基于数字人表情、嘴型及声音同步的用户跨平台交流方法与流程
本发明属于音视频同步技术领域,具体涉及一种基于数字人表情、嘴型及声音同步的用户跨平台交流方法。
背景技术:
数字虚拟人(digitalhuman)是通过虚拟现实技术,结合人机交互,高精度三维人像模拟、ai以及动作捕捉、面部表情捕捉等技术制作的拟真三维人。其中面部表情和说话时的嘴型动作的制作是数字虚拟人表现的重点和难点,数字虚拟人表情动作是否生动和话语匹配是数字虚拟人看起来是否逼真的重要判断依据。
当今,数字虚拟人在游戏、娱乐、影视领域广泛地被应用。这些行业中,往往都是通过面部表情捕捉设备,将真人说话时的面部表情和嘴型动作捕捉下来然后通过3d制作工具如faceware、iclone、maya等软件将这些表情和嘴型动作应用到数字虚拟人上,以便让数字虚拟人说话时的表情和嘴型动作看起来像真人一样。这种技术手段的问题是,人物表情和说话时的嘴型动作是事先制作好的,数字虚拟人无法和真人进行实时互动说话交流。
目前虽然也有实时驱动数字虚拟人的表情和嘴型动作的方法,但是效果和应用场景受到很大限制。受限于目前技术的发展,通过算法来驱动数字虚拟人的面部表情和嘴型动作,再配合ai与人的交互的效果往往不太理想。于是出现了通过手机摄像头、pc摄像头等轻量化设备捕捉真人面部表情和嘴型动作并实时驱动数字虚拟人,以便实现真人和数字虚拟人实时交流的技术方案。这种方案可以实现真人与数字虚拟人的互动交流对话,但问题在于,想要达到逼真的效果,数字虚拟人的实时渲染需要强大的图形图像和数据处理能力,这就严重限制了数字虚拟人在行业领域的应用和推广。
上述方案虽然可以通过云渲染的方式来解决数字虚拟人的实时渲染对终端设备要求过高的问题,但就是由于将渲染端放在了云端,和人物表情动作和嘴型动作的捕捉、声音的采集就分开了。摄像头等设备在进行实时面部表情和嘴型动作的捕捉以及说话声音采集后,通过网络将这些数据发送到云端,云端的服务器处理后,将最终渲染的画面和声音通过webrtc协议串流到另一用户端浏览器上,这个过程受到网络条件等的影响,无法保证被传输的数据到另一用户端时,数字虚拟人说话的表情、嘴型动作和说话的内容是同步的。当数字虚拟人的表情动作、嘴型动作和说话的语音不同步时,用户体验是相当差的。
技术实现要素:
针对现有技术中的上述不足,本发明提供的基于数字人表情、嘴型及声音同步的用户跨平台交流方法解决了现有的通过数字虚拟人进行互动交流时,数字虚拟人表情、嘴型和声音不同步,降低用户体验的问题。
为了达到上述发明目的,本发明采用的技术方案为:一种基于数字人表情、嘴型及声音同步的用户跨平台交流方法,包括以下步骤:
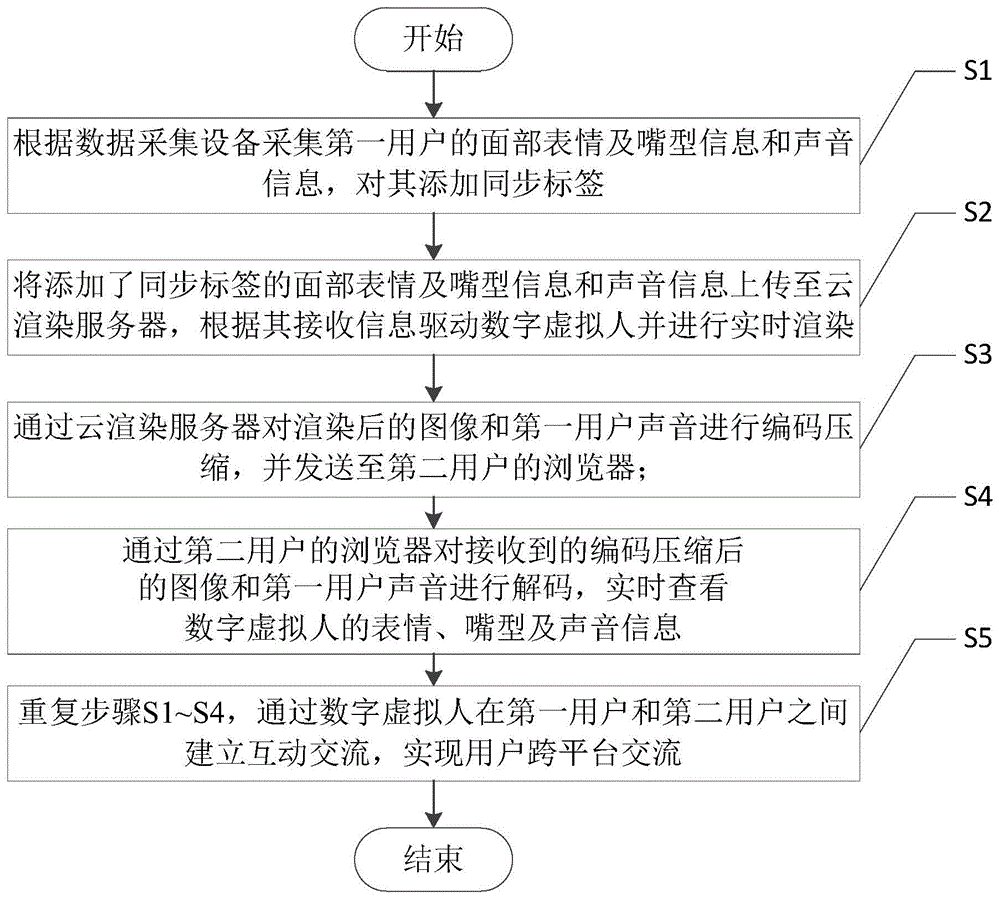
s1、根据数据采集设备采集第一用户的面部表情及嘴型信息和声音信息,对其添加同步标签;
s2、将添加了同步标签的面部表情及嘴型信息和声音信息上传至云渲染服务器,根据其接收信息驱动数字虚拟人并进行实时渲染;
s3、通过云渲染服务器对渲染后的图像和第一用户声音进行编码压缩,并发送至第二用户的浏览器;
s4、通过第二用户的浏览器对接收到的编码压缩后的图像和第一用户声音进行解码,实时查看数字虚拟人的表情、嘴型及声音信息;
s5、重复步骤s1~s4,通过数字虚拟人在第一用户和第二用户之间建立互动交流,实现用户跨平台交流。
进一步地,所述步骤s1中,添加同步标签的方法具体为:
a1、当第一用户与第二用户之间有交流需求时,通过数据采集设备采集第一用户表情、嘴型和声音信息,并将其缓存为表情及嘴型数据和声音数据;
a2、判断第一用户发出的语音是否有停顿;
若是,则进入步骤a3;
若否,则返回步骤a1;
a3、对当前语音对应的缓存表情及嘴型数据和声音数据添加同步开始标签和同步结束标签。
进一步地,所述步骤a3具体为:
a31、在数据采集设备缓存的第一用户的所有面部表情中,假设其对应的嘴型动作有k个,且嘴巴在自然闭合状态下的姿态为n,在所有打开状态下的姿态为p,并根据其中间状态m确定嘴型动作变形参数ti:
其中,中间状态m为:
式中,ti为第i个嘴型动作变形参数,且ti∈[0,1];
pi为第i个嘴巴打开的姿态;
a32、根据云渲染服务器中数字虚拟人的表情及嘴型动画制作情况,设置ti阈值为:
t={0.1,0.12,...,0.2}
a33、当检测到数据采集设备中缓存的第一用户当前所有面部表情及嘴型信息的所有ti均满足设置阈值时,在对应的面部表情及嘴型信息和声音信息中处添加开始同步标签;
当检测到数据采集设备中缓存的第一用户当前所有面部表情及嘴型信息的所有ti均为0时,在对应的面部表情及嘴型信息和声音信息处均添加结束同步标签。
进一步地,所述步骤s2具体为:
s21、通过云渲染服务器将接收到的添加了同步标签的面部表情及嘴型信息和声音信息进行缓存;
s22、对当前缓存的面部表情及嘴型信息和声音信息进行同步标签检查,判断是否有相同的开始同步标签和结束同步标签;
若是,则进入步骤s23;
若否,则返回步骤s21;
s23、根据具有相同的开始同步标签和结束同步标签的缓存信息,对数字虚拟人的表情动作、嘴型动作和声音动作进行驱动,并进行实时渲染。
进一步地,所述步骤s3中通过nvenc进行硬件实时加速视频编码,并使用h.264编码格式对音视频进行编码压缩。
进一步地,所述步骤s3中,通过rtc协议将编码压缩的音视频信息发送至第二用户的浏览器端。
进一步地,所述步骤s3中,第二用户的浏览器为支持webrtc协议的浏览器。
本发明的有益效果为:
(1)本发明方法可以给用户带来全新的与数字虚拟人的交互体验:该方法通过给数据增加同步标签,时云端渲染的数字虚拟人的表情、嘴型动作和语音实现了同步,提高了用户使用体验、用户与数字虚拟人进行对话也给用户带来了全新的交互体验。
(2)虚拟数字人在云端进行渲染,降低了用户使用成本,用户使用更加便宜的轻量化设备即可;且该方法的跨平台性质,为用户使用虚拟数字人提供了便利性。
(3)本发明方法通过云渲染的方式进行数字虚拟人的渲染并用webrtc协议进行串流,实现了轻量化访问以及跨平台的特性,这为数字虚拟人在游戏、娱乐和影视之外的更多领域的推广和应用打下了基础。
附图说明
图1为本发明提供的基于数字人表情、嘴型及声音同步的用户跨平台交流方法流程图。
图2为本发明中的用户跨平台交流实时示意图。
图3为本发明中的同步标签添加示意图。
图4为本发明中的更细一步的同步标签添加示意图。
具体实施方式
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
如图1所示,一种基于数字人表情、嘴型及声音同步的用户跨平台交流方法,包括以下步骤:
s1、根据数据采集设备采集第一用户的面部表情及嘴型信息和声音信息,对其添加同步标签;
s2、将添加了同步标签的面部表情及嘴型信息和声音信息上传至云渲染服务器,根据其接收信息驱动数字虚拟人并进行实时渲染;
s3、通过云渲染服务器对渲染后的图像和第一用户声音进行编码压缩,并发送至第二用户的浏览器;
s4、通过第二用户的浏览器对接收到的编码压缩后的图像和第一用户声音进行解码,实时查看数字虚拟人的表情、嘴型及声音信息;
s5、重复步骤s1~s4,通过数字虚拟人在第一用户和第二用户之间建立互动交流,实现用户跨平台交流。
如图2所示,本发明方案中,第一用户是用户驱动数字虚拟人的用户,第二用户是与数字虚拟人进行实时交流的用户,当第一用户驱动数字虚拟人与第二用户进行实时交流时,第一用户通过数据采集设备(摄像头、手机等)设备捕捉自己说话时的表情和嘴型动作数据的同时,也通过麦克风收集语音数据,本发明方案通过在相对独立发送的表情和嘴型数据以及语音数据添加同步标签,使数字虚拟人展示的语音和表情、嘴型信息是同步的。
具体地,为了让数据同步,当第一用户有交流需求时,捕捉端(数据采集设备)程序先将数据缓存下来,在缓存的数据中增加数据同步标记;语音开始的时候,分别给表情和嘴型数据,以及语音数据增加一个开始同步标记,在语音结束的时候,同样分别给表情和嘴型数据,以及语音数据增加一个结束同步标记。被增加了标记的数据通过网络发送到云渲染服务器上。图3展示了语音数据和表情、嘴型动作数据之间添加同步标记的方式;
为了使第一用户与第二用户在交流时,及时第一用户没有说话,第二用户也能看到第一用户的表情,我们在同步标签的添加过程中以采集的表情及嘴型作为添加基准,进行开始和结束标签的添加;因此,上述步骤s1中,添加同步标签的方法具体为:
a1、当第一用户与第二用户之间有交流需求时,通过数据采集设备采集第一用户表情、嘴型和声音信息,并将其缓存为表情及嘴型数据和声音数据;
a2、判断第一用户发出的语音是否有停顿;
若是,则进入步骤a3;
若否,则返回步骤a1;
a3、对当前语音对应的缓存表情及嘴型数据和声音数据添加同步开始标签和同步结束标签;
其中,由于数字虚拟人用于标签表情和嘴型动作的混合动画很多,为了提高效率,可以使用控制嘴部混合动画,用以配合音频进行标记;因此步骤a3具体为:
a31、在数据采集设备缓存的第一用户的所有面部表情中,假设其对应的嘴型动作有k个,且嘴巴在自然闭合状态下的姿态为n,在所有打开状态下的姿态为p,并根据其中间状态m确定嘴型动作变形参数ti:
其中,中间状态m为:
式中,ti为第i个嘴型动作变形参数,且ti∈[0,1],因此,可以通过ti判断嘴型动作的混合程度,即要找到一个状态m,该状态表示说话的开始;
pi为第i个嘴巴打开的姿态;
a32、根据云渲染服务器中数字虚拟人的表情及嘴型动画制作情况,设置ti阈值为:
t={0.1,0.12,...,0.2}
a33、当检测到数据采集设备中缓存的第一用户当前所有面部表情及嘴型信息的所有ti均满足设置阈值时,在对应的面部表情及嘴型信息和声音信息中处添加开始同步标签;
当检测到数据采集设备中缓存的第一用户当前所有面部表情及嘴型信息的所有ti均为0时,在对应的面部表情及嘴型信息和声音信息处均添加结束同步标签。
上述过程可以理解为,当所有控制嘴型动作的动画混合到ti的程度时,可以判断该数字虚拟人开始说话;一个嘴型动作比如“啊”这个嘴型,可能由i个动作混合而成的,比如嘴角张开的动作,嘴唇上下分开的动作,那么ti代表了组成“啊”这个嘴型动作的嘴角张开和嘴唇分开的程度。即,由ti对应的嘴角张开程度和嘴唇分开程度混合形成了“啊”的嘴型动作。这样做的好处是,无论第一用户是否说话,只要嘴型开始张开的动作,都视为需要进行同步处理,以确保第二用户看到的画面和听到的声音是同步的;图4为本方案中更进一步的同步标签添加示意图。
上述步骤s2具体为:
s21、通过云渲染服务器将接收到的添加了同步标签的面部表情及嘴型信息和声音信息进行缓存;
s22、对当前缓存的面部表情及嘴型信息和声音信息进行同步标签检查,判断是否有相同的开始同步标签和结束同步标签;
若是,则进入步骤s23;
若否,则返回步骤s21;
s23、根据具有相同的开始同步标签和结束同步标签的缓存信息,对数字虚拟人的表情动作、嘴型动作和声音动作进行驱动,并进行实时渲染;
在步骤s22返回步骤s21中,云渲染服务器没有找到相同且成对的同步标记,程序会等待直到缓存中表情及嘴型动作和语音数据出现相同姐成对的同步标记为止,然后再进行下一步的渲染、编码和压缩过程,最后通过rtc协议发送至第二用户的浏览器中,这就保证了用户b看到的数字虚拟人的表情、嘴型和说话的语音是同步的。
上述步骤s3中,为了保证服务器端视频编码压缩的实时性和网络传输的效率,该方法采用了nvenc进行硬件实时加速视频编码,并使用h.264编码格式对视频和音频进行编码压缩;第二用户使用支持webrtc协议的浏览器访问后,即可与用户a驱动的数字虚拟人进行实时交流对话。
需要说明的是,第二用户向第一用户发送的语音数据,不需要进行任何处理和同步操作的,通过任何其他语音传送方式发送给第一用户即可。
本发明的有益效果为:
(1)本发明方法可以给用户带来全新的与数字虚拟人的交互体验:该方法通过给数据增加同步标签,时云端渲染的数字虚拟人的表情、嘴型动作和语音实现了同步,提高了用户使用体验、用户与数字虚拟人进行对话也给用户带来了全新的交互体验。
(2)虚拟数字人在云端进行渲染,降低了用户使用成本,用户使用更加便宜的轻量化设备即可;且该方法的跨平台性质,为用户使用虚拟数字人提供了便利性。
(3)本发明方法通过云渲染的方式进行数字虚拟人的渲染并用webrtc协议进行串流,实现了轻量化访问以及跨平台的特性,这为数字虚拟人在游戏、娱乐和影视之外的更多领域的推广和应用打下了基础。
- 还没有人留言评论。精彩留言会获得点赞!