一种现场行车音视频云发布系统及方法与流程
本发明涉及音视频云发布技术领域,更具体的说,涉及一种现场行车音视频云发布系统及方法。
背景技术:
随着汽车功能的升级,用户提出了对行车音视频分享的需求。目前,市面上的车机设备在将行车音视频分享至第三方视频平台时,需要先将现场行车音视频上传至手机,然后通过手机中的第三方视频app导入本地视频再发布。
由于传统的行车音视频发布过程需要经过手机下载和转发才能最终发布至第三方视频平台,因此,行车音视频分享链路比较长,且用户无法在行车过程中实时发布现场行车音视频。
技术实现要素:
有鉴于此,本发明公开一种现场行车音视频云发布系统及方法,以实现整个行车音视频数据发布过程不需要经过手机,缩短行车音视频分享链路,实现在行车过程中实时发布现场行车音视频。
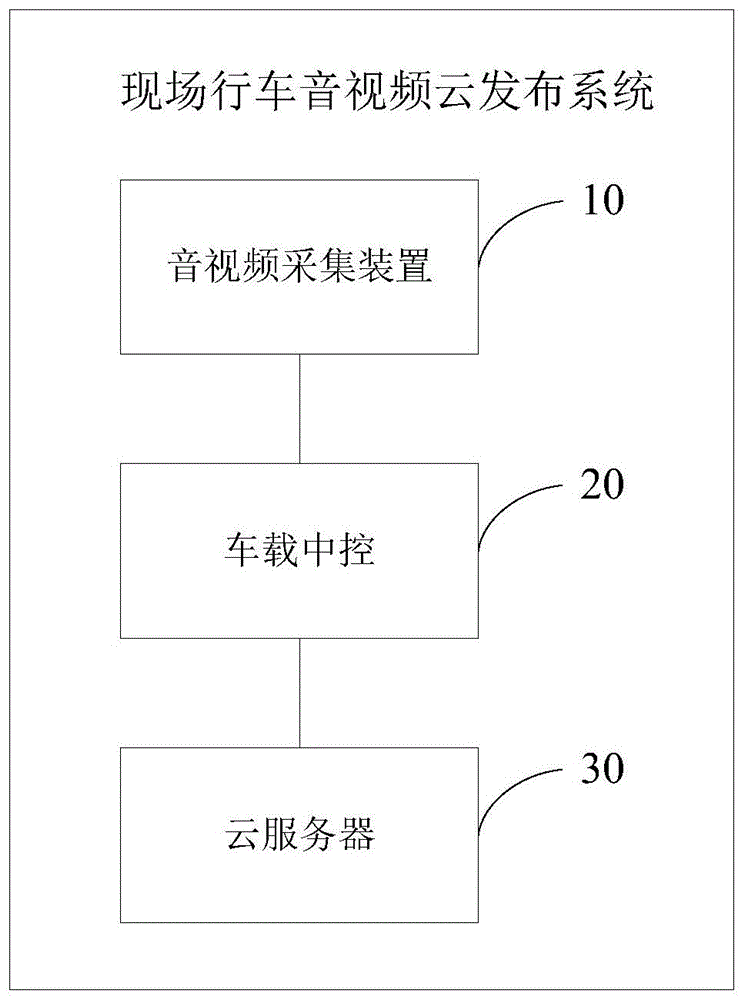
一种现场行车音视频云发布系统,包括:音视频采集装置、车载中控和云服务器;
所述音视频采集装置,用于采集现场行车音视频数据;
所述车载中控,用于在接收到用户语音输入的音视频采集指令后,获取所述音视频采集装置采集的所述现场行车音视频数据,并对所述现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;
所述车载中控,还用于在接收到用户语音输入的音视频发布指令后,获取已登录所述车载中控的用户id,并将所述目标现场行车音视频数据和所述用户id上传至所述云服务器;
所述云服务器,用于根据所述用户id进行第三方视频平台账号匹配,查找到所述用户id绑定的第三方视频平台,并将所述目标现场行车音视频数据发布至所述用户id绑定的第三方视频平台。
可选的,所述音视频采集装置包括:
摄像头,用于采集现场行车视频数据;
麦克风,用于采集现场行车音频数据。
可选的,所述车载中控包括:
语音识别模块,用于对用户语音输入的所述音视频采集指令以及所述音视频发布指令进行语音识别;
编码器,用于对获取的所述现场行车音视频数据进行编码;
封装器,用于将编码后的现场行车音视频数据封装为数据包格式的所述目标现场行车音视频数据;
联网模块,用于与所述云服务器进行通信,将所述目标现场行车音视频数据和获取的所述用户id上传至所述云服务器。
可选的,所述编码器包括:
视频编码单元,用于将现场行车视频数据编码为h.264格式;
音频编码单元,用于将现场行车音频数据编码为aac格式。
一种现场行车音视频云发布方法,应用于上述所述的现场行车音视频云发布系统中的车载中控,所述发布方法包括:
接收用户语音输入的音视频采集指令;
获取音视频采集装置采集的现场行车音视频数据;
对所述现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;
接收用户语音输入的音视频发布指令;
获取已登录所述车载中控的用户id,并将所述目标现场行车音视频数据和所述用户id上传至所述云服务器,由所述云服务器将所述目标现场行车音视频数据发布至所述用户id绑定的第三方视频平台。
可选的,在所述接收用户语音输入的音视频采集指令之前,还包括:
获取所述用户id和登录密码;
将所述用户id和所述登录密码进行匹配,当所述用户id和所述登录密码匹配成功时,由登录界面跳转至工作界面。
可选的,所述对所述现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据,具体包括:
将现场行车视频数据编码为h.264格式,以及将现场行车音频数据编码为aac格式;
将所述h.264格式的现场行车视频数据和所述aac格式现场行车音频数据封装为数据包,得到数据包格式的所述目标现场行车音视频数据。
从上述的技术方案可知,本发明公开了一种现场行车音视频云发布系统及方法,系统包括:音视频采集装置、车载中控和云服务器,车载中控在接收到用户语音输入的音视频采集指令后,获取音视频采集装置采集的现场行车音视频数据,并对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;车载中控在接收到用户语音输入的音视频发布指令后,获取已登录车载中控的用户id,将封装得到的目标现场行车音视频数据和用户id上传至云服务器,云服务器根据用户id进行第三方视频平台账号匹配,查找到用户id绑定的第三方视频平台,并将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。由此可以看出,本发明通过语音控制行车音视频数据的采集,在对采集的行车音视频数据进行编码和封装后,并在接收到语音发布指令时,通过云端将行车音视频数据实时发布至第三方视频平台,整个行车音视频数据发布过程不需要经过手机,因此不仅缩短了行车音视频分享链路,而且实现了在行车过程中实时发布现场行车音视频。
另外,由于本发明是通过语音控制行车音视频数据采集和发布,因此还有效避免了用户在行车过程中因手动操作车载中控带来的分心,从而保证了行车安全。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据公开的附图获得其他的附图。
图1为本发明实施例公开的一种现场行车音视频云发布系统的结构示意图;
图2为本发明实施例公开的另一种现场行车音视频云发布系统的结构示意图;
图3为本发明实施例公开的一种车载中控的结构示意图;
图4为本发明实施例公开的一种现场行车音视频云发布方法的流程图;
图5为本发明实施例公开的另一种现场行车音视频云发布方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种现场行车音视频云发布系统及方法,系统包括:音视频采集装置、车载中控和云服务器,车载中控在接收到用户语音输入的音视频采集指令后,获取音视频采集装置采集的现场行车音视频数据,并对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;车载中控在接收到用户语音输入的音视频发布指令后,获取已登录车载中控的用户id,将封装得到的目标现场行车音视频数据和用户id上传至云服务器,云服务器根据用户id进行第三方视频平台账号匹配,查找到用户id绑定的第三方视频平台,并将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。由此可以看出,本发明通过语音控制行车音视频数据的采集,在对采集的行车音视频数据进行编码和封装后,并在接收到语音发布指令时,通过云端将行车音视频数据实时发布至第三方视频平台,整个行车音视频数据发布过程不需要经过手机,因此不仅缩短了行车音视频分享链路,而且实现了在行车过程中实时发布现场行车音视频。
另外,由于本发明是通过语音控制行车音视频数据采集和发布,因此还有效避免了用户在行车过程中因手动操作车载中控带来的分心,从而保证了行车安全。
参见图1,本发明一个实施例公开的一种现场行车音视频云发布系统的结构示意图,该发布系统包括:音视频采集装置10、车载中控20和云服务器30。
其中:
音视频采集装置10,用于采集现场行车音视频数据。
其中,采集的现场行车音视频数据包括:现场行车音频数据和现场行车视频数据,现场行车音频数据可以通过安装在车内的麦克风实时采集,现场视频数据可以通过安装在车上的摄像头实时采集。
车载中控20,用于在接收到用户语音输入的音视频采集指令后,获取所述音视频采集装置10采集的所述现场行车音视频数据,并对所述现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据。
车载中控20作为整个现场行车音视频云发布系统的核心部件,可以根据用户输入的语音指令执行相应的操作。车载中控20与音视频采集装置10连接,当用户需要采集现场行车音视频数据时,用户向车载中控20语音输入音视频采集指令,车载中控20在接收到音视频采集指令后,会获取音视频采集装置10采集的现场行车音视频数据,并对该现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据。其中,现场行车音视频数据可以采用现有任意编码格式,例如,可以将现场行车视频数据编码为h.264格式,将现场行车音频数据编码为aac格式。本实施例中,可以将编码后的现场行车音视频数据封装为rtp(real-timetransportprotocol,实时传输协议)数据包。
本实施例中,车载中控20在对音视频采集装置10采集的现场行车音视频数据进行编码和封装后,就可以根据用户的音视频发布指令,对封装后的现场行车音视频数据进行发布。
车载中控20,还用于在接收到用户语音输入的音视频发布指令后,获取已登录车载中控20的用户id,并将封装得到的目标现场行车音视频数据和所述用户id上传至云服务器30。
需要说明的是,在用户需要发布现场行车音视频数据之前,用户首先需要登录车载中控20,在实际应用中,用户可以通过注册的用户id和密码登录车载中控20。若用户id保持不变,则用户仅需登录一次车载中控20即可。
当用户需要发布现场行车音视频数据时,用户向车载中控20语音输入音视频发布指令,车载中控20在接收到音视频发布指令后,会获取已登录车载中控20的用户id,以便通过该用户id来查找该用户id绑定的第三方视频平台。车载中控20将获取的已登录车载中控20的用户id和封装得到的目标现场行车音视频数据一同发送至云服务器30。
需要说明的是,本实施例中的云服务器30具备账号体系以及音视频分发能力。
云服务器30,用于根据所述用户id进行第三方视频平台账号匹配,查找到所述用户id绑定的第三方视频平台,并将所述目标现场行车音视频数据发布至所述用户id绑定的第三方视频平台。
具体的,不同的用户id与不同的第三方视频平台账号匹配,在实际应用中,用户id和第三方视频平台账号可以相同,比如,均为用户的手机号码,在根据用户id查找到该用户id绑定的第三方视频平台后,就可以将封装得到的目标现场行车音视频数据发布至用户id绑定的第三方视频平台。
需要说明的是,在实际应用中,云服务器30可以通过用户云管理、云存储管理和云发布管理协同工作实现对目标现场行车音视频数据的发布。
综上可知,本发明公开的现场行车音视频云发布系统,包括:音视频采集装置10、车载中控20和云服务器30,车载中控20在接收到用户语音输入的音视频采集指令后,获取音视频采集装置10采集的现场行车音视频数据,并对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;车载中控20在接收到用户语音输入的音视频发布指令后,获取已登录车载中控20的用户id,将封装得到的目标现场行车音视频数据和用户id上传至云服务器30,云服务器30根据用户id进行第三方视频平台账号匹配,查找到用户id绑定的第三方视频平台,并将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。由此可以看出,本发明通过语音控制行车音视频数据的采集,在对采集的行车音视频数据进行编码和封装后,并在接收到语音发布指令时,通过云端将行车音视频数据实时发布至第三方视频平台,整个行车音视频数据发布过程不需要经过手机,因此不仅缩短了行车音视频分享链路,而且实现了在行车过程中实时发布现场行车音视频。
另外,由于本发明是通过语音控制行车音视频数据采集和发布,因此还有效避免了用户在行车过程中因手动操作车载中控20带来的分心,从而保证了行车安全。
为进一步优化上述实施例,参见图2,本发明另一个实施例公开的一种现场行车音视频云发布系统的结构示意图,本实施例中,音视频采集装置10包括:摄像头11和麦克风12。
其中,摄像头11,用于采集现场行车视频数据。在实际应用中,摄像头11可以集成于行车记录仪,安装在车辆的前挡风玻璃位置,采集的是车辆前方的行车视频数据。
麦克风12,用于采集现场行车音频数据,在实际应用中,麦克风12设置在车内,主要采集车内人员的声音数据。
结合图3所示的车载中控的结构示意图,车载中控20具体包括:语音识别模块21、编码器22、封装器23和联网模块24。
其中,语音识别模块21分别与编码器22和联网模块24连接,封装器23分别与编码器22和联网模块24连接。
具体的,语音识别模块21,用于对用户语音输入的音视频采集指令以及音视频发布指令进行语音识别。
本发明通过采用语音形式对车载中控20进行控制,有效避免了用户在行车过程中手动操作车载中控20带来的分心,从而保证了行车安全。
编码器22,用于对获取的现场行车音视频数据进行编码。
本实施例中,编码器22可以包括:
视频编码单元221,用于将现场行车视频数据编码为h.264格式;
音频编码单元222,用于将现场行车音频数据编码为aac格式。
封装器23,用于将编码后的现场行车音视频数据封装为数据包格式的目标现场行车音视频数据。
联网模块24,用于与云服务器30进行通信,将目标现场行车音视频数据和获取的用户id上传至云服务器30。
本实施例中,车载中控20通过联网模块24实现与云服务器30之间的通信。
综上可知,本发明公开的现场行车音视频云发布系统,包括:音视频采集装置10、车载中控20和云服务器30,车载中控20在接收到用户语音输入的音视频采集指令后,获取音视频采集装置10采集的现场行车音视频数据,并对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;车载中控20在接收到用户语音输入的音视频发布指令后,获取已登录车载中控20的用户id,将封装得到的目标现场行车音视频数据和用户id上传至云服务器30,云服务器30根据用户id进行第三方视频平台账号匹配,查找到用户id绑定的第三方视频平台,并将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。由此可以看出,本发明通过语音控制行车音视频数据的采集,在对采集的行车音视频数据进行编码和封装后,并在接收到语音发布指令时,通过云端将行车音视频数据实时发布至第三方视频平台,整个行车音视频数据发布过程不需要经过手机,因此不仅缩短了行车音视频分享链路,而且实现了在行车过程中实时发布现场行车音视频。
另外,由于本发明是通过语音控制行车音视频数据采集和发布,因此还有效避免了用户在行车过程中因手动操作车载中控20带来的分心,从而保证了行车安全。
与上述现场行车音视频云发布系统相对应,本发明还公开了一种现场行车音视频云发布方法。
参见图4,本发明一个实施例公开的一种现场行车音视频云发布方法的流程图,该方法应用于上述现场行车音视频云发布系统中的车载中控,该方法包括步骤:
步骤s101、接收用户语音输入的音视频采集指令;
车载中控作为整个现场行车音视频云发布系统的核心部件,可以根据用户输入的语音指令执行相应的操作。车载中控与音视频采集装置连接,当用户需要采集现场行车音视频数据时,用户向车载中控语音输入音视频采集指令,车载中控接收用户语音输入的音视频采集指令。
步骤s102、获取音视频采集装置采集的现场行车音视频数据;
音视频采集装置实时采集现场行车音视频数据,车载中控只有在接收到用户语音输入的音视频采集指令后,才会获取音视频采集装置采集的现场行车音视频数据。
步骤s103、对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;
其中,现场行车音视频数据可以采用现有任意编码格式。例如,可以将现场行车视频数据编码为h.264格式,将现场行车音频数据编码为aac格式。然后将h.264格式的现场行车视频数据和aac格式现场行车音频数据封装为数据包,得到数据包格式的目标现场行车音视频数据。
步骤s104、接收用户语音输入的音视频发布指令;
当用户需要发布现场行车音视频数据时,用户向车载中控语音输入音视频发布指令,车载中控在接收到音视频发布指令后,会获取已登录车载中控的用户id,以便通过该用户id来查找该用户id绑定的第三方视频平台。
步骤s105、获取已登录车载中控的用户id,并将目标现场行车音视频数据和用户id上传至云服务器,由云服务器将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。
具体的,不同的用户id与不同的第三方视频平台账号匹配,在实际应用中,用户id和第三方视频平台账号可以相同,比如,均为用户的手机号码,在根据用户id查找到该用户id绑定的第三方视频平台后,就可以将封装得到的目标现场行车音视频数据发布至用户id绑定的第三方视频平台。
综上可知,本发明公开的现场行车音视频云发布方法,车载中控在接收到用户语音输入的音视频采集指令后,获取音视频采集装置采集的现场行车音视频数据,并对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;车载中控在接收到用户语音输入的音视频发布指令后,获取已登录车载中控的用户id,将封装得到的目标现场行车音视频数据和用户id上传至云服务器,云服务器根据用户id进行第三方视频平台账号匹配,查找到用户id绑定的第三方视频平台,并将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。由此可以看出,本发明通过语音控制行车音视频数据的采集,在对采集的行车音视频数据进行编码和封装后,并在接收到语音发布指令时,通过云端将行车音视频数据实时发布至第三方视频平台,整个行车音视频数据发布过程不需要经过手机,因此不仅缩短了行车音视频分享链路,而且实现了在行车过程中实时发布现场行车音视频。
另外,由于本发明是通过语音控制行车音视频数据采集和发布,因此还有效避免了用户在行车过程中因手动操作车载中控带来的分心,从而保证了行车安全。
需要说明的是,在用户需要发布现场行车音视频数据之前,用户首先需要登录车载中控,在实际应用中,用户可以通过注册的用户和密码登录车载中控。若用户id保持不变,则用户仅需登录一次车载中控即可。
因此,为进一步优化上述实施例,参见图5,本发明另一实施例公开的一种现场行车音视频云发布方法的流程图,该方法包括步骤:
步骤s201、获取用户id和登录密码;
优选的,用户id为用户的手机号码。
当用户需要将现场行车音视频数据发布至第三方视频平台时,用户首先需要在车载中控界面输入预先注册的用户id和登录密码,登录车载中控。当用户之前未注册时,用户首先需要注册,注册过程可参见现有成熟方案,此处不再赘述。
步骤s202、将用户id和登录密码进行匹配,当用户id和登录密码匹配成功时,由登录界面跳转至工作界面;
车载中控在获取到用户在界面输入的用户id和登录密码后,车载中控会将用户id和登录密码进行匹配,当匹配成功后,车载中控由登录界面跳转至工作界面。
步骤s203、接收用户语音输入的音视频采集指令;
步骤s204、获取音视频采集装置采集的现场行车音视频数据;
步骤s205、对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;
步骤s206、接收用户语音输入的音视频发布指令;
步骤s207、获取已登录车载中控的用户id,并将目标现场行车音视频数据和用户id上传至云服务器,由云服务器将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。
其中,本实施例中的步骤s203~步骤s207与图4所示实施例中的各个步骤对应。
综上可知,本发明公开的现场行车音视频云发布方法,获取用户id和登录密码,当用户id和登录密码匹配成功时,由登录界面跳转至工作界面,车载中控在接收到用户语音输入的音视频采集指令后,获取音视频采集装置采集的现场行车音视频数据,并对现场行车音视频数据进行编码和封装,得到数据包格式的目标现场行车音视频数据;车载中控在接收到用户语音输入的音视频发布指令后,获取已登录车载中控的用户id,将封装得到的目标现场行车音视频数据和用户id上传至云服务器,云服务器根据用户id进行第三方视频平台账号匹配,查找到用户id绑定的第三方视频平台,并将目标现场行车音视频数据发布至用户id绑定的第三方视频平台。由此可以看出,本发明通过语音控制行车音视频数据的采集,在对采集的行车音视频数据进行编码和封装后,并在接收到语音发布指令时,通过云端将行车音视频数据实时发布至第三方视频平台,整个行车音视频数据发布过程不需要经过手机,因此不仅缩短了行车音视频分享链路,而且实现了在行车过程中实时发布现场行车音视频。
另外,由于本发明是通过语音控制行车音视频数据采集和发布,因此还有效避免了用户在行车过程中因手动操作车载中控带来的分心,从而保证了行车安全。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!