基于FTP协议的分布式存储系统及其实现方法与流程
本发明涉及数据存储技术领域,尤其涉及一种基于ftp协议的分布式存储系统及其实现方法。
背景技术:
信息化技术的迅猛发展,加速了各行各业数字化的建设。以医院数据存储记录为例,目前,医院的各种医疗业务系统都在按照医院的实际业务需求进行电子病历数据数字化改造。但是,由于医院的各个业务系统并不都是同一厂商提供的,且一些厂商的软件开发技术过于陈旧,因而导致了各个业务系统间的数据结构不一致,数据标准不一致,系统间不得不依赖于相对传统的方式和协议进行数据的交互和传输,造成最终的电子病历数据只能基于pdf格式存储,并通过ftp协议进行传输交互。
而随着医院业务量的不断提升,医院的数据产生量也呈爆发性增长,根据国家电子病历规定的要求,医疗机构保管保存门诊病历不得低于15年、住院病历数据时间要求不得低于30年,这就对医院电子病历数据存储的快速扩容能力和高并发调阅能力提出了挑战。但目前医院采用的基于ftp协议的pdf文件传输服务器均为集中式阵列存储,普遍存在文件调阅性能瓶颈的问题,扩容和运维都非常困难,造成许多院区之间无法进行电子病历数据交互。
技术实现要素:
本发明的目的在于提供一种基于ftp协议的分布式存储系统,以解决集中式阵列存储存在的文件调阅性能瓶颈问题。
为实现上述目的,本发明采用的技术方案如下:
基于ftp协议的分布式存储系统,包括:
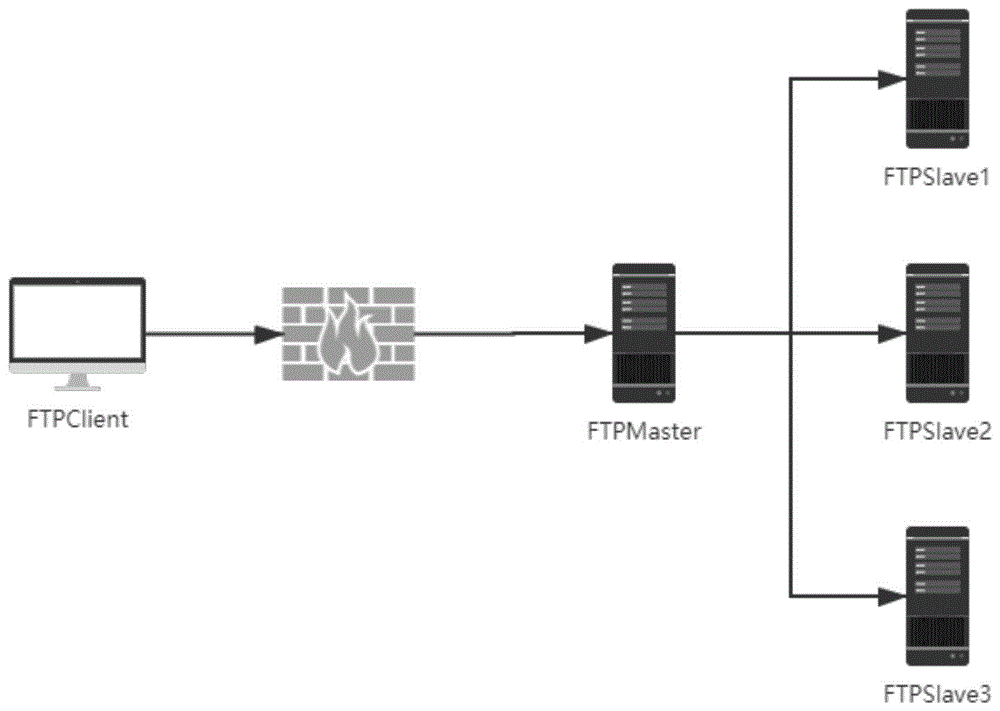
基于ftp协议并安装有业务系统的windows主机ftpclient;
若干用于负责数据流传输以及物理文件读写的linux分机ftpslave1、ftpslave2……ftpslaven;所有的linux分机之间均挂载了其它分机的共享目录;
以及,用于负责ftp协议控制命令处理和所有linux分机负载均衡的linux主机ftpmaster。
基于上述存储系统,本发明还提供了该存储系统的实现方法,包括以下步骤:
s101、linux主机创建至少2个tcp通道,其中一个tcp通道用于与windows主机建立联系并负责ftp控制命令响应和处理,另一个tcp通道用于与linux分机建立联系;
s102、每个linux分机均创建至少2个tcp通道,其中一个tcp通道用于负责ftp控制命令响应和处理,另一个tcp通道用于与linux主机建立联系;
s103、所有的linux分机均创建各自的共享目录,并将目录信息同步至linux主机,linux主机更新集群共享目录列表信息;
s104、windows主机访问linux主机;
s105、linux主机收到请求后,建立tcp连接并开始会话;
s106、windows主机和linux主机之间进行账户验证,若验证不成功,则循环步骤s106,直至验证成功后,执行步骤s107;
s107、windows主机向linux主机发起pasv命令;
s108、linux主机进行轮询,并根据轮询结果,在确保负载均衡的前提下向windows主机返回一个linux分机节点的ip和端口;
s109、windows主机根据响应派生出一个客户端数据传输进程,并随机产生一个客户端数据传输端口连接到返回的linux分机节点的ip和端口,然后windows主机、返回的linux分机节点之间基于ftp协议和所有linux分机的共享目录信息进行数据文件传输,实现文件的上传和下载。
进一步地,所述步骤s109中,在进行数据文件传输时,若为文件上传,则执行步骤s110;若为文件下载,则执行步骤s111;
s110、windows主机向linux分机节点发送“stor<文件名>”指令,并上传文件至linux分机节点,linux分机节点对“stor<文件名>”命令中的“<文件名>”进行crc32散列变换之后再对linux分机的个数进行取模,确定将文件存储到哪个节点的共享目录上,执行步骤s112;
s111、windows主机向linux分机节点发送“retr<文件名>”指令,linux分机节点对“retr<文件名>”命令中的“<文件名>”进行crc32散列变换之后再对linux分机的个数进行取模,确定文件存储在哪个节点的共享目录上,然后从该共享目录上读取文件传输至windows主机,执行步骤s112;
s112、windows主机完成操作后,关闭tcp通道。
作为优选,根据非阻塞io模型epoll创建tcp通道。
再进一步地,所述步骤s101中,linux主机还启动一个监控程序,负责linux主机进程的开机启动和崩溃后的自动重启。
再进一步地,所述步骤s102中,linux分机还启动一个监控程序,负责linux分机进程的开机启动和崩溃后的自动重启。
更进一步地,当有新的linux分机连接linux主机时,linux主机将当前集群的共享目录列表信息传送给新的linux分机,该linux分机将所有的非本机共享目录挂载到本机上;同时,linux主机根据新的linux分机的共享目录信息更新集群共享目录列表信息。
与现有技术相比,本发明具有以下有益效果:
(1)本发明基于ftp协议下,采用共享目录创建、挂载以及集群共享目录列表信息的设计,实现了数据的分布式存储和信息的实时更新和共享,并在确保所有linux分机负载均衡的前提下,采用轮询方式为windows主机提供当前最适合的节点进行连接,最终实现了数据的传输(文件上传和下载)。本发明可有效实现数据的交互,不仅操作更加方便,而且大幅度提升了并发调阅的性能,并大大降低了扩容的难度和成本。传统ftp协议服务器在步骤s108这一步轮询后返回的是本机的外部可访问ip和随机端口,本发明在不改变原有交互协议和流程的情况下使得轮询后返回固定的ip和端口,既实现了负载均衡,又提高了并发数量和并发效率。从并发角度来说,假定单机并发最大是200(根据机器配置不同,该值会随着配置提升而线性提升),那么3个节点的情况下并发理论上能够达到600,同时,3个节点将容量扩大到3倍,这就解决了集中式存储扩容难度大、难以进行并发的问题。而能否并发、并发速率如何就决定了电子病历数据能否交互和交互速率。
(2)本发明还设置了监控模式,可以实现进程的开机启动和崩溃后的自动重启,确保整个系统的持续正常运转。
(3)本发明通过上述方案的设计,除了提升并发调阅的性能、降低扩容难度外,还有效提升了存储系统接入windows主机后的响应速度,同时还实现了各分机的负载均衡,进而为扩展网络设备和服务器的带宽、增加吞吐量、加强网络数据处理能力、提高网络的灵活性和可用性提供了有力的保障。因此,本发明涉及的存储系统和方法非常适合在各大医院进行布局和应用。
附图说明
图1是本发明-实施例中的一种系统部署架构图;
图2是本发明-实施例中的一种系统应用架构图;
图3是本发明-实施例中的一种数据流向示意图。
具体实施方式
下面结合附图说明和实施例对本发明作进一步说明,本发明的方式包括但不仅限于以下实施例。
实施例
如图1~3所示,本实施例所涉及的分布式存储系统,包括1台linux主机、1台windows主机以及3台linux分机。为方便阐述,本实施例中,linux主机代号为ftpmaster,linux分机代号分别为ftpslave1、ftpslave2、ftpslave3,windows主机代号为ftpclient。
所述的ftpmaster上包含有ftp信息处理模块、共享存储管理模块、负载均衡处理模块和进程监控模块,负责ftp协议控制命令处理以及ftpslave1、ftpslave2、ftpslave3的负载均衡。本实施例中,ftpmaster的服务进程名为ftpmaster,跟主机代号同名。
所述的ftpslave1、ftpslave2和ftpslave3负责数据流传输以及物理文件读写,包含有ftp信息处理模块、共享存储工作模块、进程监控模块、nfs服务器和nfs客户端。并且ftpslave1、ftpslave2和ftpslave3基于linuxnfs4技术相互挂载了对方的共享目录。本实施例中,3台分机对应的进程名一样,均为ftpslave。
所述的ftpclient上安装有医院业务系统。
下面详细介绍上述分布式存储系统的实现流程,如下所述:
s101、ftpmaster进程启动,然后创建2个tcp通道(根据非阻塞io模型epoll创建),其中,tcp通道1用来侦听本机21端口,负责ftp控制命令响应和处理;tcp通道2用来侦听本地8080端口,负责与ftpslave建立联系;同时,ftpmaster上还启动一个监控程序,监控ftpmaster进程的开机启动和崩溃后的自动重启;
s102、分别启动ftpslave1、ftpslave2、ftpslave3的服务进程ftpslave,ftpslave启动后创建1个tcp通道(同样根据非阻塞io模型epoll创建),该tcp通道用来侦听本机8080端口,负责ftp控制命令响应和处理;同时,ftpslave还创建1个tcp客户端通道,用来连接ftpmaster创建的tcp通道2,负责将ftpslave的本地共享目录信息同步给ftpmaster;另外,ftpslave上还启动一个监控程序,监控ftpslave进程的开机启动和崩溃后的自动重启;
s103、ftpslave1、ftpslave2、ftpslave3的服务进程ftpslave启动完成后会通过shell脚本与nfs服务器(nfsserver)进行通讯创建本机的共享目录,并将本地共享目录的信息通过ftpmaster创建的tcp通道2传给ftpmaster,ftpmaster更新集群共享目录列表信息;当有新的ftpslave连接到ftpmaster时,ftpmaster会将当前集群的共享目录列表信息传送给该ftpslave,该ftpslave通过shell脚本与nfs客户端(nfsclient)进行通讯,将所有的非本机共享目录挂载到本机上;同时,ftpmaster根据新的ftpslave的共享目录信息更新集群共享目录列表信息;
s104、ftpclient进程启动,访问ftpmaster的21端口,执行步骤s105;
s105、ftpmaster收到请求后,建立tcp连接并开始会话,执行步骤s106;
s106、ftpclient和ftpmaster之间通过ftpmaster创建的tcp通道1进行用户名和密码校验操作,验证成功后,执行步骤s107;
s107、ftpclient通过ftpmaster创建的tcp通道1向ftpmaster发起pasv命令,执行步骤s108;
s108、ftpmaster收到pasv请求后,按照轮询方式返回一个ftpslave节点的ip和端口,并按照ftp协议生成指令『227enteringpassivemode(h1,h2,h3,h4,31,144)』,其中端口是31*256+144=8080,ip地址为『h1.h2.h3.h4』,代表了ftpslave节点的ip和端口,执行步骤s109;
s109、ftpclient收到ftpmaster响应后,派生出一个客户端数据传输进程,并随机产生一个客户端数据传输端口连接到ftpmaster回传过来的数据传输通道(ftpslave节点)的ip和端口,然后进行数据文件传输,传输时,如果是进行文件上传,则执行步骤s110;如果是进行文件下载,则执行步骤s111;
s110、ftpclient发送“stor<文件名>”指令到ftpslave1节点(这里假设步骤s109返回节点数据是ftpslave1对应的ip和端口),从ftpclient上传文件到ftpslave1节点,ftpslave1节点根据算法crc32(文件名)取模ftpslave节点的数量来决定文件存储到哪个节点的共享目录上,执行步骤s112;
s111、ftpclient发送“retr<文件名>”指令到ftpslave1节点(这里假设步骤s109返回节点数据是ftpslave1对应的ip和端口),ftpslave1节点根据算法crc32(文件名)取模ftpslave节点的数量,确定文件存储在哪个节点的共享目录上,然后从该共享目录上读取文件传输给ftpclient,执行步骤s112;
s112、ftpclient完成操作后,关闭tcp通道,整个流程执行完毕。
本发明实现了分布式的文件读写,大幅度提升了并发调阅的性能,并降低了扩容的难度和成本。因此,与现有技术相比,本发明技术进步十分明显,具有突出的实质性特点和显著的进步。
上述实施例仅为本发明的优选实施方式之一,不应当用于限制本发明的保护范围,凡在本发明的主体设计思想和精神上作出的毫无实质意义的改动或润色,其所解决的技术问题仍然与本发明一致的,均应当包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!