一种基于语音识别的视频文件处理方法与流程
本发明涉及一种基于语音识别的视频文件处理方法。
背景技术:
目前,视频处理技术的应用越来越广泛。在视频处理领域,很多情况下需要对视频文件进行处理,获取到视频文件中的相关数据信息,现有的视频处理方法无法对视频文件进行可靠处理。
技术实现要素:
本发明的目的在于提供一种基于语音识别的视频文件处理方法,用于解决现有的视频处理方法无法对视频文件进行可靠处理的问题。
为了解决上述问题,本发明采用以下技术方案:
一种基于语音识别的视频文件处理方法,包括:
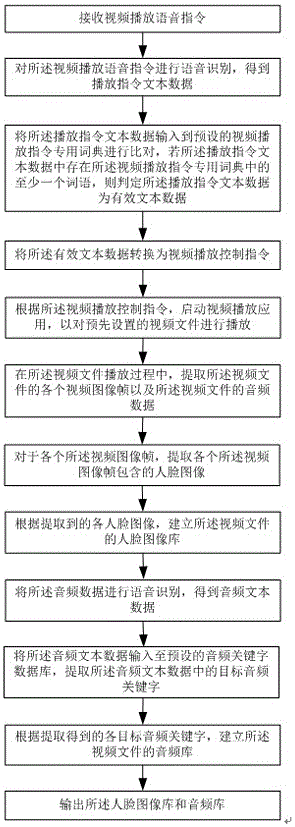
接收视频播放语音指令;
对所述视频播放语音指令进行语音识别,得到播放指令文本数据;
将所述播放指令文本数据输入到预设的视频播放指令专用词典进行比对,若所述播放指令文本数据中存在所述视频播放指令专用词典中的至少一个词语,则判定所述播放指令文本数据为有效文本数据;
将所述有效文本数据转换为视频播放控制指令;
根据所述视频播放控制指令,启动视频播放应用,以对预先设置的视频文件进行播放;
在所述视频文件播放过程中,提取所述视频文件的各个视频图像帧以及所述视频文件的音频数据;
对于各个所述视频图像帧,提取各个所述视频图像帧包含的人脸图像;
根据提取到的各人脸图像,建立所述视频文件的人脸图像库;
将所述音频数据进行语音识别,得到音频文本数据;
将所述音频文本数据输入至预设的音频关键字数据库,提取所述音频文本数据中的目标音频关键字;
根据提取得到的各目标音频关键字,建立所述视频文件的音频库;
输出所述人脸图像库和音频库。
优选地,所述将所述播放指令文本数据输入到预设的视频播放指令专用词典进行比对,包括:
将所述视频播放指令专用词典中的各个词语分别与所述播放指令文本数据进行比对,得到所述播放指令文本数据中是否存在所述视频播放指令专用词典中的词语。
优选地,所述视频播放指令专用词典中的词语包括播放。
优选地,所述视频播放指令专用词典中的词语还包括与播放相关的词语。
优选地,所述将所述音频数据进行语音识别,得到音频文本数据,包括:
将所述音频数据进行划分,划分成至少两个音频子数据,对各个所述音频子数据分别进行语音识别,得到音频文本子数据;
相应地,将所述音频文本数据输入至预设的音频关键字数据库,提取所述音频数据中的目标音频关键字,包括:
将各个音频文本子数据输入至所述音频关键字数据库,提取各个音频文本子数据中的目标音频关键字。
优选地,所述将各个音频文本子数据输入至所述音频关键字数据库,提取各个音频文本子数据中的音频关键字,包括:
对于任意一个音频文本子数据,将所述音频关键字数据库中的各个音频关键字分别与该音频文本子数据进行比对,提取该音频文本子数据中的目标音频关键字。
本发明的有益效果为:当需要对视频文件进行处理时,说出视频播放语音指令,将该视频播放语音指令进行语音识别,得到播放指令文本数据,然后需要对播放指令文本数据进行判断,根据预设的视频播放指令专用词典进行比对,若播放指令文本数据中存在视频播放指令专用词典中的至少一个词语,则判定该播放指令文本数据为有效文本数据,将有效文本数据转换为视频播放控制指令,根据视频播放控制指令,启动视频播放应用,以对预先设置的视频文件进行播放,通过这种语音识别控制启动视频播放的方式,相较于传统的点击视频文件控制启动视频播放的方式,智能化程度得到很大的提升,而且无需动作操作,提升控制便捷性;在视频文件播放过程中,提取视频文件的各个视频图像帧以及视频文件的音频数据,分别对各个视频图像帧以及音频数据进行处理,其中,对于提取各个视频图像帧包含的人脸图像,根据提取到的各人脸图像,建立视频文件的人脸图像库;将音频数据进行语音识别,得到音频文本数据,将音频文本数据输入至预设的音频关键字数据库,提取音频数据中的目标音频关键字,根据提取得到的各目标音频关键字,建立视频文件的音频库。因此,通过本发明提供的视频文件处理方法能够有效可靠地提取出视频文件中的人脸图像以及音频关键字,实现视频文件的可靠处理,得到所需的数据信息。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍:
图1是基于语音识别的视频文件处理方法的流程示意图。
具体实施方式
本实施例提供一种基于语音识别的视频文件处理方法,该视频文件处理方法的执行主体可以为台式电脑、笔记本电脑、智能移动终端等。由于需要获取到语音信号,因此,执行主体上需要设置有麦克风等语音采集设备,比如笔记本电脑或者智能移动终端自带的麦克风。由于需要控制进行视频文件播放,因此,执行主体中需要安装有视频播放应用,比如目前一些主流的视频播放软件程序,若安装有多个视频播放应用,则指定其中一个视频播放应用作为视频文件的默认播放软件,在后续控制时启动该视频播放应用。
如图1所示,视频文件处理方法包括以下步骤:
接收视频播放语音指令:
执行主体中存储有预设的视频文件,即需要处理的视频文件。当需要对视频文件进行处理时,操作人员说出视频播放语音指令。执行主体自带的麦克风或者执行主体配设的麦克风获取到操作人员的视频播放语音指令。
对所述视频播放语音指令进行语音识别,得到播放指令文本数据:
执行主体中内置有现有的语音识别算法,根据该语音识别算法将获取到的视频播放语音指令进行语音识别,得到播放指令文本数据。
将所述播放指令文本数据输入到预设的视频播放指令专用词典进行比对,若所述播放指令文本数据中存在所述视频播放指令专用词典中的至少一个词语,则判定所述播放指令文本数据为有效文本数据:
执行主体中预设有一个视频播放指令专用词典,该视频播放指令专用词典包括至少一个词语,该视频播放指令专用词典中的各个词语均为控制视频播放的控制指令的相关词语,作为一个具体实施方式,视频播放指令专用词典中的词语包括“播放”,进一步地,还包括与“播放”相关的词语,比如“启动”、“打开”等等。
将播放指令文本数据输入到该视频播放指令专用词典进行比对,本实施例给出一种实现过程,将视频播放指令专用词典中的各个词语分别与播放指令文本数据进行比对,也就是说,对于视频播放指令专用词典中的任意一个词语,将该词语输入到播放指令文本数据中,判断播放指令文本数据中是否存在该词语。那么,最终得到播放指令文本数据中是否存在视频播放指令专用词典中的词语。
若播放指令文本数据中存在视频播放指令专用词典中的至少一个词语,即播放指令文本数据中存在视频播放指令专用词典中的词语,那么,判定播放指令文本数据为有效文本数据。
将所述有效文本数据转换为视频播放控制指令:
将得到的有效文本数据转换为视频播放控制指令,作为一个具体实施方式,视频播放控制指令可以是一特定的数据串。
根据所述视频播放控制指令,启动视频播放应用,以对预先设置的视频文件进行播放:
根据得到的视频播放控制指令,控制启动已安装或者默认的视频播放应用,视频播放应用启动后播放预先设置的视频文件。
在所述视频文件播放过程中,提取所述视频文件的各个视频图像帧以及所述视频文件的音频数据:
视频播放应用在播放视频文件过程中,本实施例中,会读取视频文件包含的各个视频图像帧,并基于各个视频图像帧的帧序号,以预设的视频播放帧率依次输出各个视频播放帧,例如,该视频播放帧率可以为60dps,即每秒输出60幅视频图像帧。
执行主体获取到视频文件的各个视频图像帧。同时,对视频文件进行音频提取处理,提取得到该视频文件的音频数据,即该视频文件的声音信号。
对于各个所述视频图像帧,提取各个所述视频图像帧包含的人脸图像:
执行主体中内置有现有的人脸识别算法,人脸识别算法会对各视频图像帧进行解析处理,提取得到各个视频图像帧包含的人脸图像。应当理解,视频图像帧中可以只有一个人,也可以有多个人,因此,对于任意一个视频图像帧,可以只包含一个人脸图像,也可以包含多个人脸图像。
根据提取到的各人脸图像,建立所述视频文件的人脸图像库:
根据提取到的各人脸图像,建立视频文件的人脸图像库,可以直接将提取到的所有的人脸图像存储在一块,构成该视频文件的人脸图像库;或者,将所有的视频图像帧进行排序,得到帧号,然后,构建与视频图像帧个数相同的数据组,各数据组包括帧号以及与该帧号相对应的视频图像帧的人脸图像,所有的数据组构成该视频文件的人脸图像库;或者,将视频文件按照时间划分成多个子时间段,比如n个子时间段,设置n个数据组,各数据组包括子时间段内的所有的视频图像帧的人脸图像,所有的数据组构成该视频文件的人脸图像库。
将所述音频数据进行语音识别,得到音频文本数据:
将获取到的该视频文件的音频数据进行语音识别,得到音频文本数据。若音频数据比较长,则为了提升识别可靠性,将音频数据进行划分,划分成至少两个音频子数据,然后,对各个音频子数据分别进行语音识别,得到对应的音频文本子数据。
将所述音频文本数据输入至预设的音频关键字数据库,提取所述音频文本数据中的目标音频关键字:
执行主体中预设有一个音频关键字数据库,音频关键字数据库为包含有一定量的音频关键字(即音频关键字数据库包括至少一个音频关键字),该音频关键字数据库中的音频关键字可以根据实际需要进行专门设置,比如:将所需的关键字集合成为音频关键字数据库,这些关键字可以是不同种类的关键字,或者该音频关键字数据库中的音频关键字均是相同种类的关键字。本实施例中,音频关键字数据库中音频关键字为同种类型的关键字,比如均为动物的关键字,那么,音频关键字数据库包含的各个音频关键字就是各种动物的名字,比如:猴子、老虎、大象、狮子等等。应当理解,为了便于建立音频关键字数据库,音频关键字数据库中的各种动物均为常见的动物。
将获取到的音频文本数据输入至预设的音频关键字数据库,提取得到音频文本数据中的存在于音频关键字数据库的音频关键字,提取到的音频关键字为目标音频关键字。接上文举例,由于音频关键字数据库中存储的是各种动物的名字,则提取音频文本数据中出现的动物名字,若音频文本数据为“xxxx市的xxx湖边出现了老虎xxxx狮子xxxx”,则提取得到音频文本数据中的动物名字,包括“老虎”和“狮子”,“老虎”和“狮子”就是目标音频关键字。
作为一个具体实施方式,由于上述中将音频数据进行划分,划分成至少两个音频子数据,然后,对各个音频子数据分别进行语音识别,得到对应的音频文本子数据。那么,在提取音频关键字时,将各个音频文本子数据分别输入至音频关键字数据库,提取得到各个音频文本子数据中的目标音频关键字。
进一步地,“将各个音频文本子数据输入至音频关键字数据库,提取各个音频文本子数据中的音频关键字”具体为:对于任意一个音频文本子数据,将音频关键字数据库中的各个音频关键字分别与该音频文本子数据进行比对,若音频关键字数据库中的音频关键字存在于该音频文本子数据中,则保留该音频关键字,最终得到该音频文本子数据中的目标音频关键字。其他的各音频文本子数据也按照上述方式进行处理,最终得到所有音频文本子数据中的目标音频关键字,进而得到音频文本数据中的目标音频关键字。
接上述举例:对各个音频子数据分别进行语音识别,得到的各音频文本子数据分别是:“xxxx市的xxx湖边出现了老虎”和“xxxx狮子xxxx”,那么,将“xxxx市的xxx湖边出现了老虎”和“xxxx狮子xxxx”分别输入至音频关键字数据库,提取得到音频文本子数据“xxxx市的xxx湖边出现了老虎”中的目标音频关键字为“老虎”,音频文本子数据“xxxx狮子xxxx”中的目标音频关键字为“狮子”,则音频文本数据中的目标音频关键字为“老虎”和“狮子”。
根据提取得到的各目标音频关键字,建立所述视频文件的音频库:
提取得到音频文本数据中的目标音频关键字之后,将所有的目标音频关键字集合起来,构成视频文件的音频库。
输出所述人脸图像库和音频库:
输出建立的人脸图像库和音频库,比如有线传输或者无线传输给外部相关设备,可以使外部设备或者相关人员根据人脸图像库和音频库进行后续处理。
上述实施例仅以一种具体的实施方式说明本发明的技术方案,任何对本发明进行的等同替换及不脱离本发明精神和范围的修改或局部替换,其均应涵盖在本发明权利要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!