适配在网关上执行的软件应用程序的制作方法
本发明涉及一种用于适配第一软件应用程序的方法,所述第一软件应用程序在网关上被执行并且控制网关的数据传输,其中所述网关将本地网络的一个或多个设备与云网络连接。
本发明尤其是结合所谓的物联网(iot)被使用。
背景技术:
所谓的物联网(英语:internetofthings,iot)包括诸如传感器或执行器之类的物理设备的网络。这些设备配备有电子设备、软件和网络连接,这使得所述设备能够建立连接并且交换数据。所谓的平台使用户能够将其设备和物理数据基础设施、即其本地网络与数字世界连接、也即与另一网络、通常所谓的云网络连接。
云网络可以由多个不同的云平台组成,所述云平台通常由不同的提供商提供。云平台经由互联网提供it基础设施、诸如存储空间、计算效率或应用软件作为服务。包括本地计算资源在内的本地网络也被称为边缘(edge)。边缘处的计算资源特别适用于分散式数据处理。
设备或其本地网络典型地经由所谓的网关与云网络连接,所述云网络包括所谓的后端并且提供后端服务。网关是在两个网络之间建立连接的硬件和/或软件组件。本地网络的设备的数据现在应该经由网关可靠地被传输给另一网络的后端服务,其中这由于本地网络的带宽的波动以及数据的传输速度和数据大小的波动而变得困难。用于从本地网络经由网关到云网络中的数据传输的静态方法通常不考虑这一点。
原则上,存在iot的设备可以如何相互连接和/或与云网络连接的不同的方法:从设备到设备(英语:device-to-device)、从设备到云网络(英语:device-to-cloud)和从设备到网关(英语:device-to-gateway)。本发明主要涉及以下方法,其中设备与本地网络的网关连接,然而也可以被应用于其他方法。
在设备到网关方法的情况下,一个或多个设备经由中间设备、即网关与云网络或云服务以及正是所谓的后端服务连接。为此,网关通常使用自身的应用软件。网关附加地也可以提供其他功能性,例如安全应用程序或数据和/或协议的转换。应用软件可以是与本地网络的设备联合(英语:pairing(配对))并且与云服务建立连接的应用程序。
网关大多数支持对设备的数据的预处理(英语:preprocessing),这通常包含数据的聚合或压缩以及数据的缓存(英语:buffering),用以可以应对至后端服务的连接的中断。战胜(bewältigen)网关处的复杂工作状态、例如在文件分批传输时不同数据类型的传输或时间关键数据的传输,以及战胜本地网络的随机波动,目前尚不被很好地支持。
存在网络层面上的方案,用以改善网络的传输质量(英语:qualityofservice(服务质量),qos)。但是,这些qos方案刚好在网络层面上而不是在软件应用程序的层面上工作。由此不能探讨软件应用程序的需求。
技术实现要素:
因此,本发明的任务是说明一种方法,利用所述方法,在网关上被执行的用于传输数据的应用程序可以适配其行为。
所述任务通过根据权利要求1所述的方法解决。权利要求1涉及一种用于适配第一软件应用程序的方法,所述第一软件应用程序在网关上被执行并且控制网关的数据传输,其中所述网关将本地网络的一个或多个设备与云网络连接。在此规定,
-借助于第二软件应用程序,基于网关的环境的至少一种状态以及网关的至少一个可能的动作来执行机器学习,
-机器学习的结果包含由网关的环境的状态和网关的动作组成的配对的至少一个质量值,以及
-第一软件应用程序执行网关的以下动作,即所述动作在网关的环境的给定状态情况下具有比其他动作更高的质量值。
因此,本发明设置用于控制网关功能的机器学习。
本发明的一种实施方式规定,第二软件应用程序包括用于确认式学习的方法,其中对于由网关的环境的状态和网关的动作组成的每个配对,以奖励的形式进行反馈(rückmeldung)。
加强性学习(也称为强化学习(英语:reinforcementlearning,rl))代表一系列机器学习方法,其中代理独立地学习策略,用以最大化所获得的奖励。在此,不向代理展示:哪个动作在哪种状况下是最好的,而是所述代理在特定的时间点获得奖励,所述也可能是负的。根据这些奖励,所述代理逼近效益函数、在这里是质量函数(或质量值),其描述哪个值具有特定的状态或特定的动作。
尤其是可以规定,第二软件应用程序包括用于q学习的方法。
在本发明的一种实施方式中规定,在确认式学习之前将关于网关的环境的状态的数据组合成集群。由此可以使确认式学习简化。
在本发明的一种实施方式中,q学习借助于模型进行,所述模型在云网络中的云平台上利用网关的环境的状态的当前数据被训练,以及经训练的模型在需要时被提供给网关。由此不附加地用用于q学习的计算对网关加载荷。
该模型可以包括神经网络,所述神经网络的学习特性、例如学习速度可以良好地经由参数被定义。
本发明的一种实施方式在于,第一软件应用程序包括不考虑机器学习的结果的第一控制装置,以及包括考虑机器学习的结果的第二控制装置,其中一旦存在来自机械学习的质量值、尤其是一旦存在如上所述的经训练的模型,就使用第二控制装置。
由于根据本发明的方法在一个或多个计算机上或利用一个或多个计算机被执行,因此本发明还包括相应的计算机程序产品,所述计算机程序产品又包括指令,所述指令在通过网关执行程序时,促使所述网关执行根据本发明的方法的所有步骤。计算机程序产品例如可以是其上存储有相应的计算机程序的数据载体,或者可以是可以经由数据连接被加载到计算机的处理器中的信号或数据流。
因此,计算机程序可以促成或本身执行以下步骤:
-借助于第二软件应用程序,基于网关的环境的至少一种状态以及网关的至少一个可能的动作来执行机器学习,
-机器学习的结果包含由网关的环境的状态和网关的动作组成的配对的至少一个质量值,以及
-第一软件应用程序执行网关的以下动作,即所述动作在网关的环境的给定状态情况下具有比其他动作更高的质量值。
如果第二软件应用程序不在网关上被执行,则计算机程序将促成第二软件应用程序在另一计算机上被执行,例如在云网络中的云平台上被执行。
附图说明
为了进一步阐述本发明,在说明书的随后部分中参照图,从所述图中可以获悉本发明的其他有利细节和可能的应用领域。在此:
图1示出确认式学习的功能原理的示意图,
图2示出物联网的简化模型,
图3示出具有网关的环境的状态的可能组合的表格,
图4示出具有网关的环境的状态和网关的可能动作的表格,
图5示出具有来自图4的数据的聚类的表格,
图6示出用于确认式学习的神经网络,
图7示出用于确认式学习的可能的单工架构。
具体实施方式
图1示出确认式学习(bestätigendemlernen)的功能原理。在这里使用确认式学习来控制设备的行为,所述设备是本地网络的一部分并且参与物联网。s表示环境e的状态集。a表示代理ag的动作集。
网关g现在表示与其环境e交互的代理a。环境e包括与网关g连接并且以规则的或不规则的间隔转交数据的其他设备、网络接口以及与基于云的后端服务的连接性。所有这些因素都引起不确定性,并且在战胜工作定额和可能的性能限制或故障方面是挑战。
环境e的状态集例如包括:
-本地网络的当前状态,
-从本地网络的相邻设备到达网关g的数据的速率,
-从本地网络的相邻设备到达网关g的数据流的类型,
-和/或代理ag、即网关g的状态数据,诸如网关g(cpu、存储器、队列等)的资源的瞬时利用率(auslastung)。
代理ag、即网关g的动作集a可以包括以下内容:
-从所连接的设备接收数据
-添加到队列
-重新确定队列中的元素的优先级
-处理请求
-压缩数据
-划分数据
-变换特定数据
-将数据存放在中间存储器(英语:buffer(缓冲器))中
-将数据传输到后端服务
奖励可以基于特定度量值(英语:metrics(度量))的最小化被定义,其中度量值可以包括
-直至网关g的动作为止的平均等待时间
-队列的长度
-工作任务的平均减速,其中j=c/t,其中c表示工作任务的处理时间(也即从输入工作任务到完成的时间),以及t表示工作任务的理想持续时间。
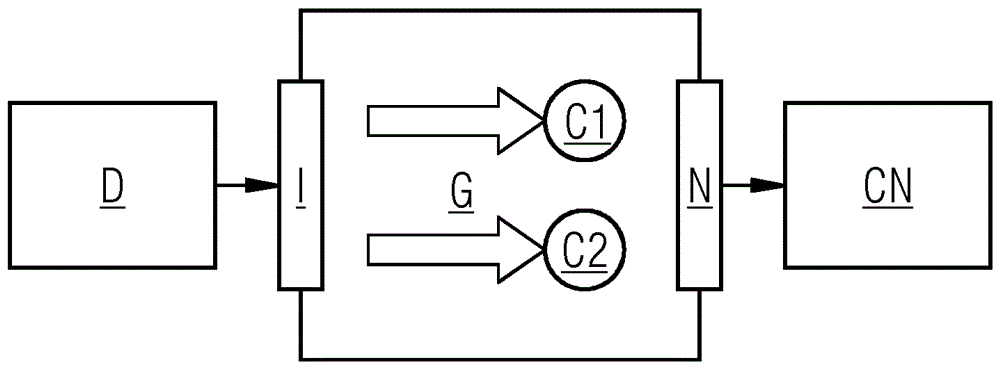
在图2中示出物联网的简化模型。仅示出本地网络的一个设备d。设备d不具有到云网络cn上的直接链接,而是所述设备d与网关g连接,并且经由输入接口i向所述网关传输数据流。网关g具有两个可以并行工作的处理器单元c1、c2。网关g经由输出接口n与云网络cn连接,例如与其中的特定云平台连接。输出接口n可以是无线互联网接入,并且因此易受连接质量或数据吞吐量的波动影响。云平台从网关g接收数据流,并且从而执行其他动作,例如存储、分析和可视化。
如果仅专注于重要组件、即输入接口i和处理器单元ci、c2,用以对网关g的环境e和工作定额(英语:workload(工作量))进行建模,并且如果仅使用三种具体的可能状态、即l-低、m-中和h-高,则对于该模型得出33=27种状态,所述状态在图3的表格中示出。
布尔值1表示存在特定状态。为了现在处理所有可能的状态,必须设立规则。但是,根据环境e的当前状态,呆板的规则也可能得出非最佳或非期望的解决方案。本发明现在规定,从当前状态导出特定动作,并且网关g处的代理随时间自主地学习:什么是最好的动作,其方式是给出用于动作的奖励。
在图4的表格中示出用于状态和可能动作的实际示例。执行聚合,以便使更好地可识别设备g和本地网络的状态。对于处理器单元ci、c2,如下聚合成c:
c=0.5*(值(c1,l)*0.1+值(c1,m)*0.5+值(c1,h))+
0.5*(值(c2,l)*0.1+值(c2,m)*0.5+值(c2,h))
函数值(x,y)从图3的表格中的相应列中取得值0或1。处理器单元c1、c2的总状态c是各个状态的加权和。基于可能的状态l-低、m-中和h-高以类似的方式导出输出接口n的网络的总条件n,网关g对于所述输出接口的网络是接口。
网关g的总状态o如下被导出:o=max(c,n),因此使用来自列c和列n中的条目的最大值。
图4中的表格示范性地表明:代理ag、即网关g可以以特定的状态s为出发点导出动作a,所述动作考虑计算容量和向后端服务的数据传输。该动作a的值或质量可以随时间通过获得奖励被学习。作为动作,在图4中为处理器单元c1、c2(倒数第二列)并且为输出接口n设置:
无限制(英语:norestrictions(无限制))
缓存(英语:performcaching(执行缓存))
压缩数据(英语:performcompression(执行压缩))
减少计算操作(英语:reduceoperations(减少操作))
发送较少数据(英语:reducedispatching(减少配送))
重新启动输出接口(英语:rebootinterface(重启接口))
仅处理/发送绝对必要的数据(英语:onlyvitaldata(仅至关重要的数据))
阻止来自本地网络的数据流(英语:stopinboundtraffic(停止入站流量))
为了确定由状态s和动作a组成的组合的质量q,应用所谓的q学习:
最后,根据状态和动作的不同集a、s得出q函数
在图5中示出来自图4的数据可以如何被分组(聚类),例如用于计算质量的最佳未来值的估计值。例如,k均值算法或层次聚类方法可以被用作用于聚类(clustering)的方法。集群、在这里是集群(cluster)1、...至集群x的形成可以例如根据列n中或还有列c和n中的相似值被执行。
由状态的集s和动作的集a组成的组合的上面列出的质量现在必须通过网关g实时地被计算,这有时由于网关g的硬件的有限容量、网关g的当前要战胜的工作定额以及要考虑的状态的数量而是困难的。代替地,可以执行函数逼近,这在图6中根据神经网络示出。
所谓的深度神经网络dnn离线地、即在网关g的正常运行之外被训练,并且然后在网关g的正常运行中由代理ag、即由网关g实例化,使得深度神经网络dnn基于环境e的当前状态s为动作a作出建议。这种方法快得多,并且引起网关g处的较少计算耗费。可以在几毫秒的范围内创建建议。
在训练深度神经网络dnn时,代理ag基于随机分布
在图7中示出用于在使用深度学习情况下的确认式学习、从而为深度强化学习的可能架构。示出网关g和云网络cn的云平台cp(参见图2)。在此使用本身已知的所谓单工系统架构,所述单工系统架构包含标准控制装置(标准控制器)sc和高级控制装置,所述高级控制装置应用确认式学习并且因此被称为rl代理rl_a。标准控制装置sc确定数据发送的时间点并且执行发送,但是无优化。rl代理rl_a应用用于学习的方法,例如刚好上述确认式学习,用以优化数据传输。
在开始时,网关g与标准控制器sc一起工作。在云平台cp中设置网关g的所谓设备影子ds,在所述设备影子上借助于训练模块tm来训练模型、也即例如来自图6的深度神经网络dnn。在此,根据网关g的实际数据ad并且根据网关g的实际配置对该模型进行训练。经训练的模型被存放在用于模型的存储器(这里用mod表示)中,并且rl代理rl_a被告知模型的存在。
rl代理rl_a从用于模型的存储器mod中加载模型,并且网关g的决策模块dm具有以下可能性:从标准控制器sc转换到rl代理rl_a,用以从而在数据传输方面改善网关g的行为。
附图标记列表:
a代理ag的动作集
a动作
ad网关g的数据
ag代理
cn云网络
cp云平台
d本地网络的设备
dm决策模块
dnn深度神经网络
ds设备影子
e环境(英语:environment)
g网关
i输入接口
mod用于模型的存储器
n输出接口
r奖励
rl_arl代理
s状态集
s状态
sc标准控制装置(标准控制器)
tm训练模块。
- 还没有人留言评论。精彩留言会获得点赞!