用于处理器核之间的改进的数据传输的方法和装置与流程
用于处理器核之间的改进的数据传输的方法和装置
1.相关专利的交叉引用
2.本技术要求于2018年12月12日提交的题为“data transfer between the cores in a microprocessor”的美国临时专利申请no.62/778,354的优先权,该美国临时专利申请通过引用整体并入本文。所公开的系统和操作方法还涉及以下专利中公开的主题,这些专利通过引用整体并入本文:(1)题为“amultiple level minimum logic network”、发明人为coke s.reed的美国专利no.5,996,020;(2)题为“a scalable low latency switch for usage in an interconnect structure”、发明人为john hesse的美国专利no.6,289,021;(3)题为“multiple path wormhole interconnect”、发明人为john hesse的美国专利no.6,754,207,题为“parallel data switch”、发明人为coke s.reed和davis murphy的美国专利no.9,954,797。
背景技术:
3.大型计算和通信系统的部件可以配置有通过互连线路连接的交换机芯片的互连结构。增加交换机芯片端口数会减少芯片到芯片跳数,从而获得较低的延迟和较低的成本。这些系统需要具有高端口数并且还能够处理短分组的交换机芯片。
4.在当今多核处理器中,使用网格在核之间传输数据。核是布置成网格结构的分块(tile)。这些技术已被用于连接芯片上的核,但在将数据从第一处理器上的核传输至第二处理器上的核方面效果不佳。除了由于网格结构导致的困难之外,在多芯片应用中,使用传递通过在芯片之间承载数据的纵横式交换机(crossbar switch)的长分组也带来了附加的困难。长分组导致低带宽、高延迟、有限的可扩展性和高拥塞。本文要求保护的本发明的目的是提供高带宽和低延迟的方法和装置来在处理器计算核之间交换信息。这是通过将数据涡交换机(data vortex switch)和处理核阵列安装在同一芯片上来实现的。
技术实现要素:
5.互连装置的实施方式即使在高时钟速率下也能实现改进的信号完整性,并能实现增加的带宽和较低的延迟。在用于核阵列的互连装置中,发送处理核可以通过形成分组(该分组的报头指示接收核的位置并且该分组的有效载荷是将被发送的数据的)来将数据发送至接收核。分组被发送至本文以及本文并入的专利中描述的数据涡交换机。数据涡交换机与处理核阵列位于同一芯片上,并首先通过将分组路由至包含接收处理核的处理核阵列来将分组路由至该接收核。然后,数据涡交换机将分组路由至处理器核阵列中的接收处理器核。由于数据涡交换机不是纵横式交换机,所以当不同组的分组进入交换机时,无需对数据涡交换机进行全局设置和重置。将数据涡交换机与处理核阵列安装在同一芯片上降低了所需的功率并降低了延迟。
附图说明
6.通过参照以下描述和附图,可以最好地理解本发明的与装置和操作方法相关的实
施方式:
7.图1是例示了包括多个子分组微片(sub
‑
packet flit)的分组格式的实施方式的数据结构图;
8.图2a是描绘了在所参考的美国专利号6,289,021和6,754,207的实施方式中描述的包括节点阵列、连接线路和fifo的交换机的高级视图的示意性框图;
9.图2b是示出了本文公开的系统的实施方式中的包括节点阵列互连的交换机的高级视图的示意性框图;
10.图3a是例示了所参考的美国专利号6,289,021和6,754,207中描述的一对简单交换机节点的示意性框图;
11.图3b是示出了所参考的美国专利号6,289,021和6,754,207中描述的交换机的“均匀延迟(flat latency)”或“双降”版本中描述的一对连接节点的示意性框图,;
12.图4是描绘了公开系统的实施方式中的节点的构建块(本文称为ldm模块)的示意性框图,该构建块包括单点击延迟(one
‑
tick delay)逻辑元件、单点击延迟fifo元件和用于组合总线的复用设备;
13.图5是示出了根据公开系统的实施方式的四个互连ldm模块的框图;
14.图6是例示了在公开系统的实施方式中使用的交换节点的框图;
15.图7是示出了被发送至公开系统的交换节点的实施方式中的逻辑元件的控制信号的源和时序的框图;
16.图8是例示了在本文公开的系统的实施方式的交换节点的逻辑元件中使用的控制寄存器的框图;
17.图9a、图9b和图9c是例示了互连结构的各种级上的节点的互连的示意性框图;
18.图10是例示了所描述的互连结构中的消息传送的时序的时序图;以及
19.图11是例示了包括报头和有效载荷的消息分组的格式的图形表示。
20.图12是包含两个部件的芯片的框图。第一部件是数据涡交换机,第二部件是处理核阵列。数据涡交换机接收数据分组并将该数据分组路由至核阵列中的适当核。
21.图13由图12中的芯片组成,具有将分组从处理核阵列中的核传输至数据涡交换机的连接。这为处理核阵列中的第一处理核提供了将数据发送至处理核阵列中的第二处理核的机制。
22.图14示出了四个处理器核阵列,各个处理器核阵列在同一芯片上具有数据涡交换机和处理核阵列。来自各个处理器核阵列的分组的传输是通过主数据涡交换机定向的。
具体实施方式
23.本文公开的设备、系统和方法描述了一种网络互连系统,该网络互连系统在连接大量对象(例如路由器中的线路卡、并行计算机中的网络接口卡或其它通信系统和设备)方面极为有效。所描述的网络互连系统具有极高的带宽以及极低的延迟。
24.计算和通信系统在配置有具有高端口数并能够处理短分组的交换机芯片时可以获得最高性能。在并入的美国专利号5,996,020和6,289,021中描述的数据涡交换机芯片具有极高的端口数并具有传输短消息分组的能力。
25.本文公开的系统和方法包括对并入的美国专利号6,289,021和6,754,207的许多
改进,这些改进是通过多个增强中的一个或更多个增强实现的,所述改进包括以下两个基本改进:1)我们增加了带宽并且减小了节点之间的并行数据线路中的第一位输入至最后一位输出的延迟;以及2)进一步增加了带宽,并且通过如下逻辑进一步减小了延迟,该逻辑设立了通过交换机的数据路径,该交换机在各级处包含一位长的并行fifo,从而允许使用比并入的美国专利号6,289,021和6,754,207中的可能时钟快得多的时钟。
26.并入的美国专利号6,289,021描述了一种适合放置在芯片上的交换机。在该系统中,数据(以分组的形式)在一位宽的数据路径上以虫洞的方式传递通过交换机。分组包括报头和有效载荷。报头的第一位是指示消息的存在的状态位(在大多数实施方式中设置为值1)。在简单的布置中,其余报头位表示目标输出端口的二进制地址。交换机的拓扑包括大量连接的环集。(2
n
×2n
)交换机包括布置成(n+1)级的环,不同级上的环之间具有连接。分组在n级进入交换机并在0级离开交换机。在n级进入交换机的消息分组的报头具有一个状态位和n个目标地址位。n级上的节点处的逻辑基于以下因素做出路由决策:1)状态位;2)报头中地址的第一位;3)从n
‑
1级上的节点发送的控制信号;以及4)(在基本实施方式中)来自n级上的节点的控制信号。报头中地址的第一位由n级上的逻辑使用。当n级节点上的逻辑将分组定向到n
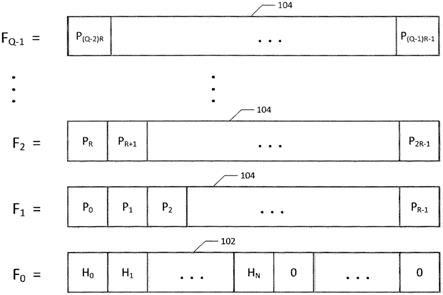
‑
1级上的节点时,地址的第一位被丢弃。这样做有以下几个原因:1)较低级上的路由决策不需要第一地址位;2)丢弃该位允许n
‑
1级上的消息分组先于n级上的分组行进,使得基于传入的分组,n
‑
1级节点可以向n级节点发送控制信号,从而使n
‑
1级节点能够定向n级业务;3)丢弃第一报头位确保了其余报头位的最高有效位是在n
‑
1级上路由分组所需的位。该处理在整个交换机中继续,使得k级上的分组具有一个状态位,随后是k个地址位。
27.这种设计的结果是,可以建立直接在级之间切断的数据路径。系统的时序是如下时序:状态位需要两个时钟点击才能在同一环上的两个逻辑节点之间移动,但该状态位只需要一个点击便可在不同级上的两个节点(k级环上的节点称为k级节点)之间移动。因此,如果分组通过交换机的路径包含n个向下步长(不同级上的环之间的步长)以及给定级处的环上的两个节点之间的j个步长,那么在第一有效载荷位到达输出0级之前需要(n+2j+1)个点击。当状态位在0级上时,在不同级上存在2j个单点击延迟,一位fifo延迟元件中的每一者中有一个数据位。信息通过不同级处的节点上的多个晶体管的传递必然会限制系统的时钟速率。事实上,如果分组在各个步长向下传递,则状态位到达0级,而第一有效载荷位在n级(最高条目级)上。
28.相比之下,针对本文描述的系统,分组的各个位在各级上传递通过至少一个单点击fifo,有利地使信号能够在各个节点处重构,并使本文描述的系统能够以比并入的美国专利号6,289,021中描述的系统高的时钟速率工作。
29.在并入的美国专利号5,996,020、6,289,021和6,754,207中描述的交换系统提供低延迟和高带宽,并且还支持短分组。并入的美国专利号5,996,020、6,289,021和6,754,207中的交换机拓扑包括大量互连的环集。图2a是在并入的美国专利号6,289,021和6,754,207中描述的交换机的实施方式的高级框图。图2a中例示的整个结构装配在单个芯片上。互连线路210、212、214、216和218是位串行的。分组装配在单个环上的规范要求包括fifo元件220。为了降低分组传递通过fifo 220的可能性,所有分组通过线路202插入到单个输入节点阵列中。图2a中例示的交换机可以使用图3a中例示的简单节点或通过使用图3b中例示的
“
双降”或“均匀延迟”节点来构建。
30.首先考虑图3a中例示的简单交换机u。美国专利号6,289,021和6,754,207的交换机操作的一个方面是数据分组的第一位只能在特定分组进入时间进入交换机节点u。在给定分组进入时间t,进入交换机节点u的分组不能超过一个。这是因为在并入的美国专利号5,996,020、6,289,021和6,754,207中描述的控制线路的新颖使用而导致的情况。
31.针对图3a的n
‑
k级上的各个交换机节点u,存在k长的多位pb
u
=(b0,b1,b2,...,b
k
‑1),使得进入u的各个分组pk具有二进制表示具有前导位(b0,b1,b2,...,b
k
‑1)的目标目的地。通过线路306离开交换机节点u的各个分组具有二进制表示具有前导位(b0,b1,b2,...,b
k
‑1,1)的目标目的地。接下来考虑k级上的如下交换机节点l,进入l的各个分组pk具有多位pb
l
=pb
u
,使得进入l的各个分组pk具有二进制表示具有前导位(b0,b1,b2,...,b
k
‑1)的目标目的地。通过线路316离开交换机节点l的各个分组具有二进制表示具有前导位(b0,b1,b2,...,b
k
‑1,0)的目标目的地。
32.在分组pk进入u并且pk的目标地址具有前导位(b0,b1,b2,...,b
k
‑1,1)并且控制线路310指示非忙碌状态的情况下,则pk将通过线路306离开u。否则,pk必须通过线路304离开u。在分组pk进入l并且pk的目标地址具有前导位(b0,b1,b2,...,b
k
‑1,0)并且控制线路320指示非忙碌状态的情况下,则pk将通过线路316离开l。否则,pk必须通过线路314离开l。
33.图3b中例示的“双降”交换机380使用附加逻辑和互连线路342和344来组合节点u和l。双降交换机dd 380被定位成使得进入n
‑
k级上的交换机dd的各个分组具有目标地址具有k个前导位pb
dd
=(b0,b1,b2,...,b
k
‑1)的目的地。交换机dd定位在网络中,使得通过线路326离开dd的节点u的各个分组具有前导位为(b0,b1,b2,...,b
k
‑1,1)的目标地址,并且通过线路336离开dd的节点l的各个分组具有前导位为(b0,b1,b2,...,b
k
‑1,1)的目标地址。
34.当分组pkt进入节点u时,交换机dd如下操作:
35.1)如果分组pkt通过线路328进入dd的节点u并且pkt的目标的前导地址位是(b0,b1,b2,...,b
k
‑1,1),那么a)如果线路330上不存在忙碌信号,则u的逻辑沿线路326向下定向分组pkt;或者b)如果线路330上存在忙碌信号,则u的逻辑将分组pkt通过线路324定向到网络中的另一双降交换机。在任一情况下,u的逻辑在线路344上向节点l发送忙碌信号以指示线路326是忙碌的。
36.2)如果分组pkt通过线路328进入dd的节点u并且pkt的目标的前导地址位是(b0,b1,b2,...,b
k
‑1,0),那么a)如果线路344上不存在忙碌信号,则u的逻辑将分组pkt通过线路342定向到节点l,使得l的逻辑可以沿线路336向下发送pkt;或者b)如果线路344上存在忙碌信号,则u的逻辑将分组pkt通过线路324定向到网络中的另一双降交换机。只有在线路330上存在忙碌信号的情况下,u的逻辑才在线路344上向节点l发送忙碌信号以指示线路326是忙碌的。
37.进入节点l的分组类似地表现。因此,当分组pkt进入交换机dd的节点l时,会发生以下事件集:
38.1)如果分组pkt通过线路338进入dd的节点l并且pkt的目标的前导地址位是(b0,b1,b2,...,b
k
‑1,0),那么a)如果线路348上不存在忙碌信号,则l的逻辑沿线路336向下定向分组pkt;或者b)如果线路348上存在忙碌信号,则l的逻辑将分组pkt通过线路334定向到网络中的另一双降交换机。在任一情况下,l的逻辑在线路344上向节点u发送忙碌信号以指示
线路336是忙碌的。
39.2)如果分组pkt通过线路338进入dd的节点l并且pkt的目标的前导地址位是(b0,b1,b2,...,b
k
‑1,1),那么a)如果线路344上不存在忙碌信号,则l的逻辑将分组pkt通过线路342定向到节点u,使得u的逻辑可以沿线路326向下发送pkt;或者b)如果线路344上存在忙碌信号,则l的逻辑将分组pkt通过线路334定向到网络中的另一双降交换机。只有在线路348上存在忙碌信号的情况下,l的逻辑才在线路344上向节点u发送忙碌信号以指示线路336是忙碌的。
40.这里公开的系统中描述的交换系统表示对并入的美国专利号6,289,021和6,754,207中描述的交换系统的重要改进。主要改进包括:
41.1)添加了通过系统的并行数据路径,该并行数据路径实现了比并入的美国专利号6,289,021和6,754,207中构建的系统中的可能带宽更高的带宽;
42.2)经修改的时序系统,其同时实现了在各个逻辑节点处创建具有fifo的数据路径,并具有所述fifo的优点(包括使用高时钟速率的能力);3)一种时序系统,该时序系统仅采用一个点击来使分组微片在不同级上的节点之间移动,并采用两个点击来使分组微片在同一级上的节点之间移动。有利地,消除了图2a的fifo线路214。
43.图1例示了分组的布局。分组被分解为q个子分组(称为微片)。微片中的各个微片具有r个位。微片被设计成行进通过r宽的总线。第一微片f
0 102是报头微片。它由状态位h0、n个路由位h1、h2、...、h
n
和附加位(在图1中设置为0)组成,可以使用该附加位来承载其它信息,例如,纠错位或qos。状态位h0设置为1以指示分组的存在。n个路由位表示目标的二进制地址。因此,在基数为2
n
的交换机中使用具有n个路由位的交换机。k级上的逻辑l使用位h
k
结合控制位来路由f0。
44.图2a表示并入的美国专利号6,289,021和6,754,207中提出的交换机的高级框图。图2b表示本专利的交换机的高级框图,其中,可以使用所有报头位来通过交换机路由分组。在所参考的美国专利号6,289,021和6,754,207以及本公开中,节点阵列按行和列布置。基数2
n
交换机中的节点阵列na(u,v)包括列v中u级上的2
n
个交换节点。在美国专利号6,289,021和6,754,207以及本系统中,在示例实施方式中,基数为2
n
的交换机具有从进入n级到离开0级的(n+1)行(或级)节点阵列。交换机具有一定数量m的列(其中列的数量是设计参数)。在公开系统中引入了系统方面的重要的新颖改进。在公开系统中,节点阵列之间的线路包括代替在专利no.6,289,021和专利no.6,754,207中使用的一位宽的线路的总线。节点阵列中的节点具有新颖的新设计,所述新设计实现了较低延迟和较高带宽。另外地,在并入的美国专利号6,289,021和6,754,207中,系统包括足够长的fifo移位寄存器220,使得整个分组可以装配在0级上的给定环上;两个分组可以装配在1级上的环上,以及更一般地,2
r
个分组可以装配在r级上的环上。使用本公开的技术可以在交换机中消除这种fifo,因为并行总线的宽度将使得可以具有足够数量的活动节点,从而使整个消息装配在一行节点的活动元件中。参照图2b,各个数据承载线路可以包括宽度等于图1中例示的r长的子分组的长度的总线。r长的子分组可以称为微片。总线连接节点,其中各个节点是如下模块(ldm模块),该模块包含单点击逻辑元件,随后是单点击延迟元件,随后是复用器。ldm模块中装配有两个微片。因此,包含q个微片的分组可以装配在图2b中的单行节点阵列上的q/2个ldm模块中。在一个例示性实施方式中,顶级(n级)在单个环上包含ldm模块。n
‑
1级上的ldm模块布置在两
个环上。底部节点阵列包括2
n
个环,各个环包括通过r宽的总线连接的m个节点。节点阵列中节点和总线的布置使得环结构成为可能。0级上的各个环必须足够长以容纳由q个微片组成的整个分组。0级上的各个环将分组传送至单个目标地址。多个输出端口238可以从单个0级环连接。来自单个环的这些输出端中的每一者都将数据传送至同一目标输出端。数据通过输入总线222输入到结构中。如图所示,在简单的实施方式中,给定级w上的各个逻辑节点被连接,以将分组转发至相关联的环上的下一逻辑节点,并且还定位成将分组转发至w
‑
1级上的两个逻辑节点中的一者。在本配置中(如美国专利号6,289,021和6,754,297中所描述的),w
‑
1级上的逻辑元件具有优于w级上的逻辑节点的优先级,以将数据转发至w
‑
1级上的逻辑元件。在本文呈现的例示性示例中,各级包含相同数量的逻辑节点。
45.在并入的美国专利号6,289,021和6,754,207的实施方式中,所有分组进入节点阵列na(n,0)(其中n表示阵列的级,0表示节点阵列的进入角),以便最小化给定分组进入fifo 220的概率。fifo 220的消除使得本公开的实施方式能够按照多个角度插入分组。多个插入角度减少了按照任何给定角度插入的分组的数量,从而减少了拥塞。在本发明中,分组的第一微片f0只能在指定进入时间(针对系统中不同节点,该指定进入时间是不同的)进入节点。
46.当前公开的交换机的实施方式具有对应于图3b中例示的连接的连接。因此,公开系统的布线图拓扑(如图2b所示)可以与图2a中例示并在并入的美国专利号5,996,020、6,289,021和6,754,207中描述的布线图拓扑相同。
47.参照图4,示出了包括逻辑元件402、延迟元件404和复用元件406的单个交换模块400的框图。具有逻辑、延迟和复用器(mux)的模块称为ldm模块。ldm模块是用于构建图2b中例示的节点阵列中的交换机节点的部件。分组进入逻辑元件402的时序对于公开系统的高速并行交换机的正确操作很重要。各个逻辑设备402能够恰好保存分组的一个微片。此外,各个延迟设备404还能够恰好保存一个分组微片。在时间步长结束时,逻辑设备402可以包含或不包含分组的一个微片。类似地,在时间步长结束时,延迟设备404也可以包含或不包含分组的一个微片。在延迟设备包含分组p的一个微片f
l
并且f
l
不是分组的最后微片(即,l<q)的情况下,则逻辑设备包含该分组的微片f
l+1
。如果l≠0并且f
l
位于逻辑单元或延迟单元中,则微片f
l
在时间t
s
的位置等于微片f
(l
‑
1)
在时间t
s
‑1的位置。以这种方式,分组以虫洞的方式行进通过交换机。
48.在例示性实施方式中,ldm模块包括被配置为将分组的时序同步的逻辑设备、延迟设备和复用器设备。
49.结合图4参照图5,描述了ldm模块的基本操作和时序。具有逻辑元件l1的ldm模块位于节点阵列na(w,z)中;逻辑元件l2位于na(w,z+1)中;l3位于na(w
‑
1,z)中;并且逻辑元件l4位于na(w
‑
1,z+1)中。
50.在l1的各个分组插入时间,逻辑单元l1通过检查设置为1的状态位h0来检查微片到达。如果在逻辑单元l1的微片到达时间t
s
,逻辑感测到h0被设置为0,则逻辑单元识别出在这个时隙中没有分组到达,并且在下一第一微片分组到达时间之前不采取动作。如果在l1的第一微片到达时间t
s
(由时钟或计数器识别),逻辑单元在f0中的状态位时隙h0中感测到1,则逻辑单元确定f0包含有效分组pkt的第一微片,并且如下进行:
51.a.如果1)基于f0的位h
w
,l1确定是否存在从l4至pkt的目标输出端的路径,以及2)
来自l3的控制信号指示l1可以自由使用线路412,则l1发送pkt的第一微片f0使其通过m3,以在时间t
s+1
到达l4。
52.b.如果不满足上述条件1)和2)中的一者或二者,则l1将pkt的第一微片f0发送至d1,以便在时间t
s+1
到达d1,随后在时间t
s+2
(第一微片到达l4后的一个时间单位)到达l2。
53.对路由位h
w
和控制信号的使用的详细讨论包括在图6、图7和图8的讨论中。第一微片到达同一列中不同级上的逻辑单元的时序对于交换系统的适当操作很重要。由于第一微片是在该第一微片到达na(w,z+1)中的逻辑元件之前的一个单位时间到达na(w
‑
1,z+1)中的逻辑元件的,所以有足够的时间在w
‑
1级上生成控制信号来控制w级上的分组路由。
54.假设分组pkt的初始微片f0以时间步长t
s
到达逻辑单元l,则pkt的下一微片f1将以时间步长t
s+1
到达l。这一直持续到pkt的最后微片f
q
‑1在时间t
s+q
‑1到达逻辑单元l。类似地,假设分组pkt的初始微片f0以时间步长t
s+1
到达延迟单元d,则pkt的下一微片f1将以时间步长t
s+2
到达d。这一直持续到pkt的最后微片f
q
‑1在时间t
s+q
到达d。每次分组的微片到达逻辑单元或延迟单元时,都会重新生成微片的信号。每次点击时的这种信号重新生成允许较高的芯片时钟速率。在简单的“单降”实施方式中,ldm模块可以用作交换机中的节点。
55.参照图6,示出了在公开系统的实施方式的交换机中使用的交换节点。交换节点包含两个ldm模块610和620以及2
×
2纵横式交换机602。假设图6中表示的交换节点位于节点阵列na(w,z)中。ldm模块有两种类型:1)α型ldm模块620,其能够通过沿线路608向下发送信号来控制纵横式交换机602,以及2)β型模块610,其不能控制纵横式交换机602。假设w级不等于0或n的有趣情况。α型模块620的分组进入时间集等于β型模块610的分组进入时间集。
56.参照图7,示意性框图示出了互连装置的实施方式,该实施方式即使在高时钟速率下也能实现改进的信号完整性,并能实现增加的带宽和较低的延迟。
57.例示性互连装置包括多个逻辑单元和多个总线,所述多个总线按照逻辑单元的选定配置联接所述多个逻辑单元,该选定配置可以被认为布置成包括逻辑单元la 624、lc 724和ld 710的三元组。逻辑单元la 624和lc 724被定位为向逻辑单元ld 710发送数据。相比于逻辑单元la 624,逻辑单元lc 724具有向逻辑单元ld 710发送数据的优先级。针对被分成子分组的分组pkt、逻辑单元la 624处的分组pkt的子分组以及指定目标的分组:(a)逻辑单元lc 724向逻辑单元ld 710发送分组pkt的子分组并且逻辑单元la 624不向逻辑单元ld 710发送分组pkt的子分组;(b)逻辑单元lc 724不向逻辑单元ld 710发送数据的子分组并且逻辑单元la 624向逻辑单元ld 710发送分组pkt的子分组;或者(c)逻辑单元lc 724不向逻辑单元ld 710发送数据的子分组并且逻辑单元la 624不向逻辑单元ld 710发送分组pkt的子分组。
58.在例示性互连结构中,逻辑单元、延迟单元和复用器单元可以不配置有足够的存储器来保存整个分组,因此只具有总线宽的先进先出(fifo)缓冲区。因此,在总线宽的数据路径上传送分组。
59.逻辑节点不对分组进行重组。分组pkt的第一子分组(称为微片)在给定时间t1到达逻辑节点la。在时间t2,pkt的第一微片到达下一下游逻辑单元或延迟单元。同样在时间t2,pkt的第二微片到达逻辑单元la 624。事实上,分组在交换机中从来没有被重组,它一次使一个微片离开交换机。详细地,由r个位形成的微片(参见图1)以虫洞的方式行进通过交换机,并通过连接至以r倍速度运行的顺序互连件的ser
‑
des(串行器
‑
解串行器)模块离开。
60.逻辑单元la 624将向逻辑单元ld 710发送pkt,条件是1)存在从逻辑单元ld 710至pkt的目标输出端口的路径;以及2)逻辑单元la 624没有被比逻辑单元la 624具有更高优先级的逻辑元件lc阻止行进至逻辑单元ld 710,以向逻辑单元ld 710进行发送。参照图7,只有比逻辑单元la 624具有更高优先级的逻辑单元lc724向逻辑单元ld 710进行发送,而逻辑单元lb和le二者比逻辑单元la 624具有更高的优先级向逻辑单元lf进行发送。在该示例中,pkt的微片位于逻辑单元la 624处。逻辑单元la 624基于报头信息和传入的控制位来路由pkt的第一微片。逻辑单元la 624向它发送第一微片的同一元件发送pkt的第二微片。在任何情况下,逻辑单元la 624都不能保存分组,如果微片在时间t1到达,则该微片在时间t2被转发。
61.互连结构按照一系列时间步长传输分组和子分组。在操作时间瞬间,分组pkt的一系列微片进入逻辑单元la 624。因此,数据通信操作可以被认为是瞬间地操作的。在例示性实施方式中,分组pkt的第一微片或子分组包含通过交换机到达目标的路由信息。
62.逻辑单元lc 724使用被发送至逻辑单元la 624的控制信号来强制优先于逻辑单元la 624来向逻辑单元ld 710发送分组。
63.逻辑单元基于分组报头信息并且还基于来自其它逻辑单元的控制信号来路由分组。
64.互连结构还可以包括单点击先进先出(fifo)缓冲区。进入逻辑单元的微片(子分组)在逻辑单元处传递通过单点击fifo,从而在各个逻辑单元处重新生成信号。
65.在一些实施方式中,互连结构可以如下操作,使得针对定位成向包括逻辑单元ld 710的多个逻辑单元发送分组的逻辑单元la 624,情况1或情况2成立。在情况1下,逻辑单元la 624确定ld是最适合接收分组pkt的逻辑单元,并且逻辑单元lc 724向逻辑单元ld 710发送分组并且逻辑单元la 624向不同于ld的逻辑单元lg发送pkt;或者没有比逻辑单元la 624具有更高优先级的逻辑单元向逻辑单元ld 710发送分组,并且逻辑单元la 624向逻辑单元ld 710发送分组。在情况2下,逻辑单元la 624确定向逻辑单元ld 710发送分组pkt是不可接受的,并且逻辑单元la 624在不同于逻辑单元ld 710的逻辑单元lg中发送分组pkt或向不同于逻辑单元ld 710的逻辑单元lf 720发送分组pkt。
66.针对在时间t
s
接收分组pkt的第一子分组的逻辑单元la 624,如果逻辑单元la 624向逻辑单元ld 710发送分组pkt的第一子分组,则逻辑单元ld 710在时间t
s+1
接收分组pkt的第一子分组。如果逻辑单元la 624向逻辑单元lg发送分组pkt的第一子分组,则第一子分组传递通过延迟单元da并在时间t
s+2
到达逻辑单元lg。如果逻辑单元lc 724向逻辑单元ld 710发送分组qkt的第一子分组并且分组qkt的第一子分组阻止分组pkt行进至逻辑单元ld 710,则子分组qkt在时间t
s+1
到达逻辑单元ld 710。
67.在一些实施方式中,如果逻辑单元la 624确定逻辑单元ld 710是接收分组pkt的最适合的逻辑单元,则逻辑单元ld 710基于分组pkt中的路由信息做出该确定。如果逻辑单元la 624确定向逻辑单元ld 710发送分组pkt是不可接受的,则逻辑单元ld 710基于分组pkt中的路由信息做出该确定。
68.结合图6和图3b参照图7,描述了对高速并行数据路径交换节点600进行管理的数据和控制线路。分组从w级或w+1级上的另一逻辑元件在线路704上到达逻辑元件la。在逻辑元件la的给定分组进入时间t
s
,恰好满足以下条件中的一者:
69.1)没有第一微片f0到达逻辑单元la;
70.2)刚好有一个第一微片从w级上的逻辑元件到达逻辑单元la,但没有第一微片f0从w+1级上的逻辑元件到达逻辑单元la;以及
71.3)恰好有一个第一微片从w+1级上的节点到达逻辑单元la,但没有第一微片f0从w级上的节点到达逻辑单元la。
72.类似地,分组从w+1级上的逻辑元件或从w级上的逻辑元件到达逻辑元件lb。在逻辑节点lb分组进入时间t
s
,没有第一微片到达逻辑元件lb或恰好有一个第一微片到达在逻辑元件lb。重要地,假设分组pkt的第一微片f0在时间t
s
到达逻辑元件la,则pkt的下一微片f1在时间t
s+1
到达l,随后是pkt的其它微片,使得pkt的最后微片f
q
‑1在时间t
s+q
‑1到达la。类似地,假设pkt的微片f
c
(其中c<q)在时间t
d
到达延迟元件del,则pkt的微片f
c+1
在时间t
d+1
位于延迟元件del中。因此,在各个逻辑元件和各个延迟元件处,信号被重构。当前公开系统的该特征(美国专利号6,289,021和6,754,207中未示出该特征)使得交换机芯片时钟能够比美国专利号6,289,021和6,754,207中描绘的系统中的时钟运行得更快。
73.结合图6继续参照图7,节点600位于n+1级交换机的w级上。将ti限定成n
‑
w。对应于节点600,存在δ长的二进制序列bs=(b0,b1,...b
δ
‑1),使得进入节点600的逻辑单元la或逻辑单元lb的各个分组具有前导位为bs的目标地址。每次分组pkt在交换机中向下移动一级,pkt的目标地址的附加位就会被设置。进入逻辑元件ld的各个分组具有二进制地址具有前导位(b0,b1,...b
δ
‑1,1)的目标。进入逻辑元件lf的各个分组具有二进制地址具有前导位(b0,b1,...b
δ
‑1,0)的目标。总线622将la和lb连接至w
‑
1级上的节点中的逻辑元件ld 710,使得逻辑单元la或逻辑单元lb中的具有第一微片f0的分组pkt能够通过ld前进至其目标输出端,前提是f0的位h
w
等于1,并且满足其它控制线路条件(下文讨论)。总线612将逻辑单元la和逻辑单元lb连接至w
‑
1级上的节点中的逻辑元件lf 720,使得逻辑单元la或逻辑单元lb中的具有第一微片f0的分组pkt能够通过逻辑单元lf前进至其目标输出端,前提是f0的位h
w
等于0,并且满足其它控制线路条件(下文讨论)。
74.逻辑元件lc 724存在于w
‑
1级上的ldm模块722中,使得逻辑元件lc被定位成通过延迟单元dc向逻辑元件ld 710发送数据。此外,逻辑元件le 714存在于w
‑
1级上,使得逻辑元件le 714能够通过延迟单元de向lf 720发送数据。假设t
s
是逻辑元件la 624和lb 614的分组到达时间。那么t
s+1
是逻辑单元lf处的分组到达时间。从逻辑元件le行进至lf的分组pkt必须在时间t
s
在de中具有该分组的第一微片f0,因此必须在时间t
s
‑1在le中具有该分组的第一微片。类似地,从lc行进至ld的分组pkt必须使该分组的第一微片在时间t
s
‑1到达lc。因此,t
s
‑1是逻辑元件lc和le的分组到达时间。
75.交换机中静态缓冲区的缺少可以通过竞争消息行进至逻辑元件ld或lf的优先级方案来补偿。优先级方案赋予w
‑
1级分组最高优先级,并相比于纵横式交换机602的纵式设置(cross setting)(其中分组对角地行进至另选路径),赋予纵横式交换机602的横式设置(bar setting)(其中分组在同一路径上水平行进)优先级。因此,在时间t
s+1
进入ld 710的分组的第一微片f0的优先级方案如下:
76.1)分组(该分组的第一微片f0在时间t
s
位于dc中)具有优先级1以行进至逻辑单元ld,并且这样的分组始终在时间t
s+1
到达逻辑单元ld;
77.2)假设不存在在时间t
s+1
到达逻辑单元ld的优先级为1的分组,则分组(该分组的
第一微片f0在时间t
s
位于逻辑单元la 624中并且该分组的f0位h
w
为1)具有优先级2,并且将行进通过被设置为横式状态的交换机602,以在时间t
s+1
到达逻辑单元ld21;以及
78.3)假设没有优先级为1或优先级为2的分组将在时间t
s+1
到达逻辑单元ld,则分组(该分组的第一微片f0在时间t
s
位于逻辑单元lb 614中并且该分组的f0位h
w
为1)具有优先级3,并且将行进通过被设置为纵式状态的交换机602,以在时间t
s+1
到达逻辑单元ld。
79.优先级方案保证了线路732和线路622不可能同时承载信息。因此,来自这两个线路的信号可以在复用器mc中结合而不会损失保真度。请注意,没有必要为复用器mc指定点击。复用器me也存在类似的情况。
80.类似地,在时间t
s+1
进入lf 720的分组的第一微片f0的优先级方案如下:
81.1)分组(该分组的第一微片f0在时间t
s
位于延迟de中)具有优先级1,以行进至逻辑lf,并且这样的分组将始终在时间t
s+1
到达逻辑lf;
82.2)假设不存在在时间t
s+1
到达逻辑lf的优先级为1的分组,则分组(该分组的第一微片f0在时间t
s
位于逻辑lb 614中并且该分组的f0位h
w
为0)具有优先级2,并且将行进通过被设置为横式状态的交换机602,以在时间t
s+1
到达逻辑lf;以及
83.3)假设没有优先级为1或优先级为2的分组将在时间t
s+1
到达lf,则分组(该分组的第一微片f
a
在时间t
s
位于逻辑la 624中并且该分组的f
a
的f0位h
w
为0的)具有优先级3,并且将行进通过被设置为纵式状态的交换机602,以在时间t
s+1
到达逻辑lf。
84.结合图7和图8参照图6。整数w表示如下整数,使得在图7中,逻辑元件la、lb、lg和lh位于交换机的w级上,而逻辑元件lc、ld、le和lf位于交换机的w
‑
1级上。优先级方案由逻辑单元控制寄存器cr和cl强制执行,cr和cl由来自ldm模块中的逻辑单元或延迟单元的控制分组设置。并行双降交换机中的逻辑元件的各个逻辑元件包含两个控制寄存器cr(远程控制)和cl(本地控制),并且各个控制寄存器包含两个位,从而允许各个寄存器存储整数0、1、2或3中的任一者的二进制表示。t
s
是分组到达逻辑元件la和lb的时间;t
s+1
是到达ld和lf的时间;t
s+2
是到达lg和lh的时间。t
s
是到达dc和de的时间,并且t
s
‑1是到达lc和le的时间。在时间t
s
‑1之前,la和lb中的寄存器cr和cl被设置为0。la中的寄存器cr被线路728上的来自lc的控制信号设置为不同于0的值。lb中的寄存器cr被线路718上的来自le的控制信号设置为不同于0的值。lb中的寄存器cl被线路604上的来自la的控制信号设置为不同于0的值。la中的寄存器cl被线路606上的来自lb的控制信号设置为不同于0的值。ldm模块620能够通过从la沿线路608向下发送信号来将纵横式交换机602设置为横式或纵式状态。纵横式控制ldm模块620称为α型ldm模块。ldm模块610没有控制纵横式交换机602的装置并且称为α型ldm模块。纵横式交换机有三种状态:状态0指示纵横式交换机没有准备好接收数据;状态1指示纵横式交换机处于横式状态并且准备好接收数据;状态2指示纵横式交换机处于纵式状态并且准备好接收数据。如果在纵横式交换机处于状态0时分组微片到达纵横式交换机,则微片将被存储在微片宽的缓冲区中,直到纵横式交换机状态被设置为1或2。存在当分组的最后微片离开纵横式交换机时保持跟踪的逻辑。当给定分组的微片传递通过纵横式交换机时,该纵横式交换机的状态保持不变。当最后微片离开纵横式交换机时,纵横式交换机被置于状态0。
85.在例示性实施方式中,逻辑元件la中的控制寄存器的功能可以如下限定:
86.1)cr=1意味着逻辑元件lo被来自逻辑元件lc的分组阻止;
87.2)cr=2意味着逻辑元件lo未被阻止并且可以从逻辑元件la接收分组;
88.3)cl=1意味着逻辑元件lb正通过处于横式状态的纵横式交换机向逻辑元件lf发送分组;
89.4)cl=2意味着逻辑元件lf未被阻止并且可以从逻辑元件la接收分组;以及
90.5)cl=3意味着逻辑元件lf被来自逻辑元件le的分组阻止。
91.在例示性实施方式中,逻辑元件lb中的控制寄存器的功能可以如下限定:
92.1)cr=1意味着逻辑元件lf被来自逻辑元件le的分组阻止;
93.2)cr=2意味着逻辑元件lf未被阻止并且可以从逻辑元件lb接收分组;
94.3)cl=1意味着逻辑元件la正通过处于横式状态的纵横式交换机向逻辑元件lo发送分组;
95.4)cl=2意味着逻辑元件lo未被阻止并且可以从逻辑元件lb接收分组;以及
96.5)cl=3意味着逻辑元件lo被来自逻辑元件lc的分组阻止。
97.图6、图7和图8中例示的交换机可以如下操作:
98.在第一动作中,在分组到达时间t
s
或之前,cr寄存器由线路728上的来自逻辑元件lc的信号和线路718上的来自逻辑元件le的信号设置。
99.在第二动作中,在分组到达时间t
s
,逻辑单元la如下继续:
100.1)情况1:分组pkt
a
的第一微片在线路704上到达逻辑元件la;pkt
a
的报头位h
w
被设置为1,这指示逻辑元件ld位于去往pkt
a
的目标输出端的路径上;并且逻辑元件la寄存器cr=2,这指示逻辑元件ld在时间t
s+1
将不会从逻辑元件lc接收分组。在这种情况下,逻辑元件la沿线路608向下发送信号以将纵横式交换机设置为横式状态。然后逻辑元件la通过纵横式交换机发送分组pkt
a
的第一微片,以在时间t
s+1
到达逻辑元件ld。然后逻辑元件la通过线路604发送信号,以将逻辑元件lb的cl寄存器设置为1。
101.2)情况2:不发生情况1的状况,并且逻辑元件la的cr寄存器被设置为2,这指示逻辑元件lc没有发送在时间t
s+1
到达逻辑元件lo的分组。在这种情况下,逻辑元件la通过线路604发送信号,以将逻辑元件lb的cl寄存器设置为2。
102.3)情况3:不发生情况1的状况并且逻辑元件la的cr寄存器被设置为1,这指示逻辑元件lc正在发送将在时间t
s+1
到达逻辑元件lo的分组。在这种情况下,逻辑元件la通过线路604发送信号,以将逻辑元件lb的cl寄存器设置为3。
103.在第三动作中,在分组到达时间t
s
,逻辑单元lb如下继续:
104.1)情况1:分组pkt的第一微片在线路702上到达逻辑元件lb;pkt的报头位h
w
被设置为0并且逻辑元件lb寄存器cr=2,这指示逻辑元件lf在时间t
s+1
将不会从逻辑元件le接收分组。在这种情况下,逻辑元件lb向纵横式交换机发送pkt8的第一微片,以在纵横式交换机已被设置为横式状态之后行进通过纵横式交换机,以便在时间t
s+1
到达逻辑元件lf。然后逻辑元件lb通过线路604发送控制信号,以将逻辑元件la的cl寄存器设置为1。
105.2)情况2:不发生情况1的状况并且逻辑元件lb的cr寄存器被设置为2,这指示逻辑元件le没有发送将在时间t
s+1
到达逻辑元件lf的分组。在这种情况下,逻辑元件lb通过线路606发送信号,以将逻辑元件la的cl寄存器设置为2。
106.3)情况3:不发生情况1的状况并且逻辑元件lb的cr寄存器被设置为3,这指示逻辑元件le正在发送将在时间t
s+1
到达逻辑元件lf的分组。在这种情况下,逻辑元件lb通过线路
606发送信号,以将逻辑元件la的cl寄存器设置为3。
107.在第四动作中,如果逻辑元件la已经将纵横式交换机设置为横式状态,则逻辑元件la不采取进一步的动作。如果逻辑元件la未将纵横式交换机设置为横式状态,则逻辑元件la在cl寄存器已被设置为非零值后检查其cl寄存器。如果cl寄存器包含1,则逻辑元件la将纵横式交换机设置为横式状态。如果cl寄存器包含不同于1的数字,则逻辑元件la将纵横式交换机设置为纵式状态。
108.在第五动作中,此时逻辑元件la处的逻辑具有纵横式交换机的状态信息,并且逻辑元件la如下继续:
109.1)情况1:在时间t
s
,逻辑元件la中不存在分组微片,这意味着逻辑元件la不需要进一步的动作。
110.2)情况2:分组pkt
a
的第一微片在时间t
s
到达逻辑元件la。纵横式交换机处于横式状态,如上文所述通过纵横式交换机发送分组pkt
a
的第一微片,这意味着逻辑元件la不需要进一步的动作。
111.3)情况3:分组pkt
a
的第一微片在时间t
s
到达逻辑元件la。纵横式交换机处于横式状态,未在如上所述的第二动作中通过纵横式交换机发送分组pkt
a
的第一微片,这意味着分组pkt
a
的第一微片将被发送至延迟单元da。因此,逻辑元件la向延迟单元da发送pkt
a
的第一微片。
112.4)情况4:分组pkt
a
的第一微片在时间t
s
到达逻辑元件la。纵横式交换机处于纵式状态,pkt
a
的报头位h
w
被设置为0,并且逻辑元件la的寄存器cl被设置为2,然后将通过纵横式交换机发送pkt
a
的第一微片,以在时间t
s+1
到达逻辑元件lf。
113.5)情况5:分组pkt
a
的第一微片在时间t
s
到达逻辑元件la。纵横式交换机处于纵式状态,但不发生情况4的状况。然后pkt
a
的第一微片将被发送至延迟单元da。
114.在可以与第五动作同时执行的第六动作中,如果逻辑元件lb的cl寄存器被设置为1,或者lb将逻辑元件la的cl寄存器设置为1,则逻辑元件la处的逻辑获知了纵横式交换机被设置为横式状态。如果这些条件都不满足,则逻辑元件la知道纵横式交换机被设置为纵式状态。逻辑元件lb如下继续:
115.1)情况1:在时间t
s
,逻辑元件lb中不存在分组微片,这意味着逻辑元件lb不需要进一步的动作。
116.2)情况2:分组pkt
b
的第一微片在时间t
s
到达逻辑元件lb。纵横式交换机处于横式状态,如上文所述通过纵横式交换机发送分组pkt
b
的第一微片,这意味着逻辑元件lb不需要进一步的动作。
117.3)情况3:分组pkt
b
的第一微片在时间t
s
到达逻辑元件lb。纵横式交换机处于横式状态,未在如上所述的第二动作中通过纵横式交换机发送分组pkt
b
的第一微片,这意味着分组pkt
b
的第一微片将被发送至延迟单元db。
118.4)情况4:分组pkt
b
的第一微片在时间t
s
到达逻辑元件lb。纵横式交换机处于纵式状态,pkt
b
的报头位h
w
被设置为1,并且逻辑元件lb的寄存器cl被设置为2,然后将通过纵横式交换机发送pkt
b
的第一微片,以在时间t
s+1
到达逻辑元件ld。
119.5)情况5:分组pkt
b
的第一微片在时间t
s
到达逻辑元件lb。纵横式交换机处于纵式状态,但不发生情况4的状况。然后pkt
a
的第一微片将被发送至延迟单元db。
120.在例示性示例中,相比于纵式状态,赋予横式状态优先级。在另一示例中,可以将优先级赋予纵式状态。在又一示例中,相比于逻辑元件lb,可以将优先级赋予逻辑元件la,或者相比于逻辑元件la,可以将优先级赋予逻辑元件lb。
121.复用器元件通过减少节点之间的互连路径的量来改进结构紧凑性和性能。在不同实施方式中,可以省略复用器。参照图7,请注意,可以通过将互连线路732连接至逻辑单元ld的第一输入端并且将互连线路622连接至逻辑单元ld的第二输入端来消除mc 738和互连线路734。在另一简化实施方式中,单个ldm模块可以用作交换机的节点。在这种情况下,可以省略节点交换节点中的纵横式交换机。在另一更复杂实施方式中,交换节点可以包括多个ldm模块以及交换机,其中ldm模块的数量n不等于1或2,并且交换机的基数为n。
122.本文公开的结构和系统包括对所参考的美国专利号5,996,020、6,289,021和6,754,207中描述的系统的显著改进,包括以下有利特性中的一者或更多者:1)即使在高时钟速率下也能获得的改进的信号完整性,2)增加的带宽,以及3)较低的延迟。
123.改进包括以下项中的一者或更多者:1)总线宽的数据路径;2)足以通过交换机路由数据的所有报头位都被包含在微片f0中;3)在ldm模块的各个逻辑单元和各个延迟单元处清理信号。
124.图9a、图9b和图9c是示出了互连结构的各级上的节点的互连的示意性框图。图9a示出了最外j级的环r上的节点a
rj 920、以及节点a
rj 920到节点b
rj 922、设备c 924、节点d
rj 926、节点e
r
(j
‑
1)928、节点f
r
(j
‑
1)930和设备g 932的互连。图9b示出了j级的环r上的节点a
rt 940、以及节点a
rt 940到节点b
rt 942、节点c
r
(t+1)944、节点d
rt 946、节点e
r
(t
‑
1)948、节点f
r
(t
‑
1)950和节点g
r
(t+1)952的互连。图9c示出了最内0级的环r上的节点a
r0 960、以及节点a
r0 960到节点b
r0
962、节点c
r1 964、节点d
r0 966、设备e 968和节点g
r1 972的互连。
125.图9a、图9b和图9c示出了互连结构的拓扑。为便于理解,该结构可以被认为是r、θ和z三个维度中的同心圆柱体的集合。各个节点或设备具有指定位置(r,θ,z),该指定位置与三维圆柱坐标中的位置(r,2π,θ/k,z)相关,其中半径r是指定了从0到j的圆柱体数量的整数,角度θ是指定了圆柱体圆形截面周围节点的间距的从0到k
‑
l的整数,并且高度z是指定了沿着z轴的距离的从0到2
j
‑1的二进制整数。高度z表示为二进制数,因为z维度中节点之间的互连最容易被描述为二进制数字的操作。因此,可以关于两个设计参数j和k限定互连结构。
126.在图9a、图9b和图9c中,用箭头指示消息数据流的方向的实线以及箭头指示控制消息流的方向的虚线来示出互连。总之,针对节点a、b和d以及节点或设备c、e、f、g:
127.1)a位于t=r级上;
128.2)b和c向a发送数据;
129.3)d和e从a接收数据;
130.4)f向a发送控制信号;
131.5)g从a接收控制信号;
132.6)b和d在t级上;
133.7)b是a的直接前驱者;
134.8)d是a的直接后继者;以及
135.9)c、e、f和g不在t级上。
136.各个节点和设备在三维圆柱符号中的位置如下:
137.1)a位于节点n(r,θ,z)处;
138.2)b位于节点n(r,θ
‑
1,h
t
(z))处;
139.3)c位于节点n(r+1,θ
‑
1,z)处,或者位于互连结构外部;
140.4)d位于节点n(r,θ+1,h
t
(z))处;
141.5)e位于节点n(r
‑
1,θ+1,z)处,或者位于互连结构外部并且与设备f相同;
142.6)f位于节点n(r
‑
1,θ,h
t
‑1(z))处,或者位于互连结构外部并且与设备e相同;
143.7)g位于节点n(r+1,θ,h
t
(z))处,或者位于互连结构外部。
144.请注意,术语θ+1和θ
‑
1分别表示加法和减法,模数(modulus)k。
145.在该符号中,当θ等于0时(θ
‑
1)mod k等于k,否则等于θ
‑
1。针对z=[z
j
‑1,z
j
‑2,...,z
r
,z
r
‑1,...,z2,z1,z0],通过将从z
r
‑1到z0的低阶z位的顺序反转为z=[z
j
‑1,z
j
‑2,...,z
r
,z0,z1,z2,...,z r
‑1]的形式、减1(模数2r)并将该低阶z位反转回来描述r级上的z到hr(z)的变换。类似地,当θ等于k
‑
1时(θ+1)mod k等于0,否则等于θ+1。针对z=[z
j
‑1,z
j
‑2,...,z
r
,z
r
‑1,...,z2,z1,z0],通过将从z
r
‑1到z0的低阶z位的顺序反转为形式z=[z
j
‑1,z
j
‑2,...,z
r
,z0,z1,z2,...,z r
‑1]、加1(模数2
r
)并将该低阶z位反转回来,来描述z到r级上的hr(z)的变换。
[0146]
根据图9a、图9b和图9c中描绘的系统的一个实施方式,互连结构可以包括:布置成如下结构的多个节点,该结构从源级到目的地级包括多个层级;跨越级的截面的多个节点;截面跨度中的多个节点。节点的级可以完全由节点在结构中的位置决定;并且多个互连线路联接结构中的节点。针对l级上的节点n:(1)多个消息输入互连线路联接至前一级l+1上的节点;(2)多个消息输入互连线路联接至l级上的节点;(3)多个消息输出互连线路联接至l级上的节点;(4)多个消息输出互连线路联接至后续级l
‑
1上的节点;(5)控制输入互连线路联接至l
‑
1级上的节点的消息输出互连线路;并且(6)交换机被联接以在控制输入互连线路上接收消息,并且根据该消息选择性地传输消息而不在联接至后续级l
‑
1节点的多个消息输出互连线路上或联接至l级的多个消息输出互连线路上进行缓冲。
[0147]
根据图9a、图9b和图9c中描绘的系统的另一实施方式,互连结构可以包括多个节点以及联接该节点的多个互连线路。多个节点中的节点x可以包括联接至不同于节点x的节点a的多个消息输入互连线路;以及联接至不同于节点a和节点x的节点b的多个消息输入互连线路。节点x接受来自节点a的消息输入和来自节点b的消息输入,其中在节点a与节点b之间传送控制信号,以确定冲突消息之间的优先级关系。控制信号可以强制执行从节点a向节点x发送消息与从节点b向节点x发送消息之间的优先级关系。
[0148]
根据图9a、图9b和图9c中描绘的系统的另外的实施方式,互连结构可以包括多个节点以及选择性地联接分层多级结构中的节点的互连结构中的多个互连线路。分层多级结构可以被布置为在从最低目的地l0级至离最低目的地l0级最远的最高l
j
级布置的层级中包括多个j+i级。节点的级可以完全由节点在结构中的位置确定,其中互连结构按照多个离散时间步长传输消息m。消息m按照时间步长移动并且互连结构具有互连,以按照时间步长以三种方式中的一者移动消息m,所述三种方式包括:(1)消息m从互连结构外部的设备进入互连结构中的节点;(2)消息m离开互连结构到指定输出缓冲区:以及(3)消息m从l
k
级上的节点u移动至同一l
k
级上的不同节点v,或者从节点u移动至l级上的节点w;其中k大于i,使得l
i
级比l
k
级更接近目的地l0级。
[0149]
根据图9a、图9b和图9c中描绘的系统的其它实施方式,互连结构可以包括多个节点;以及选择性地联接分层多级结构中的节点的多个互连线路,其中节点的级完全由节点在结构中的位置确定,其中数据仅从源级单向地或沿着多级结构的级横向地移动至目的地级。数据消息可以通过多级结构从源节点传输至指定目的地节点。多级中的一级可以包括一组或更多组节点。数据消息可以被传输至一组或更多组节点中的作为去往目的地节点的途径的一组节点。一组或更多组节点中的一组节点可以包括多个节点。如果一组中的多个节点中的节点n未被阻止,则数据消息可以被单向地朝向目的地级传输至该节点,否则如果该节点被阻止,则数据消息被横向地传输。
[0150]
根据图9a、图9b和图9c中描绘的系统的另外的实施方式,互连结构可以包括多个节点以及互连所述多个节点处的通信设备的多个互连线路l。节点可以包括按照一系列离散时间步长传送包括接收消息和发送消息的消息的通信设备。多个节点中的节点n可以包括:(1)到多个互连线路lun的连接,以将消息从设备u传输至节点n;(2)到多个互连线路lvn的连接,以将消息从设备v传输至节点n;以及(3)具有与节点n和设备u和v相关的如下优先关系pn(u,v)的网络,该优先关系使得设备u优先于设备v向节点n发送消息,使得经由多个互连线路lun定向到节点n的、设备u处的消息mu是按照时间步长t发送的,并且经由多个互连线路lvn定向到节点n的、设备v处的消息mv也是按照时间步长t发送的。消息mu成功发送至节点n,并且节点v使用控制信号来决定将消息mv发送至何处。
[0151]
根据图9a、图9b和图9c中描绘的系统的又一另外的实施方式,互连结构可以包括多个节点n以及按照预定图案连接所述多个节点n的多个互连线路l。互连线路承载消息m和控制信号c。消息m和控制信号c可以按照离散时间步长t被多个节点中的一节点接收并且消息m可以按照紧随其后的离散时间步长t+1被移动至多个节点中的后续节点。连接多个节点n的多个互连线路l可以包括:(1)具有用于接收消息ma的消息输入互连的节点na,(2)用于接收控制信号ca的控制输入互连,(3)到节点nd的直接消息输出互连,(4)到节点ne的直接消息输出互连,(5)到设备g的直接控制输出互连。用于确定消息ma是被发送至节点nd还是节点ne的控制逻辑可以基于:(1)控制信号ca;(2)节点na在多个互连线路l内的位置;以及(3)被包含在消息ma中的路由信息。
[0152]
在又一实施方式中,互连结构可以包括多个节点n以及按照预定图案连接所述多个节点n的多个互连线路l。连接多个节点n的多个互连线路l可以包括节点na,该节点具有用于接收消息ma的直接消息输入互连并且具有用于将消息ma传输至多个节点(包括最希望接收消息ma的选定节点np)的多个直接消息输出互连。仅通过消息ma的报头中的路由信息以及节点na在多个互连线路l内的位置就可以确定选定节点np。选定节点np具有用于从多个节点接收消息mp的多个直接消息输入互连,所述多个节点包括优先节点nb,该优先节点具有向选定节点np发送消息的优先级。优先节点nb可以由节点nb在多个互连线路l内的位置确定,使得:(1)如果节点na与节点nb相同,则消息ma是消息mp并且从节点na发送至节点np;(2)如果节点na与节点nb不同并且节点nb将消息mb定向至节点np,则消息mb从节点nb发送至节点np。
[0153]
在另外的实施方式中,互连结构可以包括能够同时承载多个消息m的网络,该网络包括:多个输出端口p;多个节点n,个体节点n包括多个直接消息输入互连和多个直接消息
输出互连;以及多个互连线路。个体节点n将消息m传递至多个输出端口p中的预定输出端口。预定输出端口p由消息m指定。多个互连线路可以被配置在选择性地联接分层多级结构中的节点的互连结构中,该分层多级结构被布置为在从最低目的地l0级至离最低目的地l0级最远的最高l
j
级布置的层级中包括多个j+1级,输出端口p连接至最低目的地l0级处的节点。节点的级可以完全由节点在结构中的位置确定。网络可以包括多个节点n中的节点na,控制信号进行操作,以限制被允许发送至节点na的消息的数量,以消除对节点na的预定输出端口的争用,使得消息m通过节点na的直接消息输出连接发送至节点nh,该节点nh位于不高于节点na的级的级l上,节点nh位于去往消息m的指定预定输出端口p的路径上。
[0154]
根据图9a、图9b和图9c中描绘的系统的实施方式,互连结构可以包括多个节点以及选择性地联接分层多级结构中的节点的互连结构中的多个互连线路。多级结构可以被布置为在从最低目的地l0级到最高l
j
级布置的层级结构中包括多个j+1级,其中j是大于0的整数,节点的级完全由节点在结构中的位置来确定,互连结构通过多个输入端口传输进入互连结构的未分类的多个多位消息。多个消息中的个体消息m可以是自路由的。个体消息m以多种方式移动,所述多种方式包括足以使消息m通过由消息m指定的输出端口离开互连结构的三种方式。这三种方式是:(1)消息m从互连结构外部的设备进入互连结构中的节点,消息m指定一个或更多个指定输出端口;(2)消息m移动通过互连结构中的节点,而未缓冲至指定输出端口;以及(3)消息m移动通过互连结构的l
k
级上的节点u,而未缓冲至同一l
k
级上的不同节点v,或者移动通过互连结构的l
k
级上的节点u,而未缓冲至在层级中比l
k
级更靠近目的地l0级的l
i
级上的节点w。
[0155]
根据图9a、图9b和图9c中描绘的系统的又一些其它实施方式,互连结构可以包括多个节点以及选择性地联接结构中的节点的互连结构中的多个互连线路。互连结构传输通过多个输入端口进入互连结构的未分类的多个多位消息。多个消息中的个体消息m可以是自路由的。互连结构可以包括:(1)节点ne,该节点具有来自节点na的第一数据输入互连以及来自与不同于节点na的节点nf的第二数据输入互连;以及(2)节点na与节点nf之间的控制互连,以承载解决向节点ne发送消息的争用的控制信号。控制信号可以从节点na或节点nf提供,节点na或节点nf均不同于与之传送消息的节点ne。
[0156]
根据图9a、图9b和图9c中描绘的系统的另外的其它实施方式,互连结构可以包括多个节点以及选择性地联接分层多级结构中的节点的互连结构中的多个互连线路。多级结构可以被布置为在从最低目的地l0级到最高l
j
级布置的层级结构中包括多个j+1级,其中j是大于0的整数。互连结构通过多个输入端口接收未分类的多个多位消息并传输该多位消息。多个消息中的个体消息m可以是自路由的并且使用虫洞路由移动通过节点,在该虫洞路由中,在两个节点之间只传输消息的多位中的一部分。多位消息在多个节点之间扩展。个体消息m以多种方式移动,所述多种方式包括足以使消息m通过由消息m指定的输出端口离开互连结构的四种方式。这四种方式是:(1)消息m从互连结构外部的设备进入互连结构中的节点,消息m指定一个或更多个指定输出端口;(2)消息m移动通过互连结构中的节点,而未缓冲至指定输出端口;(3)消息m移动通过互连结构的l
k
级上的节点,而未缓冲至同一l
k
级上的不同节点;以及(4)消息m移动通过互连结构的l
k
级上的节点,而未缓冲至在层级结构中比l
k
级更靠近目的地l0级的l
i
级上的节点。
[0157]
根据图9a、图9b和图9c中描绘的系统的另外的其它实施方式,互连结构可以包括
多个节点以及选择性地联接结构中的节点的互连结构中的多个互连线路。互连结构通过多个输入端口接收未分类的多个多位消息并传输该多位消息。多个消息中的个体消息m可以是自路由的并且使用虫洞路由移动通过节点,在该虫洞路由中,在两个节点之间只传输消息的多位中的一部分,多位消息在多个节点之间扩展。互连结构可以包括:节点n
e
,该节点具有来自节点n
a
的第一数据输入互连以及来自节点n
f
的第二数据输入互连;以及节点n
a
与节点n
f
之间的控制互连,其解决向节点n
e
发送消息的争用。
[0158]
根据图9a、图9b和图9c中描绘的系统的另外的其它实施方式,互连结构可以包括多个节点,各个节点具有多个输入端口和多个输出端口、与多个节点相关联的逻辑,并且节点x被包括在多个节点中并具有输出端口opx。节点x可以具有输入端子集ipx,其中,与节点x相关联的逻辑可以将进入该集ipx的输入端子的消息发送至输出端口opx。与节点x相关联的逻辑可以是可操作的,其中,如果消息m
p
到达输入端口集ipx的输入端口p并且存在从输出端口opx至消息mp的目标的路径,则只要输出端口opx未被未行进通过节点x的消息阻止,到达输入端口集ipx的消息中的一者就将被发送至输出端口opx。
[0159]
在又一些另外的实施方式中,互连结构可以包括:多个互连节点,所述多个互连节点包括不同节点f
w
、f
b
和f
x
;用于通过多个节点发送多个消息(包括通过节点f
w
发送消息集s
w
)的装置;以及用于通过节点f
w
发送关于消息集s
w
中的消息的路由的信息i(包括通过节点f
w
将消息集s
w
中的一部分消息路由至节点f
x
)的装置。互连结构还可以包括与节点f
s
相关联的用于使用信息i来通过节点f
b
路由消息的装置。
[0160]
在其它实施方式中,互连结构可以包括:多个节点,所述多个节点包括节点x、节点集t以及包括节点y和z的节点集s;连接节点的多个互连路径;联接至多个节点的多个输出端口;以及对通过节点到输出端口的数据流进行控制的逻辑。所述逻辑控制数据流,使得:(1)节点x能够向集s中的任何节点发送数据;(2)节点集t包括可以交替传递数据的节点,这些数据否则由逻辑控制流动通过节点x;(3)可以访问传递通过节点x的数据的任何输出端口也可以访问传递通过节点y的数据;(4)多个输出端口包括输出端口o,该输出端口可以访问传递通过节点x的数据,但不能访问传递通过节点z的数据;以及(5)逻辑对通过节点x的数据流进行控制,以最大化通过集t中的节点发送的数据消息的数量,使得可从集t中的节点访问的输出端口的数量小于可从节点x访问的输出端口的数量。
[0161]
参照图10,时序图例示了所描述的互连结构中的消息传送的时序。在互连结构的各种实施方式中,消息传送的控制由消息到达节点的时序确定。消息分组(诸如图11中所示的分组1100)包括报头1110和有效载荷1120。报头1110包括以二进制形式指定目标环的一系列位1112。当按照角度θ1和高度z的源设备cu(θ1,z1)向按照角度θ2和高度z2的目的地设备cu(θ2,z2)发送消息分组m时,报头1110的位1112被设置为高度z2的二进制表示。
[0162]
服务于整个互连结构的全局时钟保持积分时间模数k,其中k再次指定圆柱体高度z处的节点的数量n。存在两个常数α和β,使得α的持续时间超过β的持续时间,并且满足以下五个条件。首先,消息m在离开t级上的节点n(t,θ,z)后离开还是t级上的节点n(t,θ+l,ht(z))的时间量是α。第二,消息m在离开t级上的节点n(t,θ,z)后离开t
‑
1级上的节点n(t
‑
1,θ+l,z)的时间量是α
‑
β。第三,消息从设备cu行进至节点n(r,θ,z)的时间量是α
‑
β。第四,当消息m在持续时间α内从节点n(r,θ,z)移动至节点n(r,θ+l,hr(z))时,消息m也会使控制码从节点n(r,0,z)发送至节点n(r+1,θ,hr(z)),以偏转较外的r+1级上的消息。从消息m
进入节点n(r,θ,z)到控制位到达节点n(r+l,θ,h
r+1
(z))所经过的时间是持续时间β。当消息m从节点n(j,θ,z)移动至最外j级处的节点n(j,θ+l,h
j
(z))时,上述第四条件也适用,使得消息m也导致控制码从节点n(j,θ,z)发送至网络外部的设备d,以使d向n(j,θ+l,h
j
(z))发送数据。在一个实施方式中,d=cu(θ+1,h
j
(z))。从消息m进入节点n(r,θ,z)到控制位到达设备cu(θ,z)所经过的时间是持续时间β。第五,全局时钟按照速率α生成时序脉冲。
[0163]
当源设备cu(θ1,z1)向目的地设备cu(θ2,z2)发送消息分组m时,消息分组m从设备cu(θ1,z1)的数据输出端子发送至最外j级处的节点n(j,θ1,z1)的数据输入端子。消息分组和控制位在具有形式nα+lβ的时间进入t级上的节点n(t,θ,z),其中n是正整数。来自设备cu(θ1,z1)的消息m在时间α
‑
β发送至节点n(j,θ1,z1)的数据输入端子,并在时间t0插入节点n(j,θ1,z1)的数据输入端子,只要节点n(j,θ1,z1)未被由于消息在j级上遍历而产生的控制位阻止。时间t0的形式为(θ2‑
θ1)α+β。类似地,存在(θ2‑
θ1)α+jβ形式的时间,在该时间,节点n(j,θ1,z1)的数据输入端子接收来自设备cu(θ1,z1)的消息分组。
[0164]
节点n(t,θ,z)包括基于消息分组m的目标地址以及来自其它节点的时序信号来对消息的路由进行控制的逻辑。节点n(t,θ,z)的第一逻辑交换机(未示出)确定消息分组m是否要前进至下一级t
‑
l上的节点n(t
‑
1,θ+1,z)或节点n(t
‑
1,θ+1,z)是否被阻止。节点n(t,θ,z)的第一逻辑交换机是根据从节点n(t
‑
1,θ,h
t
‑1(z))发送的一位阻止控制码是否在时间t0到达节点n(t,θ,z)来设置的。例如,在一些实施方式中,当节点n(t
‑
1,θ+1,z)被阻止时,第一逻辑交换机采用逻辑1值,否则采用逻辑0值。节点n(t,θ,z)的第二逻辑交换机(未示出)确定消息分组m是否要前进至下一级t
‑
l上的节点n(t
‑
1,θ+1,z)或节点n(t
‑
1,θ+1,z)是否未位于用于访问消息分组m的报头的目的地设备cu(θ2,z2)的合适路径中。消息分组m的报头包括目的地高度z2(z2(j),z2(j
‑
1),...,z2(t),...,z2(l),z2(0))的二进制表示。t级上的节点n(t,θ,z)包括高度指定z(z
j
,z
j
‑1,...,z
t
,...,z1,z0)的一位指定z
t
。在该实施方式中,当第一逻辑交换机具有逻辑0值并且指定高度的位指定z2(t)等于高度指定zr时,则消息分组m在节点n(t
‑
1,θ+1,z)处前进至下一级,并且指定高度位z2(t)从消息分组m的报头剥离。否则,消息分组m在同一级t上遍历至节点n(t,θ+1,h
t
(z))。如果消息分组m前进至节点n(t
‑
1,θ+1,z),则消息分组m在时间t0+(α
‑
β)到达,该时间等于时间(z2‑
z1+1)α+(j
‑
1)β。如果消息分组m遍历至节点n(t,θ+1,h
t
(z)),则消息分组m在时间t0+α到达,该时间等于时间(z2‑
z1+1)α+jβ。当消息分组m从节点n(r,θ,z)发送至节点n(t,θ+1,h
t
(z))时,一位控制码被发送至节点n(t+1,θ,h
t
(z))(或者设备cu(θ,z)),该一位控制码在时间t0+β到达。在整个互连结构中继续该时序方案,从而随着消息分组的推进和偏转保持同步。
[0165]
消息分组m在指定目的地高度z2处达到0级。此外,消息分组m在零模数k(高度z处的节点的数量)时到达目标目的地设备cu(θ2,z2)。如果目标目的地设备cu(θ2,z2)准备好接受消息分组m,则输入端口在时间零模数k被激活以接受该分组。有利地,所有路由控制操作都是通过比较两个位而从不比较两个多位值来实现的。更有利地,在互连结构的离开点,当消息分组从节点前进至设备时,不存在比较逻辑。如果设备准备接受消息,则消息经由时钟控制门进入设备。
[0166]
参照图10和图11,互连结构的实施方式可以包括按照三维拓扑布置的多个节点以及用于将消息从节点n传输至目标目的地的装置。用于将消息从节点n传输至目标目的地的
装置可以包括用于确定位于第二维度和第三维度中的到目标目的地的途径中并且将一级朝向第一维度的目的地级推进的节点是否被另一消息阻止的装置;以及用于当途径节点未被阻止时将消息朝向第一维度的目的地级推进一级的装置,以及用于在第二维度和第三维中沿着恒定级移动消息否则在第一维度中这样操作的装置。用于将消息从节点n传输至目标目的地的装置还可以包括:用于对描述多级的第一维度、描述跨越级的截面的多个节点的第二维度以及描述级的截面中的多个节点的第三维度进行指定的装置;用于从途径节点的级上的节点向第一维度中的节点n发送控制信号的装置,其中该控制信号指定途径节点是否被阻止;用于使用全局时钟对消息进行时序传输的装置,该全局时钟指定时序间隔以保持级的截面中的节点数量的积分时间模数;以及用于设置第一时间间隔α以在第二维度和第三维度中移动消息的装置。用于将消息从节点n传输至目标目的地的装置还可以进一步包括用于设置第二时间间隔α
‑
β以将消息朝向目的地级推进一级的装置,全局时钟指定等于第二时间的全局时间间隔,第一时间间隔小于全局时间间隔;以及用于设置第三时间间隔以从途径节点的级上的节点向节点n发送控制信号的装置,第三时间间隔等于β。
[0167]
在图12中,单个芯片1200包含两个部件。第一部件是所有先前图中所描述的数据涡交换机1220,并且第二部件是处理核的阵列1240。参照图13,数据涡交换机在线路1210上从外部源接收数据。处理核的阵列1240的处理核1250可以在线路1230上从数据涡交换机接收数据。处理核的阵列1240中的发送处理核1250可以通过形成报头指示接收核的位置并且有效载荷指示将被发送的数据的分组来将数据发送至处理核阵列中的接收核。在图13中,该分组沿线路1310向下发送并租用数据涡交换机1220。数据涡交换机在线路1230上将分组路由至接收核。在图13中,处理核的阵列1240中的核也可以在输出线路1260上将分组发送至地址(未图示)。
[0168]
参照描绘四个处理器核阵列1240的图14。通常,可以存在任意数量的处理器核阵列。相比之下,对于当今纵横式或网格拓扑,考虑到这些拓扑的端点数量有限,处理器核阵列存在上限。
[0169]
处理核的阵列1240中的发送处理核可以通过形成报头指示接收核的位置并且有效载荷指示将被发送的数据的分组来将数据发送至处理核的阵列中的一者中的接收核。该分组沿线路1450向下发送并进入数据涡交换机1410。数据涡交换机1410首先通过将分组路由至包含该接收处理核的处理核阵列来将分组路由至该接收核。数据涡交换机1220将分组路由至处理器核阵列1240中的接收处理核。由于数据涡交换机1410和1220不是纵横式交换机,所以当不同组分组进入该交换机时,不需要对交换机进行全局设置和重置。在当今技术中,随着纵横式交换机中输入端的数量的增加,设置交换机的时间根据输入端的数量增加。其它技术中的该设置问题会导致长分组。有利地,因为分组只是简单地进入和离开,所以不存在数据涡交换机的设置。
[0170]
需要部署的数据涡交换机1410的数量取决于处理器核的总数量和传输线路的带宽。
[0171]
在给定处理核阵列1240中的处理核向其同一阵列中的另一处理核发送分组pkt的情况下,发送的分组传递通过数据涡交换机1410,其中该分组与传递通过系统的其它分组一起行进。分组的这种置乱提供了随机性,在由数据涡交换机支持的其它硬件系统中证明了这种随机性是有效的。这是有利的,因为与使用纵横式交换机或网格连接处理器核的芯
片和系统不同,存在精细粒度的并行性。精细粒度的并行性允许避免了拥塞的短分组移动(不长于缓存线路)。这非常适合需要小数据分组的应用。
[0172]
重要的事实是,硅基板1400上可以存在大量芯片1200,在这些芯片之间行进的分组没有必要传递通过serdes模块。在当今硬件中,行进通过serdes模块的数据分组会显著增加延迟。由于芯片1200的边缘处不存在serdes模块,因此在硅基板1400上的芯片1200之间行进的分组将不会受到这种延迟的影响。
[0173]
如果模块1200被放置在印刷电路板1400上,那么使用线路1450从一个模块1200行进通过数据涡交换机1410然后行进通过线路1440的分组必须行进通过各个芯片边界上的serdes模块。尽管在该实现中,分组受到由serdes模块引起的延迟的影响,但系统仍然受益于增加的核数量、较短的分组长度以及由数据涡交换机实现的精细粒度的并行性。
[0174]
多个处理器核阵列1240允许处理核的更大的总数量并且允许核中的各个核具有更大的大小。在使用纵横式交换机的当今技术中,随着核数量的增大,分组大小也会增大。随着核数量的增大,通过使用图12、图13和图14中描述的数据涡,分组大小保持不变。
[0175]
在图14的其它实施方式中,通过数据涡交换机1410访问与处理器核阵列相邻的存储器控制器。
[0176]
将数据涡网络和处理器阵列放置在同一模块(例如,硅基板)上具有许多优点。这样做会从数据涡路径中移除串行器/解串行器块(“serdes”),从而降低所需功率和延迟。当前,支持数据涡的系统也因商用片上网络而变慢。在同一模块上具有数据涡网络取代了那些传统的片上网络(noc),并允许整个系统受益于数据涡拓扑的所有优势(即,在整个生态系统中无拥塞的小分组移动)。因此,可以从核到核数据路径中移除非数据涡noc,因此与现有技术相比,分组可以保持较小,在现有技术中,从商用微处理器行进离开的分组在经过片外数据涡网络时会被分解。与当今支持数据涡的系统相比,这还提供了更一致的核到核或核到存储器的延迟。在下一级别(板对板)上,模块上数据涡网络提供了跨整个系统的通用套件到套件以及核到核架构,从而消除了同一系统内不同拓扑的必要性。所有这些都支持跨核、套件和服务器的通用编程模型,从而使最终用户更容易使用。
[0177]
可以在本文中使用的用语“大致”、“基本上”或“大约”涉及关于对应术语的行业接受的可变性。这种行业接受的可变性从小于百分之一变化至百分之二十,并且对应于但不限于材料、形状、大小、功能、值、处理变型等。可以在本文中使用的术语“联接”包括直接联接和经由另一部件或元件的间接联接,其中针对间接联接,中间部件或元件不修改操作。推断联接(例如其中一个元件通过推断联接至另一元件)包括两个元件之间的以与“联接”相同的方式的直接联接和间接联接。
[0178]
例示性图形示意图描绘了制造处理中的结构和处理动作。尽管特定示例例示了特定结构和处理动作,但许多另选实现是可能的,并且通常通过简单的设计选择来实现。基于对功能、目的、与标准的一致性、遗留结构等的考虑,制造动作可以以与本文的特定描述不同的顺序来执行。
[0179]
虽然本公开描述了各种实施方式,但这些实施方式应被理解为例示性的并且不限制权利要求的范围。所描述的实施方式的许多变型、修改、添加和改进是可能的。例如,本领域普通技术人员将容易实现提供本文公开的结构和方法所需的步骤,并且将理解处理参数、材料、形状和尺寸仅作为示例给出。可以改变参数、材料和尺寸以实现在权利要求的范
围内的期望的结构以及修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1