基于视觉显著性的HEVC优化算法的制作方法
本发明涉及视频处理
技术领域:
,更具体的说是涉及一种基于视觉显著性的hevc优化算法。
背景技术:
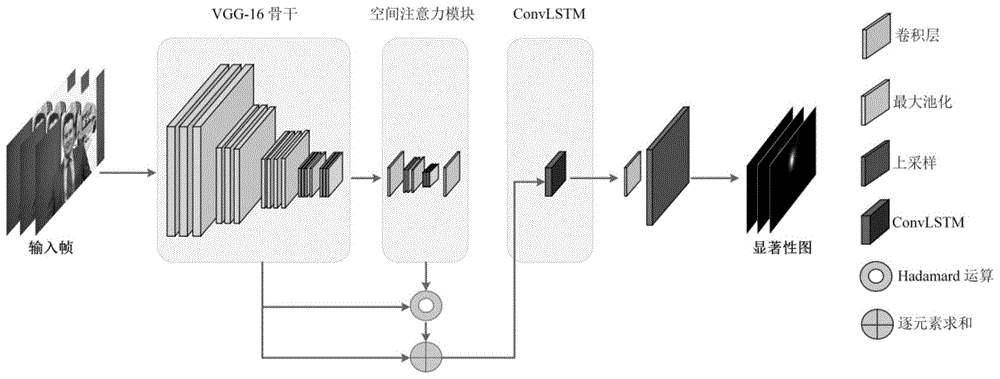
:随着超高清晰度电视、数字电视、智能手机、网络直播等的出现,越来越多的高清、超高清视频在流媒体上传输和存贮,而这些高清视频的数据量是庞大的,因此,发展视频压缩标准减少视频的容量是必要的,基于这些需求,高效视频编码作为先进的视频编码标准产生。高效视频编码(hevc)相对于现有标准,可显著提高压缩性能。它通过减少视频中的统计冗余和少量的感知冗余来实现视频的高效压缩。在统计冗余方面,其在帧内预测和帧间预测采用了更加复杂的编码模式,结合熵编码实现对过去标准的极大改进,在感知冗余方面,其通过色度亚采样,去块滤波等方法实现了一定的减少。然而,hevc也带来了相当大的编码复杂度,同时,使用传统技术以减少统计冗余为核心进一步提升视频压缩性能是困难的。最近,对人类视觉系统(hvs)的研究发现,人眼仅仅关注一个很小视角范围的物体,对于视野外的场景察觉是模糊的,这种人眼的特性被称为视觉显著性,其并未应用于现有的视频压缩标准,合理使用人眼的视觉特性可进一步减少视频中的感知冗余同时提升视频的感知质量。因此,如何提供一种利用人眼感知特性从而提高视频的压缩质量和降低编码码率的hevc优化算法是本领域技术人员亟需解决的问题。技术实现要素:有鉴于此,本发明提供了一种基于视觉显著性的hevc优化算法,首先,建立了一个高清无损eye-tracking数据集,用以推动感知高清视频压缩的研究;在视频显著性部分,利用深度学习在图像处理中的优异性能,使用空间注意力增强的vgg-16网络提取视频帧的静态特征,随后通过convlstm处理视频长范围的时域信息进行高精度的视频显著性检测;从而使用感知显著性的率失真优化,可以去除更多的主观视觉感知冗余,提升了视频压缩效果,同时降低了视频压缩时间,进而使用感知显著性的qp选择算法,视频压缩效果得到进一步提升,能够有效提升视频的感知质量,在质量不变时显著降低视频码率,同时减少压缩时间。为了实现上述目的,本发明提供如下技术方案:一种基于视觉显著性的hevc优化算法,包括以下步骤:基于神经网络提取静态图像特征,输出所述静态图像特征的空间重要性权重,加权后的静态图像特征学习时域特征进行视频显著性检测,得到视频显著性图。通过显著性图计算各个cu块的显著性值,进而使用感知显著性的率失真优化算法进行模式选择,最后通过显著性动态调整cu的qp值,进行不同区域不同的量化策略,得到满足高显著性区域高质量的优化目标。优选的,在上述的一种基于视觉显著性的hevc优化算法中,显著性预测的具体步骤:输入原始特征图,采用vgg-16网络作为骨干提取静态图像特征,采用空间注意力模块学习骨干输出静态图像特征的空间重要性权重,通过加权乘积求和得到增强后的特征图,使用残差连接将增强后的特征图与原始特征图融合;通过有状态的convlstm模块在原始空间特征基础上学习时域特征进行视频显著性预测。优选的,在上述的一种基于视觉显著性的hevc优化算法中,所述静态骨干神经网络的结构包括:以vgg-16网络为基础,去掉vgg-16网络的全连接层,保留其13个含参数卷积层,并去掉最后一个最大池化层并且修改倒数第二个最大池化层的步长为1,所有卷积层后均采用relu激活函数。优选的,在上述的一种基于视觉显著性的hevc优化算法中,利用有状态的convlstm模块学习时域特征进行视频显著性预测。具体步骤:通过注意力增强的vgg骨干输出的特征图序列为{xt},其中,t为帧序号;convlstm以门的方式控制其内部信号的流动,其共包含输入门、输出门、遗忘门三个门,同时其内部包含记忆单元保存长期的时域信息,convlstm内部运算的处理过程表示为:其中,it,ft,ot分别为输入门、遗忘门和输出门;ht为隐藏状态,ct为记忆细胞,bi,bf,bo为常偏置系数,*为卷积操作,为hadamard运算,σ()为激活函数;为候选记忆细胞;convlstm通过输入门和遗忘门来保持记忆细胞长范围的记忆能力和对新状态的可变性,将隐藏状态ht作为当前时刻的输出。优选的,在上述的一种基于视觉显著性的hevc优化算法中,利用显著性图,以cu的平均显著性作为当前cu的显著性,计算各cu块的显著值:计算当前帧平均显著性:其中,sn×n(k)第k个cu块的显著值,其大小为n×n;i表示n×n个块中从左到右的坐标,j表示从上到下的坐标;width表示视频帧的宽,height表示视频帧的高。优选的,在上述的一种基于视觉显著性的hevc优化算法中,得到显著性引导的率失真优化目标具体步骤:cu显著性的最大值和最小值分别为smax和smin,则显著性权重因子sw计算为:其中,scu表示当前块平均的显著值。显著性引导的感知优先失真度计算如下:ds=(h×sw+1)×dd表示hm标准的失真度计算方法得到的失真度;h表示感知重要程度影响因子,其计算公式为:其中,f为一个常量,作为压缩参数整合到hevc压缩标准中,需要手工由编码配置文件给定,其范围为[0,1]。对于帧内预测,失真d采用sse,对于帧间预测,失真d采用sad,计算公式分别为:最终的显著性引导的率失真优化srdo公式为:minjs,js=ds+λr,其中,ds表示当前块显著性的感知失真度;λ表示拉格朗日乘子;r表示编码比特率。需要了解的是:假设qps为用户给定的当前帧的qp值,该cu的qp值可通过在其基础上引入显著性权重计算:其中wk由下式计算得到:设置b=0.7,c=0.6,a=4,称该方法为sqp方法。hevc标准引入了qp偏移量的概念,为了适应多变的视频内容,使用了基于cu内容的自适应量化aqp方法,基本算法引用了mpeg-2标准所提出的tm-5模型,具体方法如下:对于每个深度的cu,将其slice的qp设置为其基本qp,对于大小为2n×2n的cu,将其进行四叉树划分,得到4个n×n大小的子单元,计算四个子单元的标准差,定义当前cu的平均活跃度如下:当前帧的平均活跃度由深度d的所有cu决定:其中,是深度d下每个cu的平均活跃度,n为当前帧可划分的深度为d的cu的总数;相对于cu的初始qp的qp偏移量可计算为:r为一个正常数,表示为:δqpmax是由用户在配置文件给定的参数,指的是相对于slice级qp的允许的cu最大qp偏移量。为了使得显著性更加合理地影响cu的qp的设置,不以cu的四个子单元的标准差来确定qp,而通过cu的显著性确定qp值,则相对于cu的初始qp的qp偏移量为:经由上述的技术方案可知,与现有技术相比,本发明的技术效果在于:1、现有的视频显著性数据库大部分是有损低分辨率视频,仅能用于显著性建模无法同时满足感知高清视频压缩的需求,因此建立了一个高清无损视频eye-tracking数据集,推动了高清无损视频的感知压缩的研究。2、使用了最先进的视频显著性模型,采用具有空间监督的自注意力模块,结合了能够进行时域建模的convlstm结构,在eye-tracking数据集上达到了高精度的显著性检测。3、基于视频显著性提出了一个感知率失真优化算法(srdo),在压缩中引导更加合理的比特分配达到满足人眼观看的需求,其压缩结果和压缩效率超过了最先进的方法。4、使用基于hevc的aqp方法,在其上扩展出基于显著性的qp选择算法(saqp),结合感知率失真优化算法,视频压缩性能进一步提升。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。图1附图为本发明的神经网络结构图;图2附图为本发明的vgg-16骨干结构图;图3附图为本发明的空间注意力模块结构图;图4附图为本发明的视频显著性预测结果图;(a)原始帧;(b)真实显著性图;(c)预测的显著性图;图5附图为本发明的cu划分示意图;(a)srdo的整体cu划分;(b)srdo在衣服上的cu划分;(c)srdo在人脸上的cu划分;(d)hevc的整体cu划分;(e)hevc在衣服上的cu划分;(f)hevc在人脸上的cu划分;图6附图为本发明的在kimono1视频第60帧的原图、qp分布图及显著性图;(a)aqp的qp分布图;(b)mqp的qp分布图;(c)sqp的qp分布图;(d)saqp的qp分布图;(e)原始图像;(f)预测的显著性图;图7附图为本发明的不同视频的眼动加权峰值信噪比-码率曲线;图8附图为本发明的主观质量对比图;(a)hm(ldp)压缩的整帧效果;(b)hm(ldp)压缩的人脸效果;(c)srdo+saqp方法压缩的整帧效果;(d)srdo+saqp方法的压缩的人脸效果;图9附图为本发明的整体框架图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。如图9所示,以高清无损视频的感知压缩为目的,基于hevc标准的测试用高清无损视频建立eye-tracking数据集,基于最先进的深度学习方法,采用自注意力机制和convlstm模块构建神经网络,进行高精度的高清视频时空显著性建模。同时,一个基于显著性图的感知率失真优化方法被提出,压缩结果超过了现在所有的最先进的方法,进一步地,结合前面的结构,提出了一个显著性引导的qp分配方法,使得高清视频压缩效果进一步提高,显著地优于标准hevc及hevc中的优化算法aqp、mqp以及最新的基于显著性的hevc感知压缩算法pgvc,本发明的方法实现了极高的bd-ewpsnr提升、基于bd-ewpsnr的bd-rate的大幅度下降和视频压缩时间的大量节省。为了推动感知高清压缩的研究需要,选择了26个涵盖各种场景的hevc高清无损视频序列(其中视频分辨率从416×240到2560×1600不等),招募100名志愿者(年龄22-25)自由观看并记录每帧中他们的注视点,这100名志愿者均为在校大学生,除了5人是参与视频显著性和感知压缩的研究人员,其余人均不了解显著性且不了解实验的目的。所选择的实验设备是来自丹麦的theeyetribe公司在2013年底发布的一款廉价的眼动仪,该设备的采样率为30-60hz,空间分辨率为0.1°,实验采用dell公司的p2415q的4k分辨率显示器播放视频片段。采用的网络结构如图1所示,采用image-net上预训练的vgg-16网络作为骨干提取静态图像特征,采用空间注意力模块学习骨干输出特征图的空间重要性权重,注意力通过残差连接以便网络更容易训练,最终注意力增强的特征图通过有状态的convlstm模块学习时域特征进行视频显著性预测。选取image-net上预训练的vgg-16作为本实验的骨干网络。去掉vgg-16网络的全连接层,保留其前13个含参数卷积层,并去掉最后一个最大池化层并且修改倒数第二个最大池化层的步长为1,网络结构图如图2所示,所有卷积层后均采用relu激活函数。使用空间注意力模块来增强vgg的高层特征,注意力各层结构如图3所示。其分别包含卷积层、最大池化层和上采样层,卷积层后均使用relu激活函数。采用逐元素乘积增强特征图,使用残差连接将增强后的特征图与原始特征图融合:其中,m为空间注意力模块输出的注意力图,为hardamard运算,x和xc分别为原始特征图和注意力增强的特征图。有状态的convlstm可以处理任意长度的序列,在训练时关闭状态开关,采样多个固定长度序列并且将lstm的内部记忆单元状态仅在序列内部而不在序列之间传递,在推断时,开启状态开关从头开始处理任意长度的视频序列并将记忆单元状态一直保留,这样可以满足任意长度视频序列的显著性预测需要。显著性网络的训练是一个回归问题,目的是让预测的显著性图尽可能接近真实显著性图。由于显著性图的评估指标多样化,且每个评估指标均从不同的方面描述了显著性建模的好坏。因此这里使用三个最常用的评估指标的加权和作为损失函数。假设预测的显著性图为s∈[0,1],标记的二值注视图为f∈{0,1},由注视图生成的真实显著性图为g∈[0,1],则最终的损失函数可表示为:l(s,f,g)=lkl(s,g)+α1lcc(s,g)+α2lnss(s,f)其中的α1=α2=0.1,lkl,lcc,lnss分别表示kullback-leibler(kl)散度(lkl)、线性相关系数(lcc)和归一化扫描路径显著性(lnss)。三者的计算公式分别如下:其中∑x(·)表示对所有像素求和,cov(,)表示协方差,μ(·)表示均值,ρ(·)表示方差。网络使用imagenet上预训练的vgg-16权重进行初始化,在静态图像显著性数据集salicon(10000个图像),动态视频显著性数据集dhf1k,hollywood-2,ucf-sports的合集上进行微调,静态图像的注视图和真实显著性图作为注意力图的监督,视频图像的对应物则作为最终网络预测的显著性图的监督。模型采用迭代训练的mini-batch梯度下降算法,一个图像训练batch随后紧跟一个视频训练batch。对于图像训练batch,batch大小设置为20,图像从静态注视数据集随机采样。对于视频训练batch,从所有视频序列中随机选取20个连续帧。网络使用adam优化器,初始学习率被设置为0.0001并且每两个epoch减少10倍,网络训练10个epoch,采用提前终止策略。最终的视频显著性检测结果如图4所示,与真实显著性图对比可知,网络能够较精确地结合视频空域和时域特征,进行高精度地视频显著性检测。由于压缩前的高斯模糊会造成巨大失真,因此本申请采用内嵌式视频压缩的思想,即在计算了视频显著性后,通过显著性修改hevc视频压缩标准,对于高显著性区域,以提升其视频质量为目标,并适当降低非显著区域的视频质量和比特数,使得在不影响观看的情况下,大大降低视频比特率。该部分从基本编码单元cu出发,首先优化率失真优化算法,将视频显著性的结果引入率失真代价中,寻求失真和比特率的最佳平衡,从而从全局意义上选取cu的最佳划分模式和编码模式,在保持视觉质量不变的情况下极大地降低视频比特率,在其基础上,进一步提出基于显著性的qp选择算法,将视频压缩性能进一步提高,实验结果表明,单一改进算法和整体算法均优于目前所有的最先进的感知压缩算法和hevc标准算法。hevc标准软件hm采用拉格朗日优化方法,其综合考虑失真和码率的影响,将码率受限,失真最小的约束问题化为代价最小化问题。拉格朗日乘子作为失真和码率的权衡因子,表示了失真和码率在代价中所占的比例,标准rdo采用固定的拉格朗日乘子,从ctu的划分开始优化,最终决定pu的模式和tu的划分,标准率失真优化公式为:minj,j=d+λr为了能使显著性影响率失真优化过程,使得cu在感知率失真优化过程中选择感知上最优的划分的编码模式,利用显著性图,以cu的平均显著性作为当前cu的显著性。对于一个深度d下的n×n大小的cu,用下式计算当前cu平均显著性:同时,需要计算当前帧的平均显著性,以对cu的显著程度进行分类:假设cu显著性的最大值和最小值分别为smax和smin,则显著性权重因子sw可计算为:显著性引导的感知优先失真度计算如下:ds=(h×sw+1)×dh表示感知重要程度影响因子,其计算公式为:其中,f为一个常量,可以作为压缩参数整合到hevc压缩标准中,需要手工由编码配置文件给定,其范围为[0,1],本申请选取f=0.8进行实验并与其它算法进行对比。对于帧内预测,上述失真d采用sse,对于帧间预测,上述失真d采用sad,计算公式分别为:最终的显著性引导的率失真优化srdo公式为:minjs,js=ds+λr若当前块的显著性较大,则ds会变大,使得率失真代价中的失真权重变大,为了寻找最小的率失真代价所对应的参数,编码器会倾向于降低失真,提高视觉质量。该方法对hevc的所有小块处理,通过显著性优化hevc的以cu为基础的所有编码模式的选择过程,如cu的四叉树划分,预测模式,运动搜索,tu分块等,将rdo的优先级顺序完全改变。srdo方法和hevc在kristenandsara视频上第20帧的cu划分如图5所示,从图中可以看到,对于显著的人脸区域,如眼睛鼻子等,srdo方法为倾向于划分为较小的cu,进而提升其质量。而对于不显著的区域如衣服等,srdo方法会倾向于划分为大的cu,此时hevc标准划分较为精细。假设qps为用户给定的当前帧的qp值,该cu的qp值可通过在其基础上引入显著性权重计算:其中wk由下式计算得到:设置b=0.7,c=0.6,a=4,称该方法为sqp方法。hevc标准引入了qp偏移量的概念,为了适应多变的视频内容,使用了基于cu内容的自适应量化aqp方法,基本算法引用了mpeg-2标准所提出的tm-5模型,具体方法如下。对于每个深度的cu,将其slice的qp设置为其基本qp,对于大小为2n×2n的cu,将其进行四叉树划分,得到4个n×n大小的子单元,计算四个子单元的标准差,定义当前cu的平均活跃度如下:当前帧的平均活跃度由深度d的所有cu决定:其中,是深度d下每个cu的平均活跃度,n为当前帧可划分的深度为d的cu的总数。相对于cu的初始qp的qp偏移量可计算为:r为一个正常数,表示为:δqpmax是由用户在配置文件给定的参数,指的是相对于slice级qp的允许的cu最大qp偏移量。该方法的初衷是为了契合人眼视觉特性,其充分考虑了每个编码块的局部特性,其对于mpeg-2的16×16小块来说,可适当地提升压缩性能,但hevc的cu最大大小为64×64,这种仅考虑子块方差的处理方法无法充分描述该cu与其他cu的差异性,同时其没有考虑显著性的影响。为了使得显著性更加合理地影响cu的qp的设置,改进上述在过去压缩标准中取得优异性能的aqp方法,不以cu的四个子单元的标准差来确定qp,转而通过cu的显著性确定qp值。则相对于cu的初始qp的qp偏移量为:其中r依然与aqp中的计算方法相同,在本文实验中的δqpmax设置为7,将该方法称为saqp方法。图6展示了aqp,mqp(qp范围为7),sqp和saqp方法在kimono1视频帧的qp分布图,qp分布图颜色越深表示所用qp值越小,量化越精细,可以看到aqp和mqp方法的qp分布杂乱无章,sqp方法和saqp方法均能给予高显著的位置以低的qp,saqp方法针对高显著区域的qp设置更加精细,具有明显的渐进性。使用眼动点数据加权失真,基于mse,眼动加权均方误差ewmse的计算如下:(x,y)表示视频第i帧的某点的空间坐标,w和h分别表示视频帧的宽度和高度,l'(x,y)和l(x,y)分别表示重建视频i帧和原始视频i帧在(x,y)处的像素值,w(x,y)表示与眼动数据点有关的失真权重,可通过下述高斯函数计算:其中n表示眼动实验数据库中观察者的数目,(xen,yen)表示第n个观察者观看视频时的注视点数据,σx和σy是表示高斯函数的宽度的两个参数,当视觉中心凹角度是2°时,σx和σy均为64个像素距离。通过模仿psnr指标的计算,眼动加权的psnr(ewpsnr)可计算为:由于ewpsnr指标需要确定的注视点数据,与本文所用的数据库刚好符合,且其能够充分考虑人眼的视觉特性,能很好地评价视频的感知质量,因此本文采用bd-ewpsnr和基于bd-ewpsnr的bd-rate(同等ewpsnr情况下的比特节省)来衡量各种压缩算法所得的重建视频的感知质量。同时,为了保证实验的完整性,本文同样采用对比算法比较常用的bd-psnr,bd-ssim,bd-vifp等指标。本文采用数据库中具有不同分辨率的10个高清视频进行实验,其中每个高清视频均包含观察者的注视点数据,视频的具体参数如表1所示。本文提出的基于显著性的高清视频压缩算法基于hm16.8进行改进,为方便起见,本文提出的方法共三种配置,感知率失真优化算法称为srdo,而srdo+sqp、srdo+saqp分别为感知率失真优化算法与不同的显著性qp选择算法的结合,将提出的三种算法分别与hm16.8软件的ldp标准配置算法,aqp算法,mqp算法及最新的感知压缩算法pgvc分别进行对比。为保证其他参数相同,在实验中,将gop大小设置为1,采用ippp低延迟编码结构,显著性影响因数f的值设为0.8。为了得到视频率失真曲线和计算bd-ewpsnr等指标,分别选取qp=22,27,32,37值进行压缩实验得到不同比特率和不同质量的视频。图7展示了十个视频的七种不同算法的ewpsnr-rate(眼动加权峰值信噪比-比特率)曲线结果。表1实验用高清视频序列参数信息如图7所示,曲线的ewpsnr值越高,表示相同比特率下视频质量越好,可以看出所提出的方法总体上显著优于其他算法。所提出的三种算法和pgvc均为感知压缩算法,其均优于其余三种非感知压缩算法,说明显著性对于视频压缩的引导是重要的。同时可看出显著性引导的率失真优化和动态qp选择结合优于仅适用感知率失真优化的情况,srdo+saqp为所有方法中效果最好的方法。其中fourpeople视频是个特例,其中所有算法的性能相近,通过分析可知原因在于视频中四个人在缓慢地传递纸张,吸引注意力的纸张很小且运动并不剧烈,同时四个人的言语交流伴随着缓慢的面部运动,而其面部区域在大部分帧中并不全是很显著的区域,检测面部为显著的算法结果与实际值产生了显著性上的偏差导致显著性预测的不够准确,进而导致压缩上性能没有明显变化,而其余视频均表现出本申请算法的巨大优势。为了进行定量分析,基于视频率失真曲线,分别计算三种优化方法相对于hm(ldp),aqp和mqp的bd-ewpsnr,bd-psnr,bd-ssim和bd-vifp和基于ewpsnr的bd-rate,其中bd-psnr、bd-ssim和bd-vifp均未考虑视觉显著性的影响,bd-ewpsnr以fixation为基准考虑了视觉显著性,对于这些指标,bd-psnr,bd-ssim,bd-vifp和bd-ewpsnr均是越大越好,而bd-rate则是越小越好,将实验结果绘制如表2所示。表2视频压缩质量定量评估结果对表2的结果进行分析,首先考虑与显著性相关的指标bd-ewpsnr,其中提出的三种算法的bd-ewpsnr相比于hm(ldp),aqp和mqp均具有相当大的增益,其对应的bd-rate节省均在20%以上,特别地,最优算法srdo+saqp相比于hm(ldp),bd-rate平均节省32.41%,相比于aqp和mqp算法,bd-rate平均节省分别为44.58%,35.38%。体现出本文算法相比于hevc标准明显的性能提升。然后考虑bd-psnr,bd-ssim和bd-vifp,bd-psnr给所有失真分配相同的权重,本文的不同区域不平等压缩策略造成其指标下降是必然的结果,同时其指标的下降与bd-ewpsnr的提升几乎相同。bd-ssim考虑了图像的空间结构性,能够片面的描述人眼对图像的视觉关注,由于本文算法和hevc的改进算法均没有显著提升或破坏图像中的这种结构性,在该指标上本文算法与两种方法差异不大,只有轻微的损失。bd-vifp同理。值得注意的是,aqp算法的性能最差,很好地印证了该方法时的缺陷,其在ctu的大小达到64×64时丢失了太多的细节信息是造成其性能较差的根本原因,因此tm-5模型中的aqp方法计算子单元方差的方式并不适合于hevc中较大的编码单元。同时,本发明的算法与最新的感知压缩方法pgvc的结果比较如表3所示。为了能够进行直观的比较,均直接以hm(ldp)作为基准,比较所有方法相对于其的提升。表3感知压缩算法定量评估结果方法bd-ewpsnrbd-ratebd-psnrbd-ssimbd-vifppgvc0.31682-9.18761-0.72594-0.008940.02905srdo0.703-20.822-0.877-0.007-0.022srdo+sqp1.107-30.618-1.18-0.009-0.032srdo+saqp1.217-32.41-1.342-0.01-0.037从表3中可以看到,提出的三种配置方法全面优于pgvc方法,bd-ewpsnr和bd-rate指标提升明显,同时,本发明方法的bd-psnr下降与bd-ewpsnr的提升接近,而不像pgvc的前者的降低要显著多于后者。高清视频压缩的压缩效率也是一个重要的评估指标,为了对比不同算法的压缩效率,分别记录10段视频序列在4个不同qp值的压缩时间平均值,并以hm(ldp)为基准记录不同算法的压缩时间的变化百分比,实验条件为配置inteli9-9900kcpu,内存64g,双titanvgpu的ubuntu系统主机,均使用十个进程进行视频压缩实验。视频压缩时间对比如表4所示,如前可知,本发明的方法不仅能够提升主观质量,同时也得到了视频压缩时间的大量减少(尽管没有专门针对编码复杂度进行优化),原因可能是显著性区域本身较小,导致了srdo方法在进行cu模式选择时重点关注显著区域,因而其率失真模式选择效率更高更快。srdo+saqp方法达到的最高编码时间节省大约为29.06%,其他两种改进方法的最大时间节省也高达27.81%和23.60%。而aqp方法时间节省很小,最高仅6%,mqp方法则相当于多出了大约11倍的时间,本发明的方法是唯一在提高压缩视觉质量的同时编码时间大大减少的方法,而pgvc则大约带来相比于hm的2.5倍的编码时间。表4视频压缩时间对比为了公平比较主观质量,采取hevc的速率控制算法,保证视频的相同码率,目标码率设置为1000kbps,比较srdo+saqp方法与hm(ldp)的在kimono1视频的主观质量,从图可以看到本发明的方法能够明显提升显著性区域的质量,如人脸及眼睛,嘴巴等,非显著性区域的质量几乎没有差别。针对高清视频中的感知冗余,使用针对高清视频提出的hevc视频压缩标准,提出了一种新颖的基于显著性的高清视频压缩算法,同时达到了视频质量的极大提升和视频编码时间的极大减少。首先,建立了一个高清无损eye-tracking数据集,用以推动感知高清视频压缩的研究;在视频显著性部分,利用深度学习在图像处理中的优异性能,使用空间注意力增强的vgg-16网络提取视频帧的静态特征,随后通过convlstm处理视频长范围的时域信息进行高精度的视频显著性检测;在高清视频压缩部分,使用预测的显著性图得到cu的显著性,从而使用感知显著性的率失真优化,使得相比于hm(ldp)方法,在ewpsnr不变的情况下bd-rate节省了20.822%,进一步结合显著性引导的动态qp设置算法sqp和saqp,bd-rate进一步分别节省到30.618%和32.41%,同时压缩时间最多减少了29.06%,从压缩质量和压缩效率上均大大超越了目前最先进的方法。使用本文的算法,能够有效提升视频的感知质量,在质量不变时显著降低视频码率。本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1