信息处理装置和信息处理方法与流程
本文公开的技术涉及一种信息处理装置和一种信息处理方法,该信息处理装置和信息处理方法基于包括对环境的识别和对用户动作的识别的情境识别,以适当的形式控制声音信息并将其呈现给在环境中做出动作的用户。
背景技术:
为了辅助视觉障碍者做出动作,已经开发了从三维声响空间提供声响信息的系统。例如,提出了:行走训练环境生成系统,其通过任意设置行走训练环境来生成虚拟声响空间,该行走训练环境包括例如可移动声源或墙壁(例如,参考专利文献1);耳机,其包括一组输入机构,该输入机构从用户接收用于调用将由空间交互模块实现的空间交互相关功能的相应命令,并且当用户与空间进行交互时,向用户呈现音频信息(例如,参考专利文献2);头戴式计算装置,其通过音频输出在环境中提供导航辅助(例如,参考专利文献3)等。
引用列表
专利文献
专利文献1:日本专利申请公开号2006-163175
专利文献2:pct国际申请号2018-502360的日文翻译
专利文献3:pct国际申请号2017-513535的日文翻译
技术实现要素:
技术问题
专利文献1中公开的系统能够通过基于预先定义的道路环境元素、声音元素和墙壁元素在三维空间中生成声响数据来向用户提供虚拟训练环境。
此外,专利文献2中公开的耳机通过骨传导提供音频信息,因此不关闭用户的耳道。该头戴式耳机能够在佩戴该头戴式耳机的用户在两个地方之间移动时生成路线,并且能够在用户沿着路线移动时,通过根据基于经由各种传感器掌握的绝对位置/相对位置信息和从地图掌握的障碍信息的确定,或者根据从设置在空间中的信标发送的信息,经由语音信息等向用户给出一系列提示,来向用户提供导航引导。此外,通过该耳机向用户提供用于与诸如手势输入之类的工具进行交互的方法,这使得该耳机能够提供的引导对用户友好且不引人注目。
此外,专利文献3中公开的头戴式计算装置能够向听力受损的用户提供导航辅助,例如,通过向用户提供距离信息,该距离信息的提供包括通过使用深度图像数据和可见光传感器系统掌握环境来掌握对象的物理特性,并且基于用户的头部相关传递函数,或者通过改变音量,来从三维声响空间中的特定位置生成称为音频导航提示的声音信息。
然而,当基于从信标发送的信息向佩戴专利文献2中公开的耳机的用户提供语音信息时,由于耳机不关闭用户的耳道,所以用户可能无法区分所提供的语音信息和要从真实环境直接发送到耳朵的环境语音。此外,如专利文献2和专利文献3中所公开的,即使当设置信标等时,如果发送了过量的信息,则存在用户在不依赖于视觉信息的情况下在真实空间中使用导航引导时可能被过量的信息所混淆的风险。
鉴于这种情况,本文公开了一种信息处理装置和信息处理方法,其允许将声响信息呈现给在真实环境中动作的用户,该声响信息允许用户基于使用传感器信息对环境的识别以及考虑例如用户在环境中的状况和动作的情境的识别,有利地将虚拟声音或要在三维声响空间中人工再现的语音与真实环境中的环境声音(包括语音)彼此区分开来。信息处理装置和信息处理方法还允许根据用户的需要或状况(例如,环境和情境)适当地控制在三维声响空间中再现的虚拟声音信息或语音信息的量。
问题的解决方案
本文公开的技术已经用于解决上述问题。根据第一方面,提供了一种信息处理装置,包括:
传感器,其检测对象;
耳朵开放式耳机,其戴在收听者的耳朵上,并且包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中;以及
处理单元,其处理声源的声音信息,所述声音信息是由所述声响生成单元生成的,
所述处理单元进行如下处理:
获取与由所述传感器检测到的对象相对应的声源的声音信息,并且
在根据三维声响空间中的位置相关地改变声像的位置的同时定位所获取的声源的声像,所述三维声响空间中的位置对应于检测到的对象的位置。
根据第一方面的信息处理装置具有两种或多种感测模式,包括
正常模式,其中,传感器在传感器的正常检测区域中执行检测,
白手杖模式,其中,传感器在比正常模式下的正常检测区域小的检测区域中执行检测。
在白手杖模式下,当传感器检测到收听者周围的预定范围内的区域中的对象时,所述处理单元执行在改变声像的位置的同时定位声源的声像的处理。
此外,根据本文公开的技术的第二方面,提供了一种信息处理装置,包括:
传感器,其检测对象;
耳朵开放式耳机,其戴在收听者的耳朵上,并且包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中;以及
处理单元,其处理声源的声音信息,由所述声响生成单元生成所述声音信息,
所述处理单元进行如下处理:
获取与由所述传感器检测到的所述对象相关的由信息提供单元提供的信息对应的声源的声音信息,以及
在选择声音信息的类型并控制声音信息的量的同时定位所获取的声源的声像。
此外,根据本文公开的技术的第三方面,提供了一种信息处理装置,包括
耳朵开放式耳机,包括:
声响生成单元,其设置在收听者的耳朵的后部,以及
声音引导部,
其具有经由耳垂附近从耳朵的耳廓后部向后折叠到耳朵的耳廓前部的结构,并且
将由声响生成单元生成的声音发送到耳孔中;
传感器,其获取外部信息;以及
处理器,在选择了多种模式下的任何一种模式的状态下操作所述信息处理装置,
所述处理器
基于经由传感器获取的外部信息再现外部三维空间,
生成虚拟声音信息,用于使声响生成单元根据从多种模式下选择的模式生成声音,并且
定位在三维空间中位置随时间变化的声源的声像。
此外,根据本文公开的技术的第四方面,提供了一种信息处理方法,包括:
检测对象的步骤;
获取与检测到的对象相对应的声源的声音信息的步骤;
执行在根据三维声响空间中的位置改变声像的位置的同时定位所获取的声源的声像的处理的步骤,所述三维声响空间中的位置对应于检测到的对象的位置;以及
从耳朵开放式耳机输出声像的声音的步骤,包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中。
此外,根据本文公开的技术的第五方面,提供了一种信息处理方法,包括:
检测对象的步骤;
获取与相对于检测到的对象提供的信息相对应的声源的声音信息的步骤;
执行在选择声音信息的类型并控制声音信息的量的同时定位所获取的声源的声像的处理的步骤;以及
从耳朵开放式耳机输出声像的声音的步骤,包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中。
发明的有益效果
根据本文公开的技术,可以提供信息处理装置和信息处理方法,该信息处理装置和信息处理方法允许通过使收听者戴上耳朵开放式耳机来向在真实环境中动作的收听者呈现声响,该声响允许用户有利地将在三维声响空间中人工再现的虚拟声音和真实环境中的声音彼此区分开来。
本文公开的信息处理装置能够不仅基于使用传感器信息对环境的识别以及考虑例如用户在环境中的动作对情境的识别,而且基于用户的选择或自动选择,通过控制声音信息的呈现方法(该方法不限于用于将虚拟声音和环境声音彼此区分开来的上述方法)和控制信息量来控制在三维声响空间中提供的声音信息(将被声响配置的信息,例如,虚拟声音信息)的呈现级别。通过这种方式,本文公开的信息处理装置能够有助于增强(或扩展)收听者的听觉能力。
此外,本文公开的信息处理装置不仅具有有助于增强听觉能力的能力,而且还具有装置或系统的功能,该装置或系统不仅基于使用传感器信息对环境的识别以及考虑例如用户在环境中的动作对情境的识别,而且基于用户的选择或自动选择,来控制和呈现要在三维声响空间中人工提供的声音信息和信息量的呈现方法。此外,本文公开的信息处理装置还具有信息处理装置或信息处理系统的功能,该信息处理装置或信息处理系统通过经由麦克风或各种传感器获取外部信息,并且通过单独或与服务器装置协作执行信息处理,来生成要呈现给收听者的虚拟声音信息。此外,本文公开的信息处理装置具有助听器的功能。
注意,本文描述的优点仅仅是示例,因此本发明的优点不限于此。此外,除了这些优点,本发明还可以提供其他优点。
通过以下实施方式和基于附图的更详细描述,本文公开的技术的其他目的、特征和优点将变得显而易见。
附图说明
[图1]图1是信息处理装置100的前视图;
[图2]图2是从其左手侧观察的信息处理装置100的透视图;
[图3]图3是示出信息处理装置100佩戴在收听者左耳上的状态的示图;
[图4]图4是示出信息处理装置100如何将声波输出到收听者的耳朵中的示图;
[图5]图5是示出信息处理装置100的主体中的相应功能模块的设置示例的示图;
[图6]图6是示出信息处理装置100的另一主体中的相应功能模块的另一设置示例的示图;
[图7]图7是示出信息处理装置100的功能配置示例的示图;
[图8]图8是示出信息处理装置100的另一功能配置示例(其中,提供麦克风阵列天线的配置示例)的示图;
[图9]图9是示出收听者如何沿着信息处理装置100的外壳表面上的触摸传感器514滑动他/她的手指的示图;
[图10]图10是示出收听者如何用他/她的手指轻敲信息处理装置100的外壳表面上的触摸传感器514的示图;
[图11]图11是示出经由提供给智能手机1100的用户界面来控制信息处理装置100的示例的示图;
[图12]图12是示出信息处理装置100的又一功能配置示例(其中,增强学习/估计功能的配置示例)的示图;
[图13]图13是示出神经网络加速器555的配置示例的示图;
[图14]图14是示出包括信息处理装置100的主体部1401和功能增强部1402的听觉能力增强系统1400的配置示例的示图(分离状态);
[图15]图15是示出包括信息处理装置100的主体部1401和功能增强部1402的听觉能力增强系统1400的配置示例的示图(耦合状态);
[图16]图16是示出包括信息处理装置100的主体部1401和功能增强部1402的听觉能力增强系统1400的功能配置示例的示图;
[图17]图17是示出了利用hrtf执行声像定位的系统的示例的示图;
[图18]图18是举例说明如何通过应用图17所示的系统1700从作为声源的多个对象执行同时再现的示图;
[图19]图19是描绘可以基于深度传感器512的检测结果来掌握的空间识别状态的图像的示例的示图;
[图20]图20是示出如何在三维声响空间中移动和定位声像的示图;
[图21]图21是示出如何在三维声响空间中移动和定位另一声像的示图;
[图22]图22是示出如何在三维声响空间中移动和定位又一声像的示图;
[图23]图23是示出如何在三维声响空间中移动和定位又一声像的示图;
[图24]图24是示出如何在另一三维声响空间中移动和定位又一声像的示图;
[图25]图25是示出如何在其他三维声响空间中移动和定位其他声像的示图;
[图26]图26是示出用于设置要提供的信息级别的系统的示图;
[图27]图27是示出声音模式和感测模式的组合之间的状态转换关系的示图;
[图28]图28是示出感测模式的示图;
[图29]图29是示出收听者视场中的图像的示例的示图;
[图30]图30是示出根据深度传感器512的检测结果从图29所示的收听者的视场识别的三维声响空间的示图;
[图31]图31是示出虚拟声音如何在图30所示的三维声响空间中传播的示图;
[图32]图32是示出信息处理装置100在白手杖模式下的操作示例的示图;
[图33]图33是示出用于虚拟声源呈现(声音线索)的ble信标的帧格式的示例的示图;
[图34]图34是示出虚拟声音信息(电梯开关对象)的配置示例的列表;
[图35]图35是示出为电梯开关设置的局部极坐标系统的示图;
[图36]图36是示出虚拟声源的声像的定位位置的示图,虚拟声源引导收听者向电梯开关发出远程指令;
[图37]图37是示出如何移动和定位引导收听者向电梯开关发出远程指令的虚拟声源的声像的示图;
[图38]图38是示出收听者如何经由信息处理装置100发出选择电梯的向上按钮的远程指令的示图;
[图39]图39是示出收听者如何经由信息处理装置100发出选择电梯的向下按钮的远程指令的示图;
[图40]图40是示出移动和定位引导收听者向电梯开关发出远程指令的虚拟声源的声像的另一示例的示图;
[图41]图41是示出收听者经由信息处理装置100发出做出关于电梯开关的选择的远程指令的另一示例的示图;
[图42]图42是示出引导收听者直接操作电梯开关的虚拟声源的声像的定位位置的示图;
[图43]图43是示出如何移动和定位引导收听者直接操作电梯开关的虚拟声源的声像的示图;
[图44]图44是示出在白手杖模式下由信息处理装置100执行的处理的流程图;
[图45]图45是示出用于呈现虚拟声音的详细处理的流程图;
[图46]图46是示出响应于由虚拟声音引导的收听者的远程指令来控制目标装置的详细处理的流程图;
[图47]图47是示出个人代理和声响空间控制软件的处理之间的关系的示例的示图;
[图48]图48是示出感测处理的流程图;
[图49]图49是示出情境识别处理的流程图;
[图50]图50是示出对象识别处理的流程图;
[图51]图51是示出与信息处理装置100协作的自主移动装置5100的功能配置示例的示图;
[图52]图52是示出自主移动装置5100的软件和信息处理装置100的软件的协作处理的示例的示图;
[图53]图53是示出由自主移动装置的个人代理执行的情境识别处理的流程图;
[图54]图54是示出三维声响空间生成处理的流程图;
[图55]图55是示出电梯对象的定义的列表;
[图56]图56是示出信息处理装置100的模式转换的示图;
[图57]图57是示出信息处理装置100的一些传感器的设置位置的示例的示图。
具体实施方式
在下文中,参考附图详细描述了本文公开的技术的实施方式。首先,本文使用的术语的简要定义如下。
除非另有说明,本文的短语“声音(包括语音)”包括以下三种类型的声音。
(a)自然环境声音(包括语音)从周围环境原样进入耳朵
(b)对通过临时记录或存储(包括缓冲)环境声音而获得的音频数据(例如,记录的自然语音的数据和音乐流的数据)进行的通过信号处理(包括噪声处理、放大、衰减等)而获得的经处理的声音(包括语音)
(c)基于基本声源数据(例如,标准语音数据和pcm(脉码调制)数据)人工处理或合成的虚拟声音(包括语音)
注意,具体地,短语“虚拟声音(包括语音)”或“虚拟声音”表示(b)和(c),短语“自然声音(包括语音)”表示(a)。此外,除非另有说明,“环境声音”包括“环境语音”。
此外,除非另有说明,本文的“耳机”是指一种装置,其中,用于向耳朵提供声音的声响生成单元以如下形式容纳在其外壳中:例如可以佩戴在人耳上的头戴式耳机、耳机、听筒和助听器的形式,更具体地,以例如头顶式、耳挂式和耳道式。
此外,本文的云是指通用云计算。云通过互联网等网络提供计算服务。当在更靠近网络上服务的信息处理装置的位置执行计算时,这种计算也称为边缘计算、雾计算等。本文的云可以被解释为用于云计算(计算资源(例如,处理器、存储器以及无线或有线网络连接设施)的网络环境或网络系统。或者,云也可以被解释为以云的形式提供的服务或提供者。
服务器装置是指至少一台计算机(或计算机的集合),其主要以计算提供计算服务。换言之,“服务器装置”在本文可以指独立的计算机,或者计算机的集合(组)。
除非另有说明,“服务器装置”的处理可以由直接与本文公开的信息处理装置执行信息(数据和控制)通信的单个计算机来处理,或者可以由不止一个计算机的集合基于从信息处理装置提供的信息以分布式方式来处理。在这种情况下,一台或多台计算机可以作为虚拟化提供,以由提供者管理。或者,就像iot(物联网)的雾计算一样,一台或多台计算机可以安装在世界各地。一些计算机可以充当传感器节点并执行所需的信息收集处理,其他计算机可以执行在网络上中继数据通信的处理,还有其他计算机可以管理数据库中的信息,还有其他计算机可以执行与人工智能相关的处理,例如,学习和估计(推断)。
注意,按以下顺序进行描述。
1.第一实施方式
1.1耳朵开放式耳机
1.2功能配置示例
1.3增强功能分离型装置的配置示例
1.4听觉能力增强空间识别功能
1.5控制要提供的信息级别的功能
2.网络系统
3.程序
4.变型例
1.第一实施方式
首先,下面描述实现听觉能力(或听力)增强的信息处理装置的实施方式。本文公开的信息处理装置不限于该实施方式,并且可以具有耳朵开放式耳机的配置(例如,以例如可以佩戴在人耳上的头戴式耳机、耳机、听筒和助听器的形式,更具体地,以例如头顶式、耳挂式和耳道式的这些形式)。本文公开的信息处理装置能够不仅基于使用传感器信息对环境的识别以及考虑例如用户在环境中的状况和动作对情境的识别,而且基于收听者的选择或自动选择,通过设置人工地或虚拟地通过例如信号处理在三维声响空间中经由耳机提供的声音(包括语音)的声音信息提供级别,来控制呈现要提供的虚拟声音信息和信息量的方法。通过这种方式,可以增强(或扩展)收听者的听觉能力。注意,在本文中,通过将信息处理装置的耳机部分戴在他/她的耳朵上来享受听觉能力增强功能的用户称为“收听者”
1.1耳朵开放式耳机
(1)耳朵开放式耳机的概述
称为耳道式的耳机有一个基本上封闭耳道的密封结构。因此,令人尴尬的是,收听者自己的语音和咀嚼声(在下文中,统称为“自己的声音”)与耳道打开的状态下的语音和咀嚼声不同,这经常引起收听者的不适感。这可能是因为自己的声音通过骨骼和肌肉发射到密封的耳道,然后发送到耳膜,其低音范围增强。相反,耳朵开放式耳机不具有封闭耳道的密封结构,因此不会发生这种现象。因此,可以减轻收听者的尴尬和不适感。
此外,在耳孔的入口附近,耳朵开放式耳机不会用用于再现的结构(例如,耳道式耳机的耳塞)来封闭整个耳孔(至少打开耳孔的一部分)。这种结构允许收听者直接听到环境声音。(实现了声透射率)。因此,佩戴耳朵开放式耳机的收听者可以收听要由音频装置再现的语音信息(例如,音乐和来自无线电或网络的信息语音,在下文中统称为“再现声音”),同时,可以自然地听到环境声音。即使使用耳朵开放式耳机,用户也可以正常使用依赖于听觉特征的人类功能,例如,空间识别、风险感知、交谈以及在交谈处理中对细微差别的把握,以立即响应周围人的呼叫,并像往常一样享受交谈。
同时,在同时收听真实环境声音和从耳朵开放式耳机再现的声音时,用户可能会因为不能将环境声音和再现的声音彼此区分而感到困惑。当然,环境声音与“正常听到的声音”相同,并且在人脑中,环境中的多个声源的相应声像被定位成与这些声源的相应位置具有适当的距离感。同时,关于再现的声音,当在耳道附近再现声音或音乐时,再现的声音的声像被定位在收听者附近的位置。类似地,也是在收听者以立体声模式收听诸如声音或音乐之类的再现声音时,声像在靠近收听者的位置被侧向化(lateralized)。因为环境声音和再现的声音在距离感和以这种方式听到的方式上彼此不同,所以当收听者同时收听这两种声音时,会出现“收听疲劳”等。因此,收听者需要时间才能识别声音信息。例如,当收听者在听音乐的同时环境声音中开始响起警报时,可能会延迟切换到听觉上聚焦的目标。
为了解决由环境声音和例如再现的声音之间的距离感和听到方式的差异引起的问题,根据该实施方式的耳朵开放式耳机通过信号处理将来自耳朵开放式耳机的再现声音(例如,语音和音乐)的声像虚拟地定位在期望的位置,然后在耳道附近再现该再现的声音(即,再现虚拟声音)。此外,这种耳朵开放式耳机提供与环境声音的环境相协调的虚拟声音的声源,或者控制听到虚拟声音的方式,就像其声源出现在自然空间中一样。通过这种方式,收听者的收听疲劳可以减轻。这允许收听者参考收听者在他/她的大脑中掌握的声像图来选择性地收听环境声音和虚拟声音(包括语音)。同样通过这种方式,可以减轻收听者的收听疲劳。
这种人工声像定位可以称为“声响ar”,作为在视频领域中众所周知的ar(增强现实)的声响版本。此外,这种人工声像定位可被视为虚拟声音(包括语音)在环境声音上的叠加。注意,使用耳朵开放式耳机覆盖的声音有以下三种类型。
(a)自然环境声音(包括语音)从周围环境原样进入耳朵
(b)对通过临时记录或存储(包括缓冲)环境声音而获得的音频数据(例如,记录的自然语音的数据和音乐流的数据)进行的通过信号处理(例如,噪声处理、放大、衰减等)而获得的经处理的声音(包括语音)
(c)基于基本声源数据(例如,标准语音数据和pcm(脉码调制)数据)人工处理或合成的虚拟声音(包括语音)
注意,具体地,短语“虚拟声音(包括语音)”表示(b)和(c),并且短语“自然声音(包括语音)”表示(a)。
(2)能够增强听觉能力的信息处理装置的实施方式
描述了能够增强听觉能力的信息处理装置的基本结构。信息处理装置是主要具有呈现语音信息的功能的语音信息处理装置或语音信息处理系统。然而,从如下所述具有在三维声响空间中增强收听者的听觉能力的功能的观点来看,在另一方面,信息处理装置也是“听觉能力增强装置”。此外,从通过信息处理来补偿收听者所需的“声音”的观点来看,在又一方面,信息处理装置具有助听器的功能。
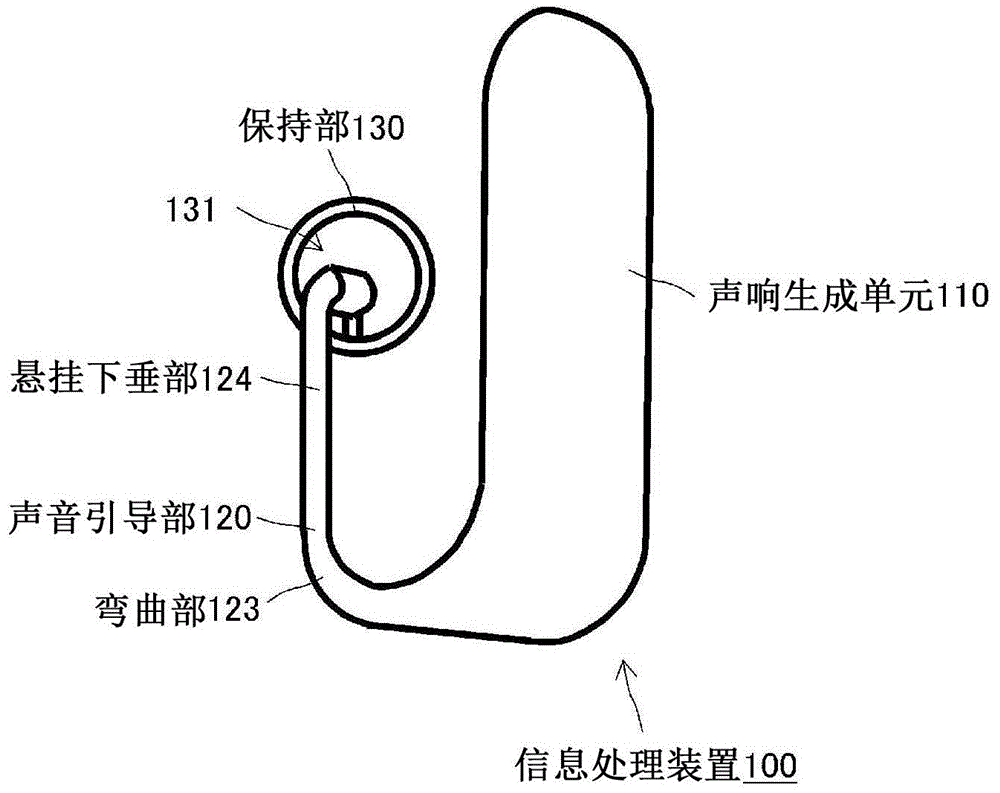
图1至图3示出了应用本文公开的技术的信息处理装置100的示例。如图1至图3所示,该信息处理装置100使用耳朵开放式耳机,并将再现的声音呈现给佩戴该耳朵开放式耳机的收听者。如下所述,信息处理装置100能够通过经由耳朵开放式耳机将再现声音的声像定位在人工位置来增强收听者的听觉能力。
图1是信息处理装置100的前视图。图2是从其左手侧观察的信息处理装置100的透视图。图3是示出信息处理装置100佩戴在收听者左耳上的状态的示图。注意,尽管图1至图3中例示的信息处理装置100的耳朵开放式耳机被配置为佩戴在收听者的左耳上,但是耳朵开放式耳机可以被配置为与之左右对称,以便佩戴在右耳上(未示出)。另外,尽管图1至图3所示的信息处理装置100不包括要连接到外部装置(未示出)的电缆,但是信息处理装置100可以包括要经由插头连接到外部装置(未示出)的电缆。
图1至图3中示出的信息处理装置100包括生成声响的声响生成单元110、从声响生成单元110的一端接收将从声响生成单元110生成的声响的声音引导部120、以及将声音引导部120保持在其另一端附近的保持部130。声音引导部120由内径为1mm至5mm的中空管形成,并且其两端是开口端。声音引导部120的一端是用于从声响生成单元110生成的声音的声响输入孔,并且其另一端是作为对应物的声响输出孔。注意,期望信息处理装置100不要太重以至于给耳朵带来负担。
如图3所示,在另一端支撑声音引导部120的保持部130附接在耳道的入口附近,理想情况是抵靠在外耳腔的底面上,并与耳屏间切迹接合。此外,将耦合到声音引导部120的一端的声响生成单元110设置在耳廓的后部。
保持部130在其另一端通过与耳道入口(具体地,耳屏间切迹)的附近接合来支撑声音引导部120,使得声音引导部120的另一端处的声响输出孔朝向耳道的深度侧。保持部130理想地是橡胶状弹性元件,并且连接到声音引导部120的外部形状,使得容易支撑声音引导部120。保持部130和声音引导部120可以彼此一体形成,或者保持部130可以形成为可从声音引导部120分离的单独元件(也称为“尖端”),以便装配和连接到声音引导部120的另一端。为了使保持部130和声音引导部120彼此牢固地耦合,例如,期望在保持部130的内侧设置切口,并且在声音引导部120的外侧设置突起,使得在可分离保持部130被设置为围绕声音引导部120的单独元件的状态下,保持部130不会围绕声音引导部120转动。作为保持部130的元件的材料可以是塑料或金属。声音引导部120形成为使得至少另一端附近的外径小于耳道的内径。因此,即使在声音引导部120的另一端被保持部130保持在耳道入口附近的状态下,收听者的耳孔也不会关闭。换言之,允许耳孔开放,因此,信息处理装置100可以保持“开放式”的特征。声音引导部120在其另一端还可以包括防止耳垢进入的部分(未示出),其防止耳垢污染。保持部130可以是可拆卸的,并且适配成多种尺寸,以便适应各种耳朵形状。此外,保持部130可以通过清洁来重复使用,或者可以通过每次污染时用新的保持部替换来使用。
此外,保持部130包括开口部131,即使在保持声音引导部120的同时,该开口部131也允许耳道(耳孔)的入口向外部世界敞开。在图1和图2所示的示例中,保持部130具有中空结构,该中空结构具有曲面形状的下边缘,从而能够保持抵靠在外耳腔的底面上,并与耳屏间切迹接合。具体地,保持部130仅在中空结构的中空部分的一部分处耦合到管状声音引导部120的外表面的一部分。或者,形成为单独元件的保持部130通过具有中空结构而耦合到外表面的一部分,该中空结构允许管状声音引导部120穿过该中空结构插入,具体地,穿过该中空结构的中空部分的一部分。除了该部分之外,中空结构的所有其他部分都对应于开口部131。注意,保持部130不必一定具有中空结构,并且可以形成为能够保持声音引导部120的另一端的任意形状,只要提供中空结构即可。
管状声音引导部120从其一端接收由声响生成单元110生成的声响,从由保持部130保持在耳道入口附近的另一端将声响的空中振动传播并发射到耳道中。通过这种方式,声响被发送到耳膜。
如上所述,保持声音引导部120的另一端附近的保持部130包括开口部131,该开口部131允许耳道(耳孔)的入口向外部世界开放。已经穿过开口部131的环境声音通过没有被声音引导部120封闭的耳道的入口发送到耳膜。因此,即使在收听者佩戴信息处理装置100的状态下,也允许收听者通过开口部131充分听到环境声音,同时在他/她的耳孔没有关闭的情况下收听从声响生成单元110输出的声响。
此外,尽管允许耳孔打开,信息处理装置100也能够抑制生成的声音(再现的声音)泄漏到外部。这是因为,由于声音引导部120的另一端佩戴在耳道入口附近,以便朝向深度侧(depthside),并且在耳膜附近发射所生成的声音的空中振动,所以即使是低音量的声音也可以充分振动耳膜。这也是因为低音量的声音的反射声也很小,因此也可以减少通过耳道泄漏到外部的声音。结果,即使当来自信息处理装置100的输出减少时,也可以获得足够的声音质量。
此外,由从声音引导部120的另一端发出的声音引起的空中振动的方向性也有助于防止声音泄漏。图4示出了信息处理装置100如何将声波输出到收听者的耳朵中。通过从声音引导部120的另一端向耳道内部发射空中振动,作为从耳道入口401延伸到耳膜402的孔的耳道400通常具有大约25mm至30mm的长度。耳道300是圆柱形封闭空间。因此,如附图标记411所示,从声音引导部120的另一端朝向耳道300的深度发射的空中振动以方向性向上传播到耳膜402。此外,在耳道400中,空中振动的声压增加,因此灵敏度(增益)尤其在低音范围中增加。同时,耳道400的外部(即外部世界)是开放的空间。因此,如附图标记412所示,从声音引导部120的另一端发射到耳道400外部的空中振动不具有方向性,因此突然衰减。
返回参考图1和图3,管状声音引导部120具有在弯曲部123处从耳孔的后侧向其前侧折回的弯曲形状。注意,尽管在图3所示的示例中,信息处理装置100以声音引导部120在耳垂附近或耳廓的下端向后折叠的方式佩戴在耳朵上,但是耳朵开放式耳机可以被配置为具有允许信息处理装置100以在耳廓的上端附近向后折叠的方式佩戴在耳朵上的结构。
此外,声音引导部120还包括位于将设置在耳道入口附近的另一端和弯曲部123之间的悬挂下垂部124。悬挂下垂部124被配置为允许声音引导部120的另一端向耳道的深度发送声音信号,允许声音引导部120从保持部130向下下垂,并且允许声响生成单元110相对于弯曲部123设置在耳朵的后部。以这种方式,悬挂下垂部124作为整体被配置为允许信息处理装置100稳定地佩戴在耳朵上。
换言之,图1至图3所示的信息处理装置100的基本结构的特征可以概括如下。
·信息处理装置100是一种佩戴在收听者的耳朵上的小巧且轻便的装置。
·信息处理装置100也是声响输出装置,例如,具有折回结构(弯曲部123)的耳机或头戴式耳机,该折回结构允许声响生成单元110设置在耳朵的后部,并允许声音引导部120从耳廓的后部折回至其前部。在图1至图3所示的示例中,信息处理装置100以声音引导部120的折回结构经由耳朵的耳垂附近到达耳孔附近的方式佩戴在收听者的耳朵上。声音引导部120的折回部分可以经由耳垂的另一端或耳垂的另一部分延伸。或者,声音引导部120的折回结构可以是u形结构。
·声音引导部120的一端耦合到声响生成单元110,以设置在耳朵的后部,并且声音引导部120的另一端(其是由开口端部形成的声响输出单元)被保持部130保持在耳孔附近。在将保持抵靠耳朵的耳朵后轮廓表面的部分处,声响生成单元110可以包括接触部,该接触部至少具有将安装到耳朵后轮廓表面的曲面形状的部分。期望设置在耳道入口处的保持部130由橡胶状弹性元件形成,使得在保持部130与耳道入口附近接合(具体地,与耳屏间切迹接合)的状态下,不会增加负担,或者保持部130可以形成为单独元件。
·声音引导部120的另一端可以被配置为具有小于耳朵耳道内径的外径。在图1至图3所示的配置示例中,声音引导部120的另一端由保持部130保持在耳朵的耳道入口附近。
·保持部130不仅具有通过与耳朵的耳道附近(耳屏间切迹)接合并且通过固定声音引导部120的另一端附近来防止声音引导部120的另一端深深插入耳道的功能,而且还具有通过与耳朵的耳屏间切迹接合来将声音引导部120(由开口形成的声响输出部分)的另一端从保持部130支撑并定向到耳道深度的功能。保持部130具有开口部131,该开口部131允许耳道的入口向外部世界敞开,并且即使支撑另一端的外径小于耳朵耳道的内径时,保持耳孔敞开的状态。期望保持部130在与耳朵的耳屏间切迹接合时保持与外耳腔的底面接触。保持部130可以包括与外耳腔的底面保持表面接触(或大面积接触)的接触部,或者可以包括与外耳腔的底面的形状一致的弯曲的接触部。注意,尽管图1至图3所示的配置示例中的保持部130具有圆形形状,以在开口的中心附近支撑声音引导部120的另一端,但是保持部130可以形成为任意形状。
注意,只要声响生成单元110具有容纳在外壳中的尺寸,声响生成单元110可以是动态扬声器、平衡电枢扬声器、压电扬声器和电容扬声器中的任何一种,或者这些类型中的两种或多种的组合。
1.2功能配置示例
图5和图6示出了信息处理装置100的主体中的相应功能模块的设置示例。此外,图7示出了信息处理装置100的功能配置示例。注意,每个附图都示出了独立的配置示例,因此要提供的功能模块的类型和数量不完全彼此相同。此外,在每个附图中,由于空间的限制,未示出一些功能模块。在所有附图中,相同的功能模块由相同的附图标记表示。
作为执行计算机程序的处理器的控制器551共同控制整个信息处理装置100的操作。
由电池控制器(未示出)控制的电池501向信息处理装置100中的所有硬件模块供电。
根据这样的通信标准,包括根据诸如蓝牙(商标)和wi-fi(商标)等通信标准的通信rf(射频)电路的无线模块553可连接到外部装置(例如,诸如与信息处理装置100协作(或配对)的智能手表等信息终端、无线访问点等)。
存储器552包括rоm(只读存储器)、sram(静态随机存取存储器)、dram(动态随机存取存储器)、闪存、ssd(固态硬盘)等。在存储器552中存储将由控制器551执行的计算机程序(软件)和在程序执行时使用的各种数据。
例如,在存储器552中不仅存储无线连接所需的信息(用于对连接装置进行访问的地址信息,例如,mac(媒体访问控制)地址)、关于与蓝牙(商标)连接装置配对的信息、与连接在诸如互联网(或云)等网络上的服务器装置相关的连接所需的信息(用于对服务器装置进行访问的地址信息,例如,ip(互联网协议)地址和mac地址)、在服务器装置上运行的个人代理的身份信息等,还存储用于辅助这些连接的计算机程序(软件)。信息处理装置100能够使用信息连接到服务器装置,并与服务器装置交换信息和数据。以这种方式,信息处理装置100可以请求在诸如个人代理等服务器装置上运行的计算机程序执行必要的信息处理,并且可以接收数据,作为信息处理装置100所需的处理的结果。从服务器装置接收的数据包括关于在环境中识别的对象的信息(特征和形状)、语音数据(例如,声源的声音信息)等。
此外,存储器552能够将数据存储在其中,例如,关于信息处理装置100的各种模式的信息、声源的声音信息(声音数据)、声音信息的类型以及声音信息的量(数据大小),作为各种硬件模块或软件模块要使用的参数,或者作为临时缓冲数据。此外,存储器552能够将声响处理滤波器和传感器处理滤波器的参数存储在其中。注意,在该实施方式中,信息处理装置100具有各种模式,例如,噪声消除模式、声音模式(语音模式或虚拟声音模式)和感测模式(正常模式或白手杖模式),将在下面描述其细节。
传感器510包括各种传感器元件,例如,对象检测传感器511、深度传感器512、图像传感器513和触摸传感器514。虽然未示出,但是传感器510还可以包括获取位置信息的gps(全球定位系统)或gnss(全球导航卫星系统)、检测佩戴信息处理装置100的收听者的头部运动的加速度传感器或陀螺仪传感器、检测信息处理装置100周围环境温度的温度传感器、获取佩戴信息处理装置100的用户的生物信息(例如,体温、血压和脉搏)的生物传感器、气压传感器、方向传感器、接近传感器等中的至少一个。例如,如图5所示,传感器510可以以分布式方式设置在具有一体形成的头戴式耳机(或耳机)形状的信息处理装置100的主体中。或者,如图6所示,传感器510可以集中设置在特定部分,例如,也用作信号电缆管道的下端部分。来自传感器511、512、...的相应检测信号分别由相应的传感器控制器521、522、...进行信号处理,然后作为数字检测信号输出。
(a)音频信号处理功能
为了提供用于听觉能力增强的基本语音服务功能,信息处理装置100还包括例如音频编解码器单元530、麦克风541、误差麦克风542、麦克风放大器543、扬声器544和扬声器放大器545,这些是普通音频耳机实现音频信号处理功能所需的电路组件。
注意,音频编解码器单元530包括例如adc(模数转换器)531、dac(数模转换器)532、dsp(数字信号处理器)533和接口控制器534,并且例如由单个半导体芯片构成。
此外,误差麦克风542是用于消除噪声的声音收集麦克风。这些电路组件经由数据总线、指令总线等相互链接。尽管图5和图6中所示的麦克风541和误差麦克风542均为一个,但是麦克风541和误差麦克风542均可以是包括两个或更多个麦克风的麦克风阵列。此外,误差麦克风542不必被认为是专用于误差信号获取的麦克风,并且可以是用于获取噪声消除信号的麦克风。
此外,从扬声器放大器545输出的音频信号基本上输入到扬声器544,并由扬声器544转换成声响(物理振动)。声响生成单元110也可以用作扬声器544。从声响生成单元110生成的声响经由声音引导部120发送到收听者的耳朵。
如下所述,dsp533能够实现对从麦克风阵列获取的信号执行波束成形处理(基于从预定声源到多个麦克风的语音到达时段之间的间隙并基于麦克风之间的距离来估计预定声源的位置(到达角度)的技术)的功能,并且能够基于用于定位声源的声像的hrtf(头部相关传递函数)来执行滤波处理。下面描述了使用hrtf的声像定位的细节。
dsp533也可以用作生成噪声消除信号的滤波器。或者,dsp533的一些硬件块可以生成噪声消除信号,或者可以通过软件处理调整滤波器的参数来生成噪声消除信号。或者,生成噪声消除信号的硬件块的操作可以由软件控制。
或者,dsp533可以预设多个噪声消除模式。在这种情况下,用于多个滤波器的参数集被存储在存储器552中,并且dsp533可以通过根据从存储器552中选择的模式读取参数集来设置滤波器的系数,从而改变噪声消除的特征。
噪声消除模式可以自动切换。例如,噪声消除模式可以根据例如环境的变化或收听者的动作(例如,跑步、走路、坐着、乘火车、乘公共汽车和驾驶汽车)自动切换,该变化和动作经由麦克风541、对象检测传感器511、深度传感器512、图像传感器513和其他传感器(例如,获取位置信息的gps或gnss、检测佩戴信息处理装置100的收听者的头部运动的加速度传感器或陀螺仪传感器、检测信息处理装置100周围环境温度的温度传感器、获取佩戴信息处理装置100的用户的生物信息(例如,体温、血压和脉搏)的生物传感器、气压传感器、方向传感器、接近传感器等)来识别,或者通过收听者的输入(例如,经由语音、命令和按钮的模式指令)来识别。
此外,噪声消除模式可以由收听者或其他人手动切换。例如,模式可以经由触摸传感器514或提供给信息处理装置100的外壳的机械控制器(例如,按钮(未示出))来手动切换。或者,噪声消除模式可以通过经由与信息处理装置100协作的外部装置(例如,智能手机和经由蓝牙(商标)、wi-fi(商标)等无线连接到信息处理装置100的其他信息终端)的用户界面的选择操作来设置。
噪声消除信号是相位与由麦克风收集并由麦克风放大器543放大的音频信号相反的信号。这些噪声消除信号被设置为由加法器(例如,在dsp533中提供)与从扬声器544输出的语音数据(例如,音乐数据、通过对由麦克风收集的环境语音数据进行滤波处理而生成的数据、以及从环境声音中分离的或经由无线模块553发送的语音数据)合成,由扬声器放大器545放大,然后从扬声器544输出。可以经由诸如信息处理装置100的触摸传感器514之类的用户界面通过模式进行选择,设置与存储器552中的多个预设噪声消除模式相关联地预先存储的参数集,来设置确定用于执行噪声消除的滤波器的特征的参数,或者可以任意设置或者通过经由与信息处理装置100(如上所述)协作的外部装置(例如,智能手机)的用户界面从预设模式下进行选择来设置这些参数。该模式可以基于来自在诸如互联网(或云)等网络上连接的服务器装置的信息来设置。
可以针对分别从多个误差麦克风542收集的每个语音数据生成噪声消除信号。设置在扬声器544附近的麦克风541也可以用作误差麦克风542。误差麦克风542也称为fb(反馈)麦克风,在数据路径中用于生成用于消除已经泄漏到扬声器544附近的fb噪声的信号。同时,麦克风541(其通常设置在远离扬声器544的位置,并且在该位置更容易收集来自外部环境的声音)也称为ff(前馈)麦克风,并且在数据路径中用于生成用于消除ff噪声的信号。
dsp533可以具有执行无线语音通信(电话呼叫或与代理的通信)的功能。这种类型的语音通信可以由硬件处理,也可以部分由软件控制。为了防止麦克风541收集的噪声在语音通信期间发送到目的地,dsp533可以包括抑制信号中的噪声的内置噪声抑制(或降低)滤波器电路。dsp533可以包括能够改变语音数据的频率特征的内置均衡器。可以经由诸如信息处理装置100的触摸传感器514之类的用户界面通过模式选择设置与存储器552中的多个预设均衡器模式相关联地预先存储的参数集来设置均衡器的参数,或者可以任意设置、或者通过经由与信息处理装置100协作的外部装置(例如,智能手机)的用户界面从预设模式下进行选择来设置均衡器的参数。此外,类似于噪声消除模式的上述设置,均衡器模式可以根据基于传感器510的检测结果的对情境的识别或对收听者的动作的识别来自动设置。
尽管由麦克风541收集的环境声音的信号可以由音频编解码器单元530分析,但是语音数据可以不发送到音频编解码器单元530,而是发送到控制器551,并且语音数据可以由控制器551处理。控制器551是称为例如cpu(中央处理单元)、mpu(微处理单元)、gpu(图形处理单元)或gpgpu(通用图形处理单元)的处理器,并且该处理器读取并执行存储在存储器552中的程序。语音数据的分析和其他处理可以由在控制器551上运行的程序来执行。此时,安装在音频编解码器单元530中的lpf(低通滤波器)或hpf(高通滤波器)可以将输入信号限制在特定频带内,或者其数据可以被采样率转换器修改,以便作为用于信号分析的侧链数据发送到另一外部控制器(未示出)。外部控制器可以是处理器,例如,mpu,或者可以是经由无线或有线通信连接的互联网上的服务器装置(处理装置或存储器(包括存储器))。
(b)空间识别传感器
信息处理装置100也是增强佩戴该装置的收听者的听觉能力以帮助他/她的视觉能力的装置。信息处理装置100能够提供白手杖功能(white-canefunction),作为听觉能力增强的一种类型。
为了提供白手杖功能,信息处理装置100包括内置对象检测传感器511。作为对象检测传感器511,例如,可以使用毫米波雷达、lidar(激光成像检测和测距)、红外传感器、超声波传感器等。或者,例如,与波束成形技术相结合的方法可以用作对象检测传感器511。对象检测传感器511能够通过主动发送信号和分析反射信号来检测对象。例如,当毫米波数据用作对象检测传感器511时,即使在诸如恶劣天气(雨、雪、雾)和夜间的环境中,也可以立即检测到强烈反射雷达信号的对象(例如,车辆)以及弱反射雷达信号的对象,例如,人。当5ghz的无线频带中的信号用作要发送的信号时,当雷达的分辨率高时,可以在小于10cm的范围内检测到对象,当雷达的方位分辨率高时,可以在小于1度的方位检测到对象。此外,毫米波雷达适用于远距离,因此甚至可以探测到几百米以外的对象。
当红外传感器用作对象检测传感器511时,期望在信息处理装置100的外壳被佩戴在收听者的一只耳朵上的状态下,红外传感器设置在从耳垂向下突出的部分(例如,在由图57中的虚线部分例示的范围内),使得可以执行向从用户的角度观看的前方的发射。当超声波传感器用作对象检测传感器511时,超声波传感器设置在信息处理装置100的外壳中,具体地,设置在从耳垂向下突出的部分(例如,在由图57中的虚线部分所例示的范围内),以便在信息处理装置100的外壳佩戴在收听者的一只耳朵上的状态下,被定向到比收听者的视线方向更低的一侧,使得在收听者向前看的状态下,可以检测到他/她的脚前面的邻近对象。更具体地,超声波传感器可以设置在预定的方向上,并且设置在这样的位置处,从该位置,在他/她的右耳上佩戴信息处理装置100的收听者向前看的状态下,可以检测前方5m内的障碍物。此外,加速度传感器和角速度传感器可用于估计头部的姿态,从而校正检测区域。
需要将检测到的关于周围对象的信息立即提供给收听者。因此,期望来自对象检测传感器511的检测信号由内置在信息处理装置100中的控制器551处理,使得能够以短延迟向收听者提供特定信息。注意,为了分析除实时信息之外的信息,可以通过将对象检测传感器511的检测结果与其他传感器信息一起发送到经由无线或有线通信连接的互联网(或云)上的服务器装置(处理装置或存储器(包括存储器))来在服务器装置中执行诸如空间识别和对象识别等处理。
信息处理装置100能够基于从包括一个或多个图像传感器513的图像传感器513获取的信息来执行对象识别。通过使用图像传感器513,可以使用关于对象的颜色和形状(包括深度)的信息。此外,信息处理装置100的深度传感器512可以是以tof(飞行时间)传感器为代表的深度传感器。tof传感器是一种包括红外相机的传感器,该红外相机以从大约30hz到60hz的频率捕捉红外反射的光线,并且基于红外线来回传播的时间段来计算到反射对象的距离。当用户进行动态移动时,tof传感器获取的数据可能会模糊。为了避免模糊,期望相对于tof传感器使用致动器进行模糊校正或者通过信号处理进行模糊校正。通过利用深度传感器512,例如,tof传感器,信息处理装置100可以帮助收听者识别如何在三维空间中呈现和排列对象。
期望图像传感器513和深度传感器(例如,tof传感器)512被设置成捕捉在他/她的耳朵上佩戴信息处理装置100的收听者的视线方向,使得这些传感器能够用于捕捉收听者正在观看的图像。期望在信息处理装置100的外壳佩戴在收听者的一只耳朵上的状态下,图像传感器513和深度传感器512设置在从耳垂向下突出的部分(例如,在由图57中的虚线部分例示的范围内),使得可以捕捉从用户观看的前侧。
利用来自图像传感器513和深度传感器512的检测信息的分析处理和识别处理,可以利用信息处理装置100中的控制器551中内置的cpu、mpu、gpu或gpgpu在本地执行。或者,可以通过在经由无线或有线通信连接的网络(例如,互联网(或云))上将关于图像的信息发送到服务器装置(例如,处理装置或存储器(包括存储器)),来在服务器装置中执行对象识别处理和环境识别处理。在后一种情况下,信息处理装置100可以从服务器装置接收关于所识别的对象和所识别的环境的信息,并将该信息作为语音信息呈现给收听者。
此外,信息处理装置100可以包括两个或更多个麦克风,以便实现麦克风阵列的功能。图8示出了信息处理装置100被配置为包括多个麦克风的配置示例。在图8中,信息处理装置100包括分别为麦克风设置的多个麦克风放大器543-1、543-2、543-3、...以及音频编解码器单元530,音频编解码器单元530包括对麦克风收集的环境声音的信号(具体地,麦克风放大器543放大处理后的信号)执行ad转换的独立的adc531-1、531-2、531-3、...。此外,dsp533处理分别通过adc531-1、531-2、531-3、...对环境声音的转换获得的数字音频信号,这些数字音频信号分别由麦克风收集。通过使多个麦克风用作麦克风阵列,并通过使用波束成形技术(如上所述),执行声源分离,以允许声源方向的识别。音频编解码器单元530或控制器551中的dsp533能够通过合成分别从多个麦克风获取的麦克风通道,然后通过在麦克风通道周围的所有角度范围(例如,通过将360°分成45°的八个相等的部分而获得的范围)中执行声源分离来分析声响。这种声响分析方法允许麦克风阵列用作空间识别传感器。
通过将声源分离与上述噪声消除信号相结合,或者通过使用滤波电路执行声源生成和减少预定带宽之外的噪声(例如,由车辆生成的语音和道路噪声),可以将人类语音、接近车辆的声音等与其方位信息一起识别。此外,信息处理装置100能够通过基于方向信息向收听者提供语音信息,利用收听者的固有听觉能力来拓宽风险规避动作,从而辅助收听者的动作。注意,声响分析不一定需要例如由信息处理装置100中的dsp533或控制器551来执行,还可以通过经由无线模块553在互联网上将语音信道上的相应信号发送到服务器装置,来在服务器装置侧执行声响分析。
通过使用从深度传感器512、图像传感器513和包括两个或更多个麦克风的麦克风阵列获取的信息,可以立即执行自身位置估计和环境地图生成。作为一种用于以这种方式立即执行自身位置估计和环境地图生成的技术,slam(同时定位和映射)是已知的。上述环境识别处理可以是slam处理,并且关于识别的环境的信息可以是slam信息。
通过关于所识别的环境的信息和关于所识别的对象的信息,可以获得关于在哪个方向上留下空白空间以及在空间中存在何种对象的信息。通过这种方式,可以提供声音信息,该声音信息帮助收听者能够即使在不依赖于虚拟声音(包括语音)的视觉信息的情况下也能够进行移动。这在收听者有视觉障碍的情况下尤其有利。
例如,深度传感器512允许获取亮度图像,其中,近对象用亮色表示,远对象用深色表示。此外,当原样使用从深度传感器512提取的点云数据信息时的信息量过大,因此,例如,可以执行滤波处理,例如,体素网格滤波。图19描绘了可以基于深度传感器512的检测结果来掌握的空间识别状态的图像的示例。注意,在图19中,人(佩戴信息处理装置100的收听者)的图像映射在该空间中。从图19中可以理解,深度传感器512可以获取关于例如对象边缘的信息。
如下所述,信息处理装置100基于图像传感器513和深度传感器512的检测结果,通过在要识别的三维空间中对虚拟声源进行定位,从而向收听者提供三维声响空间。在三维声响空间中,通过改变用于对虚拟声源进行定位的参数(例如,虚拟声音行进的起点和终点、行进轨迹、行进速度等),可以给收听者提供各种印象,这些印象也可以用于辅助收听者的动作。
此外,例如,当均配备有显示器的智能手机和眼镜(例如,称为vr(虚拟现实)眼镜、ar眼镜或智能眼镜)与信息处理装置100进行协作时,深度传感器512获取的空间识别的图像(如图19所示)可以经受图像处理并在显示器上显示。在这种情况下,允许收听者不仅将三维空间识别为声响空间,还将其识别为视觉空间。
(c)用户界面功能
信息处理装置100能够通过在其外壳的正面或侧面上设置触摸传感器514来提供用户界面。图9示出了收听者如何沿着触摸传感器514滑动他/她的手指。此外,图10示出了收听者如何用他/她的手指轻击触摸传感器514。
信息处理装置100能够根据手指沿着触摸传感器514滑动的量(距离)来控制音量级别、噪声消除级别、语音信息量等。此外,收听者可以通过诸如用他/她的手指轻敲触摸传感器514等操作来指示信息处理装置100执行电源或虚拟声音服务的打开/关闭、模式切换等。对用户界面的这些操作不必经由触摸传感器514来执行,而是可以通过语音控制来执行。经由麦克风541输入的来自收听者的语音信息可以由信息处理装置100中的控制器551进行实时语音识别,或者可以经由无线或有线通信在网络上发送到服务器装置,使得语音信息的量可以由实际向收听者提供服务的服务器装置根据收听者的需要来控制。
在远程操作外部装置的情况下,使用触摸传感器514的用户界面也是有利的。通过iot技术经由互联网等网络相互连接的装置都具有代理软件功能。使用该代理软件,可以响应于收听者对触摸传感器514的操作来远程控制装置。例如,关于电梯,可以通过向触摸传感器514发出与经由“电梯上行呼叫”按钮和“电梯下行呼叫”按钮发出的指令相同的指令来远程控制电梯。这种远程控制可以通过使用虚拟声音来执行,将在下面描述其细节。
此外,当信息处理装置100与设置有触摸接口的外部装置(智能手机)进行协作时,通过利用外部装置的触摸接口,可以选择信息处理装置100的所有模式(噪声消除模式和均衡器模式),并且可以控制声音信息的量。
图11示出了经由提供给智能手机1100的用户界面来控制信息处理装置100的示例。具体地,设置在智能手机1100的外壳的侧面上的机械控制器(例如,按钮)可以临时用作用于开启/关闭信息处理装置100的声响ar辅助功能(即,在本文的实施方式中描述的各种功能)的按钮。此外,智能手机1100的屏幕可以用作ui(用户界面),其中,例如,设置有用于在信息处理装置100侧选择预设模式以及用于向学习/估计(推断)系统提供要再现的声源的开/关的反馈的按钮。
信息处理装置100可以包括指示内部状况的led(发光二极管)554。led554可以是单一的颜色,例如,蓝色、红色、黄色或白色,或者尽管具有发射多种颜色的光束的功能,但能够每次发射任何一种颜色的光束。此外,led554可以具有制造商标志或指示产品名称的标志的形状。期望led554设置和安装在从周围容易看到的位置。例如,尽管外壳的上表面或侧面是可取的,但是只要从外部可以看到led554,led554可以设置和安装在其他位置。led554通常用于指示控制器551的处理状况。例如,led554可以用于明确地指示特定功能的通电状态或开/关状态。
此外,led554有利于指示信息处理装置100的下述模式。其中,“白手杖”模式是适用于视觉障碍收听者利用信息处理装置100的情况的功能。因此,使用led554的指示功能有利于通过利用led554的指示功能清楚地通知收听者周围的人收听者需要“白手杖”模式。期望当需要视觉能力辅助的收听者使用的特定颜色已经被定义为标准或工业标准时,通过使用led554来指示这样定义的颜色。
此外,例如,当在信息处理装置100中选择“白手杖”模式时,从收听者的脚看去的前侧可以用灯照亮,该灯发出例如白光束(未示出)以及led554的指示(或者代替led554的指示)。通过这种方式,周围的人可以看到收听者的脚前面的照明,并且通过看正常的(真实的)“白手杖”来集中注意力,从而理解收听者需要视觉辅助。该灯可以是能够投影图像的输出装置,例如,投影仪。在这种情况下,例如,通过精确地投影图像,就像拐杖出现在收听者的脚前一样,可以清楚地告知周围的人需要什么类型的帮助。
(d)学习/估计(推断)功能
图12示出了信息处理装置100包括神经网络加速器555的配置示例。除了包括cpu等的控制器551之外,通过提供神经网络加速器555,可以加速基于例如经由传感器510输入的传感器信息和收听者的动作的学习和估计的处理。注意,神经网络加速器555也可以与作为功能上彼此不同的硬件处理功能块的cpu和gpu一起以混合方式安装在单个控制器551中。另外,神经网络加速器555的功能的处理可以由通用gpgpu执行。gpgpu可以内置在控制器中,而不是上述gpu中。然而,在这种情况下,下面描述的神经网络的功能和声响空间渲染都需要由gpgpu(或gpu)处理,因此与功能和渲染被实现为彼此分离的单元的情况相比,处理能力是有限的。同时,可以降低开发成本。此外,神经网络加速器555适用于学习方法,尤其适用于使用神经网络的学习方法。具体地,使用神经网络的学习方法包括一种称为深度学习的学习方法。用于实现深度学习的神经网络的示例包括各种神经网络的组合,例如,卷积神经网络(cnn)、递归神经网络、自动编码器、风格发送网络和gan(生成对抗网络)。此外,学习方法还包括例如监督学习和非监督学习。
图13示出了神经网络加速器555的配置示例。图13所示的神经网络加速器555是多处理器。这种多处理器包括大量(理想地,几百到几千个)相应的pe(处理元件),这些处理元件能够整体充当卷积神经网络1301上的相应节点。相应pe根据程序彼此并行运行。pe之间的连接关系可以响应于来自外部处理器(例如,控制器551)的指令而动态转换。通过从控制器551接收处理指令,神经网络加速器555中的每个模块经由存储器552开始处理。
经由传感器510检测到的传感器信息和关于收听者动作的输入信息经由总线接口1302输入到神经网络加速器555。输入数据由cnn1301中的输入缓冲器临时保存,然后分发给每个pe。根据程序的执行,每个pe经由输入缓冲器接收输入向量,并从权重处理单元1303接收权重向量。然后,pe在大范围内整体计算cnn,并学习权重。由pe分别学习的权重整体存储在存储器552中,并且可以用于随后的计算。
通过加法器1304将pe的处理的相应结果彼此相加,使得可以由神经网络后处理单元1305执行后处理计算(例如,归一化)。通过这种方式,神经网络加速器555也适用于学习阶段和估计(推断)阶段。神经网络后处理单元1305的处理结果暂时保存在共享缓冲器1306中。然后,输出处理单元1307经由总线接口1302将共享缓冲器1306中的处理后的数据输出到神经网络加速器555的外部(输出到控制器551)。
使用专用模块,例如,图13所示的神经网络后处理单元1305,允许通过由cpu(例如,个人代理)执行的程序来高速实现与必要的神经网络的学习计算或估计(推断)计算相对应的操作。
信息处理装置100中的学习适合于学习理解收听者发出的语音的语音个性化。收听者可以在学习模式下开始信息处理装置100的初始使用。或者,信息处理装置100可以被配置为能够经由与信息处理装置100协作的外部装置(例如,智能手机)的用户界面切换到学习模式。
(e)声响空间渲染功能
声响空间渲染是指通过基于三维声场计算的耳朵处声压波形的数值计算来使声音可听的计算处理,所述三维声场计算考虑了声响反射器(例如,墙壁)的声响特征(例如,形状和反射率)以及声音的波动性质。声响空间渲染的处理可以由专用处理器来执行,例如,spu(声场处理单元)或gpgpu(或gpu)。使用具有高处理性能的这些处理器的声响空间渲染允许实时执行高速声响空间渲染的处理,例如,下面描述的声源在三维声响空间中移动的声像定位。
当对计算处理中的整个信息(例如,在空间识别和声响空间生成中)进行实时处理时,处理的规模可能很大。因此,信息处理装置100可以仅执行有限的计算处理,并且剩余的计算处理可以在经由无线或有线通信连接的互联网上由服务器装置(处理装置或存储器(包括存储器))来执行。作为要由信息处理装置100执行的有限计算处理的示例,可以提及在有限的小空间(例如,深度和宽度大约为2m,高度大约为地上3m)中计算与三维空间中的环境中存在的对象(例如,墙壁和地板)相对应的声源的移动的效果的处理。在有限环境之外的计算处理可以由服务器装置在互联网上执行。
1.3增强功能分离型装置的配置示例
提供给信息处理装置100的一些功能可以作为功能增强部以耳机等形式从信息处理装置100的主体分离,并且可以与主体部组合,以构成单个听觉能力增强系统。在这种情况下,也用作耳机的主体部和功能增强部可以包括用于控制信息和数据的通信以及用于电源的连接端子。
图14和图15示出了包括信息处理装置100的主体部1401和功能增强部1402的听觉能力增强系统1400的配置示例。图14示出了主体部1401和功能增强部1402彼此分离的状态,图15示出了主体部1401和功能增强部1402彼此耦合的状态。然而,相应功能模块的设置不限于图14和图15所示的示例中的设置。许多功能模块可以设置在主体部1401和功能增强部1402中的任何一个中,因此,为了设计方便等,可以方便地设置在主体部1401和功能增强部1402中的任何一个中。在图14和图15所示的示例中设置在主体部1401侧的led554可以设置在主体部1401或功能增强部1402中的至少一个中,并且信息处理装置100的内部状况可以例如通过闪光的颜色或发光图案来指示。
主体部1401包括连接端子1411,并且功能增强部1402包括连接端子1412,该连接端子1412可附接到连接端子1411并且可从连接端子1411拆卸。主体部1401和功能增强部1402能够允许在其相应的组件之间交换数据(包括命令),并且能够经由连接端子1411和1412供电。注意,还假设通过用电缆或经由无线通信将连接端子1411和连接端子1412彼此连接来提供类似功能的实施方式。
尽管在图14或图15中未示出,但是电池可以设置在主体部1401和功能增强部1402中的任何一个中。电池可以设置在主体部1401和功能增强部1402中。在这种情况下,一个电池可以用作主电源,另一电池可以用作辅助电源。另外,可以另外提供具有电池控制功能的电池控制器(未示出),例如,当一个电池的剩余容量降低时,将另一电池切换到主电源。
图16示出了包括信息处理装置100的主体部1401和功能增强部1402的听觉能力增强系统1400的功能配置示例。主体部1401和功能增强部1402经由其相应的io(输入/输出)接口1611和1612彼此连接。主体部1401和功能增强部1402能够允许在其相应的组件之间交换数据(包括命令),并且能够经由io接口1611和1612供电。
在图16所示的配置示例中,电池501和无线模块553设置在功能增强部1402侧。另外,在图16所示的配置示例中,在传感器510中,对象检测传感器511和触摸传感器514设置在主体部1401中,并且深度传感器512和图像传感器513设置在功能增强部1402侧。注意,可以想到关于在主体部1401和功能增强部1402中的哪一个中安装作为传感器510的每个传感器元件的各种组合。(当然,所有传感器元件可以安装在功能增强部1402侧)。此外,除了主体部1401侧的控制器551和存储器552之外,控制器1601和存储器1602也设置在功能增强部1402侧。通过从存储器1602读取程序并执行这些程序,控制器1601全面控制例如功能增强部1402侧的处理以及与主体部1401的通信的处理。
功能增强部1402的形状不限于如图14和图15所示的形状,通过以耳机的形式划分信息处理装置100的外壳的一部分而形成该形状。例如,构成功能增强部1402的一些或所有功能模块可以设置在外部装置的外壳中,例如,智能手机、智能手表、眼镜、颈带、肩戴、从颈部悬挂的装置或例如背心类型的可佩戴装置,或者设置在环形或手杖形式的外部装置的外壳中,外部装置设置有ar功能。此外,作为功能增强部1402的外部装置可以设置有诸如信息处理装置100的功能选择、模式选择和音量控制等功能。
当设置有显示器的智能手机、眼镜等用作功能增强部1401时,并且当信息装置100中的信息可以从主体部1401提供给功能增强部1401时,由主体部1401识别的关于对象的信息和关于环境的信息可以在功能增强部1401的显示器上显示。
1.4听觉能力增强空间识别功能
通过将通过分析来自包括各种传感器元件的传感器510的传感器信息而识别的关于环境的信息映射到三维声响空间中,并且通过在该三维声响空间中表达声响数据和声音数据,来向收听者提供根据该实施方式的信息处理装置100的空间增强功能。为了执行声像定位,作为用于听觉能力增强的基本语音服务功能,信息处理装置100在存储器552中维护hrtf数据库,并且经由音频编解码器单元530外部的控制器将存储在hrtf数据库中的一个适当的hrtf设置为dsp533的滤波特征。通过这种方式,启用声像定位。通过经由控制器551执行声像位置控制,预定声源可以被设置到收听者的预定声响空间中的任意位置。通过这种方式,可以执行声像定位。
图17示出了系统1700的一个示例,该系统1700利用hrtf执行声像定位。描述了如何在该系统1700中执行声像定位。
由滤波器1715执行hrtf的卷积。通过用滤波器1715卷积从声源(未示出)的位置到收听者的耳朵的发送特征,可以执行到任意位置的声像定位。当hrtf未卷积时,从信息处理装置100的扬声器544呈现给收听者的声音在收听者的头部内侧发声。然而,通过卷积hrtf,这种声音在收听者的头部外侧听起来是一种虚拟声音。因此,从信息处理装置100的扬声器544呈现的虚拟声音(包括语音)与环境声音一起听起来像是头外(out-of-head)声音。这使得收听者能够听到环境声音和虚拟声音,而不会感到不适。注意,fir(有限脉冲响应)滤波器可以用作hrtf的滤波器1715。此外,也可以用通过频率轴上的计算或iir(无限脉冲响应)的组合近似的滤波器来执行声像定位。
声源的声音与用于hrtf的滤波器1715的卷积允许收听者识别声源的方向感和到声源的一定距离,从而定位声像。在图17所示的系统1700中,为了在再现时使作为声像的声源适应周围环境,声响环境传递函数另外被滤波器1718卷积。声响环境传递函数主要包含关于反射声和混响的信息。理想地,基于真实再现环境的假设,或者基于接近真实再现环境的环境的假设,期望使用例如适当的两点之间(例如,虚拟扬声器的位置和耳朵的位置的两点之间)的传递函数(脉冲响应)。
对应于声像定位位置的滤波器1715的滤波器系数存储在基于声像位置的hrtf数据库1720中。此外,对应于声响环境类型的滤波器1718的滤波器系数存储在周围声响环境数据库1721中。收听者可以经由例如用户界面(ui)1722选择声像定位的位置和声响环境的类型。作为用户界面1722的示例,可以是上述的机械控制器,例如,提供给信息处理装置100的主体的开关以及与声响输出装置100协作的外部装置(例如,智能手机)的显示器(触摸屏)。或者,可以通过经由麦克风541的语音输入来选择声像定位的位置和声响环境的类型。
声像位置控制单元1724控制从扬声器544输出的声源的声像位置。此时,声像位置控制单元1724例如响应于收听者对用户界面1722的操作,从基于声像位置的hrtf数据库1720中选择滤波器系数中的最佳一个,并将最佳滤波器系数设置为滤波器1715的最佳滤波器系数。另外,声响环境控制单元1725控制从扬声器544输出的声源的声音的声响。此时,声响环境控制单元1725响应于例如收听者对用户界面1722的操作,从周围声响环境数据库1721中选择对期望的声响环境最佳的滤波器系数中的最佳一个,并将最佳滤波器系数设置为滤波器1718的最佳滤波器系数。
例如,将声源的声像定位到哪个位置可能不同,这取决于个体听觉的差异或者取决于使用声源的情况。因此,允许收听者经由用户界面1722操作和选择声像定位的位置。以这种方式,要建立的系统1700可以为收听者提供高度便利。此外,众所周知,hrtf在个体之间是不同的,特别是在个体的耳朵形状之间。因此,对应于多个耳朵形状的hrtf可以存储在基于声像位置的hrtf数据库1720中,使得收听者可以根据个体差异选择hrtf中的最佳一个。或者,为相应收听者单独测量的单独hrtf可以存储在基于声像位置的hrtf数据库1720中,使得收听者可以均选择专用于他/她自己的基于声像位置的hrtf。
同样关于声响环境,允许收听者经由用户界面1722选择最佳(或期望的)声响环境。通过这种方式,从扬声器544输出的声源的声音可以被设置为期望的声响环境中的声音。例如,允许收听者在诸如音乐厅或电影院等声响环境中听到来自扬声器544的声源的声音。
此外,可以执行结合收听者头部运动来相对于真实空间固定声像位置的处理。在图17所示的系统1700的配置中,作为一个传感器510的gps、加速度传感器、陀螺仪传感器等检测收听者头部运动,声像位置控制单元1724根据头部运动从基于声像位置的hrtf数据库1720中自动选择最佳的滤波器,并更新滤波器1715的滤波器系数。注意,期望在收听者已经经由用户界面1722指定了收听者想要定位声源的声音的声像的位置之后,声像定位的位置以跟随头部运动的方式改变。通过这种方式,例如,即使当收听者的头部的方向已经改变时,也可以控制hrtf,使得声像的位置在空间中稳定。
注意,声像位置控制单元1724和声响环境控制单元1725可以均是由运行在控制器551上的程序实现的软件模块,或者可以均是专用硬件模块。此外,基于声像位置的hrtf数据库1720和周围声响环境数据库1721可以存储在存储器552中,或者可以是可经由无线模块553访问的外部数据库。
可以经由诸如蓝牙(商标)、wi-fi(注册商标)或移动通信标准(例如,lte(长期演进)、高级lte、5g等)等无线系统从外部提供由信息处理装置100呈现的声源的声音。作为声源的声音的示例,可以提及例如音乐的声音(包括语音)、通过使用人工智能的功能由诸如互联网(或云)等网络上的服务器装置1750自动生成或再现的语音响应的语音、以及通过经由无线网络连接用麦克风1726收集操作者(或指导者、男/女配音演员、教练等)的语音而获得的语音。(通过用麦克风1726收集语音而获得的语音包括预先收集和记录的再现语音信息。更具体地,将由服务器装置1750生成或再现的语音的示例包括自动内容阅读、语音翻译和数据搜索的语音(包括由服务器装置1750的控制器1727基于地图信息的信息搜索和引导)。经由选择单元1728通过切换来选择这些语音中的任何一个,并且从服务器装置1750侧的无线通信单元1730发送到信息处理装置100的无线模块553。然后,由无线模块553接收的语音发送到滤波器1715。接下来,如上所述,在执行用于将声像定位到最佳位置(或收听者期望的位置)以及用于在再现时使作为声像的声源适合于周围环境的处理之后,从扬声器544输出所选择的语音。
例如,当图17中所示的系统1700应用于向正在讲话的行人、视力障碍者、运动员、例如汽车司机或讲话者提供建议的系统时,例如,允许行人安全地行走,因为他/她即使在收听建议时也能完全听到周围的声音。此外,建议的语音不是在公共场所针对大量普通公众生成的,而是由聪明的讲话者生成的。这允许上述人员在隐私受到保护的情况下听取他们自己的个人建议。此外,图17中所示的系统1700还能够利用下面描述的个人代理的人工智能功能,代表收听者本人自动响应来自其他人的查询。
图17所示的系统1700广泛适用于从作为声源的多个对象执行同时再现。图18示出了通过利用图17所示的系统1700在博物馆中呈现多个虚拟声源的展览引导系统的操作示例。信息处理装置100分析由作为传感器510的gps、加速度传感器和陀螺仪传感器检测到的传感器信息,然后从服务器装置1750获取语音信息。服务器装置1750基于例如由gps获取的位置信息,从作为声源的对象中,具体地,从收听者当前所在的展厅中的相应展览(“沙漠风的声音”、“法老的呼喊”、“骆驼行走和穿越的声音”以及“讲述者的路线引导”)中,自动读取内容(例如,语音),并且读取引导信息,例如,博物馆中的通告。然后,服务器装置1750将内容发送到信息处理装置100。接下来,当收听者站在诸如石像等展品前面时,声像位置控制单元1724使声源的声像位置与相应的一个展品匹配,并与收听者的头部运动互锁。此外,声响环境控制单元1725设置展厅的声响环境,以便向收听者呈现虚拟声音,例如,“沙漠风的声音”、“法老的呼喊”、“骆驼行走和穿越的声音”以及“讲述者的路线引导”。
当该系统1700应用于同一展厅中的多个参观者时,每个参观者同时体验定位于相同声像位置的虚拟声音。这允许多个人共享虚拟声像的存在,并享受真实世界和虚拟声源的融合。当然,每个参观者只听到从他们相应的信息处理装置100呈现的虚拟声音。因此,信息处理装置100可以均根据佩戴这些装置的相应一个收听者以一种语言执行再现。因此,不用说,与安装在大厅中的扬声器同时发出声音的情况不同,讲不同语言的参观者可以彼此独立地享受乐趣。
1.5虚拟声源的区分
可以再现虚拟声音(包括语音)的声源,其声像基于hrtf定位在三维声响空间中。根据该实施方式的信息处理装置100允许收听者在经由耳朵开放式耳机收听真实环境声音的同时收听人工声音。然而,此时,收听者不能区分他/她正在收听的是真实环境声音还是虚拟声音,这可能给收听者带来不便。
对虚拟声源进行定位的参数的精心设置允许收听者将环境声音和虚拟声音彼此区分开来。关于虚拟声源的信息与虚拟声音id相关联地登记在存储器552中的数据库中。作为虚拟声源,可以登记记录为pcm声源的声源。在这种情况下,即使当pcm声源的尺寸很小时,如果声源曾经再现过一次并且保留在高速缓冲存储器中,则再现处理可以仅通过指定id来高速执行。此外,基于统计信息,要频繁再现的声音可以存储在高速缓冲存储器中。
与虚拟声源相关的数据库可以存储在信息处理装置100中的存储器552中,或者可以存储在可由诸如互联网(或云)等网络上的服务器装置访问的虚拟存储装置中,具体地,存储器和存储器(例如,hdd(硬盘驱动器))中。
当虚拟声音被信息处理装置100定位在三维空间中时,首先,虚拟声音定位在佩戴装置100的收听者的头部,然后,虚拟声音移动并定位到(导致占有)目标对象。这种呈现虚拟声音的方法允许收听者识别声音不是真实的声音,而是虚拟声源的声音。此外,可以通过例如将其频率特征改变为与通过信息处理装置100的耳朵开放式耳机的开口部到达耳膜的声音的特征不同的特征,然后通过执行信号处理来生成虚拟声音。
类似地,通过使现实世界中不存在的声源或者即使存在也非常罕见的声源在三维声响空间中移动,允许收听者识别这些声音是虚拟声源的声音。下面列出了一些关于虚拟声音的声源移动的示例。
-通过从远处快速接近收听者的方式定位声像,同时移动声源。
-通过声源从墙壁上出现以在三维声响空间中再现的方式来定位声像。
-通过声源从地板下出现以在三维声响空间中再现的方式来定位声像。
-通过声源从天空(天花板)的方向下降以在三维声响空间中再现的方式来定位声像。
-通过声像在三维声响空间中螺旋移动的方式来定位声像。
-当声像在三维声响空间中像球一样弹跳时来定位声像。
-通过声像从收听者身体的一部分或一个区域(例如,他/她的指尖或他/她的脚趾)延伸或者会聚在指尖或脚趾上的方式,在三维声响空间中定位声像。
在三维声响空间中,通过改变用于使虚拟声源进行定位的参数(例如,虚拟声源进行定位的对象的类型、起点和结束点、行进轨迹、行进速度等,用于虚拟声音行进),可以给收听者提供各种印象,这些印象例如也可以用于生成消息或引导收听者,或者用于辅助收听者的动作。现在,描述一些具体的示例,其中,根据用于使虚拟声源进行定位的参数,有意地给收听者提供印象。
(a)占有对象(1)
声像定位在头部的声音从头部向目标对象(门把手)移动,从而在此处受到定位。图20示出了在三维声响空间中,基于深度传感器512的检测结果,声像位于收听者头部的声音如何从头部朝向门把手2002移动。在图20中,虚拟声源移动的轨迹由附图标记2001表示。从图20可以理解,声音逐渐占有对象的印象可以提供给收听者。具有物理身体的真实对象不能进行这样的运动,因此收听者可以认识到沿着轨迹2001运动的声源是虚拟声源。
(b)占有对象(2)
与上述(a)类似,(b)是虚拟声源占有特定对象的另一示例。然而,如图21所示,虚拟声源不从收听者头部的内部朝向门把手2102前进,而是如由附图标记2101表示的移动轨迹所指示的那样围绕收听者的身体转动,然后其声像以粘附到门把手2102的方式定位。注意,尽管在图21所示的示例中虚拟声源仅围绕身体转动一次,但是声像可以转动多次或改变转动半径,使得可以给收听者另一种印象。
(c)从上面接近
图22示出了虚拟声源基于深度传感器512的检测结果在三维声响空间中从天花板(天空)下降的示例。虚拟声源穿透收听者所在房间的天花板,然后沿着附图标记2201表示的轨迹下降,到达门把手2202。具有物理身体的真实对象几乎不进行这样的运动,因此收听者可以识别出沿着由附图标记2201表示的轨迹移动的声源是虚拟声源。此外,当虚拟声源通过穿透天花板而出现时,虚拟声源的音量可以改变(增大或减小),或者可以生成诸如穿透天花板的声音等声响效果,使得收听者可以进一步强烈地识别该声音不是真实声音而是虚拟声音。
(d)从墙壁或地板上占有对象
图23示出了一个示例,其中,在基于深度传感器512的检测结果的三维声响空间中,虚拟声源从墙壁弹出,以占有门把手2302,然后,定位其声像。虚拟声源从收听者所在的房间的墙壁中弹出,然后沿着由附图标记2301表示的轨迹前进,到达门把手2302。注意,虚拟声源不一定要从墙壁中弹出,也可以从地板中弹出。具有物理身体的真实对象几乎不进行这样的运动,因此收听者可以识别出沿着由附图标记2301表示的轨迹移动的声源是虚拟声源。此外,当虚拟声源从墙壁中弹出时,可以生成声响效果,使得收听者可以进一步强烈地识别声音不是真实声音而是虚拟声音。
(e)弹跳球
图24示出了一个示例,其中,基于深度传感器512的检测结果,定位虚拟声源的声像,而虚拟声源在另一三维声响空间中像球一样弹跳和移动。在图24所示的示例中,虚拟声源在楼梯2402的每一级台阶上弹跳时下降,如由附图标记2401表示的轨迹所示。通过使用gpu(或gpgpu)的功能对虚拟声源的运动进行物理操作(模拟),可以执行指示在三维声响空间中如何听到虚拟声源的声响空间渲染。虚拟声源可以总是发出声音,或者可以在每次接触地面时以规则的间隔发出声音。每次在每个台阶上弹跳时,虚拟声源的高度和距离都不同。这允许收听者想象虚拟声源沿着有台阶或高度差的路面行进。此外,现实世界中的对象几乎不能如此自由地移动,因此收听者可以认识到沿着由附图标记2401表示的轨迹移动的声源是虚拟声源。
(f)关于扶手的声像定位
扶手起着重要的作用,尤其是当视障者上下楼梯的时候。因此,使扶手的位置易于识别是很重要的。扶手沿着楼梯连续存在,因此收听者需要能够连续和有意识地区分虚拟声源和真实声音。
图25示出了信息处理装置100如何识别收听者已经接近楼梯2502,并基于深度传感器512的检测结果,使虚拟声源定位到另一三维声响空间中的扶手2503。在图25所示的示例中,虚拟声源的声像已经定位到应该抓住扶手的收听者的左手,沿着由附图标记2501表示的轨迹从左手朝向扶手2503移动。通知虚拟声音已经到达(已经占有)扶手2503的声源可以生成简单的乒声。然而,为了使收听者容易理解(或警告)定位已经完成,期望声音包括大约1khz到10khz的高声音范围,或者是噪声。
当信息处理装置100基于例如他/她的身体的距离和姿势识别出收听者已经接近楼梯2502时,这足以做出收听者上楼梯2502的确定,信息处理装置100将另一虚拟声源的声像也定位到扶手2503。然后,已经定位到收听者的脚(左脚)的另一虚拟声源的声像从脚趾移开,并且沿着由附图标记2504表示的轨迹定位到楼梯2502的第一级台阶。一旦收听者踏上楼梯2502的第一级台阶,可以丢弃声源。
此外,当继续上楼梯2502的收听者到达平台2505时,已经定位到收听者的脚的另一虚拟声源的另一声像可以从脚趾移开,然后可以在朝着墙壁的方向移动的同时定位。通过这种方式,可以将收听者引导到楼梯的另一边梯。
(g)自动扶梯的声像定位
当信息处理装置100基于深度传感器512的检测结果识别出收听者已经接近三维声响空间中的自动扶梯时,信息处理装置100将已经定位于收听者的脚的虚拟声源的声像从脚趾移开,然后在朝着自动扶梯的入口台阶的方向移动声像的同时定位声像。接下来,当收听者已经接近预定位置时,信息处理装置100将虚拟声源固定到自动扶梯的入口(第一级台阶),从而定位声像。以这种方式,允许收听者在被移动的虚拟声源引导的同时(即,在朝向虚拟声源的方向移动他/她的脚趾的同时)容易地乘坐自动扶梯。此外,通过将已经定位在收听者手中的虚拟声源的声像从手移向扶手,允许收听者在被移动的虚拟声源引导的同时(即,在朝向虚拟声源的方向上移动他/她的手)容易地抓住自动扶梯的扶手。
之后,在自动扶梯的出口附近,扶手变得不那么倾斜,更加级别,台阶之间的高度差减小。因此,收听者可以识别出他/她已经接近自动扶梯的出口。此外,在自动扶梯的出口附近,可以通过将已经固定到自动扶梯的台阶(或收听者的脚)上的虚拟声源的声像从台阶或脚趾移开,然后在将声像朝向自动扶梯的出口移动的同时定位声像,或者通过向前释放并固定已经固定到扶手上的虚拟声源的声像,来发出关于收听者在离开自动扶梯后应该做什么的指令。
(h)电梯的声像定位
当信息处理装置100基于深度传感器512的检测结果识别出收听者已经进入三维声响空间中的电梯门厅时,信息处理装置100使虚拟声源位于电梯门附近。当电梯上升时,信息处理装置100呈现从地面沿着电梯的门向上移动的虚拟声源。同时,当电梯下降时,信息处理装置100呈现从天花板沿着电梯的门向下移动的虚拟声源。
如下所述,信息处理装置100能够通过将模式彼此组合来提供语音模式或感测模式下的虚拟声音信息服务。作为语音模式下的服务,当收听者接近楼梯时,或者当自动扶梯或电梯到达时,可以提供关于建筑物的楼层号的信息(例如,诸如“四楼:男装部”等引导信息)。
1.6控制所提供的信息级别的功能
信息处理装置100能够根据例如使用该装置的收听者的需求来控制要作为声音信息提供的信息量(要作为虚拟声音(包括语音)提供的信息)。关于要虚拟生成的语音(虚拟语音),例如,在收听者可能被密集提供过度大量的语音信息而迷惑的情况下,服务器装置1750控制要提供的所有语音信息的汇总级别。这使信息处理装置100仅向收听者提供有限的信息。此外,信息处理装置100还能够提供包括语音消息的语音信息。然而,当收听者不想要虚拟语音的消息时,由虚拟声源生成的单个拟声词声音(例如“乒”)可以用于将信息呈现为虚拟声音。或者,该信息可以被呈现为通过利用当时在周围环境中可以听到的声音(例如,风的声音和接近汽车的声音)合成虚拟声音而生成的虚拟声音。
作为要由信息处理装置100发出的虚拟声源的示例,可以提及单个声音和多个声音的组合(不仅包括简单的音阶、旋律等,还包括人物的人工合成声音)。此外,通过将关于这些声音的数据的信息与声像定位相结合,信息处理装置100可以以移动虚拟声源的方式提供信息。此外,通过执行声响空间渲染,具体地,通过使用例如多普勒频移,信息处理装置100还可以提供利用特殊效果的信息,例如,对象正在接近收听者的状态以及对象相反地远离收听者的状态。下面描述包括使用各种虚拟声源的信息处理方法的细节以及由此获得的优点。
图26示出了用于设置要在信息处理装置100中提供的信息级别的系统。在以下四种主要模式下控制要提供的信息级别。
·信息量控制:
在这种模式下,控制作为虚拟声音(包括语音)提供的信息量。当信息量大时,收听者(或信息处理装置100)周围的传感器510检测到提供信息的个人代理,并且尝试连续地并且尽可能多地提供识别的信息。通过将信息量设置为最小,可以使信息处理装置100根本不提供作为虚拟声音(包括语音)的信息。当在信息处理装置100已经被设置为紧急模式的状态下识别出紧急情况时,可以向收听者发出警告,作为虚拟声音(包括语音)。
·声音模式:
可以从语音模式和虚拟声音模式下选择声音模式。声音模式是以下一种模式:其中,信息处理装置100基于根据传感器510的检测结果的信息识别,在识别的情况下提供信息作为虚拟生成的声音。如下所述,可以进行设置,使得收听者可以从委托模式和简档模式下进行选择。可以经由要在与信息处理装置100协作的外部装置(例如,智能手机)的显示器上提供的gui(图形用户界面)以菜单格式从这些模式下进行选择。或者,可以通过对提供给信息处理装置100的主体的按钮、杠杆、触摸传感器等的操作,以逐步的方式提供从这些模式下选择。
·引导模式:
如下所述,引导模式是可以从委托模式或简档模式下自动或手动选择并且改变引导提供方法的模式。委托模式是将提供的指导委托给个人代理的模式,简档模式是根据针对各种情况分别定制的简档来执行引导的模式。
·感测模式:
感测模式是信息处理装置100基于传感器510的检测结果根据信息识别来提供信息作为虚拟声音(包括语音)的模式。如下所述,作为感测模式,信息处理装置100提供两种类型,具体为:正常模式和白手杖模式。
可以经由用户界面选择上述四种主要模式。作为也可以用于模式选择的用户界面,诸如开关、滑动条和触摸传感器(包括将输入信息转换成电信号并将这些信号发送到处理装置的电路或总线)的输入装置可以提供在信息处理装置100的外壳的正面。信息处理装置100可以通过语音命令来设置模式。或者,可以经由与信息处理装置100协作的外部装置(例如,智能手机、智能手表或眼镜)的用户界面发出模式选择的指令。当与信息处理装置100协作的外部装置具有诸如智能手机的触摸屏显示器时,可以经由显示器上的gui显示菜单,使得可以经由触摸屏发布模式选择的指令。注意,无论收听者是否想要语音服务,要提供的用户界面都可以允许用户通过他/她的语音选择要提供的信息的级别,或者允许收听者选择该级别。
图27示出了声音模式和感测模式的组合之间的状态转换关系。在控制信息提供方法时,信息量控制和引导模式可以添加到图27所示的四种状态。这允许收听者根据例如他/她对声音信息的期望或者对声音信息的需要程度来控制不同级别的信息。
注意,在该实施方式中,为了方便表示假定的功能,给出了引导模式下的模式的名称。因此,其他名称也可以用于类似的功能。此外,下面描述的功能也可以通过其他方法来区分。
(a)引导模式
引导模式至少细分为以下两个功能。例如,引导模式被配置为允许收听者经由用户界面选择以下任何功能。
(a-1)委托模式(信息量控制模式)
委托模式是个人代理在当前时间点或沿时间线读取信息(呈现作为虚拟声音的信息)或适当表达作为虚拟声音的信息的模式。
通过如上所述经由为信息量控制提供的用户界面来调整级别,可以调整信息处理装置100读取(用虚拟声音进行表达)的频率。
可以进行设置,使得即使当信息处理装置100处于虚拟声音模式时,在有来自收听者或其他人的语音查询的情况下也能做出响应作为虚拟生成的语音。当信息量控制被设置为最低级别(最小、零)时,信息根本不作为虚拟声音(包括语音)提供。同时,在信息量控制已经被设置为最大级别(max)的状态下,如果代理基于传感器当前识别的信息发现感兴趣的话题,则连续地提供信息作为虚拟声音(包括语音)。当要控制的信息量是中间值时,以一定的间隔提供信息。
信息量控制可以被设置为根据系统以预设数量逐步切换。在一个实施方式中,要控制的信息量可以设置在1到10的刻度内,1是最小值,10是最大值。可以进行设置,使得每次数字从刻度上的最大值减少1时,读取间隔延长1分钟,或者每次数字从刻度上的最大值减少1时,要读取的句子中的单词的数量减少一半。此外,收听者或其他人可以经由与信息处理装置100协作的外部装置(例如,智能手机)的用户界面适当地进行信息量控制的设置。
此外,委托模式可以与简档选择模式结合使用。在这种情况下,在信息处理装置100已经根据特定简档提供了作为虚拟声音(包括语音)的信息的状态下,当收听者感觉信息量太大时,收听者可以通过调整级别来减少信息量(生成语音消息的频率)。同时,当收听者想要更多的消息时,将级别设置为最大值是合适的。当收听者想要像语音翻译一样实时翻译来自另一方的消息的所有内容时,仅通过将级别设置为最大值就可以翻译所有内容。
在委托模式没有与简档选择模式相结合的状态下,在简档中被定义为在对象识别处理中优先考虑的对象的对象是属于在最近识别的对象中很少被识别的对象的类别(类或子类)的对象。换言之,运行在信息处理装置100的控制器551上的个人代理可以被配置为基于从传感器510获取的信息来执行对象识别,对在预定时间段内观察到的对象的类别(类或子类)执行统计处理,并且如果识别出不常见的对象,则为收听者生成声音信息。
个人代理可以在通过无线或有线通信连接的诸如互联网等网络上的服务器装置(例如,处理装置或存储器(包括存储器))上运行。在这种情况下,信息处理装置100经由无线模块553将经由麦克风541等获取的来自收听者的语音信息发送到服务器装置1750。在服务器装置1750侧,针对接收到的语音信息执行实时语音识别,然后基于识别结果,将由已经理解来自收听者的查询内容的个人代理生成的语音信息返回给信息处理装置100。然后,信息处理装置100可以通过利用从服务器装置1750接收的语音信息向收听者做出语音响应。
此外,当个人代理使用信息处理装置100中的控制器551处理经由传感器510获取的信息时,个人代理也可以立即将信息发送到服务器装置。在这种情况下,在服务器装置中执行对来自传感器510的信息的分析处理或识别处理。信息处理装置100能够接收分析处理或识别处理的结果,并且能够将这些结果作为语音信息呈现给收听者。
(a-2)简档选择模式
预先从信息处理装置100的简档中进行选择,必要时,信息处理装置100基于所选择的简档的定义生成引导作为虚拟声音(包括语音)。根据定义,简档选择模式包括以下形式。
·家庭模式:
家庭模式是个人代理响应于来自收听者的语音查询而将信息作为虚拟声音(包括语音)提供的模式。对收听者来说,他/她的家通常是一个熟悉的环境,通常,没有收听者需要支持的情况。因此,通过设置信息处理装置100不提供作为虚拟声音(包括语音)的信息,除非有来自陷入麻烦情况的收听者的查询,收听者不会被不必要的虚拟声音(包括语音)困扰。这种情况下的“麻烦情况”是例如视觉障碍的收听者请求确认某种信息(例如“告诉我冰箱里还有什么”)的情况。在家庭模式下,信息处理装置100不生成作为虚拟声音(包括语音)的信息,除非收听项目不进行查询。在家庭模式下,在对象识别处理中优先考虑的对象是不能从过去的信息中识别的人或对象。
·办公模式:
办公模式是这样一种模式,其中,信息处理装置100基于例如传感器510的检测结果来监视收听者的动作,并且在信息处理装置100识别出异常动作的情况下,提供在该情况下需要的个人代理的响应。当(虚拟)语音模式被设置为声音模式时,信息处理装置100将信息呈现为虚拟生成的声音。当已经设置了虚拟声音模式时,信息处理装置100将信息呈现为虚拟声音。
例如,当收听者长时间停留在自动售货机前面时,估计(推断)收听者不知道选择哪一个的情况。因此,信息处理装置100生成例如语音消息,例如,“咖啡在右上角”。此外,当收听者长时间停留在电梯大厅的中心而不与任何人交谈时,信息处理装置100生成语音消息“右转并直走,您将找到自动售货机”。此外,当选择了虚拟声音模式时,虚拟声源移动,使得其声像定位于自动售货机上的咖啡按钮(具体地,定位于收听者的手的虚拟声源从指尖向自动售货机移动,并且声像最终定位于咖啡按钮)。通过这种方式,可以告知收听者咖啡按钮的位置。
在办公模式下,收听者的目标位置是有限的。例如,当收听者走出办公室进入走廊,然后在洗手间或自动售货机区之间进行选择时,定位声像,而其的声源占有对象,并且交替地和连续地朝着洗手间和自动售货机区的方向移动。这允许收听者正好在风从他/她的耳朵附近吹向两个方向时有印象。在分支点处,当洗手间在左侧,并且自动售货机拐角在右侧时,从左耳附近生成对应于其声像被定位到的洗手间的声源数据,同时声源向洗手间的方向移动,并且从右耳附近生成对应于其声像被定位到的自动售货机的声源数据,同时声源向自动售货机区的方向移动,这些数据彼此交替地生成。当收听者在分支点右转时,确定已经选择自动售货机区,并且当声源在向自动售货机区的方向上移动时,仅定位对应于自动售货机区的声源的声像。
在办公模式下的对象识别处理中优先考虑的对象是收听者通常使用的对象(洗手间、餐厅、自动售货机区),或者收听者长时间停留的地方的收听者前面的对象。
·输出模式:
作为输出模式,可以设置多个进一步细分的模式。作为一个实施方式,可以从以下模式下选择输出模式。
从输出模式进一步细分的所有模式都有相应的名称。然而,模式的名称不一定表示模式的相应功能。例如,可能会给出不直接暗示功能的名称或者抽象名称,例如,模式a、模式b、模式c、...。现在,描述从输出模式细分的所有模式。
·步行模式(或模式a)
步行模式是这样一种模式,其中,当收听者在他知道并每天访问的地方走动时,优先提供确保安全所必需的建议。即使当已经设置委托模式时,并且同时即使当信息量控制已经设置为最小值时,信息处理装置100也总是提供对于确保安全性来说必不可少的特定信息,作为虚拟声音(包括语音)。例如,当信息处理装置100基于作为一个传感器510的障碍物检测传感器(对象检测传感器511)的检测结果识别出车辆正从收听者后方接近时,例如,在碰撞风险高的情况下,信息处理装置100生成语音消息。在行走模式下,在对象识别处理中优先考虑的对象是障碍物。
·购物模式(或模式b)
购物模式是这样一种模式,其中,对预先列出的值得注意的一个项目提供指导。在购物模式下的对象识别处理中优先考虑的对象是登记在购物列表中的对象。
·行驶模式(或模式c)
行驶模式是这样一种模式,其中,根据预先制定的计划向收听者适当地提供必要的建议。信息处理装置100基于例如经由gps(或gnss)获取的位置信息和经由图像传感器513获取的图像信息,收集在互联网上提供的关于商店和酒店的地图信息和信息,并通过组合该信息来提供建议。此外,在收听者的当前位置处于可能发生盗窃、事故等的地方的情况下,信息处理装置100提供提醒收听者的特定信息作为虚拟声音(包括语音)。在警报级别被设置为高的地方,信息处理装置100优先于其他语音消息提供警报消息。此外,信息处理装置100可以总是提供警报消息,即使当已经设置委托模式时,同时,即使当信息量控制已经设置为最小值时。在行驶模式下在对象识别处理中优先考虑的对象是poi(兴趣点)。poi包括在指南或者在地图上需要注意的点(例如,易被盗窃的区域、易发生事故的区域等)以及与某些poi相关联的对象(例如,纪念品、餐单、名画等)中突出显示的旅游景点、商店、酒店、机场、汽车租赁公司、博物馆和剧院。
·观看模式(或模式d)
观看模式是这样一种模式,其中,适当地提供关于在收听者当前所在的地方举行的演出等中的观看目标的必要建议。例如,当信息处理装置100基于gps(或gnss)的检测结果识别出收听者在剧院时,信息处理装置100允许设置在服务器装置1750中或驻留在信息处理装置100自身的存储器552中的个人代理在演出开始时间之前从网络上的服务器装置获取关于剧院演出的信息。例如,当所获取的关于表演的信息是外语,因此收听者难以理解时,可以包括收听者通过使用翻译功能等能够理解的并且能够描述演出内容的信息。此外,在以英语作为母语或日常语言的收听者观看日本歌舞伎表演的情况下,个人代理可以根据表演的进展将大纲翻译成英语。通过这种方式,信息处理装置100可以用英语进行解释。在信息处理装置100已经被设置为委托模式的情况下,通过将委托模式与信息量控制相结合,可以调整关于要解释的内容的语音信息量。在观看模式下的对象识别处理中优先考虑的对象是表演中的场景。
·休闲模式(或模式e)
休闲模式是这样一种模式,其中,在推荐的时间提供关于所选休闲(例如,爬山和露营)的推荐信息。例如,当信息处理装置100基于作为一个传感器510的gps的检测结果识别出收听者处于攀登入口时,信息处理装置100可以生成关于收听者的语音消息,例如,“请在此提交攀登计划”。在休闲模式下在对象识别处理中优先考虑的对象是poi(例如,攀登入口和营地)以及与这些poi相关联的特殊项目(例如,攀登杆和小屋)。
·运动模式(或模式f)
运动模式是这样一种模式,其中,基于作为一个传感器510的加速度传感器或陀螺仪传感器的检测结果,来检测收听者身体的运动,然后记录传感器信息,由此适当地提供必要的建议。例如,当收听者正在打网球时,在加速度传感器尽管已经连续识别出正加速度但突然识别出负加速度的情况下,信息处理装置100识别出收听者已经做出击球的动作。当信息处理装置100认识到击球的时间晚了时,信息处理装置100可以提供建议,作为语音信息,例如,“稍微早一点挥动球拍”。在运动模式下,在对象识别处理中优先考虑的对象是与运动相关的工具,例如,球和球拍。
·其他模式:
作为其他模式的一个示例,具有驾驶支持模式(或模式g)。驾驶支持模式是这样一种模式,其中,通过允许信息处理装置100中的个人代理与安装在汽车中的计算机上运行的个人代理交换信息,或者通过汽车的计算机的移动无线通信功能与在诸如互联网等网络上的服务器装置上运行的个人代理交换信息,来提供声音信息服务,允许个人代理通过将诸如汽车信息娱乐系统等车载无线装置(例如,蓝牙(商标))和信息处理装置100的无线模块553彼此连接来彼此交换信息,使得可以在其间执行通信。由用户选择或自动执行切换到驾驶支持模式。当一起执行简档的切换时,可以提供不同的声音信息服务。当连接到汽车的车载计算机的nfc(近场通信)读取器通过邻近无线通信认证信息处理装置100时,可以自动建立连接。或者,只有在信息处理装置100基于传感器信息识别出用户在车上之后,个人代理才可以自动连接到汽车的计算机的无线装置。
(b)感测模式
如图28所示,通过作为传感器510的各种传感器,根据待检测区域的大小,感测模式细分为至少两种功能模式,具体地,“正常模式”和“白手杖模式”。收听者或其他人可以经由信息处理装置100的用户界面或者外部装置的用户界面选择感测模式,以与其协作。
如图28所示,正常模式下的目标是在收听者周围的环境中能够被传感器510检测到的所有对象。正常模式下的检测区域由附图标记2801表示。在正常模式下,图28中的对象“id005”和“id360”对应于检测目标。同时,在白手杖模式下,执行在可由传感器510检测的对象中检测和识别存在于由虚线包围的预定范围内的对象的操作。白手杖模式下的检测区域由附图标记2802表示。在白手杖模式下,仅检测到对象“id360”。
在白手杖模式下,从收听者或小区域周围观察的前方主要集中在以下情况:收听者用手电筒照亮前方,收听者用白手杖摸索道路,或者导盲犬在收听者周围警戒。白手杖模式主要用于基于对象检测传感器511的检测结果提供外围信息的目的。通过将经由对象检测传感器511获取的信息与经由图像传感器513和深度传感器512获取的信息相结合,可以提供用于提供增强服务的配置。
注意,尽管在图28所示的示例中,以圆柱形示出了白手杖模式下的检测区域2802,但是该形状仅表示仅在预定范围内检测到目标。因此,检测区域的形状不限于圆柱形。此外,根据系统设计,白手杖模式下的检测区域2802可以以各种形式限制。
同样关于声像定位的方法,各种形式是可以想象的。例如,当个人代理的角色类型在白手杖模式下被设置为“狗”时,可以定位声像,同时其声源以在地面附近移动的方式改变其位置。
在每种感测模式下,信息处理装置100能够通过将感测模式与声音模式相结合并通过执行信息量控制来以各种形式提供信息。此外,响应于特定事件的发生,例如,收听者接近他/她最喜欢的地方,或者个人代理接近推荐的地方,信息处理装置100可以自动将感测模式从正常模式切换到白手杖模式。通过这种方式,可以向收听者提供声音信息服务,同时进一步限制信息量。当然,信息处理装置100可以响应于另一事件的发生而自动且反向地从白手杖模式恢复到正常模式。
(b-1)正常模式
正常模式是信息处理装置100的白手杖模式已经关闭的模式。在正常模式下,信息处理装置100基于对环境状况的分析或识别结果,将与收听者周围环境中的对象相关的信息作为虚拟声音(包括语音)来提供,其中,利用来自作为传感器510的各种传感器的全部传感器信息。
(b-2)白手杖模式
白手杖模式可以被认为是这样一种模式,其中,优先执行诸如在离收听者相当短的距离内的对象检测之类的处理。信息处理装置100在必要时根据声音模式提供关于在离收听者很短的距离内检测到的对象的信息,作为虚拟声音(包括语音)。这种情况下的“很短距离”对应于白手杖模式下的检测区域的范围。(直径约为5m或更小的范围是可取的)。对象检测传感器511的功能是总是在收听者的脚附近搜索。白手杖模式可以与语音模式相结合。此外,当白手杖模式与虚拟声音模式组合时,信息量被限制为小于要作为虚拟生成的声音提供的信息的信息量。因此,可以为视觉障碍的收听者提供相对满意的环境。
在白手杖模式下,为了在收听者自己用手杖行走时表达声音,信息处理装置100可以例如与行走步骤(当振动传感器等识别行走步骤时的步骤,或者收听者要同步他/她的步骤的参考行走步骤)同步地生成虚拟脉冲声音。或者,信息处理装置100可以生成前方人员的虚拟脚步,这给出了其他人正在前方行走的印象,或者可以生成三维声响空间中前方的其他虚拟声音信息,然后定位脚步的声像。例如,当对象检测传感器511识别出沿相同方向前进的前方人员时,可以强调前方人员的脚步,使得收听者可以跟随,并且脚步的声像可以定位在三维声响空间中。
或者,在白手杖模式下,当信息处理装置100检测到前方有可能碰撞的对象时,信息处理装置100根据该对象的类型生成虚拟声音。具体地,可以通过使用虚拟声源向收听者提供服务,如上面1.4“虚拟声源的区分”中所示例的。或者,信息处理装置100可以在三维声响空间中再现来自点声源的脉冲和声纳的虚拟声音,并计算空间传播,从而向收听者呈现虚拟反射声音。
图30示出了基于深度传感器512的检测结果从图29所示的真实空间(收听者的真实视场)识别的三维空间。在图30中,由深度传感器512在16个尺度上感测的深度信息被表示为根据深度的灰度图像。注意,由于从深度传感器512提取的点云数据信息的信息量太大而不能直接使用,所以例如可以应用诸如体素网格滤波等滤波处理。此外,图31示出了基于图30所示的深度信息从设置在三维声响空间中的虚拟声源3101再现的虚拟声音如何被设置在相同空间中的另一对象3102反射以及反射的声音如何传播通过由附图标记3103表示的空间,以到达收听者的双耳。在图31所示的示例中,虚拟声源3101设置在收听者视场中更远处的墙壁上,并且坐在房间中的女性对应于反射对象3102。信息处理装置100计算在再现设置为三维声响空间中的虚拟声源3101的来自点声源的脉冲或声纳的虚拟声音时的空间传播,并且根据计算的空间传播来移动和定位声源的声像。
如图31所示,在向收听者呈现虚拟反射声音时,信息处理装置100可以进一步根据对象检测传感器511检测到的对象的属性或特征(例如,对象的硬度)来精细控制呈现声音的方法。具体地,当用对象检测传感器511检测到的障碍物是坚硬对象(例如,墙壁或柱子)时,信息处理装置100呈现高音。当检测到软障碍物(例如,人)时,信息处理装置100呈现低音。这允许收听者基于由信息处理装置100呈现的声音的音高来掌握对障碍物的感觉,并且准备(预期)与障碍物碰撞。注意,通过另外使用毫米波传感器等以及对象检测传感器511,可以有利地获得关于对象硬度的信息。
此外,信息处理装置100可以根据到障碍物的距离来改变声音的音量。具体地,信息处理装置100随着障碍物变得越来越近而增大声音的音量,并且随着障碍物变得越来越远而减小声音的音量。这允许收听者基于由信息处理装置100呈现的声音的音量来掌握到障碍物的距离,并且准备(预期)与障碍物碰撞。例如,允许收听者做避免碰撞的动作,特别是停止行走或向不同的方向行走。
此外,信息处理装置100还能够在白手杖模式下的检测区域中识别应当呈现虚拟声音的对象的对象id,从而基于这些对象的数据提供呈现虚拟声音的服务。例如,当所识别的对象可由收听者操作时(或者当收听者需要操作该对象时),信息处理装置100可以通过利用虚拟声音的声像定位的移动来引导收听者执行期望的操作。
注意,收听者可以接近并直接操作对象,或者可以远程操作对象。作为远程操作的方法的示例,可以提及使用收听者的手势的远程指令以及经由信息处理装置100的用户界面(例如,触摸传感器514)的远程指令。收听者可以选择这些对象操作方法中的任何一种,并且信息处理装置100通过使用虚拟声音的声像定位的移动来引导收听者,使得收听者可以根据所选择的操作方法来操作对象。例如,信息处理装置100通过如上所述的虚拟声音表达技术“占有(占有对象)”来引导收听者操作对象。
收听者可操作的对象可以发出例如指示其自身的对象id的信息。或者,信息处理装置100可以通过识别由图像传感器513拍摄的对象的图像来指定对象id。在前一种情况下,收听者可操作的对象可以通过利用允许在白手杖模式下的检测区域内通信的短程无线技术,例如,ble(蓝牙(商标)低能量),来发出用于虚拟声源呈现的信标。或者,对象可以利用使用光束或声波的信标及其组合处理。信息处理装置100可以从经由无线模块553接收的信标中包含的信息中识别对象id。或者,诸如二维条形码或二维标记等视觉信息可以附着到收听者可操作的对象,并且信息处理装置100可以根据图像传感器513拍摄的图像的图像识别结果来指定对象id。
此外,信息处理装置100可以从诸如互联网等网络上的服务器装置或者从与信息处理装置100协作的外部装置(例如,智能手机)获取呈现虚拟声音所必需的虚拟声音信息,用于引导收听者基于对象id来操作对象。当然,信息处理装置100可以与对象id相关联地缓存曾经用于呈现虚拟声音的虚拟声音信息。
然后,信息处理装置100通过从服务器装置或外部装置获取虚拟声音呈现信息,或者通过利用缓存的虚拟声音呈现信息,来移动虚拟声音的声像定位。以这种方式,信息处理装置100引导收听者操作对象。
在这种情况下,通过以下情况的特定示例,来描述信息处理装置100在白手杖模式下的操作示例:如图32所示,佩戴信息处理装置100的收听者进入电梯门厅3200,并操作作为可操作对象的电梯开关(“向上”和“向下”按钮)。
在电梯大厅3200中,电梯的“向上”按钮3202和“向下”按钮3203对应于收听者可操作的对象,并且应该从该对象向收听者呈现虚拟声音。在图32所示的示例中,安装在“向上”按钮3202和“向下”按钮3203之间的发射机3204发射ble信标,用于指定对象,具体地,包括“向上”按钮3202和“向下”按钮3203的“电梯开关”。同时,当“向上”按钮3202和“向下”按钮3203落在白手杖模式下的检测区域3201内时,佩戴在收听者的右耳或左耳中的两个或至少一个上的信息处理装置100(图32中未示出)从发射机3204接收ble信标。通过这种方式,信息处理装置100可以指定“电梯开关”的对象id。
图33示出了从作为远程指令的目标的对象发送的用于虚拟声源呈现(声音线索)的ble信标的帧格式的示例。该ble分组3300从分组的开头开始依次包括前导字段3301、访问地址字段3302和协议数据单元(pdu)字段3303,并且用于纠错的长度为3oct的crc(循环冗余码)3204添加到分组的末尾。前同步码字段3301存储长度为1oct的比特流,用于在接收侧逐比特同步。此外,访问地址字段3302存储长度为4oct的固定数据,用于在接收端逐字节地进行分组鉴别和同步(在广告信道的情况下)。pdu字段3303存储在分组3300中携带的长度高达39oct的主要数据部分。
由附图标记3310表示在发送信标时使用的广告信道的pdu字段3303的格式。广告信道的pdu字段3303从pdu字段3303的开头开始依次包括长度为2oct的报头字段3311、长度为6oct的广告商地址字段3312和长度高达31oct的广告商数据字段3313。
此外,在用于声音线索的ble信标的帧的情况下,由附图标记3320表示广告商数据字段3313的配置的细节。广告商数据字段3313包括:长度为9字节的声音线索信标前缀字段3321,其指示该分组是声音线索的信标;长度为16字节的uuid字段3322,其存储允许唯一识别对象的uuid(通用唯一标识符);长度为2字节的声音类型字段3323,其指示虚拟声音的类型;长度为2字节的优先级字段3324,其指示虚拟声音的优先级;以及长度为1字节的tx功率字段3325,其指示分组的发送功率。uuid用作对象id。
返回参考图32进行描述。信息处理装置100获取呈现用于引导收听者操作对象的虚拟声音所必需的虚拟声音信息,特别是“向上”按钮3202或“向下”按钮3203,虚拟声音信息是基于从ble信标获取的对象id而获取的,并且是从诸如互联网等网络上的服务器装置获取的,或者是从与信息处理装置100协作的外部装置(例如,智能手机)获取的。或者,当对应于从ble信标获取的对象id的虚拟声音信息已经高速缓存在例如存储器552中时,信息处理装置100从高速缓冲存储器中获取该虚拟声音信息。
图34示出了基于由从电梯门厅3200中的发射机3204发射的ble信标指定的对象id来获取的虚拟声音信息的配置示例。图34所示的虚拟声音信息是用于引导收听者操作“向上”按钮3202或“向下”按钮3203的信息。在下文中,该信息也称为“电梯开关对象”。为了更好地理解,以自然语言格式描述图34中例示的电梯开关对象。或者,电梯开关对象可以用任意语言描述。
图34中所示的电梯开关对象包括关于相应的电梯开关的对象id的信息3401(在图34中所示的示例中,电梯的对象id是“evsw0340”)、关于电梯开关的参考位置和参考方向的信息3402、用于使用于引导收听者向该电梯开关发出远程指令的虚拟声源进行定位的api(在图34所示的示例中,称为“api-typeselecton_a_or_b”)3403、以及用于使用于引导收听者直接操作该电梯开关的虚拟声源进行定位的api(在图34所示的示例中,称为“api_locatoin_presentation”)3404。
由附图标记3402表示的关于电梯开关的参考位置和参考方向的信息是用于设置电梯开关的局部坐标系(相对于世界坐标系)的信息。在图32和图34所示的示例中,电梯开关的局部坐标系的原点设置在电梯的向上按钮3202和向下按钮3203之间,并且设置(1,0,0),即,北向被设置为前向。图35示出了为电梯开关设置的局部极坐标系统。
参考符号3403表示用于使用于引导收听者向该电梯开关发出远程指令的虚拟声源进行定位的api。该api包括用于识别引导收听者向电梯开关发出远程指令的虚拟声源的声源id(os0030)、为收听者从电梯开关的远程指令中进行选择而定义的辅助语音的文本信息和语音信息、用于识别引导收听者向电梯的向上按钮3202发出远程指令(“向上”)的虚拟声源的声源id(os0030)、指示该虚拟声源的定位位置的信息、用于识别引导收听者向电梯的向下按钮3203发出远程指令(“向下”)的虚拟声源的声源id(os7401)、以及指示该虚拟声源的定位位置的信息。注意,是否由收听者为命令选择定义辅助语音取决于对象。然而,在虚拟声音模式下,不需要使用这种辅助声音。(在下文中,同样适用。)
参考符号3404表示用于使用于引导收听者直接操作该电梯开关的虚拟声源进行定位的api。该api包括用于识别引导收听者直接指示电梯开关的虚拟声源的声源id(os0031)、为收听者直接选择电梯开关而定义的辅助消息和辅助语音、用于识别将收听者引向电梯的向上按钮3202的位置的虚拟声源(或用于指示向上按钮3202的位置)的声源id(os0031)、指示该虚拟声源的定位位置的信息、用于识别将收听者引向电梯的向下按钮3203的位置的虚拟声源(或用于指示向下按钮3203的位置)的声源id(os7402)、以及指示该虚拟声源的定位位置的信息。
注意,用于引导收听者向电梯开关发出远程指令的虚拟声源的定位位置由局部坐标系(以收听者的头部中心为中心的极坐标系统)来表示,这些定位位置由图34所示的电梯开关对象中的附图标记3403表示的代码部分来定义。图36示出了每个虚拟声源的声像的定位位置。引导收听者向向上按钮3202发出远程指令的虚拟声源的定位位置是由附图标记3601表示的位置,该位置是在以下方向上与头部中心间隔40cm的位置:从收听者角度来看,相对于对应于前向方向的0°,顺时针方向上的方位角为45°,对应于级别面上的旋转坐标;并且相对于同一前向方向的0°,仰角为10°,对应于垂直平面上的旋转坐标。同时,引导收听者向向下按钮3203发出远程指令的虚拟声源的定位位置是由附图标记3602表示的位置,该位置是在以下方向上与头部中心间隔40cm的位置:从收听者角度来看,相对于对应于前向方向的0°,顺时针方向上的方位角为-45°,对应于级别面上的旋转坐标;并且相对于同一前向方向的0°,仰角为10°,对应于垂直平面上的旋转坐标。
因此,当选择了对电梯开关的远程指令时,如图37所示,由声源id“os0030”指定的虚拟声音的声像从电梯的向上按钮3202移动到由附图标记3601表示的定位位置,例如,沿着由附图标记3701表示的轨迹。通过这种方式,引导收听者向向上按钮3202发出远程指令。此时,收听者可以发出选择向上按钮3202的远程指令,例如,通过触摸佩戴在他/她的右耳上的信息处理装置100的触摸传感器514(参考图38)。信息处理装置100通知电梯侧已经经由服务器装置或协作外部装置(例如,智能手机)选择了向上按钮3202。
此外,如图37所示,由声源id“os7401”指定的虚拟声音从电梯的向下按钮3203移动到由附图标记3602表示的定位位置,例如,沿着由附图标记3702表示的轨迹。通过这种方式,引导收听者向向下按钮3203发出远程指令。此时,收听者可以发出选择向下按钮3203的远程指令,例如,通过触摸佩戴在他/她的左耳上的信息处理装置100的触摸传感器514(参考图39)。信息处理装置100通知电梯侧已经经由服务器装置或协作外部装置(例如,智能手机)选择了向下按钮3203。
图34中所示的电梯开关对象中的代码部分由附图标记3403表示,可以被视为api的描述示例,api假设收听者将信息处理装置100佩戴在他/她的两个耳朵上,并且使用左右信息处理装置100发出远程指令。作为图36至图39的变型例,图40示出了仅使用佩戴在他/她的右耳上的信息处理装置100来表达引导收听者向电梯开关发出远程指令的虚拟声音的技术的示例。由声源id“os0030”指定的虚拟声音的声像沿着由附图标记4001表示的轨迹从电梯的向上按钮3202移开,然后被定位到由附图标记4003表示的收听者的右上臂。通过这种方式,引导收听者向向上按钮3202发出远程指令。此外,由声源id“os7401”指定的虚拟声音的声像沿着由附图标记4002表示的轨迹从电梯的向下按钮3203移开,然后被定位到由附图标记4004表示的收听者的右前臂。通过这种方式,引导收听者向向下按钮3203发出远程指令。注意,在虚拟声音的相应声像已经定位到收听者的手臂之后,这些声像可以以风消失的方式返回到向上按钮3202和向下按钮3203。此时,如图41所示,收听者可以通过触摸佩戴在他/她的右耳上的信息处理装置100的触摸传感器514的上侧来发出选择向上按钮3202的远程指令,并且可以通过触摸触摸传感器514的下侧来发出选择向下按钮3203的远程指令。
注意,在白手杖模式下向检测区域中的对象发出远程指令时,信息处理装置100的用户界面(例如,触摸传感器514)不必如图38、图39和图41所示那样使用,而是可以使用收听者的手势。例如,可以基于深度传感器512的检测结果来识别收听者的手势操作,例如,用他/她的手触摸或与期望的操作目标的声像相交以及触摸佩戴在他/她的耳朵上的信息处理装置100的上侧或下侧。
此外,用于引导收听者直接操作电梯开关的虚拟声源的定位位置在图34所示的电梯开关对象中由附图标记3404表示的代码部分定义,由对应于由附图标记3402表示的部分的以电梯开关的参考位置为中心的极坐标系统表示(参见图35)。图42示出了用于引导收听者直接操作电梯开关的虚拟声源的定位位置。引导收听者直接操作向上按钮3202的虚拟声源的定位位置是由附图标记4201表示的位置,该位置是在以下方向上与参考位置间隔20cm的向上按钮3202的位置:从参考位置(在向上按钮3202和向下按钮3203之间)角度来看,相对于对应于前向方向的0°,顺时针方向上的方位角为0°,对应于级别面上的旋转坐标;并且相对于同一前向方向的0°,仰角为90°,对应于垂直平面上的旋转坐标。同时,引导收听者直接操作向下按钮3203的虚拟声源的定位位置是由附图标记4202表示的位置,该位置是在以下方向上与参考位置间隔20cm的向下按钮3203的位置:从参考位置角度来看,相对于对应于前向方向的0°,顺时针方向上的方位角为0°,对应于级别面上的旋转坐标;并且相对于同一前向方向的0°,仰角为90°,对应于垂直平面上的旋转坐标。
因此,如图43所示,当选择对电梯开关的直接操作时,由声源id“os0031”指定的虚拟声音的声像从收听者的右耳附近移动到向上按钮3202,例如,沿着由附图标记4301表示的轨迹。通过这种方式,将收听者引导到向上按钮3202的位置。然后,当收听者想要乘电梯上楼时,他/她可以通过直接按下由声源id“os0031”指定的虚拟声音的声像已经定位到的向上按钮3202,来呼叫电梯的轿厢上楼。类似地,由声源id“os7402”指定的虚拟声音的声像从收听者的右耳附近移动到向下按钮3203,例如,沿着由附图标记4302表示的轨迹。通过这种方式,将收听者引导到向下按钮3203的位置。然后,当收听者想要乘电梯下楼时,他/她可以通过直接按下由声源id“os7402”指定的虚拟声音的声像已经定位到的向下按钮3203,来呼叫电梯的轿厢下楼。
图44以流程图的形式示出了在白手杖模式下由信息处理装置100执行的处理。在白手杖模式下,信息处理装置100检测从检测区域中的对象发送的ble信标,向收听者呈现虚拟声源,并响应于收听者的操作来控制目标装置(例如,电梯)。基本上在控制器551的控制下执行信息处理装置100中的处理。
在白手杖模式下,信息处理装置100等待在白手杖模式下的检测区域中检测到ble信标(步骤s4401)。然后,当信息处理装置100检测到ble信标时(步骤s4402中为是),信息处理装置100执行接收ble分组的处理(步骤s4403)。
接下来,参考接收到的ble信标中的声音线索信标前缀,信息处理装置100检查该前缀是否用于虚拟声源(步骤s4404)。当前缀不用于虚拟声源时,接收到的ble信标的源不是作为远程指令的目标的对象。因此,信息处理装置100不需要向收听者呈现虚拟声音,因此结束该处理。
同时,当前缀用于虚拟声源时(步骤s4404中为是),接收到的ble信标的源是作为远程指令的目标的对象。因此,信息处理装置100另外检查关于对应于ble信标中描述的uuid(对象id)的虚拟声音的信息是否已经缓存(步骤s4405)。
当关于相应uuid的信息还没有缓存时(步骤s4405中为否),信息处理装置100查询互联网上的服务器装置或协作的外部装置(例如,智能手机)关于uuid的信息(步骤s4406),并等待,直到做出具有关于对应于uuid的虚拟声音的信息(例如,电梯开关对象)的响应(步骤s4407)。
当在服务器装置侧或外部装置侧接收到来自信息处理装置100的关于uuid的查询时(步骤s4411中为是),服务器装置或外部装置用关于对应于uuid的虚拟声音的信息来响应信息处理装置100(步骤s4412),然后结束到处理装置100的连接。
然后,当信息处理装置100从服务器装置或外部装置接收到关于虚拟声音的信息时(步骤s4407中为是),或者当关于虚拟声音的信息已经缓存时(步骤s4405中为是),信息处理装置100移动并定位虚拟声源的声像,用于引导收听者在白手杖模式下操作在检测区域中检测到的对象(步骤s4408)。在步骤s4408中,信息处理装置100引导收听者通过虚拟声音表达技术“占有(占有对象)”来操作对象,例如,如图37、图40和图43所示。
收听者通过虚拟声音的声像的移动和定位的引导,向白手杖模式下的检测区域中的对象发出远程指令。然后,信息处理装置100响应于收听者发出的远程指令来控制目标装置(步骤s4409),并结束该处理。
图45以流程图的形式示出了信息处理装置100在图44所示的流程图中的步骤s4408中呈现虚拟声音的详细处理。
信息处理装置100将来自虚拟声源的定位信息的外围三维地图加载到存储器552,该虚拟声源的定位信息包括在步骤s4407中获取的虚拟声音信息(例如,电梯开关对象)中(步骤s4501)。
信息处理装置100可以向互联网上的服务器装置或协作的外部装置(例如,智能手机)查询相应的三维地图。服务器装置或外部装置总是等待来自信息处理装置100的查询。然后,响应于来自信息处理装置100的查询(步骤s4511中为是),服务器装置或外部装置用地图信息进行响应(步骤s4512)。
当信息处理装置100已经将地图信息加载到存储器552中时(步骤s4502中为是),信息处理装置100随后将与在步骤s4407中获取的虚拟声音信息中包括的声源id相对应的声源数据加载到存储器552中(步骤s4503)。
信息处理装置100可以向服务器装置或协作的外部装置查询相应的声源数据。然后,响应于来自信息处理装置100的查询(步骤s4513中为是),服务器装置或外部装置用声源数据进行响应(步骤s4514)。
当信息处理装置100已经将声源数据加载到存储器552中时(步骤s4504中为是),信息处理装置100在虚拟声源的定位位置的外围三维地图中估计在他/她的耳朵上佩戴该信息处理装置100的收听者的头部位置(步骤s4505)。
然后,基于虚拟声音信息中包括的虚拟声源的定位信息以及基于收听者的头部位置,信息处理装置100生成用于移动和定位虚拟声音的声像的轨迹(步骤s4506)。信息处理装置100再现虚拟声音的声源数据,同时沿着该声源轨迹移动和定位声像(例如,参考图37)(步骤s4507)。然后,信息处理装置100结束用于呈现虚拟声音的处理。
图46以流程图的形式示出了信息处理装置100响应于在图44所示的流程图中的步骤s4409中由虚拟声音引导的收听者的远程指令来控制目标装置的详细处理。
当信息处理装置100接收到对用户界面(例如,触摸传感器514)的输入,或者识别出收听者的手势时(步骤s4601中为是),信息处理装置100通过将被选择作为操作目标的对象的对象id(远程指令)、所选择的api类型、以及关于与收听者选择的操作相对应的声源id的信息发送到互联网上的服务器装置或协作的外部装置(例如,智能手机),来进行查询(步骤s4602)。例如,在电梯开关对象已经是操作目标并且已经选择了api类型“selection_a_or_b”的状态下,当收听者通过触摸佩戴在他/她的右耳上的信息处理装置100的触摸传感器514来进行选择时(例如,参考图38),信息处理装置100向服务器装置或外部装置查询声源id“os0030”,并且等待来自作为查询目的地的服务器装置或外部装置的响应(步骤s4603)。
服务器装置或外部装置以及被收听者选择作为操作目标的装置一直等待查询。
当服务器装置或外部装置从信息处理装置100接收到关于对象id、api类型和关于所选择的声源id的信息的查询时(步骤s4611中为是),服务器装置或外部装置指定所选择的装置,作为操作目标,并且请求操作目标装置执行与已经查询的api类型和声源id相对应的控制(步骤s4612),并且等待来自作为请求目的地的操作目标装置的响应(步骤s4613)。
当操作目标装置从服务器装置或外部装置接收到查询时(步骤s4621中为是),操作目标装置用已经接受控制请求的通知来响应(步骤s4622),然后根据请求的内容来控制操作目标装置自身的操作(步骤s4623)。然后,在操作目标装置已经根据控制请求完成其操作之后,操作目标装置再次进入查询等待模式。
接下来,当服务器装置或外部装置从作为控制请求的目的地的操作目标装置接收到控制接受的通知时(步骤s4613中为是),服务器装置或外部装置通知作为查询源的信息处理装置100操作目标装置已经接受了控制(步骤s4614),然后再次进入查询等待模式。
之后,当信息处理装置100从作为查询目的地的服务器装置或外部装置接收到操作目标装置已经接受控制的通知时(步骤s4603中为是),信息处理装置100向收听者提供反馈,即收听者在步骤s4601中输入的操作已经完成(步骤s4604)。然后,信息处理装置100结束该操作。
(c)个人代理
个人代理是运行在计算机处理器上的软件(计算机程序)。在该实施方式中,信息处理装置100使个人代理驻留在存储器552中,并监视收听者的动作。这允许个人代理识别收听者的动作,并根据信息处理装置100的模式设置(如上所述)提供适当的信息,作为虚拟声音信息(包括语音信息)。个人代理的一部分可以驻留在存储器552中(换言之,本地在信息处理装置100中),并且个人代理的另一部分或另一个人代理可以在诸如互联网(或云)等网络上运行。通过这种方式,服务可以与云协作地提供给收听者。
图47示出了个人代理和声响空间控制软件的处理之间的关系的示例。注意,在图47中,传感器510(包括麦克风541)、用户界面4701和声响生成单元110是信息处理装置100的主要硬件。(用户界面4701可以包括触摸传感器514,或者可以是提供给信息处理装置100的机械控制器,例如,按钮或开关。或者,用户界面4701可以包括由与信息处理装置100协作的外部装置(例如,智能手机)提供的用户界面)。同时,在图47中,除了上面提到的那些之外,由虚线包围的其他处理块基本上表示当由处理器(例如,控制器551)执行软件模块时要从存储器552中读取的软件模块和数据(内部状况(例如,信息量和模式)以及识别对象的数据)。
注意,由图47所示的组件分别执行的处理彼此并行执行,除非处理之间相互需要同步等待。因此,当多处理器可用时,或者当多线程可以由操作系统(os)实现时,可以彼此并行执行的所有处理块可以读取到存储器中,并且彼此并行执行。例如,在个人代理软件中,传感处理单元4702和输出信息确定处理单元4706相互关联,使得其处理相互用作数据缓冲器,因此总是可以彼此并行执行。情境识别处理单元4703的处理和动作识别处理单元4705的处理可以类似地彼此并行执行。
个人代理能够通过使传感处理单元4702、情境识别处理单元4703、动作识别处理单元4705和学习/估计处理单元4704相互协作来提供人工智能的功能。人工智能的功能可以由个人代理软件的一部分、作为硬件的控制器(或专用神经网络加速器)或这些软件和硬件的组合来提供。期望人工智能的功能处理由配备有上述神经网络加速器555的控制器5151或者作为独立实体控制神经网络加速器555的控制器551提供。控制器551可以使用神经网络作为个人代理软件中的一些处理来执行诸如学习和估计(推断)等处理。
当个人代理经由包括麦克风541的传感器510获取输入,并且获取内部状态数据(例如,收听者经由用户界面4701选择的模式)和信息量时,个人代理将这些输入数据发送到情境识别处理单元4703、动作识别处理单元4705和学习/估计处理单元4704。注意,学习/估计处理单元4704可以是可选的,或者其处理可以仅在必要时执行。将在下面详细描述学习的功能。情境识别处理单元4703在其处理中从数据库(未示出)获取关于检测到的对象的信息。注意,当数据库由诸如互联网(或云)等网络上的服务器装置管理时,情境识别处理单元4703经由通信接口(例如,无线模块553)与服务器装置通信,从而获取关于检测到的对象的信息。由情境识别处理单元4703获取的对象的数据和识别的情境的数据以及由动作识别处理单元4705识别的收听者的动作的数据发送到输出信息确定处理单元4706。注意,情境识别处理单元4703和动作识别处理单元4705可以例如通过使用学习的神经网络的估计(推断)处理来执行识别。
在输出信息确定处理单元4706中,例如,在向其发送的数据上适当地执行使用学习/估计处理单元4704已经学习的神经网络的估计(推断)处理,该数据包括内部状况数据,例如,收听者经由用户界面4701选择的模式和信息量。通过这种方式,选择三维声响空间所需的数据。例如,已经被确定为在输出信息确定处理单元4706中输出的对象的声源数据发送到声响空间控制软件的声像位置控制处理单元4707。声像位置控制处理单元4707例如通过声响空间渲染计算声源的位置移动的效果,并且通过基于hrtf数据设置dsp533的滤波器来执行定位声像的处理。然后,最终由三维声响空间生成处理单元4708生成的三维声响空间中的声音发送到作为音频输出驱动器的声响生成单元110,然后作为声音数据通过管状声音引导部120输出到收听者的耳朵。
注意,声响空间控制软件的处理需要考虑收听者的耳朵处的hrtf来执行,因此,软件在存储在包括麦克风541和声响生成单元110的信息处理装置100的存储器552中的同时运行是合适的。然而,关于个人代理软件的其他处理(例如,基于对象识别提供对象信息),其一些或全部相应的处理块可以由与信息处理装置100协作的外部装置(例如,智能手机)中或者在诸如互联网(或云)等网络上的服务器装置中的代理在代理处理中执行。此外,尽管期望将对象数据的数据库存储在由服务器装置管理的存储器中,但是该数据库可以存储在收听者使用的个人装置中的存储器中,例如,与信息处理装置100协作的外部装置(例如,智能手机)。
现在,描述在信息处理装置100中执行的代理处理的示例。注意,在信息处理装置100中,代理在电源接通后重复以下处理步骤。
(步骤1)
在传感处理单元4702中,彼此并行地执行三个处理,具体地,深度处理(对经由深度传感器512接收的深度数据的处理)、图像处理(对经由图像传感器513接收的图像数据的处理)和对象检测处理(对已经经由对象检测传感器511接收的检测对象的数据的处理)。当控制器551(例如,mpu)包括多核处理器时,执行真正的并行处理。当控制器551包括单核处理器时,由os的调度器执行伪并行处理(多处理或多线程处理)。作为深度处理,执行通过过滤将经由深度传感器512捕捉的深度数据转换成便于管理空间的深度信息(例如,体素网格)的信息的处理。以这种方式,生成深度图信息。作为图像处理,执行图像识别处理,以识别对象,由此生成关于所识别的对象的信息。作为对象检测处理,在用户周围检测到可能碰撞的对象,由此生成关于所识别的对象的信息。这些处理中的一些或全部可以由诸如互联网(或云)等网络上的服务器装置执行,或者由与信息处理装置100协作的外部装置(例如,智能手机)执行。
(步骤2)
与传感处理单元4702的感测处理并行,情境识别处理单元4703执行情境识别处理。情境识别处理包括基于由传感处理单元4702生成的对象信息和深度图信息来识别对象。为了提取关于所识别的对象的信息,在随后的步骤3(如下所述)中调用对象数据获取处理。这些处理中的一些或全部可以由诸如互联网(或云)等网络上的服务器装置执行,或者由与信息处理装置100协作的外部装置(例如,智能手机)执行。
(步骤3)
在对象数据获取处理中,从识别出的对象中选择收听者可能非常感兴趣的对象,从数据库中获取关于该目标对象的声源的信息。该处理的一部分或全部可以由诸如互联网(或云)等网络上的服务器装置执行,或者由与信息处理装置100协作的外部装置(例如,智能手机)执行。当在信息处理装置100的外部,具体地,在服务器装置中,执行对象数据获取处理时,数据库存储在网络上的存储器中,该存储器可经由无线或有线通信连接到服务器装置,使得服务器装置等可从该数据库获取数据。
(步骤4)
输出信息确定处理单元4706获取关于所选声源的信息(在对象数据获取处理中经由存储器552或通信线路获取信息)。该声源信息包括例如基于例如到对象的距离的关于检测到的对象的位置的信息(当对象是固定位置的对象,例如,电梯时,向数据库登记的位置信息)以及与对象相关联地登记的声源的数据。
(步骤5)
声像位置控制处理单元4707基于收听者的当前位置信息和所获取的对象的位置信息,将收听者和对象映射到三维声响空间中的位置,并计算所定义的声像(例如,占有对象的图像)在两个映射位置之间的移动轨迹。
(步骤6)
在三维声响空间生成处理中,通过控制声响空间滤波器来生成三维声响数据,使得当声源沿着在前面的步骤5中生成的轨迹移动时,定位声像。此时,三维声响空间生成处理单元4708还考虑收听者的单独hrtf执行滤波处理。此外,生成的声响数据从扬声器544声响输出。(或者,声响数据由声响生成单元110转换成由物理振动形成的声响,然后经由声音引导部120输出到收听者的耳朵。)
现在,描述从四个角度控制个人代理的处理的示例,具体地,声音模式、感测模式、引导模式和信息量控制。
图48以流程图的形式示出了个人代理使传感处理单元4702在上述(步骤1)中执行的感测处理。
首先,个人代理检查信息处理装置100的感测模式是否是白手杖模式(步骤s4801)。
然后,当信息处理装置100处于白手杖模式时(步骤s4801中为是),个人代理将对象检测传感器511设置为短程优先模式(步骤s4802)。如上所述,在白手杖模式下,优先考虑来自用户的短距离内的对象检测(例如,参考图28)。因此,对象检测传感器511的模式被设置为“短程优先模式”。具体地,当信息处理装置100可以使用毫米波雷达和超声波传感器作为对象检测传感器511时,毫米波雷达关闭(或者被设置为启用模式),并且超声波传感器打开(或者被设置为禁用模式),使得可以优先执行超声波传感器对邻近对象的检测。或者,当信息处理装置100仅配备毫米波雷达,作为对象检测传感器511时,毫米波雷达的范围可以被设置为短范围,使得以低功耗执行对象检测。
同时,当信息处理装置100不处于白手杖模式(或正常模式)时(步骤s4801中为否),个人代理将对象检测传感器511的模式设置为“正常模式”(步骤s4803)。在这种情况下,对象检测传感器511不必只在正常的短距离内执行检测,并且可以使用长距离传感器,使得可以最大程度地执行对象检测。或者,当信息处理装置100可以使用多个对象检测传感器时,所有这些传感器可以被设置为启用模式。
图49以流程图的形式示出了个人代理使情境识别处理单元4703在上述(步骤2)情况中执行的情境识别处理。
首先,个人代理检查信息处理装置100的感测模式是否是白手杖模式(步骤s4901)。
然后,当信息处理装置100处于白手杖模式时(步骤s4901中为是),个人代理执行检测可能碰撞的对象是否存在于收听者的前进方向的处理(步骤s4902)。
当在收听者的前进方向上检测到可能碰撞的对象时(步骤s4902中为是),个人代理另外检查信息处理装置100的声音模式是否是虚拟声音模式(步骤s4903)。同时,当在收听者的前进方向上没有检测到可能碰撞的对象时(步骤s4902中为否),个人代理基于例如对象检测传感器511的检测结果执行对象识别处理(s4906)。在个人代理已经获取关于检测到的对象的信息之后,个人代理检查信息处理装置100的声音模式(步骤s4903)。当信息处理装置100处于虚拟声音模式时(步骤s4903中为是),个人代理生成警告虚拟声音(步骤s4904)。同时,当信息处理装置100处于语音模式时(步骤s4903中为否),个人代理生成警告虚拟语音(步骤s4905)。
同时,当个人代理不处于白手杖模式而是处于正常模式时(步骤s4901中为否),个人代理基于例如对象检测传感器511的检测结果执行对象识别处理(s4906),从而获取关于检测到的对象的信息。然后,个人代理另外检查信息处理装置100的声音模式是否是虚拟声音模式(步骤s4907)。当信息处理装置100处于虚拟声音模式时(步骤s4907中为是),个人代理生成与所识别的对象相关的虚拟声音(步骤s4908)。同时,当信息处理装置100处于语音模式时(步骤s4903中为否),个人代理生成用于通知关于识别对象的信息的虚拟语音(步骤s4909)。
图50以流程图的形式示出了在图49所示的流程图中的步骤s4906中要执行的对象识别处理。
首先,个人代理检查信息处理装置100的引导模式(步骤s5001)。
然后,当信息处理装置100的引导模式是委托模式时(步骤s5001中为是),个人代理另外检查信息量是否为0(步骤s5002)。当信息量为0时(步骤s5002中为“是”),收听者不想要声音信息。因此,个人代理停止并结束对象识别处理。同时,当信息量不为0时(步骤s5002中为否),基于预设的信息量并通过对传感器510的检测结果的识别处理(例如,图像处理),个人代理搜索个人代理感兴趣(或想要向收听者推荐)的对象,并列出关于这些对象的信息(步骤s5003)。
同时,当信息处理装置100的引导模式不是委托模式时(步骤s5001中为否),个人代理另外检查在收听者经由用户界面等在信息量控制下设置的信息量是否为0(零)(步骤s5004)。当信息量为0(零)时(步骤s5004中为“是”),收听者不想要声音信息。因此,个人代理停止并结束对象识别处理。同时,当信息量不为0(零)时(步骤s5002中为否),基于预设的信息量,根据在所选的简档中指定的优先级,并通过对传感器510的检测结果的识别处理(例如,图像处理),个人代理搜索对象,并列出关于这些对象的信息(步骤s5003)。
在图50所示的对象识别处理结束后,控制返回到图49所示的情境识别处理。然后,在步骤s4907中,检查声音模式是否是虚拟声音模式,并且基于检查的结果生成虚拟声音(包括语音)。
(d)学习功能的模式选择支持
通过使个人代理驻留在信息处理装置100的存储器552中,以便监视收听者的动作,可以实现用于控制要提供给收听者的语音服务或感测服务中的信息量的学习支持。
例如,收听者选择白手杖模式作为感测模式,选择委托模式作为引导模式,选择虚拟声音模式作为声音模式,并且将信息量控制设置为“最小”。在这种情况下,尽管虚拟声音信息原则上是以白手杖模式提供的,但是个人代理可以仅在收听者进行语音查询的情况下适当地用虚拟生成的语音信息进行响应。
在已经监视了收听者的行为的个人代理识别出收听者在特定的地方停留了预定的时间段或更长时间的情况下,个人代理确定收听者已经处于困境,并且可以激活个人代理的学习/估计处理单元4704,以学习这种情况。
当收听者知道他/她在哪里时,他/她不会查询这个地方。例如,在知道他/她在自动售货机前的收听者有一段时间没有在自动售货机进行购买动作的情况下,收听者说“请指出罐装咖啡在哪里”。由于选择了白手杖模式,所以移动和定位声源(其虚拟声像),以占有罐装咖啡的按钮。
在这种情况下,个人代理激活神经网络加速器555,以使学习/估计处理单元4704学习,或者使用控制器551(例如,mpu)中的神经网络的学习功能。通过这种方式,输入并学习“自动售货机”的位置和“罐装咖啡按钮”的位置,作为输入向量信息。以这种方式,信息处理装置100可以自动执行移动和定位声源的声像的处理,使得当收听者下次来到相同的地方时,声源占有罐装咖啡的按钮,信息处理装置100被设置为白手杖模式。当学习/估计处理单元4704已经学习了关于同一“自动售货机”的多个选项时,可以定位多个声源的多个声像,以指示多个按钮。或者,可以移动和定位虚拟声音的声像,以占有可能被收听者按压的按钮。
在信息处理装置100的学习模式下,可以将日期、天气、最新选择等与关于相应对象(例如,自动售货机)的位置的信息一起学习,作为输入向量信息。这允许个人代理移动和定位虚拟声源的声像,以便当个人代理基于传感器510的检测结果识别出类似情况(由位置、日期、天气、最新选择等定义的一组状态)时,建议收听者按下预定按钮。
当然,当个人代理在诸如互联网(或云)等网络上的服务器装置(例如,处理装置或存储器(包括存储器))上运行,以经由无线或有线通信连接时,服务器装置可以提供学习功能,如上所述。
<2.网络系统>
接下来,描述支持在与信息处理装置100通信的同时提供服务的听觉能力增强系统。
听觉能力增强系统是一种将信息处理装置100包含在也称为“云”的计算机网络系统中的系统,该系统包括要连接到互联网的大量服务器装置(具体地,云服务器、边缘服务器、雾服务器等)、以及与信息处理装置100协作的iot装置或多个信息处理装置100和外部装置(收听者占有的信息终端,例如,智能手机、智能手表、平板电脑和个人计算机)。
个人代理可以根据环境自动或手动选择。个人代理可以作为不同的个人代理例如在诸如互联网(或云)等网络上的服务器装置上,在收听者乘坐的车辆的计算机(收听者自己驾驶的汽车或诸如公共汽车和火车等公共交通工具)上,或者在安装在各种电器(例如,安装在收听者家中的家用服务器、电视和冰箱)中的计算机上运行。可以根据收听者动作的环境自动选择个人代理,或者可以进行设置,使得总是与预先存储在信息处理装置100的存储器552中的一个所选的个人代理建立连接。此外,信息处理装置100存储关于与这些个人代理运行的服务器装置的连接的信息。
当自动选择个人代理时,也可以自动选择简档选择模式。图56示出了简档选择模式下的信息处理装置100的模式转换。个人代理还根据信息处理装置100的模式切换彼此切换。具体地,听觉能力增强系统可以被设置成使得当收听者在家时,家庭个人代理起作用并选择家庭模式,当收听者在他/她的办公室时,办公室个人代理选择办公模式,当收听者去电影院时,电影院专用个人代理选择观看模式,当收听者在他/她的汽车中时,汽车专用个人代理选择驾驶支持模式。
<3.程序>
用于实现上述听觉能力增强功能的计算机程序包括由诸如音频编解码器单元530和控制器551等处理器(更具体地,cpu、mpu、dsp、gpu、gpgpu或以神经网络加速器555的形式提供的程序处理装置)执行的指令。在控制器551可读的存储器552(rom、sram、dram、闪存或ssd)中存储和维护计算机程序。存储器552与构成控制器551的电路芯片(例如,gpu和神经网络加速器555)结合,可以实现为共享存储器,用于允许每个处理单元中包括的大量pe在其相应的处理单元中共享数据。以这种方式,声响空间的计算、神经网络的计算等处理可以独立于外部存储器或外部处理单元而高速且高效地执行。
这些程序记录在可移动存储介质上,例如,便携式半导体存储器和dvd(数字多功能光盘),并作为所谓的打包介质软件来提供。
或者,程序可以记录在连接到互联网的服务器装置的存储装置中,并且可以从该服务器装置下载程序。(服务器装置可以通过指定位置来访问,例如,通过url(统一资源定位符),有时也称为站点。)可以经由互联网或局域网(局域网),具体地,经由诸如蓝牙(商标)或wi-fi(商标)等无线通信或者诸如以太网(商标)或usb(通用串行总线)等有线通信,将程序下载到信息处理装置100。
不管获取方法如何,通过将获取的程序记录在存储器552中,然后将该程序安装为由os管理的程序,根据该实施方式的信息处理装置100的功能可以例如由通用信息终端来实现。
简而言之,计算机程序的形式允许广泛使用根据该实施方式的信息处理装置100。结果,包括视力受损者在内的各种人可以容易地享受由信息处理装置100提供的听觉能力增强功能。
<4.变型例>
关于上文公开的技术的实施方式的描述,可以想到各种其他变型。
(1)个人代理
个人代理的角色可以由收听者经由用户界面选择。角色数据包括如下项目。虽然有些项目是预先定义的,但其他项目可以由收听者自定义和设置。
·类型:可选自人类(标准)、登记的特殊角色(特别是视频游戏和动画中的角色)、动物(猫和狗)、鸟类等。
·性别:当角色类型是人类时可选。
·年龄:当角色类型是人类时可选。
·偏好:例如,可以选择和输入爱好的偏好。
·脾气:可选择温和、积极等。
·(虚拟)音频数据:用于生成当选择语音模式时使用的虚拟声音的数据。
(a)当选择人(标准)作为角色类型时,从语音数据库生成的平均语音的特征数据,语音数据库已经累积了性别、年龄和偏好,作为输入项目。(特征数据是足以根据数据读取文本的数据。)
(b)当角色类型是特殊角色时,扮演该角色的真实语音男/女演员的语音的特征数据。基于特征数据生成虚拟语音男/女演员的语音。
(c)当角色类型为动物时,默认情况下不使用的数据。参考虚拟语音数据。
(d)自动生成的数据:由于对给定声音样本进行分析而提取的语音的特征数据。基于特征数据虚拟生成语音。基于特征数据虚拟生成语音。
·虚拟语音数据(虚拟语音除外):每个数据包括频率、持续时间、声压样本值的时间序列数据或虚拟声音id。虚拟声音id是与在虚拟声音数据库中登记的虚拟声音信息相关联的标识符。当选择了虚拟声音模式时,虚拟声音用作由个人代理发出的基本虚拟声音,用于通知个人代理的存在。当不必要时,虚拟声音可以通过来自收听者的输入而停止,或者可以防止从一开始就生成虚拟声音。
(a)当角色类型为人类(标准)时,默认情况下不会生成的数据。
(b)当角色类型为特殊角色时,默认情况下不会生成的数据。可以针对各种情况分别登记动画等的声音效果,并且可以选择根据所识别的情况适当地生成声音效果的模式。
(c)当角色类型是动物或鸟时,可以定义根据所识别的情况生成的虚拟声音。当角色类型是狗时,可以生成虚拟声音,例如,由围绕收听者跳舞的狗的声源生成的虚拟声音,作为当个人代理的角色的功能以白手杖模式实现时生成的声音。
虚拟声音(包括语音)的数据与角色id相关联地登记。因此,当选择特定的角色id时,可以通过使用特定的虚拟声音(包括语音)来提供服务。
(2)根据对象特征的虚拟声源的属性
可以根据要占有的对象的特性和属性来切换虚拟声源。例如,当收听者乘坐电梯时,在虚拟声源占有电梯的时间点,从脚向电梯方向发出的虚拟声音“嗖嗖”可以切换为类似于电梯到达声音的“叮”。可以预先提供这种特征,作为预设简档,或者可以作为可以由收听者经由诸如智能手机的用户界面来改变的简档。
(3)虚拟声源的数量的控制
在上述实施方式中,描述了控制个人代理的语音消息数量的功能。同时,可以根据基于环境中传感器510的检测结果识别的对象的数量和类型来生成虚拟声源,并且可以定位其声像。当在环境中可以识别的对象数量大且类型多样时,同时当虚拟声源的数量过大时,可以提供控制功能,以允许收听者手动(例如,通过手势)或自动地根据例如他/她的偏好和可用性来控制这些声源的数量。作为减少虚拟声源数量的方法,可以提供以下功能。
·允许收听者手动和明确地关闭特定的虚拟声源。对于这种控制,收听者只需要做出触摸和推开由虚拟声源呈现的声音的位置的手势。当使用tof传感器或立体摄像机识别的用户的手的位置与虚拟声源的方向基本重叠时,可以关闭预定的一个虚拟声源。
·打开与接近收听者的对象相关的虚拟声源,并关闭与从收听者移开的对象相关的虚拟声源。
·在收听者从未去过的地方或在收听者几乎不知道的地方打开虚拟声源,并在收听者曾经去过的地方或在收听者很熟悉的地方关闭虚拟声源。
·打开与个人代理感兴趣或想要向收听者推荐的对象相关的虚拟声源,并关闭与个人代理不感兴趣或不需要向收听者推荐的对象相关的虚拟声源。
(4)作为白手杖模式应用的自主移动系统
信息处理装置100的白手杖模式可以与外部装置相结合。具体地,可以建立听觉能力增强系统,其中,与传感器510或情境识别处理单元4703相对应的自主移动装置(例如,能够自主飞行的自主移动机器人或无人驾驶飞行器(无人机))与信息处理装置100相结合。
在这种情况下,当白手杖模式被选择作为信息处理装置100的感测模式时,与白手杖模式协作的其他外部装置可以是另外可选的。具体地,登记与信息处理装置100协作以在白手杖模式下操作的外部装置。更具体地,经由由配备有显示器的危机用户界面(例如,智能手机)提供的白手杖模式设置屏幕,可以选择可经由短距离无线通信(例如,蓝牙(注册商标))连接的外部装置,作为在白手杖模式下协作的装置。当信息处理装置100在正常模式下操作时,被设置为在白手杖模式下与信息处理装置100协作的外部装置不需要与之协作。以下装置可以例示为可以在白手杖模式下协作的外部装置。
·通用和个人装置,例如,智能手机
·头戴式装置,例如,眼镜(智能眼镜、vr眼镜和ar眼镜)(图16中的功能增强部1402也属于这种类型。)
·佩戴在头部以外的部位的装置,例如,智能手表和肩部佩戴
·专用手持装置,例如,手杖型装置
·自主移动装置,例如,移动机器人和无人机(在地面、地下、空中和水下操作)
在上述装置中,自主移动装置(例如,移动机器人和无人机)不同于其他类型的装置,例如,在移动装置的驱动系统(例如,马达、轮子、腿和螺旋桨)和外壳结构中。然而,处理例如传感器的检测结果的其他部分(例如,传感器、硬件和软件)基本上与上述信息处理装置100的那些相同。因此,可以使自主移动装置(例如,移动机器人和无人机)与作为外部装置的信息处理装置100协作,外部装置辅助收听者收集信息或实现其他目的。
通过使外部装置与信息处理装置100进行协作,至少可以获得以下两个主要优点。
·降低了信息处理装置100的电池消耗。
·降低了信息处理装置100的处理负荷。
图51示出了与信息处理装置100协作的自主移动装置5100的功能配置示例。在图51所示的示例中,作为传感器5110的许多传感器元件和传感器控制器安装在自主移动装置5100中,并且在自主移动装置5100侧执行基于传感器5110的检测结果的识别处理。(尽管未示出,但是传感器5110包括麦克风541(如上所述)。另外,识别的结果经由与自主移动装置5100的配对通信提供给信息处理装置100。因此,可以认为信息处理装置100的电池消耗和处理负荷比图7所示的信息处理装置100的配置示例中的电池消耗和处理负荷降低得更低。
作为执行计算机程序的处理器的控制器5151共同控制整个自主移动装置5100的操作。控制器5151适当地包括处理器,例如,cpu、gpu或神经网络加速器。
由电池控制器(未示出)控制的电池5101向自主移动装置5100中的所有硬件模块供电。
无线模块5153包括根据通信标准(例如,蓝牙(商标)和wi-fi(商标))的通信rf(射频)电路,根据这样的通信标准,无线模块5153可连接到与之协作(或配对)的信息处理装置100。通过这种方式,可以交换控制指令和数据。
存储器5152包括rоm、sram、dram、闪存、ssd等。在存储器5152中存储将由控制器5151执行的计算机程序(软件)和在程序执行时使用的各种数据。
例如,在存储器5152中存储无线连接所需的信息(用于访问信息处理装置100的地址信息,例如,mac地址)以及关于与要经由蓝牙(商标)通信连接的信息处理装置100配对的信息。自主移动装置5100能够利用连接信息以耳机形状连接到信息处理装置100,并且能够为信息处理装置100提供传感器的功能以及情境识别、对象识别等的功能,用于收听者的听觉能力增强。
传感器5110包括各种传感器元件,例如,对象检测传感器5111、深度传感器5112和图像传感器5113。尽管未示出,但是传感器510还可以包括获取位置信息的gps、检测自主移动装置5100的运动的加速度传感器或陀螺仪传感器、检测环境温度的温度传感器等中的至少一个。来自传感器5111、5112、5113、...的相应检测信号分别通过相应的传感器控制器5121、5122、5123、...进行信号处理,然后作为数字检测信号输出。
此外,图52示出了自主移动装置5100的软件和信息处理装置100的软件的协作处理的示例。在图52所示的示例中,个人代理软件在自主移动装置5100上运行,而声响空间控制软件在信息处理装置100上运行。因此,可以认为信息处理装置100的处理负荷比图47所示的软件处理示例中的处理负荷降低得更低,其中,个人代理软件和声响空间控制软件都在信息处理装置100上运行。
当个人代理经由包括麦克风541的传感器5110获取输入时,个人代理将输入的数据发送到情境识别处理单元5203、动作识别处理单元5205和学习/估计处理单元5204。注意,学习/估计处理单元5204可以是可选的,或者可以仅在必要时执行其处理。情境识别处理单元5203在其处理中从数据库(未示出)获取关于检测到的对象的信息。注意,当数据库由诸如互联网(或云)等网络上的服务器装置管理时,情境识别处理单元5203经由诸如无线模块5153等通信接口与服务器装置通信,从而获取关于检测到的对象的信息。由情境识别处理单元5203获取的对象的数据和识别的情境的数据以及由动作识别处理单元5205识别的收听者的动作的数据发送到输出信息确定处理单元5206。注意,情境识别处理单元5203和动作识别处理单元5205可以例如通过使用学习的神经网络的估计(推断)处理来执行识别。
在输出信息确定处理单元5206中,例如,对向其发送的数据适当地执行到使用学习/估计处理单元5204已经学习的神经网络的估计(推断)处理,该数据包括内部状况数据,例如,经由信息处理装置100选择的模式和信息量。通过这种方式,选择三维声响空间所需的数据。例如,已经被确定为在输出信息确定处理单元5206中输出的对象的声源数据发送到声响空间控制软件的声像位置控制处理单元5207。声像位置控制处理单元5207例如通过声响空间渲染计算声源的位置移动的效果,并且通过基于hrtf数据设置dsp533的滤波器来执行定位声像的处理。然后,最终由三维声响空间生成处理单元5208生成的三维声响空间中的声音发送到作为音频输出驱动器的声响生成单元110,然后作为声音数据通过管状声音引导部120输出到收听者的耳朵。
当选择在白手杖模式下的信息处理装置100与移动机器人的协作时,设置移动机器人的个人代理的角色类型。当选择的移动机器人是狗型机器人时,在开始与移动机器人协作时,该个人代理的角色类型被设置为“狗”。
移动机器人被配置为基于由gps和传感器510的检测结果来检查收听者的位置,并且在保持与收听者相距预定位置的同时根据收听者的移动来向前移动收听者。从图52可以理解,移动机器人的个人代理执行感测处理、情境识别处理和对象识别处理。感测处理和情境识别处理类似于由信息处理装置100的个人代理执行的处理(参考图47)。
图53以流程图的形式示出了由自主移动装置的个人代理执行的情境识别处理。个人代理执行对象识别处理(步骤s5301),然后经由例如无线通信向信息处理装置100发送对象声音信息(例如,声源的数据和声源的位置的数据),以输出到三维声响空间,以由协作信息处理装置100再现(步骤s5302)。
图54以流程图的形式示出了由个人代理在信息处理装置100侧执行的三维声响空间生成处理。
首先,个人代理检查信息处理装置100是否已经与自主移动装置协作(步骤s5401)。然后,当信息处理装置100还没有与自主移动装置协作时(步骤s5401中为否),信息处理装置100基于传感器510的检测结果执行情境识别处理(步骤s5406)。
同时,当信息处理装置100已经与自主移动装置协作时(步骤s5401中为是),个人代理等待来自协作的自主移动装置的声音信息(步骤s5402中为否)。
接下来,当信息处理装置100从自主移动装置接收声音信息时(步骤s5402中为是),个人代理另外检查信息处理装置100的声音模式是否是虚拟声音模式(步骤s5403)。当信息处理装置100处于虚拟声音模式时(s5403中为是),声响空间控制软件生成虚拟声音(步骤s5404)。当信息处理装置100处于语音模式时(步骤s5403中为否),提供某个信息,作为虚拟生成的语音。
(5)其他变型
·当收听者遇到队列时,信息处理装置100从收听者的脚生成虚拟声音,并且移动和定位该虚拟声音的声像,使得声像占有队列的尾端。
·用强调个人代理感兴趣的东西或个人代理想要向收听者推荐的东西的声源生成虚拟声音,并且移动和定位声像,使得声像例如围绕收听者的身体转动,然后占有某物。
·在行驶模式下,当收听者在离目的地(例如,高层建筑)稍远的地方(例如,大约1km)时,生成虚拟声音,并且移动和定位其声像,使得声像飞向作为目的地的高层建筑并消失在天空中。允许收听者在从虚拟声音前进的方向掌握到目的地的大致方向的同时继续进行。此外,当收听者已经接近目的地时,通过逐渐降低飞行虚拟声音的高度,可以给收听者提供收听者已经接近目的地的印象。
·当基于例如gps已经记录的收听者的历史做出收听者已经第一次访问了一个地方的确定时,自动打开信息处理装置100的引导模式,使得例如对该地方进行解释。
·当收听者走到自动售货机时,信息处理装置100生成虚拟声音,并移动和定位该虚拟声音的声像,使得虚拟声音占有可向收听者推荐的产品的按钮。当已经为自动售货机学习的多个选项(例如,咖啡、茶和橙汁)可用时,使得虚拟声音占有通过使用轮盘等随机选择的候选按钮。
·在收听者第一次访问的地方,或者当收听者第一次经历声像定位时,打开个人代理的学习功能。
·即使当声音信息的量非常有限时,服务器装置也可以管理数据库中与识别的地点和关于时间点的信息相关联的所有识别的对象的列表。在这种情况下,可以提供“语音再现”功能,使得当收听者有时间时,收听者可以接收关于当天由传感器识别的对象的语音信息服务。在这种情况下,用户界面可以提供例如“语音再现”按钮(不仅包括硬件按钮,还包括通过软件经由gui提供的按钮),使得收听者可以通过按下“语音再现”按钮来接收关于当天由传感器识别的对象的信息。此外,同样在这种情况下,当收听者感觉信息量大时,收听者可以经由用于“信息量控制”的用户界面来控制声音信息的量(作为虚拟声音(包括语音)提供的信息)。
注意,关于本文使用的诸如“声音id”、“虚拟声音id”、“角色id”和“对象id”之类的术语,只要这些id是uuid,并且只要“声音”、“虚拟声音”、“角色、“对象”等被认为是分配uuid的数据结构的类型,就没有问题。例如,如图55所示定义上述电梯的对象。在图55所示的示例中,不仅定义了电梯开关的标识符是“evsw0340”,电梯是“对象”的子类,并且电梯的基本声源的标识符是“os9470”,还定义了电梯的基本声源的标识符是“os9470”,并且pcm声源是“声源”的子类,并且定义了声源数据的数据大小和pcm声源数据的数据块。
工业适用性
在上文中,已经参考具体实施方式详细描述了本文公开的技术。然而,很明显,本领域技术人员可以在本文公开的技术要点内修改或替换实施方式。
应用本文公开的技术的信息处理装置是主要具有呈现声音信息(作为声音或虚拟声音提供的信息)的功能的语音信息处理装置或语音信息处理系统。然而,从如下所述具有在三维声响空间中增强收听者听觉能力的功能的观点来看,在另一方面,信息处理装置也是“听觉能力增强装置”。此外,在又一方面,信息处理装置具有助听器的功能。此外,本文结合对基础技术的描述来描述本发明特有的优点,并且本文公开的技术不限于权利要求中描述的发明。
简而言之,本文公开的技术已经通过举例的方式进行了描述,并且本文描述的内容的解释不应该受到限制。为了确定本文公开的技术的要点,应该参考权利要求。
注意,本文公开的技术也可以采用如下配置。
(1)一种信息处理装置,包括:
传感器,其检测对象;
耳朵开放式耳机,其戴在收听者的耳朵上,并且包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中;以及
处理单元,其处理声源的声音信息,所述声音信息是由所述声响生成单元生成的,
所述处理单元执行以下处理:
获取与由所述传感器检测到的对象相对应的声源的声音信息,以及
在根据三维声响空间中的位置改变声像的位置的同时定位所获取的声源的声像,所述三维声响空间中的位置对应于检测到的对象的位置。
(2)根据(1)所述的信息处理装置,其中,
所述声源生成虚拟声音,并且
所述处理单元相对于生成虚拟声音的声源的声像执行在改变声像位置的同时定位声源的声像的处理。
(3)根据(2)所述的信息处理装置,其中,
由处理单元处理的虚拟声音具有与通过耳朵开放式耳机的开口部到达耳膜的声音的特征不同的特征。
(4)根据(1)至(3)中任一项所述的信息处理装置,其中,
所述传感器具有与感测模式一致的检测区域。
(5)根据(4)所述的信息处理装置,其中,
所述感测模式包括
正常模式,其中,传感器在传感器的正常检测区域中执行检测,以及
白手杖模式,其中,传感器在比正常模式下的正常检测区域小的检测区域中执行检测。
(6)根据(5)所述的信息处理装置,其中,
在白手杖模式下,当传感器检测到收听者周围的预定范围内的区域中的对象时,所述处理单元执行在改变声像的位置的同时定位声源的声像的处理。
(7)根据(5)或(6)所述的信息处理装置,还包括
led,其具有发射多种颜色的光束的功能,其中,
在白手杖模式下,所述led发射多种颜色中预定一种颜色的光束。
(8)一种信息处理装置,包括:
传感器,其检测对象;
耳朵开放式耳机,其戴在收听者的耳朵上,并且包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中;以及
处理单元,其处理声源的声音信息,由所述声响生成单元生成所述声音信息,
所述处理单元执行以下处理:
获取所述声源的声音信息,所述声音信息对应于与由所述传感器检测到的对象相关并且由信息提供单元提供的信息,以及
在选择声音信息的类型并控制声音信息的量的同时定位所获取的声源的声像。
(9)根据(8)所述的信息处理装置,其中,
所述声音信息的类型是语音数据或声源数据。
(10)根据(8)或(9)所述的信息处理装置,其中,
所述处理单元根据生成声源数据的声音的频率来控制声音信息的量。
(11)根据(9)或(10)所述的信息处理装置,其中,
在声音信息的类型是语音数据的情况下,所述声音信息包括
角色id,以及
关于由角色id指定的语音的特征的信息。
(12)根据(9)或(10)所述的信息处理装置,其中,
在声音信息的类型是声源数据的情况下,所述声音信息包括以下中的至少一个
频率,
持续时间,
声压样本值的时间序列数据,或
声音id。
(13)根据(8)所述的信息处理装置,其中,
所述信息提供单元
从数据库获取要从对象指定的信息,并且
提供要从对象指定的信息。
(14)根据(8)所述的信息处理装置,其中,
所述信息提供单元
与连接到互联网的服务器装置上运行的软件通信,并且
获取并提供服务器从对象中指定的信息。
(15)根据(8)所述的信息处理装置,其中,
所述处理单元包括个人代理。
(16)根据(15)所述的信息处理装置,其中,
所述个人代理提供人工智能的功能。
(17)根据(16)所述的信息处理装置,其中,
所述人工智能的功能是用于学习或估计(推断)的计算。
(18)根据(8)所述的信息处理装置,还包括
神经网络处理单元。
(19)根据(18)所述的信息处理装置,其中,
所述神经网络处理单元执行人工智能的功能的处理。
(20)根据(8)至(19)中任一项所述的信息处理装置,其中,
所述处理单元还在个人代理的控制下通过信息提供单元执行处理。
(21)根据(20)所述的信息处理装置,还包括
存储器,其存储与对象相关的信息,其中,
所述信息提供单元从存储器中读取并提供与对象相关的信息。
(22)根据(20)或(21)所述的信息处理装置,还包括
通信单元,其中,
所述信息提供单元
向经由通信单元连接的服务器装置查询与对象相关的信息,并且
从服务器装置接收并提供与对象相关的信息。
(23)根据(20)或(21)所述的信息处理装置,还包括:
通信单元;以及
麦克风,其中,
所述信息提供单元
通过发送收听者的语音来向经由通信单元连接的服务器装置查询与对象相关的信息,经由麦克风获取所述语音,并且
从服务器装置接收并提供与对象相关的信息。
(24)根据(23)所述的信息处理装置,其中,
所述信息提供单元还从服务器装置接收对应于所述语音的相关信息,并且
所述处理单元
获取所述声源的声音信息,所述声音信息包括在相关信息中,并且
执行定位声源的声像的处理。
(25)一种信息处理装置,包括:
耳朵开放式耳机,包括
声响生成单元,其设置在收听者的耳朵的后部,以及
声音引导部
其具有经由耳垂附近从耳朵的耳廓后部向后折叠到耳朵的耳廓前部的结构,并且
将由声响生成单元生成的声音发送到耳孔中;
传感器,其获取外部信息;以及
处理器,在选择了多种模式下的任何一种模式的状态下操作所述信息处理装置,
所述处理器
基于经由传感器获取的外部信息再现外部三维空间,
生成虚拟声音信息,用于使声响生成单元根据从多种模式下选择的模式生成声音,并且
定位在三维空间中位置随时间变化的声源的声像。
(26)一种信息处理方法,包括:
检测对象的步骤;
获取与检测到的对象相对应的声源的声音信息的步骤;
执行在根据三维声响空间中的位置改变声像的位置的同时定位所获取的声源的声像的处理的步骤,所述三维声响空间中的位置对应于检测到的对象的位置;以及
从耳朵开放式耳机输出声像的声音的步骤,包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中。
(27)一种信息处理方法,包括:
检测对象的步骤;
获取与相对于检测到的对象提供的信息相对应的声源的声音信息的步骤;
执行在选择声音信息的类型并控制声音信息的量的同时定位所获取的声源的声像的处理的步骤;以及
从耳朵开放式耳机输出声像的声音的步骤,包括
声响生成单元,以及
声音引导部,其将由声响生成单元生成的声音发送到耳孔中。
附图标记列表
100信息处理装置
110声响生成单元
120声音引导部
130保持部
501电池
511对象检测传感器
521传感器控制器
512深度传感器
522传感器控制器
513图像传感器
523传感器控制器
514触摸传感器
530音频编解码器单元
531adc
532dac
533dsp
534接口控制器
541麦克风
542误差麦克风
543麦克风放大器
544扬声器
545扬声器放大器
551控制器
552存储器
553无线模块
554led
555神经网络加速器
1301卷积神经网络(cnn)
1302总线接口
1303权重处理单元
1304加法器
1305神经网络后处理单元
1306共享缓冲器
1307输出处理单元
1400听觉能力增强系统
1401主体部
1402功能增强部
1411、1412连接端子
1601控制器
1602存储器
1611、1612io接口
1715滤波器(hrtf)
1718滤波器(声响环境传递函数)
1720基于声像位置的hrtf数据库
1721周围声响环境数据库
1722用户界面
1724声像位置控制单元
1725声响环境控制单元
1726麦克风
1727控制器
1728选择单元
1730无线通信单元
1750服务器装置
4701用户界面
4702传感处理单元
4703情境识别处理单元
4704学习/估计处理单元
4705动作识别处理单元
4706输出信息确定处理单元
4707声像位置控制处理单元
4708三维声响空间生成处理单元
5201用户界面
5202传感处理单元
5203情境识别处理单元
5204学习/估计处理单元
5205动作识别处理单元
5206输出信息确定处理单元
5207声像位置控制处理单元
5208三维声响空间生成处理单元。
- 还没有人留言评论。精彩留言会获得点赞!