移动通信网络中基于异常检测和核密度估计(KDE)的指标突变小区检测方法与流程
本发明涉及移动通信网络的网络优化技术,具体是移动通信网络中基于异常检测和核密度估计(kde)的指标突变小区检测方法。
背景技术:
在移动通信网络中,指标突变小区的检测一直是一个重要的研究内容。指标突变小区的检测应用范围十分广泛,尤其是在快速定位网络恶化、指定指标优化、指标突变小区检测等方面起着重要作用。
在长期演进中,某些小区的一些关键性能指标(kpi,keyperformanceindicators)数据相对长时间的历史数据发生了较大的变化,被认为相对之前的数据范围产生了较大的异常。此外,在这些异常的小区中,某些小区的kpi相对近期的kpi急剧变化。这些因为kpi急剧变化导致指标异常的小区即为指标突变小区。
目前的指标突变小区的检测主要分为两类:一类是基于长期网络优化的经验判断,即基于长期演进的经验来划定正常小区指标的门限,根据这个门限和实时的网络数据进行比较,如果某小区的指标数据超出了这个门限,则将该小区标记为指标突变小区;一类是使用实时数据进行估计,它用密度估计的方法,计算每个小区的每个kpi的突变程度,如果某个指标突变程度过大,该指标即为突变指标,该小区即为指标突变小区。
在现有的指标突变小区检测的方法中,基于经验门限的方法设置了一个固定的门限值来筛选出异常小区,在实际生产中,使用经验门限的方法要求在检测之前给定一个固定的门限范围,这个范围通常来自于长时间网络优化的经验。然而,这个门限值不能随着检测经验而快速更新,也不具有根据检测数据本身更新的特性,从而影响了异常检测的效果。此外,应当指出的是,这种基于设定好的门限检测得到的异常小区并不全是指标突变小区,还包含了很多其他造成异常的原因,因此仅仅用该检测方法是不完善的。另一方面,基于密度函数检测的方法使用每个数据点的临近点数据来估计每个数据点的突变程度。密度函数的检测需要一定量的训练数据,在现实生产中,该方法的训练数据往往来源于实时数据周边的少量数据样本点。由于这些样本点的数据并不一定都是正常数据,因此可能会对训练本身造成干扰。同时,由于这些样本点本身数量较少,直接使用这些数据作为训练数据存在训练量不足的弊端。
技术实现要素:
本发明的目的是解决现有技术中存在的问题。
为实现本发明目的而采用的技术方案是这样的,移动通信网络中基于异常检测和核密度估计(kde)的指标突变小区检测方法,主要包括以下步骤:
1)获取移动通信网络所有小区关键性能指标kpi序列,并对每个小区的kpi序列进行数据清洗,主要步骤如下:
1.1)基于设定的粒度g,筛选掉粒度不合规的小区。
1.2)基于设定的数据长度s=t/g,筛选掉时间长度不合规的小区。t为指标突变小区检测周期。
1.3)以0填充剩余小区缺失值。
1.4)基于业务告警信息,筛选掉业务告警小区。
2)基于清洗后的kpi序列,建立历史数据序列和测试数据序列。
进一步,历史数据序列为t0-t1时间段的kpi序列。测试数据序列为t2-t3时间段的kpi序列。t0为kpi序列起始时间。t1∈(t0,t3)为历史数据序列终结时间。t2∈(t0,t3)为测试数据序列起始时间。t3为kpi序列终结时间。
3)基于历史数据序列和测试数据序列,筛选掉全部kpi序列均正常的小区,保留异常小区,并记录每个小区的所有异常kpi的第一个发生异常的时间点t1st。
确定异常小区的主要步骤如下:
3.1)利用季节差分法对历史数据序列和测试数据序列进行差分。将差分后的历史数据序列和测试数据序列输入到加法模型中,得到历史趋势数据集和测试趋势数据集。
加法模型y[t]=t[t]+s[t]+e[t]。其中,t[t]、s[t]、e[t]为kpi差分后得到的三个分解因子。y[t]表示加法模型输出的历史趋势数据或测试趋势数据。
3.2)基于历史趋势数据集,分别计算不同小区中不同kpi序列的均值μ和标准差σ,并确定每个kpi的正常区间i。
kpi的正常区间i=(μ-ω×σ,μ+ω×σ)。ω为常数。
3.3)判断测试趋势数据集中每个元素是否位于对应kpi序列的正常区间i内,若否,则将对应kpi标记为异常指标,并将所述异常指标所在小区标记为异常小区。
4)利用基于高斯核的kde计算异常小区差分前的异常kpi序列的异常分数,并建立异常分数矩阵a。
建立异常分数矩阵a的主要步骤如下:
4.1)以t0-t1st时间段的异常kpi序列作为kde的训练数据集,对kde进行训练。
4.2)以t1st-t3时间段的异常kpi序列作为kde的测试数据集,并将测试数据集输入到kde中。
4.3)利用kde对测试数据集拟合,计算出t1st-t3时间段的每个时间点对应的异常分数值,并取对数,得到每个时间点对应的异常分数。将异常分数写入异常分数矩阵a中。
5)判断异常分数矩阵a中是否存在元素a>α,若是,则记元素a对应的kpi值v为突变指标,kpi值v对应小区记为指标突变小区。α为预设的阈值。
值得说明的是,为了发挥经验门限检测方法和密度函数检测方法的优势并弥补两者的不足,本发明使用每个小区每个kpi的历史数据计算出该指标的门限值,基于这个门限值找到异常小区和异常kpi。之后,对于这些异常小区的异常kpi,本发明使用基于高斯核心的kde检测方法来判断该指标是否为突变指标,接着判断该小区是否为指标突变小区。这样可以尽可能的避免两种方法的弊端的同时,以尽可能高的准确率定位指标突变小区,帮助指导定点优化。
本发明的技术效果是毋庸置疑的。本发明解决了现有的经验门限检测方法门限无法实时更新和不完善的缺陷和密度函数存在非正常训练数据干扰和训练数据不足的问题。本发明使用历史数据来动态生成门限以检测得到异常小区和异常的kpi,并使用异常kpi的正常的历史数据作为训练数据来拟合高斯核心的kde,输出每个数据点的指标突变程度,以得到指标突变小区。该检测方法可精确定位指标突变小区,灵活性高,鲁棒性强,性能稳定。
附图说明
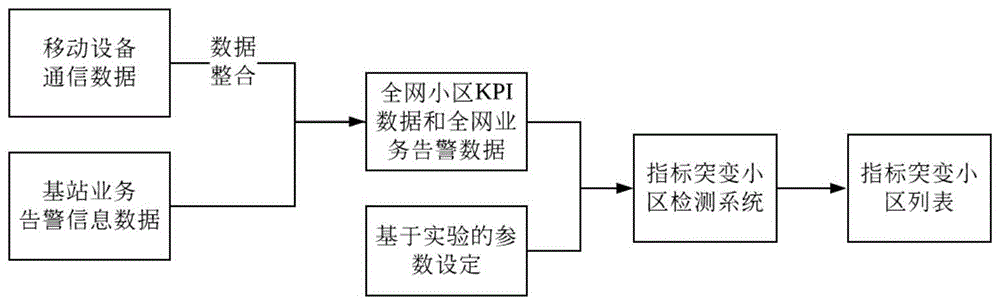
图1为网络中检测指标突变小区的过程示意图。
图2为指标突变检测系统的具体数据流程图。
具体实施方式
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
实施例1:
参见图1至图2,移动通信网络中基于异常检测和核密度估计(kde)的指标突变小区检测方法,主要包括以下步骤:
1)获取移动通信网络所有小区kpi(关键性能指标,keyperformanceindicator)数据序列,并对每个小区的关键性能指标kpi序列进行数据清洗,主要步骤如下:
1.1)基于设定的粒度g,筛选掉粒度不合规的小区。
1.2)基于设定的数据长度s=t/g,筛选掉时间长度不合规的小区。t为指标突变小区检测周期。
1.3)以0填充剩余小区缺失值。
1.4)基于业务告警信息,筛选掉业务告警小区。
2)基于清洗后的kpi序列,建立历史数据序列和测试数据序列。
进一步,历史数据序列为t0-t1时间段的kpi序列。测试数据序列为t2-t3时间段的kpi序列。t0为kpi序列起始时间。t1∈(t0,t3)为历史数据序列终结时间。t2∈(t0,t3)为测试数据序列起始时间。t3为kpi序列终结时间。
3)基于历史数据序列和测试数据序列,筛选掉全部kpi序列均正常的小区,保留异常小区,并记录每个小区的所有异常kpi的第一个发生异常的时间点t1st。
确定异常小区的主要步骤如下:
3.1)利用季节差分法对历史数据序列和测试数据序列进行差分。将差分后的历史数据序列和测试数据序列输入到加法模型中,得到历史趋势数据集和测试趋势数据集。
加法模型y[t]=t[t]+s[t]+e[t]。其中,t[t]、s[t]、e[t]为kpi差分后得到的三个分解因子。y[t]表示加法模型输出的历史趋势数据或测试趋势数据。
3.2)基于历史趋势数据集,分别计算不同小区中不同kpi序列的均值μ和标准差σ,并确定每个kpi的正常区间i。
kpi的正常区间i=(μ-ω×σ,μ+ω×σ)。ω为常数。
3.3)判断测试趋势数据集中每个元素是否位于对应kpi序列的正常区间i内,若否,则将对应kpi标记为异常指标,并将所述异常指标所在小区标记为异常小区。
4)利用基于高斯核的kde(核密度估计,kerneldensityestimation)计算异常小区差分前的异常kpi序列的异常分数,并建立异常分数矩阵a。
建立异常分数矩阵a的主要步骤如下:
4.1)以t0-t1st时间段的异常kpi序列作为kde的训练数据集,对kde进行训练。
4.2)以t1st-t3时间段的异常kpi序列作为kde的测试数据集,并将测试数据集输入到kde中。
4.3)利用kde对测试数据集拟合,计算出t1st-t3时间段的每个时间点对应的异常分数值,并取对数,得到每个时间点对应的异常分数。将异常分数写入异常分数矩阵a中。
5)判断异常分数矩阵a中是否存在元素a>α,若是,则记元素a对应的v关键性能指标kpi为突变指标,v对应小区记为指标突变小区。α为预设的阈值。
实施例2:
移动通信网络中基于异常检测和核密度估计(kde)的指标突变小区检测方法,主要包括以下步骤:
1)获取移动通信网络所有小区kpi序列,并对每个小区的kpi序列进行数据清洗。
2)基于清洗后的kpi序列,建立历史数据序列和测试数据序列。
3)基于历史数据序列和测试数据序列,筛选掉全部kpi序列均正常的小区,保留异常小区,并记录每个小区的所有异常kpi的第一个发生异常的时间点t1st。
4)利用基于高斯核的kde(kerneldensityestimation)计算异常小区差分前的异常kpi序列的异常分数,并建立异常分数矩阵a。
5)判断异常分数矩阵a中是否存在元素a>α,若是,则记元素a对应的kpi为突变指标,对应小区记为指标突变小区。α为预设的阈值。
实施例3:
移动通信网络中基于异常检测和核密度估计(kde)指标突变小区检测方法,主要步骤见实施例2,其中,确定异常小区的主要步骤如下:
1)利用季节差分法对历史数据序列和测试数据序列进行差分。将差分后的历史数据序列和测试数据序列输入到加法模型中,得到历史趋势数据集和测试趋势数据集。
加法模型y[t]=t[t]+s[t]+e[t]。其中,t[t]、s[t]、e[t]为kpi差分后得到的三个分解因子。y[t]表示加法模型输出的历史趋势数据或测试趋势数据。
2)基于历史趋势数据集,分别计算不同小区中不同kpi序列的均值μ和标准差σ,并确定每个kpi的正常区间i。
kpi的正常区间i=(μ-ω×σ,μ+ω×σ)。ω为常数。
3)判断测试趋势数据集中每个元素是否位于对应kpi序列的正常区间i内,若否,则将对应kpi标记为异常指标,并将所述异常指标所在小区标记为异常小区。
实施例4:
移动通信网络中基于异常检测和核密度估计(kde)的指标突变小区检测方法,主要步骤见实施例2,其中,建立异常分数矩阵a的主要步骤如下:
1)以t0-t1st时间段的异常kpi序列作为kde的训练数据集,对kde进行训练。
2)以t1st-t3时间段的异常kpi序列作为kde的测试数据集,并将测试数据集输入到kde中。
3)利用kde对测试数据集拟合,计算出t1st-t3时间段的每个时间点对应的异常分数值,并取对数,得到每个时间点对应的异常分数。将异常分数写入异常分数矩阵a中。
- 还没有人留言评论。精彩留言会获得点赞!