发送装置、发送方法、处理装置以及处理方法与流程
本技术涉及发送装置、发送方法、处理装置以及处理方法,并且更具体地,涉及发送基于场景的音频等的数据的发送装置。
背景技术:
使用为宽视角提供的反射镜、透镜等捕获宽视角图像。在发送宽视角图像的运动图像数据的情况下,在接收侧,当在宽视角图像的固定位置处的图像被截取并显示时,还考虑使用立体声再现方法将语音输出互锁。作为立体声再现方法,基于场景的方法是已知的。非专利文献1描述了高保真度立体声响复制(基于场景的音频)。
引用列表
非专利文献
非专利文献1:ryuichinishimura,“高保真度立体声响复制”,图像信息和电视工程师协会杂志,第68卷,第8期,第616至620页(2014年)
技术实现要素:
本发明要解决的问题
本技术的目的是使得能够容易地获取对应于宽视角图像的固定位置的语音输出。
问题的解决方案
根据本技术的一方面,一种发送装置包括发送单元,被配置为发送空间语音数据和关于预定数量的登记视点的信息。
在本技术中,处理单元发送空间语音数据和关于预定数量的登记视点的信息。例如,关于视点的信息可以包括关于指示该视点的位置的方位角(方位角信息)和仰角(仰角信息)的信息。例如,空间语音数据可以是基于场景的音频数据。在这种情况下,例如,基于场景的音频的数据可以是hoa格式的每个分量。
例如,发送单元可以将基于场景的音频的数据和关于预定数量的登记视点的信息包括在对象音频的包中以进行发送。在这种情况下,例如,对象音频的包可以是mpeg-h音频流包。此外,在这种情况下,例如,发送单元可以将对象音频的包包括在isobmff的容器中以进行发送。
以这种方式,在本技术中,发送空间语音数据和关于预定数量的登记视点的信息。因此,在接收侧,可以容易地获取与宽视角图像的固定位置相对应的语音输出。
注意,在本技术中,例如,可以对关于预定数量的登记视点的信息进行分组。以这种方式,通过在接收侧对信息进行分组,可以针对每个预期目的或每个用户获取对应于宽视角图像的固定位置的语音输出。
此外,根据本技术的另一方面,一种处理装置包括:获取单元,被配置为获取空间语音数据和关于预定数量的登记视点的信息;以及处理单元,被配置为通过基于关于登记视点的信息处理空间语音数据来获取输出语音数据。
在本技术中,通过获取单元获取空间语音数据和关于预定数量的登记视点的信息。例如,空间语音数据可以是基于场景的音频数据。在这种情况下,例如,基于场景的音频的数据可以是hoa格式的每个分量。然后,处理单元通过基于关于登记视点的信息处理空间语音数据来获取输出语音数据。例如,获取单元接收基于场景的音频的数据和关于预定数量的登记视点的信息,或者通过从媒体再现来获取基于场景的音频的数据和关于预定数量的登记视点的信息。
此外,例如,获取单元可以从接收到的对象音频的包中获取基于场景的音频的数据和关于预定数量的登记视点的信息。在这种情况下,例如,对象音频的包可以是mpeg-h音频流包。此外,例如,获取单元可以从被配置为通过基于视点信息处理宽视角图像的图像数据来获取显示图像数据的视频处理系统获取关于预定数量的登记视点的信息。
以这种方式,在本技术中,获取基于场景的音频的数据和关于预定数量的登记视点的信息,并且通过基于关于登记视点的信息处理基于场景的音频的数据来获取输出语音数据。由此,能够容易地获取与宽视角图像的固定位置对应的语音输出。
注意,在本技术中,例如,可以对预定数量的登记视点信息进行分组,并且处理单元可以使用基于用户属性或合同内容确定的组的视点信息。在这种情况下,可以以获取对应于用户的属性或合同内容的语音输出的方式执行限制。
此外,在本技术中,例如,还可以包括被配置为对通知用户当前视点的位置与由关于登记视点的信息指示的位置之间的关系进行控制的控制单元。在这种情况下,用户可以容易地将当前视点的位置移动到由关于登记视点的信息指示的位置。
本发明的效果
根据本技术,可以容易地获取对应于宽视角图像的固定位置的语音输出。注意,这里描述的效果不一定是限制性的,并且可以是本公开中描述的任何效果。
附图说明
[图1]是示出基于mpeg-dash的流传输系统的配置示例的框图。
[图2]是示出在mpd文件中分级布置的结构之间的关系的示例的图。
[图3]是示出根据实施例的发送和接收系统的配置示例的框图。
[图4]是示意性地示出发送和接收系统的整个系统的配置示例的图。
[图5]是用于描述用于从球面表面捕获图像获取投影画面的平面包装的图。
[图6]是示出hevc编码中的spsnal单元的结构示例的图。
[图7]是用于描述使截取位置的中心o(p,q)与投影画面的参考点rp(x,y)一致的图。
[图8]是示出渲染元数据的结构示例的图。
[图9]是示出图8所示的结构示例的主要信息的内容的图。
[图10]是用于描述图8所示的结构示例中的每一条信息的图。
[图11]是示出“video_viewpoint_grid()”的结构示例的图。
[图12]是示出图11所示的结构示例的主要信息的内容的图。
[图13]是用于描述作为登记视点的视点网格的图。
[图14]是用于描述视点网格的位置的图。
[图15]是用于描述按类别对视点网格进行分组的示例的图。
[图16]是示出图15所示的分组中的组1到3的用户的显示示例的图。
[图17]是示出视点网格的类别和子类别的具体示例的图。
[图18]是示出在mpeg-h3d音频的发送数据中的音频帧的结构示例的图。
[图19]是示出“audio_viewpoint_grid()”的结构示例的图。
[图20]是示出图19所示的结构示例的主要信息的内容的图。
[图21]是示出作为传输流的视频mp4流的示例的图。
[图22]是示出与mp4流相对应的mpd文件的描述示例的图。
[图23]是示出在使用hmd和hmd扬声器观看和收听的情况下的示例的图。
[图24]是示出在使用hmd和房间扬声器观看和收听的情况下的示例的图。
[图25]是示出在使用诸如tv和房间扬声器的显示面板观看和收听的情况下的示例的图。
[图26]是示出音频解码器和音频渲染器的特定配置示例的图。
[图27]是用于描述将对应于观察点位置的hoa分量“w、x、y和z”转换为hoa分量“w”、x”、y”和z””的处理的图。
[图28]是用于描述被转换为经布置为围绕收听者的预定数量的扬声器的驱动信号的hoa分量“w”、x”、y”和z””的图。
[图29]是示出服务发送系统的配置示例的框图。
[图30]是示出服务接收装置的配置示例的框图。
具体实施方式
在下文中,对实施本发明的方式(在下文中,称之为实施例)进行描述。注意,将按以下顺序给出描述。
1.实施例
2.变型例
<1.实施例>
[基于mpeg-dash的流传输系统的概述]
首先,将描述可以应用本技术的基于mpeg-dash的流传输系统的概述。注意,可以通过广播或通信来执行传输。在下文中,将主要描述通过通信执行传输的示例。
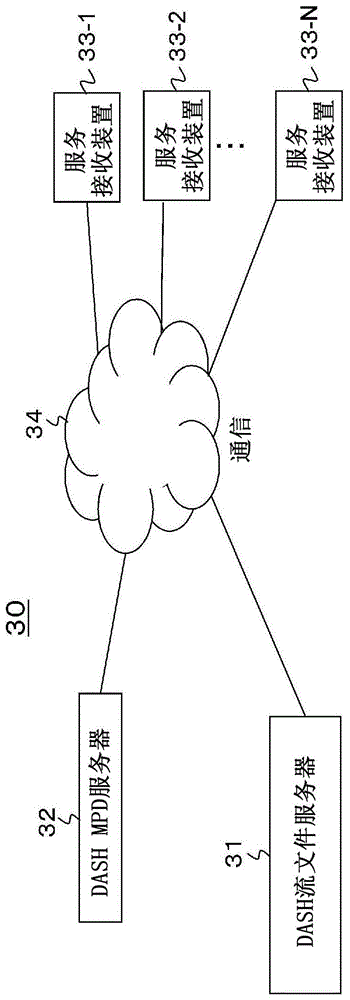
图1示出了基于mpeg-dash的流传输系统30的配置示例。在配置示例中,通过通信网络发送路径(通信发送路径)发送媒体流和媒体展现描述(mpd)文件。流传输系统30具有n个服务接收装置33-1、33-2…和33-n经由内容传输网络(cdn)34连接到dash流文件服务器31和dashmpd服务器32的配置。
dash流文件服务器31基于预定内容(视频数据、音频数据、字幕数据等)的媒体数据来生成具有dash规范的流分段(在下文中,将适当地称为“dash分段”),并响应于来自服务接收装置的http需求来发送该分段。dash流文件服务器31可以是专用于流传输的服务器。此外,在一些情况下,网络服务器用作dash流文件服务器31。
此外,响应于对经由cdn34从服务接收装置33(33-1、33-2、…和33-n)发送的预定流的分段的需求,dash流文件服务器31经由cdn34将该流的分段发送到需求源接收装置。在这种情况下,参考在媒体展现描述(mpd)文件中描述的速率的值,服务接收装置33选择最佳速率的流,并且根据客户端所处的网络环境的状态来执行需求。
dashmpd服务器32是生成用于获取在dash流文件服务器31中生成的dash分段的mpd文件的服务器。dashmpd服务器32基于来自内容管理服务器(未示出)的内容元数据和在dash流文件服务器31中生成的分段的地址(url)来生成mpd文件。注意,dash流文件服务器31和dashmpd服务器32在物理上可以是相同的。
在mpd的格式中,对于视频、音频等的每个流,使用称为表示(representation)的元素来描述每个属性。例如,在mpd文件中,针对具有针对相应表示的不同速率的多个视频数据流来描述相应速率。在服务接收装置33中,参考速率值,可以根据服务接收装置33所处的网络环境的状态如上所述地选择最佳流。
图2示出了在mpd文件中分级布置的结构之间的关系的示例。如图2(a)所示,在作为整个mpd文件的媒体展现中存在以时间间隔分开的多个周期。例如,第一个周期从零秒开始,下一个周期从100秒开始,依此类推。
如图2(b)所示,在每个周期中存在多个适配集。每个适配集取决于诸如视频或音频的媒体类型的差异,甚至对于相同媒体类型的语言的差异、观察点的差异等。如图2(c)所示,在每个适配集中,存在多个表示。每个表示取决于流属性,诸如速率差。
如图2(d)所示,每个表示包括分段信息。如图2(e)所示,在该分段信息中,存在初始化分段和多个媒体分段,其中存在通过进一步精细地分离周期而获取的每个分段的信息。在每个媒体分段中,存在关于用于实际获取诸如视频或音频等分段数据的地址(url)的信息。
注意,可以在适配集中包括的多个表示之间自由地执行流的切换。因此,可以根据接收侧的网络环境的状态来选择具有最佳速率的流,并且可以执行非间歇视频传输。
[发送和接收系统的配置示例]
图3示出了根据实施例的发送和接收系统10的配置示例。发送和接收系统10包括服务发送系统100和服务接收装置200。在发送和接收系统10中,服务发送系统100对应于图1所示的上述流传输系统30的dash流文件服务器31和dashmpd服务器32。此外,在发送和接收系统10中,服务接收装置200对应于图1所示的上述流传输系统30的服务接收装置33(33-1、33-2、…、33-n)。
服务发送系统100通过通信网络发送路径传输dash/mp4,即作为元文件的mpd文件,以及包括视频或音频等媒体流(媒体分段)的mp4(isobmff)流(参见图1)。
视频mp4流包括视频流,该视频流包括通过对宽视角图像的图像数据进行编码而获取的编码图像数据。这里,宽视角图像是通过截取球面表面捕获图像的一部分或全部并执行平面包装而获取的投影画面,但是宽视角图像不限于此。
将渲染元信息插入视频流和/或容器的层中。通过在视频流的层中插入渲染元信息,可以不考虑容器的类型而动态地改变渲染元信息。该渲染元信息包括关于登记在分组中的预定数量的视频视点的信息,并且相应地包括关于预定数量的分组视频视点网格的信息。视点指示显示图像的中心位置,登记视点称为“视点网格”。这里,关于视点网格的信息包括关于方位角(方位角信息)和仰角(仰角信息)的信息。
此外,音频mp4流包括对象音频的包。在该实施例中,包括mpeg-h音频流包。该包包括基于场景的音频的数据、在分组之后登记的预定数量的音频视点信息片,并且因此包括关于预定数量的音频视点网格的信息。这里,基于场景的音频的数据是基于通过在某个位置收集声音而获取的音频数据,在用户面对360度的任意方向时产生的用于再现待输出的声音的数据。基于场景的音频的数据以声音听到的位置根据用户观看的方向而改变的方式形成用于再现语音的空间语音数据。
这里,关于预定数量的音频视点网格的信息与上述关于预定数量的视频视点网格的信息一一对应,并且每个信息通过视点网格id与相应的信息相关联。在这种情况下,关于预定数量的音频视点网格的信息被认为与关于预定数量的视频视点网格的信息基本相同,但是可以考虑关于预定数量的音频视点网格的信息与关于预定数量的视频视点网格的信息部分或完全不同的情况。注意,在两条信息相同的情况下,也可以省略将关于音频视点网格的信息插入到mpeg-h音频流包中。
服务接收装置200接收通过通信网络发送路径从服务发送系统100发送的上述视频和音频的mp4(isobmff)流(参见图1)。
服务接收装置200基于预定的视频视点网格信息,通过处理通过从视频mp4流中提取视频流并且对视频流进行解码而获取的宽视角图像的图像数据来获取显示图像数据。例如,服务接收装置200获取显示图像数据,在该显示图像数据中,将中心位置设置为由用户操作单元从基于用户的属性或合同内容而确定的组中的预定数量的视频视点网格中选择的预定视频视点网格。
此外,服务接收装置200基于关于预定音频视点网格的信息,通过对从音频mp4流中提取的mpeg-h音频流包中进一步提取的基于场景的音频的数据进行处理来获取输出语音数据。
在这种情况下,如上所述,使用与关于在已经获取显示图像数据时已经使用的视频视点网格信息相对应的音频视点网格信息。因此,获取与显示图像互锁的语音输出。注意,在关于音频视点网格的信息未包括在mpeg-h音频流包中的情况下,基于当已经获取显示图像数据时已经使用的关于视频视点网格的信息来获取输出语音数据。注意,下面的描述将假定mpeg-h音频流包包括关于音频视点网格的信息。
图4示意性地示出了发送和接收系统10的整个系统的配置示例。服务发送系统100包括360度相机102、平面包装单元103、视频编码器104、360度麦克风105、hoa转换单元106、音频编码器107、容器编码器108和存储器109。
360度相机102使用预定数量的相机捕获对象的图像,并获取宽视角图像。在本实施例中,360度相机102获取球面表面捕获图像(360°虚拟现实(vr)图像)的图像数据。例如,360度相机102使用背对背方法执行图像捕获,并且获取均使用鱼眼镜头捕获的具有180°或更大视角的超宽视角前表面图像和超宽视角背表面图像作为球面表面捕获图像。
平面包装单元103通过截取360度相机102获取的部分或全部球面表面捕获图像,并且执行平面包装,来获取投影画面。在这种情况下,选择例如等距柱状、交叉立方体等作为投影画面的格式类型。注意,在平面包装单元103中,根据需要对投影画面进行缩放,并且获取具有预定分辨率的投影画面。
图5(a)示出了超宽视角前表面图像和超宽视角背表面图像的示例,其用作由相机102获取的球面表面捕获图像。图5(b)示出了由平面包装单元103获取的投影画面的示例。该示例是投影画面的格式类型为等距柱状的情况的示例。此外,该示例是图5(a)所示的每个图像以虚线示出的纬度截取的情况的示例。图5(c)示出了在其上已经执行了缩放的投影画面的示例。
返回参见图4,视频编码器104例如对来自平面包装单元103的投影画面的图像数据执行诸如mpeg4-avc或hevc的编码,获取编码图像数据,并生成包括编码图像数据的视频流。将截取位置信息插入到视频流的spsnal单元中。例如,在hevc编码中,“conformance_window”对应于截取位置信息,并且在mpeg4-avc编码中,“frame_crop_offset”对应于截取位置信息。
图6示出hevc编码中的spsnal单元的结构示例(语法)。“pic_width_in_luma_samples”的字段指示在投影画面的水平方向上的分辨率(像素大小)。“pic_height_in_luma_samples”的字段指示在投影画面的垂直方向上的分辨率(像素大小)。然后,当设置“conformance_window_flag”时,存在截取位置信息。将该截取位置信息视为其中在投影画面的左上设置基点(0,0)的偏移信息。
“conf_win_left_offset”字段指示截取位置的左端位置。“conf_win_right_offset”字段指示截取位置的右端位置。“conf_win_top_offset”字段指示截取位置的上端位置。“conf_win_bottom_offset”字段指示截取位置的下端位置。
在该实施例中,将由该截取位置信息指示的截取位置的中心设置为与投影画面的参考点一致。这里,当截取位置的中心由o(p,q)示出时,p和q可以分别由下面的公式表示。
p=(conf_win_right_offset-conf_win_left_offset)*1/2
+conf_win_left_offset
q=(conf_win_bottom_offset-conf_win_top_offset)*1/2
+conf_win_top_offset
图7示出使截取位置的中心o(p,q)与投影画面的参考点rp(x,y)一致。在图中所示的示例中,“projection_pic_size_horizontal”指示投影画面的水平像素大小,而“projection_pic_size_vertical”指示投影画面的垂直像素大小。注意,在配备有hmd的vr支持终端中,可以通过渲染投影画面来获取显示视图(显示图像),但是默认视图以参考点rp(x,y)为中心。
在这种情况下,例如,当投影画面包括多个区域时,该多个区域包括中心位置与参考点rp(x,y)相对应的默认区域,由截取位置信息指示的位置经设置与默认区域的位置一致。在这种情况下,由截取位置信息指示的截取位置的中心o(p,q)与投影画面的参考点rp(x,y)一致。
返回参见图4,视频编码器104将具有渲染元数据的sei消息插入到访问单元(au)的“sei”的一部分中。图8示出渲染元数据(渲染元数据)的结构示例(语法)。图9示出了结构示例中的主要信息的内容(语义)。
“rendering_metadata_id”的16位字段是用于识别渲染元数据结构的id。“rendering_metadata_length”的16位字段指示渲染元数据结构的字节大小。
“start_offset_sphere_latitude”、“start_offset_sphere_longitude”、“end_offset_sphere_latitude”,以及“end_offset_sphere_longitude”的相应16位字段指示在执行球面表面捕获图像的平面包装的情况下的截取范围的信息(参见图10(a))。“start_offset_sphere_latitude”的字段指示从球面表面偏移的截取开始的纬度(垂直方向)。“start_offset_sphere_longitude”的字段指示从球面表面偏移的截取开始的经度(水平方向)。“end_offset_sphere_latitude”的字段指示从球面表面偏移的截取结束的纬度(垂直方向)。“end_offset_sphere_longitude”的字段指示从球面表面偏移的截取结束的经度(水平方向)。
“projection_pic_size_horizontal”和“projection_pic_size_vertical”的相应16位字段指示投影画面的大小信息(参见图10(b))。“projection_pic_size_horizontal”的字段指示在投影画面的大小中从左上方开始的水平像素计数。“projection_pic_size_vertical”的字段指示在投影画面的大小中从左上方开始的垂直像素计数。
“scaling_ratio_horizontal”和“scaling_ratio_vertical”的相应16位字段指示来自投影画面的原始大小的缩放比率(参见图5(b)和图5(c))。“scaling_ratio_horizontal”的字段指示从投影画面的原始大小的水平缩放比率。“scaling_ratio_vertical”的字段指示从投影画面的原始大小的垂直缩放比率。
“reference_point_horizontal”和“reference_point_vertical”的相应16位字段指示投影画面的参考点rp(x,y)的位置信息(参见图10(b))。“reference_point_horizontal”的字段指示参考点rp(x,y)的水平像素位置“x”。“reference_point_vertical”的字段指示参考点rp(x,y)的垂直像素位置“y”。
“format_type”的5位字段指示投影画面的格式类型。例如,“0”指示等距柱状、“1”指示交叉立方体、并且“2”指示分段的交叉立方体。
“backwardcompatible”的1位字段指示是否进行向后兼容设置,即,将由插入到视频流的层中的截取位置信息指示的截取位置的中心o(p,q)设置为与投影画面的参考点rp(x,y)一致(参见图7)。例如,“0”指示不进行向后兼容设置,而“1”指示进行向后兼容设置。“video_viewpoint_grid()”是存储关于分组的视点网格的信息的字段。
图11示出了“video_viewpoint_grid()”的结构示例(语法)。图12示出了结构示例中的主要信息的内容(语义)。“initial_viewpoint_grid_center_azimuth”的16位字段指示初始(默认)视点位置偏离参考点的方位角。“initial_viewpoint_grid_center_elevation”的16位字段指示初始(默认)视点位置偏离参考点的仰角。
“number_of_group”的8位字段指示组的数量。重复以下字段该数量的次数。“group_id”的8位字段指示组id。“category”的8位字段指示组的类别(分类类型)。
“number_of_viewpoint_grids”的8位字段指示视点网格(viewpoint_grid)的数量。重复以下字段该数量的次数。“viewpoint_grid_id”的8位字段指示视点网格的id。“sub_category”的8位字段指示一组视点网格中的类别。
“video_center_azimuth”的16位字段指示视点网格的方位角(方位角信息)。“video_center_elevation”的16位字段指示视点网格的仰角(仰角信息)。
这里,将描述视点网格。图13(a)示出了平面转换图像。该图像由朝向风景的矩形包围,并且通过以将失真部分校正为适当图像的方式对上述投影画面执行转换处理而获取。
在附图所示的示例中,在该平面转换图像(宽视角图像)中,将八个视点vpa至vph登记为视点网格。注意,以上描述假定基于方位角(方位角信息)和仰角(仰角信息)来识别每个视点网格的位置。然而,每个视点网格的位置(坐标值)也可以通过从参考点rp(x,y)偏移的像素来表示(参见图7)。如图13(b)所示,在接收侧,通过从由a至h视点网格id识别的相应视点网格中选择期望视点网格,可以显示具有与视点网格相对应的中心位置的图像。
图14是示出与图13(a)的平面转换图像对应的球面表面图像的一部分的图。“c”指示对应于观看位置的中心位置。在附图所示的示例中,示出了与八个视点网格vpa至vph相对应的相应位置的方位角
图15(a)示出了按类别对视点网格进行分组的示例。在附图中所示的示例中,组1包括三个视点网格vpc、vpd和vpg。此外,组2包括两个视点网格vpb和vpe。此外,组3包括三个视点网格vpa、vpf和vph。图15(b)示出了在图15(a)的示例中通过组id分类的类别和视点网格id的列表。
图16(a)示出了组1中的用户的显示示例。这里,如下所述,组1的用户是指基于用户的属性或合同内容允许使用组1中包括的视点网格的用户。这同样适用于其他组的用户。这同样适用于另一个示例。
附图中所示的示例示出了通过用户操作来选择视点网格vpd的状态,并且将具有与视点网格vpd相对应的中心位置的图像(显示范围d的图像,指的是与图15(a)中所示的视点网格vpd相对应的点划线框)显示为主图像。然后,在附图所示的示例中,ui图像被叠加在主图像中而显示在右下位置。在该ui图像中,指示示出整个图像的范围的矩形区域m1,并且在该矩形区域m1中指示示出当前显示范围的矩形区域m2。此外,在该ui图像中,指示与当前显示范围对应的视点网格的id为“d”,并且指示可选择视点网格的id的“c”和“g”被进一步显示在矩形区域m1中的对应位置处。
图16(b)示出了组2中的用户的显示示例。附图中所示的示例示出了通过用户操作来选择视点网格vpb的状态,并且将具有与视点网格vpb相对应的中心位置的图像(显示范围b的图像,指的是与图15(a)中所示的视点网格vpb相对应的点划线框)显示为主图像。然后,在附图所示的示例中,ui图像被叠加在主图像中而显示在右下位置。在该ui图像中,指示示出整个图像的范围的矩形区域m1,并且在该矩形区域m1中指示示出当前显示范围的矩形区域m2。此外,在该ui图像中,指示与当前显示范围对应的视点网格的id为“b”,并且指示可选择视点网格的id的“e”被进一步显示在矩形区域m1中的对应位置处。
图16(c)示出了组3中的用户的显示的示例。附图中所示的示例示出了通过用户操作来选择视点网格vpf的状态,并且将具有与视点网格vpf相对应的中心位置的图像(显示范围f的图像,指的是与图15(a)中所示的视点网格vpf相对应的点划线框)显示为主图像。然后,在附图所示的示例中,ui图像被叠加在主图像中而显示在右下位置。在该ui图像中,指示示出整个图像的范围的矩形区域m1,并且在该矩形区域m1中指示示出当前显示范围的矩形区域m2。此外,在该ui图像中,指示与当前显示范围对应的视点网格的id为“f”,示出可选择视点网格的id的“a”和“h”被进一步显示在矩形区域m1中的对应位置处。
图17(a)示出了按类别对视点网格进行分组的示例。在附图中所示的示例中,组1包括三个视点网格gp11、gp12,和gp13。此外,组2包括两个视点网格gp21和gp22。此外,组3包括一个视点网格gp31。
图17(b)示出了与每个部分循环相对应的类别,并且进一步示出了当以管弦乐队的表演图像为目标时,与组中的每个视点网格相对应的子类别的具体示例。在附图中所示的示例中,组1的类别对应于弦乐器、组2的类别对应于管乐器,并且组3的类别对应于打击乐器。
然后,组1的视点网格gp11、gp12和gp13的子类别分别对应于小提琴、中提琴和低音提琴。此外,组2的视点网格gp21和gp22的子类别分别对应于长笛和小号。此外,组3的视点网格gp31的子类是定音鼓。
返回参见图4,360度麦克风105是收集来自360°所有方向的声音的麦克风。在该实施例中,360度麦克风105是高保真度立体声响复制麦克风。如通常已知的,高保真度立体声响复制麦克风包括四个或更多个麦克风,诸如四个麦克风盒体,其向外设置在规则四边形的相应表面上。这里,每个麦克风盒体基本上具有单向性。
高阶高保真度立体声响复制(hoa)转换单元106通过将通过360度麦克风105的四个麦克风盒体收集声音而获取的四个语音信号(听觉信号)分解为例如在球面表面上具有不同周期的正交分量,来获取作为基于场景的音频的数据的hoa格式的每个分量(在下文中,称之为“hoa分量”)。在本实施例中,在hoa转换单元106中,在以零阶和一阶的四个声音收集方向特性收集声音的情况下,通过四个麦克风盒体收集声音获取的声音信号被转换为信号表示。在这种情况下,零阶对应于由全向麦克风收集声音的情况,并且一阶对应于由双向麦克风在彼此正交的x、y和z轴方向上收集声音的情况。
这里,当通过四个麦克风盒体收集声音而获取的声音信号由lb、lf、rb和rf指示时,hoa分量“w、x、y和z”通过以下公式(1)获取。这里,w指示全向分量;并且x、y和z指示相应轴方向上的定向分量。
[公式1]
音频编码器107将由hoa转换单元106获取的hoa分量“w、x、y和z”以及关于预定数量的视点网格的信息包括到对象音频的包中。在本实施例中,在音频编码器107中,执行mpeg-h3d音频的编码,并且将对象音频的包转换为mpeg-h音频流包。
图18示出在mpeg-h3d音频的发送数据中的音频帧的结构示例的图。该音频帧包括多个mpeg音频流包。每个mpeg音频流包包括报头和净荷。
报头包括诸如包类型、包标签和包长度的信息。在净荷中,布置由报头的包类型定义的信息。在净荷信息中,存在与同步开始码对应的“sync”,作为3d音频的发送数据的实际数据的“mpegh3daframe()”,或指示该“mpegh3daframe()”的配置等的“mpegh3daconfig()”。
在本实施例中,“mpegh3dadecoderconfig()”布置在“mpegh3daconfig()”中,并且“mpegh3daextelementconfig()”、“hoaconfig()”和“hoadecoderconfig()”在本实施例中依次分层布置在“mpegh3dadecoderconfig()”中。然后,“hoaconfig()”包括诸如高保真度立体声响复制阶和hoa分量的数量的信息,并且“hoadecoderconfig()”包括关于hoa解码器配置的信息。
此外,“mpegh3daextelement()”布置在“mpegh3daframe()”中,并且“mpegh3daextelement()”和“hoaframe()”在该“mpegh3daextelement()”中依次分层布置。然后,“hoaframe()”包括作为基于场景的音频的数据的hoa分量。
此外,“mpegh3daconfigextension()”布置在“mpegh3daconfig()”中,并且“mae_audiosceneinfo()”、“mae_data()”和“mae_audioviewpointgrid()”在该“mpegh3daconfigextension()”中依次分层布置。“mae_audioviewpointgrid()”是存储关于分组的视点网格的信息的字段。注意,“mae_audioviewpointgrid()”对应于“audio_viewpoint_grid()”(参见图19)。
图19示出了“audio_viewpoint_grid()”的结构示例(语法)。图20示出了结构示例中的主要信息的内容(语义)。“initial_viewpoint_grid_center_azimuth”的16位字段指示初始(默认)视点位置偏离参考点的方位角。“initial_viewpoint_grid_center_elevation”的16位字段指示初始(默认)视点位置偏离参考点的仰角。
“number_of_group”的8位字段指示组的数量。重复以下字段该数量的次数。“group_id”的8位字段指示组id。“category”的8位字段指示组的类别(分类类型)。
“number_of_viewpoint_grids”的8位字段指示视点网格(viewpoint_grid)的数量。重复以下字段该数量的次数。“viewpoint_grid_id”的8位字段指示视点网格的id。“sub_category”的8位字段指示一组视点网格中的类别。
“audio_center_azimuth”的16位字段指示视点网格的方位角(方位角信息)。“audio_center_elevation”的16位字段指示视点网格的仰角(仰角信息)。
返回参见图4,容器编码器108生成包括由视频编码器104获取的视频流和由音频编码器107获取的音频流的容器。在该实施例中,容器编码器108生成mp4流作为传输流。在这种情况下,关于视频,除了视频流的层之外,还将渲染元数据(参见图8)插入到容器的层中。注意,渲染元数据被认为仅被插入到任一个中。
图21示出了视频mp4流的示例。将整个服务流分片段并发送。每个随机访问周期具有从初始化分段(is)开始,随后是框“styp”、“segmentindexbox(sidx)”、“sub-segmentindexbox(ssix)”、“moviefragmentbox(moof)”以及“mediadatabox(mdat)”。
初始化分段(is)具有基于iso基础媒体文件格式(isobmff)的框结构。在顶部,布置指示文件类型的“ftyp”框,随后布置用于控制的“moov”框。在该“moov”框中分层布置有“trak”框、“mdia”框、“minf”框、“stbl”框、“stsd”框以及“schi”框,并且将渲染元数据(rendering_metadata)(参见图8)插入到该“schi”框中,将省略对其的详细描述。
分段类型信息被插入到“styp”框中。将每个轨迹的范围信息插入到“sidx”框中,指示“moof”/“mdat”的位置,并且还指示“mdat”中的每个样本(画面)的位置。在“ssix”框中插入轨迹的分段信息,执行i/p/b类型的分段。
将控制信息插入到“moof”框中。视频、音频等的信号(发送媒体)的实际对象自身被插入到“mdat”中。“moof”框和“mdat”框形成电影片段。因为将通过分片段发送媒体获取的分段插入到一个电影片段的“mdat”框中,所以插入到“moof”框中的控制信息变为关于该片段的控制信息。
在每个电影片段的“mdat”框中,布置预定数量的投影画面的编码图像数据(访问单元)。例如,该预定数量对应于画面的预定数量,并且是对应于一个gop的数量。这里,每个访问单元包括nal单元,诸如“vps”、“sps”、“pps”、“psei”、“slice”或“ssei”。注意,“vps”或“sps”仅被插入到例如gop的开始画面中。
将关于用作截取位置信息的“conformance_window”的信息插入spsnal单元(参见图6)。此外,插入具有渲染元数据(rendering_metadata)(参见图8)的sei消息作为“ssei”的nal单元。
返回参见图4,已经由容器编码器108生成的视频和音频的mp4流通过存储器109被发送到服务接收装置200。图22是示出与这些mp4流相对应的mpd文件的描述示例的图。
在该mpd文件中,存在与视频mp4流相对应的适配集。
在该适配集中,通过描述“<adaptationsetmimetype="video/mp4"codecs="hev1.xx.xx.lxxx,xx,hev1.yy.yy.lxxx,yy">"”,存在与视频流对应的适配集,指示视频流是以mp4文件结构提供的,并且已经过hevc编码。
在该适配集中,表示存在。在该表示中,通过描述“<supplementarydescriptorschemeiduri="urn:brdcst:video:vrviewgrid"value="1"/>”,指示关于视点网格的信息的存在。
此外,在该表示中,通过描述“width="3840"height="2160"framerate="60"”,指示“codecs="hev1.xx.xx.l153,xx"”、“level=“0"”、分辨率、帧速率和编解码器类型,并且进一步指示等级“0”被分配作为标签信息。此外,通过描述“<baseurl>videostreamvr.mp4</baseurl>”,将该mp4流的位置目的地指示为“videostreamvr.mp4”。
在该mpd文件中,还存在与音频mp4流相对应的适配集。
在该适配集中,通过描述“<adaptationsetmimetype="audio/mp4"codecs="mpegh.xx.xx.xx,xx">”,存在与该音频流相对应的适配集,指示该音频流是以mp4文件结构提供的,并且已经过mpegh编码。
在该适配集中,表示存在。在该表示中,通过描述“<supplementarydescriptorschemeiduri="urn:brdcst:audio:vrviewgrid"value="1"/>”,指示关于视点网格的信息的存在。此外,通过描述“<baseurl>audiostreamvr.mp4</baseurl>”,将该mp4流的位置目的地指示为“audiostreamvr.mp4”。
返回参见图4,服务接收装置200包括容器解码器203、视频解码器204、视频渲染器205、音频解码器207和音频渲染器208。
容器解码器203从已经从服务发送系统100发送的视频的mp4流中提取视频流,并将视频流发送到视频解码器204。视频解码器204通过对视频流进行解码处理获取投影画面(图像数据)。视频渲染器205通过对投影画面(图像数据)进行渲染处理来获取渲染图像(图像数据)。
在这种情况下,当用户从基于用户属性或合同内容确定的组中选择预定视点网格时,视频渲染器205获取具有与视点网格相对应的中心位置的显示图像数据。此时,基于叠加在主图像上的ui图像(参见图16),用户可以识别在整个图像的范围m1中的当前显示范围,并且此外,可以识别进一步可由其自身可选择的视点网格。基于该识别,用户可以选择任意视点网格并切换显示图像。
注意,在用户选择任意视点网格并切换显示图像之后,用户还可以将显示图像的中心位置从视点网格的位置移位。用户可以选择视点网格,还可以通过例如以下方式移位显示图像的中心位置。
图23示出在使用头戴式显示器(hmd)和hmd扬声器(头戴式耳机)观看和收听的情况下的示例。在这种情况下,如图23(a)所示,通过佩戴hmd的用户以t1、t2和t3的顺序从左向右转动他/她的颈部,观察点变得更靠近视点网格,并且在t3所示的状态下,观察点处于观察点对应于视点网格的状态。图23(b)示出当佩戴hmd的用户以t1、t2和t3的顺序从左向右转动他/她的颈部时获取的hmd屏幕的ui显示的示例。
在这种情况下,直到观察点对应于视点网格,视点网格的方向由箭头的方向指示,并且箭头的长度指示直到观看者视图对应于视点网格的到达程度。然后,当观察点对应于视点网格时,预定标记,诸如感叹号“!”显示在附图中所示的示例中。因此,用户可以将观察点平滑地移动到视点网格。
注意,如上所述,在通过ui显示引导用户的观察点的移动的同时,或者在没有通过hmd扬声器执行ui显示的情况下,可以通过叠加来自hmd扬声器的合成声音来给出引导,如“向右看大约45°。”、“向右看大约15°。”或“方向与视点网格一致。”以这种方式,通过由控制单元控制的用户通知当前视点的位置与由关于视点网格的信息指示的位置之间的关系(网格位置同步通知),用户可以容易地将当前视点的位置移动到由关于视点网格的信息指示的位置。这同样适用于其他示例。
注意,在用户执行用于使观察点对应于视点网格的收听转动操作的时段期间,视频渲染器205停止用于获取显示图像数据的渲染处理,或者甚至在这时段期间继续用于获取显示图像数据的渲染处理。注意,在图23(b)的hmd屏幕上,标记“+”指示显示图像的中心位置,即,指示对应于观察点位置的视点。
此外,通过对应于音频渲染器208的观察点位置的渲染处理(稍后将描述),以对应于用户的观察点位置的方式调整来自hmd扬声器的声音的再现。在附图中所示的示例中,虚线a指示用户的视线方向(用户前方的方向)、点划线b指示用户收听到视点网格的声音的方向。例如,t1指示用户从前方方向向右旋转θs1的方向收听到视点网格的声音的状态。与此相反,t2指示用户从前方方向向右旋转θs2(<θs1)的方向收听到视点网格的声音的状态。此外,t3指示用户从其自身的前方方向收听到视点网格的声音的状态。
图24示出在使用头戴式显示器(hmd)和房间扬声器观看和收听的情况下的示例。注意,尽管附图中所示的示例示出了扬声器的数量为两个的情况,但是也可以提供三个或更多个扬声器。该示例类似于图23中的示例,除了房间扬声器被用来代替hmd扬声器之外。
同样在这种情况下,类似于图23中使用hmd扬声器的示例,通过对应于音频渲染器208的观察点位置的渲染处理(稍后将描述),以对应于用户的观察点位置的方式调整来自房间扬声器的声音的再现。在附图中所示的示例中,虚线a指示用户的视线方向(用户前方的方向),点划线b示出用户收听到视点网格的声音的方向。例如,t1指示用户从前方方向向右旋转θs1的方向收听到视点网格的声音的状态。与此相反,t2指示用户从前方方向向右旋转θs2(<θs1)的方向收听到视点网格的声音的状态。此外,t3指示用户从其自身的前方方向收听到视点网格的声音的状态。
图25示出了在使用诸如tv和房间扬声器的显示面板来观看和收听的情况下的示例。注意,尽管附图中所示的示例示出了扬声器的数量为两个的情况,但是也可以设置三个或更多个扬声器。在这种情况下,如图25(a)所示,通过执行滚动操作,用户以t1、t2和t3的顺序移动视点网格的位置,并且在t3所示的状态下,观察点处于观察点对应于视点网格的状态。图25(b)示出当用户执行滚动操作时获取的显示面板上的ui显示的示例。注意,滚动操作可以通过指示设备或语音ui输入来执行。
在这种情况下,直到视点网格对应于观察点,视点网格的方向由箭头的方向指示,并且箭头的长度指示直到观看者视图对应于视点网格的到达程度。然后,当视点网格对应于观察点时,预定标记,诸如感叹号“!”显示在附图中所示的示例中。因此,使用者可平滑地将视点网格移动至观察点。
注意,如上所述,在通过室内扬声器的ui显示引导用户的视点网格的移动的同时,或者在不执行ui显示的情况下,可以通过叠加来自室内扬声器的合成声音来给出引导,如“向右看大约45°。”、“向右看大约15°。”或“方向与视点网格一致。”
注意,在用户执行用于使视点网格对应于观察点的滚动操作的时段期间,视频渲染器205停止用于获取显示图像数据的渲染处理,或者甚至在这时段期间继续用于获取显示图像数据的渲染处理。注意,在图25(b)的显示面板表面上,标记“+”指示显示图像的中心位置,即,指示对应于观察点位置的视点。
此外,通过与后面将描述的音频渲染器208的观察点位置相对应的渲染处理,以与用户的观察点位置相对应的方式调整来自室内扬声器的声音的再现。在附图中所示的示例中,虚线a指示用户的视线方向(用户前方的方向),点划线b示出用户收听到视点网格的声音的方向。例如,t1指示用户从前方方向向右旋转θs1的方向收听到视点网格的声音的状态。与此相反,t2指示用户从前方方向向右旋转θs2(<θs1)的方向收听到视点网格的声音的状态。此外,t3指示用户从其自身的前方方向收听到视点网格的声音的状态。
返回参考图4,容器解码器203从已经从服务发送系统100发送的音频mp4流中提取音频流,并将该音频流发送到音频解码器207。音频解码器207通过对音频流执行解码处理来获取作为基于场景的音频的数据的hoa分量和关于预定数目的视点网格的信息。
音频渲染器208基于关于视点网格(
注意,尽管音频系统的视点网格基本上被设置为类似于视频系统的视点网格,但音频系统的视点网格被认为被设置为经移位。因此,在存在音频系统的视点网格的情况下,基于与所选择的视频系统的视点网格相对应的音频系统的视点网格来执行渲染处理。应当理解,在音频系统的视点网格不存在的情况下,认为基于视频系统的视点网格执行渲染处理。
注意,如上所述,除了用于执行对应于视点网格的语音的再现的渲染处理之外,即使在观察点位置不对应于视点位置的情况下,音频渲染器208也可以基于关于观察点位置(
图26示出音频解码器207和音频渲染器208的特定配置示例。音频解码器207通过解码音频mp4流来提取包括在mpeg-h音频流包(参见图18)中的“hoaconfig()”、“hoaframe()”以及“mae_audio_viewpoint_grid()”。
音频渲染器208包括hoa帧转换器281、渲染器(渲染器1)282、hoa反向转换单元283和渲染器(渲染器2)284。在hoa帧转换器281中,基于“hoaconfig()”、“hoaframe()”以及“mae_audio_viewpoint_grid()”,hoa分量“w、x、y和z”对应于一个帧,为每个音频帧获取预定数目的网格参数(关于视点网格的信息)。将预定数量的网格参数发送到控制单元。
由hoa帧转换器281获取的hoa分量“w、x、y和z”被提供给渲染器282。此外,将用作关于观察点位置(当观察点对应于视点网格时,与视点网格位置相同)的信息的方位角
在渲染器282中,hoa分量“w、x、y和z”基于关于观察点位置(
当将hoa分量“w、x、y和z”应用于某一观察点时,在观察点从x轴上的点p(r,0,0)改变到任意点s(r,θ',
首先,通过下面的公式(2)将hoa分量“w、x、y和z”转换为hoa分量“w'、x'、y'和z'”,可以实现点q在水平表面上从点p改变
[公式2]
接着,通过下面的公式(3)将hoa分量“w'、x'、y'和z'”转换为hoa分量“w”、x”、y”和z””,可以实现点q在垂直表面上从点s改变θ'的声场再现。
[公式3]
最后,通过下面的公式(4)将hoa分量“w、x、y和z”转换为hoa分量“w”、x”、y”和z””,即可以实现s点的声场再现。
[公式4]
返回参见图26,在hoa反向转换单元283中,将用于再现与由渲染器282获取的观察点位置相对应的声音的hoa分量“w”、x”、y”和z””转换为布置成包围收听者的预定数量的扬声器的驱动信号。例如,通过下面的公式(5)至(8)将hoa分量“w”、x”、y”和z””转换为四个扬声器的驱动信号“lf、rf、lb以及rb”。
lf=w”+0.707(x”+y”)(5)
rf=w”+0.707(x”-y”)(6)
lb=w”+0.707(-x”+y”)(7)
rb=w”+0.707(-x”-y”)(8)
这里,如图28所示,四个扬声器等间隔地布置在水平表面上以包围收听者。在附图中,lf指示布置在收听者的左前侧的扬声器、rf指示布置在收听者的右前侧的扬声器、lb指示布置在收听者的左后侧的扬声器、并且rb指示布置在收听者的右后侧的扬声器。
在渲染器284中,基于已经由hoa反向转换单元283转换的预定数量的扬声器的驱动信号来生成预定信道的语音信号。例如,在使用hmd扬声器的情况下,通过卷积与每个扬声器的位置相对应的头部相关传输函数(hrtf)并相加,生成双耳信号。
注意,以上描述是通过将观察点从视点网格的移位包括到关于从控制单元提供到渲染器282的观察点位置(
“服务发送系统的配置示例”
图29示出服务发送系统100的配置示例。服务发送系统100包括控制单元101、用户操作单元101a、360度相机102、平面包装单元103、视频编码器104、360度麦克风105、hoa转换单元106、音频编码器107、容器编码器108和包括存储器109的通信单元110。
控制单元101包括中央处理单元(cpu),并且基于控制程序来控制服务发送系统100的每个单元的操作。用户操作单元101a是用于用户执行各种操作的键盘、鼠标、触摸面板、遥控器等。
360度相机102使用预定数量的相机捕获对象的图像,并且获取球面表面捕获图像(360°vr图像)的图像数据。例如,360度相机102使用背对背方法执行图像捕获,并且获取均使用鱼眼镜头捕获的具有180°或更大视角的超宽视角前表面图像和超宽视角背表面图像作为球面表面捕获图像(参见图5(a))。
平面包装单元103通过截取360度相机102获取的球面表面捕获图像的一部分或全部,并执行平面包装,获取矩形投影画面(参见图5(b))。在这种情况下,选择例如等距柱状、交叉立方体等作为投影画面的格式类型。注意,在平面包装单元中,根据需要对投影画面执行缩放,并且获取具有预定分辨率的投影画面(参见图5(c))。
视频编码器104例如对来自平面包装单元103的投影画面的图像数据执行诸如mpeg4-avc或hevc的编码,获取编码的图像数据,并且生成包括编码的图像数据的视频流。将截取位置信息插入到视频流的spsnal单元中(参见图6中关于“conformance_window”信息)。
此外,视频编码器104将具有渲染元数据(渲染元信息)的sei消息插入到访问单元(au)的“sei”的一部分中。在渲染元信息中插入关于执行球面表面捕获图像的平面包装的情况下的截取范围的信息、关于投影画面的原始大小的缩放比率的信息、关于投影画面的格式类型的信息、指示是否进行了用于使截取位置的中心o(p,q)与投影画面的参考点rp(x,y)一致的向后兼容设置的信息等(参见图8)。
此外,该渲染元信息包括关于预定数量的分组视点网格的信息(参见图11)。关于视点网格的信息包括关于方位角(方位角信息)和仰角(仰角信息)的信息。
360度麦克风105是收集来自360°全方向的声音,并输出通过四个麦克风盒体收集声音而获取的语音信号lb、lf、rb和rf的高保真度立体声响复制麦克风。hoa转换单元106通过将由360度麦克风105获取的四个语音信号lb、lf、rb和rf分解为在球面表面上具有不同周期的正交分量(参见公式(1)),来获取作为基于场景的音频的数据的hoa分量“w、x、y和z”。
音频编码器107生成包括由hoa转换单元106获取的hoa分量“w、x、y和z”以及关于预定数量的视点网格的信息的mpeg-h音频流。在这种情况下,hoa分量“w、x、y和z”以及关于预定数量的视点网格的信息被包括在音频流包中(参见图18)。
容器编码器108生成包括由视频编码器104获取的视频流和由音频编码器107获取的音频流的mp4流作为传输流。在这种情况下,关于视频,渲染元数据(参见图8)也被插入到容器的层中(参见图21)。
包括在通信单元110中的存储器109累积在容器编码器108中生成的mp4流。通信单元110从服务接收装置200接收传输需求请求,并响应于传输需求请求向服务接收装置200发送mpd文件(参见图22)。服务接收装置200基于该mpd文件识别传输流的配置。此外,通信单元110从服务接收装置200接收对mp4流的传输需求,并将mp4流发送到服务接收装置200。
“服务接收装置的配置示例”
图30示出了服务接收装置200的配置示例。服务接收装置200包括控制单元201、ui单元201a、传感器单元201b、通信单元202、容器解码器203、视频解码器204、视频渲染器205、图像显示单元206、音频解码器207、音频渲染器208和语音输出单元209。
控制单元201包括中央处理单元(cpu),并且基于控制程序来控制服务接收装置200的每个单元的操作。ui单元201a用于执行用户界面,并且包括例如用于用户操作显示区域的移动的指示设备,用于用户输入语音以发出用于移动显示区域的语音指令的麦克风等。传感器单元201b包括用于获取用户状态和关于环境的信息的各种传感器,并且包括例如安装在头戴式显示器(hmd)上的姿势检测传感器等。
通信单元202在控制单元201的控制下接收对服务发送系统100的传输需求请求,并且响应于传输需求请求从服务发送系统100接收mpd文件(参见图22)。通信单元202将该mpd文件发送到控制单元201。控制单元201基于该mpd文件识别传输流的配置。
此外,通信单元202在控制单元201的控制下向服务发送系统100传输对于mp4流的传输需求(发送需求),并且响应于该需求从服务发送系统100接收视频和音频的mp4流。
这里,基于由安装在hmd上的陀螺仪传感器等获取的关于移动方向和移动量的信息,或基于以用户操作为基础的指示信息或用户的语音ui信息,控制单元101获取显示区域的移动的方向和速度,并且进一步获取关于视点网格的切换的信息。
此外,控制单元201包括用户识别功能。基于用户的属性(年龄、性别、兴趣、熟练程度、登录信息等)或合同内容,控制单元201识别用户的类型,并确定可由用户使用的一组视点网格。然后,控制单元201使视频渲染器205和音频渲染器208进入使用用户可以使用的组的视点网格的状态。
容器解码器203提取插入在视频mp4流的初始化分段(is)中的渲染元数据(参见图8),并将渲染元数据发送到控制单元201。因此,控制单元201获取关于预定数量的分组视点网格的信息(视频系统)。
视频解码器204通过对视频流执行解码处理获取投影画面(图像数据)。此外,视频解码器204提取插入到视频流中的参数集和sei消息,并将该参数集和sei消息发送到控制单元201。该提取的信息包括关于插入在spsnal包中的截取位置“conformance_window”的信息,并且还包括具有渲染元数据的sei消息(参见图8)。
在控制单元201的控制下,视频渲染器205通过对投影画面(或图像数据)执行渲染处理来获取渲染图像(图像数据)。在这种情况下,当用户从基于用户属性或合同内容确定的组中选择预定视点网格时,视频渲染器205获取具有与视点网格相对应的中心位置的显示图像数据。
基于叠加在主图像上的ui图像(参见图16),用户可以识别在整个图像的范围m1中的当前显示范围,并且此外,可以识别进一步由其自身可选择的视点网格。基于这种识别,用户可以选择任意视点网格并切换显示图像(参见图23、图24和图25)。图像显示单元206显示由视频渲染器205获取的渲染图像。
此外,容器解码器203从由通信单元202接收的视频mp4流中提取音频流,并将该音频流发送到音频解码器207。音频解码器207通过对音频流执行解码处理来获取作为基于场景的音频的数据的hoa分量和关于预定数量的分组视点网格(音频系统)的信息。音频解码器207将关于视点网格的信息发送到控制单元201。
在控制单元201的控制下,音频渲染器208基于关于视点网格(
如上所述,在图3所示的发送和接收系统10中,服务发送系统100发送作为基于场景的音频的数据的hoa分量和关于预定数量的视点网格的信息。因此,在接收侧,可以容易地获取与宽视角图像的固定位置相对应的语音输出。
此外,在图3所示的发送和接收系统10中,服务发送系统100发送关于分组的视点网格的信息。因此,在接收侧,可以针对每个预期目的或每个用户获取对应于宽视角图像的固定位置的语音输出。
此外,在图3所示的发送和接收系统10中,服务接收装置200获取作为基于场景的音频的数据的hoa分量和关于预定数量的视点网格的信息,并且基于关于视点网格的信息通过处理hoa分量来获取输出语音数据。因此,能够容易地获取与宽视角图像的固定位置对应的语音输出。
此外,在图3所示的发送和接收系统10中,服务接收装置200使用基于用户属性或合同内容确定的组的视点信息。因此,可以以获取对应于用户的属性或合同内容的语音输出的方式执行限制。
此外,在图3所示的发送和接收系统10中,服务接收装置200通过ui显示或语音来引导用户的观察点的移动。由此,能够容易地获取与宽视角图像的固定位置对应的语音输出。
<2.变型例>
注意,在上述实施例中,已经描述了容器是mp4(isobmff)的示例。然而,本技术不限于容器是mp4的示例,并且即使容器是诸如mpeg-2ts或mmt的另一格式的容器,也可以类似地应用本技术。
此外,在上述实施例中,已经描述了使用零阶和一阶作为基于场景的音频的数据的hoa分量的示例,但是可以类似地考虑使用高阶分量的配置。
此外,在上述实施例中,从服务发送系统100接收作为基于场景的音频的数据的hoa分量和关于预定数量的登记视点网格的信息的示例,但是可以类似地考虑通过从记录媒体再现来获取作为基于场景的音频的数据的hoa分量和关于预定数量的登记视点网格的信息的配置。
此外,在上述实施例中,已经描述了既存在视频系统又存在音频系统的示例,但是可以考虑仅包括语音系统的配置。
此外,在上述实施例中,已经描述了包括服务发送系统100和服务接收装置200的发送和接收系统10的示例,但是可以应用本技术的发送和接收系统的配置不限于此。例如,也可以考虑将服务接收装置200的一部分改变为通过诸如高清晰度多媒体接口(hdmi)等数字接口连接的机顶盒和显示器的情况。注意,“hdmi”是注册商标。
此外,本技术还可以采用以下配置。
(1)一种发送装置,包括:
发送单元,被配置为发送空间语音数据和关于预定数量的登记视点的信息。
(2)根据上述(1)所述的发送装置,
其中,关于视点的信息包括关于指示视点的位置的方位角和仰角的信息。
(3)根据上述(1)或(2)所述的发送装置,
其中,对预定数量的登记视点信息进行分组。
(4)根据上述(1)至(3)中任一项所述的发送装置,
其中,空间语音数据是基于场景的音频的数据。
(5)根据上述(4)所述的发送装置,
其中,基于场景的音频的数据是hoa格式的每个分量。
(6)根据上述(4)或(5)所述的发送装置,
其中,发送单元将基于场景的音频的数据和关于预定数量的登记视点的信息包括在对象音频的包中以进行发送。
(7)根据上述(6)所述的发送装置,
其中,对象音频的包是mpeg-h音频流包。
(8)根据上述(6)或(7)所述的发送装置,
其中,发送单元将对象音频的包包括在isobmff的容器中以进行发送。
(9)一种发送方法,包括:
由发送单元发送空间语音数据和关于预定数量的登记视点的信息的步骤。
(10)一种处理装置,包括:
获取单元,被配置为获取空间语音数据和关于预定数量的登记视点的信息;以及
处理单元,被配置为通过基于关于登记视点的信息处理空间语音数据来获取输出语音数据。
(11)根据上述(10)所述的处理装置,
其中,关于视点的信息包括关于指示视点位置的方位角和仰角的信息。
(12)根据上述(10)或(11)所述的处理装置,
其中,空间语音数据是基于场景的音频的数据。
(13)根据上述(12)所述的处理装置,
其中,基于场景的音频的数据是hoa格式的每个分量。
(14)根据上述(12)或(13)所述的处理装置,
其中,获取单元接收基于场景的音频的数据和关于预定数量的登记视点的信息,或者通过从媒体再现来获取基于场景的音频的数据和关于预定数量的登记视点的信息。
(15)根据上述(12)至(14)中任一项所述的处理装置,
其中,获取单元从所接收的对象音频的包获取基于场景的音频的数据和关于预定数量的登记视点的信息。
(16)根据上述(15)所述的处理装置,
其中,目标音频的包是mpeg-h音频流包。
(17)根据上述(10)至(16)中任一项所述的处理装置,
其中,获取单元从视频处理系统获取关于预定数量的登记视点的信息,该视频处理系统被配置为通过基于视点信息处理宽视角图像的图像数据来获取显示图像数据。
(18)根据上述(10)至(17)中任一项所述的处理装置,
其中,对关于预定数量的登记视点的信息进行分组,并且
处理单元使用基于用户的属性或合同内容确定的组的登记视点信息。
(19)根据上述(10)至(18)中任一项所述的处理装置,还包括
控制单元,被配置为对通知用户当前视点的位置与由关于登记视点的信息指示的位置之间的关系进行控制。
(20)一种处理方法,包括:
由获取单元获取空间语音数据和关于预定数量的登记视点的信息的步骤;以及
由处理单元通过基于关于登记视点的信息处理空间语音数据来获取输出语音数据的步骤。
本技术的主要特征在于,通过在接收侧发送空间语音数据和关于预定数量的登记视点的信息,可以容易地获取对应于宽视角图像的固定位置的语音输出(参见图18、图19和图28)。
参考符号列表
10发送和接收系统
100服务发送系统
101控制单元
101a用户操作单元
102360度相机
103平面包装单元
104视频编码器
105360度麦克风
106hoa转换单元
107音频编码器
108容器编码器
109存储器
110通信单元
200服务接收装置
201控制单元
201aui单元
201b传感器单元
202通信单元
203容器解码器
204视频解码器
205视频渲染器
206图像显示单元
207音频解码器
208音频渲染器
209语音输出单元
281hoa帧转换器
282,284渲染器
283hoa反向转换单元。
- 还没有人留言评论。精彩留言会获得点赞!