一种自动跟随的音视频采集系统和方法与流程
本发明涉及一种自动跟随的音视频采集系统和方法,特别涉及一种自动跟随的音视频采集系统和方法。
背景技术:
现有的自动跟随机器人通常是基于gps、蓝牙以及视觉识别等跟随方案之一进行跟随并在一个固定角度拍摄,跟随易受环境影响。同时传统的视频采集过程仅仅是通过视觉识别实现对图像的粗采集,被采集的目标位置、角度可能是不准确或者不合适的,感兴趣的目标往往会出现在图像的边角位置,成像品质较差。在动态拍摄过程中,需要考虑到拍摄角度、高度和焦距等参数,才能呈现最佳的拍摄效果。
技术实现要素:
本发明其中一个目的在于提供一种自动跟随的音视频采集系统和方法,所述自动跟随的音视频采集系统和方法能够在复杂环境下自动跟随被拍摄人,从多角度、多位置进行拍摄,自动选择拍摄角度、高度和焦距等参数,呈现最佳的拍摄效果。所述自动跟随的音视频采集系统还能实现人群环绕拍摄和自拍。
本发明其中一个目的在于提供一种自动跟随的音视频采集系统和方法,所述自动跟随的音视频采集系统和方法通过rtk定位、视觉定位以及射频定位多种定位方式相互配合,先通过rtk、射频定位对目标粗定位,进而采用视觉识别定位对目标精定位,分级多重定位方式可提高定位系统的鲁棒性,在rtk信号较弱并且目标不在图像采集器的视野中时,图像采集器根据射频信号实现方向调整,需要说明的是,通过射频信号采集的方向位置信息无需借助附近基站即可实现方向定位,实用性能更好。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述自动跟随的音视频采集系统和方法对同一目标的两个或两个以上不同区域或图像特征之间建立关联关系的数据模型,本发明中举例人脸和人体特征说明,并可选择地根据其中一个便于识别的图像特征进行定位跟踪,藉此,可解决拍摄过程中选定图像特征移速或转动角度过快导致图像定位跟踪失败或无法识别的风险。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述系统和方法首先通过rtk对目标进行精定位,以获取目标绝对位置,若目标在精定位过程中出现故障或环境影响rtk定位功能时,所述系统和方法可迅速切换通过人体或特定图像特征识别以实现粗定位,并通过视觉识别系统进一步对目标实现精定位,在极端环境中部分定位元件或模块功能丧失情况下,可由其他元件替代完成。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述系统和方法能在对图像采集的过程中,通过算法调整云台高度和角度,使得目标在拍摄采集的过程中处于中心部位,以采集高质量的图像信息。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述系统和方法能在对图像采集的过程中,通过算法调整摄像机的焦距,使得目标在拍摄采集的过程中保持合适的大小,以采集高质量的图像信息。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述系统和方法采用多种方式对目标进行粗定位,并根据粗定位信息对图像以人脸识别或特定人物识别的方式实现精定位,并根据精定位所获取的图像信息进行视觉跟踪,用于预测目标的走向。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述系统和方法采用红外、超声波以及视觉感知中的任意一种或多种方式执行避障。
本发明另一个目的在于提供一种自动跟随的音视频采集系统和方法,所述系统和方法可实现自拍和对人群的环拍工作,在拍摄开始和结束时,对机器人自身进行自拍,可用于检测和了解机器人自身外形状况。当视野内出现人群信息时,可用于人群的识别跟踪和环绕拍摄,以及识别群体性事件。
为了实现上述至少一个发明目的,本发明进一步提供一种自动跟随的音视频采集系统,包括:
控制模块;
跟踪定位模块;
音视频采集模块;
运动模块;
拍摄角度调整模块;
其中所述跟踪定位模块包括rtk(载波相位差分技术)模块,射频定位模块和视觉定位模块,所述控制模块通讯连接所述跟踪定位模块、音视频采集模块、运动模块和拍摄角度调整模块,所述音视频采集模块包括图像采集装置和音频采集装置,所述控制模块驱动所述运动模块跟随目标采集音视频信息。
根据本发明另一个较佳实施例,所述跟踪定位模块进一步包括一避障模块,所述避障模块包括红外避障模块、超声避障模块和视觉避障模块中至少一种,所述控制模块接收红外感应信息、超声感应信息以及视觉感应信息中的至少一种,用于驱动所述运动模块做避障运动。
根据本发明另一个较佳实施例,所述拍摄角度调整模块包括一云台,所述云台通讯连接所述控制模块,所述控制模块根据音视频采集模块所获取的目标信息以控制云台升降或旋转。
根据本发明另一个较佳实施例,所述跟踪定位模块通过rtk模块和/或射频定位模块对目标粗定位,之后通过所述视觉定位模块对目标精定位。
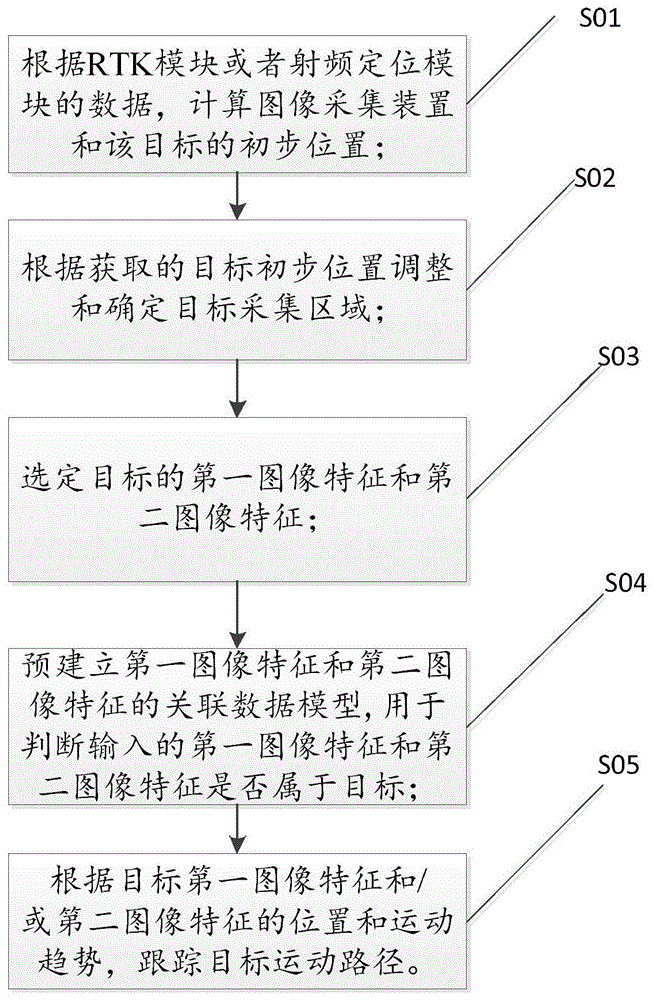
为了实现上述至少一个发明目的,本发明进一步提供一种自动跟随的音视频采集方法,其特征在于,包括如下步骤:
s01:根据rtk模块或者射频定位模块的数据,计算图像采集装置和目标的初步位置;
s02:根据获取的目标初步位置调整和确定目标采集区域;
s03:选定目标的第一图像特征和第二图像特征;
s04:预建立第一图像特征和第二图像特征的关联数据模型,用于判断输入的第一图像特征和第二图像特征是否属于目标;
s05:根据目标第一图像特征和/或第二图像特征的位置和运动趋势,跟踪目标运动路径。
根据本发明另一个较佳实施例,所述s01步骤包括:通过rtk模块获取目标的初步位置,初步位置包括:目标相对于图像采集装置的距离和角度。
根据本发明另一个较佳实施例,所述s01步骤还包括:通过射频定位模块获取目标的初步位置,初步位置包括:目标相对于图像采集装置的距离和角度。
根据本发明另一个较佳实施例,在上述s03步骤中进一步包括,s031:获取目标第一图像特征或第二图像特征的中心位置,并且根据中心位置调整图像采集视野,以使得所述目标第一图像特征或第二图像特征处于图像采集视野中心区域。
根据本发明另一个较佳实施例,s031步骤包括如下步骤:
对目标拍摄,并获取目标相对于图像采集装置的角度和距离;
当目标保持静态时,若获取到目标第一图像特征或第二图像特征的侧面特征,则控制所述运动模块移动至所述目标正面,用于获取第一图像特征或第二图像特征的正面特征;
根据目标第一图像特征或第二图像特征获取最佳目标拍摄角度、高度和焦距。
根据本发明另一个较佳实施例,通过云台调整目标位于视野中部,方法如下:设定图像左上角为拍摄视野原点,当前图像的宽高分别为w,h。设目标的第一图像特征或第二图像特征位置为(xf,yf),若yf<h/2并且|yf-h/2|>ht,ht为预先设置的高度阈值,则云台上升直到|yf-h/2|<=ht;如果yf>h/2并且|yf-h/2|>ht,则云台下降直到|yf-h/2|<=ht;若xf<w/2并且|xf-w/2|>wt,wt为预先设置的宽度阈值,则云台向左旋转直到|xf-w/2|<=wt;如果xf>w/2并且|xf-w/2|>wt,则云台向右旋转直到|xf-w/2|<=wt。
根据本发明另一个较佳实施例,通过调整相机焦距,使目标在视野中保持合适的大小,方法如下:设定图像左上角为拍摄视野原点,当前图像的宽高分别为w,h;设目标的第一图像特征或第二图像特征的宽和高为分别为wh,hh;若wh/w<σ并且|wh/w-σ|>σt,σ、σt为预先设置的比例阈值,则焦距变长直到|wh/w-σ|<=σt;若wh/w>σ并且|wh/w-σ|>σt,则焦距变短直到|wh/w-σ|<=σt。
根据本发明另一个较佳实施例,在上述s04步骤中,包括:通过深度学习技术和卷积神经网络对第一图像特征和第二图像特征的特征矢量建立具有映射关系的关联数据模型;
通过向关联数据模型中输入待测的第一图像特征和第二图像特征,以判别是否属于目标的第一图像特征和第二图像特征,若否,继续输入待测第一图像特征和第二图像特征,若是,则提取该测量的目标的位置信息用于图像精定位和跟踪。
优选地,在上述s05步骤中,在获取的每一帧图像识别目标后对目标进行预测和跟踪,包括如下步骤:
s051:根据提取的目标的第一图像特征信息作为跟踪模板t0;
s052:通过kalman滤波或者粒子滤波预测目标运动趋势;
s053:根据置信度图像cm判断目标的是否跟踪成功;
其中置信度函数的获取方法如下:
选定一检测区域c,使用在imagenet视频数据集上预训练的siamesenetwork作为特征提取器
其中*表示卷积,b为cm在每个位置处的偏置系数;
设定置信度图阈值vt,vmax是测量的置信度图最大值,当vmax>vt时,则跟踪成功,vmax为新的第一图像特征位置v(x,y),若vmax<vt则,根据kalman滤波或者粒子滤波预测新的v(x,y)的位置;
s054:设定一预测时长阈值tmax,若预测时长tp>tmax,则重新获取目标的初步位置信息,若tp<tmax,则持续预测每一帧目标。
根据本发明另一个较佳实施例,在上述s054步骤中,若vmax>vt,tp=0,若vmax<vt,则tp=tp+1,其中,tp为预测时长。当预测时长tp>tmax时,射频定位模块和/或rtk模块重新获取目标初步位置信息。
根据本发明另一个较佳实施例,在上述s04步骤中,选定一检测区域,将检测区域中每一帧图像都投入关联数据模型,若检测到第二图像特征,则根据关联数据模型获取最大关联度的第一图像特征,提取该第一图像特征,并获取该目标的位置信息,用于图像跟踪。
根据本发明另一个较佳实施例,在上述s04步骤中,选定一检测区域,将检测区域中每一帧图像都投入关联数据模型,若未检测到第二图像特征,通过图像采集装置获取第一图像特征,并将第一图像特征输入关联数据模型,获取该目标的位置信息;
若在s04步骤中无法识别和获取第一图像特征,则重新执行s01-s03步骤。
根据本发明另一个较佳实施例,在上述s04步骤中,所述第一图像特征被设置为人体图像,第二图像特征被设置为人脸图像。
根据本发明另一个较佳实施例,设定拍摄距离高值和低值,根据所述射频定位模块或rtk模块探测获取目标对应于图像采集装置的距离用于和目标保持合理距离。
为了实现上述至少一个发明目的,本发明进一步提供一种自拍和环拍方法,所述方法采用所述自动跟随的音视频采集系统,用于机器人自拍和对人群环拍,包括以下步骤:
当机器人拍摄开始或结束时,通过云台控制图像采集装置升降或转动,并使得机器人本体落入拍摄视野。
根据本发明另一个较佳实施例,对人群进行聚类分析,包括如下步骤:
检测采集视野中人体位置和特征;
根据采集的人体位置和特征信息进行人群聚类分析;
对每一聚类人群环拍,以采集每一聚类人群特征。
根据本发明另一个较佳实施例,采用kmeans方法对人群进行聚类,获取若干个类簇si(x,y,count),其中坐标(x,y)是类簇si的中心,count是类簇中的元素个数,ct为预先设置的人群个数阈值,若count>ct,则认为坐标(x,y)处出现了人群。
附图说明
图1显示的是本发明一种自动跟随的音视频采集方法的流程示意图;
图2显示的是本发明一种自动跟随的音视频采集方法的目标预测和跟踪步骤示意图;
图3显示的是本发明一种自动跟随的音视频采集方法的置信度图cm的公式图。
具体实施方式
以下描述用于揭露本发明以使本领域技术人员能够实现本发明。以下描述中的优选实施例只作为举例,本领域技术人员可以想到其他显而易见的变型。在以下描述中界定的本发发明的基本原理可以应用于其他实施方案、变形方案、改进方案、等同方案以及没有背离本发明的精神和范围的其他技术方案。
本领域技术人员应理解的是,在本发明的揭露中,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系是基于附图所示的方位或位置关系,其仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此上述术语不能理解为对本发明的限制。
可以理解的是,术语“一”应理解为“至少一”或“一个或多个”,即在一个实施例中,一个元件的数量可以为一个,而在另外的实施例中,该元件的数量可以为多个,术语“一”不能理解为对数量的限制。
请看考图1-3,自动跟随的音视频采集系统包括一控制模块、一音视频采集模块、一运动模块、跟踪定位模块和拍摄角度调整模块,其中所述控制模块通讯连接所述音视频采集模块、运动模块跟踪定位模块和拍摄角度调整模块,其中所述控制模块被设置为一控制芯片或计算机以及相应控制程序,所述音视频采集模块包括音频采集装置和图像采集装置,具体地,所述音频采集装置被优选实施为一麦克风,并电性或通讯连接所述控制模块,所述图像采集装置被优选实施为一摄像头,通过摄像头捕获图像信息用于所述控制模块分析处理,所述拍摄角度调整模块包括云台,所述云台通讯连接所述控制模块,用于调整所述图像采集装置的拍摄角度。
需要说明的是,在本发明中,所述运动模块被设置于一可移动机器人,所述可移动机器人包括但不仅限于轮式机器人、步进式机器人和飞行机器人,其中所述可移动机器人载有图像采集装置以及相应的传感器,用于拍摄动态目标,可以理解的是,本发明所提到的机器人中运动模块的运动形式不是本发明的限制。
值得一提的是,所述跟踪定位模块包括一rtk(载波相位差分技术)模块、一射频定位模块和一视觉定位模块,其中所述rtk模块采用卫星或基站定位,在一实施场景中,若所述自动跟随的音视频采集系统处于通讯良好的环境中,可直接通过rtk模块获取目标的绝对位置,其中该绝对位置可以根据为经纬度或根据两基站接收信号的时间差获得的目标绝对位置。换句话说,目标设置一跟踪装置,所述跟踪装置包括但不仅于手机等具有通讯功能的定位元件,通过定位元件和卫星或基站通讯通过时间差可获取目标的绝对位置,以供所述自动跟随的音视频采集系统定位,进一步地,获取的目标绝对位置发送至所述控制模块,以供所述控制模块分析并获取所述目标相对于机器人本体图像采集装置的相对位置,所述控制模块被优选设置于机器人本体,进一步地,当所述控制模块获取目标相对于所述机器人的相对位置时,所述控制模块通过控制运动模块调整机器人运动方向、距离以及速度等靠近目标,并控制所述跟踪定位模块和角度调整模块对目标的拍摄的角度和距离,用于定位和跟踪拍摄。
在本发明一较佳实施例中,目标设置一射频标签,所述机器人本体设有对应的射频信号接收器,在获取目标的相对位置后,可直接通过射频定位模块获取目标相对于图像设备的相对位置。
在本发明一个较佳实施例中,提供一种利用射频定位方法获取目标的和图像采集装置之间的相对位置,其中射频定位方法采用如下公式求解:
其中(x,y)是射频标签坐标,该射频标签被放置于目标上,di,dj为基站i,j到标签的距离,其中(xi,yi),(xj,yj)是基站i,j的坐标。联立求解不同i,j组合的方程组可以得到(x,y)的值。将(x,y)的序列值经过kalman滤波进行时序预测,得到(x’,y’)为标签的绝对坐标。根据(x’,y’)和机器人当前的位置(xr,yr),即可计算得到二者的相对位置和角度。
因此,在一场景中,若所述自动跟随的音视频采集系统处于gps信号较差的野外环境时,无法通过rtk模块获取目标的绝对位置,可根据本发明中的射频定位模块获取所述目标相对于图像采集装置的相对位置,进而可驱动所述运动模块沿着预定或探测路线趋近所述目标,所述射频定位模块中,射频标签为有源标签或无源标签中的任意一种。
所述跟踪定位模块对所述目标采用粗定位和精定位相结合的方式以实现对目标的定位和跟踪,其中所述粗定位方法包括:
s01:根据rtk模块或者射频定位模块的数据,计算图像采集装置和该目标的初步位置;
在s01步骤中,目标位置信息可以是绝对位置信息或相对位置信息,具体可根据gps信号是否优良确定,本发明前面已阐述,对此不再赘述。根据该绝对位置或相对位置信息计算图像采集装置和该目标的初步位置,其中该初步位置包括目标对于图像采集装置的距离和角度。
对目标粗定位后,进一步对目标进行精定位,其中对目标精定位的方法包括如下步骤:
预先建立第一图像特征和第二图像特征的关联数据模型,并且通过深度学习和卷积神经网络对该数据模型进行训练,其中深度学习和卷积神经网络所涉及到的算法皆可用现有技术实现,本发明不再赘述。所述运动模块带动所述音视频采集模块趋近所述目标时,通过测定目标的第一图像特征和第二图像特征,用于区分待测定目标的身份信息,具体包括如下步骤:
通过所述图像采集装置采集待测目标第一和第二图像特征,将所述待测第一和第二图像特征输入经过数据训练的关联数据模型进行匹配;
分别计算待测目标第一和第二图像特征的特征向量,并将所述第一和第二图像特征向量投入到所述关联数据模型,分别计算第一和第二图像特征向量的欧式距离或余弦距离,以获取第一图像特征和第二图像特征的关联度。
当所述待测第一图像特征和第二图像特征匹配的关联度高于设定阈值时,表示该待测图像为目标,进一步保存该目标的位置信息、第一图像特征以及第二图像特征,用于该目标精定位和图像追踪。
为了更好地理解本发明,本发明以人为目标作为一个较佳实施例举例说明:
通过深度学习训练人脸识别模型和人体再识别模型,以建立人脸特征和人体特征关联数据模型,用于识别人脸特征和人体特征,并用于待测人脸和人体的匹配,其中所述人脸识别模型可选择使用包括但不仅限于facenet、deepface模型,人体再识别模型可选择使用包括但不仅限于pcb模型,通过深度学习后获取的关联数据模型在可识别人体特征和人脸特征的功能基础上,可进一步确定人脸特征和人体特征之间的关联度,其中对该人脸特征和人体特征关联度设定一阈值,当待测的人脸特征和人体特征输入所述关联数据模型时,若关联度大于该阈值时,则判定人脸特征和人体特征属于同一关系,并将该人体特征和人脸特征作为精定位目标,需要说明的是,对于关联度阈值是基于人脸特征和人体特征的特征矢量计算获得,深度学习神经网络可计算获得人体特征和人脸特征的特征矢量,通过数据训练可获得人体特征和人脸特征之间的关联数据模型,其中深度学习处理人脸识别模型和人体再识别模型皆是现有技术,对此本发明不再进一步说明。
选定目标,所述目标特征包括目标人脸特征和人体特征,用于对目标人脸和人体的精定位和跟踪,其中对目标的确定方式包括但不仅限于文字/语音输入查询数据库中的目标,或通过图像采集装置采集目标的人脸特征和人体特征并保存于数据库中,并将采集的目标作为精定位和跟踪目标,本领域技术人员可以理解的是,目标的输入和获取方式不是本发明的限制。
确定拍摄视野中的目标,当拍摄视野中存在待测人体特征或人脸特征时,通过图像采集装置识别并获取待测图像,并将待测的人脸特征和人体特征输入关联数据模型,当待测人脸特征和人体特征匹配度高于预设的阈值时,则确定待测图像为目标,获取该目标位置信息,并对该目标持续进行精定位和追踪,在本发明另一可行实施例中,若获取到待测图像的人脸特征时,可通过人脸识别模型识别目标,通过关联其人体特征,获取目标位置信息,通过视觉定位模块持续定位目标,其中所述人体特征包括人体形态特征、姿态特征以及运动特征等。
当目标处于拍摄视野内时,本发明进一步提供目标的跟踪预测方法,其中跟踪预测方法以人脸和人体图像举例说明:
提取首次精定位获取的目标的人体图像和位置信息;
将首次精定位获取的人体位置信息保存作为跟踪模板t0;
初始化跟踪器,其中所述跟踪器的预测模块优先采用kalman滤波或者粒子滤波;
选取一预测区域c,通过神经网络计算预测区域c相对于跟踪模板t0的置信度图cm;
设定一置信度阈值vt,定义vmax为置信度图cm中最大值,若vmax>vt,表示跟踪成功,则vmax值所对应的位置v(x,y)为新位置信息,同时根据新的人体位置信息更新模板t,若vmax<vt,则根据kalman滤波或者粒子滤波预测新的位置v(x,y)。
在一较佳实施例中,置信度图获取方法为:
使用在imagenet视频数据集上预训练的siamesenetwork作为特征提取器
其中*表示卷积,b为cm在每个位置处的偏置系数。
进一步地,在拍摄过程中,还包括从目标对象的跟踪状态到目标粗定位步骤,具体包括如下步骤:
定义一实际预测时长tp,初始值为0,同时定义预测时长阈值tmax。在预测过程中若vmax>vt,tp=0,若vmax<vt,则tp=tp+1,其中,tp为预测时长。当预测时长tp>tmax时,表示跟踪失败,所述跟踪定位模块重新对目标进行粗定位。需要说明的是,在上述追踪定位过程中,粗定位到精定位和图像追踪的过程可重复执行。
在图像精定位的过程中,若图像采集装置的视野中只有有目标人脸特征,则通过yolo等人体检测方法对待测目标人脸特征匹配目标人体特征,并输出关联度最大的人体特征作为目标人体图像,用于目标精定位和跟踪。若图像采集装置视野中只有目标人体图像,则采用人体再识别模型识别目标人体相对于图像采集装置的位置关系。
进一步地,本发明进一步提供一种人正脸跟踪方法,若所述图像采集装置采集到人脸侧面图像信息,所述人脸识别模块计算获得目标人脸图像相对于图像采集装置视野的偏转角度,其中可根据deepgaze库中的头部姿态估计方法计算得到头部的俯仰角pitch、偏航角yaw和翻滚角roll。所述控制模块预设头部偏航角阈值,当控制模块采集到图像中头部偏航角小于该阈值时,可判定该图像包括目标人的正脸图像,其中正脸视角可作为本发明最佳拍摄视角,所述控制模块可根据头部偏航角控制所述运动模块、跟踪定位模块、拍摄角度调整模块以获取最佳拍摄角度。
需要说明的是,所述控制模块控制所述避障模块按照预定路线或实时探测路线移动,为了更好地规划运动路线,本发明优选采用实时探测路线对目标人脸图像的跟踪拍摄,具体地,所述避障模块包括红外避障装置、超声避障装置和视觉避障装置中的至少一种,用于路线实时探测和规划。
所述红外避障装置的实时探测避障方法为:红外避障装置以一角度发射一红外探测光束,探测光束可被接收器接收,以探测路径方向是否有障碍物。
所述超声避障装置向路径方向发射超声波,并且通过超声波接收的时间差探测路径方向上的障碍物以及和该障碍物之间的距离。
所述视觉避障采用对路径上的图像进行分析,获取障碍物的大小和距离,从而可通过控制模块驱动运动模块对障碍物先进行绕行,然后计算目标和图像采集装置之间的最短路径,藉此可大幅提高跟随效率。
为了保持目标的脸部特征处于采集视野中部,本发明进一步提供一种人脸图像拍摄调整方法:
设定图像左上角为拍摄视野原点,当前图像的宽高分别为w,h。设目标的第一图像特征或第二图像特征位置为(xf,yf),若yf<h/2并且|yf-h/2|>ht,ht为预先设置的高度阈值,则云台上升直到|yf-h/2|<=ht;如果yf>h/2并且|yf-h/2|>ht,则云台下降直到|yf-h/2|<=ht;若xf<w/2并且|xf-w/2|>wt,wt为预先设置的宽度阈值,则云台向左旋转直到|xf-w/2|<=wt;如果xf>w/2并且|xf-w/2|>wt,则云台向右旋转直到|xf-w/2|<=wt,所述人脸图像拍摄调整方式需要在对人脸和人体精定位后执行该方法。
为了使目标在拍摄视野中保持合适的大小,本发明进一步提供一种相机焦距调整方法:
设定图像左上角为拍摄视野原点,当前图像的宽高分别为w,h;设目标的第一图像特征或第二图像特征的宽高分别为wh,hh,若wh/w<σ并且|wh/w-σ|>σt,σ、σt为预先设置的比例阈值,则焦距变长直到|wh/w-σ|<=σt;若wh/w>σ并且|wh/w-σ|>σt,则焦距变短直到|wh/w-σ|<=σt,所述人脸图像拍摄调整方式需要在对人脸和人体精定位后执行该方法。
为了采集更丰富多元的图像信息,本发明进一步提供一种自拍方法和人群环拍方法,其中自拍方法用于机器人自拍,环拍可用于特定人群的识别分析以及环绕拍摄,其中自拍方法包括如下步骤:
当机器人拍摄开始或结束时,通过云台控制图像采集装置升降或转动,并使得机器人本体落入拍摄视野。
人群环拍方法包括如下步骤:
检测采集视野中人体位置和特征;
根据采集的人体位置和特征信息进行人群聚类分析;
对每一聚类人群环拍,以采集每一聚类人群特征。
采用yolo算法获取视野中人体位置信息,并采用kmeans方法对人群进行聚类,聚类方法包括:获取若干个类簇si(x,y,count),其中坐标(x,y)是类簇si的中心,count是类簇中的元素个数,ct为预先设置的人群个数阈值,若count>ct,则认为坐标(x,y)处出现了人群。
当视野中识别为人群时,所述机器人控制所述控制模块驱动所述运动模块、跟踪定位模块、以及角度拍摄模块对人群进行环绕拍摄,并且可根据人群中人脸特征,体形特征以及运动特征进一步对人群分析,需要说明的是上述人脸特征、体型特征以及运动特征可使用本发明所述的yolo、facenet、deepface、pcb等现有分析模型实现,本领域技术人员可以理解的是,分析模型的种类不是本发明的限制。
需要说明的是本发明中第一图像特征和第二图像特征可根据目标选择而更改,比如为了获取目标手掌特征,可设定第二图像特征为手掌特征,第一图像特征为人体或人脸图像,可以理解的是本发明中人脸和人体仅仅作为举例说明而不是本发明限制。
特别地,根据本公开的实施例,上文参考流程图描述的过程可以被实现为计算机软件程序。例如,本公开的实施例包括一种计算机程序产品,其包括承载在计算机可读介质上的计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。在这样的实施例中,该计算机程序可以通过通信部分从网络上被下载和安装,和/或从可拆卸介质被安装。在该计算机程序被中央处理单元(cpu)执行时,执行本申请的方法中限定的上述功能。需要说明的是,本申请上述的计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质或者是上述两者的任意组合。计算机可读存储介质例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子可以包括但不限于:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本申请中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。而在本申请中,计算机可读的信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了计算机可读的程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。计算机可读的信号介质还可以是计算机可读存储介质以外的任何计算机可读介质,该计算机可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。计算机可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于:无线、电线、光缆、rf等等,或者上述的任意合适的组合。
附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,该模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图和/或流程图中的每个方框、以及框图和/或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
本领域的技术人员应理解,上述描述及附图中所示的本发明的实施例只作为举例而并不限制本发明,本发明的目的已经完整并有效地实现,本发明的功能及结构原理已在实施例中展示和说明,在没有背离所述原理下,本发明的实施方式可以有任何变形或修改。
- 还没有人留言评论。精彩留言会获得点赞!