一种基于端信息扩展序列与随机森林模型的身份认证方法与流程
本发明涉及一种基于端信息扩展序列与随机森林模型的身份认证方法,旨在实现复杂网络环境下合法用户的身份认证,属于网络安全技术领域。
背景技术:
端信息扩展是指将通信内容或合法身份信息通过端信息扩展算法进行转换,用多项端信息组成序列的方式表示一条信息,各项端信息与所传递的信息本身无关。客户端利用端信息扩展序列所具有的隐蔽性与抗分析能力,将通信内容或者合法身份认证信息通过端信息扩展算法进行调制,从而实现将通信内容或合法身份认证信息隐藏在端信息扩展序列中并发送至复杂网络。服务器监听网络数据流并识别出可信客户端发送的端信息扩展序列,通过对识别出的端信息扩展序列进行解调,获得客户端发送的通信内容或实现合法客户端的身份认证。
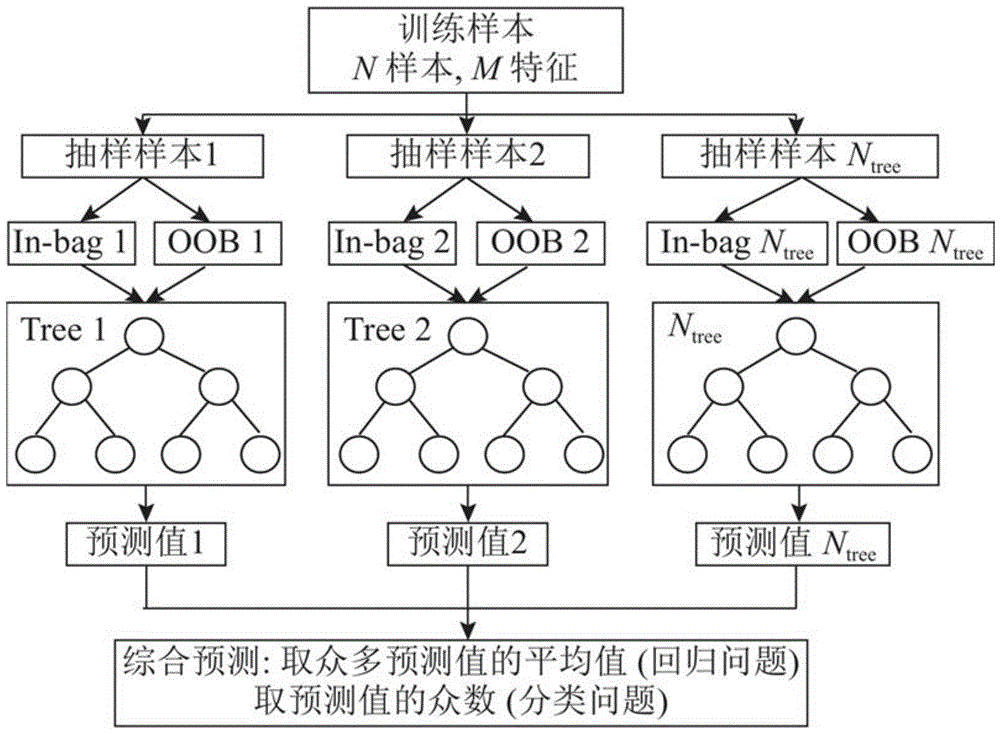
随机森林作为新兴起的、高度灵活的一种机器学习算法,即使没有超参数调整,大多数情况下也会带来好的结果,可以用来执行分类和回归任务,拥有广泛的应用前景。随机森林是一种集成算法(ensemblelearning),通过组合多个弱分类器,最终结果通过投票或取均值,使得整体模型的结果具有较高的精确度和泛化性能。随机森林能够处理高维特征数据集,对数据集的适应能力强,既能处理离散型数据,也能处理连续型数据。由于每棵树可以独立、同时生成,容易做成并行化方法,具有很快的学习速度。
认证技术是当今网络空间信息安全第一技术,使用安全可靠的身份认证技术对保证系统服务的正常运行具有重要意义。现有基于端信息扩展序列的安全通信系统中,客户端产生的端信息扩展序列抗分析能力弱且自相关性差,服务器端的身份认证方法过度依赖网络数据流特征且无法对各合法用户进行个性化识别与解调。为充分利用端信息扩展序列的自相关性,提高服务器端的个性化解调能力,本发明基于随机森林模型,使用各合法用户产生的端信息扩展序列作为数据集进行学习训练,将训练好的随机森林模型对客户端发送的端信息扩展序列进行分类,从而实现合法用户的身份认证。本发明充分发挥了端信息扩展序列抗分析能力的优势,利用网络数据流特征对合法客户端进行建模分析,大大提高端信息扩展序列的抗截获与抗分析能力,使端信息扩展序列更好地适用于复杂网络环境,为基于端信息扩展序列的安全通信系统提供身份认证新思路。
技术实现要素:
为了充分利用端信息扩展序列的自相关性,本发明基于随机森林模型,使用各合法用户产生的端信息扩展序列作为数据集进行学习训练,将训练好的随机森林模型对客户端发送的端信息扩展序列进行分类,从而实现合法用户的身份认证。本发明使用的训练集特征包括ip数据包头部中的标志位(记作ipid)、源端口号(记作srcport)、源ip(记作srcip)、目的端口号(记作dstport)、目的ip(记作dstip)。随机森林模型在训练学习过程中需要对各特征做重要性评估,筛选出重要性较高的特征,提高样本的预测效果,本发明重要性较高的特征为ipid与srcport。本发明为基于端信息扩展序列的安全通信系统提供了身份认证新思路,其特征在于以下步骤:
(1)客户端输入基因函数f(x);
(2)端信息扩展序列生成算法基于f(x)生成自相关性良好的端信息ipid、srcport等;
(3)将(2)中生成的端信息ipid、srcport等加载到套接字数据包中,从而得到端信息扩展序列{extendseq1,extendseq2,……,extendseqn},使用socket套接字发送到网络环境中;
(4)服务器端采用随机森林模型对各合法客户端生成的端信息扩展序列组成的数据集进行训练学习,得到随机森林模型rf-model;
(5)服务器端监听网络环境中的客户端发出的端信息扩展序列{extendseq1,extendseq2,……,extendseqn},提取出数据包中的端信息添加至测试集中;
(6)将(5)中得到的测试集输入(4)中得到的随机森林模型rf-model中进行分类;
(7)分析(6)中的分类结果,得出请求身份认证的合法客户端并提供个性化服务;
本发明使用端信息ipid、srcport、srcip、dstport、dstip作为数据集特征,其中ipid与srcport作为主要特征,由于这两种端信息的随机性与隐蔽性,使得端信息扩展序列组成的网络数据流不易被攻击者提取主要特征,增大了攻击者分析网络数据流的难度。本发明基于各合法用户所特有的基因函数生成端信息扩展序列,使得端信息扩展序列间具有良好的自相关性,本发明充分利用端信息扩展序列间所具有的相关性,基于随机森林模型对端信息扩展序列进行特征提取,从而大大提高认证精度。随机森林模型具有分类精度高、学习速度快的特点,能够在提高认证精度的同时,还能提高合法用户的身份认证效率。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面结合附图与具体实施方案对本发明做进一步说明:
图1随机森林模型示意图。
图2基于端信息扩展序列与随机森林模型的身份认证流程图。
具体实施方式
为使本发明的目的、技术、优点更清晰,下面结合附图对本发明作进一步详细、完整的描述。
步骤(1):客户端输入基因函数f(x);
所述步骤(1)中,客户端输入基因函数f(x),需要f(x)具有较好的自相关性,从而保证各合法用户生成的端信息扩展序列间保持良好的自相关性。
步骤(2):端信息扩展序列生成算法基于f(x)生成自相关性良好的端信息ipid、srcport等;
步骤(3):将步骤(2)中生成的端信息ipid、srcport等加载到套接字数据包中,从而得到端信息扩展序列{extendseq1,extendseq2,……,extendseqn},使用socket套接字发送到网络环境中;
步骤(4):服务器端采用随机森林模型对各合法客户端生成的端信息扩展序列组成的数据集进行训练学习,得到随机森林模型rf-model;
所述步骤(4)中,服务器端采用随机森林模型对各合法客户端生成的端信息扩展序列组成的数据集进行训练学习,需要服务器端根据各合法客户端所持有的基因函数生成带有标记的数据集,随后将数据集输入随机森林模型中进行有监督学习,从而得到随机森林模型rf-model。
步骤(5):服务器端监听网络环境中的客户端发出的端信息扩展序列{extendseq1,extendseq2,……,extendseqn},提取出数据包中的端信息添加至测试集中;
步骤(6):将步骤(5)中得到的测试集输入步骤(4)中得到的随机森林模型rf-model中进行分类;
步骤(7):分析步骤(6)中的分类结果,得出请求身份认证的合法客户端并提供个性化服务;
所述步骤(7)中,分析步骤(6)中的分类结果,需要在分类结果中出现频率最高的合法客户端作为最终的身份认证结果。
本发明使用端信息ipid、srcport、srcip、dstport、dstip作为数据集特征,其中ipid与srcport作为主要特征,由于这两种端信息的随机性与隐蔽性,使得端信息扩展序列组成的网络数据流不易被攻击者提取主要特征,增大了攻击者分析网络数据流的难度。本发明基于各合法用户所特有的基因函数生成端信息扩展序列,使得端信息扩展序列间具有良好的自相关性,本发明充分利用端信息扩展序列间所具有的相关性,基于随机森林模型对端信息扩展序列进行特征提取,从而大大提高认证精度。随机森林模型具有分类精度高、学习速度快的特点,能够在提高认证精度的同时,还能提高合法用户的身份认证效率。
- 还没有人留言评论。精彩留言会获得点赞!