一种基于虚拟视点绘制的3D-HEVC错误隐藏方法与流程
本发明涉及视点绘制技术领域,尤其是涉及一种基于虚拟视点绘制的3d-hevc错误隐藏方法。
背景技术:
视频数据包在有限带宽通信系统传输过程中,会因网络拥塞、路由问题而丢失,导致传输效率降低。现有的差错控制方法都是为了提高差错鲁棒性,如自动重传查询(arq)、前向纠错(fec)和多描述编码(mdc)。尽管这些方法通常在低错误率下工作良好,但是随着错误率的增加,它们的性能会降低。在图像和视频传输领域缓解这些问题的另一种方案是错误隐藏技术。错误隐藏技术是在解码端利用视频流帧间和帧内压缩冗余来隐藏解码帧中的出错区域,以达到主观视觉上不易觉察的效果。
而针对整帧丢失,有研究利用相邻视点中宏块的运动矢量相关性,将b帧的重要等级分级,对不同等级帧采用不同错误隐藏方法。有提出结合结构相似度,根据宏块结构相似度的大小采用不同的错误隐藏方法。有在虚拟视点绘制的基础上提出图像块联合运动判定法,将图像块像素的平均差与绘制图像相加的错误隐藏方法。还有利用相邻视点中帧物体的运动一致性,把丢失视点帧的相邻帧与其前一帧的帧差投影到当前丢失视点帧上的错误隐藏方法。还有研究用当前丢失帧时域和邻视点帧中的运动信息,区分丢失帧中的运动区域和静止区域。静止区域直接拷贝,对运动区域进一步划分遮挡边界区域和非遮挡区域后分别采用运动补偿和视差补偿恢复。利用视点间相关性和视差矢量进行错误隐藏,不足在于视差矢量具有局限性,即视点间可参考的信息少,且图像边界处一般没有参考,整帧恢复难度较大。
结合虚拟视点绘制采用图像块联合运动判定法进行错误隐藏,不足在于运动块内平均像素差与每个像素差差异过大,导致补偿过程效果较差。并且虚拟视点绘制产生的遮挡块判定方式不完善。
技术实现要素:
针对现有技术中由于视差矢量具有局限性导致整帧恢复难度较大和由于图像块联合运动导致运动块内平均像素差与每个像素差差异过大问题,本发明提出了一种基于虚拟视点绘制的3d-hevc错误隐藏方法,突破了视差矢量的局限性,在不使用视差矢量的情况下,改进了虚拟视点绘制产生遮挡块的判别和填充方式,在提高错误隐藏准确率的同时,降低了总体复杂度,更好的消除遮挡块和图像失真。
为实现上述目的,本发明提供以下的技术方案:
一种基于虚拟视点绘制的3d-hevc错误隐藏方法,包括以下步骤:
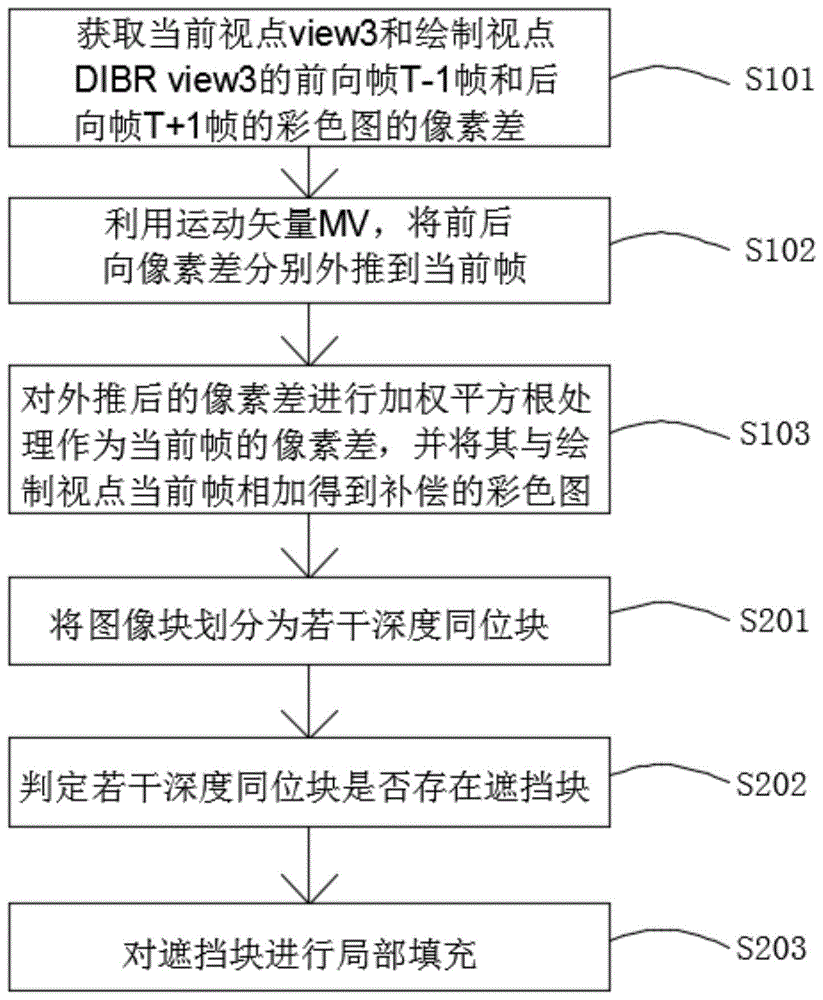
s1、彩色图补偿,对丢失的整帧彩色图像进行绘制并生成绘制视点,由于绘制视图中存在遮挡块和失真,根据当前视点和绘制视点的前后向参考帧的信息,对绘制的彩色图进行补偿;
s2、判定遮挡块及进行局部填充,提取补偿后的彩色图仍然存在较小的遮挡块,并进行局部填充。
作为优选,所述步骤s1具体包括:
s101、获取当前视点view3和绘制视点dibrview3的前向帧t-1帧和后向帧t+1帧的彩色图的像素差front_difference(t-1)和back_difference(t+1)
front_difference(t-1)=view3(t-1)-dibrview3(t-1);
back_difference(t+1)=view3(t+1)-dibrview3(t+1);
所述彩色图补偿过程中引入front_difference(t-1)和back_difference(t+1),当前t帧总像素差由前后两个方向的参考帧像素差协同确定,消除了只利用单方向参考帧像素差作为总像素差的偶然性。
s102:利用运动矢量mv,将前后向像素差分别外推到当前帧;
由于view3的t帧丢失,其运动矢量无法获取,但可以由前向帧的运动矢量参考获得,即将由t-1帧指向t-2帧的运动矢量mv反转,变为由t-1帧指向t帧的运动矢量mv;
设前向帧像素坐标为(x1,y1),其运动矢量mv为(mv(x1,t-1),mv(y1,t-1)),则外推到t帧的像素坐标为(x1-mv(x1,t-1),y1-mv(y1,t-1)),其外推到t帧的像素差为
front_mvedifference(x1-mv(x1,t-1),y1-mv(y1,t-1),t)=front_difference(x1,y1,t-1)
而由t+1帧指向t帧的后向帧运动矢量mv可以直接获取,设后向帧像素坐标为(x2,y2),其外推到t帧的像素差为
back_mvedifference(x2+mv(x2,t+1),y2+mv(y2,t+1),t)=back_difference(x2,y2,t+1);
所述彩色图补偿的外推过程中,因前向帧的mv是由t-1帧指向t-2帧的mv反转变为由t-1帧指向t帧的mv,通过反转获得的前向帧mv有时并不能准确反映t帧信息。而引入由t+1帧指向t帧的后向帧运动矢量较为准确反映t帧信息,并可以直接获取,不必进行mv反转,在提高准确率的同时,降低了总体复杂度。
s103:对外推后的像素差进行加权平方根处理作为当前帧的像素差,并将其与绘制视点当前帧相加得到补偿的彩色图;
设t帧像素坐标为(x,y),由于前后向运动矢量mv可能具有差异性,导致有些运动像素的front_mvedifference(x,y,t)与back_mvedifference(x,y,t)差异较大,本发明采取加权平方根处理,使得最终像素差相比两者平均值,更接近于两者之中较大的像素差,以更好的消除遮挡块和图像失真。
最终t帧像素差
补偿后的t帧像素
view3(x,y,t)=dibrview3(x,y,t)+pixel_difference(x,y,t)。
作为优选,所述步骤s2具体包括:
s201、将图像块划分为若干深度同位块;
s202:判定若干深度同位块是否存在遮挡块,首先判定非遮挡块,再将不属于非遮挡块的块判定为遮挡块;
s203:对遮挡块进行局部填充,根据视频序列的时间相关性,被运动物体遮挡的背景区域的信息可以在相邻参考帧得到,首先提取遮挡块对应深度同位块像素值偏小的背景区域,设若干深度同位块内最小像素值为dmin,将像素值小于t的像素视为背景区域像素,其中t=dmin+40,通过图像二值化实验获得,再将这部分像素用相邻参考帧同位像素填补。由于背景区域的深度像素较小,相比块内深度像素最大值,从块内深度像素的最小值出发,更能准确提取背景区域。
补偿过程虽然修复了图像失真和较大的遮挡块,但由于获取运动像素的mv不够准确,处于前景区域的运动物体遮挡了背景区域所产生的遮挡块不能完全修复,导致补偿后的彩色图仍存在较小的遮挡块。对于修补这部分遮挡块,本发明采用了基于深度图像素值的局部填充算法,假设当前视点深度帧未丢失,当前视点相对相邻视点位置为水平差异时,通过比较块内局部深度像素差,更好的判定遮挡块并按图像块的精度填充遮挡块。
作为优选,所述若干深度同位块由图像块划分而成,将图像块划分为32x32大小,再将其划分为16个8x8的块。所述判定遮挡块过程中,细分遮挡块,将原本64x64的图像块划分为32x32大小,再将其划分为16个8x8的块。如果图像块较大(64x64),会将遮挡块判为非遮挡块,导致遮挡块在后续无法填补。
作为优选,所述步骤s202具体包括以下步骤:
若同时满足block_1-block_2<m,block_1-block_3<m,block_1-block_4<m,block_5-block_6<m,block_5-block_7<m,block_5-block_8<m,则判定整个图像块为非遮挡块,否则为待处理的遮挡块;
其中block_i(i=1,2,3,…8)为8x8块内的每块的平均像素值,m为像素差阈值,m=25,通过图像二值化实验获得。
若采用处于图像块两边界的角块的像素差的大小直接判定遮挡块,会将两边界的块都属于前景区域,而中间块属于背景区域的遮挡块误判为非遮挡块。为改善上述判别方式,本发明采用逆向思维,首先判定非遮挡块,再将不属于非遮挡块的块判定为遮挡块。通过比较块内局部深度像素差,更好的判定遮挡块并按图像块的精度填充遮挡块。
作为优选,在所述彩色图补偿的过程中,利用运动矢量mv,仅将后向像素差外推到当前帧作为当前帧的总像素差,即pixel_difference(x,y,t)=back_mvedifference(x,y,t)。
作为优选,所述步骤s202具体包括以下步骤:当前视点相对相邻视点位置更改为垂直差异时,
若同时满足block_1-block_2<m,block_1-block_3<m,block_1-block_4<m,block_5-block_6<m,block_5-block_7<m,block_5-block_8<m,则判定整个图像块为非遮挡块,否则为待处理的遮挡块。
其中block_i(i=1,2,3,…8)为8x8块内的每块的平均像素值,m为像素差阈值,m=25,通过图像二值化实验获得。
本发明有以下有益效果:引入front_difference(t-1)和back_difference(t+1),当前t帧总像素差由前后两个方向的参考帧像素差协同确定,消除了只利用单方向参考帧像素差作为总像素差的偶然性;引入由t+1帧指向t帧的后向帧运动矢量较为准确反映t帧信息,并可以直接获取,不必进行mv反转,在提高准确率的同时,降低了总体复杂度;由于背景区域的深度像素较小,相比块内深度像素最大值,从块内深度像素的最小值出发,更能准确提取背景区域。通过比较块内局部深度像素差,更好的判定遮挡块并按图像块的精度填充遮挡块。
附图说明
图1是本发明的流程图;
图2是实施例1的分块示意图;
图3是实施例2的分块示意图;
具体实施方式
实施例1:
本实施例提出一种基于虚拟视点绘制的3d-hevc错误隐藏方法,参考图1,包括以下步骤:
s1、彩色图补偿,对丢失的整帧彩色图像进行绘制并生成绘制视点,由于绘制视图中存在遮挡块和失真,根据当前视点和绘制视点的前后向参考帧的信息,对绘制的彩色图进行补偿;
步骤s1具体包括:
s101、获取当前视点view3和绘制视点dibrview3的前向帧t-1帧和后向帧t+1帧的彩色图的像素差front_difference(t-1)和back_difference(t+1)
front_difference(t-1)=view3(t-1)-dibrview3(t-1);
back_difference(t+1)=view3(t+1)-dibrview3(t+1);
彩色图补偿过程中引入front_difference(t-1)和back_difference(t+1),当前t帧总像素差由前后两个方向的参考帧像素差协同确定,消除了只利用单方向参考帧像素差作为总像素差的偶然性。
s102:利用运动矢量mv,将前后向像素差分别外推到当前帧;
由于view3的t帧丢失,其运动矢量无法获取,但可以由前向帧的运动矢量参考获得,即将由t-1帧指向t-2帧的运动矢量mv反转,变为由t-1帧指向t帧的运动矢量mv;
设前向帧像素坐标为(x1,y1),其运动矢量mv为(mv(x1,t-1),mv(y1,t-1)),则外推到t帧的像素坐标为(x1-mv(x1,t-1),y1-mv(y1,t-1)),其外推到t帧的像素差为
front_mvedifference(x1-mv(x1,t-1),y1-mv(y1,t-1),t)=front_difference(x1,y1,t-1)
而由t+1帧指向t帧的后向帧运动矢量mv可以直接获取,设后向帧像素坐标为(x2,y2),其外推到t帧的像素差为
back_mvedifference(x2+mv(x2,t+1),y2+mv(y2,t+1),t)=back_difference(x2,y2,t+1);
彩色图补偿的外推过程中,因前向帧的mv是由t-1帧指向t-2帧的mv反转变为由t-1帧指向t帧的mv,通过反转获得的前向帧mv有时并不能准确反映t帧信息。而引入由t+1帧指向t帧的后向帧运动矢量较为准确反映t帧信息,并可以直接获取,不必进行mv反转,在提高准确率的同时,降低了总体复杂度。
s103:对外推后的像素差进行加权平方根处理作为当前帧的像素差,并将其与绘制视点当前帧相加得到补偿的彩色图;
设t帧像素坐标为(x,y),由于前后向运动矢量mv可能具有差异性,导致有些运动像素的front_mvedifference(x,y,t)与back_mvedifference(x,y,t)差异较大,本发明采取加权平方根处理,使得最终像素差相比两者平均值,更接近于两者之中较大的像素差,以更好的消除遮挡块和图像失真。
最终t帧像素差
补偿后的t帧像素
view3(x,y,t)=dibrview3(x,y,t)+pixel_difference(x,y,t);
s2、判定遮挡块及进行局部填充,提取补偿后的彩色图仍然存在较小的遮挡块,并进行局部填充。
步骤s2具体包括:
s201、将图像块划分为若干深度同位块;
参考图2,将图像块划分为32x32大小,再将其划分为16个8x8的深度同位块。
s202:判定若干深度同位块是否存在遮挡块,首先判定非遮挡块,再将不属于非遮挡块的块判定为遮挡块;在判定遮挡块过程中,细分遮挡块,将原本64x64的图像块划分为32x32大小,再将其划分为16个8x8的块。如果图像块较大(64x64),会将遮挡块判为非遮挡块,导致遮挡块在后续无法填补。
步骤s202具体包括以下步骤:
若同时满足block_1-block_2<m,block_1-block_3<m,block_1-block_4<m,block_5-block_6<m,block_5-block_7<m,block_5-block_8<m,则判定整个图像块为非遮挡块,否则为待处理的遮挡块;
其中block_i(i=1,2,3,…8)为8x8块内的每块的平均像素值,m为像素差阈值,m=25,通过图像二值化实验获得。
若采用处于图像块两边界的角块的像素差的大小直接判定遮挡块,会将两边界的块都属于前景区域,而中间块属于背景区域的遮挡块误判为非遮挡块。为改善上述判别方式,本发明采用逆向思维,首先判定非遮挡块,再将不属于非遮挡块的块判定为遮挡块。通过比较块内局部深度像素差,更好的判定遮挡块并按图像块的精度填充遮挡块。
s203:对遮挡块进行局部填充,根据视频序列的时间相关性,被运动物体遮挡的背景区域的信息可以在相邻参考帧得到,首先提取遮挡块对应深度同位块像素值偏小的背景区域,设32x32深度同位块内最小像素值为dmin,将像素值小于t的像素视为背景区域像素,其中t=dmin+40,通过图像二值化实验获得,再将这部分像素用相邻参考帧同位像素填补。由于背景区域的深度像素较小,相比块内深度像素最大值,从块内深度像素的最小值出发,更能准确提取背景区域。
补偿过程虽然修复了图像失真和较大的遮挡块,但由于获取运动像素的mv不够准确,处于前景区域的运动物体遮挡了背景区域所产生的遮挡块不能完全修复,导致补偿后的彩色图仍存在较小的遮挡块。对于修补这部分遮挡块,本发明采用了基于深度图像素值的局部填充算法,假设当前视点深度帧未丢失,当前视点相对相邻视点位置为水平差异时,通过比较块内局部深度像素差,更好的判定遮挡块并按图像块的精度填充遮挡块。
实施例2:
本实施例在实施例1的基础上当前视点相对相邻视点位置更改为垂直差异参考图3,步骤s202做出改变,具体包括以下步骤:
若同时满足block_1-block_2<m,block_1-block_3<m,block_1-block_4<m,block_5-block_6<m,block_5-block_7<m,block_5-block_8<m,则判定整个图像块为非遮挡块,否则为待处理的遮挡块。
其中block_i(i=1,2,3,…8)为8x8块内的每块的平均像素值,m为像素差阈值,m=25,通过图像二值化实验获得。
同时在步骤s1中,利用运动矢量mv,仅将后向像素差外推到当前帧作为当前帧的总像素差,即pixel_difference(x,y,t)=back_mvedifference(x,y,t),使得算法更加简便。
因此,本发明有以下有益效果:引入front_difference(t-1)和back_difference(t+1),当前t帧总像素差由前后两个方向的参考帧像素差协同确定,消除了只利用单方向参考帧像素差作为总像素差的偶然性;引入由t+1帧指向t帧的后向帧运动矢量较为准确反映t帧信息,并可以直接获取,不必进行mv反转,在提高准确率的同时,降低了总体复杂度;由于背景区域的深度像素较小,相比块内深度像素最大值,从块内深度像素的最小值出发,更能准确提取背景区域。通过比较块内局部深度像素差,更好的判定遮挡块并按图像块的精度填充遮挡块。
- 还没有人留言评论。精彩留言会获得点赞!