一种基于单一状态机的网络日志解析方法与流程
本发明涉及网络日志解析技术领域,特别是一种基于单一状态机的网络日志解析方法。
背景技术:
随着大数据业务在各个行业的普及,针对各种数据源的安全分析变的越来越重要。其中网络设备日志是数据安全分析最重要的数据类型,但其具有复杂、多样、不规则以及可深度挖掘等特性,业务场景还原和有效价值分析难度比较高。
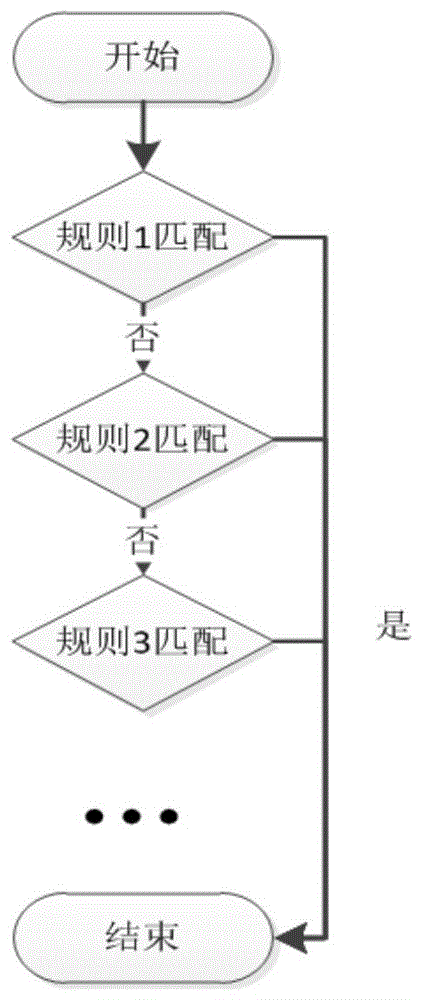
为了解决这些问题,业界使用了各种数据解析方式,比如业界广泛使用的logstash中的grok、awk/gred等等。这些大多基于正则解析,业务场景明晰,但在数据量较大、数据不规范以及自身特性决定的上下文依赖的场景下,执行效率较低,网络设备所要表达的含义还原度不高,代码也随着业务复杂度的提升变的更加复杂、不易维护。例如,在图1中,在极端情况下,数据会经过所有的规则到达终点,而事实上网络设备产品有上百种,就会有上百种规则。
技术实现要素:
本发明的目的是提供一种基于单一状态机的网络日志解析方法,旨在解决现有技术中网络日志解析在数据量大、数据不规范的情况下执行效率低的问题,实现提高执行效率以及扩展性。
为达到上述技术目的,本发明提供了一种基于单一状态机的网络日志解析方法,所述方法包括以下操作:
将字符串、字符、数字、通用以及量词状态机组装成单一状态机;
日志内容作为字符流驱动状态机的状态转移,字符流的每个字符驱动状态机通过当前字符所符合的条件转移转移到下一个状态,并执行该条件转移上定义的动作;
当日志内容的字符流流尽,状态机转移到最终状态,完成匹配。
优选地,所述状态机提取高频共用规则为公共状态机,进行复用,包括各种格式的时间、地区、设备厂商、ip地址。
优选地,所述状态机在利用共用的关键字的基础上,增加相关规则,形成新的状态机。
优选地,所述该条件转移上定义的动作包括:标记、关键字、值,通过标记起始位置,提取起始位置以及当前位置之间的字串作为关键字或值。
优选地,所述方法以单个字符驱动状态机。
优选地,所述方法还包括:基于词义进行状态机的执行,以词驱动状态机。
发明内容中提供的效果仅仅是实施例的效果,而不是发明所有的全部效果,上述技术方案中的一个技术方案具有如下优点或有益效果:
与现有技术相比,本发明语法简单、复用率高,因为状态机的特性,可以提取出高频共用的规则为公共状态机,实现复用,例如各种格式的时间、地区、设备厂商、ip地址等,新日志可以继续使用旧有的抽取的关键字直接替代;执行效率高,在日志处理过程中只经过一个整合过的状态机,不再有多余的处理;可扩展性强,通过不断编译增强的状态机可以解决各种复杂日志,在利用共用的关键字的基础上,增加相关规则即可;还原业务场景度较高,在现实场景下,对单词的识别会比一串字符有更高的识别准确率,加入词义的规则过滤,更加有利于消除日志表述中的歧义,为数据采集提供更准确的信息。
附图说明
图1为现有技术中所提供的规则匹配流程图;
图2为本发明实施例中所提供的一种基于单一状态机的网络日志解析方法流程图;
图3为本发明实施例中所提供的字符串“hell”的状态机执行示意图;
图4为本发明实施例中所提供的字符数字状态机执行示意图;
图5为本发明实施例中所提供的单一日志解析样例状态机执行示意图;
图6为本发明实施例中所提供的复杂多日志解析样例状态机执行示意图;
图7为本发明实施例中所提供的基于词义的日志解析状态机执行示意图。
具体实施方式
为了能清楚说明本方案的技术特点,下面通过具体实施方式,并结合其附图,对本发明进行详细阐述。下文的公开提供了许多不同的实施例或例子用来实现本发明的不同结构。为了简化本发明的公开,下文中对特定例子的部件和设置进行描述。此外,本发明可以在不同例子中重复参考数字和/或字母。这种重复是为了简化和清楚的目的,其本身不指示所讨论各种实施例和/或设置之间的关系。应当注意,在附图中所图示的部件不一定按比例绘制。本发明省略了对公知组件和处理技术及工艺的描述以避免不必要地限制本发明。
下面结合附图对本发明实施例所提供的一种基于单一状态机的网络日志解析方法进行详细说明。
如图2所示,本发明实施例公开了一种基于单一状态机的网络日志解析方法,所述方法包括以下操作:
将字符串、字符、数字、通用以及量词状态机组装成单一状态机;
日志内容作为字符流驱动状态机的状态转移,字符流的每个字符驱动状态机通过当前字符所符合的条件转移转移到下一个状态,并执行该条件转移上定义的动作;
当日志内容的字符流流尽,状态机转移到最终状态,完成匹配。
状态机由一组状态、连接状态的条件转移以及条件转移上定义的动作组成,在图形化表示的状态机中以圆形表示普通形态,以圆环表示结束状态,以有向箭头加条件标注表示条件转移,动作标注在条件标注之后。日志内容作为字符流驱动状态机的状态转移,从初始状态开始,字符流中的每个字符都可以驱动状态机通过当前字符所符合的条件转移转换到下一个状态,并执行该条件转移上定义的动作。当字符流流尽,状态机转移到最终状态即完成匹配。
如图3所示,以字符串“hello”为例,使用字符串“hello”执行该状态机:
初始状态1;
字符‘h’符合到状态2的条件转移,状态机转移到状态2;
字符‘e’符合到状态3的条件转移,状态机转移到状态3;
以此类推状态机依次转移到状态6完成匹配。
例如,若使用字符串“hillo”,状态机转移到状态2后,字符‘i’无法满足连接状态2的条件转移,状态机匹配失败。
如图4所示,识别标识符的状态机[a-za-z_][a-za-z0-9],使用字符串“_hello”执行该状态机:
初始状态1;
字符‘_’符合到状态2的条件转移,状态机转移到状态2;
字符‘h’符合到状态2的条件转移,状态机转移到状态2;
以此类推状态机转移到状态2完成匹配。
若使用字符串“1hello”,状态机转移到状态1后,字符‘1’无法满足连接状态1的条件转移,状态机匹配失败。
对于通用状态机,如下所示:
any匹配任意字符
ascii匹配ascii字符,0..127
alpha匹配字母表字符,[a-za-z]
digit匹配数字,[0-9]
对于量词,如下所示:
*任意次
?0或1次
+1或更多次
{n}n次
{,n}最多你次
{n,}至少n次
{n,m}n到m次
在实际使用中识别多种多样的网络设备日志,需要将简单的状态机组装连接成一个大的单一状态机,本发明实施例通过单一日志解析以及复杂多日志解析进行具体描述。
对于单一日志样例:
ha;host_id:00001-70a3a-1662689e;host_name:localhost;host_ip:192.168.17.31;hdid:wd-wmc3f0ha92l6;mac:f80f41dcc3a0;username:李某;dept:dp;opt_time:2016-01-02?11:12:11;
其状态机执行过程如图5所示:
状态机初始状态1;
字符串中‘h’、‘a’、‘;’三个字符驱动状态机从状态1依次转移到状态2、状态3、状态4;
字符串中第4个字符‘h’,符合连接状态4的条件转移,驱动状态机转移到状态5,在转移过程中执行了转移上定义的动作a_mark,该动作作用为标记一个起始位置,记为s1;
从字符串中第5个字符到第1个‘:’,都符合连接状态5的标记为def的转移,在字符‘:’前状态机循环转移到状态5;
字符串中第1个‘:’符合另一个连接状态5的条件转移,状态机转移到状态6,并在转移过程中执行转移上定义的动作a_key,该动作作用为以s1为起始位置(包含),当前位置为结束位置(不包含),从字符串中取出子串,该子串为“host_id”;
下一个字符‘0’符合连接状态6的条件转移,驱动状态机转移到状态7,在转移过程中执行了转移上定义的动作a_mark,该位置记为s1;
接下来的字符到‘;’为止都符合连接状态7的标记为def的转移,在字符‘;’前状态机循环转移到状态7;
字符‘;’符合另一个连接状态7的条件转移,状态机转移到状态8,并在转移过程中执行了转移上定义的动作a_value,该动作作用为以s1为起始位置(包含),当前位置为结束位置(不包含),从字符串中取出子串,该子串为“00001-70a3a-1662689e”,并命名为提取的子串“host_id”;
以此类推,依次提取出host_name=localhost,host_ip=192.168.17.31等,并组装为结构化数据,解析后的结果为:
{
"host_id":"00001-70a3a-1662689e",
"host_name":"localhost",
"host_ip":"192.168.17.31",
"hdid":"wd-wmc3f0ha92l6",
"mac":"f80f41dcc3a0",
"username":"李某",
"dept":"dp",
"opt_time":"2016-01-02?11:12:11"
}
对于复杂多日志样例:
ha;host_id:00001-70a3a-1662689e;host_name:localhost;host_ip:192.168.17.31;hdid:wd-wmc3f0ha92l6;mac:f80f41dcc3a0;username:李某;dept:dp;opt_time:2016-01-02?11:12:11;
<1>本主机~1~2011-04-0216:21:25~192.168.21.10:0~127.0.0.1:0~系统告警~中~1104021621255407290~主机当前cpu使用率[65%]已超过[60%]的限定门限!
状态机执行过程如图6所示:
除了执行单一日志样例中的状态机执行过程外,还执行以下过程:
字符串中‘<’、‘1’、‘>’三个字符驱动状态机从状态1依次转移到状态2、状态3、状态4;
下一个字符符合连接状态4的条件转移,驱动状态机转移到状态5,在转移过程中执行了转移上定义的动作a_mark,该动作作用为标记一个起始位置,记为s1;
接下来的字符到‘~’为止都符合连接状态5的条件转移,状态机转移到状态6,并在转移过程中执行了转移上定义的动作a_value,该动作作用为以s1为起始位置(包含),当前位置为结束为止(不包含),从字符串中取出子串,该子串为“本主机”;
以此类推,依次取出各个子串,并组装为结构化数据,解析后的结果为:
{
"host_id":"00001-70a3a-1662689e",
"host_name":"localhost",
"host_ip":"192.168.17.31",
"hdid":"wd-wmc3f0ha92l6",
"mac":"f80f41dcc3a0",
"username":"李某",
"dept":"dp",
"opt_time":"2016-01-02?11:12:11"
}
{
"k1":"本主机",
"k2":"1",
"k3":"2011-04-0216:21:25",
"k4":"192.168.21.10:0",
"k5":"127.0.0.1:0",
"k6":"系统告警",
"k7":"中",
"k8":"1104021621255407290",
"k9":"主机当前cpu使用率[65%]已超过[60%]的限定门限!"
}
另外,可采用基于词义进行日志解析,基于词义的状态机执行流程的原理与基于字符流的状态机一致,唯一的不同在于驱动状态机的字符单位:基于字符流的状态机以单个字符驱动,基于词义的状态机以词驱动,以词驱动的状态机可以减少状态机状态,消除歧义,其状态机执行过程如图7所示。
本发明实施例语法简单、复用率高,因为状态机的特性,可以提取出高频共用的规则为公共状态机,实现复用,例如各种格式的时间、地区、设备厂商、ip地址等,新日志可以继续使用旧有的抽取的关键字直接替代;执行效率高,在日志处理过程中只经过一个整合过的状态机,不再有多余的处理;可扩展性强,通过不断编译增强的状态机可以解决各种复杂日志,在利用共用的关键字的基础上,增加相关规则即可;还原业务场景度较高,在现实场景下,对单词的识别会比一串字符有更高的识别准确率,加入词义的规则过滤,更加有利于消除日志表述中的歧义,为数据采集提供更准确的信息。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!