从可视内容生成交互式音轨的制作方法
从可视内容生成交互式音轨
背景技术:
1.数据处理系统可以将数字内容提供给计算设备,以使计算设备呈现数字内容。数字内容可以包括可视内容,计算设备可以经由显示器呈现所述可视内容。数字内容可以包括音频内容,计算机可以经由扬声器输出所述音频内容。
技术实现要素:
2.本技术解决方案的至少一个方面涉及一种生成音轨的系统。该系统包括数据处理系统。该数据处理系统包括一个或多个处理器。该数据处理系统可以经由网络接收数据分组,该数据分组包括由远离数据处理系统的计算设备的麦克风检测到的输入音频信号。该数据处理系统可以解析输入音频信号以识别请求。该数据处理系统可以基于所述请求,选择具有可视输出格式的数字组件对象,该数字组件对象与元数据相关联。该数据处理系统可以基于计算设备的类型,确定将数字组件对象转换为音频输出格式。该数据处理系统可以响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。该数据处理系统可以基于数字组件对象的场境(context),选择数字语音以渲染文本。该数据处理系统可以利用由数字语音渲染的文本,构造数字组件对象的基线音轨。该数据处理系统可以基于数字组件对象的元数据,生成非话语音频提示。该数据处理系统可以将非话语音频提示与数字组件对象的基线音频形式相结合,以生成数字组件对象的音轨。该数据处理系统可以响应于来自计算设备的请求,将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
3.该技术解决方案的至少一个方面涉及生成音轨的方法。该方法可以由数据处理系统的一个或多个处理器执行。该方法可以包括数据处理系统接收数据分组,该数据分组包括由远离数据处理系统的计算设备的麦克风检测到的输入音频信号。该方法可以包括数据处理系统解析输入音频信号以识别请求。该方法可以包括数据处理系统基于请求,选择具有可视输出格式的数字组件对象,该数字组件对象与元数据相关联。该方法可以包括数据处理系统基于计算设备的类型,确定将数字组件对象转换为音频输出格式。该方法可以包括数据处理系统响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。该方法可以包括基于数字组件对象的场境,选择数字语音以渲染文本。该方法可以包括数据处理系统利用由数字语音渲染的文本,构造数字组件对象的基线音轨。该方法可以包括数据处理系统基于数字组件对象,生成非话语音频提示。该方法可以包括数据处理系统将非话语音频提示与数字组件对象的基线音频形式相结合,以生成数字组件对象的音轨。该方法可以包括数据处理系统响应于来自计算设备的请求,将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
4.该技术解决方案的至少一个方面涉及一种生成音轨的系统。该系统可以包括具有一个或多个处理器的数据处理系统。该数据处理系统可以识别与由计算设备渲染的数字流媒体内容相关联的关键字。该数据处理系统可以基于关键字,选择具有可视输出格式的数字组件对象,该数字组件对象与元数据相关联。该数据处理系统可以基于计算设备的类型,
确定将数字组件对象转换为音频输出格式。该数据处理系统可以响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。该数据处理系统可以基于数字组件对象的场境,选择数字语音以渲染文本。该数据处理系统可以利用由数字语音渲染的文本构造数字组件对象的基线音轨。该数据处理系统可以基于数字组件对象,生成非话语音频提示。该数据处理系统可以将非话语音频提示与数字组件对象的基线音频形式相结合,以生成数字组件对象的音轨。该数据处理系统可以以及将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
5.在下文中,详细讨论这些和其他方面以及实施方式。前述信息和以下详细描述包括各个方面和实施方式的说明性示例,并且提供了用于理解所要求保护的方面和实施方式的性质和特性的概述或框架。附图提供了对各个方面和实施方式的说明和进一步的理解,并且被并入本说明书中并构成本说明书的一部分。
附图说明
6.附图不旨在按比例绘制。在各个附图中,相同的附图标记和标号指示相同的元件。为了清楚起见,并非每个组件都在每个附图中被标记。在附图中:
7.图1是根据实施方式的用于生成音轨的系统的图示。
8.图2是根据实施方式的用于生成音轨的方法的图示。
9.图3是示出了计算机系统的总体架构的框图,所述计算机系统可以被用来实施图1中所描绘的系统的元件和图2所描绘的方法。
具体实施方式
10.以下是与用于生成音轨的方法、装置和系统有关的各种概念及其实施方式的更详细描述。例如,所述方法、装置和系统可以由可视内容生成音轨。可以以许多方式中的任何一种来实施上文介绍的和下文更详细讨论的各种概念。
11.该技术解决方案通常针对产生音轨。该技术解决方案的系统和方法可以处理可视内容,以产生具有话语和非话语提示的音轨。例如,某些类型的计算设备可以提供仅音频的接口(例如,从用户接收语音输入、处理该输入,以及经由数字语音来提供音频或话语输出)。某些计算设备可以主要使用音频用户接口,或者在一些情况下可以主要使用音频接口。例如,移动计算设备的用户在驾驶车辆、跑步或收听串流音乐服务时,可能主要使用仅音频的接口。当主接口是基于音频时,数据处理系统可以提供音频数字组件对象(例如,音频内容项)。例如,数据处理系统可以选择由第三方音频内容提供者建立或提供的音频内容项。数据处理系统可以响应于来自用户的内容请求或基于另一个触发事件来提供音频内容项。但是,第三方内容提供者建立的内容项可能不是音频内容项。数据处理系统可以基于诸如关键字、相关性或其他因素的匹配标准来确定选择这样的内容项。但是,数据处理系统可能无法将内容项提供给计算设备,因为计算设备仅具有基于音频的接口。或者,在一些情况下,如果计算设备主要使用音频接口,或者音频接口是最有效的接口,则数据处理系统可能会由于提供可视内容项并且使得计算设备使用该计算设备的显示器渲染所述可视内容项,导致效率低下或浪费的计算利用率或负面的用户体验。使用显示器可能会浪费移动计算设备(例如,智能手机、智能手表或其他可穿戴设备)上的电池电量。因此,数据处理系统通过
提供在其中音频内容为首选的视频内容、或因为最相关的内容项只能以可视格式提供而不能提供所述最相关的内容项,可能会导致移动计算设备的浪费的计算资源、或者降低的用户体验。
12.此外,由于包括例如确定生成内容项的格式、如何为可视内容项(可能包括任何文本或可能不包括任何文本)准确地生成话语文本、为所生成的话语文本选择适当的语音以及添加非话语音频提示等各种技术问题,以不同的格式生成内容项在技术上具有挑战性。本技术解决方案的系统和方法可以使用自然语言处理和通过使用机器学习技术和历史数据所训练的模型来选择格式(例如,仅音频、视听格式、以及基于计算设备的类型和计算设备的当前场境的交互模型)、基于可视内容项和相关联的元数据自动地生成文本、为所生成的话语文本选择适当的数字声纹,并且选择和提供非话语音频提示以及话语文本。
13.例如,计算设备可以配置有可视用户接口(例如,带有用于用户输入的触摸屏的显示屏)和基于音频的用户接口(例如,麦克风和扬声器)两者。该计算设备当前可以是流媒体音乐,用于经由与该计算设备相关联的扬声器进行输出。数据处理系统可以通过使用与请求、查询或流媒体音乐相关联的信息来选择第三方内容项。所选择的第三方内容项可以是可视内容项(例如,可以包括文本的图像)。数据处理系统可以基于与请求、查询或流媒体音乐相关联的关键字来选择该可视内容项。例如,所选择的可视内容项可以是基于实时内容选择过程而确定的最高排名的内容项,其中,可以至少基于相关性得分来对内容项进行排名。数据处理系统可以确定计算设备配置有可视用户接口(例如,显示屏和触摸屏输入)和音频用户接口(例如,用于输出的扬声器和用于输入的麦克风)。但是,数据处理系统可以进一步基于计算设备的当前功能来确定当前主要使用的接口是基于音频的接口。因此,数据处理系统可以确定:尽管计算设备配置有可视和音频接口两者,但是当前正在使用的主要接口是音频接口,并且基于可视内容项来生成音频内容项以提供由内容项渲染将减少所述计算设备的电池消耗或浪费的计算资源(例如,提供音频内容项与流媒体音乐,而不是唤醒计算设备的显示器),并且改善计算设备所提供的用户体验(例如,以无干扰的方式提供音频内容项)。因此,该技术解决方案可以在不同模态之间无缝地转变内容项,以减少电池或计算资源的使用,同时提高用户接口功能和用户体验。
14.在创建音频内容项时,数据处理系统可以确定音频音乐流中的插入时间。数据处理系统可以进一步动态地确定是否使音频内容项带有任何可视指示符,以及为该内容项配置何种类型的交互性。
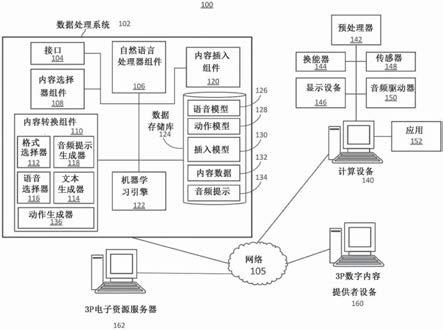
15.图1图示了用于生成音轨的示例性系统100。系统100可以由可视内容生成音轨。系统100可以包括内容选择架构。系统100可以包括数据处理系统102。数据处理系统102可以包括一个或多个处理器(例如图3描绘的处理器310)或在一个或多个处理器上执行。数据处理系统102可以经由网络105与3p数字内容提供者设备160或计算设备140(例如客户端设备)中的一个或多个通信。网络105可以包括计算机网络,诸如互联网、局域网、广域网、城域网或其他区域网络、内联网、卫星网络以及其他通信网络,诸如语音或数据移动电话网络。网络105可以被用来访问信息资源,诸如网页、网站、域名或统一资源定位符,它们可以在至少一个计算设备140(诸如膝上型计算机、台式计算机、平板计算机、个人数字助理、智能电话、便携式计算机或扬声器)上呈现、输出、渲染或显示。例如,经由网络105,计算设备140的用户可以访问由3p数字内容提供者设备160提供的信息或数据。计算设备140可以包括显示
设备146和扬声器(例如,由音频驱动器150驱动的换能器)。计算设备140可以包括显示器或可以不包括显示器;例如,计算设备可以包括有限类型的用户接口,诸如麦克风或扬声器(例如智能扬声器)。在一些情况下,计算设备140的主要用户接口可以是麦克风和扬声器。计算设备140可以与基于语音的计算环境交互或被包括在基于语音的计算环境中。
16.网络105可以由数据处理系统102使用以访问可以由客户端计算设备140呈现、输出、渲染或显示的信息资源,诸如应用、网页、网站、域名或统一资源定位符。例如,客户端计算设备140的用户可以经由网络105访问由3p数字内容提供者设备160提供的信息或数据。网络105可以包括或构成可在互联网上使用的信息资源的子网,其与内容投放或搜索引擎结果系统相关联,或有资格将第三方数字组件包括为数字组件投放活动的一部分。
17.网络105可以是任何类型或形式的网络,并且可以包括以下任何一种:点对点网络、广播网络、广域网、局域网、电信网络、数据通信网络、计算机网络、atm(异步传输模式)网络、sonet(同步光网络)网络、sdh(同步数字体系)网络、无线网络和有线网络。网络105可以包括无线链路,诸如红外信道或卫星频带。网络105的拓扑结构可以包括总线、星形或环形网络拓扑结构。网络可以包括使用用于在移动设备之间进行通信的任何一种或多种协议的移动电话网络,所述协议包括高级移动电话协议(“amps”)、时分多址(“tdma”)、码分多址(“cdma”)、全球移动通信系统(“gsm”)、通用分组无线业务(“gprs”)或通用移动电信系统(“umts”)。可以经由不同的协议传输不同类型的数据,或者可以经由不同的协议传输相同类型的数据。
18.数据处理系统102可以包括至少一个逻辑设备,诸如具有处理器以经由网络105通信的计算设备。数据处理系统102可以包括至少一个计算资源、服务器、处理器或存储器。例如,数据处理系统102可以包括位于至少一个数据中心中的多个计算资源或服务器。数据处理系统102可以包括多个按逻辑分组的服务器,并且可以有助于分布式计算技术。服务器的逻辑组可以被称为数据中心、服务器场或机器场。服务器也可以在地理位置上分散。数据中心或机器场可以作为单个实体被管理,或者所述机器场可以包括多个机器场。每个计算机场内的服务器可以是异构的
‑‑
一个或多个服务器或机器可以根据一种或多种操作系统平台进行操作。
19.机器场中的服务器可以与相关联的存储系统一起存储在高密度机架系统中,并且可以位于企业数据中心中。例如,以这种方式整合服务器可以通过在本地化的高性能网络上放置服务器和高性能存储系统来提高系统可管理性、数据安全性、系统的物理安全性和系统性能。包括服务器和存储系统的所有或一些数据处理系统102组件的集中化、以及将它们与高级系统管理工具耦合在一起允许更有效地利用服务器资源,这节省了电力和处理需求并减少了带宽使用。
20.数据处理系统102可以包括至少一个接口104,该接口可以经由网络105或者在数据处理系统102的各个组件之间接收和传输数据分组或信息。数据处理系统102可以包括至少一个自然语言处理器组件106,其可以接收语音或音频输入并处理或解析所输入的音频信号。数据处理系统102可以包括至少一个内容选择器组件108,其被设计、构造和操作为选择由一个或多个3p数字内容提供者设备160提供的数字组件项(例如,内容项)。数据处理系统102可以包括至少一个内容转换组件108,以确定是否将以第一模态或格式的内容项转换为不同模态或格式。转换内容项可以是指或包括以不同的格式生成新的内容项(例如,由可
视内容项生成音轨,或由仅可视内容项生成视听内容项)。新内容项可以包括或可以不包括原始内容项的一部分。内容转换组件110可以包括格式选择器112、文本生成器114、语音选择器116、动作生成器136或音频提示生成器118。数据处理系统102可以包括至少一个内容插入组件120,其可以确定何时或何处插入内容项。数据处理系统102可以包括至少一个机器学习引擎122。数据处理系统102可以包括至少一个数据存储库124。数据存储库124可以包括或存储一个或多个数据结构、数据文件、数据库或其他数据。数据存储库124可以包括一个或多个本地或分布式数据库,并且可以包括数据库管理系统。数据存储库124可以包括计算机数据存储装置或存储器。
21.数据存储库124可以包括、存储或维护语音模型126、动作模型128、插入模型130、内容数据132或音频提示134。语音模型126可以包括基于包括音频或视听内容的历史内容项以及与该历史内容项相关联的元数据通过使用机器学习引擎122所训练的模型。也可以通过使用与历史内容项相关联的性能信息来训练语音模型126。
22.动作模型128可以包括通过使用机器学习引擎122训练的模型,该模型可以为内容项确定动作或交互的类型。例如,用户可以通过询问有关内容项的更多信息、进行购买、选择超链接、暂停、前进、倒带或跳过内容项来与内容项进行交互或执行一些其他动作。数据处理系统102可以使用动作模型128来确定或预测与内容项的可能交互,然后为所预测的交互配置内容项。动作模型128还可以包括映射到预定动作的内容项的类别。
23.可以使用机器学习引擎122来训练插入模型130,以确定何处插入所生成的内容项,诸如在数字音乐流中的何处。可以使用历史数据来训练插入模型130,诸如在何处将不同类型的内容项插入数字音乐流中。
24.内容数据132可以包括关于由3p数字内容提供者设备160提供的内容项或数字组件对象的数据。内容数据132可以包括例如可视内容项或可视内容项的指示、内容活动参数、关键字或有助于内容选择或内容分发的其他数据。
25.音频提示134可以是指可以被添加到基线音轨的非话语音频提示。音频提示134可以包括音频文件和用于描述音频文件的元数据。示例性音频提示可以是海浪声、鸟鸣、体育赛事中的观众欢呼、刮风或汽车发动机声音。
26.接口104、自然语言处理器组件106、内容选择器组件108、内容转换组件110、格式选择器组件112、文本生成器组件114、语音选择器组件116、动作生成器136、音频提示生成器118、内容插入组件120、机器学习引擎122或数据处理系统102的其他组件中的每一个可以包括或利用至少一个处理单元或其他逻辑设备,诸如可编程逻辑阵列引擎,或被配置为与彼此或其他资源或数据库进行通信的模块。接口104、自然语言处理器组件106、内容选择器组件108、内容转换组件110、格式选择器组件112、文本生成器组件114、语音选择器组件116、音频提示生成器118、内容插入组件120、机器学习引擎122或数据处理系统102的其他组件可以是分开的组件、单个组件或数据处理系统102的一部分。系统100及其组件(诸如数据处理系统102)可以包括硬件元件,诸如一个或多个处理器、逻辑设备或电路。数据处理系统102的组件、系统或模块可以至少部分地由数据处理系统102执行。
27.计算设备140可以包括接口,或以其他方式与至少一个传感器148、换能器144、音频驱动器150、预处理器142或显示设备146通信。传感器148可以包括例如环境光传感器、接近传感器、温度传感器、加速度计、陀螺仪、运动检测器、gps传感器、位置传感器、麦克风或
触摸传感器。换能器144可以包括扬声器或麦克风。音频驱动器150可以向硬件换能器144提供软件界面。音频驱动器可以执行音频文件或由数据处理系统102提供的其他指令,以控制换能器144产生相应的声波或音波。显示设备146可以包括图3描绘的显示器335的一个或多个组件或功能。预处理器142可以被配置为检测触发关键字、预定热词、启动关键字或激活关键字。在一些情况下,触发关键字可以包括执行动作(诸如,通过使用动作模型128由动作生成器136选择的动作)的请求。在一些情况下,触发关键字可以包括预定动作关键字以使能或激活计算设备140,并且请求关键字可以在触发关键字或热词之后。预处理器142可以被配置为检测关键字并基于该关键字执行动作。预处理器142可以检测唤醒词或其他关键字或热词,并且响应于该检测,调用由计算设备140执行的数据处理系统102的自然语言处理器组件106。在一些情况下,在将术语传输到数据处理系统102以进行进一步处理之前,预处理器142可以过滤掉一个或多个术语或修改术语。预处理器142可以将由麦克风检测到的模拟音频信号转换为数字音频信号,并且经由网络105,将携带数字音频信号的一个或多个数据分组传输或提供给数据处理系统102或数据处理系统102。在一些情况下,响应于检测到执行这种传输的指令,预处理器142可以向自然语言处理器组件106或数据处理系统102提供携带一些或全部输入音频信号的数据分组。该指令可以包括例如触发关键字或其他关键字或许可,以将包括输入音频信号的数据分组传输到数据处理系统102或数据处理系统102。
28.客户端计算设备140可以与终端用户相关联,该终端用户将语音查询作为音频输入(经由传感器148)输入到客户端计算设备140中,并且接收以计算机生成的语音形式的音频输出,其被从数据处理系统102(或3p数字内容提供者设备160)提供到客户端计算设备140、从换能器144(例如,扬声器)输出。计算机生成的语音可以包括来自真实人的录音或计算机生成语言。
29.计算设备140可以执行应用152。数据处理系统102可以包括或执行操作系统,经由该操作系统,计算设备140可以执行应用152。应用152可以包括客户端计算设备140被配置为执行、运行、启动或以其他方式提供的任何类型的应用。应用152可以包括多媒体应用、音乐播放器、视频播放器、web浏览器、文字处理器、移动应用、桌面应用、平板电脑应用、电子游戏、电子商务应用或其他类型的应用。应用152可以执行、渲染、加载、解析、处理、呈现或以其他方式输出与电子资源相对应的数据。电子资源可以包括例如,网站、网页、多媒体web内容、视频内容、音频内容、数字流媒体内容、旅行内容、娱乐内容、与购买商品或服务有关的内容或其他内容。
30.在计算设备140上执行的应用152可以从第三方(“3p”)电子资源服务器162接收与电子资源相关联的数据。3p电子资源服务器162可以提供用于由所述应用执行的电子资源。3p电子资源服务器162可以包括文件服务器、web服务器、游戏服务器、多媒体服务器、云计算环境或其他后端计算系统,其被配置为提供数据以使所述应用经由计算设备140呈现或提供电子资源。计算设备140可以经由网络105访问3p电子资源服务器162。
31.3p电子资源服务器162的管理员可以开发、建立、维护或提供电子资源。3p电子资源服务器162可以响应于对电子资源的请求,将电子资源传输到计算设备140。电子资源可以与标识符(诸如统一资源定位符(“url”)、统一资源标识符、网址或文件名或文件路径)相关联。3p电子资源服务器162可以从应用152接收对电子资源的请求。电子资源可以包括电
子文档、网页、多媒体内容、流媒体内容(例如音乐、新闻或播客)、音频、视频、文字、图像、视频游戏、或其他数字或电子内容。
32.数据处理系统102可以访问至少一个3p数字内容提供者设备160或以其他方式与之交互。3p数字内容提供者设备160可以包括至少一个逻辑设备,诸如具有处理器的计算设备,以经由网络105与例如计算设备140、数据处理系统102或数据处理系统102通信。3p数字内容提供者设备160可以包括至少一个计算资源、服务器、处理器或存储器。例如,3p数字内容提供者设备160可以包括位于至少一个数据中心中的多个计算资源或服务器。3p数字内容提供者设备160可以包括或指代广告商设备、服务提供者设备或商品提供者设备。
33.3p数字内容提供者设备160可以提供数字组件以由计算设备140呈现。数字组件可以是用于经由计算设备140的显示设备146呈现的可视数字组件。数字组件可以包括对搜索查询或请求的响应。数字组件可以包括来自数据库、搜索引擎或网络资源的信息。例如,数字组件可以包括新闻信息、天气信息、体育信息、百科全书条目、字典条目或来自数字教科书的信息。数字组件可以包括广告。数字组件可以包括商品或服务的要约,诸如陈述“您要购买运动鞋吗?(would you like to purchase sneakers?)”的消息。3p数字内容提供者设备160可以包括存储器,以存储可以响应于查询而提供的一系列数字组件。3p数字内容提供者设备160还可以将基于可视或音频的数字组件(或其他数字组件)提供给数据处理系统102,在此可以存储它们以供内容选择器组件108选择。数据处理系统102可以选择数字组件,并向客户端计算设备140提供(或指示内容提供者计算设备160提供)所述数字组件。数字组件可以是专门的可视、专门的音频、或者是音频和视频数据与文本、图像或视频数据的组合。数字组件或内容项可以包括以一种或多种格式的图像、文本、视频、多媒体或其他类型的内容。
34.数据处理系统102可以包括具有至少一个计算资源或服务器的内容投放系统。数据处理系统102可以包括至少一个内容选择器组件108,与该至少一个内容选择器组件108连接或以其他方式与之通信。数据处理系统102可以包括至少一个数字助理服务器、与该至少一个数字助理服务器连接或以其他方式与之通信。
35.数据处理系统102可以获得与多个计算设备140相关联的匿名计算机网络活动信息。计算设备140的用户可以肯定地授权数据处理系统102获得与用户的计算设备140相对应的网络活动信息。例如,数据处理系统102可以提示计算设备140的用户以同意获得一种或多种网络活动信息。计算设备140的用户的身份可以保持匿名,并且计算设备140可以与唯一标识符(例如,用于由数据处理系统提供的用户或计算设备或计算设备的用户的唯一标识符)相关联。数据处理系统102可以将每个观察与相应的唯一标识符相关联。
36.3p数字内容提供者设备160可以建立电子内容活动。电子内容活动可以作为内容数据被存储在内容选择器组件的存储库108中。电子内容活动可以是指对应于共同主题的一个或多个内容组。内容活动可以包括分层数据结构,该分层数据结构包括内容组、数字组件数据对象和内容选择标准。为了创建内容活动,3p数字内容提供者设备160可以为内容活动的活动级别参数指定值。活动级别参数可以包括例如活动名称、用于投放数字组件对象的首选内容网络、将用于内容活动的资源的值、内容活动的开始和结束日期、内容活动的持续时间、数字组件对象投放的时间表、语言、地理位置、要在其上提供数字组件对象的计算设备的类型。在一些情况下,印象可以是指何时从其来源(例如,数据处理系统102或数字内
容提供者设备160)中提取数字组件对象,并且是可计数的。在一些情况下,由于可能会发生点击欺骗,因此作为印象,可以过滤并排除机器人活动。因此,在一些情况下,印象可以是指对来自浏览器的页面请求的来自web服务器的响应的度量,该度量过滤掉机器人活动和错误代码,并且被记录在尽可能接近渲染数字组件对象以在显示设备140上显示的机会的点处。在一些情况下,印象可以是指可见的或可听的印象;例如,数字组件对象在客户端计算设备140的显示设备上至少部分可见(例如20%、30%、30%、40%、50%、60%、70%或更多),或可经由计算设备140的扬声器136可听。点击或选择可以是指用户与数字组件对象的交互,诸如对可听印象的语音响应、鼠标单击、触摸交互、手势、摇动、音频交互或键盘点击。转换可以是指用户相对于数字组件对象采取了预期的动作;例如,购买产品或服务、完成调查、访问与数字组件相对应的实体商店、或完成电子交易。
37.3p数字内容提供者设备160可以进一步为内容活动建立一个或多个内容组。内容组包括一个或多个数字组件对象和相应的内容选择标准,诸如关键字、词、术语、短语、地理位置、计算设备的类型、时刻、兴趣、主题或垂直元(vertical)。相同内容活动下的内容组可以共享相同的活动级别参数,但是可以针对特定内容组级别参数定制规范,诸如关键字、否定性关键字(例如,在主要内容上存在否定性关键字的情况下阻止投放数字组件)、关键字出价、或与出价或内容活动相关联的参数。
38.为了创建新的内容组,3p数字内容提供者设备160可以提供内容组的内容组级别参数的值。内容组级别参数包括例如内容组名称或内容组主题以及对不同内容投放机会(例如,自动投放或管理投放)或结果(例如,点击、印象或转化)的出价。内容组名称或内容组主题可以是一个或多个术语,3p数字内容提供者设备160可以使用该术语来捕获将为其被选择内容组的数字组件对象的话题或主题以进行显示。例如,汽车经销商可以为其出售的每个品牌的车辆创建不同的内容组,并且可以进一步为其出售的每种型号的车辆创建不同的内容组。汽车经销商可以使用的内容组主题的示例包括例如“品牌a跑车(make a sports car)”、“品牌b跑车(make b sports car)”、“品牌c轿车(make c sedan)”、“品牌c卡车(make c truck)”、“品牌c混合动力车(make c hybrid)”或“品牌d混合动力车(make d hybrid)”。示例性内容活动主题可以是“混合动力车”并且包括例如用于“品牌c混合动力车(make c hybrid)”和“品牌d混合动力车(make d hybrid)”两者的内容组。
39.3p数字内容提供者设备160可以向每个内容组提供一个或多个关键字和数字组件对象。关键字可以包括与产品或服务有关的术语,所述产品或服务与数字组件对象相关联或由数字组件对象标识。关键字可以包括一个或多个术语或短语。例如,汽车经销商可以包括“跑车”、“v-6发动机”、“四轮驱动”、“燃油效率”以作为内容组或内容活动的关键字。在一些情况下,可以由内容提供者指定否定性关键字以避免、防止、阻止或禁用有关某些术语或关键字的内容投放。内容提供者可以指定用于选择数字组件对象的匹配类型,诸如精确匹配、短语匹配或宽泛匹配。
40.3p数字内容提供者设备160可以提供一个或多个关键字以供数据处理系统102使用来选择由3p数字内容提供者设备160提供的数字组件对象。3p数字内容提供者设备160可以识别要出价的一个或多个关键字,并且进一步提供用于各种关键字的出价金额。3p数字内容提供者设备160可以提供其他内容选择标准以供数据处理系统102使用以选择数字组件对象。多个3p数字内容提供者设备160可以对相同或不同的关键字出价,并且数据处理系
统102可以响应于接收到电子消息的关键字的指示来运行内容选择过程或广告拍卖。
41.3p数字内容提供者设备160可以提供一个或多个数字组件对象以供数据处理系统102选择。当与资源分配、内容时间表、最高出价、关键字和为内容组指定的其他选择标准匹配的内容投放机会变得可用时,数据处理系统102(例如经由内容选择器组件108)可以选择数字组件对象。在内容组中可以包括不同类型的数字组件对象,诸如语音数字组件、音频数字组件、文本数字组件、图像数字组件、视频数字组件、多媒体数字组件或数字组件链接。在选择数字组件后,数据处理系统102可以传输数字组件对象以经由计算设备140呈现、在计算设备140上或在计算设备140的显示设备上渲染。渲染可以包括在显示设备上显示数字组件,或者经由计算设备140的扬声器播放数字组件。数据处理系统102可以向计算设备140提供指令以渲染数字组件对象。数据处理系统102可以指示计算设备140的自然语言处理器组件106或计算设备140的音频驱动器150以生成音频信号或声波。数据处理系统102可以指示由计算设备140执行的应用来呈现所选择的数字组件对象。例如,该应用(例如,数字音乐流媒体应用)可以包括其中可以呈现数字组件对象的插槽(例如,内容插槽)(例如,音频插槽或可视插槽)。
42.数据处理系统102可以包括至少一个接口104。数据处理系统102可以包括被设计、配置、构造或操作为通过使用例如数据分组来接收和传输信息的接口104。接口104可以通过使用一种或多种协议(诸如网络协议)来接收和传输信息。接口104可以包括硬件接口、软件接口、有线接口或无线接口。接口104可以有助于将数据从一种格式转换或格式化为另一种格式。例如,接口104可以包括应用编程接口,该应用编程接口包括用于在诸如软件组件之类的各种组件之间进行通信的定义。接口104可以有助于在系统100的一个或多个组件之间的通信,诸如在自然语言处理器组件106、内容选择器组件108、内容转换组件110和数据存储库124之间的通信。
43.接口104可以经由网络105接收数据分组,该数据分组包括由远离数据处理系统102的计算设备140的麦克风(例如,传感器148)检测到的输入音频信号。计算设备140的用户可以向计算设备140提供话音或语音输入,并且指示或以其他方式使计算设备140将输入的音频信号或由预处理器142基于该音频信号生成的数据分组传输到数据处理系统102。
44.数据处理系统102可以包括自然语言处理器组件106、与自然语言处理器组件106连接或以其他方式与自然语言处理器组件106通信,该自然语言处理器组件106被设计、构造和操作以解析该数据分组或输入音频信号。自然语言处理器组件106可以包括数据处理系统102处的硬件、电子电路、应用、脚本或程序。自然语言处理器组件106可以接收输入信号、数据分组或其他信息。自然语言处理器组件106可以包括或被称为话音识别器,该话音识别器被配置为处理包含话音的输入音频信号以将话音转录为文本,然后执行自然语言处理以理解转录的文本。自然语言处理器组件106可以经由接口104接收数据分组或其他输入。自然语言处理器组件106可以包括用于从数据处理系统102的接口104接收输入音频信号并驱动客户端计算设备的组件以渲染输出音频信号的应用。数据处理系统102可以接收包括或识别音频输入信号的数据分组或其他信号。例如,自然语言处理器组件106可以配置有可以接收或获得音频信号并解析音频信号的nlp技术、功能或组件。自然语言处理器组件106可以提供在人与计算机之间的交互。自然语言处理器组件106可以配置有用于理解自然语言并允许数据处理系统102从人类或自然语言输入中得出含义的技术。自然语言处理器
组件106可以包括或配置有基于机器学习的技术,诸如统计机器学习。自然语言处理器组件106可以利用决策树、统计模型或概率模型来解析输入音频信号。自然语言处理器组件106可以执行例如诸如命名实体识别之类的功能(例如,给出文本流、确定文本中的哪些项映射到诸如人或地点的适当名称,以及每一这样的名称是什么类型,诸如人、位置或组织)、自然语言生成(例如,将来自计算机数据库或语义意图的信息置换成可理解的人类语言)、自然语言理解(例如,将文本转换为更正式的表示,诸如计算机模块可以操作的一阶逻辑结构)、机器翻译(例如,自动地将文本从一种人类语言翻译为另一种人类语言)、形态学分割(例如,将单词分离为单个词素并识别词素的类别,基于所考虑的语言的单词的词法或结构的复杂性,这可能具有挑战性)、问题回答(例如,确定人类语言问题的答案,其可以是特定的或开放式的)、语义处理(例如,在识别单词并对其含义进行编码以便将所识别的单词与具有相似含义的其他单词相关联之后发生的处理)。
45.自然语言处理器组件106可以(例如,利用nlp技术、功能或组件)通过使用基于包含的训练数据的机器学习模型训练,将音频输入信号转换为识别的文本。音频波形的集合可以被存储在数据存储库124或数据处理系统102可访问的其他数据库中。可以在大的用户集上生成代表性的波形,然后可以利用来自用户的语音样本来增强。在音频信号被转换成所识别的文本之后,自然语言处理器组件106可以将文本与单词匹配,所述单词例如通过使用存储在数据存储库124中的、已经过用户训练的或者通过手动指定的模型而与数据处理系统102可以提供的动作相关联。
46.音频输入信号可以由客户端计算设备140的传感器148或换能器144(例如,麦克风)检测。经由换能器144、音频驱动器150或其他组件,客户端计算设备140可以向数据处理系统102提供音频输入信号,在此可以被(例如接口104)接收,并且将其提供给nlp组件106或存储在数据存储库124中。
47.自然语言处理器组件106可以获得输入音频信号。从输入音频信号中,自然语言处理器组件106可以识别至少一个请求或至少一个触发关键字、关键字或请求。该请求可以指示输入音频信号的意图或主题。关键字可以指示可能采取的动作的类型。例如,自然语言处理器组件106可以解析输入音频信号,以识别至少一个请求以调用应用、与内容项交互或请求内容。自然语言处理器组件106可以解析输入音频信号以识别至少一个请求,诸如,晚上出门吃晚餐和看电影的请求。关键字可以包括至少一个单词、短语、词根或部分单词,或表示要采取的动作的派生词。例如,来自输入音频信号的关键字“去(go)”或“要去(to go to)”可以指示交通需要。在该示例中,输入音频信号(或所识别的请求)未直接表达交通意图,但是该关键字指示交通是由所述请求指示的至少一个其他动作的辅助动作。
48.自然语言处理器组件106可以解析输入音频信号以识别、确定、检索或以其他方式获得请求和关键字。例如,自然语言处理器组件106可以将语义处理技术应用于输入音频信号以识别关键字或请求。自然语言处理器组件106可以将语义处理技术应用于输入音频信号以识别一个或多个关键字。关键字可以包括一个或多个术语或短语。自然语言处理器组件106可以应用语义处理技术来识别执行数字动作的意图。
49.例如,计算设备140可以接收由客户端计算设备140的传感器148(例如,麦克风)检测到的输入音频信号。输入音频信号可以是“数字助理,我需要有人帮我洗衣服和干洗(digital assistant,i need someone to do my laundry and my dry cleaning)”。客户
端计算设备140的预处理器142可以检测输入音频信号中的唤醒词、热词或触发关键字,诸如“数字助理”。预处理器142可以通过将输入音频信号中的音频签名或波形与对应于触发关键字的模型音频签名或波形进行比较来检测唤醒词、热词或触发关键字。预处理器142可以确定输入音频信号包括唤醒词、热词或触发关键字,其指示输入音频信号将由自然语言处理器组件106处理。响应于检测到热词、唤醒词或触发关键字,预处理器142可以向数据处理系统102确定、授权、路由、转发或以其他方式提供所检测到的输入音频信号,以由自然语言处理器组件106进行处理。
50.自然语言处理器组件106可以接收输入音频信号并将语义处理技术或其他自然语言处理技术应用于包括句子的输入音频信号,以识别触发短语“洗衣服(do my laundry)”和“干洗(do my dry cleaning)”。在一些情况下,自然语言处理器组件106可以将对应于输入音频信号的数据分组提供给数据处理系统102,以使自然语言处理器组件106处理输入音频信号。自然语言处理器组件106可以结合或经由数字助理服务器来处理输入音频信号。自然语言处理器组件106可以进一步识别多个关键字,例如洗衣店和干洗。
51.自然语言处理器组件106可以识别与执行对信息的搜索或其他请求相对应的搜索查询、关键字、意图或短语。自然语言处理器组件106可以确定输入音频信号对应于对有关主题、事件、当前事件、新闻事件、字典定义、历史事件、人、地点或事物的信息的请求。例如、自然语言处理器组件106可以确定输入音频信号对应于查询、请求、意图或动作,以进行旅行安排、预定行程、获得信息、执行web搜索、检查股票价格、启动应用、查看新闻、订购食物、或购买其他产品、商品或服务。
52.自然语言处理器组件106可以使用一种或多种技术来解析或处理输入音频信号。技术可以包括基于规则的技术或统计技术。技术可以利用机器学习或深度学习。示例性技术可以包括命名实体识别、情感分析、文本摘要、方面挖掘或主题挖掘。技术可以包括或基于文本嵌入(例如,字符串的实数值向量表示)、机器翻译(例如,语言分析和语言生成)、或对话和会话(例如,人工智能使用的模型)。技术可以包括确定或利用语法技术(例如,基于语法的句子中的单词排列),诸如词条化、形态学分割、单词分割、词性标记、解析、断句或词干。技术可以包括确定或利用语义技术,诸如命名实体识别(例如,确定可以被识别和分类为当前组的文本部分,例如应用152的名称、人员或地点)、词义消歧或自然语言生成。
53.在一些情况下,自然语言处理器组件106可以识别启动应用152的请求,并且向计算设备140提供指令以启动应用152。在一些情况下,应用152可能已经在自然语言处理器组件106接收输入音频信号之前被启动。例如,基于对输入音频信号的处理或解析,自然语言处理器组件106可以识别应用152以调用、启动、打开或以其他方式激活。自然语言处理器组件106可以基于解析输入音频信号以识别术语、关键字、触发关键字或短语来识别应用152。自然语言处理器组件106可以使用所识别的术语、关键字、触发关键字或短语来在数据存储库124中执行查找以识别应用152。在一些情况下,关键字可以包括应用152的标识符,诸如“application_name_a”或“application_name_b”。在一些情况下,关键字可以指示应用152的类型或类别,诸如拼车应用、餐厅预订应用、电影票应用、新闻应用、天气应用、导航应用、流媒体音乐应用、流媒体视频应用、餐厅评论应用或其他类型或类别的应用152。对于在接收到输入音频信号之前可能已经启动和执行应用152的情况,自然语言处理器组件106可以处理输入音频信号以确定在应用152中要执行的动作或对经由被应用152渲染的电子资源
呈现的调用动作进行响应。
54.数据处理系统102可以经由计算机网络,接收对在计算设备140上呈现的内容的请求。数据处理系统102可以通过处理由客户端计算设备140的麦克风检测到的输入音频信号来识别该请求。该请求可以包括该请求的选择标准,诸如设备类型、位置、以及与该请求相关联的关键字。选择标准可以包括关于计算设备140的场境的信息。计算设备140的场境可以包括关于正在计算设备140上执行的应用的信息、关于计算设备140的位置的信息、关于正在经由计算设备140(例如经由应用152)渲染、呈现、提供或访问的内容的信息。例如,内容选择标准可以包括信息或关键字,诸如与正在经由数字流媒体音乐应用152播放的音乐相关联的艺术家、歌曲标题或流派。在一些情况下,内容选择标准可以包括与应用152的浏览历史相关联的关键字。
55.数据处理系统102可以确定以选择由3p数字内容提供者设备160提供的数字组件。数据处理系统102可以响应于来自计算设备140的请求,确定以选择数字组件。数据处理系统102可以响应于识别应用152中的内容插槽来确定以选择数字组件。数据处理系统102可以响应于事件、条件、触发或基于时间间隔来确定以选择数字组件。
56.数据处理系统102可以从可以包括由一个或多个3p数字内容提供者设备160提供的内容的数据存储库124或数据库中选择数字组件对象,并且经由网络105提供数字组件以经由计算设备140呈现。计算设备140可以与数字组对象进行交互。计算设备140可以接收对数字组件的音频响应。计算设备140可以接收指示以选择与数字组件对象相关联的超链接或其他按钮,该指示使得或允许计算设备140识别商品或服务提供者、请求来自商品或服务提供者的商品或服务、指示商品或服务提供者执行服务、向服务提供者传输信息或以其他方式查询商品或服务提供者设备。
57.数据处理系统102可以包括、执行或以其他方式与内容选择器组件108通信,以接收请求、查询、关键字或内容选择标准,并且基于所接收到的信息来选择数字组件。数据处理系统102可以基于输入到实时内容选择过程中的内容选择标准来选择数字组件对象。数据处理系统102可以从存储由多个第三方内容提供者160提供的多个数字组件对象的数据存储库124中选择数字组件对象。
58.数据处理系统102可以将用于选择内容数据132中的数字组件对象的信息存储在数据存储库124中的数据结构或数据库中。内容数据132可以包括内容选择标准、数字组件对象、历史性能信息、首选项、或用于选择和传递数字组件对象的其他信息。
59.内容选择器组件108可以经由实时内容选择过程来选择数字组件。内容选择过程可以包括例如经由搜索引擎执行搜索,或访问存储在远程服务器或设备(诸如3p数字内容提供者设备160)上的数据库。内容选择过程可以是指或包括:选择由第三方内容提供者160提供的赞助数字组件对象。实时内容选择过程可以包括服务,在所述服务中由多个内容提供者提供的数字组件被解析、处理、加权或匹配以便选择提供给计算设备140的一个或多个数字组件。内容选择器组件108可以实时执行内容选择过程。实时执行内容选择过程可以是指响应于对经由客户端计算设备140接收的内容的请求来执行内容选择过程。可以在接收请求的一段时间间隔(例如1秒、2秒、5秒、10秒、20秒、30秒、1分钟、2分钟、3分钟、5分钟、10分钟或20分钟)内执行实时内容选择过程。可以在与客户端计算设备140的通信会话期间或者在终止通信会话之后的一段时间间隔内,执行实时内容选择过程。该实时内容选择过程
可以是指或包括在线内容项拍卖。
60.为了选择数字组件以在基于语音的环境中呈现,数据处理系统102(例如,经由自然语言处理器组件106的nlp组件)可以解析输入音频信号以识别查询、关键字,并且使用关键字和其他内容选择标准来选择匹配的数字组件。内容选择器组件108可以基于与在请求之前正在计算设备140上执行的应用152渲染的内容相关联的关键字来选择数字组件对象。数据处理系统102可以基于广泛匹配、精确匹配或短语匹配来选择匹配的数字组件。例如,内容选择器组件108可以分析、解析或以其他方式处理候选数字组件的主题,以确定候选数字组件的主题是否对应于由客户端计算设备140的麦克风检测到的输入音频信号的关键字或短语的主题。内容选择器组件108可以通过使用图像处理技术、字符识别技术、自然语言处理技术或数据库查找来标识、分析或识别候选数字组件的语音、音频、术语、字符、文字、符号或图像。候选数字组件可以包括用于指示候选数字组件的主题的元数据,在这种情况下,内容选择器组件108可以处理元数据以确定候选数字组件的主题是否对应于输入音频信号。
61.3p数字内容提供者160可以在设置包括数字组件的内容活动时提供其他指示符。内容提供者可以在内容活动或内容组级别上提供关于内容选择器组件108可以通过使用有关候选数字组件的信息执行查找来识别的信息。例如,候选数字组件可以包括唯一标识符,其可以映射到内容组、内容活动或内容提供者。内容选择器组件108可以基于存储在数据存储库124中的内容活动数据结构中的信息,确定有关3p数字内容提供者设备160的信息。
62.由内容选择器组件108选择的数字组件对象的格式或模态可以是可视的、视听的或仅音频的。具有仅可视格式的数字组件对象可以是图像或带有文字的图像。具有仅音频格式的数字组件对象可以是音轨。具有视听格式的数字组件对象可以是视频剪辑。可以基于数字组件对象的格式,对不同类型的交互配置数字组件对象。例如,可以对经由键盘、鼠标或触摸屏输入的交互(例如,以选择嵌入在数字组件对象中的超链接),配置仅可视的数字组件对象。可以对经由语音输入的交互(例如,被配置为检测预定关键字以执行动作),配置仅音频数字组件对象。
63.但是,由内容选择器组件108选择的数字组件对象的格式可能与计算设备140不兼容,或者可能未被优化以由计算设备140呈现。在一些情况下,数据处理系统102可以过滤对计算设备140兼容或优化的数字组件对象。基于格式或模态的过滤可能导致选择具有对计算设备140兼容或优化的格式的数字组件对象。基于格式或模态的过滤可能会妨碍选择可能与内容选择标准相关或更好匹配的数字组件对象,因为所述数字组件对象的格式可能对计算设备140不兼容或未优化。例如,如果计算设备140是没有显示设备146的智能扬声器,则可以过滤掉或阻止选择可视内容项,而将选择限于仅音频内容项。在可视内容项与所选择的仅音频内容项相比包含与内容选择标准更好匹配的关键字的情况下,数据处理系统102可能无法提供最佳匹配的内容项。由于未提供最佳匹配内容项,数据处理系统102可能会由于提供不相关的内容项来呈现,浪费了计算设备140的计算资源消耗、网络带宽或电池电量。
64.因此,该技术解决方案可以基于内容选择标准并且不考虑格式来选择最匹配的数字组件对象,然后将数字组件对象转换为对计算设备140优化或兼容的格式。通过不由于格式或模态而未移除或阻止被选择的内容项,因此该技术解决方案可以基于相关性和其他内
容选择标准来选择排名最高的内容项,然后将内容项实时转换为所需格式。
65.为此,数据处理系统102可以包括内容转换组件110,该内容转换组件110被设计、构造和操作为以不同于由3p数字内容提供者设备160提供的数字组件对象的原始格式的格式来生成数字组件对象。3p数字内容提供者设备160可以以第一格式提供原始内容项,而数据处理系统102可以以第二格式生成基于原始内容项的第二内容项。例如,内容选择器组件108可以基于请求或内容选择标准来选择具有可视输出格式的数字组件对象。内容转换组件110可以确定计算设备140缺少显示设备,但是具有音频接口。然后,内容转换组件110可以生成具有仅音频格式的新的数字组件对象。内容转换组件110可以使用与数字组件对象相关联的元数据来生成所述具有仅音频格式的新的数字组件对象。内容转换组件110可以为新内容项选择格式、基于原始内容项生成文本、为新内容项选择语音、对新内容项生成非话语音频提示、生成用于与新内容项交互的动作、且然后生成提供给计算设备140的新内容项。
66.内容转换组件110可以包括格式选择器112,格式选择器112被设计、构造和操作为基于由内容选择器组件108选择的数字组件对象来选择用于生成数字组件对象的格式。格式选择器112可以使用各种技术或因素来确定用于将数字组件对象转换成的格式。因素可以包括例如计算设备140的类型、计算设备140的可用接口、计算设备140的剩余电池电量、计算设备140的位置、与计算设备140相关联的交通方式(例如,驾驶、火车、飞机、步行、跑步、骑自行车或静止)、在计算装置140的前台中执行的应用152的类型、计算装置140的状态、或其他因素。在一些情况下,因素可以包括用户活动,诸如烹饪、工作或放松。数据处理系统102可以基于时刻或最近的搜索活动(例如,寻找食谱)来确定用户正在烹饪。数据处理系统102可以基于时刻、星期几和位置(例如,营业地点)来确定用户是否在工作。数据处理系统102可以基于时刻、位置和计算设备140上的活动(例如,流式传输电影)来确定用户是否正在放松。
67.格式选择器112可以基于计算设备140的类型来选择用于将所选择的数字组件对象转换成的格式。格式选择器112可以接收有关计算设备140的类型的信息以及对内容的请求。例如,由计算设备140提供的对内容的请求可以指示计算设备140的类型。在没有接收到对内容的请求的情况下,格式选择器112可以基于与计算设备140相关联的账户信息或简档信息,或从在计算设备140上正在执行的应用152接收的信息,来确定计算设备140的类型。在一些情况下,格式选择器112可以向计算设备140查询关于计算设备140的类型的信息。计算设备140的示例性类型可以包括膝上型计算机、平板电脑、智能手表、可穿戴设备、智能手机、智能扬声器、智能电视、或物联网设备(例如,智能仪表或智能灯)。设备的类型可以指示在计算设备140上可用的接口的类型(例如,可视输出接口、音频输出接口、音频输入接口、触摸输入接口或键盘和鼠标接口)。例如,如果计算设备140的类型是智能扬声器,则数据处理系统102可以确定计算设备140的主要接口是音频接口,并且计算设备140缺少显示设备。格式选择器112可以响应于用于设备类型的主要接口是仅音频接口,确定将原始可视数字组件对象转换为仅音频格式的数字组件对象。在另一示例中,如果计算设备的类型是智能电视,则数据处理系统102可以确定主要接口是视听接口。响应于确定主要接口是视听界面,格式选择器112可以确定将原始的仅可视的数字组件对象转换为视听数字组件对象。通过将数字组件对象转换为用于计算设备140的类型的主要格式,数据处理系统102可以优化
数字组件对象在计算设备140上的渲染或呈现。优化渲染或呈现可以是指通过使用计算设备140的用户接口中的主要用户接口或主要组合来输出数字组件对象。
68.格式选择器112可以基于计算设备140的可用接口来选择用于转换的格式。计算设备140的类型可以指示计算设备140所包括的接口的类型。但是,一个或多个接口可能不可用,在这种情况下,格式选择器112可以识别可用接口,且然后将数字组件对象转换为与可用接口相对应的格式。例如,计算设备140可以输出诸如流媒体数字音乐的音频同时禁用或关闭显示设备146,这可以减少功耗。在该示例中,格式选择器112可以确定由于已经关闭了显示设备146,可视接口当前不可用,但是可以确定音频输出接口是可用的,因为它当前正在输出音频。在另一示例中,如果音频已经被静音,则格式选择器112可以确定音频接口不可用,并且如果显示设备146正在主动提供可视输出,则格式选择器112可以确定可视输出接口可用。因此,如果音频接口不可用,则格式选择器112可以为数字组件对象选择可视输出格式;如果可视接口不可用,则格式选择器112可以为数字组件对象选择音频输出格式。如果可视或音频输出接口均不可用,则格式选择器112可以终止内容转换并阻止递送数字组件对象,以避免浪费计算资源利用和网络带宽利用。
69.格式选择器112可以基于计算设备140的剩余电池电量来确定输出接口。例如,如果剩余电池电量低于阈值(例如,10%、15%、20%、25%或一些其他阈值),则格式选择器112可以确定选择用于利用最少能量进行渲染的格式,诸如与显示设备相比可以消耗较少能量的音频输出。
70.格式选择器112可以基于计算设备140的交通方式来选择数字组件对象的格式。示例性交通方式可以包括驾驶、火车、飞机、步行、跑步、骑自行车或静止(例如,没有移动或没有交通)。如果交通方式是驾驶、跑步或骑自行车,则格式选择器112可以选择仅音频的输出格式,从而避免使用户分心并避免浪费能量消耗,因为在那些交通方式下,用户可能无法感知可视输出。如果交通方式是步行、静止、公共交通或飞机,则格式选择器112可以选择可视输出或视听输出格式,因为可视输出可能不会使用户分心并且用户很可能能够感知可视输出。
71.格式选择器112可以基于正在计算设备140的前台中执行的应用152的类型来选择数字组件对象的格式。如果应用152的主要输出接口是仅音频的,诸如数字音乐流媒体应用152,则格式选择器112可以选择例如音频输出格式。如果应用152的主要输出接口是仅可视格式,则格式选择器112可以选择仅可视输出。如果应用152的主要输出接口是视听输出的组合,诸如在数字视频流媒体应用152中,则格式选择器112可以对数字组件对象选择视听输出格式。
72.格式选择器112可以基于作为数字助理设备的计算设备140的类型,或者基于计算设备140正在执行包括数字助理应用的应用152,来选择用于数字组件对象的格式。数字助理应用可以是指或包括虚拟助理。数字助理应用可以包括可以基于命令或问题而执行任务或服务的软件代理。数字助理应用152可以被配置为接收和处理(例如,由用户说出的)自然语言输入,且然后执行任务、动作或提供对输入的响应。格式选择器112可以响应于应用152的类型或作为数字助理的计算设备140来确定选择用于数字组件对象的仅音频格式,因为数字助理应用152的主要接口可以是基于语音(或基于音频)的接口。
73.内容转换组件110可以包括文本生成器114,该文本生成器114被设计、构造和操作
为基于数字组件对象生成文本。例如,响应于格式选择器112确定将可视数字组件对象转换成仅音频的数字组件对象,文本生成器114可以处理数字组件对象以生成可以经由音频输出的文本。为了基于可视组件对象生成文本,文本生成器114可以解析可视组件中的文本、应用图像处理技术来处理可视数字组件对象,或者应用光学字符识别技术。文本生成器114可以获得与可视组件对象相关联的元数据,并且解析或处理该元数据以生成文本。元数据可以包括例如产品规格或产品描述。因此,文本生成器114可以使用例如可视数字组件中的文本元组、嵌入在数字组件对象中的超链接或统一资源定位符、产品的链接或产品描述。
74.文本生成器114可以将从可视数字组件、元数据或相应的链接获得的文本的元组输入到自然语言生成模型中以生成文本。文本生成器114可以包括、配置有或者访问自然语言生成引擎或组件。自然语言生成可以是指将结构化数据转换为自然语言的过程。文本生成器114通过使用自然语言生成,可以生成可以由文本到可由语音系统读出的文本。
75.配置有自然语言生成技术的文本生成器114可以在多个阶段中生成文本,诸如:内容确定(例如,确定在文本中提及了什么信息);文档结构化(例如,要传达的信息的整体组织);聚合(例如,合并相似的句子以提高可读性和自然性);词汇选择(例如,用文字来解释概念);指代表达生成(例如,创建用于识别对象和区域的指代表达);以及实现(例如,创建实际文本,其根据语法、词法和拼字法的规则可能是正确的)。
76.文本生成器114可以通过使用机器学习来(诸如在人类书面文本的大型语料库上)训练统计模型以执行自然语言生成。机器学习可以处理与例如由3p数字内容提供者设备160提供的数字组件对象相对应的人类书面文本,以便训练模型。
77.文本生成器114可以使用序列-序列模型来生成文本。序列-序列模型可以包括两个部分:编码器和解码器。编码器和解码器可以是组合在一个网络中的两种不同的神经网络模型。该神经网络可以是递归神经网络(“rnn”),诸如长短期记忆(“lstm”)块。所述网络的编码器部分可以被配置为理解输入序列(例如,与可视数字组件中的文本相对应的元组、嵌入数字组件对象中的超链接或统一资源定位符、产品链接或产品描述),且然后创建所述输入的较小尺寸表示。编码器可以将该表示转发到解码器网络,该解码器网络可以被配置为生成用于表示输出的序列。解码器可以在每次解码器的迭代步骤中逐个生成单词。
78.文本生成器114可以使用生成对抗网络(“gan”)来生成文本。gan可以是指通过引入被配置为检测生成的文本是“真实的”还是“伪造的”的对手(例如,鉴别器网络)而被训练以产生真实样本的生成器网络。例如,鉴别器可以是用于调谐所述生成器的动态更新的评估度量。gan中的生成器和鉴别器可以不断改善,直到达到平衡点为止。
79.因此,文本生成器114可以通过使用自然语言生成技术、基于可视数字组件对象来生成文本。内容转换组件110可以选择数字声纹以用于将文本输出为语音。内容转换组件110可以包括语音选择器116,该语音选择器116被设计、构造和操作为选择数字语音以渲染文本。内容转换组件110可以基于数字组件对象的场境或基于所生成的文本来选择数字语音。语音选择器116可以选择与数字组件对象的类型或文本的上下文匹配的数字语音。例如,与用于动作电影的广告相比,语音选择器116可以为枕头的广告选择不同的数字语音。
80.为了选择数字声纹以生成用于由文本生成器114所生成的文本的音轨,语音选择器116可以使用由机器学习引擎122通过使用历史数据所训练的语音模型126。用于训练语音模型126的历史数据可以包括例如,由3p数字内容提供者创建以经由计算设备140或其他
介质呈现的音频数字组件对象。历史数据可以包括与由3p数字内容提供者创建的每个音频数字组件对象相关联的元数据或场境信息。元数据或场境信息可以包括例如主题、概念、关键字、地理位置、品牌名称、垂直元类别、产品类别、服务类别或描述音频数字组件对象的各方面的其他信息。历史数据可以包括与音频数字组件对象相关联的性能信息。性能信息可以指示终端用户是否与音频数字组件进行了交互,诸如有关音频数字组件对象的选择或转化。
81.例如,历史数字组件可以包括由3p内容提供者创建的电台广告(例如广播电台或数字流媒体广播电台)、电视广告(例如广播或有线电视或数字流媒体电视频道)以在电视、电台或计算设备140上广播。这些历史数字组件可以包括音频和可视组件(如果在电视上呈现的话)。与电视广告相关联的元数据或场境信息可以包括产品类型(例如汽车、旅行、消费电子产品或食品)、服务类型(例如税务服务、电话服务、互联网服务、餐厅、送货服务或家庭服务)、有关产品或服务的描述性信息、有关提供产品或服务的公司或实体的信息、要在其上提供广告的地理位置(例如州、地理区域、城市或邮政编码)、或其他关键字。因此,历史数据可以包括与3p数字组件对象的音频(或音视频)相对应的音轨,以及与该音轨关联的元数据。在表1中示出了用于存储历史3p数字组件对象的示例性数据结构。
[0082][0083]
表1:历史数据的示例性示例
[0084]
表1提供了历史数据的说明性示例,所述历史数据可由机器学习引擎122使用以训练由语音选择器116使用以选择数字语音的语音模型126以用来渲染文本生成器114生成的文本。如表1所示,每个历史3p数字组件对象可以包括音轨(例如audio_1.mp3和audio_2.mp3)、广告是否用于产品或服务的指示、垂直元市场的指示(例如汽车或银行业)、提供广告的位置的指示(例如美国或诸如新英格兰的地理区域)、广告的品牌或提供者(例如company_a或company_b)、以及与数字组件对象相关联的其他描述或关键字(例如,豪华跑车或低利率信用卡优惠)。音频文件可以采用任何格式,包括例如.wav、.mp3、.aac或任何其他音频格式。在一些情况下,历史数字组件对象可以同时包含音频和视频,在这种情况下,音频文件格式可以是指音频和可视文件格式,诸如.mp4、.mov、.wmv、.flv或其他文件格式。
[0085]
数据处理系统102可以对历史数字组件数据进行预处理,以使数据处于以适合于机器学习引擎122的格式来处理该数据以训练语音模型126。例如,语音选择器116或机器学习引擎122可以配置有音频处理技术或解析技术,以处理历史数字组件数据来识别数据中的特征。特征可以包括例如,音频文件中的音频特性、产品/服务、垂直元类别、描述中的关键字、或其他信息。示例性音频特征可以包括语音的性别、语音的年龄范围、音调、频率、幅度或响度、语调、方言、语言、口音、说话的速率、或其他特征。
[0086]
机器学习引擎122可以使用任何机器学习或统计技术来分析历史数据并训练语音模型126。机器学习引擎122可以被配置有可以基于样本数据或训练数据(例如,历史数字组件对象)来构建模型的学习技术或功能,以便进行预测或决策。机器学习引擎122可以被配
置有监督或无监督学习技术、半监督学习、强化学习、自学习、特征学习、稀疏词典学习、或关联规则。为了执行机器学习,机器学习引擎122可以创建在训练数据上训练的语音模型126。该模型可以基于例如,人工神经网络、决策树、支持向量机、回归分析、贝叶斯网络或遗传算法。
[0087]
语音选择器116在接收到由文本生成器114基于可视数字组件生成的文本时,可以使用该文本以及与可视数字组件相关联的元数据,以通过使用经由机器学习引擎122训练的语音模型126来选择数字声纹。例如,数据处理系统102可以经由语音模型126,基于数字组件对象的场境选择数字语音。场境可以包括或是指或包括与数字组件对象相关联的文本、元数据或其他信息。场境可以是指或包括与计算设备140相关联的信息。在一些情况下,语音选择器116可以基于计算设备140的场境(诸如交通方式、位置、偏好、性能信息或与计算设备140相关联的其他信息)来选择数字语音。
[0088]
语音选择器116可以将数字组件对象的场境输入到语音模型126中以生成语音特征向量,且然后选择数字语音以渲染文本。文本和元数据可以指示有关产品、服务、垂直元类别、关键字或者可以输入到语音模型126中的其他信息的信息。语音模型126的输入可以是基于可视数字组件生成的文本,或者可视数字组件的文本和元数据的组合。语音模型126的输出可以是语音特征向量,该语音特征向量预测数字声纹的特征以用于渲染文本。输出可以指示数字声纹的性别(例如,男性或女性)、语调(例如,语调可以针对文本中的每个音节改变)、重音、发音、音高、响度、语速、语调、质感、响度或其他信息。语音模型126的输出可以包括其他语音类型,诸如男低音、男中音、男高音、女低音、女中音和女高音。
[0089]
语音选择器116可以将由语音模型126输出的语音特征向量与存储在数据存储库124中的可用数字声纹进行比较,以识别匹配的数字声纹或最接近的匹配数字声纹。可以基于性别、口音、发音、音调、响度、语速或其他信息对数字声纹进行分类。语音选择器116可以将语音模型126的输出与所存储的或可用的数字声纹进行比较,以选择最接近的匹配数字声纹以用于渲染文本。语音选择器116可以加权所述特征以选择匹配的声纹。例如,与诸如音调的特征相比,更重地加权诸如性别的特征。与诸如音调的特征相比,更重地加权诸如语速的特征。在一些情况下,语音选择器116可以选择与大多数特征相匹配的数字语音。语音选择器116可以使用任何匹配技术来基于语音模型126的输出选择数字声纹。
[0090]
所选择的数字声纹可以包括用于识别数字声纹的唯一标识符。数字声纹可以包括内容转换组件110可以用来执行文本到语音转换的信息。数字声纹可以包括文本到语音引擎的指令。内容转换组件110可以使用任何类型的文本语音转换技术来使用由数字声纹指示的语音特性来渲染文本。例如,内容转换组件110可以使用神经网络技术以通过使用由数字声纹定义的类人语音来渲染文本。
[0091]
内容转换组件110可以使用文本语音转换技术并且基于所选择的数字声纹来生成所渲染的文本的基线音轨。例如,内容转换组件110可以包括音频提示生成器118,该音频提示生成器118被设计、构造和操作以利用由数字语音渲染的文本构造数字组件对象的基线音轨。音频提示生成器118可以根据数字语音,使用文本语音转换引擎来渲染或合成文本。
[0092]
内容转换组件110可以确定将非话语音频提示添加到基线音轨。音频提示生成器118可以被设计、配置和操作为生成非话语音频提示以添加到基线音轨。非话语提示可以包括或是指声音效果。非话语可以包括例如,海浪声、风声、树叶沙沙作响、汽车发动机、驾驶、
飞机起飞、人群欢呼、运动、动作电影效果(例如,高速追车、直升机等)、跑步、骑自行车或其他声音效果。因此,非话语音频提示可以是指其中缺少带有单词或数字(例如,所说单词)的语音的声音或声音效果。
[0093]
音频提示生成器118可以基于数字组件对象的文本或元数据来生成一个或多个非话语音频提示。音频提示生成器118可以基于为文本选择的数字语音来生成一个或多个非话语音频提示。音频提示生成器118可以基于计算设备140的场境(例如,交通方式、计算设备的类型、正在计算设备140的前台中执行的应用152的类型、应用152中呈现的内容或从计算设备140接收的要求)来选择非话语音频提示。
[0094]
音频提示生成器118可以使用音频提示模型134或音频提示数据库来选择一个或多个非话语音频提示以添加到基线音轨。音频提示134数据库可以包括用元数据标记的声音效果,诸如声音效果的指示符。例如,可以用诸如“海浪”之类的声音效果的描述来标记海浪的声音效果。音频提示134数据库可以包括多种类型的海浪声音效果,并且包括在每个海浪之间进行区分的相应标签或描述。
[0095]
在一些情况下,可以针对数字语音中的特性配置或优化音频提示。可以优化某些音频提示以呈现为用于具有某些语音特征向量的数字语音的背景声音效果。优化的声音效果可以是指可以与利用数字语音对文本的渲染一起被渲染的声音效果,而不会阻碍或分散所述文本,目的是使所述文本可被用户理解,从而提供改进的用户界面。例如,具有与数字语音相同的频率和幅度的声音效果可能会使得难以感知、辨别或区分数字语音和声音效果,从而导致用户体验下降,并且由于提供无效的输出而浪费计算资源利用率。
[0096]
音频提示生成器118可以在可视数字组件上执行图像识别,以识别数字组件对象中的可视对象。音频提示生成器118可以忽略与可视数字组件相关联的任何文本,并且执行图像识别以检测对象。音频提示生成器118可以使用任何图像处理技术或对象检测技术。音频提示生成器118可以使用由机器学习引擎122并且基于训练数据集训练的模型,该训练数据集包括用对象的描述标记的对象的图像。机器学习引擎122可以利用训练数据来训练模型,使得音频提示生成器118可以使用该模型来检测输入到模型中的新图像中的对象。音频提示生成器118可以使用训练的模型来检测可视数字组件对象中的图像。因此,音频提示生成器118可以对可视数字组件对象执行图像识别以识别数字组件对象中的可视对象。音频提示生成器118可以从存储在数据存储库124中的非话语音频提示134中选择与可视对象相对应的非话语音频提示。
[0097]
音频提示生成器118还可以通过访问嵌入在可视数字组件中的链接(诸如到与数字组件对象相对应的登录网页的链接)来识别对象。音频提示生成器118可以解析网页以识别可视对象以及附加的场境信息、关键字或元数据。音频提示生成器118可以基于对象、场境信息、关键字或元数据来选择音频提示。例如,登录网页的文本可以包括关键字“海滩,度假,邮轮(beach,vacation,cruise)”。音频提示生成器118可以选择与一个或多个关键字相对应的音频提示。
[0098]
如果音频提示生成器118基于可视对象中的图像或与可视数字组件或链接到数字组件的网页的元数据相关联的其他关键字或场境信息来识别多个候选音频提示,则音频提示生成器118可以选择一个或多个非话语音频提示。音频提示生成器118可以使用策略来确定要选择多少个非话语音频提示。该策略可以是选择所有已识别的音频提示、随机选择预
定数量的音频提示、交替通过整个音轨中的不同的音频提示、覆盖或混合一个或多个音频提示、或选择预定数量的最高排名的音频提示。
[0099]
例如,音频提示生成器118可以识别可视数字组件中最突出的对象,并且选择与最突出的对象相对应的音频提示。对象的突出可以是指可视数字组件中的对象的大小(例如,可视数字组件中最大的对象可以是最突出的对象)。突出可以基于对象在图像的前景中而不是在背景中。音频提示生成器118可以识别在可视数字组件中、与文本生成器114生成的文本最相关的对象。可以基于对象和文本的描述来确定相关性。例如,如果所生成的文本包括对象的名称或对象的描述中的关键字,则可以确定该对象与该文本相关。音频提示生成器118可以确定与文本最相关的关键字或概念,并且为音频提示选择那些关键字。
[0100]
音频提示生成器118可以基于突出、相关性、或者突出与相关性两者对所述对象进行排名。音频提示生成器118可以基于该排名来确定选择一个或多个音频提示。例如,音频提示生成器118可以选择最高排名的音频提示、前两个最高排名的提示、前三个最高排名的提示、或一些其他数量的音频提示。
[0101]
在一些情况下,基于从由数字语音渲染的文本中分散的音频提示,音频提示生成器118可以滤除、移除或防止将音频提示添加到基线音轨。例如,音频提示生成器118可以经由图像识别技术来识别数字组件对象中的多个可视对象。音频提示生成器118可以基于元数据(例如,由3p数字内容提供者设备160提供的元数据或与对应于数字组件对象中的链接的登录页面相关联的关键字)和文本来识别多个非话语音频提示。音频提示生成器118可以确定每个可视对象的匹配得分,该匹配得分指示在每个可视对象和元数据之间的匹配程度。音频提示生成器118可以使用任何匹配技术来确定匹配得分,诸如相关性、广泛匹配、短语匹配或精确匹配。音频提示生成器118可以使用类似于内容选择器组件108的技术来确定匹配得分。音频提示生成器118可以基于匹配得分对非话语音频提示进行排名。在一些情况下,音频提示生成器118可以选择最高的一个或多个排名音频提示。
[0102]
在一些情况下,音频提示生成器118可以选择最高排名的一个或多个音频提示,其不会干扰、混合、阻碍或以其他方式负面影响使用数字语音合成的文本。例如,音频提示生成器118可以确定在每个非话语音频提示渲染文本所选的数字语音之间的音频干扰程度。例如,可以使用一个或多个因素(诸如振幅、频率、音调或时序)来确定干扰程度。在说明性示例中,具有与合成文本相同的频率和幅度的声音效果可能会导致高干扰程度,这将妨碍终端用户准确地感知所渲染的文本。在另一示例中,大的撞击声会分散文本的注意力。但是,整个话语音轨中的较低幅度的轻柔微风声可能不会分散文本的注意力。
[0103]
为了确定干扰程度,音频提示生成器118可以确定由非话语音频提示对合成文本造成的干扰量。所述量可以是文本的百分比、连续的持续时间或相对于文本的分贝级别。在一些情况下,干扰可以基于信噪比或文本信号与非话语提示信号的比。可以使用等级(例如,低、中或高)或数值(例如,以1到10的刻度或任何其他刻度,其中,该刻度的一端表示无干扰,而该刻度的另一端表示完全干扰)指示干扰程度。完全干扰可以是指可以完全抵消合成文本的破坏性干扰。
[0104]
在一些情况下,音频提示发生器118可以通过将与合成文本相对应的音频波形和非话语音频提示进行组合、且然后处理组合信号以确定终端用户是否能够感知到该合成文本来确定干扰程度。音频提示生成器118可以使用类似于接口104或自然语言处理器组件
106的音频处理技术来验证、校验或确定数据处理系统102本身是否可以准确地感知合成文本,这可以指示终端用户是否也将能够主动感知音轨。
[0105]
在识别出具有小于预定阈值的干扰程度(例如,低干扰、小于5、6、7或其他度量的干扰得分)的音频提示时,音频提示生成器118可以选择音频干扰程度小于阈值的最高排名的非话语音频提示。
[0106]
音频提示生成器118可以将所选择的非话语音频提示与基线音轨组合以生成数字组件对象的音轨。音轨可以对应于基于可视数字组件对象的仅音频数字组件对象。音频提示生成器118可以使用任何音频混合技术来将非话语提示与基线音轨组合。例如,音频提示生成器118可以将非话语音频提示覆盖在基线音轨上,将非话语音频提示添加为背景音频,在合成文本之前或之后或在合成文本之间插入非话语音频提示。数据处理系统102可以包括数字混合组件,该数字混合组件被配置为组合、改变两个或更多个输入音频信号的动态、均衡或其他改变特性以生成音轨。数据处理系统102可以接收非话语音频提示和基线音轨,并且将两个信号求和以生成组合的音轨。数据处理系统102可以使用数字混合过程来组合输入音频信号,从而避免引入不期望的噪声或失真。
[0107]
因此,一旦合成了基线音频格式,数据处理系统102就可以执行插入可以从元数据确定的非话语音频提示或伴奏曲的第二生成步骤。例如,如果可视数字组件看起来像带有棕榈树的海滩胜地,则数据处理系统102可以合成波浪和风吹动树叶的音频,并且将合成的音频添加到文本到语音基线音轨,以生成音轨。
[0108]
在一些情况下,动作生成器136可以将预定或固定的音频添加到基线音轨或具有非话语提示的生成的音轨。例如,数据处理系统102可以使用启发式或基于规则的技术来确定添加短语,诸如“更多信息请访问我们的网站(learn more about this on our website)”。这可以提示用户然后独立地执行与数字组件对象无关的动作。数据处理系统102可以基于历史性能信息、音轨的时间长度或者基于配置或设置(例如,由数据处理系统102的管理员设置的默认设置,或可以由3p数字内容提供者设备160提供的设置)来确定自动地添加固定音频。在一些情况下,固定音频可以包括语音输入的提示,诸如“您想在我们的网站上了解更多有关此的信息吗?(would you like to learn more about this on our website?)”。数据处理系统102可以配置音频数字组件对象以响应于提示,诸如在这种情况下的“是”来检测触发词,以便随后自动地执行与提示相对应的数字动作。
[0109]
数据处理系统102可以将所生成的音轨提供给计算设备140,以使计算设备140经由扬声器(例如,换能器144)输出或呈现音轨。在一些情况下,数据处理系统102可以将可进行动作的命令添加到音轨。内容转换组件110可以包括动作生成器136,该动作生成器136被设计、配置并且可操作为向音轨添加触发词。触发词可以有助于与音轨的交互。预处理器142可以侦听触发词,然后响应于该触发词以执行动作。触发词可以成为在预定的时间间隔,诸如在音轨的回放期间和在音轨之后的预定时间量(例如1秒、2秒、5秒、10秒、15秒或其他适当的时间间隔)内,保持活动的新的唤醒或热词。响应于在由计算设备140的麦克风(例如,传感器148)检测到的输入音频信号中检测到触发词,数据处理系统102或计算设备140可以执行与触发词相对应的数字动作。
[0110]
在说明性示例中,音轨可以包括广告,以购买游轮票并去带海滩的岛度假。音轨可以包括提示,诸如“would you like to know the price of the cruise tickets?(您想
知道游轮票的价格吗?)”。触发词可以是“是”或“价格是多少(what is the price)”、“价格多少(how much does it cost)”或传达用户请求门票价格的意图的一些其他变体。数据处理系统102可以将触发词提供给计算设备140或计算设备140的预处理器142,使得预处理器142可以检测在由用户提供的后续语音输入中的触发关键字。响应于检测到语音输入中的触发词,预处理器142可以将语音输入转发到数据处理系统102。nlp组件106可以解析语音输入并执行与语音输入相对应的动作,诸如将用户引导到与呈现给用户或以其他方式访问和提供所请求的信息的数字组件相关联的登录页面。
[0111]
触发关键字可以链接到各种数字动作。示例性数字动作可以包括提供信息、启动应用、启动导航应用、播放音乐或视频、订购产品或服务、控制设备、控制照明设备、控制物联网使能的设备、从餐馆中订购食物、进行预订、订购拼车、预订电影票、预订机票、控制智能电视、或其他数字动作。
[0112]
动作生成器136可以使用一种或多种技术来为数字组件对象选择动作。动作生成器136可以使用启发式技术以从一组预定动作中选择动作。动作生成器136可以使用动作模型128,该动作模型128被配置为将所生成的文本接收为输入并输出预测动作。
[0113]
例如,动作生成器136可以确定数字组件对象的类别。该类别可以指的是垂直元类别,诸如汽车、银行、运动、服装等。动作生成器136可以执行查找或查询具有该类别的数据库,以检索一个或多个触发词以及为该类别建立的数字动作。该数据库可以包括类别与触发关键字和数字动作的映射。表2图示了类别与触发词和动作的示例性映射。
[0114][0115]
表2:将类别映射到触发词和数字动作的说明性示例
[0116]
表2图示了类别与触发词和数字操作的示例性映射。如表2所示,类别可以包括拼车、旅行和购车。动作生成器136可以基于对数字组件对象生成的文本、与数字组件对象相关联的元数据、或者与嵌入数字组件对象中的链接相关联的解析数据,来确定所选择的数字组件对象的类别。在一些情况下,3p数字内容提供者设备160可以提供类别信息以及元数据。在一些情况下,动作生成器136可以使用语义处理技术,以基于与数字组件对象相关联的信息来确定类别。
[0117]
动作生成器136在识别或确定数字组件对象的类别后,可以执行查找或查询映射(例如,表2)。动作生成器136从映射中检索对应于与类别相关联的一个或多个数字动作的一个或多个触发词。例如,如果动作生成器136将类别标识为“拼车”,则动作生成器136可以响应于查询或查找而检索触发关键字“是(yes)”、“乘车(ride)”、“订车(order a ride)”或“去往(go to)”。动作生成器136可以进一步识别数字动作:在计算设备140上启动拼车应
用;或预订拼车来接用户。动作生成器136可以为音频数字组件对象配置指令以检测所有触发关键字并响应于检测到触发关键字来执行相应的数字动作。
[0118]
在一些情况下,动作生成器136可以确定将一个或多个但并非全部检索到的触发关键字和数字动作添加到数字组件对象。例如,动作生成器136可以使用基于触发关键字的历史性能训练的数字动作模型128,对基于数字组件对象的场境和客户端设备的类型的触发词进行排名。动作生成器136可以选择最高排名的触发关键字以添加到音轨。
[0119]
动作模型128可以由机器学习引擎122使用训练数据来训练。训练数据可以包括与触发关键字相关联的历史性能信息。历史性能信息可以包括对于每个触发关键字,触发关键字是否导致交互(例如,计算设备140在呈现音轨之后接收到的语音输入中检测到触发关键字)、与数字组件对象相关联的场境信息(例如,交互程中的类别、关键字、概念或状态)以及交互的场境信息。计算设备140的场境可以包括例如计算设备140的类型(例如,移动设备、膝上型设备、智能电话或智能扬声器)、计算设备140的可用接口、交通方式(例如,步行、驾驶、静止、骑自行车等)或计算设备140的位置。例如,如果交通方式是跑步、骑自行车或驾驶,则数据处理系统102可以选择可能不需要可视或触摸输入的交互类型,因此可能导致音频输出,以改善用户体验。
[0120]
机器学习引擎122可以基于该训练数据来训练动作模型128,使得动作模型128可以基于数字组件对象的场境和计算设备140来预测最有可能导致交互的触发关键字。因此,动作生成器136可以在实时过程中自定义或定制动作以添加到数字组件对象,以提供最有可能导致交互的触发关键字。通过将触发关键字的数量限制为最有可能导致由动作模型128确定的交互的关键字数量,动作生成器136可以提高预处理器142或nlp组件106准确可靠地检测到触发关键字的可能性,同时减少计算设备140的用户无意中导致执行不必要的动作的可能性。此外,通过限制触发词的数量,动作生成器136可以通过减少经由网络105传输的命令或数据分组的数量,以及减少预处理器142处理的触发词的数量,从而减少网络带宽通信和计算资源利用率。
[0121]
数据处理系统102可以将数字组件对象的音轨提供给计算设备140,以经由计算设备140的扬声器输出。在一些情况下,数据处理系统102可以确定用于数字组件对象的音轨的插入点。插入点可以是指相对于计算设备140的音频输出的时间点。音频输出可以对应于数字流媒体音乐或经由在计算设备140上执行的应用152提供的其他音频(或视听)输出。数据处理系统102可以确定插入时间,以便防止正由计算设备140输出的主要音频内容模糊或失真,同时提高所生成的音轨被终端用户感知并最终接收交互的用户体验和可能性。
[0122]
数据处理系统102可以包括内容插入组件120,该内容插入组件120被设计、构造和可操作为识别音轨的插入点。内容插入组件120可以识别由计算设备140输出的数字媒体流中的音轨的插入点。内容插入组件120可以使用插入模型130来识别该插入点。机器学习引擎122可以使用历史性能数据来训练该插入模型130。历史性能数据可以包括或被称为训练数据。用于训练插入模型130的历史性能数据可以包括关于用于数字媒体流中插入的音轨的历史插入点的数据。所述数据可以指示何时插入音轨、关于音轨的场境信息、关于数字媒体流的场境信息、用户是否与音轨进行了交互、用户如何与音轨进行交互(例如,用户采取了何种动作或交互是肯定的还是否定的)或有关计算设备140的场境信息(例如,计算设备的类型、计算设备的可用接口或计算设备的位置)。
[0123]
机器学习引擎122可以使用该训练数据来训练插入模型130。机器学习引擎122可以使用任何技术来训练插入模型130,以便可以使用插入模型130来预测何时将基于可视数字组件对象所生成的音轨插入数字内容流(例如,流媒体音乐、新闻、播客、视频或其他媒体)中
[0124]
内容插入组件120可以基于使用历史性能数据训练的插入模型130来识别插入点。插入点可以是例如,在当前流媒体片段之后并且在下一个片段开始之前。每个片段可以对应于另一首歌曲。在另一个示例中,诸如播客,内容插入组件120可以使用插入模型130确定在片段期间插入音轨。内容插入组件120可以在该片段开始之后和该片段结束之前插入音轨。例如,片段可以具有30分钟的持续时间,并且内容插入组件120可以使用插入模型130来确定在片段播放15分钟之后插入音轨。
[0125]
内容插入组件120可以基于当前场境(例如,所生成的音轨的场境、流媒体和计算设备140)来确定定制插入点。内容插入组件120可以实时确定定制插入点。如果第一和第二计算设备是不同类型的计算设备(例如,膝上型计算机与智能扬声器),则与第二计算设备140相比,内容插入组件120可以对第一计算设备140确定不同的插入点。内容插入组件120可以基于与不同计算设备相关联的交通模式(例如,步行、驾驶、静止)来针对第一计算设备140和第二计算设备140确定不同的插入点。
[0126]
内容插入组件120可以确定接近数字媒体流中的关键字、术语或概念插入音轨。内容插入组件120可以监视数字媒体流以检测与音轨相关的数字媒体流中的触发词,然后确定在数字媒体流中检测到的触发词之后或响应于该触发词而插入仅音频的数字组件对象。
[0127]
内容插入组件120可以从3p电子资源服务器162获得数字媒体流的片段的副本。内容插入组件120可以解析数字媒体流的片段,以识别所有令牌(例如,关键字、主题、或概念)和片段中的句子。内容插入组件120可以确定每个令牌和句子的相关性得分,以确定令牌或句子与数字组件对象具有怎样的相关性。内容插入组件120可以选择具有最高相关性得分的令牌,然后提供仅音频数字组件对象以与所选择的令牌相邻地插入(例如,在呈现令牌之前或之后)。
[0128]
在一些情况下,内容插入组件120可以识别数字媒体段中的所有令牌,并且执行蒙特卡洛仿真,其中,在每个令牌附近插入音轨。内容插入组件120可以将变化输入到神经网络引擎中以确定哪个插入点听起来最好。可以基于训练数据来训练神经网络,该训练数据包括使用机器学习技术插入数字媒体流中的人类评分的音轨。例如,内容插入组件120可以使用插入模型130来确定插入点。训练数据可以包括人类评分器,其对在插入点处具有音轨的数字媒体流进行分级。等级可以是二进制的,诸如好或坏,或者可以是比例尺上的得分(例如,0到10,其中,10表示最佳发声轨道,0表示最差发声轨道)。
[0129]
在一些情况下,内容插入组件120可以使用启发式技术来确定所生成的音轨的插入点。启发式技术可以基于数字媒体流的类型而有所不同。如果数字媒体流的内容是歌曲,则启发式规则可以是在歌曲播放完毕后插入所生成的音轨。如果数字媒体流的内容是播客,则启发式规则可以是在包含相关令牌的句子之后插入音轨。
[0130]
在选择插入点之后,数据处理系统102可以向计算设备140提供指令以使计算设备140在数字媒体流中的插入点处渲染音轨。
[0131]
图2是根据一种实施方式的生成音轨的方法的图示。方法200可以由图1或3中描绘
的一个或多个系统、组件或模块来执行,包括例如,数据处理系统、接口、内容选择器组件、自然语言处理器组件、内容转换组件或计算设备。在判定框202,数据处理系统可以确定是否已经接收到输入信号。输入信号可以对应于由远离数据处理系统的计算设备检测到的语音输入。输入信号可以包括传达音频输入信号的数据分组,诸如由计算设备的麦克风检测到的语音输入。数据处理系统可以经由数据处理系统的接口来接收输入信号。数据处理系统可以经由网络从计算设备接收输入信号。
[0132]
如果在判定框202,数据处理系统确定接收到输入信号,则数据处理系统可以进行到动作204以解析输入信号并检测请求。数据处理系统可以使用自然语言处理技术来解析输入信号并检测输入信号中的一个或多个关键字、术语、概念、短语或其他信息。
[0133]
数据处理系统可以前进到判定框206以确定是否选择内容。选择内容可以是指执行实时内容选择过程以选择由第三方数字组件提供者提供的数字组件对象。选择内容可以是指通过使用由第三方数字组件提供者提供的内容来选择标准执行实时在线拍卖。
[0134]
如果数据处理系统在动作204,在输入信号中检测到对内容的请求,则数据处理系统可以在判定框206确定选择内容。在数据处理系统在判定框202确定未接收到输入信号的情况下,则数据处理系统还可以在判定框206决定选择内容。例如,数据处理系统可以主动确定执行在线内容选择过程,并且将数字组件对象推送到计算设备,而无需从计算设备接收对数字组件对象的明确请求。数据处理系统可以识别由计算设备输出的数字音乐流中的呈现机会(例如,在媒体片段或歌曲之间),并且自动确定在该机会提供数字组件对象。因此,在一些情况下,数据处理系统可以接收对内容的请求,然后执行内容选择过程,而在其他情况下,数据处理系统可以不接收内容,而是主动确定执行内容选择过程。在数据处理系统接收到对内容的请求的情况下,该请求可以针对主要内容(例如,响应于在输入音频信号中的查询的搜索结果),并且数据处理系统可以执行在线拍卖以选择响应于该请求的补充内容(例如,与广告相对应的数字组件对象),但不同于直接响应于所述输入查询的非付费搜索结果。
[0135]
如果在判定框206,数据处理系统确定不执行用于选择3p数字组件提供者的数字组件对象的内容选择过程,则数据处理系统可以返回到判定框202,以确定是否接收到输入信号。然而,如果数据处理系统在判定框206处确定选择内容,则数据处理系统可以前进到动作208以执行内容选择过程来选择内容。数据处理系统(例如,经由内容选择器组件)可以通过使用内容选择标准或与输入请求、计算设备或数字流媒体内容相关联的其他场境信息来选择数字组件对象。
[0136]
数据处理系统可以选择具有格式的数字组件对象,诸如配置为经由计算设备的显示设备进行显示的仅可视数字组件对象、配置为经由计算设备的扬声器进行回放的仅音频数字组件对象、或配置为经由计算设备的显示器和扬声器两者进行输出的视听数字组件。
[0137]
在判定框210,数据处理系统可以确定是否将选择的数字组件转换为不同的格式。例如,如果所选择的数字组件对象是仅可视格式,则数据处理系统可以确定是否以可视格式将数字组件对象提供给计算设备以经由计算设备的显示设备呈现,或者将数字组件对象转换为不同的格式,以经由诸如扬声器之类的计算设备的不同输出接口呈现。
[0138]
数据处理系统(例如,格式选择器)可以确定是否转换数字组件对象。数据处理系统可以基于计算设备的可用接口、计算设备的主要接口、计算设备的场境(例如,交通方
式)、计算设备的类型、或其他因素来做出决定。如果在判定框210,数据处理系统确定不将所选择的数字组件对象转换成不同的格式,则数据处理系统可以前进到动作212,并且将所选择的数字组件对象以其原始格式传输到计算设备。
[0139]
然而,如果数据处理系统在判定框210处确定将数字组件对象转换为不同格式,则数据处理系统可以前进到动作214以生成文本。例如,如果原始格式是仅可视格式,并且数据处理系统确定将数字组件转换为仅音频格式,则数据处理系统可以前进到动作214以生成用于可视数字组件对象的文本。数据处理系统(例如,经由文本生成器)可以使用自然语言生成技术基于可视数字组件对象来生成文本。数据处理系统可以基于仅数字组件对象的可视内容来生成文本。可视内容可以是指图像。在一些情况下,数据处理系统可以基于与可视数字组件对象相关联的元数据来生成文本。
[0140]
在动作216,数据处理系统可以选择数字语音以用于合成或渲染文本。数据处理系统可以使用所选的数字语音对生成的文本执行文本到语音的转换。数据处理系统可以基于所生成的文本、与数字组件对象相关联的场境信息(例如,关键字、主题、概念、垂直元类别)、元数据、与计算设备相关联的场境信息来选择数字语音。数据处理系统可以使用基于机器学习技术和历史数据训练的模型来选择要用于合成所生成的文本的数字语音。例如,数据处理系统可以将与数字组件对象(例如元数据)相关联的场境信息输入模型中,并且该模型可以输出语音特征向量。语音特征向量可以指示性别、语速、语调、响度或其他特征。
[0141]
数据处理系统可以选择与语音特征向量匹配的数字语音。数据处理系统可以使用所选择的数字语音来构建基线音轨。数据处理系统可以构建如由语音特征向量指示的基线音轨。例如,数字语音可以包括固定特征(诸如性别)以及动态特征(例如语速、语调或响度)。动态特征可以在每个音节的基础上变化。数据处理系统可以使用文本到语音引擎,该引擎被配置为在每个音节的基础上,使用与语音特征向量相对应的固定和动态特征来合成文本。
[0142]
在动作218,数据处理系统可以生成非话语音频提示。数据处理系统可以将非话语音频提示与在动作216生成的基线音轨进行组合。为了生成非话语音频提示,数据处理系统(例如,经由音频提示生成器)可以识别可视数字组件中的对象。数据处理系统可以仅识别可视组件。数据处理系统可以识别可视和文本组件(例如,与数字组件对象相关联的元数据)两者。在识别出对象之后,数据处理系统可以识别标识或指示对象的音频提示。例如,如果数据处理系统识别出海浪和棕榈树,则数据处理系统可以选择海浪声和穿过树叶的微风声。
[0143]
数据处理系统可以通过使用任何音频混合技术来将所选择的音频提示与基线音轨进行组合。数据处理系统可以在基线音轨的一部分或整个音轨上添加非话语音频提示。数据处理系统可以以不使基线音轨中的非话语文本失真或模糊的方式将非话语音频提示添加到基线音轨,从而改善用户体验。在一些情况下,数据处理系统可以模拟组合的音轨并测试质量。例如,数据处理系统可以模拟接收组合的音轨并在组合的音轨上执行自然语言处理。数据处理系统可以通过将解析后的文本与由数据处理系统的文本生成器生成的文本进行比较,来验证数据处理系统的nlp组件是否能够准确检测话语文本。如果数据处理系统无法准确地解码组合音轨中的文本,则数据处理系统可以确定非话语音频提示会对话语文本产生负面影响,并阻止终端用户准确地识别话语文本。因此,为了改善用户体验,数据处
理系统可以去除一个或多个非话语音频提示,然后重新生成并重新测试组合的音轨。数据处理系统可以执行这种非话语音频提示的移除,然后重新生成和重新测试,直到数据处理系统可以准确解释话语文本为止。响应于确定组合音轨中的话语文本是可感知的,数据处理系统可以批准组合音轨以呈现。
[0144]
在一些情况下,数据处理系统可以将组合的音轨传输到计算设备以呈现。在一些情况下,数据处理系统可以前进到动作220,以确定音轨的插入点。数据处理系统可以使用经由机器学习技术和历史数据训练的插入模型,以确定将音轨插入计算设备正在输出的数字媒体流中的何处。数据处理系统可以确定插入点,该插入点减少计算资源利用率、网络带宽消耗、避免数字媒体流中的等待时间或延迟、或改善用户体验。例如,数据处理系统可以确定在数字媒体流的一部分的开始、期间或之后插入音轨。
[0145]
在确定插入点之后,数据处理系统可以前进到动作222,并将转换后的内容(或仅音频数字组件对象)提供给计算设备,以使计算设备渲染、播放或以其他方式呈现转换后的数字组件。在一些情况下,数据处理系统可以配置转换后的数字组件以调用、启动或执行数字动作。例如,数据处理系统可以提供指令以配置计算设备或数据处理系统来检测来自用户的后续语音输入中的触发词,然后响应于该触发词来执行数字动作。
[0146]
在一些情况下,数据处理系统可能不会接收到对内容的请求。例如,数据处理系统可以主动识别与由计算设备渲染的数字流媒体内容相关联的关键字。数据处理系统可以在判定框206处确定响应于关键字而选择内容。然后,数据处理系统可以基于关键字选择具有可视输出格式的数字组件对象。数据处理系统可以基于计算设备的类型来确定将数字组件对象转换为音频输出格式。数据处理系统可以响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。数据处理系统可以基于数字组件对象的场境来选择数字语音以渲染文本。数据处理系统可以利用数字语音渲染的文本来构造数字组件对象的基线音轨。数据处理系统可以基于数字组件对象生成非话语音频提示。数据处理系统可以将非话语音频提示与数字组件对象的基线音频形式组合,以生成数字组件对象的音轨。数据处理系统可以将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
[0147]
图3是示例性计算机系统300的框图。计算机系统或计算设备300可以包括或被用来实施系统100或其组件,诸如数据处理系统102。计算机系统300包括总线305或用于传送信息的其他通信组件、以及耦合到总线305以处理信息的处理器310或处理电路。计算系统300还可以包括耦合到总线以处理信息的一个或多个处理器310或处理电路。计算系统300还包括耦合到总线305以存储信息以及将由处理器310执行的指令的主存储器315,诸如随机存取存储器(ram)或其他动态存储设备。主存储器315可以是或包括数据存储库。主存储器315还可以被用于在由处理器310执行指令期间存储位置信息、临时变量或其他中间信息。计算系统300可以进一步包括耦合到总线305以存储用于处理器310的静态信息和指令的只读存储器(rom)320或其他静态存储设备。诸如固态设备、磁盘或光盘的存储设备325可以被耦合到总线305,以持久地存储信息和指令。存储设备325可以包括数据存储库或作为其一部分。
[0148]
计算机系统300可以经由总线305耦合到显示器335,诸如液晶显示器或有源矩阵显示器,以向用户显示信息。诸如包括字母数字和其他键的键盘的输入设备330可以耦合到
总线305,用于将信息和命令选择传送给处理器310。输入设备330可以包括触摸屏显示器335。输入设备330还可以包括光标控件,诸如鼠标、轨迹球或光标方向键,用于将方向信息和命令选择传送给处理器310并用于控制显示器335上的光标移动。显示器335可以是例如图1的数据处理系统102、客户端计算设备140或其他组件的一部分。
[0149]
本文描述的过程、系统和方法可以由计算系统300响应于处理器310执行包含在主存储器315中的指令的布置来实施。这样的指令可以从诸如存储设备325的另一计算机可读介质读入主存储器315中。执行包含在主存储器315中的指令的布置使得计算系统300执行本文所述的说明性过程。也可以采用在多处理布置中的一个或多个处理器来执行包含在主存储器315中的指令。可以使用硬布线电路代替软件指令或者与软件指令以及与本文所述的系统和方法结合。本文描述的系统和方法不限于硬件电路和软件的任何具体组合。
[0150]
虽然在图3中描述了示例性计算系统,但是包括在本说明书中描述的操作的主题可以实施在其他类型的数字电子电路中,或实施在包括在本说明书中公开的结构及其等同结构的计算机软件、固件或硬件或者它们的一个或多个组合中。
[0151]
对于本文描述的系统收集有关用户或安装在用户设备上的应用的个人信息或利用个人信息的情况,可以为用户提供机会来控制程序或功能部件是否可以收集用户信息(例如,有关用户的社交网络、社交行为或活动、职业、用户的偏好或用户的当前位置的信息)。另外或作为替代,某些数据在被存储或使用之前,可以以一种或多种方式进行处理,以便移除个人信息。
[0152]
本说明书中描述的主题和操作可以以数字电子电路、或者以计算机软件、固件或硬件(包括本说明书中公开的结构及其结构等同物)、或者它们中的一个或多个的组合实现。本说明书中描述的主题可以实现为一个或多个计算机程序(例如,编码在一个或多个计算机存储介质上的计算机程序指令的一个或多个电路,用于由数据处理装置执行或控制数据处理装置的操作)。替换地或附加地,程序指令可以编码在人工生成的传播信号上,例如,机器生成的电、光或电磁信号,其被生成以编码信息以便传输到合适的接收器装置以供数据处理装置执行。计算机存储介质可以是或包括在计算机可读存储设备、计算机可读存储基板、随机或串行存取存储器阵列或设备、或者它们的一个或多个的组合中。虽然计算机存储介质不是传播信号,但是计算机存储介质可以是以人工生成的传播信号编码的计算机程序指令的源或目的地。计算机存储介质也可以是或包括在一个或多个单独的组件或介质(例如,多个cd、磁盘或其他存储设备)中。本说明书中描述的操作可以被实施为由数据处理装置对存储在一个或多个计算机可读存储设备上或从其他源接收的数据执行的操作。
[0153]
术语“数据处理系统”、“计算设备”、“组件”或“数据处理装置”涵盖用于处理数据的各种装置、设备和机器,举例来说包括,可编程处理器、计算机、片上系统、或多个片上系统、或前述的组合。该装置可以包括专用逻辑电路,例如fpga(现场可编程门阵列)或asic(专用集成电路)。除了硬件之外,该装置还可以包括为所述的计算机程序创建执行环境的代码,例如,构成处理器固件、协议栈、数据库管理系统、操作系统、跨平台运行时环境、虚拟机、或它们的一个或多个的组合的代码。装置和执行环境可以实现各种不同的计算模型基础结构,诸如web服务、分布式计算和网格计算基础结构。自然语言处理器组件106和其他数据处理系统102或数据处理系统102组件可以包括或共享一个或多个数据处理装置、系统、计算设备或处理器。内容转换组件110和内容选择器组件108例如可以包括或共享一个或多
个数据处理装置、系统、计算设备或处理器。。
[0154]
计算机程序(也称为程序、软件、软件应用、应用、脚本或代码)可以用任何形式的编程语言编写,包括编译或解释语言、声明或过程语言,并且可以以任何形式部署,包括作为独立程序或作为模块、组件、子例程、对象、或适用于计算环境的其他单元。计算机程序可以对应于文件系统中的文件。计算机程序可以存储在保存其他程序或数据的文件的一部分(例如,存储在标记语言文档中的一个或多个脚本)中、存储在专用于所述的程序的单个文件中、或者存储在多个协调文件(例如,存储一个或多个模块、子程序或代码部分的文件)中。可以部署计算机程序以在一个计算机上或在位于一个站点上或分布在多个站点上并通过通信网络互连的多个计算机上执行。
[0155]
本说明书中描述的过程和逻辑流程可以由执行一个或多个计算机程序(例如,数据处理系统102的组件)的一个或多个可编程处理器执行,以通过对输入数据进行操作并生成输出来执行动作。过程和逻辑流程也可以由专用逻辑电路执行,并且装置也可以实施为专用逻辑电路,例如fpga(现场可编程门阵列)或asic(专用集成电路)。适用于存储计算机程序指令和数据的设备包括所有形式的非易失性存储器、介质和存储器设备,包括例如:半导体存储器设备,例如eprom、eeprom和闪存设备;磁盘,例如内部硬盘或可移动磁盘;磁光盘;以及cd rom和dvd-rom磁盘。处理器和存储器可以由专用逻辑电路补充或并入专用逻辑电路中。
[0156]
本文描述的主题可以在包括后端组件(例如作为数据服务器)或者包括中间件组件(例如应用服务器)或者包括前端组件(例如,具有通过其用户可以与本说明书中描述的主题的实施方式进行交互的图形用户界面或网络浏览器的客户端计算机)或者一个或多个这样的后端、中间件或前端组件的组合的计算系统中实施。系统的组件可以通过任何形式或介质的数字数据通信(例如通信网络)互连。通信网络的示例包括局域网(“lan”)和广域网(“wan”)、互连网(例如,互联网)和对等网络(例如,自组织对等网络)。
[0157]
诸如系统100或系统300的计算系统可以包括客户端和服务器。客户端和服务器通常彼此远离,并且通常通过通信网络(例如,网络105)进行交互。客户端和服务器的关系通过在相应的计算机上运行并且彼此具有客户端-服务器关系的计算机程序而生成。在一些实施方式中,服务器将数据(例如,表示数字组件的数据包)发送到客户端设备(例如,为了向与客户端设备交互的用户显示数据或从其接收用户输入的目的)。可以在服务器处,(例如由数据处理系统102的接口104接收)从客户端设备接收在客户端设备处生成的数据(例如,用户交互的结果)。
[0158]
虽然在附图中以特定顺序描绘了操作,但是不需要以所示的特定顺序或按顺序执行这些操作,并且不需要执行所有示出的操作。本文描述的动作可以以不同的顺序执行。
[0159]
各种系统组件的分离不需要在所有实施方式中均要求分离,并且所描述的程序组件可以包括在单个硬件或软件产品中。例如,内容置换组件110和内容插入组件120可以是单个组件、应用或程序,或具有一个或多个处理电路的逻辑设备,或者由数据处理系统102的一个或多个处理器执行。
[0160]
本技术解决方案的至少一个方面针对一种生成音轨的系统。该系统包括数据处理系统。该数据处理系统包括一个或多个处理器。该数据处理系统可以经由网络接收数据分组,该数据分组包括由远离数据处理系统的计算设备的麦克风检测到的输入音频信号。该
数据处理系统可以解析输入音频信号以识别请求。该数据处理系统可以基于请求,选择具有可视输出格式的数字组件对象,该数字组件对象与元数据相关联。该数据处理系统可以基于计算设备的类型,确定将数字组件对象转换为音频输出格式。该数据处理系统可以响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。该数据处理系统可以基于数字组件对象的场境,选择数字语音以渲染文本。该数据处理系统可以利用由数字语音渲染的文本,构造数字组件对象的基线音轨。该数据处理系统可以基于数字组件对象的元数据,生成非话语音频提示。该数据处理系统可以将非话语音频提示与数字组件对象的基线音频形式相结合,以生成数字组件对象的音轨。该数据处理系统可以响应于来自计算设备的请求,将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
[0161]
数据处理系统可以基于包括智能扬声器的计算设备的类型,来确定将数字组件对象转换为音频输出格式。数据处理系统可以基于包括数字助理的计算设备的类型,来确定将数字组件对象转换为音频输出格式。
[0162]
数据处理系统可以响应于请求,基于输入到实时内容选择过程中的内容选择标准来选择数字组件对象,数字组件对象是从由多个第三方内容提供者提供的多个数字组件对象中选择的。数据处理系统可以基于与在请求之前由计算设备渲染的内容相关联的关键字,来选择数字组件对象。数字组件对象可以是从由多个第三方内容提供者提供的多个数字组件对象中选择的。
[0163]
数据处理系统可以经由自然语言生成模型,基于数字组件对象的元数据来生成用于数字组件对象的文本。数据处理系统可以经由语音模型,基于数字组件对象的场境来选择数字语音。可以由机器学习技术利用包括音频和视频媒体内容的历史数据集来训练语音模型。
[0164]
数据处理系统可以将数字组件对象的场境输入到语音模型中以生成语音特征向量。可以由机器学习引擎利用包括音频和可视媒体内容的历史数据集训练来训练语音模型。数据处理系统可以基于语音特征向量,从多个数字语音中选择数字语音。
[0165]
数据处理系统可以基于元数据确定向音轨添加触发器。响应于在第二输入音频信号中检测到触发词导致数据处理系统或计算设备执行与触发词相对应的数字动作。
[0166]
数据处理系统可以确定数字组件对象的类别。数据处理系统可以从数据库中检索与类别相关联的多个数字动作相对应的多个触发词。数据处理系统可以使用基于触发关键字的历史性能训练的数字动作模型,基于数字组件对象的场境和计算设备的类型,对多个触发词进行排名。数据处理系统可以选择排名最高的触发关键字以添加到音轨中。
[0167]
数据处理系统可以对数字组件对象执行图像识别,以识别数字组件对象中的可视对象。数据处理系统可以从数据库中存储的多个非话语音频提示中选择与可视对象相对应的非话语音频提示。
[0168]
数据处理系统可以经由图像识别技术,识别数字组件对象中的多个可视对象。数据处理系统可以基于元数据和多个可视对象,选择多个非话语音频提示。数据处理系统可以对可视对象的每一个确定匹配得分,以指示在每个可视对象与元数据之间的匹配程度。数据处理系统可以基于匹配得分,对多个非话语音频提示进行排名。数据处理系统可以确定在多个非话语音频提示中的每一个与基于场境选择的数字语音之间的音频干扰程度,以
渲染文本。数据处理系统可以基于最高排名,从多个非话语音频提示中选择与低于阈值的音频干扰程度相关联的非话语音频提示。
[0169]
数据处理系统可以基于使用历史性能数据训练的插入模型,确定在由计算设备输出的数字媒体流中的音轨的插入点。数据处理系统可以向计算设备提供指令以使计算设备在数字媒体流中的插入点处渲染音轨。
[0170]
该技术解决方案的至少一个方面针对生成音轨的方法。该方法可以由数据处理系统的一个或多个处理器执行。该方法可以包括数据处理系统接收数据分组,该数据分组包括由远离数据处理系统的计算设备的麦克风检测到的输入音频信号。该方法可以包括数据处理系统解析输入音频信号以识别请求。该方法可以包括数据处理系统基于请求,选择具有可视输出格式的数字组件对象,该数字组件对象与元数据相关联。该方法可以包括数据处理系统基于计算设备的类型,确定将数字组件对象转换为音频输出格式。该方法可以包括数据处理系统响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。该方法可以包括基于数字组件对象的场境,选择数字语音以渲染文本。该方法可以包括数据处理系统利用由数字语音渲染的文本,构造数字组件对象的基线音轨。该方法可以包括数据处理系统基于数字组件对象,生成非话语音频提示。该方法可以包括数据处理系统将非话语音频提示与数字组件对象的基线音频形式相结合,以生成数字组件对象的音轨。该方法可以包括数据处理系统响应于来自计算设备的请求,将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
[0171]
该方法可以包括数据处理系统基于包括智能扬声器的计算设备的类型来确定将数字组件对象转换为音频输出格式。该方法可以包括数据处理系统响应于请求,基于输入到实时内容选择过程中的内容选择标准来选择数字组件对象,数字组件对象是从由多个第三方内容提供者提供的多个数字组件对象中选择的。
[0172]
该方法可以包括数据处理系统基于与在请求之前由计算设备渲染的内容相关联的关键字来选择数字组件对象。数字组件对象可以是从由多个第三方内容提供者提供的多个数字组件对象中选择的。
[0173]
该技术解决方案的至少一个方面针对一种生成音轨的系统。该系统可以包括具有一个或多个处理器的数据处理系统。该数据处理系统可以识别与由计算设备渲染的数字流媒体内容相关联的关键字。该数据处理系统可以基于关键字,选择具有可视输出格式的数字组件对象,该数字组件对象与元数据相关联。该数据处理系统可以基于计算设备的类型,确定将数字组件对象转换为音频输出格式。该数据处理系统可以响应于将数字组件对象转换为音频输出格式的确定,生成用于数字组件对象的文本。该数据处理系统可以基于数字组件对象的场境,选择数字语音以渲染文本。该数据处理系统可以利用由数字语音渲染的文本构造数字组件对象的基线音轨。该数据处理系统可以基于数字组件对象,生成非话语音频提示。该数据处理系统可以将非话语音频提示与数字组件对象的基线音频形式相结合,以生成数字组件对象的音轨。该数据处理系统可以以及将数字组件对象的音轨提供给计算设备,以经由计算设备的扬声器输出。
[0174]
数据处理系统可以基于包括智能扬声器的计算设备的类型来确定将数字组件对象转换为音频输出格式。数据处理系统可以基于输入到实时内容选择过程中的关键字来选择数字组件对象,数字组件对象是从由多个第三方内容提供者提供的多个数字组件对象中
选择的。
[0175]
现在已经描述了一些示例性实施方式,显而易见的是,前述内容是示例性的而非限制性的,已经通过示例呈现。特别地,尽管本文呈现的许多示例涉及方法动作或系统元件的特定组合,但是这些动作和那些元件可以以其他方式组合以实现相同的目标。结合一个实施方式讨论的动作、元件和特征不旨在从其他实施方式中的类似角色中排除。
[0176]
本文使用的措辞和术语是出于描述的目的,不应当被视为限制。使用“包括”、“包含”、“具有”、“含有”、“涉及”、“特征在于”、“特征是”及其变形意味着涵盖其后列出的项目、其等同物、和附加项目、以及由其后列出的项目组成的替代实施方式。在一个实施方式中,本文描述的系统和方法包括一个、多于一个的每个组合或所有所描述的元件、动作或组件。
[0177]
以单数形式提及的对本文的系统和方法的实施方式、元件或动作的任何引用也可以涵盖包括多个这些元件的实施方式,并且对本文的任何实施方式、元件或动作的以复数形式的任何引用也可以涵盖仅包括一个元件的实施方式。以单数或复数形式的引用并不旨在将当前公开的系统或方法、它们的组件、动作或元件限定到单个或多个配置。对基于任何信息、动作或元件的任何动作或元件的引用可以包括其中所述动作或元件至少部分地基于任何信息、动作或元件的实施方式。
[0178]
本文公开的任何实施方式可以与任何其他实施方式或实施例组合,并且对“实施方式”、“一些实施方式”、“一个实施方式”等的引用不一定是相互排斥的并且旨在指示结合实施方式描述的特定特征、结构或特性可以包括在至少一个实施方式或实施例中。本文使用的这些术语不一定都指的是相同的实施方式。任何实施方式可以以与本文公开的方面和实施方式一致的任何方式包含或排他地与任何其他实施方式组合。
[0179]
对“或”的引用可以被解释为包含性的,使得使用“或”描述的任何术语可以指示单个、多于一个和所描述的术语中的任何一个。对术语的组合列表中的至少一个的引用可以被解释为包括性的或,以指示单个、多于一个和所有所描述的术语中的任何一个。例如,对
““
a”和“b”中的至少一个”的引用可以仅包括“a”、仅包括“b”、以及“a”和“b”两者。与“包括”或其他开放术语结合使用的此类引用可以包括另外的项目。
[0180]
在附图、详细说明或任何权利要求中的技术特征之后是附图标记的情况下,已经包括附图标记以增加附图、详细说明和权利要求的可懂度。因此,附图标记和它们的缺失都不会对任何权利要求要素的范围具有任何限制作用。
[0181]
在不脱离其特性的情况下,本文描述的系统和方法可以以其他特定形式实现。例如,描述为3p或第三方(诸如3p数字内容提供者设备160)的设备、产品或服务可以部分地或完全地是或包括第一方设备、产品或服务,并且可以由与数据处理系统102或其他组件相关联的实体共同拥有。前述实施方式是示例性的而不是限制所描述的系统和方法。因此,本文描述的系统和方法的范围由所附权利要求而不是前面的描述指示,并且在此涵盖在权利要求的等同物的含义和范围内的变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1