基于多源安全检测框架的检测方法及系统与流程
本申请涉及安全检测技术领域,具体而言,涉及一种基于多源安全检测框架的检测方法及系统。
背景技术:
随着信息技术的不断发展,信息安全问题也日益突出。传统的信息安全检测所使用的产品、检测策略一般都是较为分散且使用困难,而且伴随黑客技术的愈发成熟,各类黑客工具的使用也是极为广泛,其中一些工具也能在如github等开源社区平台上轻易获得,例如empire、gh0strat(一个远程控制框架)等,而且诸如sqlmap、acunetix扫描器、msf(metasploit)一些渗透测试工具也被广泛使用,虽然各类安全产品如下一代防火墙、入侵检测系统、防病毒系统、端点检测响应(endpointdetectionresponse,简称edr)等产品都能或多或少地检测到一些安全问题,但对于无明显特征的网络活动或主机活动则无能为力,即对于一些未知威胁的检测可能存在比较大的局限性,因为它们不会覆盖一些看似正常的网络访问或主机操作,故一般企业单位会部署诸如态势感知产品、安全管理产品或下一代安全事件管理系统(ng-siems)会收集一般的主机日志、网络访问日志(包括各类nat日志)、安全报警等进行集中的检测和分析,以期从这些日志和报警中能发现一些在单一安全设备的报警中无法发现的问题。
与传统的安全事件管理系统不同,因为集成了一些蜜罐、网络流量探针、端点检测响应等子系统,所以一般而言安全态势感知、安全管理平台或下一代安全事件管理系统等此类产品本身具备一定的安全问题发现以及处置能力,但它们核心的功能主要是集中对收集的相关日志、安全报警进行集中地、广泛地和深入地分析,从而能检测到一些单点安全设备所无法发现的问题;而且,通过嵌入一些人工智能/机器学习手段或方法,配合传统的基于特征和简单统计等方法可以发现安全方面的蛛丝马迹,当然这些安全问题不仅指一般意义上的黑客入侵事件,可能还包含了诸如账号冒用、敏感数据泄漏、数据大量获取(存在离职倾向的员工等)等用户行为异常问题,故与传统安全相较,此类问题不是一般安全设备能够直接检测到的。
通过上述分析,可以看出对于现代的安全态势感知、安全管理产品或下一代安全事件管理系统等集中安全管理平台而言,就其检测和分析手段,不仅需要集成基于一般特征的规则(一般它们叫做关联规则,但与一般意义上的关联规则不同,如apriori等),而且需要包含能支持人工智能/机器学习的规则或策略。而spark或flink等相关开源框架可以提供相关支撑,但是这些框架存在如下问题:
其一是它们是由java开发的,而客户对于安全的投入较少,不太可能提供大量硬件以支撑它们的运行(相较于数据量而言;如果提供比较全面的分析,仅一台windows主机每日输出的日志数量就可能达到上千万);
其二是它们本身在提供分析语义上就存在不甚统一的问题,很难将基于特征、基于状态机分析、基于机器学习等方法完整统一,用户很难自定义一些策略规则;
其三是即使使用了一些机器学习技术来分析安全问题,也存在可视化和追溯困难(主要因为使用二维图、三维图等来展示高维数据,本身就难以理解和解释,即便使用了如主成分分析/等距线性嵌入方法)。
因此,亟需提供一种能支持各种数据来源,即不限于主机日志、网络设备日志、安全设备报警、网络传输流量、安全漏洞信息以及其它脆弱性信息的统一的安全检测框架,并且还可以使用户更容易的定义一些检测策略规则,以解决上述现有框架存在的问题。
技术实现要素:
本申请的主要目的在于提供一种基于多源安全检测框架的检测方法及系统,以提供一种能支持各种数据来源、并且可以使用户更容易的定义一些检测策略规则的统一的安全检测框架,并基于该种安全检测框架更高效的进行安全检测。
为了实现上述目的,根据本申请的第一方面,提供了一种基于多源安全检测框架的检测方法。
根据本申请的基于多源安全检测框架的检测方法包括:
根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子,所述多源安全检测模型为利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架;
根据选取的基础算子构建形式化检测策略;
基于检测策略进行安全威胁的检测。
可选的,所述根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子包括:
若各特征之间的存在时序关系,则选取取序列算子;
若各特征之间的不存在时序关系,则选取选择算子。
可选的,所述根据选取的基础算子构建形式化检测策略包括:
若各特征之间的存在时序关系,则根据取序列算子创建每个特征对应的检测函数,并结合且运算得到形式化检测策略。
可选的,所述根据选取的基础算子构建形式化检测策略包括:
若各特征之间的不存在时序关系,则根据选择算子创建每个特征对应的检测函数,并结合析取或且运算得到形式化检测策略。
可选的,在创建每个特征对应的检测函数之前,所述方法还包括:
根据投影算子和/或连接算子进行检测数据集的预处理。
可选的,若各特征之间的存在时序关系,得到形式化检测策略为:
且r1.time<r2.time<…<rn.time,
其中,seqfi(xi,ti)为取序列算子的形式化表示,ri为数据集,ri.time是时间属性,满足偏序关系,^表示合取。
可选的,若各特征之间的不存在时序关系,得到形式化检测策略为:
其中,σfi(r)为选择算子的形式化表示,ri为数据集,^表示合取,v表示析取。
为了实现上述目的,根据本申请的第二方面,提供了一种基于多源安全检测框架的检测系统。
根据本申请的基于多源安全检测框架的检测系统包括:
算子选取单元,根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子,所述多源安全检测模型为利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架;
检测策略构建单元,用于根据选取的基础算子构建形式化检测策略;
安全威胁检测单元,基于检测策略进行安全威胁的检测。
为了实现上述目的,根据本申请的第三方面,提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使所述计算机执行上述第一方面中任意一项所述的基于多源安全检测框架的检测方法。
为了实现上述目的,根据本申请的第四方面,提供了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器执行上述第一方面中任意一项所述的基于多源安全检测框架的检测方法。
在本申请实施例中,基于多源安全检测框架的检测方法及系统中,根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子,所述多源安全检测模型为利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架;根据选取的基础算子构建形式化检测策略;基于检测策略进行安全威胁的检测。看以看出,本申请中,多源安全检测框架可以支持对各种来源数据的检测,而且在检测策略构建时,只需要选择合适的检测算子进行组合就可以方便的得到,可以简化用户定义相关检测规则的流程;并且检测算子以及检测策略都是形式化的表达,使用和构建都非常的方便。因此,基于该种安全检测框架更高效的进行安全检测。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请实施例提供的一种基于多源安全检测框架的检测方法流程图;
图2是根据本申请实施例提供的一种基于多源安全检测框架的检测系统的组成框图;
图3是根据本申请实施例提供的一种多源安全检测框架的构建装置的组成框图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
在基于多源安全检测框架进行检测之前,必须先对多源安全检测框架的构建组成进行说明,多源安全检测框架是基于安全威胁情报技术构建的,能够支持各种数据来源,不限于主机日志、网络设备日志、安全设备报警信息、网络传输流量、安全漏洞信息以及其他脆弱性信息。多源安全检测模型能够利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架。下面对多源安全检测框架进行具体的说明,如下:
首先,基于stix设置安全检测框架的对象以及对象的表示,所述对象至少包括资产对象、脆弱性对象、日志或安全报警对象、威胁情报对象;
任何形式的框架都会涉及到一些基础的定义,本申请所提出的统一安全检测框架也不例外,故首先给出框架的相关定义,包括对象和检测算子的定义。首先是对象的定义,具体如下。
通过对stix(stix是一种描述网络威胁信息的结构化语言,stix能够以标准化和结构化的方式获取更广泛的网络威胁信息)的相关研究,可知:stix1.0定义了8种构件:可观测数据(observation)、攻击指标(indicator)、安全事件(incident)、攻击活动(campaign)等。stix2.0定义了12种构件:攻击模式(attackpattern)、战役(campaign)、应对措施(courseofaction)等。2.0将1.0版本中的ttp拆分为attackpattern、intrusionset、tool、malware;从exploittarget拆分出vulnerability;从威胁主体(threatactor)中拆分出identity、intrusionset;删去了incident;新增了report。
本申请实施例中对于相关对象(与构件相对应)的定义与上述存在一定差异,在实际应用中主要定义的对象包括如下几种,这几种都是与安全相关的对象,关于各对象以及对象属性的设置如下:
1.资产对象:资产对象是在整体安全策略中居于核心地位的对象,它是安全问题的承载者和处理安全问题的主体。用a表示一个资产对象的集合,资产对象主要包含的属性有相对静态部分,包括资产标识(可以唯一定位资产,如名称、ip地址、mac地址主机名等)、价值、操作系统类型等,还包含一些动态属性,如安装软件、开放端口、网络连接、补丁、账号/用户、脆弱性等,简单表示即资产是一个三元组:<id,static,dynamic>,其中id是资产的唯一标识,而static和dynamic则分别是资产的静态和动态属性集合;
2.脆弱性对象:与stix中定义的漏洞构件类似(脆弱性对象的实例可以成为资产的属性),其包含了唯一标识(如cve编号、cnnvd编号、脆弱性名称等等)、作用端口、影响系统等属性。简单起见,定义脆弱性为v,可以使用如下元组表示:<id,protocol,affcted>,其中id是脆弱性标识,而protocol是与网络协议相关属性集合,包含了作用端口和协议(如tcp、udp、icmp等传输层协议,也可能是如http、ftp等应用层协议),而affcted是受影响系统的集合;
3.日志或安全报警对象:日志或安全报警对象应具有类似的结构;这里不做区分,我们用e来表示日志或安全报警对象集合,此对象包含了标识、源、目的、原始信息、其它观测信息,其中源和目的不是狭义的源ip/端口、目的ip/端口等,而可能还包含mac、用户、区域等信息,原始信息包含了相关日志或报警的原生内容,而其它观测信息包含了无法纳入到上述属性的其它属性,如进程等等,较为形式化地可以表示为:<id,time,souce,dest,original,observable>,分别对应标识、产生时间、源、目的、原始信息和其它观测信息等;
4.威胁情报对象:这里所提出的威胁情报信息,实际上应与stix中的report构件相对应,它主要包括的属性为标识、指示器集合、工具集合、恶意软件集合等,我们用t表示,这些属性中比较重要的是恶意软件集合,它包含ttp的相关内容,对于我们进行黑客画像有着至关重要的作用,较为形式化地可以表示为:<id,indicator,tool,malware,intrusionset>,分别对应标识、指示器、工具、恶意软件、入侵集等。
另外,还需要说明的是,定义上述对象是为了结合安全攻击事件与威胁情报,定位攻击来源的类型和可能的黑客组织;或者某些攻击是针对特定漏洞,如针对struts的有关反序列化漏洞s2-048的攻击,是结合了安全事件“疑似strutss2-053(cve-2017-12611)漏洞利用攻击”与漏洞cve-2017-12611进行(若被攻击资产上包含有此漏洞);它们分属不同的对象类型。
其次,设置检测算子以及检测算子的形式化表示,所述检测算子包括基于关系代数的基础算子、机器学习算子、辅助函数。
与一般的数学上定义的算子(如泛函分析)或函数类似,在多源安全检测框架中,算子也是将空间中的元素映射为另一个空间中的元素,但它们也存在一些不同的地方,如这些算子一般不是什么严格意义上的线性空间中的线性算子(如巴拿赫/赋范空间或希尔伯特/向量空间的微分算子、积分算子、左移/右移算子等)。
本申请中的检测算子可以被划分为基于传统意义的基于关系代数的基础算子和机器学习算子,还有一些辅助函数也可被涵盖在内;但它们都具有空间映射功能,即将向量空间的元素映射为实数空间的元素,如求集合元素数量。
另外,在实际应用中,始终无法回避的是在很多情况下,时间是一个必须要考虑的因素,此处主要与日志或安全告警及其相关生成集合存在联系,因为在很多安全场景下,时间序列是一定的。
一、基于关系代数的基础算子:
标准的关系代数中所涉及的基础算子共有五种,分别是结合的并、差、笛卡尔积以及选择、投影算子;但本申请所涉及的算子中,主要是为了满足一般的数据处理所需,而且我们一般其实并不需要支持集合的差运算,另外针对笛卡尔积运算而言,在绝大多数场合下,实际上都是有条件的或者自然连接运算,它用于扩充元组。本申请中进行了一些改动,从安全分析的实际出发,使用如下几个算子,分别是:
1.选择算子:选择算子与过滤器类似,从形式上来看即是从空间集合中筛选符合条件的子集,在多源安全检测框架中,空间集合主要是针对日志或安全告警而言的,当然也包括这些日志或安全告警集合与其它对象的联合筛选,形式化地可以记作:σf(r)→r′(1)
其中,r和r′分别是筛选前后的日志或安全告警,r′是r的一个子集,f是筛选条件,此类对象在前述中没有提及,其内容并不复杂,主要包含各类对象的属性运算条件的合取或析取范式;
2.n选择算子:从符合条件的集合中获取n条记录,类似sql中的limit运算,其形式与选择算子类似,形式化地可以记作:
其中l为整型数值,是一个有序集合中的起始位置,n选择算子含义为从排序集合中获取从l条记录开始的n条记录。
3.投影算子:与传统意义上的投影算子类似,主要含义是从集合空间上的相关元素的属性中,选取若干属性生成新的集合,新生成的集合可以理解为原空间的子空间,故在一般情况下它们的维数是不同的,形式化地可以记作:
π(r)→r′(3)
其中,r′是r的子空间,其元素的个数与r相同,但属性维度变少,即其属性仅是原空间的子集,即dim(r)>dim(r′);
4.连接算子:与关系代数中的连接算子并无二至,其作用是通过一定条件连接两个集合,生成新的关系,如果不指定条件,是自然连接,是在实施连接运算时只考虑某些具有相同属性(这些属性应来源于相同的域)值的记录,形式化地记作:
其中,r1,r2分别是两个集合,而f是连接条件,可以为空,r是连接后生成的新的集合空间;
5.分组算子:在传统的关系代数中,没有这个算子或者运算,为了方便地对相关数据进行处理,则加入此算子;就形式上而言,分组算子是将一个集合按照某个条件进行划分,得到一个由集合组成的集合,即其结果是集类,形式化地可以记作:
其中,r是原始集合,而ri是在条件f下的对于集合r的划分,它们的交集为空,而在实际使用时,一般f条件都是某个属性或者某些属性相等,如同distinct或者groupby语句产生的效果;
6.空间膨胀算子:主要作用是对当前的集合空间进行扩展,相当于在一定的属性基础上通过一定方法增加一些新的属性,而这些新的属性一般是通过原有属性利用给定方法生成的,其形式化地记作:inflatef(r)→r′(6)
其中,f为膨胀的方法,如将r中的两个属性相加或者平均生成新的属性,也可以是某些属性通过字符串连接运算而得到新的属性,甚至是可以直接插入一个到多个新的属性,可以给这些新的属性赋默认值;另外也可以根据集合域的所有取值情况来膨胀空间,如所有国家/地区、所有2个字母的组合等;显然dim(r′)>dim(r);
7.取序列算子:对于日志或者安全告警而言,时间属性是相当重要的,故本申请提出一个取序列的算子以满足此类操作,可以形式化地记为:
seqf(x,±t)→r,t∈t(7)
其中,x是集合中的元素,而t是时间长度,其算子含义即为在元素x发生时间向前t时间或者向后t时间内获取相关符合条件的集合(结果集中含元素x),其中f是给定的条件,它可以对相关元素进行筛选。
8.映射算子:加入映射算子主要是能将集合空间中相关的一些属性进行映射,一般是将一些枚举值映射成数值,或者利用一些常见函数将属性变换为其它值,其形式化的表示方法如下:mapf(r)→r′(8)
其中f是具体的映射方法,定义域一般是某个属性,而值域一般为数域或其它常见类型,如果需要变换多个属性,则可以多次调用,不再赘述。
二、机器学习算子
在安全检测框架中,机器学习也是一类比较重要的方法或手段,用户运用它们可以发现一些无法完全使用基于传统特征手段进行检测的场合,也是为了发现一些高级威胁或未知威胁,这是现代安全态势感知系统、安全管理系统或者下一代安全事件管理系统必须具备的能力之一,但考虑到安全检测的实际场景,并根据一些常用的工具,如sklearn、flink的机器学习框架等提供的能力;但在本申请的多源安全检测框架中没有必要提供过多的机器学习方法,主要考虑一般性的算子以覆盖主要场景即可;从大类上而言,只关注回归、分类、聚类以及降维即可,其中回归和分类是有监督的机器学习算法,而聚类是无监督的聚类算法,降维则其实是对高维数据进行处理,一般使用pca(主成分分析)方法就能满足实际运用。
在现代信息安全的要求下,机器学习的主要焦点还是如何对数据建模,而在本申请是如何从动态变化的日志及安全报警中抽取相关特征向量,其实在前述中的基础算子是进行类似处理的部分,而且配合一些如归一化、向量运算、求统计分布等处理就可以基本满足安全检测的要求。
1.回归算子:在机器学习领域内,回归方法与一般的分类算法其实没有特别大的差别,主要区别在于最后的输出部分,即可以认为分类是回归的离散化,回归算法在如sklearn等框架中有基于线性的回归、逻辑回归、岭回归、混合高斯等方法,本申请不进行具体讨论和扩展,一个回归算子可以形式化记作:
regressionf(x,x)=r,r∈rn(9)
式中f是一个具体的回归算法,而x和x分别是需要学习的回归数据集合以及需要验证的数据元素,而r是取值在实数范围内的数值或向量,故可以认为回归是从集合空间到实数空间或实数向量空间的映射;
2.分类算子:如前所述,分类本质上与回归没有什么差别,仅是将回归的结果映射到不同的分类上而已,故就其形式而言,与公式(9)没有本质的不同,这里用正整数来表示分类的结果情况(至于结果是正常的还是不正常的则不在此处反映),形式化的可以记作:
classificationf(x,x)=r,r∈z+n(10)
此公式与回归算子类似,相关符号的定义不再赘述,只是其结果映射为正整数,而n是分类的数量。
3.聚类算子:聚类方法本身是一种无监督的算法,它可以指定结果分为几类或者按照指定的领域自动聚合为若干类(如dbscan)等等,本申请不去区分到底是使用何种聚类算法,因为聚类算法也有多种(如kmeans、山峰聚类、谱聚类、高斯混合等等),而且本申请并不是讨论机器学习算法在安全数据处理方面具体应用为主要目的;聚类算子形式上与分组算子类似,在不考虑噪声的数据情况下,即通过一定方法将原始的数据集划分为一个集类,每个集类中的一个元素则为同一类,可以形式化地表示为:
从上述形式看出,此公式与分组算子基本相同,只是这里的f为具体的聚类算法(包含聚类算法的各种参数等等),n为最终聚类的数量,不同的是对于类别的划分而言一般是基于向量空间的度量方法,即基于距离的;
4.相似度算子:严格地说,相似度的计算不能完全算作是机器学习算法的一部分,无论是使用余弦相似、jaccard相似等等,但在一些场合,它确实是用于检测未知威胁的利器,比如资产变动、模式变化等等,其形式化的记作:
simf(x1,x2)→r,r∈[0,1](12)
在上式中f是具体的相似度计算方法,其输出结果为区间[0,1]之间的一个实数,即相似的程度是怎样的;
5.降维算子:主要应用一般在可视化中;其算子映射方法的形式和投影算子比较类似,可以形式化的记作:drf(r)→r′(13)
其中f为具体的降维算法,而dim(r)>dim(r′)且保留下来的属性应是具有显著特征的那些属性,故降维主要还是应用于数据预处理的场合。
三、辅助函数
在实际运用中,除了上述基础算子以及机器学习算子以外,还需要提供一些额外的辅助函数(实际上也可认为它们都是算子)方能覆盖应用;这些辅助函数被划分为以下若干类别,本申请从实用角度对其分别进行一定的描述:
1.时间函数:支持一般的时间运算(时间加减)、格式化、从时间中获取年/月/周/星期/日等基本运算;2.数学函数:支持一般的如绝对值、平方根、除法取余、取整、随机、四舍五入、符号、幂运算、对数运算、三角函数运算等数学基础函数;3.统计函数(聚合函数):支持如求计数(count)、求和、求最大、求最小、求期望、求方差等基础统计函数;这些函数的输入均是向量,另外支持针对向量的概率分布计算函数,其输入亦是向量,输出按指定间隔(如每5%)返回概率分布向量;4.距离评估函数:按指定距离评估方法,计算两个向量之间的距离,距离评估方法包括曼哈顿、欧几里得、切比雪夫、闵可夫斯基以及海明距离等;5.字符串函数:支持如字符串的大写转换、小写转换、比较、子串匹配、子串正则匹配、字符串连接、取字符串长度、字符串替换、字符串trim等等;6.矩阵/向量运算函数:支持如矩阵的加法、减法、乘法、转置、求特征值和特征向量等;7.归一化函数:支持对向量进行归一化运算,得到的结果仍是一个向量,可以采用最大-最小归一化等方法;8.序列化/反序列化:由于需要在安全检测中对中间结果进行暂存,或者从其它策略中获取暂存的数据以进行后续处理(一般用于机器学习部分、用户界面展示),故提供此操作可将中间数据进行暂存;暂存的内容类似于二维表形式,有统一的序列号与之对应。
另外,还需要说明的是,本申请中的多源安全检测框架主要基于c/c++进行,因为类似spark等框架是基于java的,在单节点或节点较少的情况下无法高速、有效地处理大规模数据,而且因为需要支持多种混合数据,故显得捉襟见肘。
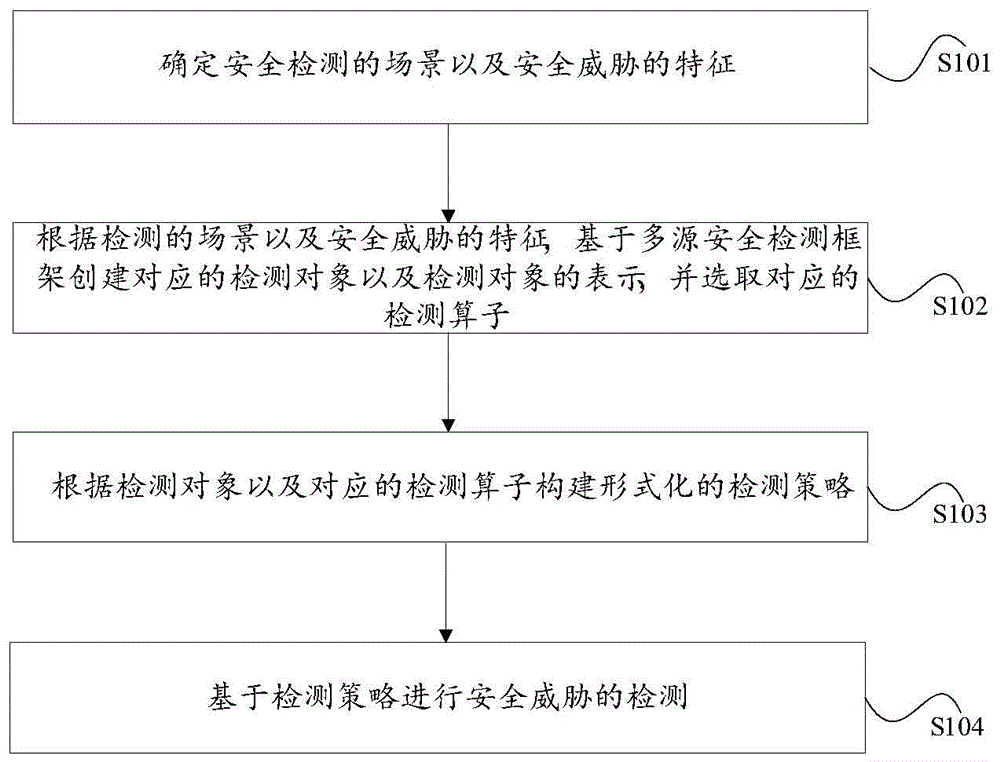
本实施例提供了一种基于多源安全检测框架的检测方法,如图1所示,该方法包括如下的步骤:
s101.确定安全检测的场景以及安全威胁的特征。
具体的,本实施例的安全检测场景分为基于基础规则的检测场景、基于时序状态的检测场景以及基于机器学习的检测场景,这些场景就基本上覆盖了安全检测的需要。另外需要强调的一点是,为了使发现的安全问题可以被处理,所有满足条件的数据集一般必须绑定到同一个资产对象或用户上,否则可能导致无法对结果进行处理和解释,即在日志或安全报警中的相关属性中都出现相同的内容。
安全威胁的特征为安全威胁在网络系统中的一些表现,比如,对于恶意软件为名为“jhuhugit”,为黑客组织apt28所经常使用,它的主要特征包括如下内容:1.修改注册表hkcu\environment\userinitmprlogonscript用于自身程序的持久化;2.对浏览器进程进行远程过程注入;3.注册定时任务;4.创建http或https网络连接,与僵尸主机进行通讯,而且其目的地址/域名如果出现在威胁情报的指示器中。
s102.根据检测的场景以及安全威胁的特征,基于多源安全检测框架创建对应的检测对象以及检测对象的表示,并选取对应的检测算子。
具体的,根据安全威胁的特征可以确定检测对象,比如对于上述步骤中的安全威胁“jhuhugit”,第1-3个特征对应的信息可以在主机日志中获取,因此对应的检测对象包括主机日志,第4个特征对应的信息可以在流量通讯日志中获取,也可以在安装了如sysmon工具的主机日志中发现,因此对应的检测对象包括流量通讯日志以及sysmon工具的主机日志。综上,可以确定安全威胁“jhuhugit”的检测对象为主机日志和流量通讯日志。
确定检测对象后,根据前述不同对象的表示规则获取对象的属性值,得到检测对象的表示。
对于检测算子的选择,需要根据检测的场景以及安全威胁的特征等进行选择,比如对于基于基础规则的检测场景,通常选择基于关系代数的基础算子、和辅助函数就可以了;对于基于时序状态的检测场景通常选择基于关系代数的基础算子、和辅助函数就可以了,与基于基础规则的检测场景不同的是,基于时序状态的检测场景中一定会选择基础算子中的取序列算子;对于基于机器学习的检测场景,需要选择基于关系代数的基础算子、机器学习算子以及辅助函数。
s103.根据检测对象以及对应的检测算子构建形式化的检测策略。
检测对象和检测算子确定后,构建形式化的检测策略。构建形式化的检测策略需要根据各检测算子的公式,设置公式中包括的参数的值,然后将各检测算子进行组合得到检测策略。
下面给出几个简单的形式化的检测策略。检测策略是由一个或者多个检测表达式组成的。
上式为一个检测表达式,其中用到了选择算子,数据集r为检测对象,fi(i=1,2,…,n)表示不同的过滤条件。上述检测表达式表示根据不同过滤条件fi,其结果集都不能为空,符号“^”是“且”,即满足所有的过滤条件的才可以确定存在要检测的安全威胁。
s104.基于检测策略进行安全威胁的检测。
完成检测策略的构建后,就可以通过执行检测策略进行安全威胁的检测,检测完成后根据检测的结果可以判断是否存在威胁。
从以上的描述中,可以看出,本申请实施例的基于多源安全检测框架的检测方法中,首先,确定安全检测的场景以及安全威胁的特征;然后根据检测的场景以及安全威胁的特征,基于多源安全检测框架创建对应的检测对象以及检测对象的表示,多源安全检测模型为利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架;并,基于检测的场景以及安全威胁的特征在多源安全检测框架中选取对应的检测算子;最后,根据检测对象以及对应的检测算子构建形式化的检测策略;并基于检测策略进行安全威胁的检测。看以看出,本申请中,多源安全检测框架可以支持对各种来源数据的检测,而且在检测策略构建时,只需要选择合适的检测算子进行组合就可以方便的得到,可以简化用户定义相关检测规则的流程;并且检测算子以及检测策略都是形式化的表达,使用和构建都非常的方便。因此,基于该种安全检测框架更高效的进行安全检测。
作为上述实施例的进一步的补充和细化,本实施例针对每一种检测场景进行分别说明。
一、基于基础规则的检测场景:
一般而言,此类规则或策略在安全检测中占据主要地位,其覆盖的场景较多,结合当今att&ck(adversarialtacticstechniquesandcommonknowledge)框架(att&ck一般是针对恶意软件相关分析的,它在威胁溯源和分析中占有重要地位,一般单纯的网络攻击是不需要与其结合的,如分布式拒绝服务攻击(ddos),但针对木马、病毒、勒索软件、广告、挖矿等则需要与其结合,特别是利用网络流量和主机日志进行综合分析的时候),可以对大多数安全场景进行检测;其基本原理比较简单,是在策略规则中可以包含一个到多个选择算子,针对不同的设置,可以指定它们都匹配或者匹配部分甚至匹配其一即可,对于完全满足则其形式化地能写为如下方式:
即根据不同过滤条件fi,其结果集都不能为空,符号“^”的含义是“且”,而对于匹配部分过滤条件(包括仅需满足一个)的则可以写为如下形式:
其中,符号“v”表示析取,即只要满足一个过滤条件就可以了,其结果集只需要部分不空。
以下以对黑客组织apt28所经常使用的一个恶意软件名为“jhuhugit”进行检查为例,采用主机运行日志和网络流量日志同时进行检测,它的主要特征包括如下内容:
1.修改注册表hkcu\environment\userinitmprlogonscript用于自身程序的持久化(此信息可在主机日志中获取);2.对浏览器进程进行远程过程注入(使用createremotethread,此信息可在主机日志中获取);3.注册定时任务(此信息也可在主机日志中获取);4.创建http或https网络连接,与僵尸主机进行通讯(此信息可在流量通讯日志中获取,也可以在安装了如sysmon工具的主机日志中发现),而且其目的地址/域名如果出现在威胁情报的指示器中(如请求恶意域名cdnverify[.]net),则更可增加可信度。
那么针对上述特征可以通过多个选择算子联合对其进行发现,每个特征可以对应创建一个选择算子,并设置过滤条件、检测的数据集(r),然后根据检测的要求,可以将多个选择算子通过“^”或者“v”进行连接,完成检测策略的构建。
另外,还需要说明的是,在实际应用中基于基础规则的检测场景也会涉及到投影算子、连接算子等。对于投影算子,因为安全事件的字段太多,一般不需要去关心所有字段,因此需要通过投影算子选择部分字段进行检测;对于连接算子,通常会在针对漏洞攻击的场景中使用,如针对“microsoftiis远程代码执行攻击(cve-2017-7269)”就可将安全事件攻击特征和对应被攻击资产的漏洞情况进行连接,其连接属性是安全事件的ip地址和资产的ip地址及漏洞cve编号(通过漏洞扫描发现)
二、基于时序状态的检测场景:
本质上基于时序状态与基于基础规则的检测场景没有特别大的区别,只是这些被选择出来的集合应该存在偏序关系,一般使用取序列算子就可以满足,但需要指出的是在基于时序状态的检测中,一般每个序列都应需要满足,而不存在仅满足一部分即可,形式化地可以记作:
且r1.time<r2.time<…<rn.time,
在上述公式中,seqfi(xi,ti)为取序列算子的形式化表示,ri为数据集,ri.time是检测对象(日志或安全报警)的时间属性,它们满足偏序关系,而符号“^”表示合取。
以下以恶意软件emotet为例,解释下如何使用基于时序的方法来进行发现:
1.首先,对于主机收邮件的日志,判断其邮件地址是否在ioc(即失陷指示器,indicatorofcompromised)中;附件中是含有宏的word文件,其中嵌入了powershell代码;2.其次,如果运行word文件,它会从相关网站上下载执行代码,一般这几个网站地址是依次进行的;3.然后,如果主机被植入相关下载的软件,它会修改注册表项以开机自启,即持久化;4.利用ms017-010漏洞(即永恒之蓝,eternalblue)对内网中的机器进行探测如可能则进行渗透,即所谓的横向移动,此类报警可以从入侵检测系统上获得;或者它对网银程序进行注入,记录登录数据等机密信息。
上述动作1-4一般是被顺序执行的,所以可以使用去序列算子构建检测策略行检测,可以提高整体可信度。每个动作对应一个emotet的特征,具体的,对于每个特征可以选择一个取序列算子,并设置对应的条件f,关键的是还需要设置每个取序列算子中元素的时间属性存在的偏序关系,偏序关系与动作的执行顺序相对应。以此检测策略进行安全检测,可以准确的判断是否存在安全威胁。当然,在实际的应用中,如果无法确定动作的顺序,可以将其作为基于基础规则的检测场景进行检测,以避免因顺序上的错误而无法获得准确的匹配结果。
对于前述两种检测场景,也可以综合到一起得到一个非机器学习的基于多源安全检测框架的检测方法,如图2所示,包括如下流程:
s201.根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子;
具体的,若各特征之间的存在时序关系,则选取取序列算子;若各特征之间的不存在时序关系,则选取选择算子。
s202.根据选取的基础算子构建形式化检测策略;
具体的,若各特征之间的存在时序关系,则根据取序列算子创建每个特征对应的检测函数,并结合且运算得到形式化检测策略。具体的检测策略参见基于时序状态的检测场景中的描述。若各特征之间的不存在时序关系,则根据选择算子创建每个特征对应的检测函数,并结合析取或且运算得到形式化检测策略。具体的检测策略参见基于基础规则的检测场景。
s203.基于检测策略进行安全威胁的检测。
三、基于机器学习的检测场景:
在信息安全领域中,机器学习有着广泛的应用,如使用贝叶斯方法或深度置信网络识别垃圾/钓鱼邮件,使用深度卷积神经网络识别恶意软件变体,使用ltsm、svm等识别动态生成域名等等,但这些方法一般都是针对实际网络中的负载部分或实际文件数据,需要大量已经做了标识的正向和负向样本进行训练和验证,而且它们一般都使用线下学习(有监督学习)、线上检验地方式,但在本申请所涉及的实际场景下,这种方式可能不太适用;因为其一框架处理的是线上数据,而用户也不知道哪些是正常的数据、哪些是异常的数据;其二在这个检测框架中,所能涉及的数据不太可能深入底层原生数据,往往仅是一些较为简略的描述。故鉴于上述原因,一般只能采用线上学习,结合无监督和半监督方法进行检测,在这个过程中可能需要用户进行干预,即对获取的基础数据令用户进行参与,让其对数据集进行一定程度的标记,再利用其在向量空间上的距离特性进行聚类,从而较为清晰地对正向和负向数据进行分离(比较方便地是,在信息安全领域中,一般只要关注二分类问题即可,而一般无需特别注意多分类问题,但如对于恶意软件的家族识别、动态域名生成算法类型的识别是多分类问题)。
考虑到机器学习场景的多样性和复杂性,以及用户可以承受的学习成本包括机器学习结果的可视性、可解释性、可追溯性等相关因素,在本申请中的场景主要为实用的、有代表性、不过于复杂的场景。
另外,即使使用机器学习方法,也必须使用一些基础算子以生成数据集进行机器学习的检验,故类似如选择算子、投影算子、映射算子等基础算子也会被应用,所以在使用机器学习方法进行安全问题检测时一般包含数据选择/预处理以及数据检测两个主要部分。
对于机器学习场景检测场景,本实施例提供一种基于多源安全检测框架的机器学习场景检测方法,包括如下步骤:1.根据安全威胁的特征从多源安全检测框架中选取基于关系代数的基础算子以及机器学习算子。2.根据关系代数的基础算子以及机器学习算子构建检测策略。3.基于检测策略进行机器学习场景的安全威胁检测。
具体的,根据关系代数的基础算子以及机器学习算子构建检测策略包括:根据基于关系代数的基础算子构建用于线上学习数据集选择和/或预处理的形式化检测策略;根据机器学习算子(主要为相似度算子)构建用于对检测对象进行异常检测的形式化检测策略。线上学习数据集为通过线上学习的方式,确定后续进行待检测或者待检验数据安全威胁判断的参考标准的数据集。
本实施例中,机器学习场景包括异常偏离场景、相似度异常场景、序列异常场景。具体的:
若机器学习场景为异常偏离场景,根据基于关系代数的基础算子构建用于线上学习数据集选择和/或预处理的形式化检测策略包括:根据选择算子、分组算子和辅助函数构建线上学习数据集筛选、分组、统计、求期望的检测策略。
若机器学习场景为相似度异常场景,根据基于关系代数的基础算子构建用于线上学习数据集选择和/或预处理的形式化检测策略包括:根据选择算子、投影算子、分组算子、膨胀算子、辅助函数构建线上学习数据集筛选、分组、增加属性、集合并的检测策略。
若机器学习场景为序列异常场景,根据基于关系代数的基础算子构建用于线上学习数据集选择和/或预处理的形式化检测策略包括:根据选择算子、投影算子和辅助函数构建线上学习数据集筛选、分组、集合并、统计、求分布的检测策略。
下面针对三种常用的基于机器学习的检测场景进行说明:
1.异常偏离场景
异常偏离场景是一种比较传统意义上的、较为简单的机器学习异常检测场景,可以将其理解为基于统计的检测方法,它可以适用于比较广泛的安全检测上下文中,例如简单的网络访问吞吐异常、用户登录行为异常等等;以下以邮箱发送/接收异常为例,说明在多源安全检测策略框架下是如何运作的。
一般而言,用户邮箱的发送邮件存在周期性的规律,其发送或接收的邮件会在一个正常水平范围内波动,如果出现一定偏离(主要是正偏离),则有理由相信邮箱账号沦陷(从发送角度而言)或者接收了大量的垃圾邮件(从接收角度而言),而邮件网关未做必要的过滤。
首先需要利用选择算子从相关日志数据中获取邮件收发信息中某用户的邮箱信息(线上学习数据集)并按日期进行分组和计数:σf1(r)→r1,πf2(r1)→r2,count(r2)→r3
在上述公式中,最后一部分是对集类中的每个集合进行计数,形成集类并将集类中的所有元素合并成集合r3,然后再将r3中的相关元素的所有计数求期望:
如果s的值和相关需要检测的收发邮件的某段时间的数量出现较大偏差(偏差值可由用户指定)则认为出现了异常;另外,如果需要出现针对不同的小时范围进行检查,可以把结果集再进行划分(比如按照24小时进行划分),那么可以形成一个基线向量,则上述公式可以改写为:
其中,
需要说明的是,s的值和相关需要检测的收发邮件的某段时间的数量之间的偏差可以通过选择相似度算子构建检测策略实现,具体的,是将s的值和相关需要检测的收发邮件的某段时间的数量作为相似度比较的对象,然后得到相似度,根据相似度的大小来衡量两者之间的偏差,根据偏差的大小来进行是否存在安全威胁的判断。同样,将对应的某日收发邮件数量按小时组合成向量,分别检查也可以通过选择相似度算子构建检测策略实现。具体的,将由线上学习数据集处理得到的收发邮件数量按小时组合成向量和需要检测的某日的收发邮件数量按小时组合成向量作为相似度比较对象,然后得到相似度,根据相似度的大小来衡量两者之间的偏差,根据偏差的大小来进行是否存在安全威胁的判断。
2.相似度异常场景
在多源安全检测策略框架下,相似度的检测应该包含了横向相似(即不同对象之间的相似性)以及纵向相似性(即某个对象与其历史上的表现是否相似)。在实际场景中,一般后者的应用范围更为广泛。
以一个例子来说明如何构建检测策略来进行相似度的检测:vpn用户登录地区异常。此例的实际意义是检测用户的vpn账号是否被盗用,这个场景其实与邮件发送地区异常、用户操作时间异常等类似,均可以采用相似的流程和方法进行,其步骤如下:
利用选择算子过滤某个用户的最近若干天的vpn类登录日志(线上学习数据集),选取日期和源vpn区域属性,并按日期进行分组:
σf1(r)→r1,πf2(r1)→r2,τf3(r2)→r3
其中f1是过滤条件,包含了用户名、时间以及日志类型条件的合取,而f2中是日期(无时间)、区域字段(可以通过ip地址利用map算子映射获得),而f3是将结果集按日期进行分组,得到的结果r3是一个分组后的集类,由于分组字段为日期,故在集类中同一个集合中的元素均是不同的源区域,使用计数函数将集类中的每个集合进行压缩,并将计数生成为新的一个属性:
inf(r3)→r4
其中r4也是一个集类,并且它们都增加了一个计数属性,将r4中的每个集合中的元素转换为一个向量,每个向量中的某一维就代表某个区域(如国家、省份或者城市,这里需要提供一个维度和区域的映射方法),则其维度是区域的总体数量,然后将向量中的每个元素进行0-1化,即大于0的数值映射为1,否则映射为0,而某个维度不为0则表示其有登录行为,此集类命名为r5;将集类中的每个元素做集合并运算,得到一个新的集合:
至此数据的预处理部分完成,其实质上是得到一个按日划分的、每个维度为不同区域的向量集合,现设需要检验的向量为r(某日vpn地区登录情况),可以使用如下方法进行(这是一个平均相似度):
根据上述公式所得到的值是某日vpn登录情况与历史相较的结果,比较极端的当s为0时就表明历史上从来未在某个或某些区域执行登录操作,用户可以设定一个[0,1]之间的阈值,若低于这个阈值则存在异常否则应为正常行为。
通过上述过程可以看出,其实这是一个无监督的检测方法,当然如果用户能对r6中的数据进行部分标识,则可以从正负两个方面进行检验,这样所得到的结果应该更为可信,不过提供用户参与的界面必须简单易懂,这需要对最后得到的数据有个比较明确的解释或图形化的展示,如提供地图、直方图、气泡图、分布图、雷达图等进行标识,使用户可能充分利用这些界面对数据有较为直观的认识;当然如果系统存储空间允许,我们应尽量保存每个步骤中的临时数据,以提供明确的挖掘路径信息。
需要说明的是,上述数据预处理过程中的形式化的公式即为根据选择算子、投影算子、分组算子、膨胀算子、辅助函数构建的线上学习数据集筛选、分组、增加属性、集合并的检测策略。
3.序列异常场景
主要应用在用户行为异常的上下文中,其主要诉求是对用户操作顺序的存在异常,当然也可以用于任意的序列异常场景,其基本方法是利用n-gram(一般n是2或3,不宜过大否则造成样本空间规模不可控)从原始数据中抽取出来,然后使用概率分布进行计算,然后用需要校验的数据进行符合性检查,其本质实际上是利用马尔可夫转移概率进行计算和验证。
以用户操作某应用系统的模块为例,给出检测策略构建和检测的方式:
首先利用选择算子和投影算子获取相关操作记录,筛选条件为某个用户在若干天内的所有操作记录,按时间升序,投影的属性为其操作的模块,如下:
σf1(r)→r1,πf2(r1)→r2,
在上式中,使用n选择算子分别从集合r2中获取|r2|-1个子集(对于n-gram方法而言,此处n为2)组成一个集类,然后将每个集合中的记录(每个集合只有两个元素)进行拼接形成一条记录,结果形成r4,对r4进行计数得到r5,将r5中的计数列转变成一个向量r,对r中的计数求分布得到处理后的向量r′,r′中每一维对应了一种序列,如下:r(r′1,r′2,...,r′n),其中
然后,利用类似的方法得到某一待检数据r″,其维度与r′相同,而且维度顺序一样,按照维度对应位置获取r″的在r′中的概率和p,若p小于某个指定阈值(如0.01),则可以认为待检序列中存在罕见操作序列。
需要说明的是,得到向量r′的过程中所涉及的公式为线上学习数据集筛选、分组、集合并、统计、求分布的检测策略。按照维度对应位置获取r″的在r′中的概率可以通过相似度算子实现,具体的,可以将r″和r′中对应位置的序列作为相似度比较的对象,计算得到相似度,相似度的值可以衡量r″的序列在r′中的概率,然后计算得到概率和。
需要指出的是,这些序列可以由用户进行检视,指出是否存在异常的内容并剔除一些没有必要检测的序列,例如针对工控指令的序列异常检测等,这样能够提高整体模型的工作效率和可信程度。
另外,需要说明的是,前述机器学习的检测场景中都主要用到了相似度算子,在实际的应用中,其他的机器学算子也会根据实际的需求进行选择应用,比如机器算子中的聚类算子,用户可以指定资产集合,使用它们的端口开放特征以及这些端口上的通信流量进行聚类,聚类的方法非常简单,即可按照它们开放的端口进行直接分组就可获得资产集合的划分,设置一个重叠阈值即可将不同的资产对象进行分组,对于分组异常的资产则可以认为它们存在问题。而机器算子汇总的降维算子等实际是数据预处理的一部分,它们一般并不能单独使用;而利用相似度算子进行检测恰是可以对类似“稀少”和“暴增”问题进行检测的最有效方法,而本申请中的检测框架的目的是为了简化用户定义相关规则的流程,故一般只关心“稀少”性问题或者“暴增”性问题,所以基本以此为例进行说明。
最后对申请的有益效果进行总结:
本申请的目的旨在提出一个基于多种混合数据来源,在统一的策略框架下提供综合安全检测的机制,以满足一般安全态势感知系统、安全管理系统或者下一代安全事件管理系统的需要,在这个框架中主要利用预定义的算子组合对各种数据进行检测,这些数据包括了传统意义上的日志或者安全报警、各类脆弱性以及近年来在安全检测中具有重要作用的威胁情报。
此框架给出了一些基础算子以及机器学习算子等的一般形式化的描述,需要指出的是本框架无意于提供一般机器学习框架的所有算法,因为从安全实践出发,用户是无法掌握这些复杂的、种类繁多的算法,也完全不知道如何选择算法和对安全数据进行检测,这势必降低系统的可用性;另外,如前所述,这样也基本上没有什么可解释性和可追溯性,故将安全问题检测的机器学习范围固定在一个可控的范围内是比较合适的,也是比较符合一般的网络空间安全实践,如果用户有较为复杂的机器学习需求可以视其是否具有通用性以决定需要增加新的固定模型,例如分组异常模型(其中比较典型的是用户分组异常,这是一个横向异常检测模型,即用户出现跨组访问异常,这在审计用户越权操作中具有比较重要的作用),如果过于复杂并不具有代表性则可以考虑直接嵌入脚本实现而不一定需要通过界面定义,当然考虑到安全因素,一般不允许直接上传脚本。
统一的安全检测框架本身是一个非常复杂的问题,它其实不仅包含了各类检测方法,而且它在主动安全防御框架中也处于核心位置,它对安全风险评估、态势预测、安全处置(如soar)等具有重要意义。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
根据本申请实施例,还提供了一种用于实施上述图2方法的基于多源安全检测框架的检测的系统,如图3所示,该系统包括:
算子选取单元31,根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子,所述多源安全检测模型为利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架;
检测策略构建单元32,用于根据选取的基础算子构建形式化检测策略;
安全威胁检测单元33,基于检测策略进行安全威胁的检测。
具体的,本申请实施例的装置中各单元、模块实现其功能的具体过程可参见方法实施例中的相关描述,此处不再赘述。
从以上的描述中,可以看出,本申请实施例的基于多源安全检测框架的检测的系统中,根据安全威胁的各特征及其之间的关系从多源安全检测框架中选取基于关系代数的基础算子,所述多源安全检测模型为利用预定义的检测算子组合得到检测策略以对各种来源数据进行安全检测的统一检测框架;根据选取的基础算子构建形式化检测策略;基于检测策略进行安全威胁的检测。看以看出,本申请中,多源安全检测框架可以支持对各种来源数据的检测,而且在检测策略构建时,只需要选择合适的检测算子进行组合就可以方便的得到,可以简化用户定义相关检测规则的流程;并且检测算子以及检测策略都是形式化的表达,使用和构建都非常的方便。因此,基于该种安全检测框架更高效的进行安全检测。
具体的,本申请实施例的装置中各单元、模块实现其功能的具体过程可参见方法实施例中的相关描述,此处不再赘述。
根据本申请实施例,还提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机指令,所述计算机指令用于使所述计算机执行上述方法实施例中的基于多源安全检测框架的检测方法。
根据本申请实施例,还提供了一种电子设备,包括:至少一个处理器;以及与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器执行上述方法实施例中的基于多源安全检测框架的检测方法。
显然,本领域的技术人员应该明白,上述的本申请的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本申请不限制于任何特定的硬件和软件结合。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!