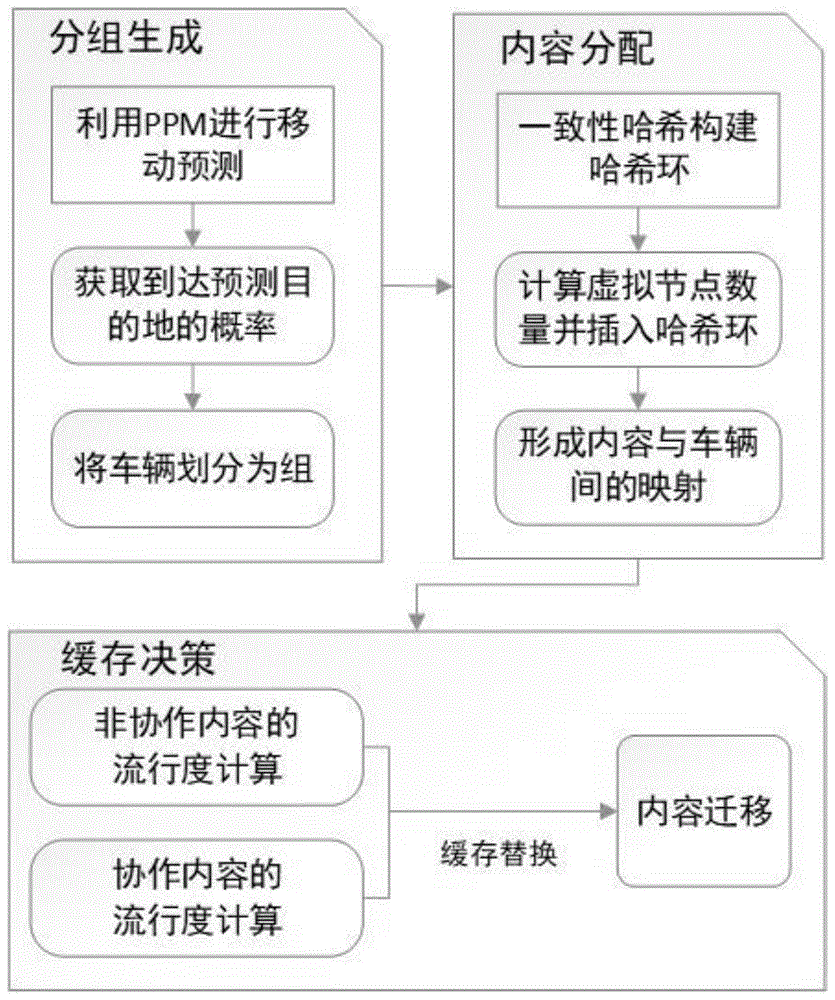
为了有效的提高车载内容中心网络下的缓存系统性能,本发明提出了一种基于一致性哈希的移动感知协作缓存方法。rsu根据车辆的历史移动路径来预测车辆在下一个时间片最有可能到达的位置,再将当前处在同一区块下并且具有相同预测目的地的车辆划分为一组。rsu通过一致性哈希将组内的车辆组成哈希环并加权配置虚拟节点,然后将哈希环广播给各车辆。车辆在接收到内容后根据流行度做出缓存决策,通过一致性哈希映射到当前车辆的内容将会获得额外的流行度加成。最后,车辆会将被替换的内容转发给合适的邻居节点以分摊缓存负载。
本发明的技术方案:
一种车载内容中心网络下基于一致性哈希的移动感知协作缓存方法,步骤如下:
(1)首先在车载网的动态环境下将车辆进行分组,通过移动预测的方式找出具有相同预测目的地的车辆并归为一组,使得分组内的车辆之间具有相对稳定的连接;
分组的生成与调整,具体过程如下:
(1.1)车辆定期向对应的rsu上传自己的路径信息,rsu之间通过有线连接同步信息并利用基于部分匹配的预测(predictionbypartialmatching,ppm)技术,预测每个车辆下一个时间片可能到达的区块的概率,概率最高的区块被选为该车辆的预测目的地;对同一个区块内具有相同预测目的地的车辆,rsu把它们划分为一个组,并将每个组的预测目的地以及车辆和各车辆的预测概率pi广播给各组车辆;rsu周期性地重复上述操作以保证分组的有效性;
(1.2)为了应对两次更新之间出现的异常情况,系统触发式地对分组进行调整;当车辆发现自己连续几个时间片都没有收到任何来自组内其他车辆的信标帧时,或发现自己偏离了预定的行驶路径时,车辆会持续向rsu发出带有“join”标志的信标帧,rsu在收到该信息后会更新该车辆原分组的信息并告知原分组车辆,同时重新对该车辆进行预测并查找是否有合适的组供该车辆加入;一旦找到合适的组,rsu会告知该车辆并向新分组的车辆更新组的信息;加入新的组后,车辆将停止发送“join”信息;
另外,如果一个车辆在周期性的组划分过程中被单独编为一个组,它也会不断发送“join”请求直至rsu帮助它找到一个合适的分组并成功加入;
(2)为了减轻不同车辆对相同内容重复缓存的问题,在分组内将内容均匀分配给不同的车辆,使得每个车辆尽可能缓存不同内容,同时又能在组内快速获取其他内容,达到缓存空间共享的目的;
内容分配的具体过程如下:
(2.1)rsu在对车辆进行分组的同时,将每个车辆的id通过哈希函数映射到0~232-1中的一个整数上,这些整数首尾相连构成一个哈希环;同样,每个内容的名称也被映射到一个整数对应的哈希环上的位点,每个内容从自己所在位点出发,沿哈希环顺时针搜索到的第一个车辆位点,这样就构建出一个内容与车辆的多对一映射,从而实现初步的内容分配;
(2.2)考虑到分组可能出现的车辆变化,尽管一致性哈希解决了所有车辆重新分配内容的问题,但一个车辆离开后原本分配的内容将全部顺延到下个车辆的范围,将导致分配不平衡的问题;同时,不同车辆的移动稳定性和可用缓存空间不同,实际上具备的缓存能力是有差异的;为此,为各个组内的车辆引入不同数量的虚拟节点,这些虚拟节点同样通过哈希函数映射到哈希环上的一个位点,在为一个内容确定对应缓存节点时,如果顺时针搜索到的第一个车辆位点是一个虚拟节点,那么这个内容对应的缓存节点即为这个虚拟节点所对应的车辆;rsu依据各车辆预测概率pi和可用存储空间sai加权设置虚拟节点数量:
其中,
计算并插入虚拟节点后,完整的哈希环得以构成,哈希环作为分组信息会在rsu完成分组后一并广播给组内全体车辆;每个组内车辆都能通过哈希环确定一个内容是否被分配到自身,如果是则该内容称为自己的协作内容,反之则称为非协作内容;
(3)在构成哈希环并建立内容与车辆的映射之后,rsu并不会直接将内容按分配结果推送到各个车辆,一方面是因为内容总数通常较大缓存空间不足以全部存储,另一方面也无法应对实时变化的内容请求分布;在基本的流行度基础上为协作内容添加一个增量,使得协作内容在缓存决策中具有更高的优先级,即更高的概率得到缓存;同时为减轻可能出现的缓存负载不平衡的问题,发生缓存替换时被替换的内容会被转发给一个合适的邻居节点;
缓存决策的具体过程如下:
(3.1)车辆统计收到各个内容的兴趣包数量并记录在对应的计数器cri,根据自身的统计数据计算内容的流行度,周期性地对各个内容的流行度进行更新,同时每次更新时重置cri为0;对于非协作内容,流行度的基本计算公式如下:
其中,ρi为内容ci的流行度,λ为权重常数,为增大最近一个周期的请求次数权重,设0.5<λ<1,avg(cr)是最近一个周期内所有内容请求次数的平均值;
(3.2)对于协作内容,车辆在计算它的流行度时,会在上述流行度基本计算公式的基础上再乘以一个额外的增益常数ε,即:
ρi←ερi
其中,ε∈(1,+∞);通过这个增益,协作内容在进行流行度比较的时候会具有更高的优先级;
(3.3)增益常数的设置以最小化内容获取时延的预期
其中,t1、t2和t3分别为三种获取途径的平均获取时延,可从系统预热阶段的统计数据中计算获得;p1、p2和p3分别为三种情况对应的概率,表示为ε的函数;通过最优化的途径求得最合适的ε使得预期时延最小;
(3.4)在接收到一个未缓存内容时,车辆首先查看自身缓存空间是否有剩余空间,如果有则直接缓存该内容;如果没有足够剩余空间,车辆会判断该内容是否为协作内容,如果是协作内容就会首先为该内容的流行度乘以加成常数,否则流行度保持通常状态;然后该内容会与已缓存内容进行流行度比较,如果低于所有已缓存内容,则该内容会被丢弃,如果存在至少一个流行度低于该内容的已缓存内容,那么流行度最低的内容会被替换而新内容会被缓存;被替换的内容不会被直接丢弃,而是由当前车辆根据邻居相似度、链路地位、移动模式寻找合适的邻居将被替换内容向邻居转发;邻居节点接收到迁移内容后会重复上述判断与操作。
本发明的有益效果:对于车载的移动网络而言,广泛应用于固定拓扑的协作缓存策略不能直接适用于动态拓扑。针对动态环境下链接不稳定的特点,本发明通过移动预测的方式估计车辆可能的移动路线,并将具有相似移动模式的车辆归为一组,使组内车辆之间具有相对稳定的交互能力,一定程度上解决了动态变化的问题。
更进一步,本发明采用一致性哈希对组内内容和车辆的映射关系进行管理,降低了组内节点间缓存重复和冗余的情况;为达到缓存资源的有效利用和负载的均衡,本发明根据车辆不同的情况加入不同数量的虚拟节点。
另外以rsu推送或者预缓存的形式分配内容的方式不能适应内容的流行度的动态变化,本发明通过为协作内容的流行度添加增益的方式实现内容在不同节点的不同赋权,兼顾了缓存的协作需求和流行度的浮动变化,并且可以根据系统的统计数据调整增益的具体数值以实现内容获取时延的最小化;同时,被替换的内容会被推送给合适的邻居节点,从而减轻了缓存过载的不良影响,提升了缓存命中率。
附图说明
图1为本发明所述的协作缓存方法的组织结构图。
图2为本发明所述的车辆移动预测与分组的流程图。
图3为本发明所述的内容分配的流程图。
图4为本发明所述的缓存替换与迁移的流程图。
具体实施方式
为了将本发明的目的,技术方案和优点表达的更清晰明了,接下来将通过实施例和附图,对本发明做进一步的详尽的说明。
一种车载内容中心网络下基于一致性哈希的移动感知协作缓存方法,本方法包括rsu对车辆移动轨迹进行预测并对车辆分组、rsu构建哈希环并为车辆插入不同数量的虚拟节点、车辆计算内容流行度并据此进行缓存决策。
参照图2,rsu对车辆移动轨迹进行预测并对车辆分组的具体运行过程如下:
步骤1.在预热阶段rsu统计各个车辆的历史移动路径。
步骤2.rsu以宽度为3的滑动窗口遍历每个车辆的历史路径信息,为每个车辆构建深度为3的搜索树,树的每个节点记录有一个位置l以及从根节点到当前节点所构成的序列出现过的次数n(sl),其中s代表从根节点到当前节点之间的子序列。
步骤3.每个车辆定期上传自己所在的位置。
步骤4.rsu将车辆的最近两个时间片的位置代入搜索树中计算各个车辆下一个时间片最有可能到达的位置。如果两个连续位置构成的前缀序列s在搜索树中出现过则进行步骤5,否则进行步骤6。
步骤5.在s={l(i-1),l(i)}后到达位置l(i+1)的概率为:
其中,n(sl(i+1))和n(s)分别为序列sl(i+1)和s在历史轨迹记录中出现的次数。
步骤6.如果搜索树中不存在前缀序列s,则只参考前一个位置,按如下方式计算概率:
其中,m代表历史序列中出现过的所有位置的集合,m(l(i))为历史序列中在l(i)前出现过的位置的集合,|m-m(l(i))|为未出现在l(i)前的位置的数量。
步骤7.求得概率最高的位置被设为预测目的地,同时记录预测的概率。
步骤8.rsu将当前处在同一区域并具有相同预测目的地的车辆划分为一组,并将目的地、车辆列表和各车辆的预测概率广播给组内车辆。
步骤9.在两次周期性更新之间,如果车辆长时间没有收到来自组内车辆的信标帧,或者自身偏离了预测的移动路径,车辆会向rsu发送请求加入新的组。rsu在收到请求后会通知原分组的车辆该车辆已离开,然后重复步骤4-8对该车辆进行移动预测并寻找新的分组。
参照图3,rsu在组内进行内容分配的具体运行过程如下:
步骤10.计算各车辆应分配的虚拟节点数量:
其中
步骤11.为各车辆构造虚拟节点标识符,具体方法可以是在原标识符的后面添加数字,如n1,n2,n3等。
步骤12.将车辆和对应虚拟节点的标识符通过哈希函数映射为一个0~232-1的整数,将整数序列首尾相接构成哈希环。
步骤13.将内容的唯一名称用同样的哈希函数映射到哈希环上,然后从内容对应的位置出发顺时针搜索第一个车辆节点或虚拟节点,对应车辆即该内容所分配到的车辆,亦即该内容为对应车辆的协作内容。
步骤14.在每次更新分组信息,包括周期性更新和异常状况更新时,rsu都会重新计算哈希环并将其向对应分组的车辆广播。
参照图4,缓存替换与迁移的具体运行过程如下:
步骤15.预热阶段采集信息并统计从本地、组内、组外获取内容的平均时延t1,t2和t3。
步骤16.假设经过足够长的时间内容完全充满缓存且缓存内容保持稳定,以增益常数ε作为变量表示出协作内容与非协作内容的流行度排序缓存阈值,即协作内容流行度排序超过r1、非协作内容流行度排序超过r1内容就会被缓存。具体推导过程如下:
内容请求频率通常服从zipf分布,即生成流行度为r的内容的请求概率为
令
解得
步骤17.由r1、r2进一步推导出三种内容获取方式的概率p1、p2、p3。能从本地获取的内容包括排名达到r2的全部内容和排名在r1和r2之间的协作内容,即
可以从组内车辆获取的是r1和r2之间的非协作内容,即
剩余的排名低于r1的内容将只能从组外获取,即
步骤18.求得最优增益常数。由上述公式可以推导出内容获取的期望时延
步骤19.每当车辆接收到内容请求时,对应计数器cri会自增1。
步骤20.车辆周期性地更新所有内容的流行度,同时重置cri为0,流行度的计算公式为:
步骤21.当接收到一个未缓存内容ci时,如果有空余缓存空间,那么内容将被直接缓存。
步骤22.如果没有缓存空间,将对内容的流行度进行比较,其中协作内容的流行度将会乘以增益常数ε再进行比较。
步骤23.如果已缓存内容中没有比ci流行度更低的内容,那么ci会被丢弃。
步骤24.如果存在比ci流行度更低的内容,那么已缓存内容中流行度最低的内容cj被替换,ci被缓存。
步骤25.一旦缓存替换发生,车辆会寻找合适的邻居将替换掉的内容转发过去。车辆vi选择vj作为转发对象的概率
prij=α·nsij+β·cnij+γ·pj
其中α、β、γ为权重常数;邻居相似度nsij为两节点邻居集合nli、nlj的交集占nli的比例:
链路地位cnij为两个车辆间链接总时长
其中
- 还没有人留言评论。精彩留言会获得点赞!