一种基于听觉匹配的虚拟声定制方法及装置与流程
本发明涉及3d虚拟声技术领域,具体涉及一种基于听觉匹配的3d虚拟声定制的方法及装置,其生成为满足个体听觉特性的虚拟声。
背景技术:
头相关传输函数(head-relatedtransferfunction,hrtf)是3d虚拟声技术的核心数据。hrtf与原始单通路信号以及房间脉冲响应进行运算所合成的双耳虚拟声信号,从物理的角度重构了真实3d声场景中某声源所对应的双耳声压信号,经耳机重放可以使用户获得和真实声源相同或相似的主观感受(即现场感和沉浸感)。
从物理起源上看,hrtf表征了从声源到双耳的传输过程中声波与人体生理结构(如头部、耳廓)的相互作用。一方面,每个空间声源方位对应一对hrtf数据(左耳hrtf和右耳hrtf);3d虚拟声重放需要大量空间方位的hrtf数据。另一方面,不同个体的生理结构具有不同的生理特征(如不同的头部尺寸和耳廓精细结构),因此hrtf是一个因人而异的个性化物理量。现有研究表明,为了获得高质量的3d虚拟声重放效果,需要采用听者自己的个性化hrtf数据进行虚拟声合成;而采用非个性化hrtf可能引起定位精度下降、头中率和前后混乱率增高的不良现象。个性化hrtf可以通过实验室测量或数值计算获取。然而,这两种方法都需要专业设备、场地且非常耗时,很难将其用于获取虚拟声产品潜在用户的个性化hrtf数据(xieb.s.,head-relatedtransferfunctionandvirtualauditorydisplay,j.rosspublishing,usa,2013)。
依据现有的hrtf数据库(部分数据库已在互联网公开,例如美国cipic数据库、奥地利ari数据库等),有研究提出采用匹配的方法获取个性化hrtf的近似。该方法的基本思路是:依据特定的匹配因子,从hrtf数据库中挑选出和用户匹配的hrtf数据,作为用户个性化hrtf的近似。hrtf匹配法的精度主要取决于匹配因子的选择。目前的匹配因子主要有两种:1)生理特征值;2)少量空间方位的hrtf。虽然生理特征值的异同是hrtf异同的主要原因,然而hrtf相关生理特征值的选取以及权重赋值,都是尚未完全解决并取得共识的问题。这将直接影响基于生理特征值的hrtf匹配的精度。另一方面,由于声波和生理结构相互作用的复杂性,采用少量空间方位的hrtf匹配出大量空间方位的hrtf的思路可能会出现“以偏概全”的错误。整体来看,最终的虚拟声重放是一个从生理到物理(即hrtf)再到心理(即听觉感知)的复杂过程,无论是基于生理特征值还是基于少量空间方位hrtf的匹配方法都未能直接和听觉感知效果关联。这也是现有hrtf匹配法精度有限的主要原因。而有限精度的hrtf匹配效果也将直接影响后续基于hrtf的虚拟声定制的效果。
技术实现要素:
本发明为解决上述现有个性化hrtf匹配以及虚拟声定制方法的缺陷,提供一种基于听觉匹配的虚拟声定制方法及装置。本发明以神经网络预测的听觉分数为匹配因子,从已有的hrtf数据库中挑选出对应最高听觉分数的hrtf数据,作为用户听觉匹配的hrtf数据进行虚拟声合成。该方法可提升现有基于匹配的hrtf以及虚拟声的定制效果,包括仰角定位精度的提高以及头中率和前后混乱率的下降。
本发明的目的至少通过以下技术方案之一实现。
一种基于听觉匹配的虚拟声定制方法,其包括如下步骤:
步骤1、获取用户头部的3d模型;
步骤2、从3d模型中提取hrtf相关的生理特征值;
步骤3、将生理特征值输入听觉评估神经网络,预测听觉分数;
步骤4、从已知hrtf数据库中挑选出最高听觉分数所对应的hrtf数据,作为用户听觉匹配的hrtf数据;
步骤5、将原始单通路信号、听觉匹配hrtf数据、房间脉冲响应依次进行时间域卷积处理或等价地频率域滤波处理,得到用户定制的双耳虚拟声信号;
步骤6、采用耳机播放双耳虚拟声信号。
进一步地,步骤1中的所述用户头部的3d模型能通过移动终端自带的3d传感装置直接获取,或通过移动终端拍摄的2d图像的3d重构间接获取。
进一步地,步骤2中hrtf相关的生理特征值包括:两耳屏间宽、耳甲腔高度、耳甲腔宽度、耳甲腔深度、耳前后偏转角、耳凸起角和斐波那契偏离度等。
进一步地,采用公式(1)计算斐波那契偏离度:
公式(1)中的34和55分别是斐波那契数列(fibonaccisequence)的第九项和第十项。
进一步地,步骤3中听觉评估神经网络的输入是用户的m个生理特征值,输出是用户对n类hrtf数据的听觉分数。
进一步地,步骤3中听觉评估神经网络已事先构造和训练完毕,步骤如下:
1、选取一个已知的hrtf数据库,包括n名受试者的多个空间方向的hrtf数据(即n类hrtf数据);
2、选取k个听音者,采用3d扫描的方式获取听音者头部的3d模型。进一步,利用软件从3d模型中提取hrtf相关的m个生理特征值,进行离差标准化,获得m×k的生理特征值矩阵p=[pm,k](m=1,2,…,m;k=1,2,…,k);
3、采用n类hrtf数据制作虚拟声信号,用k个听音者进行虚拟声的听觉实验,得到n×k的听觉分数矩阵s=[sn,k](n=1,2,…,n;k=1,2,…,k),其中
(2)式中an,k表示第k个听音者对第n类hrtf虚拟声信号的头中率,bn,k表示第k个听音者对第n类hrtf虚拟声信号的前后混乱率,cn,k表示第k个听音者对第n类hrtf虚拟声信号的仰角定位准确率;
4、构造一个广义回归神经网络,生理特征值作为网络输入,听觉分数作为网络输出,上述{p=[pm,k],s=[sn,k]}构成训练集。采用留一法确定网络的平滑因子。
5、保存训练好的神经网络模型。
进一步地,步骤2和步骤3中所述的涉及双耳的生理特征值,都是先分别对双耳提取特征值,然后再取平均值。
进一步地,步骤4中,如果有多类hrtf数据都对应最高听觉分数,则根据应用场景的需求,按照公式(2)中的三个听觉指标(头中率、前后混乱率、仰角定位准确率)再进行排序,直至可以唯一确定听觉匹配的hrtf类别。
一种用于实现权利要求1至权利要求8中任一项所述方法的装置,其特征在于,包括:
3d头模获取模块,用于采集用户头面部的3d结构信息;
运算控制模块,用于从已知hrtf数据库中,依据神经网络根据用户生理特征值所预测的听觉分数,找出用户听觉匹配的hrtf数据进行虚拟声合成;
虚拟声播放模块,由声卡和耳机组成,用于播放合成的虚拟声信号。
进一步地,所述的运算控制模块包括:
生理特征值提取模块,用于从3d头模中提取出m个生理特征值,包括(但不限于)两耳屏间宽、耳甲腔高度、耳甲腔宽度、耳甲腔深度、耳前后偏转角、耳凸起角、斐波那契偏离度;
hrtf听觉匹配模块,将用户生理特征值输入事先训练好的听觉评估神经网络,预测用户对n类hrtf的听觉分数;从hrtf数据库中挑选出最高听觉分数所对应的hrtf数据,作为用户听觉匹配的hrtf数据;
虚拟声信号合成模块,用于将原始单通路信号、听觉匹配hrtf数据、房间脉冲响应依次进行时间域卷积处理或等价地频率域滤波处理,合成得到特定声场景下的双耳虚拟声信号,输出到耳机进行重放。
本发明的原理是:从听觉形成的全链条来看,虚拟声重放是一个从生理到物理再到心理的复杂过程。无论是从生理到心理的过程,还是从物理到心理的过程,都涉及高阶的非线性映射关系。由于现有的基于生理特征值(即生理角度)和少量空间方位hrtf(即物理角度)的匹配方法都是基于线性映射假设,因此其定制效果有限。本发明利用神经网络强大的非线性映射功能,将生理特征值和听觉效果直接关联,即将用户生理特征值输入已训练好的神经网络即可预测出用户可能给出的听觉分数。这种hrtf听觉匹配的方法直接采用听觉分数作为匹配因子,理应比现有采于非听觉因子的hrtf匹配法更为准确,相应的虚拟声定制效果也更优。需要指出的是:如果不使用神经网络预测听觉分数,那么用户就需要对hrtf数据库中的多类hrtf数据逐个进行听觉实验(包括仰角方位的判断、头中现象的判断、前后混乱现象的判断),获得每类hrtf数据的听觉分数,然后再依据最高听觉分数进行库中hrtf数据的挑选。如此繁琐和冗长的hrtf匹配是用户所无法接受的。因此,本发明中采用神经网络进行预测是降低实际用户负担的必要环节。此外,hrtf相关的生理特征值尚无定论,本发明一方面采用3d头模尽可能多的提取可能的hrtf相关生理特征值;另一方面提出了一个反映耳廓整体特征的特征值——斐波那契偏离度。本发明在匹配因子的选取、hrtf相关生理特征值的遴选以及听觉分数获取方面的优点都将有助于实际虚拟声产品效果的提升。在一定程度上,现有移动终端(特别是手机)3d成像功能以及神经网络运算的发展为本发明的实现提供了有力支持。
本发明与现有技术相比,具有如下优点和有益效果:
1.采用听觉分数作为hrtf的匹配因子,将匹配效果直接和听觉效果关联起来,使最终的虚拟声定制效果更加符合用户的听觉感知,从而提高仰角定位准确性,减少前后虚拟声像的混淆,增强3d虚拟声重放的现场感和沉浸感。
2.采用神经网络建立生理特征值和听觉分数之间的高度非线性映射关系,提高了hrtf匹配的效率和精度。
3.充分利用现有3d成像设备的普及化,在hrtf相关生理特征值的选取上更为全面。同时,提出的斐波那契偏离度可以反映耳廓整体的形态特征。
4.本发明可采用算法语言编制的软件在多媒体计算机上实现,也可以采用通用信号处理芯片(dsp硬件)电路或专用的集成电路实现,用于各种便携式播放设备包括智能手机、虚拟头盔等方面的声音重放。
附图说明
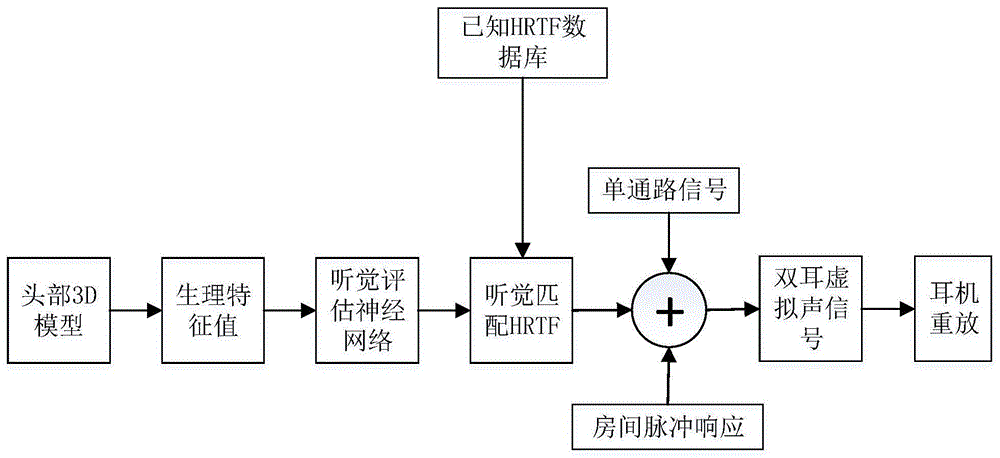
图1是本发明实施例中基于听觉匹配的虚拟声定制方法的原理图;
图2是本发明实施例中听觉匹配hrtf的获取过程示意图;
图3是本发明实施例的模块连接示意图。
具体实施方式
下面结合附图对本发明作进一步的说明,但本发明要求保护范围并不局限于实施例表示的范围。
图1是本发明的一种基于听觉匹配的虚拟声定制方法的原理方框图。它采用神经网络建立了生理特征值和听觉分数之间的非线性映射关系;进一步的,以神经网络预测的听觉分数为匹配因子,从已知hrtf数据库中挑选出和用户听觉匹配的hrtf数据,作为个性化hrtf的近似;最后,采用听觉匹配的hrtf进行双耳虚拟声合成,实现虚拟声的用户定制。该方法优于现有的采用非听觉因子的hrtf匹配以及虚拟声定制的方法,表现为仰角定位准确性的提高、头中以及前后混淆现象的减少,最终可增强3d虚拟声重放的现场感和沉浸感。
一种基于听觉匹配的虚拟声定制方法,其包括如下步骤:
步骤1、获取用户头部的3d模型;
具体而言,步骤1中的所述用户头部的3d模型能通过移动终端(例如手机)自带的3d传感装置直接获取,或通过移动终端拍摄的2d图像的3d重构间接获取。
根据厂家发布的信息,oppofindx智能手机自带全隐藏式3d摄像头装置,vivonex智能手机搭载tof3d超感应深度摄像技术等。这些移动终端自带的3d传感装置可以在数十秒内获取头面部的3d模型。此外,对于普通的智能手机,可以通过3d建模软件app(例如qlone、altizure等),实现基于多张普通2d图像的3d重构。虽然移动终端采集头面部3d模型的初衷是进行人脸识别以及扫脸支付等功能,但是这里也可以借用以提升虚拟声定制的效果。
步骤2、从3d模型中提取hrtf相关的生理特征值;
具体而言,步骤2中hrtf相关的生理特征值包括:两耳屏间宽、耳甲腔高度、耳甲腔宽度、耳甲腔深度、耳前后偏转角、耳凸起角和斐波那契偏离度等。
采用成熟的图像处理软件(例如solidworks)和图像特征提取算法(例如方向梯度直方图hog法、局部二值模式lbp法、haar-like特征法)可以得到3d头模的生理特征值。原则上,可提取的特征量有无限多。考虑到目前hrtf相关的生理特征值尚无定论,本发明的hrtf相关生理特征值不仅涵盖了现有研究中认为比较重要的头部和耳部主要特征量(两耳屏间宽、耳甲腔高度、耳甲腔宽度、耳甲腔深度、耳前后偏转角、耳凸起角),同时提出了一个反映耳廓整体形态的斐波那契偏离度。
具体而言,采用公式(1)计算斐波那契偏离度:
公式(1)中的34和55分别是斐波那契数列(fibonaccisequence)的第九项和第十项。人耳整体上呈现为一个斐波那契偏离度螺旋线(即黄金螺旋线),它可以通过一个斐波那契数列构造,其中第九项和第十项的比例对应耳廓最大宽和耳廓最大长的比例。斐波那契偏离度可以表征真人耳廓整体上相对于理想的斐波那契偏离度螺旋线的偏离程度,而与耳廓的绝对尺寸无关。
步骤3、将生理特征值输入听觉评估神经网络,预测听觉分数;
具体而言,步骤3中听觉评估神经网络的输入是用户的m个生理特征值,输出是用户对n类hrtf数据的听觉分数。
具体而言,步骤3中听觉评估神经网络已事先构造和训练完毕,训练步骤包括:
1、选取一个已知的hrtf数据库,包括n名受试者的多个空间方向的hrtf数据(即n类hrtf数据);
理论上,n越大越好;实际应用中,综合考虑可用的hrtf数据库以及后续听音者的听觉实验工作量,n一般取30~100之间。
目前国际上已有多个公开的hrtf数据库,例如美国cipichrtf数据库、奥地利arihrtf数据库等。
2、选取k个听音者,采用3d扫描的方式获取听音者头部的3d模型。进一步,利用软件从3d模型中提取hrtf相关的m个生理特征值,进行离差标准化,获得m×k的生理特征值矩阵p=[pm,k](m=1,2,…,m;k=1,2,…,k);
3、采用n类hrtf数据制作虚拟声信号,用k个听音者进行虚拟声的听觉实验,得到n×k的听觉分数矩阵s=[sn,k](n=1,2,…,n;k=1,2,…,k),其中
(2)式中an,k表示第k个听音者对第n类hrtf虚拟声信号的头中率,bn,k表示第k个听音者对第n类hrtf虚拟声信号的前后混乱率,cn,k表示第k个听音者对第n类hrtf虚拟声信号的仰角定位准确率;
为了获取上述三个听觉效果指标(头中率、前后混乱率、仰角定位准确率),听音实验中虚拟声像的方位(水平角θ,仰角
4、构造一个广义回归神经网络,生理特征值作为网络输入,听觉分数作为网络输出,上述{p=[pm,k],s=[sn,k]}构成训练集。采用留一法确定网络的平滑因子。
5、保存训练好的神经网络模型。
具体而言,步骤2和步骤3中所述的涉及双耳的生理特征值,都是先分别对双耳提取特征值,然后再取平均值。
步骤4、从hrtf数据库中挑选出最高听觉分数所对应的hrtf数据,作为用户听觉匹配的hrtf数据;
图2是用户听觉匹配hrtf获取的具体流程图,涵盖步骤3和步骤4。图2中,如果有多类hrtf数据都对应最高听觉分数,则根据应用场景的需求,按照公式(2)中的三个听觉指标(头中率、前后混乱率、仰角定位准确率)再进行排序,直至可以唯一确定听觉匹配的hrtf类别。
步骤5、将原始单通路信号、听觉匹配hrtf数据、房间脉冲响应依次进行时间域卷积处理或等价地频率域滤波处理,得到用户定制的双耳虚拟声信号;
房间脉冲响应用来模拟特定的室内效果,例如音乐厅、报告厅、餐厅等。如果不计房间脉冲响应,则最终合成的是自由场(即不含反射声)双耳虚拟声信号。
步骤6、采用耳机播放双耳虚拟声信号。
如图3所示,一种用于实现所述方法的装置,包括:
3d头模获取模块,用于采集用户头面部的3d结构信息;
运算控制模块,用于从已知hrtf数据库中,依据神经网络根据用户生理特征值所预测的听觉分数,找出用户听觉匹配的hrtf数据进行虚拟声合成;
虚拟声播放模块,由声卡和耳机组成,用于播放合成的虚拟声信号。
其中,所述的运算控制模块包括:
生理特征值提取模块,用于从3d头模中提取出m个生理特征值,包括两耳屏间宽、耳甲腔高度、耳甲腔宽度、耳甲腔深度、耳前后偏转角、耳凸起角和斐波那契偏离度等;
hrtf听觉匹配模块,将用户生理特征值输入事先训练好的听觉评估神经网络,预测用户对n类hrtf的听觉分数;从hrtf数据库中挑选出最高听觉分数所对应的hrtf数据,作为用户听觉匹配的hrtf数据;
虚拟声信号合成模块,用于将原始单通路信号、听觉匹配hrtf数据、房间脉冲响应依次进行时间域卷积处理或等价地频率域滤波处理,合成得到特定声场景下的双耳虚拟声信号,输出到耳机进行重放。
其中,3d头模获取模块可以采用移动终端的3d传感装置直接获取(例如oppofindx智能手机、vivonex智能手机),也可以通过移动终端拍摄的2d图像的3d重构间接获取(例如qlone、altizure)。上述方式获取的3d头模可以在移动终端进行后续处理,也可以导入个人多媒体计算机进行后续处理。如果后续的运算控制模块采用个人多媒体计算机实现,其中的三个模块(生理特征值提取模块、hrtf听觉匹配模块、虚拟声信号合成模块)可以采用matlab、c++或者python语言编程。运算控制模块也可以设计成专用的集成电路芯片实现,还可以利用通用信号处理芯片所做成的硬件电路实现,应用于各种手持移动终端。
本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!