一种基于改进后的支持向量机的恶意程序识别方法与流程
本发明属于网络流量中检测恶意程序领域,涉及一种基于改进后的支持向量机的恶意程序识别方法。
背景技术:
随着人口数量的不断增长,促使网络规模日益扩大,网络流量中充斥着各种各样的繁杂数据,一些窃取利益者通过借助网络中的一些漏洞来进行网络攻击,造成了重要信息的泄露,以及非法访问的安全问题,更有甚者,使得企业系统瘫痪,给人们的生活带来了巨大的困扰。
在这庞大的网络流量中,网络恶意攻击者会发布一些钓鱼网站或者蠕虫病毒,来窃取用户的重要信息,然后利用这些漏洞将正常的程序转换为恶意程序,进而使得用户的主机被黑客控制或崩溃,造成了巨大的经济损失,扰乱了社会秩序。
在对恶意程序的检测前,需要先对网络流量进行分类识别,分离出有危害的恶意程序才好进一步对面向缓冲区溢出漏洞的恶意程序进行检测,而随着技术的不断发展,分类识别技术也种类多样,而现有一些分类识别方法都有其优缺点。teufl等人提出了一个简化经验模型选择和特征提取的框架,通过对网络流量进行分析,来观察流量中的数据是否违反了某项规则,同时从数据中提取最佳的特征集来构建流量分类模型,以此来实现对网络流量进行分类识别。shrivastav等人分析并实现了一种半监督的网络流量分类方法,通过对已标记的流和未标记的流的训练数据进行分类,该数据集包含攻击数据和正常数据,将标记的数据划分给集群进行分类识别,然后将测试的结果和基于svm的分类器进行对比,实验证明该方法具有较好的准确性。yang等人在分析多个网络数据之后发现,对于不同的协议,应用层传输的参数都会不同,比如有效负载的大小以及每个包的信息熵,然后借助基于最小划分距离的决策树算法来进行训练分类,实验表明截取前四个或前六个数据包对分类可以缩短时长和有较高的准确性。这些技术通过对网络中可能出现的恶意攻击行为进行扫描,在获取到相应的数据之后进行分析,具有较高的延迟性,同时最终的分类识别的测试结果与预期结果有较大的差异,所以本文提出的基于改进后的支持向量机的恶意程序识别方法有着重要意义。
技术实现要素:
基于现有技术对于网络流量中恶意程序的检测准确率不高且存在着分类精度较低等情况,因此本发明提出了一种基于改进后的支持向量机的恶意程序识别方法来解决上述问题。
本发明提供了一种基于改进后的支持向量机的恶意程序识别方法,包括:
步骤1通过netflow对网络流量中数据进行采集,并对采集到的数据包进行数据规范化;
步骤2为了完成对恶意程序的识别,需要进行特征提取;
步骤3为了消除冗余特征的问题,进行特征属性降维,并进行归一化处理;
步骤4然后采用ofsvm算法进行分类训练;
步骤5最后使用ntmi识别算法构建网络流量识别模型,最终实现对网络流量中恶意程序的识别。
第一方面,上述步骤2具体包括:
通过对处理后的数据集比较样本类型和特征属性的相关性,权值将不断增大随着相关性越高,然后设置一个阈值,超过该阈值,我们就保留该特征属性,否则就不选取。同时,若在提取过程中发现某个数据包出现多个特征属性,则选取出现频率最高的来进行代替。具体的特征选取的过程如下:从数据集d中分层随机选择一些样本s,然后在与样本s最近的相同类型da中选取y个样本r,然后在不同类的db中选取y个样本t,最终计算出样本s分别与样本r和样本t的距离,为dsr和dst;如果dsr>dst,说明该特征属性是有问题的,无法利用来进行分类,进而设置较小的权值;反之,该特征属性是易于分类的,就设置较大的权值。
第二方面,上述步骤3具体包括:
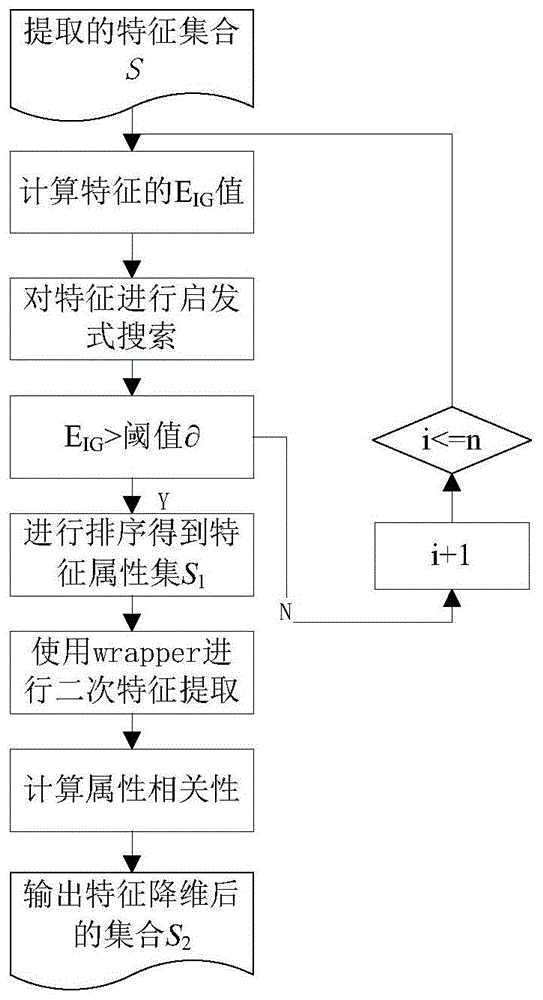
首先将提取到的特征属性添加到集合s中,在研究了之前的一些方法后,在此基础上提出了filter特征降维的方法,然后借助信息增益算法对特征属性集合s进行信息增益的评估,通过评估每一项特征属性对后续分类的效果,来决定是否更新值以及是否更新特征属性集合s,接着采用启发式的搜索策略对特征属性进行排序,得到特征属性集s1,循环该过程,达到指定的次数才会停止,在此基础上,采用wrapper方法进行二次特征选取,采用启发式序列向前的搜索方式,得到特征属性集s2,在进行特征降维后,不仅缩短了时间降低了计算复杂度,更改善了分类效果。
第三方面,上述ofsvm算法包括:
进行参数优化中,在有限次搜索中寻找出最优参数组合,使用网格搜索参数优化来对svm算法进行改进;同时借助采用计算每个样本到类之间的距离作为模糊因子,对于每个样本点si都存在对应的模糊因子ei,这表示样本分布的不确定性,其中0≤ei≤1,然后使用r+、r-来表示正负样本的均值点,那么法向量可以用
第四方面,上述ntmi识别算法具体包括:对采集到的网络流量数据进行数据抽样和规范化处理,获取到对实验更有价值的数据集,同时该网络流量数据更方便我们对特征进行提取,之后利用relieff算法对网络流量中的数据包进行特征提取,此时提取到特征的仍然包含有一些冗余的属性特征,这些特征将极大的降低网络流量分类的精度,进而提出对上述提取到的特征集进行降维,使用信息增益技术对各个特征进行计算评估,然后对特征集进行排序,并进行二次特征选取,采用启发式序列向前的搜索方式,并计算特征的相关性,最终实现对特征的降维。接着,对于得到的特征子集需要进行归一化处理,将所有的特征属性都转化为数值,然后以此放到矩阵数组中,进行最小欧式距离计算,然后借助ofsvm算法进行训练,得到一个分类效果较大改进的分类器,将剩余的网络流量测试集作为输入,利用该分类器,实现对网络流量中正常程序和恶意程序进行分类,最终实现对网络流量中恶意程序的识别。
本发明有益的效果是:
1.ofsvm算法可以用来提升网络流量的分类精度,提出使用网格搜索,扩大搜索范围,并采用样本到分类超平面的距离来设计模糊因子,这种做法将减小分类平面形状对分类精度的影响,同时根据特征有效度来衡量特征权值,最后使用径向基核函数降低复杂度,最终提升分类训练的性能。
2.ntmi识别算法通过对采集的数据包进行特征提取、特征降维以及归一化处理,以此来作为分类ofsvm算法的输入,生成分类性能更好的分类器,以此来构建网络流量的恶意程序识别模型,完成对恶意程序的识别。
3.有效的从网络流量中采集对应的数据流量,完成实时监测;对数据包进行特征提取;特征降维来处理冗余特征,提高了分类性能;便于特征的处理,提出归一化处理,可以更好的作为输入处理;ofsvm算法用来完成对恶意程序的分类训练;ntmi算法被用来识别网络流量中是否有恶意程序;实验结果表明所提的方法对网络流量的恶意程序识别有一定的效果,可以实现对网络流量中恶意程序的识别,保证了网络安全。
附图说明
图1特征降维的流程图;
图2是本发明的基于改进后的支持向量机的恶意程序识别方法流程图;
图3网络流量中恶意程序识别模型流程图;
图4特征提取后的特征属性示意图;
图5特征降维后的特征属性示意图;
图6五种方法在caida上的准确率对比图;
图7五种方法在caida上的误报率对比图。
具体实施方式
下面将通过附图以及具体步骤对本发明进一步阐述。
本发明的目的是针对网络流量中存在着一些利用漏洞的恶意程序,提供一种基于改进后的支持向量机的恶意程序识别方法,有效的完成对恶意程序的识别,提供了ntmi识别算法,并进行了充分的实验,这也证明了该方法的可行性和有效性。
如图2所示,本发明的基于改进后的支持向量机的恶意程序识别方法,包括:
步骤201通过netflow对网络流量中数据进行采集,并对采集到的数据包进行数据规范化;
步骤202为了完成对恶意程序的识别,需要进行特征提取;
步骤203为了消除冗余特征的问题,进行特征属性降维,并进行归一化处理;
步骤204然后采用ofsvm算法进行分类训练;
步骤205最后使用ntmi识别算法构建网络流量识别模型,最终实现对网络流量中恶意程序的识别。
上述步骤201,具体的步骤如下所示:
(1)数据采集
首先需要借助netflow进行网络流量数据采集,该工具其实也可以实现对网络流量分析,进而排查出网络故障,但是对于攻击者编写的许多漏洞类型的恶意程序识别效率较低,同时需要相应的网络设备对netflow的支持,而且需要使用人员可以区分出正常流量和恶意流量,因此本研究仅通过该工具进行网络流量采集,其可以监控指定时间段内通过端口的所有流量,是一个轻量级的工具,进而得到数据包的版本、个数、缓冲区大小等信息。
(2)数据规范化
对采集到的网络流量数据包进行规范化之前,先进行数据抽样,以此来挑选出更好的数据集。数据抽样主要是在实验的整个数据集中先选取一些数据作为子集然后进行抽样观察,因为该集合具有原始集合的特性,从而实现对整个网络流量数据集优良的判断。主要的抽样方式是系统抽样、随机抽样与分层抽样。系统抽样就是先对原来的数据样本进行排序,从头开始,每个一段时间随机抽取指定数量的样本数据;随机抽样:就是接着在整个样本数据中随机选取一些样本数据;而分层抽样就是把整个数据样本集先按照指定的规则分层,然后每层中随机抽取一些数据。本文将采取分层抽样来观察整个数据集合的优良。
对于步骤202,网络流量中数据包进行特征提取主要步骤如下:
(1)借助现有的relieff分析技术进行特征提取,该技术是在经典的filter上改进后的方法,该方法是通过对处理后的数据集比较样本类型和特征属性的相关性,权值将不断增大随着相关性越高,然后设置一个阈值,超过该阈值,我们就保留该特征属性,否则就不选取。同时,若在提取过程中发现某个数据包出现多个特征属性,则选取出现频率最高的来进行代替。
(2)具体的特征选取的过程如下:从数据集d中分层随机选择一些样本s,然后在与样本s最近的相同类型da中选取y个样本r,然后在不同类的db中选取y个样本t,最终计算出样本s分别与样本r和样本t的距离,为dsr和dst;如果dsr>dst,说明该特征属性是有问题的,无法利用来进行分类,进而设置较小的权值;反之,该特征属性是易于分类的,就设置较大的权值,特征权值的计算参考现有文献进行,其中d(x,r,t)为对应的欧式距离,w(x)为对应的权值,dj为数据集中第j个样本数据,n是指在n个数据中计算权值大小来进行特征提取,循环执行上述过程,并将最终计算的权值与设置的权值进行比对,符合要求就保留,否则就遗弃,进而可以得到最终的提取到特征属性集合s。最终提取到的特征如图4所示。
对于步骤203,为了消除冗余特征的问题,进行特征属性降维,并进行归一化处理,具体步骤如下:
(1)首先将提取到的特征属性添加到集合s中,在研究了之前的一些方法后,在此基础上提出了filter特征降维的方法,然后借助信息增益算法,eig=evaluate(ffilter,s)是对特征属性集合s进行信息增益的评估,通过评估每一项特征属性对后续分类的效果,来决定是否更新eig的值以及是否更新特征属性集合s,接着采用启发式的搜索策略对特征属性进行排序,得到特征属性集s1,循环该过程,达到指定的次数才会停止,在此基础上,采用wrapper方法进行二次特征选取,采用启发式序列向前的搜索方式,得到特征属性集s2,具体的流程图如图3所示。在进行特征降维后,不仅缩短了时间降低了计算复杂度,更改善了分类效果。
(2)在使用wrapper方法时,下述公式通过采用现有的文献对流量特征属性的相关性进行计算,来对特征属性进行二次选取,其中n表示对所有初始选取的特征属性个数,
(3)数据归一化在数据挖掘中扮演着重要的角色,对于不同的评价指标其对应的衡量单位是有差异的,在这种情况下将会无法进行数据分析操作,基于此,进行归一化处理,进而使得不同的数据有可比性和可操作性,在数据经过处理之后,将转换为无量纲和单位的纯数值,变成了同一量级的数据指标,便于进行后续的处理和评价,同时,进行归一化之后提升收敛速度和提高分类精度。具体归一化处理如下所示:借助现有文献中提出的离差标准化方法,也可以称作min-max标准化,其主要是用来处理数据的,通过把目标数据集转换到0到1之间,通过将获取到的特征子集进行线性变换,使用转换函数如下:
对于步骤204,后采用ofsvm算法进行分类训练,具体的步骤如下:
对于现有的svm分类方法,随着经济的快速发展,网络的普及范围扩大,使得网络流量规模也越来越庞大,同时在真实的网络环境中存在着许多噪音,且没有对样本数据中存在许多冗余的特征进行处理,导致svm分类精度较低;还有就是对样本数据进行训练生成分类器的过程中,需要人工的标识样本数据,将耗费许多精力同时很难保证不出现人为误差。
为了解决上述问题,将主要从参数优化的角度对svm算法进行改进,svm参数优化主要是在由许多参数空间中使用某种搜索策略,在有限次的搜索中寻找到一个趋近最优解,而在参数优化中我们需要考虑核函数参数和惩罚参数这两个重要参数。其中,惩罚参数将对svm超平面的泛化能力起着决定作用,主要被用于表示在构建超平面时候的容错度,而核函数参数会决定作用范围,进而也会影响svm的泛化能力。
(1)我们将从参数优化,在有限次搜索中寻找出最优参数组合的角度出发,提出使用网格搜索参数优化来对svm算法进行改进。网格搜索的原理如下,首先在k个参数中划分成k维的参数空间,其中使用网格节点来代表候选的参数;接着,在指定的步长进行采样并生成对应的集合p(ci)={p(c1)×p(c2)×…×p(ck)},并设置参数ci的范围,来生成不同方向的网格;最后根据指定的评估方法对每个网格节点ci进行评测,并输出最终的近似最优解。在这个过程中,首先设置递增步长为默认步长q的t倍,也就是q.t,这个是为了减少搜索时间和生成网格的密度,然后进行遍历搜索,在执行完所有的样本数据后,可以得到最优参数组合。为了表示构建分类平面时对样本数据的容错度,引入惩罚参数p,与设置的过拟合临界值f进行比较,当小于f时,缩小搜索空间,并设置搜索的步长为初始步长的一半,再次进行搜索,减少步长是为了扩大网格的密度,进而实现更精确的搜索;如果超过了过拟合临界值f,则扩大搜索空间并调整搜索方向方向进行再次的搜索,此时目的是既可以优化参数也能防止出现过拟合行为,循环执行样本数据,直至惩罚参数p在临界范围内,停止执行,输出最优的参数组合值。该算法有着较大的可搜索空间,且彼此节点互不相关,可通用性比较高,可以实现帮助完成分类的误差最小。
(2)接着为了提高分类精度,首先通过引入模糊因子,现有的一些研究提出采用计算每个样本到类之间的距离作为模糊因子,使得无法获得最优分类超平面,此种做法将减少支持向量对分类超平面的作用。本研究将采用样本到分类超平面的距离来设计模糊因子,这种做法将减小分类平面形状对分类精度的影响。在此基础上,首先构建对应的分类超平面,接着计算各个样本节点到超平面的距离,这样便可以借助模糊因子来消除多余噪音对分类精度,在此基础上,提出构建特征有效度,用来消除冗余特征对分类精度的影响。对于每个样本点si都存在对应的模糊因子ei,这表示样本分布的不确定性,其中0≤ei≤1,然后使用r+、r-来表示正负样本的均值点,那么法向量可以用
(3)通过参考现有文献提出的特征有效度的计算方法,对于每个样本数据的特征i其都有一个相对应的特征有效度
(4)核函数主要是用来将原始非线性样本数据映射到特征空间中,然后再借助构造的最优分类平面将该非线性样本转换为线性可分类问题,这样便可以便可以避免高维特征空间带来的庞大计算量。假设输入空间p∈r^n,对应的特征空间是f,当存在映射函数γ(y)=y→p,对于属于y的任意的yi和yj都满足k(yi,yj)=γ(yi)tγ(yj),则此时便存在核函数k。而核函数又需要满足mercer定理,也就是对于输入空间的任意向量,其对应的核矩阵应该为半正定矩阵。当选择合适的核函数后,实现不增加复杂度的同时来完成线性分类。因此,svm的分类效果与核函数有极大的关联。本研究将采用径向基核函数来作为核函数,该函数在局部范围中有较好的性能,同时可以实现对数据集中的样本点有很高的分类效率。而且其不被样本数量和特征维数约束的优点使得其应用更加广泛,同时径向基核函数有着较少的参数,而一般情况下,核函数的复杂度是与其参数个数是有关联的,这使得还核函数有较低的复杂度。通过采用上述方式对svm算法的分类进行改进使得误差相对较小,进而使得对于网络流量中恶意程序分类识别能力有较大的改善。
对于步骤205,最后使用ntmi识别算法构建网络流量识别模型,最终实现对网络流量中恶意程序的识别,具体步骤如下:
(1)首先解决对网络流量中的程序进行准确分类问题,为了实现该目标,首先使用netflow技术对网络流量进行采集,整个采集流程主要包括三个步骤,步骤一尝试获取网卡列表,借助网络底层访问工具来获取网卡列表,实时监测所有经过网卡的流量;步骤二是挑选网卡进行检测,对步骤一获取的网卡数据,需要设置其为混杂模式;步骤三就是将流量中的数据包进行合并,在某一段时间内通过网络的流量数据,通过提取它们的数据包并合并,最终将得到采集到的网络流量数据。
(2)对采集到的网络流量数据进行数据抽样和规范化处理,获取到对实验更有价值的数据集,同时该网络流量数据更方便我们对特征进行提取,之后利用relieff算法对网络流量中的数据包进行特征提取,此时提取到特征的仍然包含有一些冗余的属性特征,这些特征将极大的降低网络流量分类的精度,进而提出对上述提取到的特征集进行降维,使用信息增益技术对各个特征进行计算评估,然后对特征集进行排序,使用wrapper方法进行二次特征选取,采用启发式序列向前的搜索方式,并计算特征的相关性,最终实现对特征的降维。
(3)对于得到的特征子集需要进行归一化处理,将所有的特征属性都转化为数值,然后以此放到矩阵数组中,进行最小欧式距离计算,然后借助ofsvm算法进行训练,得到一个分类效果较大改进的分类器,将剩余的网络流量测试集作为输入,利用该分类器,实现对网络流量中正常程序和恶意程序进行分类,最终实现对网络流量中恶意程序的识别,在此基础上,进而完成对该识别模型的构建。
通过将本发明提出的ntmi识别方法与现有的四种方法进行比较,如图6和如图7所示,对于该公共数据集较大,然后我们便选取10%的数据集分别作为训练和测试,最终用于测试的数据集接近4万个左右,同时该从图中可以看出,本研究提出的ntmi算法的准确率依旧表现的不错,随着数据包个数的增加,在更大规模的网络流量公共数据集时,ntmi算法相比其他四种算法的误报率是更低的,也是趋于稳定的,维持在6%左右,这也证明了本发明是可行的。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示意性实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!