一种针对MapReduce计算的数据保密方法及系统与流程
本发明属于云计算数据保密技术领域,尤其涉及一种针对mapreduce计算的数据保密方法及系统。
背景技术:
目前,最接近的现有技术:mapreduce是一种并行编程模型,用于大规模数据集的并行计算,具有函数式编程语言和矢量编程语言的特性,具有数据划分和计算任务调度、系统优化、出错检测和恢复的功能,因此,使得mapreduce适用于日志分析、机器学习、分布排序等应用程序。一个mapreduce作业是一个用户希望被执行的工作单元:它包括输入数据,mapreduce程序和配置信息。mapreduce通过把作业分成tasks(任务)的形式来运行该作业。任务分为map任务(maptask)和reduce任务(reducetask)两种。多reduce任务的标准mapreduce的数据流是由分片、map、reduce等阶段构成。mapreduce中的每个map任务可以细分为4个阶段:recordread(用于数据分割)、map、combine(用于数据聚合,该阶段可省去)、partition(用于数据拆分)。hadoop中的每个reduce任务可以细分为4个阶段:shuffle(混排)、sort(排序)、reduce和outputformat(输出格式)。
hadoop是mapreduce框架的一种实现。它是开发和运行处理大规模数据的软件平台,是apache用java语言实现的开源软件框架,实现由大量计算机组成的集群对海量数据进行分布式计算。hadoop具有高效率、成本低、扩容能力强和可靠性的优点。hadoop的框架最核心的设计就是:hdfs和mapreduce。hdfs为海量的数据提供了存储,而mapreduce则为海量的数据提供了计算。
sgx技术全称intelsoftwareguardextensions,是一组x86-64isa扩展,可以设置受保护的执行环境(称为enclave),除了处理器和用户放置在其包围区内的代码之外,不需要任何信任。一旦软件和数据位于enclave中,即便操作系统或者vmm(hypervisor)也无法影响enclave里面的代码和数据。enclave的安全边界只包含cpu和它自身。enclave受到处理器的保护:处理器控制对enclave内存的访问。试图从enclave外部读取或写入正在运行的enclave的存储器的指令都将失败。enclave缓存行在写入内存(ram)之前经过加密和完整性保护。可以通过类似于intelx86架构中的一种callgate调用机制从不受信任的代码调用enclave代码,该机制将控制转移到enclave内的用户定义的入口点。sgx支持远程认证,它使远程系统能够以加密方式验证特定软件是否已在安全区enclave内加载,并建立端到端的加密通道共享机密。
云计算是网格计算、分布式处理、并行处理的发展,可看作是这些计算机科学概念上的商业服务模式的实现,是一片用于计算的、能提供超大规模计算资源的服务器集群。作为基于网络计算的商业服务模式,云计算的用户可以按自己需求获取存储空间、计算能力、软件服务等,将计算任务分布在由大量计算机构成的资源池,使得用户的计算能力不再受自身的资源限制,而将负载较大的计算任务外包给云以完成高代价的计算。
虽然云计算具有虚拟化、按需服务、高可扩展性等较多优点,但用户将应用、数据等放于云端服务器,必然会面临一定的风险,可以预料到依赖云计算提供商来处理敏感数据将带来隐私泄露的风险。云服务提供商的可信性问题将严重影响用户对云服务的有效使用。
使用公共云基础设施来存储和处理大型数据集引发了新的安全问题。当前的解决方案建议加密所有数据,并且仅在安全硬件内以明文访问它。例如微软公司研究的vc3系统,该系统依靠sgx保护本地map任务和reduce任务的运行,可以调整流行的hadoop框架保证完整性和保密性。所有数据都经过系统aes-gcm加密。
即使是在用安全环境保护的vc3系统中,大量数据的分布式处理仍然涉及不同处理和网络存储单元之间密集的加密通信,并且这些通信模式可能泄漏敏感信息。仅保护分布式计算的各个单元(例如,map和reduce单元),不可避免的暴露给攻击者了几个重要信息的泄漏通道。map和reduce作业的数据量对云提供者是可见的,并且在较小程度上对其他用户可见,观察和关联每个map和每个reduce之间交换的一系列中间键值对,由数据量大小可以学习到敏感信息。
对于以上问题,在微软的研究论文olga等人的observingandpreventingleakageinmapreduce中提出了两种方案,shuffle-in-the-middle方案,通过安全的将所有map生成交给所有reduce使用的所有键值对进行改组操作来阻止对作业的中间流量分析。但是,攻击者仍然会观察每个map任务生成的记录数、reduce任务接收的记录数以及他们之间关联分布情况,效率低下。shuffle&balance方案,将此预处理拆分为离线和在线阶段,离线阶段随机化输入记录的顺序,保证所有map任务产生相同的键值对分布。在线阶段对输入数据采样,收集map生成的键值对的统计信息,用于在reduce之间平衡,并概率估计每个mapper发送给每个reduce的键值对数量的上限,从而实现将每个map任务发送的中间流量均匀分配到每个reduce任务,以来满足更高的安全定义。但实际上该方案离线阶段随机化输入记录的顺序,使得大小相同的两组输入数据集在运行过程中最大key值分布值相等。这个随机化记录的过程耗时会导致线下效率低下,且安全性仍然有不足,比如该方案会泄露相关数据集信息(最大key值)。
综上所述,现有技术存在的问题是:
1.现有方案对实验数据集运行记录要求相比很苛刻,这也导致了现有技术解决问题的适用性不高。
2.现有方案相比标准mapreduce框架而言具有较高的性能开销,例如shuffle-in-the-middle方案会造成191%到205%的性能开销,shuffle&balance方案在线上阶段会造成95%到101%的性能开销。
3.现有方案只支持默认partition函数,而不支持用户自定义的混洗函数。
4.现有方案成功的前提是对于输入数据的准确概率估计,一旦估计不准确,那么将会导致方案的失败以及不必要的高性能开销。
解决上述技术问题的难度:在保证mapreduce运行安全可靠的前提下,最大限度的避免数据集敏感信息的泄露以及提高方案的适用性,同时达到很好的性能提升。必须均衡安全性和性能之间的最佳关系,达到方案的最优化效果,这同时也是设计的难点与挑战。
解决上述技术问题的意义:通过解决上诉技术问题,可以在原有mapreduce框架下更好的保护中间数据流隐私,抵制不可信公共云中mapreduce框架中基于中间数据流的边信道攻击,在这一前提下最优化性能开销,以不影响云环境中分布式计算的高效率的特征,提出的一种新型系统方法。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种针对mapreduce计算的数据保密方法及系统。
本发明是这样实现的,一种针对mapreduce计算的数据保密方法,所述针对mapreduce计算的数据保密方法包括以下步骤:
第一步,在标准mapreduce计算框架下提出两种新型数据混洗方案:fullshuffle和safeshuffle;在mapping阶段层定义三个新型子阶段:map阶段、combine阶段以及partition阶段,在reducing阶段层定义reduce子阶段;
第二步,在mapreduce的mapping阶段层的map子阶段中,系统将输入数据整理为key-value键值对的形式进行预处理;
第三步,通过combine阶段,将map子阶段每一个map任务中的键值对根据key值进行合并,并通过预先的数据集key值种类数目添加假键值对到该值,以使每一个map任务输出的数据量大小相等,或者,在前述基础上添加混淆键值对,以使隐藏真实数据集key值种类数目;
第四步,partition子阶段的partition函数会将合并后的键值对分别分发给reducing阶段层的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;
第五步,对reduce子阶段的每个reduce任务接受到的数据进行处理,丢弃所有假键值对、混淆键值对以及不属于reduce子阶段各个reduce任务合并的键值对数据;
第六步,在reduce子阶段每个reduce任务的最后输出存储dfs阶段(cleanup函数),根据数据集key值种类数目再次添加混淆键值对,以使每个reduce任务输出的数据大小相等。
进一步,所述第二步具体包括:mapreduce的mapping阶段层的map子阶段中,map主函数将输入的数据整理为t=(t.key,t.value)键值对的格式进行预处理;其中输入的数据将会均匀地分配给每一个map任务,即每个map任务会有|d|/m大小的数据输入,对于输入的数据先解密,然后通过map_function按行读取成中间键值对<k,v>的形式;其中输入数据集用|d|表示,|.|表示对数据加密处理后的大小,m表示map任务数量,map_function为每个map任务中的map主函数。
进一步,所述第三步具体包括:在每个map任务中部署combiner_function,当map_function生成输出加密键值对|t|时,combiner_function会先进行解密,然后利用reduce_function合并拥有相同key值的键值对;其中reduce_function为每个reduce任务中的reduce主函数,combiner_function为combine子阶段的主函数;作为结果,每一个map任务中会生成合并的键值对组,其中每一个键值对的key值都是独一无二的,用键值对格式(kauthentic,vauthentic)称该键值对组为可信键值对组;
一个map任务mapi产生了可信键值对组tm={<k1,v1>,…,<k|tm|,v|tm|>},当|tm|<k,m将会生成dm=k-|tm|个假键值对<kd1,vd1>,…,<kddm,vddm>;其中mapi∈{map1,…,mapm},任务下标mu(1,m),k为原始数据集中key的种类数量,|tm|为可信键值对组中键值对的数量;生成的假键值对的格式为(kdummy,vdummy),其中kdummy和vdummy是预先设定好的带有标记的虚拟假值;最后在partition子阶段,每个map任务中将会有|tm|个可信键值对以及dm个假键值对,<k1,v1>,…,<kk,vk>,被加密分发给reduce子阶段的每个reduce任务;添加一定数量的混淆键值对<kf1,vf1>,…,<kfk’,vfk’>,以使隐藏真实数据集key值种类数目k;其中混淆键值对的数量用k’表示,键值对格式同样使用带有特殊标记的虚拟值(kfake,vfake)表示;最后在partition子阶段,每个map任务中将会有|tm|个可信键值对、dm个假键值对以及k’个混淆键值对,<k1,v1>,…,<kk+k’,vk+k’>,被加密分发给reduce子阶段的每个reduce任务。
进一步,所述第四步具体包括:partition子阶段的partition函数会将合并后的键值对分别分发给reduce子阶段的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;在partition子阶段的partition函数中,先对每一个加密键值对|t|=<t.key,t.value>解密,之后通过全分配函数full_partition_function来进行完全分配键值对t;其中对于每个键值对t来说都会执行r次full_partition_function,从而依次生成full_partition_function(t.key)=r(1,2,...,r)的分配规则;令reduce子阶段中的reduce任务为reducej∈{reduce1,…,reducer},对于fullshuffle方案,每个任务reducej都会接收到k=dm+|tm|个加密键值对,其中包括可信键值对组(kauthentic,vauthentic)和假键值对(kdummy,vdummy),或者对于safeshuffle方案将接收到k+k’个加密键值对,包括可信键值对组(kauthentic,vauthentic)、假键值对(kdummy,vdummy)以及混淆键值对(kfake,vfake)。
进一步,所述第五步具体包括:通过partition子阶段的partition函数,reduce子阶段的每个reducej任务将会接收到各个mapi任务传来的加密键值对组{|t|i},先解密键值对|t|,对于得到的每一个键值对t=(t.key,t.value)进行判断;如果t.key=kdummy或者t.key=kfake,那么任务reducej将会丢弃这些键值对,在每一个任务reducej的主函数reduce_function中,通过引用用户自定义的分配函数user_partition_function来处理可信键值对;如果user_partition_function(t.key)=j,则保留该键值对,否则丢弃该键值对;其中对于reducej任务下标r,函数user_partition_function(t.key)=ru(1,r),通过判断r与当前reduce任务j的值来确定键值对的取舍;之后保留的键值对会依次通过reduce任务主函数reduce_function的处理,将拥有相同key值的键值对进行分组合并,作为结果,每个reducej任务中将会生成一组key值唯一的键值对集合,称为可信键值对组tm,标记为(kauthentic,vauthentic)。
进一步,所述第六步具体包括:对于fullshuffle方案而言,每个reducej任务生成的可信键值对组tm,当其数量|tm|<k时,r将会生成dr=k-|tm|个假键值对<kd1,vd1>,…,<kddr,vddr>;其中任务下标ru(1,r),k为原始数据集中key的种类数量,|tm|为可信键值对组中键值对的数量;生成的假键值对的格式为(kdummy,vdummy),其中kdummy和vdummy是预先设定好的带有标记的虚拟假值;最后在存储dfs阶段,每个reduce任务中将会有|tm|个可信键值对以及dr个假键值对,即<k1,v1>,…,<kk,vk>,被加密存储到dfs中;
对于safeshuffle方案而言,每个reducej任务生成的可信键值对组tm,当其数量|tm|<k时,r将会生成dr=k+k’-|tm|个假键值对<kd1,vd1>,…,<kddr,vddr>;其中任务下标ru(1,r),k为原始数据集中key的种类数量,|tm|为可信键值对组中键值对的数量;生成的假键值对的格式为(kdummy,vdummy),其中kdummy和vdummy是预先设定好的带有标记的虚拟假值;最后在存储dfs阶段,每个reduce任务中将会有|tm|个可信键值对以及dr个假键值对,<k1,v1>,…,<kk+k’,vk+k’>,被加密存储到dfs中。
本发明的另一目的在于提供一种实施所述针对mapreduce计算的数据保密方法的针对mapreduce计算的数据保密系统,所述针对mapreduce计算的数据保密系统包括:
map子阶段处理模块,用于在mapreduce的mapping阶段层的map子阶段中,系统将输入数据整理为key-value键值对的形式进行预处理;
combine子阶段处理模块,用于将map子阶段每一个map任务中的键值对根据key值进行合并,并通过预先的数据集key值种类数目添加假键值对到该值,以使每一个map任务输出的数据量大小相等,或者,在前述基础上添加混淆键值对,以使隐藏真实数据集key值种类数目;
partition子阶段处理模块,用于partition子阶段的partition函数将合并后的键值对分别分发给reducing阶段层的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;
reduce子阶段处理模块4,用于对reduce子阶段的每个reduce任务接受到的数据进行处理,丢弃所有假键值对、混淆键值对以及不属于reduce子阶段各个reduce任务合并的键值对数据;
reduce子阶段末处理模块,用于在reduce子阶段每个reduce任务的最后输出存储dfs阶段(cleanup函数),根据数据集key值种类数目再次添加混淆键值对,以使每个reduce任务输出的数据大小相等。
本发明的另一目的在于提供一种实现所述针对mapreduce计算的数据保密方法的信息数据处理终端。
本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的针对mapreduce计算的数据保密方法。
本发明的另一目的在于提供一种应用所述针对mapreduce计算的数据保密方法的云计算数据保密系统。
综上所述,本发明的优点及积极效果为:本发明在标准mapreduce计算框架下提出两种新型数据混洗方案:fullshuffle和safeshuffle;在mapping阶段层定义三个新型子阶段:map阶段、combine阶段以及partition阶段,在reducing阶段层定义reduce子阶段;在所述mapreduce的mapping阶段层的map子阶段中,系统将输入数据整理为key-value键值对的形式进行预处理;通过combine阶段,将map子阶段每一个map任务中的键值对根据key值进行合并,并通过预先的数据集key值种类数目添加假键值对到该值,以使每一个map任务输出的数据量大小相等,或者,在前述基础上添加混淆键值对,以使隐藏真实数据集key值种类;partition阶段的partition函数会将合并后的键值对分别分发给reducing阶段层的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;对reduce子阶段的每个reduce任务接受到的数据进行处理,丢弃所有假键值对、混淆键值对以及不属于reduce子阶段各个reduce任务合并的键值对数据;在reduce子阶段每个reduce任务的最后输出存储dfs阶段(cleanup函数),根据数据集key值种类数目再次添加混淆键值对,以使每个reduce任务输出的数据大小相等。本发明能够对在云计算平台中的用户作业运行中的数据进行数据保密。
与现有技术相比,本发明具有如下有益效果:
(1)本发明一种针对mapreduce计算的数据保密方法及系统,在partition函数中写入特定的全分配函数,该分配将map任务中数据全分给reduce任务,所有map任务输出数据的量和大小相等,并且里面包含着假数据来混淆数量,使得数据量大小与输入数据统计学分布关系不明确,使攻击方不能通过跟踪每个map任务到reduce任务的流量来推测数据,即攻击者通过观察输入无法分辨相同数据大小的输入的输出对应关系,从而实现map输出的不可分辨性。
(2)本发明一种针对mapreduce计算的数据保密方法及系统,每个reduce任务接收以及输出存储的数据量大小相等,不具有统计后推测意义,防止攻击者多次使用不同数据跟踪map任务到reduce任务的对应关系,从而实现reduce输入的不可分辨性。
本发明保护了远程执行环境场景下基于mapreduce框架的数据和隐私,避免了应用程序的数据隐私被恶意观察者通过边信道攻击获取。
附图说明
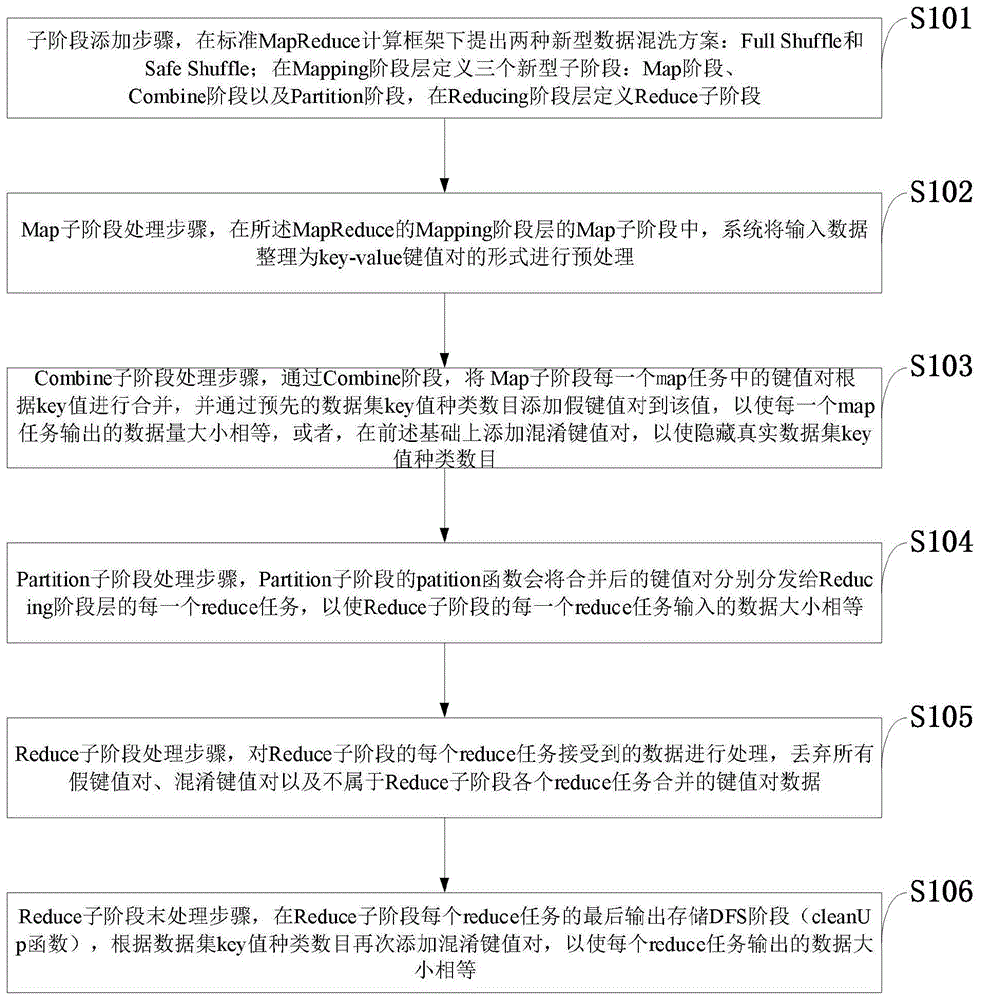
图1是本发明实施例提供的针对mapreduce计算的数据保密方法流程图。
图2是本发明实施例提供的针对mapreduce计算的数据保密系统的结构示意图;
图中:1、map子阶段处理模块;2、combine子阶段处理模块;3、partition子阶段处理模块;4、reduce子阶段处理模块;5、reduce子阶段末处理模块。
图3是本发明实施例提供的原始mapreduce框架图。
图4是本发明实施例提供的方案一fullshuffle方案图。
图5是本发明实施例提供的方案二safeshuffle方案图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
针对现有技术存在的问题,本发明提供了一种针对mapreduce计算的数据保密方法及系统,下面结合附图对本发明作详细的描述。
如图1所示,本发明实施例提供的针对mapreduce计算的数据保密方法包括以下步骤:
s101,子阶段添加步骤,在标准mapreduce计算框架下提出两种新型数据混洗方案:fullshuffle和safeshuffle;在mapping阶段层定义三个新型子阶段:map阶段、combine阶段以及partition阶段,在reducing阶段层定义reduce子阶段;
s102,map子阶段处理步骤,在所述mapreduce的mapping阶段层的map子阶段中,系统将输入数据整理为key-value键值对的形式进行预处理;
s103,combine子阶段处理步骤,通过combine阶段,将map子阶段每一个map任务中的键值对根据key值进行合并,并通过预先的数据集key值种类数目添加假键值对到该值,以使每一个map任务输出的数据量大小相等,或者,在前述基础上添加混淆键值对,以使隐藏真实数据集key值种类数目;
s104,partition子阶段处理步骤,partition子阶段的partition函数会将合并后的键值对分别分发给reducing阶段层的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;
s105,reduce子阶段处理步骤,对reduce子阶段的每个reduce任务接受到的数据进行处理,丢弃所有假键值对、混淆键值对以及不属于reduce子阶段各个reduce任务合并的键值对数据;
s106,reduce子阶段末处理步骤,在reduce子阶段每个reduce任务的最后输出存储dfs阶段(cleanup函数),根据数据集key值种类数目再次添加混淆键值对,以使每个reduce任务输出的数据大小相等。
如图2所示,本发明实施例提供的针对mapreduce计算的数据保密系统包括:
map子阶段处理模块1,用于在所述mapreduce的mapping阶段层的map子阶段中,系统将输入数据整理为key-value键值对的形式进行预处理;
combine子阶段处理模块2,用于将map子阶段每一个map任务中的键值对根据key值进行合并,并通过预先的数据集key值种类数目添加假键值对到该值,以使每一个map任务输出的数据量大小相等,或者,在前述基础上添加混淆键值对,以使隐藏真实数据集key值种类数目;
partition子阶段处理模块3,用于partition子阶段的partition函数将合并后的键值对分别分发给reducing阶段层的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;
reduce子阶段处理模块4,用于对reduce子阶段的每个reduce任务接受到的数据进行处理,丢弃所有假键值对、混淆键值对以及不属于reduce子阶段各个reduce任务合并的键值对数据;
reduce子阶段末处理模块5,用于在reduce子阶段每个reduce任务的最后输出存储dfs阶段(cleanup函数),根据数据集key值种类数目再次添加混淆键值对,以使每个reduce任务输出的数据大小相等。
下面结合附图对本发明的技术方案作进一步的描述。
本发明具体实施时,使用本发明方法进行mapreduce计算的数据保密之前,需要对mapreduce的数据进行加密操作。具体的,数据加密建立在mapreduce框架运行在安全的执行环境的基础上。所述安全的执行环境具体实施中可采用可信执行环境(trustedexecutionenvironment(tee))技术,如intelsgx。mapreduce通常把job(作业)分解成tasks(任务,分为map任务(maptask)和reduce任务(reducetask)两种),由集群中的节点分别运行。本发明将每个任务部署在可信执行环境中进行执行,因此实现任务运行时保密,但数据在不同任务之间进行传输时仍需保护。本发明对任务间数据进行加密传输。
由于安全执行环境中仅包含mapreduce中每个task处理数据的代码,例如标准mapreduce的map任务和reduce任务,而其余的hadoop分布式基础架构则不需要信任,加密处理后数据的明文不会在运行阶段被攻击方直接获取。
尽管对数据进行加密操作后能够保证数据明文不会在运行阶段被攻击方直接获取和修改。但上述处理后,恶意观察者仍然可以记录加密数据的交换,例如mapreduce系统中每个节点之间的数据交换(网络流量分析)或每个节点和存储之间的数据交换(存储流量分析),交换的数据量包括字节、页、分组或记录等。观察者在先验统计学知识上得到输入数据的统计学分布,从而通过观察map任务与reduce任务之间的流量进行分析,得到数据中的敏感信息,导致隐私泄露。
本发明的数据保密方法将从map任务输入输出的不可分辨性和reduce任务输入输出的不可分辨性四方面对数据进行保密:map任务输入的不可分辨性:在job任务的预处理阶段,原始数据集大小会被平均分割m份大小相等的样本数据集,这些数据集样本会分别发送到m个不同的map任务中进行处理,是的每一个map任务的输入数据的量和大小相同,防止攻击者观察到存储单元dfs到每一个map任务的对应关系。
map任务输出的不可分辨性:在partition函数中写入特定的全分配函数,该分配将map任务中数据平均分给reduce任务,所有map任务输出数据的量和大小相等,使得数据量大小与输入数据统计学分布关系不明确,使攻击方不能通过跟踪每个map任务到reduce任务的流量来推测数据,即攻击者通过观察输入无法分辨相同数据大小的输入的输出对应关系。
reduce任务输入的不可分辨性:每个reduce任务接收的数据量大小相等,不具有统计后推测意义,防止攻击者多次使用不同数据跟踪map任务到reduce任务的对应关系。
reduce任务输出的不可分辨性:在每一个reduce任务的cleanup函数中写入特定规则的存储函数,该规则将每一个reduce任务的输出量和大小与每一个map任务的输出量和大小统一,使攻击方不能通过跟踪每个reduce任务到dfs的流量来推测数据的固有特征。
具体的,为实现从map任务输入输出的不可分辨性和reduce任务输入输出的不可分辨性四方面对数据进行保密,本发明将通过如下两种实施方式实现。
实施例1
如图4所示,对比标准mapreduce过程(如图3,标准mapreduce框架),本实施方式主要在在mapping阶段层定义三个新型子阶段:map阶段、combine阶段以及partition阶段,在reducing阶段层定义reduce子阶段。该方案符合map任务输入输出的不可分辨性,符合reduce端输入输出不可分辨的每个reduce任务接收以及存储的数据量大小相等。
设用户提交作业所使用的数据集输入为d,|d|表示输入数据大小,|.|表示对数据加密处理后的大小,m表示map任务的数量,r表示reduce任务的数量,map_function为每个map任务中的map主函数,reduce_function为每个reduce任务中的reduce主函数,用户自定义的分配函数user_partition_function以及全分配函数full_partition_function,combiner_function为combine子阶段的主函数。如下分别对map子阶段的处理、combine子阶段的处理、partition自己段的处理和reduce子阶段的处理方法进行说明。
map子阶段:map主函数map_function将输入的数据整理为t=(t.key,t.value)键值对的格式进行预处理,其中输入的数据将会均匀地分配给每一个map任务,即每个map任务会有|d|/m大小的数据输入,对于输入的数据先解密,然后通过map_function按行读取成中间键值对<k,v>的形式
combine子阶段:在每个map任务中部署combiner_function,当map_function生成输出加密键值对|t|时,combiner_function会先进行解密,然后利用reduce_function来合并拥有相同key值的键值对,作为结果,每一个map任务中会生成合并的键值对组,其中每一个键值对的key值都是独一无二的,本发明用键值对格式(kauthentic,vauthentic)称该键值对组为可信键值对组。假设一个map任务mapi产生了可信键值对组tm={<k1,v1>,…,<k|tm|,v|tm|>},当|tm|<k,m将会生成dm=k-|tm|个假键值对<kd1,vd1>,…,<kddm,vddm>;其中mapi∈{map1,…,mapm},任务下标mu(1,m),k为原始数据集中key的种类数量,|tm|为可信键值对组中键值对的数量;生成的假键值对的格式为(kdummy,vdummy),其中kdummy和vdummy是预先设定好的带有标记的虚拟假值;最后在partition子阶段,每个map任务中将会有|tm|个可信键值对以及dm个假键值对,即<k1,v1>,…,<kk,vk>,被加密分发给reduce子阶段的每个reduce任务,本发明称以上方案为fullshuffle。
partition子阶段:partition函数会将合并后的键值对分别分发给reduce子阶段的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;在partition子阶段的partition函数中,先对每一个加密键值对|t|=<t.key,t.value>解密,之后通过全分配函数full_partition_function来进行完全分配键值对t;其中对于每个键值对t来说都会执行r次full_partition_function,从而依次生成full_partition_function(t.key)=r(1,2,...,r)的分配规则;令reduce子阶段中的reduce任务为reducej∈{reduce1,…,reducer},对于该方案,每个任务reducej都会接收到k=dm+|tm|个加密键值对,其中包括可信键值对组(kauthentic,vauthentic)和假键值对(kdummy,vdummy)。
reduce子阶段:通过partition子阶段的partition函数,reduce子阶段的每个reducej任务将会接收到各个mapi任务传来的加密键值对组{|t|i},先解密键值对|t|,对于得到的每一个键值对t=(t.key,t.value)进行判断;如果t.key=kfake,那么任务reducej将会丢弃这些键值对,在每一个任务reducej的主函数reduce_function中,本发明通过引用用户自定义的分配函数user_partition_function来处理可信键值对;如果user_partition_function(t.key)=j,则保留该键值对,否则丢弃该键值对;其中对于reducej任务下标r,函数user_partition_function(t.key)=ru(1,r),通过判断r与当前reduce任务j的值来确定键值对的取舍;之后保留的键值对会依次通过reduce任务主函数reduce_function的处理,将拥有相同key值的键值对进行分组合并,作为结果,每个reducej任务中将会生成一组key值唯一的键值对集合,本发明同样将其称为可信键值对组tm,标记为(kauthentic,vauthentic)。
reduce子阶段末:对于该方案而言,每个reducej任务生成的可信键值对组tm,当其数量|tm|<k时,r将会生成dr=k-|tm|个假键值对<kd1,vd1>,…,<kddr,vddr>;其中任务下标ru(1,r),k为原始数据集中key的种类数量,|tm|为可信键值对组中键值对的数量;生成的假键值对的格式为(kdummy,vdummy),其中kdummy和vdummy是预先设定好的带有标记的虚拟假值;最后在存储dfs阶段,每个reduce任务中将会有|tm|个可信键值对以及dr个假键值对,即<k1,v1>,…,<kk,vk>,被加密存储到dfs中。
具体的,本实施方式在实际中可以以一个标准的job(一个mapreduce任务称为job)实现。本实施方式利用均匀传输的方式来保密了数据,。在两个已知k种类数、大小相同的不同数据集运行该方案上时,map任务的输入输出、reduce任务的输入输出这几个会被观察者监视的过程中流量均相等。
实施例2
本实施方式利用加入假数据的方式来实现数据保密,同时对key值的种类数k进行保护。本实施方式对mapreduce改写后符合map任务输入输出的不可分辨性,符合reduce端输入输出不可分辨的每个reduce任务接收的数据量大小相等。
如图5所示,对比标准mapreduce过程(如图3,标准mapreduce框架),本实施方式主要在在mapping阶段层定义三个新型子阶段:map阶段、combine阶段以及partition阶段,在reducing阶段层定义reduce子阶段。该方案符合map任务输入输出的不可分辨性,符合reduce端输入输出不可分辨的每个reduce任务接收以及存储的数据量大小相等。
设用户提交作业所使用的数据集输入为d,|d|表示输入数据大小,|.|表示对数据加密处理后的大小,m表示map任务的数量,r表示reduce任务的数量,map_function为每个map任务中的map主函数,reduce_function为每个reduce任务中的reduce主函数,用户自定义的分配函数user_partition_function以及全分配函数full_partition_function,combiner_function为combine子阶段的主函数。如下分别对map子阶段的处理、combine子阶段的处理、partition自己段的处理和reduce子阶段的处理方法进行说明。
map子阶段:map主函数map_function将输入的数据整理为t=(t.key,t.value)键值对的格式进行预处理,其中输入的数据将会均匀地分配给每一个map任务,即每个map任务会有|d|/m大小的数据输入,对于输入的数据先解密,然后通过map_function按行读取成中间键值对<k,v>的形式
combine子阶段:在每个map任务中部署combiner_function,当map_function生成输出加密键值对|t|时,combiner_function会先进行解密,然后利用reduce_function来合并拥有相同key值的键值对,作为结果,每一个map任务中会生成合并的键值对组,其中每一个键值对的key值都是独一无二的,本发明用键值对格式(kauthentic,vauthentic)称该键值对组为可信键值对组。特别地,为了安全性考虑,该方案可以在fullshuffle方案基础上再添加一定数量的混淆键值对<kf1,vf1>,…,<kfk’,vfk’>,以使隐藏真实数据集key值种类数目k;其中混淆键值对的数量用k’表示,键值对格式同样使用带有特殊标记的虚拟值(kfake,vfake)表示;最后在partition子阶段,每个map任务中将会有|tm|个可信键值对、dm个假键值对以及k’个混淆键值对,即<k1,v1>,…,<kk+k’,vk+k’>,被加密分发给reduce子阶段的每个reduce任务,本发明称以上方案为safeshuffle。
partition子阶段:partition函数会将合并后的键值对分别分发给reduce子阶段的每一个reduce任务,以使reduce子阶段的每一个reduce任务输入的数据大小相等;在partition子阶段的partition函数中,先对每一个加密键值对|t|=<t.key,t.value>解密,之后通过全分配函数full_partition_function来进行完全分配键值对t;其中对于每个键值对t来说都会执行r次full_partition_function,从而依次生成full_partition_function(t.key)=r(1,2,...,r)的分配规则;令reduce子阶段中的reduce任务为reducej∈{reduce1,…,reducer},对于该方案,每个任务reducej都会接收到k+k’(k=dm+|tm|)个加密键值对,包括可信键值对组(kauthentic,vauthentic)、假键值对(kdummy,vdummy)以及混淆键值对(kfake,vfake)。
reduce子阶段:通过partition子阶段的partition函数,reduce子阶段的每个reducej任务将会接收到各个mapi任务传来的加密键值对组{|t|i},先解密键值对|t|,对于得到的每一个键值对t=(t.key,t.value)进行判断;如果t.key=kdummy或者t.key=kfake,那么任务reducej将会丢弃这些键值对,在每一个任务reducej的主函数reduce_function中,本发明通过引用用户自定义的分配函数user_partition_function来处理可信键值对;如果user_partition_function(t.key)=j,则保留该键值对,否则丢弃该键值对;其中对于reducej任务下标r,函数user_partition_function(t.key)=ru(1,r),通过判断r与当前reduce任务j的值来确定键值对的取舍;之后保留的键值对会依次通过reduce任务主函数reduce_function的处理,将拥有相同key值的键值对进行分组合并,作为结果,每个reducej任务中将会生成一组key值唯一的键值对集合,本发明同样将其称为可信键值对组tm,标记为(kauthentic,vauthentic)。
reduce子阶段末:对于该方案而言,当其数量|tm|<k时,r将会生成dr=k+k’-|tm|个假键值对<kd1,vd1>,…,<kddr,vddr>;其中任务下标ru(1,r),k为原始数据集中key的种类数量,|tm|为可信键值对组中键值对的数量;生成的假键值对的格式为(kdummy,vdummy),其中kdummy和vdummy是预先设定好的带有标记的虚拟假值;最后在存储dfs阶段,每个reduce任务中将会有|tm|个可信键值对以及dr个假键值对,即<k1,v1>,…,<kk+k’,vk+k’>,被加密存储到dfs中。
本实施方式也是以一个标准的job实现。job保留完整的mapreduce过程,job2的map只是简单的复制过程,该方案利用在map任务与reduce任务传输过程中加入假数据来实现数据保密,保护了不同key数量不被泄露。在两个大小相同的不同数据集运行该方案上时,map任务的输入输出,reduce任务的输入输出依旧是完全相等的。在本实施方式中,加入混淆假数据为常量k′,其与原始真实数据在自定义的partition函数中可以得到很好的分配,使得map任务到reduce任务的每一条路径上的流量都相等。
下面结合实验对本发明的技术效果作详细的描述。
实验结果表明,本发明的方案产生了有限的性能开销,有时甚至比标准的mapreduce运行还要快:对于所有试验任务,fullshuffle方案比标准mapreduce方案快2.5%,当混淆键值对添加数目为8,16,32时,safeshuffle方案分别比标准mapreduce方案快0.8%,慢4.9%以及慢11.6%。相比于shuffle-in-the-middle方案和shuffle&balance方案,性能分别提升了212.7%、107.5%。
应当注意,本发明的实施方式可以通过硬件、软件或者软件和硬件的结合来实现。硬件部分可以利用专用逻辑来实现;软件部分可以存储在存储器中,由适当的指令执行系统,例如微处理器或者专用设计硬件来执行。本领域的普通技术人员可以理解上述的设备和方法可以使用计算机可执行指令和/或包含在处理器控制代码中来实现,例如在诸如磁盘、cd或dvd-rom的载体介质、诸如只读存储器(固件)的可编程的存储器或者诸如光学或电子信号载体的数据载体上提供了这样的代码。本发明的设备及其模块可以由诸如超大规模集成电路或门阵列、诸如逻辑芯片、晶体管等的半导体、或者诸如现场可编程门阵列、可编程逻辑设备等的可编程硬件设备的硬件电路实现,也可以用由各种类型的处理器执行的软件实现,也可以由上述硬件电路和软件的结合例如固件来实现。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!