一种基于大规模MIMO的随机接入方法与流程
本发明属于通信技术领域,更进一步涉及无线通信技术中的一种基于大规模mimo的随机接入方法。在考虑频率误差和时间误差的情况下,在一定程度上改善了现有方法在估计用户数方面受到频域资源数n的限制的问题,在估计用户的时间误差和信道信息方面也有了很大的改善。
背景技术:
多输入多输出(multiple-inputmultiple-output,mimo)技术是指在发送端和接收端分别使用多个发射天线和接收天线,充分利用空间资源,在不增加频谱资源和天线发射功率的情况下提高系统的信道容量。大规模mimo技术是基于mimo技术的改进,通过在集站配置几十甚至几百根天线获得优于mimo技术的性能。在针对h2h(humantohuman)用户的大规模mimo系统中,可以为每一个用户分配专用的导频,导频的正交性可以使集站准确的估计出用户到基站的信道信息。但是在m2m(machinetomachine)场景下,用户数远远多于h2h场景的用户数,会存在有多个用户同时选择相同导频的情况,从而造成导频污染,此时采用传统的导频分配方法进行信道估计的方法将不再适用。
采用导频随机接入的方法可以在一定程度改善导频污染的问题。但是现有的随机接入方案,大多考虑的是完美的频域和时间同步网络,使得随机接入的导频序列的正交性在集站处得以保留。在随机接入期间,在初始的下行链路同步过程中的多普勒频移和估计错误会导致产生频率误差,小区内用户的位置的不同也会导致产生时间误差。在存在频率误差和时间误差的情况下,在相邻的子载波和连续的ofdm符号上发送的随机接入导频在集站处将不再具有正交性。结果会导致随机接入方案的性能会有显著的恶化。
考虑到频率和时间误差,lucasanguinetti等人在“randomaccessinmassivemimobyexploitingtimingoffsetsandexcessantennas”中提出了一种新的随机接入方案,其主要步骤为:首先,对于想要进入的激活用户选择一对随机接入码发送给基站;然后基站处使用mdl算法估计每个时域资源的用户数量,并估计用户定时偏移,计算信道估计;使用sucr协议判断用户是否需要重传;最后使用信道估计来区分两个具有相近时间偏移的用户。但是其中使用的用户数估计方法,极大程度上收到了频域资源数的限制,一旦选择同一时域资源的用户大于频域资源数,其估计的用户数、时间偏移和信道信息都会有很大的偏差,重新发送导频的用户数也会减少。
技术实现要素:
为了克服现有方法的不足,本发明提出了一种基于大规模mimo的随机接入方法,在考虑频率误差和时间误差的情况下,在一定程度上改善了现有方法在估计用户数方面受到频域资源数n的限制的问题,在估计用户的时间误差和信道信息方面也有了很大的改善。
为了实现上述的目标,本发明采用的技术方案为:
一种基于大规模mimo的随机接入方法,包括以下步骤:
步骤1:对于小区内给定的一个想进入网络的用户,该用户分别从时域资源和频域资源选择代码组成时域频域随机接入块,向基站发送随机接入请求,对于随机接入块,其由q个连续的ofdm符号和n个相邻的子载波组成,共计有τ个样本,其中τ=qn,在下行链路同步之后,对于给定的一个想接入网络的激活用户,该用户随机的从cq={t0,t1,…,tq-1,}和cn={f0,f1,…,fn-1,}中选择一对代码块,其中
步骤2:基站估计选择同一时域资源的激活用户数,在进行随机接入的过程中,我们利用以下事实:传播信道不会破坏时域码的正交性,选择了不同时域码的用户之间不会产生互相干扰,所以在不失一般性的情况下,我们可以仅关注选择了同一时域资源的用户,过程为:
步骤2.1:基站收到激活用户的接收信号矩阵
其中k表示用户的集合,ρk表示用户k的发射功率,hkm表示用户k到天线m的信道传输系数,
步骤2.2:将接收信号矩阵与当前时域资源相关联,可以估计出选择当前时域资源的用户数。
其中
步骤3:对所有用户进行频域资源代码识别和定时偏移估计,过程为:
步骤3.1:利用一种估计定时偏移的方法估计出所有估计用户的定时偏移;
先前于步骤2.2中获取到了估计到的用户数
步骤3.2利用所得的定时偏移估计值获取用户所选择的频域资源码;
步骤4:基站端估计用户的信道响应,过程为:
步骤4.1:利用步骤3所获取的参数,获取到估计用户的信道响应估计值,其表示为:
其中||·||表示欧几里得范数,*表示矩阵的共轭;
步骤4.2:根据信道响应估计值判断是否在步骤3有错误的估计值。
利用步骤4.1中获取的信道响应估计,计算每个用户的
如果有用户
步骤4.3:如果有错误估计的用户,对误估计用户进行重新估计定时偏移和频域码;
步骤4.4:再次获取到所有估计用户的信道响应估计值,记录能够成功检测到的用户,并且判断是否有需要进行重传的用户,再次获取到的信道响应估计值记为
如果用户k的numk大于1,则证明有大于等于1个用户与该用户位于同一随机接入块,且这几个用户的定时偏移相差非常小,模型难以区分,将这些用户记录下来进行重传;
步骤5:对于重传用户基站进行第二次信道响应估计,过程为:
步骤5.1:对于步骤4.4中需要重传的用户重复步骤2-4.3;
步骤5.2:针对重传用户获取信道响应估计值,记录重传之后的能够成功检测到的用户数;
步骤5.3:记录步骤4.4与步骤5.2中成功检测到的用户;
步骤6:随机接入过程结束。
进一步,所述步骤1中,对于激活用户可选择的随机接入块,其由q个连续的ofdm符号和n个相邻的子载波组成,共计有τ个样本,其中τ=qn。
再进一步,所述步骤2中,因为传播信道不会破坏时域码的正交性,选择了不同时域码的用户之间不会产生互相干扰。
再进一步,所述步骤2中,基站获得的接收信号为
所述步骤3中,对估计用户进行定时偏移估计和频域码识别之前,需要判断估计的用户数
所述步骤4.4中,如果存在两个或两个以上的用户所选择的随机接入块相同并且他们的定时偏移相差非常小,模型将难以区分这两个用户,所以根据估计得到的用户信道信息,可以判断是否存在多个用户无法区分,记录无法区分的用户并将这些用户重新发送,重传的用户重复步骤1到步骤4,最终基站端重新估计重传用户的信道响应。
本发明的有益效果是:
1.相比传统的随机接入方案,本发明考虑到了随机接入期间的频率误差和时间误差。
2.本发明提出了一种新的用户数估计方法,在一定程度上改善了现有方法在估计用户数方面受到频域资源数n的限制的问题,在估计用户的时间误差和信道信息方面也有了很大的改善。
附图说明
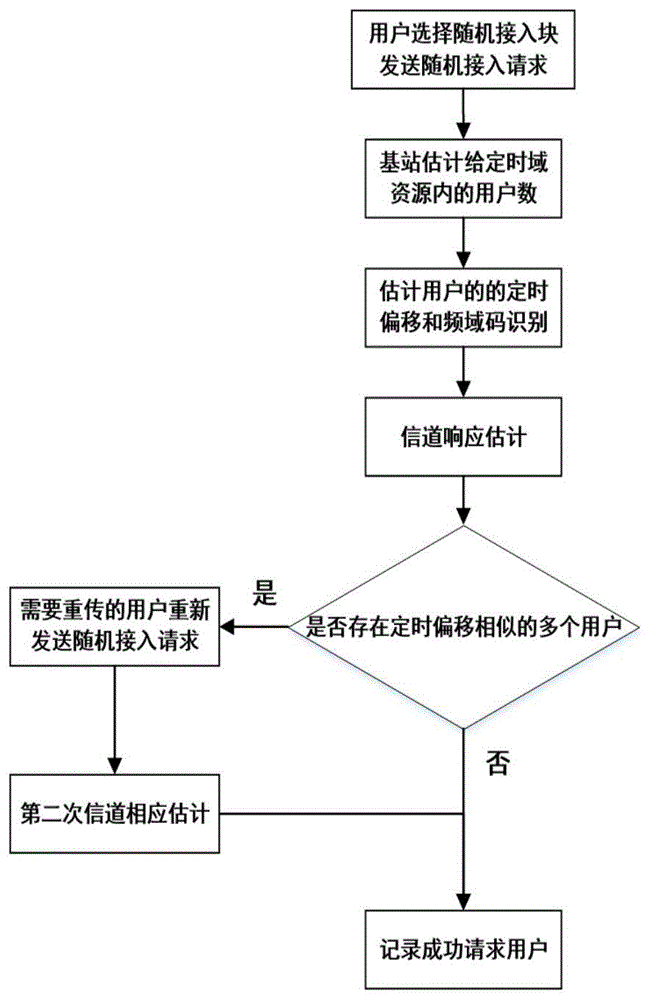
图1是本发明的流程图;
图2和图3是本发明的结果仿真图。
具体实施方式
以下结合附图和具体实施例子,对本发明做进一步详细说明。
参照图1~图3,一种基于大规模mimo的导频随机接入方法,包括以下步骤:
步骤1:对于小区内给定的一个想进入网络的用户,该用户分别从时域资源和频域资源选择代码组成时域频域随机接入块,向基站发送随机接入请求,针对本专利提出的系统模型,为了充分利用大规模mimo系统中多天线带来的性能增益,基站需要准确的获得每个用户的信道状态信息,所考虑单个小区大规模mimo系统模型,在该模型中,基站位于小区的中心位置,并配置有m根天线,小区内总共有k个单天线用户均匀分布在小区内,每个用户以pa概率被激活成为激活用户,总激活用户数na=k*pa(m>>na),其中随机接入块由q个连续的ofdm符号和n个相邻的子载波组成,共计有τ个样本,其中τ=qn,在下行链路同步之后,对于给定的一个想接入网络的激活用户,该用户随机的从cq={t0,t1,…,tq-1,}和cn={f0,f1,…,fn-1,}中选择一对代码块,其中
其中用户k向基站端传输的随机接入信号,伴随有特定的载波频率偏移ωk和归一化的定时误差θk。其中θk取决于用户k到基站端的距离,其表示为
步骤2:基站估计选择同一时域资源的激活用户数,过程为:
步骤2.1:基站收到激活用户的接收信号矩阵;
在q个ofdm符号期间,于子载波n上的基站的第m根天线的dft输出为:
其中κ表示所有激活用户的集合,ρk为用户的发射功率,其中hkm表示用户k与基站端第m根天线之间的信道传输系数,其可通过大尺度衰落及小尺度衰落共同决定
其中
因为传播信道不会破坏时域码的正交性,选择了不同时域码的用户之间不会产生互相干扰,所以在不失一般性的情况下,可以仅关注选择了同一时域资源的用户所以将公式(1)改写为
其中t表示矩阵的转置,k表示单一时域块中的激活用户集合,为了简化公式,删除了t的下标索引ik;
步骤2.2:将接收信号矩阵与当前时域资源相关联,可以估计出选择当前时域资源的用户数,将接收信号
其中
步骤3:对所有用户进行频域资源代码识别和定时偏移估计,过程为:
步骤3.1:利用一种估计定时偏移的方法估计出所有估计用户的定时偏移;
首先计算样本相关矩阵
针对
由此使用esprit算法来重新获取估计用户的有效定时偏移;
其中
对于剩余的
其中h表示矩阵的转置,
其中t表示矩阵的转置。
步骤3.2:利用所得的定时偏移估计值获取用户所选择的频域资源码;
对于定时误差的最大值θmax,如果满足条件
lk=ceil(n∈k)(2)
其中根据ceil(·)函数表示返回大于或等于指定表达式的最小整数,根据公式(2),使用步骤3.1中获得到定时偏移,获得估计用户的频域码;
步骤4:基站端估计用户的信道响应,过程为:
步骤4.1:利用步骤3所获取的参数,获取到估计用户的信道响应估计值;
其中*表示矩阵的共轭,||·||表示欧几里得范数;
步骤4.2:根据信道响应估计值判断是否在步骤3有估计值
其中h表示矩阵的共轭转置,如果
步骤4.3:如果有错误估计的用户,对误估计用户进行重新估计定时偏移和频域码,重新估计之后的用户定时偏移记为
步骤4.4:再次获取到所有估计用户的信道响应估计值,记录能够成功检测到的用户,并且判断是否有需要进行重传的用户,再次估计后的信道响应估计值记为
其中h表示矩阵的共轭转置,如果numk中的每一行个元素相加大于1,说明有多个用户与该用户的偏移量相似,模型难以区分,所以需要进行用户重传,记录下能够正确检测到的用户数uesuccess1,并且对需要重传的用户进行重传,
步骤5:对于重传用户基站进行第二次信道响应估计,过程为:
步骤5.1:对于步骤4.4中需要重传的用户重复步骤2-4.3;
步骤5.2:针对重传用户获取信道响应估计值,记录重传之后的能够成功检测到的用户数uesuccess2;
步骤5.3:记录步骤4.4与步骤5.2中成功检测到的用户,uesuccess=uesuccess1+uesuccess2为总的成功检测到的用户数;
步骤6:随机接入过程结束。
下面结合仿真图对本发明做进一步的描述。
1.仿真条件:
在使用软件仿真平台matlabr2016a的条件下,对本发明进行仿真实验。其结果如图2和图3所示。本发明的仿真参数设置为:时域资源块数q=2,频域资源块数设置了两个对比值n=8和n=10。基站的天线总数默认值m=500,小区内用户数默认值k=800。
2.仿真内容和结果分析:
图2为本发明的激活用户检测概率与基站端天线数量的关系。图2的横坐标表示基站端的天线个数,从坐标表示激活用户检测概率。根据曲线变化我们可以得出,用户的检测概率随着天线数量的增加逐步增加,并且频域资源块n=10时的检测概率明显高于n=8时的用户检测概率。图3为本发明的激活用户检测概率与小区内用户数的关系。图3的横坐标表示小区内的总用户数,纵坐标表示激活用户检测概率。可以看出,用户检测概率随着小区内用户数的增加而降低,但基于仿真结果,用户数达到1300时,检测概率仍然可以达到70%左右,其中频域资源块n=10时的检测概率明显高于n=8时的检测概率。
- 还没有人留言评论。精彩留言会获得点赞!