一种源网荷系统安全防护方法与流程
1.本发明涉及一种源网荷系统安全防护方法,属于电力系源网荷系统互动领域术领 域。
背景技术:
2.近年来,随着智能电网建设的推进,将发电侧、电网侧和负荷侧组成的“源网荷
”ꢀ
系统,通过友好互动的形式将三者进行协调发展、集成互补,成为国内能源互联网战略 规划的重要途径。目前国网公司初步建成的“大规模源网荷友好互动系统”(简称源网 荷系统),主要以复杂交直流混联输配电网的电网侧和接入大规模柔性负荷的需求侧之 间的“网荷互动”应对特高压直流多馈入带来的电网稳定问题。
3.目前源网荷系统在系统的横向边界及纵向边界部署正反向隔离装置及纵向加密认 证装置,能有效抵御来自互联网的传统病毒木马的入侵。但是在外部严峻的工控安全形 势下,工控系统的物理隔离并非绝对安全。由于管理原因或技术原因,恶意攻击依然可 以通过负荷侧不可控的智能负荷控制终端设备、接入内网的u盘等移动媒介、接入控制 区网络内部的调试人员笔记本等方式对系统实施恶意数据注入、伪造控制指令、获取超 级权限、造成网络中断等多种形式的恶意攻击。为了应对源网荷系统信息安全防护面临 的挑战,有必要针对源网荷系统研究一种基于adaboost集成学习的网络入侵检测方法, 使电力侧有足够的恶意攻击识别能力,以保障源网荷系统的安全稳定运行。
技术实现要素:
4.发明目的:本发明为了解决源网荷系统互动所出现的安全问题,提出一种源网荷系 统安全防护方法。
5.技术方案:一种源网荷系统安全防护方法,包括以下步骤:
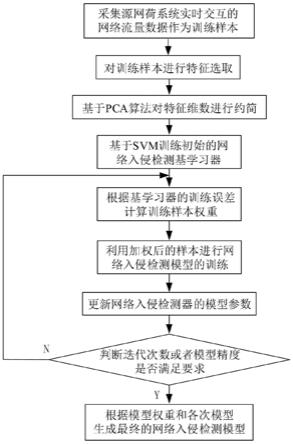
6.步骤一、采集源网荷系统实时交互的网络流量数据,作为训练样本;
7.步骤二、对采集的源网荷系统网络流量数据进行特征选取;
8.步骤三、基于主成分分析(pca)算法对特征维数进行约简;
9.步骤四、基于神经网络分类器训练初始的网络入侵检测基学习器;
10.步骤五、根据初始基学习器的训练误差计算样本权重;
11.步骤六、利用加权后的样本进行新一轮的神经网络分类器训练,得到更新后的网络 入侵检测模型;
12.步骤七、更新网络入侵检测器的模型参数;
13.步骤八、根据迭代次数或者模型精度是否达到设定值来判断是否结束迭代,如果迭 代结束,则跳转至步骤八,否则跳转至步骤五;
14.步骤九、生成最终的网络入侵检测模型。
15.进一步地,步骤2中,流量特征属性包括源地址、目的地址、ip包总长度、ip包 头长度、tcp包头长度、源端口号、目的端口号、流量大小、协议标识符、长度、业务 标识符、功能
码、数据长度。
16.进一步地,步骤4中,神经网络分类器采用adaboost算法。
17.进一步地,步骤5中,利用训练误差绝对值来衡量这一权重值,其方法如下式:
[0018][0019]
式中,e
t
表示第t次迭代得到的网络入侵检测模型对各训练样本的加权方差和,β
t
为调节系数,ω
t
为最终输出的第t次迭代得到的网络入侵检测模型对最终检测模型的影 响权重值。
[0020]
进一步地,步骤9中,最终的网络入侵检测模型为t为adaboost算法 的最大迭代次数,h
t
为第t次的网络入侵检测模型
[0021]
有益效果:本发明基于adaboost集成学习训练神经网络分类器,够将多个精度相 对较低的弱分类器综合优化,训练出精度较高的强分类器,提高网络入侵检测模型的泛 化能力。
附图说明
[0022]
图1为一种源网荷系统安全防护方法流程图。
具体实施方式
[0023]
下面结合附图对本发明作进一步说明:
[0024]
如图1所示,本发明公开了一种源网荷系统安全防护方法,包括以下步骤:
[0025]
步骤一、采集源网荷系统实时交互的网络流量数据,作为训练样本;
[0026]
步骤二、对采集的源网荷系统网络流量数据进行特征选取;
[0027]
步骤三、基于主成分分析(pca)算法对特征维数进行约简;
[0028]
步骤四、基于神经网络分类器训练初始的网络入侵检测基学习器;
[0029]
步骤五、根据初始基学习器的训练误差计算样本权重;
[0030]
步骤六、利用加权后的样本进行新一轮的神经网络分类器训练,得到更新后的网络 入侵检测模型;
[0031]
步骤七、更新网络入侵检测器的模型参数;
[0032]
步骤八、根据迭代次数或者模型精度是否达到设定值来判断是否结束迭代,如果迭 代结束,则跳转至步骤八,否则跳转至步骤五;
[0033]
步骤九、生成最终的网络入侵检测模型。
[0034]
源网荷系统网络流量采集主要是在源网荷系统运行时对单位时间网络内传输的信 息量进行捕获。所谓网络流量是指2个系统之间交互时拥有相同通信五元组信息(源ip 地址、源端口、目的ip地址、目的端口和传输层协议)的连续数据包。
[0035]
源网荷系统网络流量信息处理包括特征选取与特征维数约简。所谓网络流量特征选 择是依据一定的规则从已有的网络流量特征中选取出部分特征来表示原始网络流量数 据,特征选择保留了训练样本的原始物理意义。而所谓网络流量特征提取则是按照一定 的规则将原始的网络流量特征空间变换成一个维数更小的空间,是使用数学方法对某些 特征进行融合产生了新的特征,新的特征只具有数学含义,难以找到其现实意义。在源 网荷系统可供选择的流量特征属性包括源地址、目的地址、ip包总长度、ip包头长度、 tcp包头长度、源端口号、目的端口号、流量大小、协议标识符、长度、业务标识符、 功能码、数据长度等,再通过主成分分析(pca)方法将其进行特征降维。
[0036]
通过网络流量特征反映源网荷系统的实时交互情况,并基于这些数据进行网络入侵 检测,检测的结果只能是正常或异常两种情况,所以对源网荷系统的入侵检测可以被认 为是一种二分类问题,在本方法中采用神经网络分类器训练入侵检测模型。但考虑到源 网荷系统中存在很多的网络节点,且节点受到入侵威胁的因素有很多,入侵过程的发生 时间、特征信息呈现一定的弱随机性,单一的神经网络算法虽然具有一定的小样本泛化 能力,但对于复杂系统的入侵检测问题仍然精度不高。因此在本方法中采用adaboost 集成学习的思想,adaboost是典型的集成学习方法,其能够将多个精度相对较低的弱分 类器综合优化,训练出精度较高的强分类器,并作为最终的网络入侵检测模型,以提升 网络入侵检测的准确率。
[0037]
假设经过数据采集、特征选取、特征维数约简后获得的网络流量数据特征样本集s的 长度为m,即s={(x1,y1),(x2,y2),
…
,(x
m
,y
m
)}。其中x
i
为每个数据训练样本的特征向量,y
i
为对于网络入侵检测问题的检测结果,每个样本初始权重d
i
均设置为1/m。设置 adaboost算法的最大迭代次数为t,并初始化当前迭代次数t=1。针对m个训练样本, 利用算法对神经网络模型的参数进行计算,得到最优参数值。利用参数优化后的神经网 络分类器对m个训练样本进行训练,获得第t次的网络入侵检测模型h
t
。记录本次入侵 检测模型h
t
,计算并保存第t次网络入侵检测模型的权重ω
t
,并判断得到的入侵检测模 型样本集的误差绝对值和是否小于设定值,或达到最大迭代次数。若成立则算法结束, 若不成立,则根据网络入侵检测模型对m个训练样本的误差绝对值和,更新m个训练样 本的权重d1,d2,
…
,d
m
生成新的训练集,并基于此训练集对神经网络分类器再次进行训练。 最终得到的网络入侵检测模型为在上述过程中影响adaboost集成学习效果 的因素主要有两个,一是每一轮循环中训练集上的样本权重如何分布;二是许多个规则 如何集成为一个有效的检测规则。这两点分别通过样本权重和模型权重来体现。
[0038]
通过对样本权重值的调节,能够有效地降低错误样本对入侵检测模型的影响,提升 正确样本的影响。样本权重值分为计算和归一化处理两个步骤,其中权重值采用训练误 差绝对值进行衡量,其方法如式():
[0039][0040]
式中,e
t
表示第t次迭代得到的入侵检测模型对各个训练样本的加权方差和,β
t
为调节 系数,d
′
t+1
(k)为新样本权重。
[0041]
各样本的权重值综合必须为1,因此必须进行归一化处理,其方法如式():
[0042][0043]
网络入侵检测模型的权重ω
t
的计算,直接影响了最终的检测模型的输出。为了提升 误差较小的入侵检测模型h
t
在最终的模型中的影响权重,本方法利用训练误差绝对值来 衡量这一权重值,其方法如下式所示:
[0044][0045]
式中,e
t
表示第t次迭代得到的网络入侵检测模型对各训练样本的加权方差和,β
t
为 调节系数,调节系数的选取有多种方式,为了保证最终的检测模型能够稳定,本方法采 用了上述方式,ω
t
为最终输出的第t次迭代得到的网络入侵检测模型对最终检测模型的 影响权重值。
[0046]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员 来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也 应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1