一种视频处理方法及系统与流程
本发明涉及视频处理技术领域,尤其涉及一种视频处理方法及系统,特别是适用于对视频的处理和动态目标识别的方法及系统。
背景技术:
随着移动设备拍照和摄像技术的发展,使用短视频记录我们的日常生活已成为一个日益明显的发展趋势。根据iimedia研究的短视频行业报告,仅在中国从移动设备上传到视频平台的视频数量就已经非常庞大,如“抖音”和“西瓜视频”上的短视频数量均已超过2000万。通过生活经验和实验证明,可以发现视频包含大量信息,例如异常事件、人人交互和人物交互。
而目前对视频中的信息进行识别和提取的比较好的方式之一即深度学习,具体而言一般都是用卷积神经网络(convolutionalneuralnetwork,cnn)对视频帧进行处理。但深度学习一般而言都有较大的计算任务量,因而也会带来较大的计算延迟,如文献1(l.n.huynh,y.lee,andr.k.balan,“deepmon:mobilegpubaseddeeplearningframeworkforcontinuousvisionapplications,”inproceedingsofthe15thannualinternationalconferenceonmobilesystems,applications,andservices(mobisys),2017.)所示,即使在移动设备gpu的支持下,对一个视频帧进行典型的cnn处理也需要600毫秒。
因此提高移动设备上执行深度学习任务的效率最近受到了很多关注,如文献2(m.xu,m.zhu,y.liu,f.x.lin,andx.liu,“deepcache:principledcacheformobiledeepvision,”inproceedingsofthe24thannualinternationalconferenceonmobilecomputingandnetworking(mobicom),2018.)提出deepcache,它使用输入帧内容作为缓存键,推理结果作为缓存值。利用视频中连续帧之间的信息冗余,deepcache可以在两帧之间重用缓存的推断结果,从而显著减少执行时间和能耗。此外还有如文献1中则通过分解cnn模型并将卷积层卸载到移动设备的gpu中来加快运算速度等提高移动设备深度学习任务效率的方法。
现有移动设备深度学习技术的这些工作中一部分是在移动设备上以单独的视频帧作为对象进行深度学习处理,即没有深入考虑到视频帧之间的关系,因而也就无法高效地识别出一个短视频中所包含的动作信息,另一部分则是关注于目标检测等静态信息,针对动态信息的识别有必要进行深入的研究。
技术实现要素:
本发明要解决的技术问题就在于:针对现有技术存在的技术问题,本发明提供一种可有效降低识别的延时,同时保证识别准确率的视频处理方法及系统。
为解决上述技术问题,本发明提出的技术方案为:一种视频处理方法,包括:
s1.将待处理视频中的帧进行分组,得到帧编组,并将所述帧编组(gof,groupofframe)内的帧划分为基础帧和变化帧;
s2.以延时最小作为优化目标,确定所述帧编组内的所述基础帧和所述变化帧的处理主体,并将其分配给所确定的所述处理主体;所述处理主体包括本地端和服务端;
s3.通过所述处理主体对所述基础帧和所述变化帧进行识别,得到识别结果。
进一步地,所述帧编组内的第一帧为基础帧,其余帧为变化帧。
进一步地,所述变化帧记录的数据信息包括所述变化帧与其前一帧的变化量;
所述变化量包括运动矢量和残差。
进一步地,所述步骤s1之前还包括预测步骤s0,具体包括:根据预设的准确率,通过智能算法模型预测所述帧编组的采样率和变化帧数量。
进一步地,步骤s2中所述以延时最小作为优化目标具体包括通过式(1)所示的目标函数进行优化:
式(1)中,lop为延迟优化问题的名称缩写(latencyoptimizationproblem),f(sgof,np)为在采样率sgof和变化帧数量np下所能实现的准确率,λ为预设的准确率,oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,sgof为采样率,np为帧编组内变化帧数量,qm(t)为根据所述分配情况,本地端处理所需要的时间,qs(t)为根据所述分配情况,服务端处理所需要的时间,t为视频的最大时长限制。
进一步地,步骤s2中所述以延时最小作为优化目标具体包括通过式(2)所示的目标函数进行优化:
式(2)中,mod-lop为简化后的延迟优化问题的名称缩写(modifiedlatencyoptimizationproblem),oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,qm(t)为根据所述分配情况,本地端处理所需要的时间,qs(t)为根据所述分配情况,服务端处理所需要的时间。
一种视频处理系统,包括帧编组模块、分配模块和结果处理模块;
所述帧编组模块用于将待处理视频中的帧进行分组,得到帧编组,并将所述帧编组内的帧划分为基础帧和变化帧;
所述分配模块用于以延时最小作为优化目标,确定所述帧编组内的所述基础帧和所述变化帧的处理主体,并将其分配给所确定的所述处理主体;所述处理主体包括本地端和服务端;
所述结果处理模块用于获取所述处理主体对所述基础帧和所述变化帧进行识别的结果,得到识别结果。
进一步地,所述帧编组内的第一帧为基础帧,其余帧为变化帧;所述变化帧记录的数据信息包括所述变化帧与其前一帧的变化量;所述变化量包括运动矢量和残差。
进一步地,还包括预测模块,用于根据预设的准确率,通过智能算法模型预测所述帧编组的采样率和变化帧数量。
进一步地,所述分配模块以延时最小作为优化目标,具体包括通过式(3)所示的目标函数进行优化:
式(3)中,lop为延迟优化问题的名称缩写(latencyoptimizationproblem),f(sgof,np)为在采样率sgof和变化帧数量np下所能实现的准确率,λ为预设的准确率,oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,sgof为采样率,np为帧编组内变化帧数量,qm(t)为根据所述分配情况,本地端处理所需要的时间,qs(t)为根据所述分配情况,服务端处理所需要的时间,t为视频的最大时长限制;
或者:
所述分配模块以延时最小作为优化目标,具体包括通过式(4)所示的目标函数进行优化:
式(4)中,mod-lop为简化后的延迟优化问题的名称缩写(modifiedlatencyoptimizationproblem),oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,qm(t)为根据所述分配情况,本地端处理所需要的时间,qs(t)为根据所述分配情况,服务端处理所需要的时间。
与现有技术相比,本发明的优点在于:
1、本发明通过将视频分组成由基础帧和变化帧组成的帧编组,以延时最小作为优化目标,为基础帧和变化帧分配处理主体,即将帧编组内的帧分配给本地端或服务端进行识别,既能保证识别的准确率,又可以大幅的降低图像处理的延时;使得用户感知的延时大大缩短。
2、本发明通过智能算法模型预测帧编组的采样率和变化帧数量,智能算法模型通过基于不同的帧编组的采样率sgof和变化帧数量np下的准确率来训练智能算法模型,通过训练好的智能算法模型,对于给定的准确率,智能算法模型就可以计算得出一组采样率sgof和变化帧数量np参数,可以满足准确的前提下,有效减少视频处理所需要的计算量。
附图说明
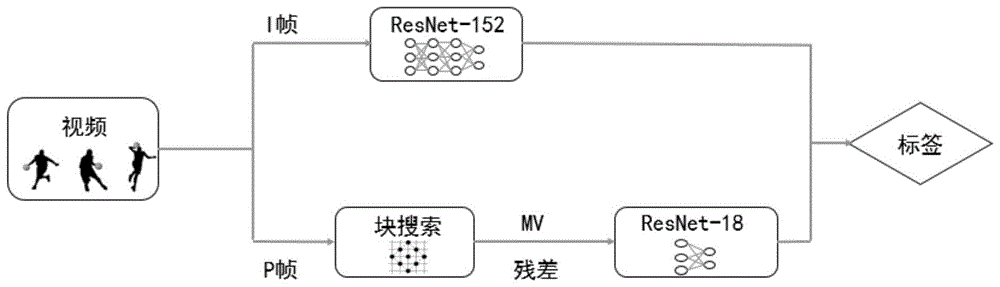
图1为本发明具体实施例视频动作识别过程的示意图。
图2为本发明具体实施例的系统框架体系结构示意图。
图3为本发明具体实施例gof到达时分配决策举例示意图。
图4为本发明具体实施例中准确率与采样率sgof和变化帧数量np之间的关系的示意图。
图5为本发明具体实施例resnet-18和resnet-152在移动设备小米mi8上运行的延迟情况。
图6为本发明具体实施例resnet-18和resnet-152在边缘服务器上运行的延迟情况。
图7为本发明具体实施例采取的opencl和renderscript(rs,用于移动设备的android操作系统的一个组件,它提供了一个利用异构硬件加速的api)两种方式对块搜索进行实现后所得到的延迟情况的对比图。
图8为本发明具体实施例采取的opencl和rs两种方式对块搜索进行实现下gpu的占用率情况图。
图9为本发明具体实施例对视频压缩采取了opencl和rs+jni(javanativeinterface)两种实现方式,并将视频压缩过程和i帧的推理过程并行后得到的延迟情况图。
图10为本发明具体实施例中不同信道和不同准确率要求下的对比情况图一。
图11为本发明具体实施例中不同信道和不同准确率要求下的对比情况图二。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
如图1和图2所示,本实施例的视频处理方法,包括:s1.将待处理视频中的帧进行分组,得到帧编组,并将帧编组内的帧划分为基础帧和变化帧;s2.以延时最小作为优化目标,确定帧编组内的基础帧和变化帧的处理主体,并将其分配给所确定的处理主体;处理主体包括本地端和服务端;s3.通过处理主体对基础帧和变化帧进行识别,得到识别结果。
在本实施例中,以移动设备(如智能手机等)为本地端,以与移动设备网络连接的边缘服务端为服务端为便进行说明。移动设备通过摄像头拍摄视频图像,再对所拍摄的视频图像的动作进行识别。本实施例中,具体以运行android9的小米mi8作为移动设备,以及运行ubuntu的台式计算机作为边缘服务端,台式计算机的cpu为intelcorei78700k,gpu为geforcertx2080,以ucf-101数据集对本方法的技术方案进行实现。
在本实施例中,步骤s1之前还包括预测步骤s0,具体包括:根据预设的准确率,通过智能算法模型(图2中的离线预测器)预测帧编组的采样率和变化帧数量。由于帧的采样率与动作识别的准确率之间存在函数关系,如图4所示,因此,在本实施例中,通过智能算法模型来学习采样率与动作识别的准确率之间存在的关系,即通过基于不同的帧编组的采样率sgof和变化帧数量np下的准确率来训练智能算法模型,训练好的智能算法模型就可以在给定准确率的情况下,计算得出一组采样率sgof和变化帧数量np参数。智能算法模型优选采用离线模型,预先将智能算法模型训练好,再加载到移动设备,计算出帧编组的采样率和变化帧数量。
在本实施例中,优选以f(sgof,np)为来表征帧的采样率与动作识别的准确率之间存在函数关系,并通过二元三次多项式来表征采样率sgof和变化帧数量np之间的关系,通过将多项式拟合到图4中的测量值,就可以得到采样率sgof和变化帧数量np。二元三次多项式可以如式(9)所示:
式(9)中,p00、p10、p20、p11、p02、p30、p21、p12、p03均为二元三次多项式系数,其余参数的定义与上文相同。如下表1是通过ucf-101数据集对二元三次多项式进行拟合的情况。
表1:
其中accuracysetting字段是智能算法模型的输入,sampledgof是由于在系统实际运行中gof的采样是离散的,所以转化成分数的形式,data(1261)中的1261表示在ucf-101数据集的测试集中选择进行测试的视频数量,字段下的元组内容表示实际测试得到的准确率,gap表示实际测出的准确率和输入的准确率要求的差值。
在本实施例中,帧编组内的第一帧为基础帧(i帧,i-frame),其余帧为变化帧(p帧,p-frame)。变化帧记录的数据信息包括变化帧与其前一帧的变化量;变化量包括运动矢量和残差。优选,变化量使用其前一帧为参考,仅编码其自身与前一帧之间的变化量,变化量由运动矢量(motionvector,mv)和残差两部分组成,运动矢量表示两帧之间像素块的移动,通过块搜索(blocksearch)的方式获取残差表示基础帧与从运动矢量所恢复的帧之间的差异。本实施例中,通过opencl和renderscript(rs)两种块搜索方式的延迟情况如图7所示。通过opencl和rs两种块搜索方式的gpu占用率情况如图8所示。
在本实施例中,优选以大型cnn模型resnet-152来识别基础帧,以小型cnn模型resnet-18来识别变化帧(即识别运动矢量和残差)。通过过滤掉帧之间的冗余信息,cnn模型可以显著降低动作识别的复杂性,同时实现更好的准确性能。在每个帧编组中,所有的变化帧的运动矢量和残差分别被累加到一起来增强变化帧所包含的信息,并减少变化帧在cnn模型(resnet18)中的推理次数。cnn模型resnet-152和cnn模型resnet-18均为深度学习模型。
在本实施例中,如图2所示,在划分了帧编组,确定了帧编组内的基础帧和变化帧后,将基础帧、变化帧分配给本地端处理和分配给服务端处理,所花费的时间不同,用户能够感受到的延时也不相同,本实施例中,通过图2中的在线调度器实现对基础帧和变化帧的分配,系统分析器用于获取系统状态。因此,本实施例中,通过以延时最小作为优化目标,确定帧编组内的基础帧和变化帧的处理主体,并将其分配给所确定的处理主体。步骤s2中以延时最小作为优化目标具体包括通过式(1)或式(2)所示的目标函数进行优化。
在本实施例中,式(1)为:
式(1)中,lop为延迟优化问题的名称缩写(latencyoptimizationproblem),f(sgof,np)为在采样率sgof和变化帧数量np下所能实现的准确率,λ为预设的准确率,oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,sgof为采样率,np为帧编组内变化帧数量,qm(t)为根据分配情况,本地端处理所需要的时间,qs(t)为根据分配情况,服务端处理所需要的时间,t为视频的最大时长限制。
由于本实施例采用智能识别模型来预测采样率sgof和变化帧数量np,因此,也可以从式(1)所示中的(lop)中去除采样率sgof和变化帧数量np,并将其减化为调度问题,以分配决定oi(t)和op(t)作为变量。同时,考虑系统状态的变化,qs(t)和qm(t)的值在连接的帧编组到达的过程中会发生变化,因此,可以将目标函数优化为式(2)所示:
式(2)中,mod-lop为简化后的延迟优化问题的名称缩写(modifiedlatencyoptimizationproblem),oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,qm(t)为根据分配情况,本地端处理所需要的时间,qs(t)为根据分配情况,服务端处理所需要的时间。qm(t)和qs(t)由系统分析器获取的系统状态确定,并在一个帧编组完成后更新。
在本实施例中,对于深度学习模型,移动设备采用了专为移动设备所设计的深度学习框架tensorflowlite,边缘服务器端采用pytorch。
在本实施例中,当基础帧和/或变化帧分配给服务端处理时,先将基础帧和/或变化帧进行压缩,再通过网络发送给服务端进行处理。在压缩过程中,对于基础帧,根据h.264标准使用帧内预测,以离散余弦变换(discretecosinetransform,dct)和熵编码(entropyencoding,ec)来压缩帧。在运动矢量和残差的情况下,直接运行dct和ec以进行压缩,为避免对精度的影响,通过去除了量化过程来达到无损压缩。压缩后的数据进行打包,并通过tcp/ip协议发送给服务端。服务端在接收到时,使用解码器(decoder)解码数据,然后运行cnn模型识别帧中的动作,得到所识别出的各动作的分数。而由本地端来识别基础帧和/或变化帧时,移动设备直接通过cnn模型对基础帧和/或变化帧中的动作进行识别,得到所识别出的各动作的分数。再将各动作的分数加权求和后,以得分最高的动作作为识别结果(即标签)。为了提高基于压缩的深度学习模型推理的性能,使用了opencl来实现移动gpu上的压缩相关操作,这样在移动设备cpu上运行的推理可以与视频压缩并行。如图9所示,本实施例中,对视频压缩采取了opencl和rs+jni(javanativeinterface)两种实现方式,并将视频压缩过程和i帧的推理过程并行后得到的延迟情况。其中图9中所例“基准线”表示仅i帧推理单独运行时的延迟情况,“opencl实现”表示在opencl实现的视频压缩和i帧推理并行下的延迟情况,“rs+jni实现”表示在rs+jni实现的视频压缩和i帧推理并行下的延迟情况。
在本实施例中,移动设备在oi(t)和op(t)上有四种情形。不同的选择下对于qs(t)和qm(t)将会有不同的更新规则,在此基础上我们选择最优的分配决定来最小化(mod-lop)目标函数的值。由于当t时刻帧编组gof到达时,t-1时刻的gof的计算可能无法完成,因此使用g(t)来表示第(t-1)和第t个帧编组gof之间的时间间隔。剩余的计算时间可用rs(t)=max(qs(t-1)-g(t),0)和rm(t)=max(qm(t-1)-g(t),0)来表示,rs(t)、rm(t)分别用于表示服务端和移动设备剩余的计算时间。oi(t)=0表示基础帧分配给本地端处理,oi(t)=1表示基础帧分配给服务端处理;op(t)=0表示变化帧分配给本地端处理,op(t)=1表示变化帧分配给服务端处理。帧编组到达时分配决策处理的时间如图3所示,在t=1时,在线调度器决定将i帧卸载到边缘服务器,并保留p帧在本地计算,即oi(t)=1和op(t)=0,qm(t)和qs(t)是根据系统分析器提供的系统状态获得的,并在gof完成后更新。用户感知的延迟是最后一个到处理的gof的到达和完成之间的时间间隔,例如,图3中的第二个到处理的gof。
情形一:oi(t)=0,op(t)=0,即将t时刻到达的帧编组gof的基础帧(i帧)和变化帧(p帧)均留在本地端计算,那么,其延时如式(5)所示:
式(5)中,di,m(t)为t时刻所预测的在移动设备上运行resnet-152的延迟,dsch(t)为t时刻块搜索获取p帧所需信息的延迟,dp,m(t)表示t时刻在移动设备上运行resnet-18的延迟,其余参数的定义与上文相同。由于使用gpu来获取mv和残差,所以di,m(t)和dsch(t)可以并行。在移动设备小米mi8上运行resnet-18和resnet-152的延迟情况如图5所示。
情形二:oi(t)=1,op(t)=1,即将t时刻到达的帧编组gof中的i帧和p帧均分配给服务端处理,即移动设备需要将帧编组内的帧进行压缩,然后再发送给边缘服务器,边缘服务器等待数据到达并接收后,然后分别在i帧和p帧上运行resnet-152和resnet-18,边缘服务器等待数据的时间等于视频压缩和数据传输的总和。那么,其延时如式(6)所示:
式(6)中,i帧和p帧具有压缩和获取延迟di,c(t)+dsch(t)+dp,c(t),其中di,c(t)表示t时刻预测压缩i帧的延迟,dp,c(t)表示t时刻预测压缩p帧的延迟,di,w(t)为t时刻预测的i帧的等待时间,dp,w(t)为t时刻预测的p帧的等待时间,di,s(t)为t时刻预测的在边缘服务器上运行resnet-152的延迟,dp,s(t)为t时刻预测的在边缘服务器上运行resnet-18的延迟,其余参数的定义与上文相同。在边缘服务器上运行resnet-18和resnet-152的延迟情况如图6所示。
情形三:oi(t)=0,op(t)=1,即将t时刻到达的帧编组gof中的i帧分配给本地端,而p帧均分配给服务端处理,在移动设备的cpu上运行的resnet-152可以和在gpu上运行的blocksearch以及p帧压缩并行,边缘服务器在等待计算任务达到的过程中可以进行剩余的计算。那么,其延时如式(7)所示:
式(7)中,各参数的定义与上文相同。
情形四:oi(t)=1,op(t)=0,即将t时刻到达的帧编组gof中的i帧分配给服务端,而p帧均分配给本地端处理,在移动设备的cpu上运行的resnet-18可以和在gpu上运行的i帧压缩并行,边缘服务器在等待计算任务达到的过程中可以进行剩余的计算。那么,其延时如式(8)所示:
式(8)中,各参数的定义与上文相同。
在本实施例中,在以较差的4种无线信道状态和3种不同的准确率要求的组合下,将“deepaction”和“本地执行”两种情况进行对比如图10所示(图10中,(a)、(b)、(c)分别表示三种不同情况组合),图例deepaction表示采用了本方法的完整执行流程所得到的结果,“本地执行”表示没有采用方法,而是将采样得到的结果全部放在本地计算。从图中可以看出即使信道状态极差的情况(带宽=0.75mbps)下,deepaction依旧可以有效降低计算时延。
在本实施例中,在以较好的4种无线信道状态和3种不同的准确率要求的组合下,将“deepaction”、“本地执行”和“远程执行”三种情况进行对比如图11所示(图11中,(a)、(b)、(c)分别表示三种不同情况组合),图例“deepaction”表示采用了本方法的完整执行流程所得到的结果,“本地执行”表示没有采用方法,而是将采样得到的结果全部放在本地计算得到的结果,图例“远程执行”表示没有采用本方法,而是将所有帧全部分配给边缘服务器上进行计算得到的结果。从图中可以看出即使在信道状态极佳的情况(带宽=93.84mbps)下,deepaction相比于“远程执行”依旧可以有效降低计算时延。
本实施例的视频处理系统,包括帧编组模块、分配模块和结果处理模块;帧编组模块用于将待处理视频中的帧进行分组,得到帧编组,并将帧编组内的帧划分为基础帧和变化帧;分配模块用于以延时最小作为优化目标,确定帧编组内的基础帧和变化帧的处理主体,并将其分配给所确定的处理主体;处理主体包括本地端和服务端;结果处理模块用于获取处理主体对基础帧和变化帧进行识别的结果,得到识别结果。帧编组内的第一帧为基础帧,其余帧为变化帧;变化帧记录的数据信息包括变化帧与其前一帧的变化量;变化量包括运动矢量和残差。
在本实施例中,还包括预测模块,用于根据预设的准确率,通过智能算法模型预测帧编组的采样率和变化帧数量。分配模块以延时最小作为优化目标,具体包括通过式(3)所示的目标函数进行优化:
式(3)中,lop为延迟优化问题的名称缩写(latencyoptimizationproblem),f(sgof,np)为在采样率sgof和变化帧数量np下所能实现的准确率,λ为预设的准确率,oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,sgof为采样率,np为帧编组内变化帧数量,qm(t)为根据分配情况,本地端处理所需要的时间,qs(t)为根据分配情况,服务端处理所需要的时间,t为视频的最大时长限制;
或者:
分配模块以延时最小作为优化目标,具体包括通过式(4)所示的目标函数进行优化:
式(4)中,mod-lop为简化后的延迟优化问题的名称缩写(modifiedlatencyoptimizationproblem),oi(t)为第t个帧编组到达时基础帧的分配决定,op(t)为第t个帧编组到达时变化帧的分配决定,qm(t)为根据分配情况,本地端处理所需要的时间,qs(t)为根据分配情况,服务端处理所需要的时间。
通过本实施例的系统,可以实现上述处理方法,有效降低识别的延时,同时保证识别准确率。
上述只是本发明的较佳实施例,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭露如上,然而并非用以限定本发明。因此,凡是未脱离本发明技术方案的内容,依据本发明技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均应落在本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!